
Abstract
Background
Clinical care is moving from a “one size fits all” approach to a setting in which treatment decisions are based on individual treatment response, needs, preferences, and risk. Research into personalized treatment strategies aims to discover currently unknown markers that identify individuals who would benefit from treatments that are nonoptimal at the population level. Before investing in research to identify these markers, it is important to assess whether such research has the potential to generate value. Thus, this article aims to develop a framework to prioritize research into the development of new personalized treatment strategies by creating a set of measures that assess the value of personalizing care based on a set of unknown patient characteristics.
Methods
Generalizing ideas from the value of heterogeneity framework, we demonstrate 3 measures that assess the value of developing personalized treatment strategies. The first measure identifies the potential value of personalizing medicine within a given disease area. The next 2 measures highlight specific research priorities and subgroup structures that would lead to improved patient outcomes from the personalization of treatment decisions.
Results
We graphically present the 3 measures to perform sensitivity analyses around the key drivers of value, in particular, the correlation between the individual treatment benefits across the available treatment options. We illustrate these 3 measures using a previously published decision model and discuss how they can direct research in personalized medicine.
Conclusion
We discuss 3 measures that form the basis of a novel framework to prioritize research into novel personalized treatment strategies. Our novel framework ensures that research targets personalized treatment strategies that have high potential to improve patient outcomes and health system efficiency.
Highlights
It is important to undertake research prioritization before conducting any research that aims to discover novel methods (e.g., biomarkers) for personalizing treatment.
The value of unexplained heterogeneity can highlight disease areas in which personalizing treatment can be valuable and determine key priorities within that area.
These priorities can be determined under assumptions of the magnitude of the individual-level treatment effect, which we explore in sensitivity analyses.
Keywords
Decision modeling in health generally aims to support population-level decision making by synthesizing the available evidence to identify the treatment strategy that offers the maximum benefit at the population level, among a set of potential options. 1 Although these “population-level” decisions are usually based on a small number of patient-level features (e.g., their diagnosis), greater clinical and/or economic value could be generated by personalizing treatment decisions.2–4 This is because each individual would be offered the treatment that is expected to maximize the value associated with their treatment, 2 implying that an individual would be switched from the population-level optimal treatment strategy only if greater benefit could be derived from an alternative treatment option. However, to make accurate individual-level treatment decisions and realize this additional value, significant investment must be made in research to develop these novel personalized treatment strategies.
With limited budgets available, it is important to prioritize the funding of research that has the greatest potential to efficiently improve health outcomes, thereby increasing value in the health care system. 5 Thus, research into novel personalized treatment strategies should be directed toward disease areas in which making treatment decisions at the individual level has the potential to generate value. Once a suitable disease area has been identified (e.g., breast cancer), research can be further prioritized by focusing on the development of individualized treatment strategies that have the potential to generate substantial benefit. This article aims to develop 3 measures that can indicate, alongside subject-specific expertise, key research priorities that would allow the development of valuable personalized treatment strategies.
Value-of-information (VoI) methods have long been suggested as a method for research prioritization,6–11 as they assess the impact of statistical uncertainty on decision making and prioritize research that efficiently reduces this uncertainty. 12 VoI methods require decision models that estimate the population-average benefit of each potential treatment strategy for a given disease. Typically, this population-average benefit is defined using the net monetary or net health benefit function, 13 where the net benefit values are calculated conditional on a set of decision model parameters. Uncertainty in the net benefit, and in the decision making, is induced by statistical uncertainty in the model parameters and is usually estimated by simulation. VoI then determines the value of collecting additional data to inform these parameters. 10
VoI analyses assume that decision makers are searching for a single optimal treatment strategy to implement across the whole population of interest, and decision uncertainty arises from imperfect knowledge of model parameters.14,15 However, VoI concepts have been extended to calculate the value of individualizing care by exploiting heterogeneity in individual patient response.2,4,16 First, the expected value of individualized care (EVIC) calculates the value of personalizing care based on patient preferences. 2 To achieve this, patient preferences are valued (e.g., using quality-of-life [QoL] weights) and assumed to vary across the population, making the assumption that patients are homogeneous except for these differences in preference. EVIC can then be extended and combined with previously published concepts, 4 to define the value of heterogeneity (VoH) framework. VoH is a unified theory that quantifies the expected value to be gained from making stratified treatment decisions based on patient characteristics and the value of resolving parameter uncertainty within these subgroups. 16
To calculate EVIC and VoH, we must estimate the net monetary benefit for each treatment option for each individual to determine the optimal treatment at the individual level. Once the individual optimal treatment is found, the value of personalizing treatment can be computed by comparing to the value of a single treatment for the population. 16 The EVIC calculations assume that patient preferences for a given health state are unaffected by treatment and an individual’s net benefit for each treatment option can be computed using the value they assign to different health states. VoH calculations assume that treatment decisions are stratified based on known patient characteristics (e.g., gender, health status, or body mass index). 16 Individual-level data on treatment response and baseline characteristics can then be used to calculate the net benefits for each treatment, conditional on these known characteristics (e.g., using regression). 16
However, research into individualized treatment strategies is often concerned with identifying new patient subgroups that are defined by some, currently unknown, characteristic (e.g., a novel genetic or biologic marker or a clinical algorith).17–19 In these instances, the characteristic that allows for individual treatment decisions is currently unknown. Thus, the individual net benefit across each treatment cannot be computed for a given individual, and the individual-level optimal treatment is unknown. This means that the current VoH measures cannot prioritize research studies that aim to identify these novel markers.
