
Abstract
Smart city projects require complex coordination of resources, but research on how capabilities form at the city-ecosystem level remains scarce. This article develops a multi-level approach to capability development in smart city ecosystems through an empirical study of London’s city data. We analyse the London case to discover how two ecosystem-level capabilities – data provisioning and data insights – developed through global, configural and shared aggregation processes. We find that the emergence process changes as the smart city ecosystem develops, requiring different coordination and resource mobilisation mechanisms at various stages. We contribute to the capability development and smart city literatures by focusing on ecosystem-level capabilities linked to collective city-level outcomes rather than the capabilities of the leading city authority. Insights from the study are of value to city authorities considering how to scale up and organise smart city initiatives in support of urban development goals.
Introduction
Scholars have begun to develop an ecosystem view to understand the complex landscape of digital technologies deployed in smart cities (Dawes, Vidiasova, & Parkhimovich, 2016; Ooms, Caniëls, Roijakkers, & Cobben, 2020; Visnjic, Neely, Cennamo, & Visnjic, 2016). This line of research depicts a city ecosystem as an innovation environment where actors collaborate in ways that are not hierarchically controlled (Jacobides, Cennamo, & Gawer, 2018). Studies of organising processes in city ecosystems have shown how they are shaped by the local governance context in which cities operate (Lee, Hancock, & Hu, 2014; Meijer, Gil-Garcia, & Rodríguez Bolívar, 2016; Meijer & Rodríguez Bolívar, 2016; Sørensen & Torfing, 2018).
These perspectives have informed the organisation of smart city projects, but not yet explained how capability development unfolds in city ecosystems. Our current understanding implies that metropolitan authorities can lead the development of capabilities by scaling up some of the various projects in a similar fashion to how capabilities develop in organisations (Bundgaard & Borrás, 2021). However, capability development at an aggregate ecosystem level can be critically different as a dynamic process that requires the combination of resources and activities held by ecosystem actors across different administrative and organisational levels (Reypens, Lievens, & Blazevic, 2021; Shaw, Achuthan, Sharma, & Grainger, 2019). Approaches to capability development in organisations as a multi-level phenomenon provide a starting point to theorise how capabilities emerge through complex interactions between ecosystem actors (Jacobides et al., 2018; Salvato & Vassolo, 2018).
We build on this literature in the context of smart cities to generate new insights into how ecosystem-level capabilities develop at the aggregate level. Ecosystem-level capabilities need to be configured from increasingly expanding resources that are distributed across city ecosystems such as multiple data sources and technologies. In practice, especially in large cities, it is likely that no single actor can manage the development of capabilities that complex projects require throughout their lifecycle. Metropolitan authorities leading smart city projects have to make critical decisions about when to centralise their approach or stimulate the widest possible collaboration (Mora, Deakin, & Reid, 2019; Ooms et al., 2020; Visnjic et al., 2016). This commonly leads to tensions and conflicting visions between the leading role of metropolitan authorities (top-down) and initiatives led by citizens or industry actors (bottom-up) (Kornberger, Meyer, Brandtner, & Höllerer, 2017; Mora et al., 2019; Pansera, Marsh, Owen, Flores López, & De Alba Ulloa, 2023). Furthermore, unlike organisational capabilities that serve clear competitive advantage outcomes for individual organisations, the purpose and outcomes of ecosystem-level capabilities are collective, public and at the city level.
Our core research question is to ask how capabilities are aggregated at the city-ecosystem level and how these processes are different from the organisational level. We explain capability development in smart cities as a multi-level phenomenon, that is, to understand the emergence of ecosystem capabilities in smart cities and how they aggregate across administrative and organisational levels. We draw on Kozlowski and Klein (2000) to examine the global, configural and shared aggregation processes of ecosystem capabilities as they emerge from lower organisational levels. This approach guides our theory development and empirical research to understand how activities in smart cities scale up to become capabilities and, when they do, how they operate across a city ecosystem. These questions are timely for scholars and practitioners who are looking to understand how ecosystem-level capabilities are organised and developed in smart cities.