To address this, we generalize the VoH and EVIC measures to allow for the prioritization of research into novel personalized medicine strategies. We discuss 3 measures to generalize VoH and include a consideration of the value of unexplained heterogeneity (i.e., heterogeneity in the individual responses that cannot be explained by currently known characteristics). We demonstrate these measures using an individual-level decision model that we have adapted from a previously published model. 10 This article begins by introducing this model and its key assumptions. We then define each of the 3 measures in turn and discuss how they can help prioritize research. The first measure determines whether there is any potential to generate value by personalizing medicine in the disease area under investigation. Following this, the next 2 measures aim to highlight research areas where value is likely to be generated through the development of specific personalized treatment strategies. We discuss how these measures should be combined with subject matter expertise to undertake the research prioritization. We conclude with a discussion on the limitations of these proposed measures and suggestions for potential extensions.
Decision Making with Individual-Level Decision Models
The research prioritization framework developed in this article requires estimates of the individual-level net monetary/health benefit, a summary measure of the value of a treatment, measured in monetary or health units, respectively. 13 We assume that, in a given context, individuals are choosing between multiple treatment options. The heterogeneity in the individual-level net monetary or health benefit under each of the treatment options is estimated using an individual-level decision model that combines key outcomes into a single measure of net monetary or health benefit. Thus, the VoH is based on a model that incorporates individual-level variation into the net benefit estimates. We consider that individual-level variation includes explainable variation, for example, due to currently unknown (but feasibly collected) biomarkers, and unexplainable first-order uncertainty due to the inherent differences in outcomes. Both of these sources of variation are distinct from the commonly performed probabilistic analysis (PA; sometimes called probabilistic sensitivity analysis), which explores the impact of second-order, parametric uncertainty on decision making. 20 Note that PA forms the basis of standard VoI calculations.
Individualized decision models are generally more complex than cohort models. 21 They often require a higher number of assumptions/parameters as potential relationships between individual-level outcomes and parameters must be considered (e.g., individuals who live longer may have a lower risk of treatment-related adverse events). Detailed, accurate data to inform these individualized models are likely required to ensure the individual-level net benefit is correctly estimated. These data can come from a range of sources but will likely need to be individual patient–level data. In the relatively rare scenario in which clinical trial data are available to accurately define the net benefit, 22 modeling can be minimized and the net benefit estimated directly from these data. The proposed methodology can then be applied to those estimated net benefits.
Individual-Level Decision Models: A Case Study
We developed an individual-level decision model based on a previously published population-level decision tree, 10 depicted in Figure 1. This model calculates the individual net monetary benefit for 2 treatment options for a hypothetical disease. Under no treatment, modeled individuals are at risk of experiencing a critical event that results in a constant QoL detriment and yearly cost of treatment for the remainder of their life. A treatment is assumed to reduce the risk of this event at the population level. However, this treatment can cause transient side effects, resulting in a short-term QoL detriment and a one-off cost. We assume, as a simplification, that the model parameters, defined in Table 1, are known with certainty. Thus, we do not consider second-order uncertainty, and the optimal treatment, at the population level, is known. If second-order uncertainty is modeled, it can be averaged out before using these methods.
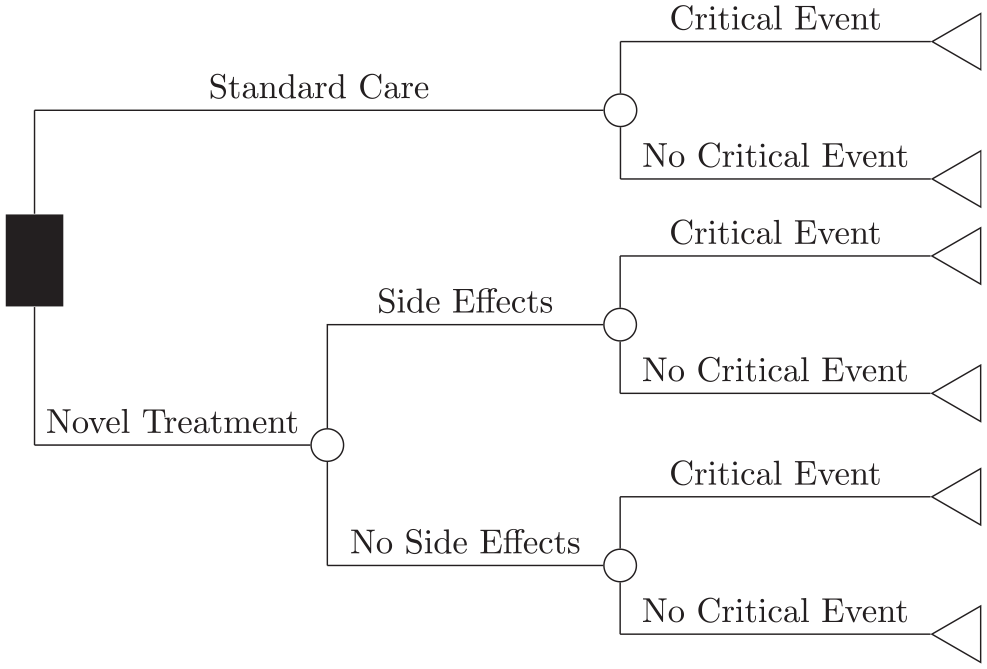
The structure of the decision tree model comparing 2 treatment options for a hypothetical disease that causes a critical event to occur, adapted from Ades et al. 10
Population-level parameter values for our individual-level decision model comparing treatment to no treatment
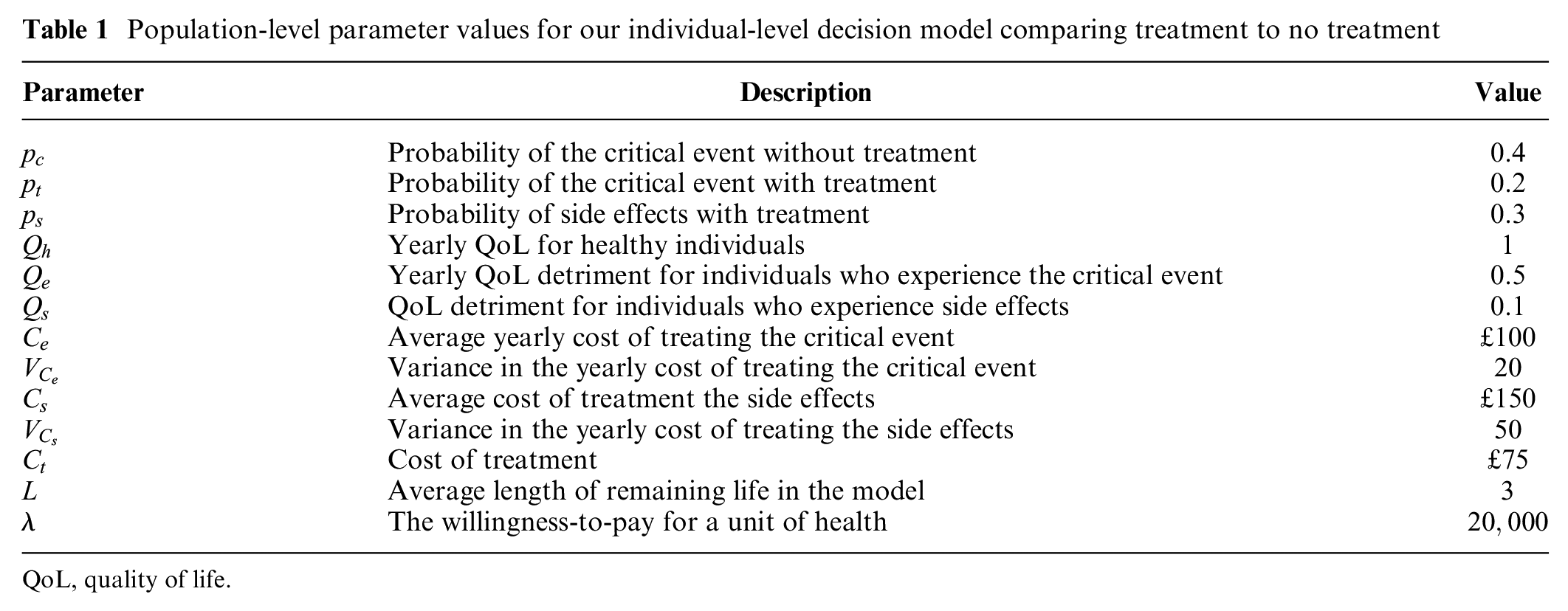
QoL, quality of life.