We present findings from a longitudinal case study of London’s city data ecosystem that offers the opportunity to observe processes of capability development for nearly a decade. We identify two ecosystem-level capabilities in data provisioning (providing open and shared data) and data insights (extracting useful insights from city data). We illustrate the development of the two capabilities and how they were formed to support urban development outcomes in the Greater London region. Each ecosystem capability eventually matured as a bundle of resources and capabilities shared by various teams and organisations across the ecosystem, having progressed through three types of aggregation with distinctive resource mobilisation mechanisms, key actors and approaches to coordination. Our analysis shows what it means to have a city-level capability and where it will eventually reside within the city ecosystem. Focusing on smart city ecosystems yields more general conclusions on the emergence of ecosystem-level capabilities, how they are developed and by whom.
Conceptual Background
Ecosystems are collective entities of organisations that are dependent on each other for value creation (Jacobides et al., 2018; Shipilov & Gawer, 2020). The ecosystem metaphor – broadly used to describe technology and innovation systems (e.g. Wareham, Fox, & Giner, 2014) – relates to the realities of a coordinated city environment without exclusive central control. Studies of smart city ecosystems capture the dynamic challenges of collaboration, organisation and orchestration (Appio, Lima, & Paroutis, 2019; Gupta, Panagiotopoulos, & Bowen, 2020; Mora et al., 2019; Ooms et al., 2020; Snow, Håkonsson, & Obel, 2016; Sørensen & Torfing, 2018; Visnjic et al., 2016). These studies have established the ecosystem perspective in smart cities to: (1) map structural relationships between internal and external actors like local authorities, universities, suppliers and businesses to foster a city’s economy, (2) highlight how metropolitan authorities adapt to changing leadership roles throughout the implementation of different smart city projects and (3) inform guidance on managing smart city projects.
Harnessing the potential of smart city ecosystems requires resources and capabilities to be generated and organised within the ecosystem. For example, city data projects like traffic management or air quality monitoring rely on the use of distributed resources to systematically execute tasks in generating, publishing, analysing and visualising vast amounts of data from multiple sources. Contemporary research has not yet focused on how the systematic execution of these tasks can develop into ecosystem-wide capabilities. In response, we outline our view of ecosystem capabilities in smart cities and then develop a multi-level approach to guide our theoretical and practical investigation.
Ecosystem capabilities in smart cities
Organisational capabilities are an organisation’s ability to regularly deploy resources, usually in combination, to achieve a desired end (Amit & Schoemaker, 1993). They are the tangible and intangible processes that are developed over time and directed towards an intended outcome (Dosi, Nelson, & Winter, 2000), usually towards gaining competitive advantage (Collis, 1994). Capabilities can themselves be of higher order when used to integrate, build or reconfigure lower-order resources or capabilities in response to changing external environments (Teece, Pisano, & Shuen, 1997).
While there is extensive research on the nature, causes and consequences of organisational capabilities, our knowledge of capabilities at aggregate levels like cities and ecosystems is still evolving. The majority of studies that examine capabilities beyond organisational boundaries focus on the role of inter-firm linkages, networks and embedded alliances in capability development (Dagnino, Levanti, & Mocciaro Li Destri, 2016; Dyer & Singh, 1998; Hong & Snell, 2013; Reypens et al., 2021). These studies emphasise the relevance of relational capabilities as the ability of lead firms to derive value from knowledge exchange in networks (Capaldo, 2007; Martins, 2016). The relational view of capabilities is characterised by linear, formalised and structured relationships with each firm playing a defined role (Clegg, Josserand, Mehra, & Pitsis, 2016; Huybrechts & Haugh, 2018), supplemented by informal elements such as trust and reciprocity (Reypens et al., 2021; Shipilov & Gawer, 2020).