We specify individual-level distributions to generate the individual-specific trajectories, based on these population-level parameters. We model whether an individual experiences the critical event using a Bernoulli distribution, where the probability of experiencing the event is
Based on these assumptions, we now present the calculation method for the net monetary benefit for individuals with and without treatment. First, we define 3 health and economic quantities of interest that must be generated to calculate the individual net benefit, irrespective of whether we assume the individual receives treatment or not. We simulate the net monetary benefit for
We must define 2 additional vectors that capture treatment-related side effects to simulate the individual-level net monetary benefit for
Based on these simulations, we can compute the individual-level net monetary benefit for all individuals. We define the first half of the vectors
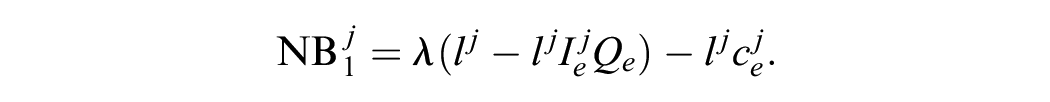
The first half of this equation, that is, terms multiplied by the willingness to pay (
The net monetary benefit for individuals receiving treatment is then defined, for
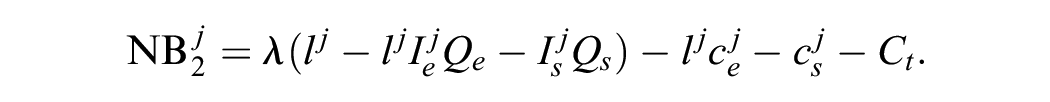
This net benefit calculation also includes the treatment-related side effects that can lead to a QoL detriment and additional costs. Note that, as the side effects only affect individuals in the short term, the QoL detriments and costs are not multiplied by
Once
Maximum VoH
The VoH and EVIC are defined as the expected opportunity loss, across all individuals, incurred by implementing a treatment that is optimal on average, rather than implementing the treatment that is optimal for each individual, separately. 16 At the individual level, the opportunity loss is defined as the difference between the net monetary benefit of the treatment that is optimal for the individual and the net monetary benefit the patient would gain if they were given the treatment that is optimal at the population level. 16
In the original VoH framework, the individual net benefit is estimated conditional on a set of observed characteristics.
16
However, when generalizing this definition to include unexplained heterogeneity, the individual net benefit is calculated using a model (e.g., our decision tree). More specifically, the individual-level net benefit is calculated as a function of several intermediate simulated quantities, that is,
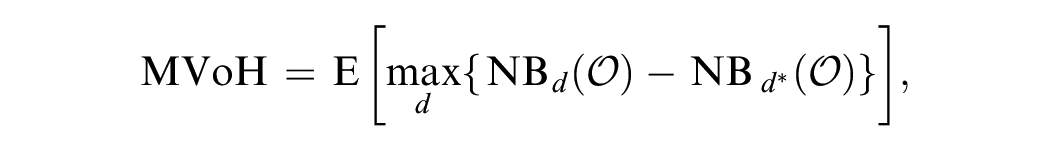
where
Table 2 visualizes how to estimate the MVoH, based on simulated values for the net monetary benefit for our 2 treatment options. First, the optimal treatment at the population level is found by calculating the average net benefit for each treatment. An individualized treatment decision would treat each individual with the treatment that maximizes their net monetary benefit; for example, individual 1 would not receive treatment while individual 3 would be treated. The opportunity loss of the population-level decision, calculated in column 3, is the difference between the net monetary benefit of the individualized optimal treatment and the net monetary benefit of the population level optimal treatment. Finally, the MVoH is estimated as the average opportunity loss across all individuals.
How to Calculate the Value of Heterogeneity a
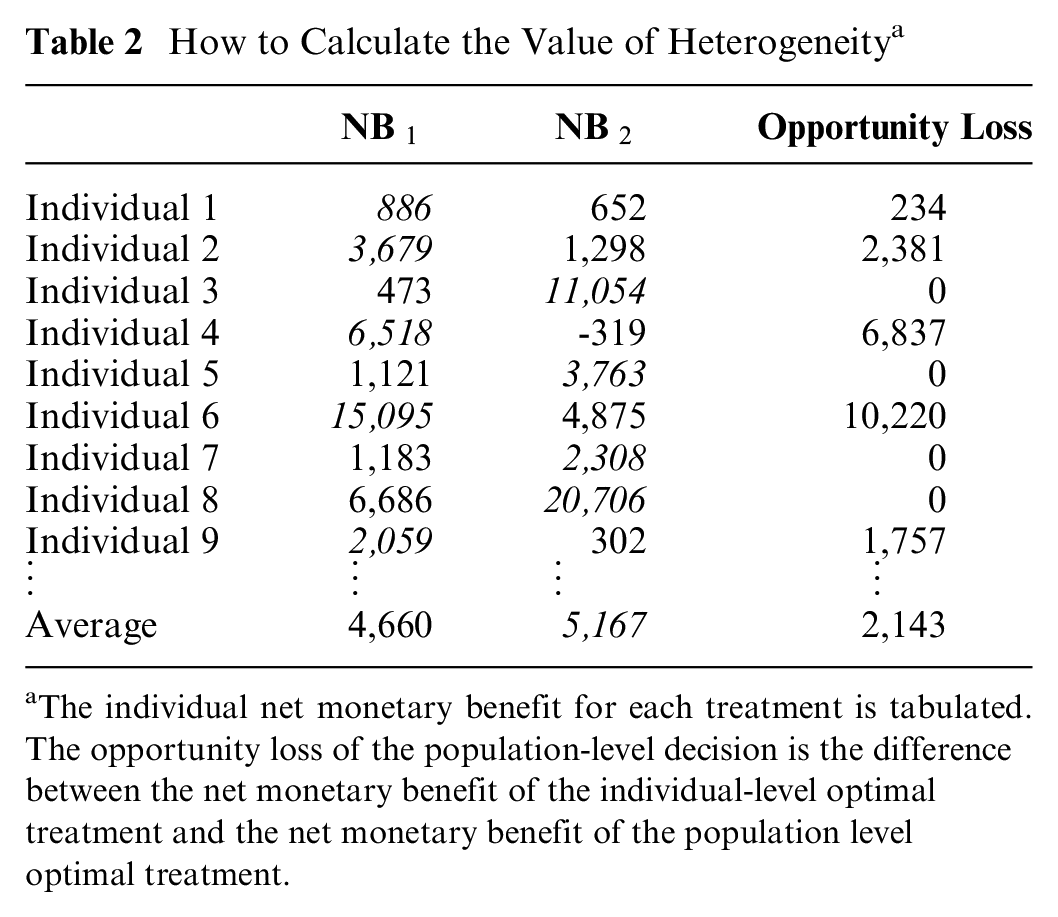
The individual net monetary benefit for each treatment is tabulated. The opportunity loss of the population-level decision is the difference between the net monetary benefit of the individual-level optimal treatment and the net monetary benefit of the population level optimal treatment.
To compute the MVoH, we must determine the net benefit of each treatment for a given individual. This represents what would have happened to a simulated individual under the other treatment options, known as the counterfactual. Espinoza et al. matched patients based on observable characteristics (e.g., age, sex), ensuring that the counterfactual could be computed from individuals with the same characteristics but different treatments. 16 However, the outcomes of a decision model cannot be used to determine the counterfactual based on unknown characteristics. Thus, we must make an explicit assumption about the counterfactual. However, as the magnitude of the opportunity loss is equal to the difference between the net benefit across the different treatment options, the MVoH changes significantly for different assumptions about the counterfactual. Thus, we suggest that these assumptions should be parameterized and the MVoH calculated across a range of scenarios, as we discuss below.
Defining the Counterfactual
The counterfactual can be defined by modifying the correlation, denoted
In practice,
Figure 2 plots the MVoH analysis for our example. We used
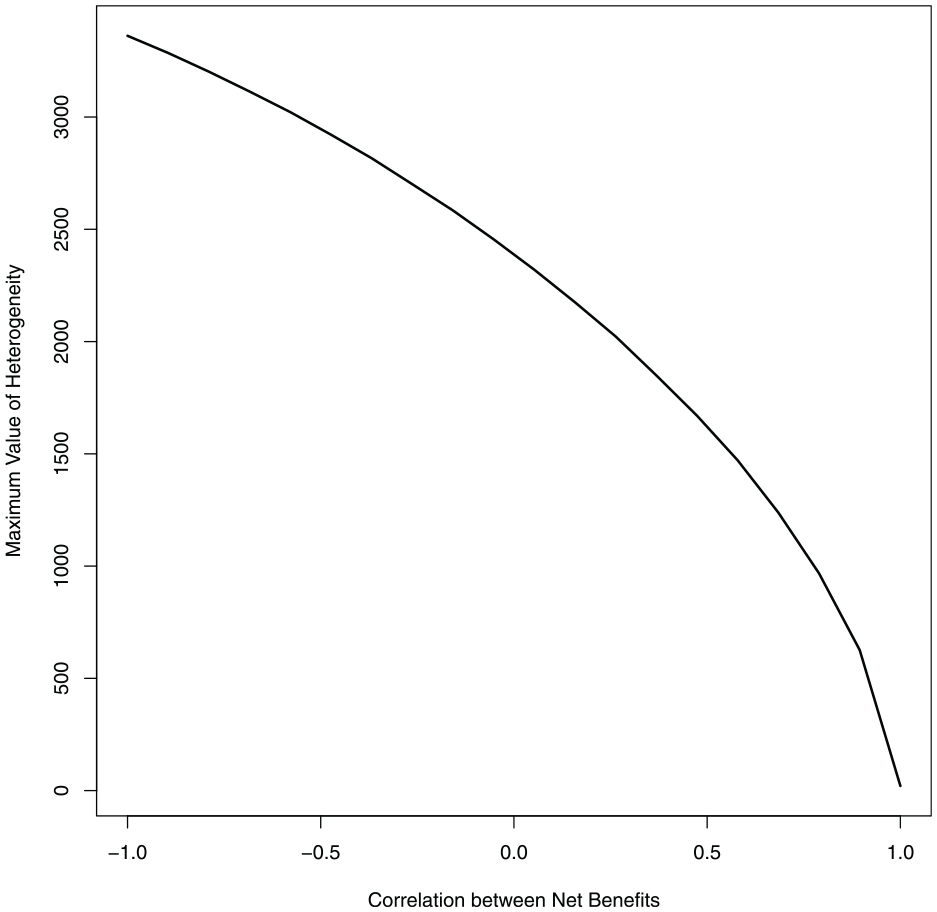
The maximum value of heterogeneity plotted against the correlation between the net benefit across the 2 treatments for the Ades et al. 10 example.