Capabilities in smart city ecosystems can be expected to be radically different from the organisational level for two primary reasons. First, the purpose of capabilities in smart cities is the pursuit of public city-level outcomes, which is critically different to the pursuit of individual firm competitive advantage (Barney, 1991; Schilke, Hu, & Helfat, 2018; Wilden, Devinney, & Dowling, 2016). Organisational capabilities are directed at enabling organisation-level purposes and outcomes (Dosi et al., 2000). In contrast, ecosystems consist of varied independent actors with unique complementarities between participants that enable an overarching purpose without formal hierarchical control (Phillips & Ritala, 2019; Shipilov & Gawer, 2020). But even in ecosystems with a shared purpose, such as a collective innovation goal, the ecosystems literature tends to emphasise private value capture and appropriation by lead actors (Aarikka-Stenroos & Ritala, 2017; Walrave, Talmar, Podoynitsyna, Romme, & Verbong, 2018). In the case of smart cities, outcomes are delivered for shared public value, they are collective in nature, and geographically bound within local governance structures (Janssen & Estevez, 2013; Labory & Bianchi, 2021; Meijer et al., 2016; Pereira, Macadar, Luciano, & Testa, 2017). Our theoretical understanding thus needs to shift from capabilities to support value creation and capture at the organisational level, to capabilities for shared value co-creation and urban development at the ecosystem level.
Second, the structural micro-foundations of capability development are different at the city-ecosystem level compared with the organisational level due to the complexities involved in coordinating distributed resources. While single organisations are assumed to be able to own or control the resources and capabilities required to deliver competitive advantage (Teece et al., 1997), smart city ecosystems have to balance cooperation, tensions and governance challenges beyond organisational boundaries (Gupta et al., 2020; Hannah & Eisenhardt, 2018). Smart city studies tend to focus on the prerogative of the lead metropolitan authority to set ecosystem-level goals and structure the involvement of other actors (Chong, Habib, Evangelopoulos, & Park, 2018; Linde, Sjödin, Parida, & Wincent, 2021). This view does not give sufficient attention to the more complex, distributed roles and resources over multiple organisations within the city supporting capability development (Mora et al., 2021). Smart city capabilities somehow emerge at the ecosystem level through interactions between the resources and capabilities held by many different organisations, yet the process of how ecosystem-level capabilities are integrated and coordinated is not well understood.
Both these differences – in shared city-level outcomes, and in distributed resources and capabilities – point towards the need to better understand the process of how capabilities are aggregated in smart cities, which we introduce as our theoretical perspective in the next section.
A multi-level approach to capability development
A multi-level approach can advance our understanding of how ecosystem-level capabilities develop within smart cities. In their seminal work on multi-level analysis, Kozlowski and Klein (2000) bring together micro and macro perspectives to describe how lower-level properties emerge to form higher-level phenomena. They distinguish between global, configural and shared aggregation processes.
Global aggregation is when a phenomenon originates and manifests at a lower level and is then deployed more broadly across the higher-level entity. In our context, a global capability originates from a single individual, team, or organisation and is then applied across the collective ecosystem. Note that due to the nested nature of capabilities, a global capability originating at a lower-level entity can itself be composed from a range of lower-order resources and capabilities, but crucially these originate from a single lower-level entity and are leveraged across the collective ecosystem. In smart cities, we can expect to see some global ecosystem-level capabilities. City authorities are usually assumed to lead the initial stages of capability creation by setting strategic priorities, deploying their own resources and deciding which smart city initiatives should be launched and when. This relies on global capabilities, where the city authority (lower level) mobilises its capabilities to support the overall ecosystem (higher level). However, global capabilities may reach limits as city authorities seek to scale up by coordinating the wider involvement of people and resources towards common goals while loosening central control (Kornberger et al., 2017; Lekkas & Souitaris, 2023; Ooms et al., 2020; Visnjic et al., 2016).
In contrast, both shared and configural aggregation processes span two or more administrative or organisational levels, originating at lower levels (such as a team or organisation) and manifesting at higher levels (such as the overall ecosystem). By their definition, both shared and configural aggregation processes exhibit forms of emergence since the higher-level, ecosystem capabilities emerge from resources, processes and interactions at lower organisational levels. The higher-level whole is greater than the sum of the parts in the sense that the higher-level property cannot be simply separated back down into the lower-level constituent parts (Costa et al., 2013). Ecosystem capabilities that emerge through shared and configural processes are composed of a range of resources and capabilities that are distributed across several teams or organisations. We would expect smart city ecosystems to need to aggregate these more distributed resources and capabilities in order to deliver collective city-level outcomes.