MVoH is interpreted as the upper bound on the value that could be generated from personalizing treatment decisions. Thus, if the MVoH is “high,” then there may be value in developing new personalized medicine strategies. However, the MVoH is calculated conditional on the correlation between the net benefits
The Value of Perfect Outcome Prediction
If the MVoH analysis indicates that there could be substantial value in exploiting the unexplained heterogeneity, it is important to determine what research would allow the development of valuable personalized treatment strategies. In our framework, the heterogeneity in the net benefit comes from the simulated individual-level outcomes
This prioritization step assumes that, for a set of outcomes
To define the VPOP for a set of outcomes
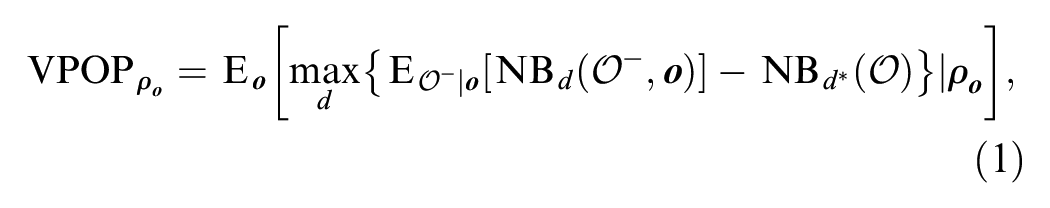
where
The range of possible values for
To compute the VPOP from Eq. 1, we must estimate the expected individual net monetary benefit conditional on the values of
Directing Research with the VPOP
For our example, Figure 3 displays the VPOP for the 5 clinical and economic individual outcomes; the duration of an individual’s life (
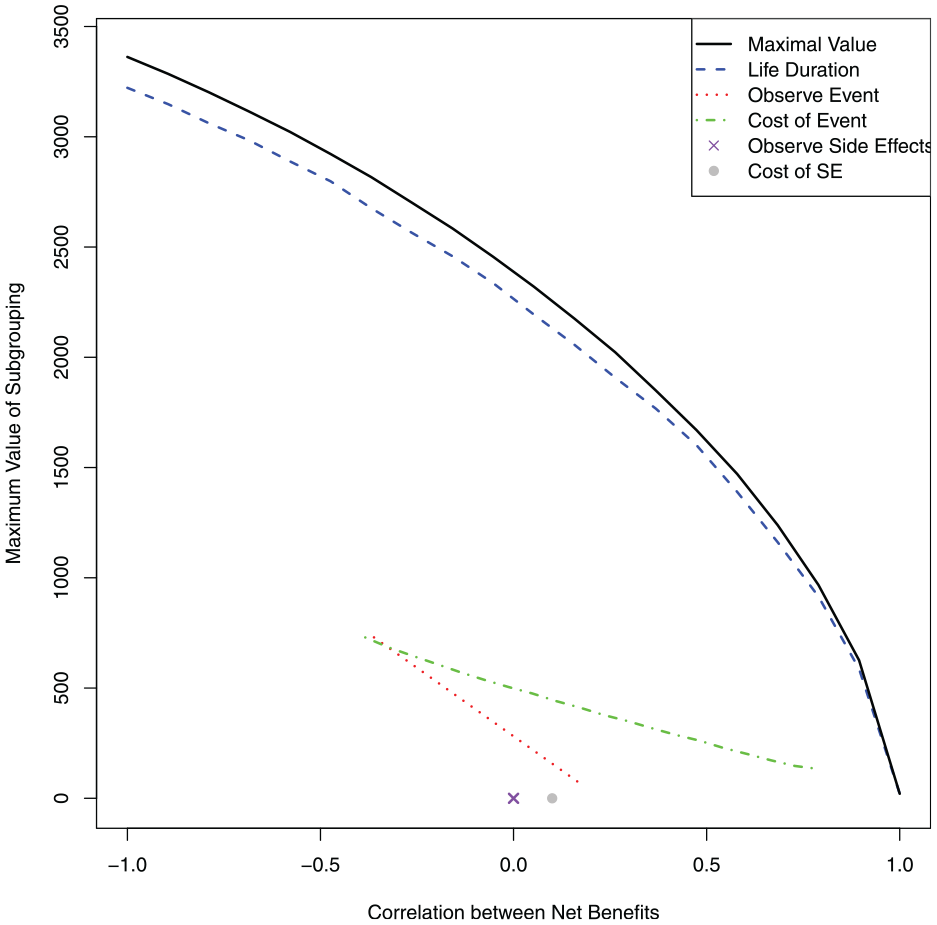
The value of perfect outcome prediction (VPOP) for all outcomes in the modified Ades et al.10 example and the MVoH for comparison (black line). The VPOP for the duration of an individual's life (l) is represented by the blue dashed line. The VPOP for whether an individual experiences the critical event (Ic) is represented by the green dashed and dotted line. The VPOP for the cost of treating the critical event (cc) is represented by the red dotted line. Finally, the VPOP for whether an individual experiences side effects (Is) is represented by a purple cross and the VPOP for the cost of side effects (cs) is represented by a gray dot.
Figure 3 demonstrates that, for most values of
Figure 3 also indicates that predicting whether an individual would experience side effects would not generate value. This is because the risk reduction for the critical event is substantial. Thus, even if the individual would experience side effects, they should still be offered the treatment (cf. the supplementary material). On the other hand, it may be possible to generate value from a personalized treatment strategy, if we knew which individuals would experience the critical event. In this setting, we would be able to identify individuals who do not require treatment (i.e., those who would not experience the critical event even if they receive treatment), and they can avoid being exposed to a risk of harmful side effects.
The Value of Subgroups
Following the VPOP analysis, we now assess whether a test to identify individuals who may experience the critical event could generate sufficient value to encourage its development. In this section, we use scenario analyses to identify what the properties of the test would have to be to generate value from personalizing treatment decisions. We assume that this test will imperfectly predict the outcomes
To calculate this value, we assume that the test will identify
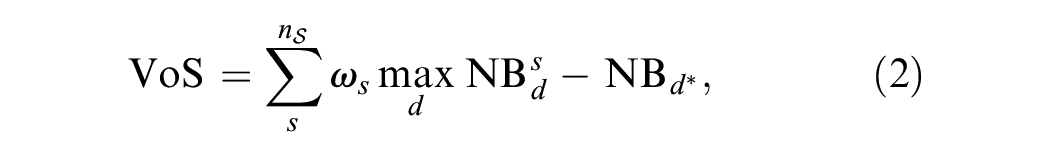
where
Value of Subgrouping
We identified from our VPOP analysis that predicting who would experience the critical event with and without treatment has the potential to generate value. Thus, we define the subgroups in our scenario analysis in terms of the probability of experiencing the critical event. We assume that a test would identify 2 subgroups (
To define the probability of the critical event in subgroup 1 and subgroup 2 without treatment,
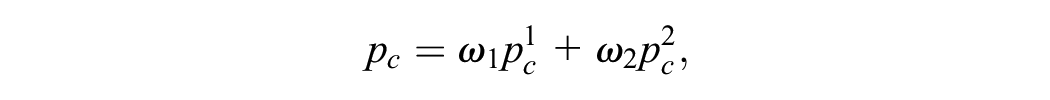
where
Thus, our scenario analyses vary the values of
Figure 4 displays the VoS across different values for the risk reduction in the reduced-risk subgroup,
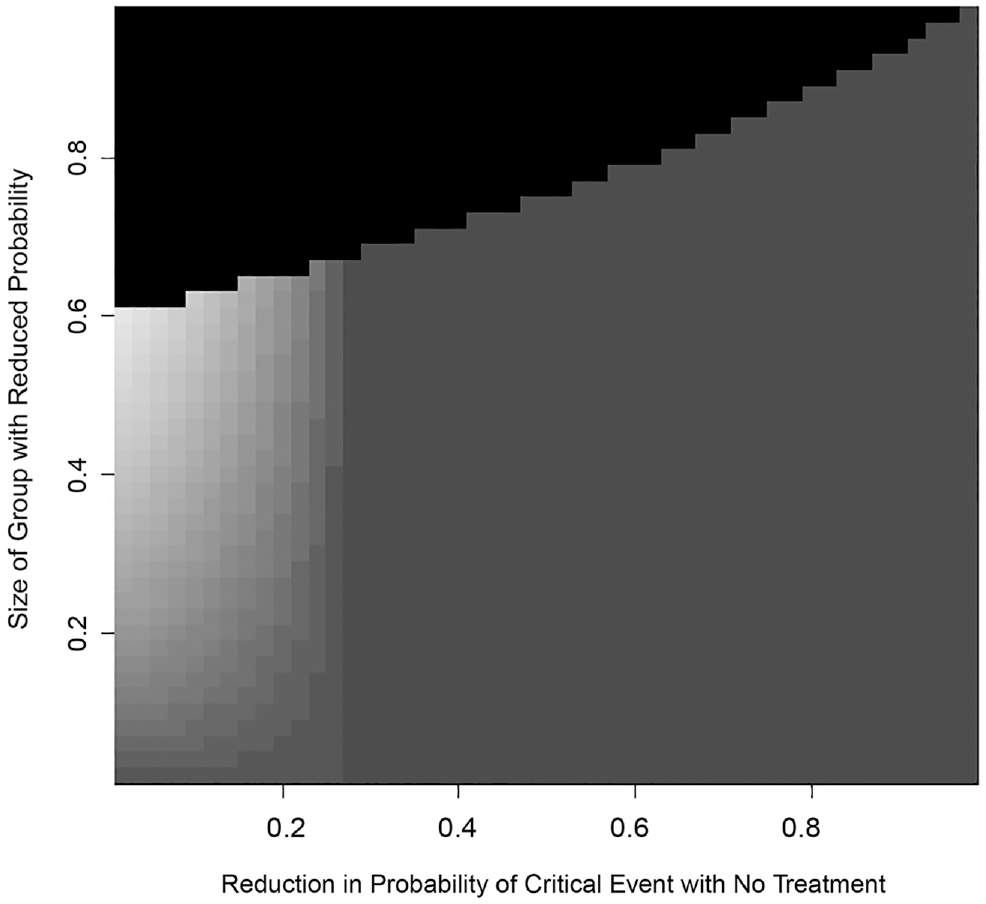
A heat map displaying the value of subgroups for different values of the proportion reduction in the probability of a critical event (
Discussion
We aimed to develop a method to support research prioritization in the discovery of new personalized treatment strategies, given the limits on research funding. To achieve this, we developed 3 measures that generalize previous work on the VoH 16 to settings in which the source of heterogeneity is unknown. Although research prioritization can also include other considerations such as improving equity in research (e.g., focusing on underrepresented genders or races), these methods can form part of a comprehensive research prioritization framework in personalized medicine that improves the value of research.
We begin by developing the MVoH, which explores whether value could be generated by explaining individual-level heterogeneity. We then develop the VPOP, which can be used, alongside clinical expertise, to indicate which individual-level outcomes, if they could be predicted, would allow us to personalize treatment and generate value. This measure can prioritize the development of prediction algorithms for specific outcomes. Finally, we demonstrate how scenario analyses can be used to explore the VoS and determine the characteristics that these subgroups need to have to generate value from a potential strategy that offers different treatments to each subgroup. This measure could direct research, as it highlights the features required from a specific test/prediction algorithm to generate value. However, it is more complex to conceptualize and compute as the subgroup structure must be designed separately for each model and the individual decision model must be rerun for each subgroup.
There are several limitations to the currently proposed measures and their graphical representations that should be addressed in future work. First, this article calculates the MVoH and VPOP by varying the correlation between the net benefit to define the counterfactual and then plotting these values against correlation. In decision models with more than 2 treatment options, this method could be extended to estimate the MVoH and VPOP for different correlation matrices. However, the graphical representation used in this article is possible only when the correlation is univariate. Thus, future work should develop alternative graphical presentations for decision models with more than 2 potential treatment options.
Second, we have developed the MVoH, VPOP, and VoS measures based on a deterministic decision model that ignores second-order parametric uncertainty. In general, decision models include a PA to assesses the impact of uncertainty in the model parameters on the decision-making process. 27 Thus, these measures will need to be extended to incorporate parametric uncertainty alongside individual-level heterogeneity, similar to Espinoza et al. 16 Ideally, these extensions would allow researchers to rank the relative importance of reducing uncertainty in key model parameters and developing mechanisms by which we could personalize care.
Third, the proposed VoS is relatively complex to conceive and may be computationally expensive. The relevant scenario analyses will change across different decision models, with the conclusions heavily dependant on the chosen scenarios. There are also challenges associated with presenting the VoS analysis if more than 2 quantities are used to define the subgroups. Thus, future research should focus on conceptualizing and presenting the VoS analysis for different outcome types. Methods will also be required to tackle the computational challenges of this analysis, potentially adapting methods that were developed the reduce the computational cost of VoI analyses,26,28–32 so they can efficiently compute the net monetary benefit for different subgroup specifications. The VoS analysis will also be most useful when informed by clinical expertise about what subgroups may be potentially available. This will require significant effort to translate clinical expertise into relevant scenarios. If clinical expertise were available, then a VoS analysis could focus on assessing whether realizable subgroup structures could generate value from personalizing treatment. This may reduce the range of scenarios to be considered.
In addition to estimating VoS, research prioritization requires 2 additional elements. Currently available evidence (e.g., from biological models) should be used to consider whether the valuable subgroups are potentially feasible. Second, we should compare the value of subgroups to all the costs of bringing the test to identify the reduced risk subgroup into practice. This could include preclinical and clinical investigation of the test, purchase of equipment to manufacture and analyze the test, obtaining market authorization, and the cost of widespread implementation of the test. These costs could be estimated from the real-world development, validation, and implementation of similar testing procedures.
Finally, these methods will provide accurate research prioritization only if the decision model realistically describes the current observed heterogeneity in the population. This is similar to standard VoI methods in which researchers must accurately capture all second-order uncertainty in their model to ensure correct research prioritization. 33 However, individual-level models are complex to develop, and relevant data may be lacking. 21 Thus, future research should focus on addressing these issues and implementing these measures in a realistic individual-level decision model. However, through the initial presentation of these measures, we have laid the foundation of a framework that will allow researchers to undertake research prioritization for novel personalized treatment strategies.
Supplemental Material
sj-pdf-1-mdm-10.1177_0272989X211072858 – Supplemental material for Prioritizing Research in an Era of Personalized Medicine: The Potential Value of Unexplained Heterogeneity
Supplemental material, sj-pdf-1-mdm-10.1177_0272989X211072858 for Prioritizing Research in an Era of Personalized Medicine: The Potential Value of Unexplained Heterogeneity by Anna Heath and Petros Pechlivanoglou in Medical Decision Making
Footnotes
Acknowledgements
The authors would like to thank David Glynn for his comments on an earlier draft of this article and 3 anonymous reviewers for their insightful comments. Early ideas included in this article were presented at SMDM2019, Portland, Oregon, in a presentation titled “The Maximum Value of Heterogeneity for Unknown Subgroups.”
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Anna Heath was funded by the Canadian Institutes of Health Research through the PERC SPOR iPCT grant (funding No. MYG-151207; 2017–2020), a Canada Research Chair in Statistical Trial Design and the Natural Sciences and Engineering Research Council of Canada (award No. RGPIN-2021-03366). The funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report.
Supplemental Material
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.