According to Kozlowski and Klein (2000), the difference between shared and configural properties is primarily whether the lower-level components are similar or different to each other. Shared capabilities are composed of similar capabilities held at lower organisational levels, leading to ecosystem-level capabilities that are essentially the same as they emerge upward across levels. Configural capabilities are compiled from different resources and capabilities held at lower organisational levels, where combinations of functionally equivalent but distinctive resources come together to emerge into a higher-level whole based on a varied pattern at lower levels.
It is important to understand the aggregation process of ecosystem-level capabilities because this has implications for how the overall ecosystem is organised. For example, whether capabilities are global, configural or shared will influence resource mobilisation, that is, how resources are deployed, brought together and transformed into capabilities at the ecosystem level. Salvato and Vassolo (2018) demonstrate how organisation-level capabilities emerge as complex combinations of resources mobilised by individual employees at lower levels. The ecosystem literature has not sufficiently explained these dynamics although smart city projects usually involve extensive combination of resources, resource transfer and acquisition of new resources (Lee et al., 2014; Mora, Bolici, & Deakin, 2017). We would expect fundamental differences between mobilising resources and capabilities that are essentially similar (shared aggregation) from those that are different (configural aggregation). More broadly, we would expect to see differences in who leads capability development and how, depending on the aggregation process of ecosystem capabilities.
Empirical research has not clearly examined the emergence of capabilities at the ecosystem level. Yet, this is vital to understand how capabilities develop in city ecosystems, and ultimately whether they are successful in achieving city-level outcomes. Thus, the empirical focus of our paper is to examine the development of ecosystem-level capabilities in smart cities.
Research Approach
Empirical context
We chose London as a revelatory case study for the aims of this research (Yin, 2018). London’s city data landscape offers a rare opportunity to observe large-scale processes of capability development for a period of over 10 years with visible city-level outcomes that reveal different phases of activities and resource mobilisation. This contrasts with the majority of smart city projects that are either at earlier stages of implementation or their outcomes are not as effectively upscaled (Organisation for Economic Co-operation and Development, 2020).
London is unusual in its complex institutional landscape led by the Greater London Authority (GLA) as the main administration body with metropolitan oversight of 33 individual local authorities known as the London boroughs. The GLA is responsible for delivering city-level outcomes such as promoting the city’s economic and social development. The London boroughs and special functional bodies including Transport for London (TfL), the police, ambulance and fire services across the metropolitan area are responsible for delivering all citizen-facing services. They are the largest sources generating the transactional and administrative data that form London’s city data.
London’s data ecosystem is characterised by strong central urban management, pressing needs around the optimal use of data, and deep innovative capacity with many companies and individuals in London specialising in aspects of data management and analytics. 1 Therefore, it is not surprising that London was one of the first major cities globally to develop an open data platform in the form of the London Datastore that was launched in 2010 and became the city’s central hub for open and shared data in 2020. This was followed in 2018 by the establishment of the City Analytics Programme that aims to accelerate data-driven collaboration and data science capacity within the ecosystem. Centred around these two strategic initiatives, two major capabilities have developed gradually within the ecosystem: (1) data provisioning in the form of providing open and shared data and (2) data insights as the ability to extract useful insights and create value from city data. We next explain our approach to data collection and analysis to map the development of these two capabilities within the ecosystem.
Data collection and analysis
A study of capability development within complex smart city ecosystems calls for a process perspective supported by longitudinal qualitative data (Langley, Smallman, Tsoukas, & Van de Ven, 2013; Van de Ven, 2007). The case study covers the period of 2010–2019 based on primary and secondary data collected within 2017–2019.
The primary data are based on a total of 30 interviews with key stakeholders involved in different aspects of London’s city data. Interview participants were approached due to their professional roles that included data scientists and analysts, data strategists and heads of data insight at London’s boroughs, the metropolitan authority GLA, and the Transport for London authority. A number of interview participants held major roles as programme managers, smart city standards consultants, members of the Smart London Advisory Board or founders of smart city data solutions providers. Other participants represented different perspectives and experiences within the ecosystem coming from technology providers or other functional bodies. Crucially, several interview participants have been active in shaping London’s city data since its initial conceptualisation in 2010, thus allowing for reflections on key past events, and to get a better understanding of the contextual conditions, challenges and opportunities underpinning them. The interviews were conducted in person or via videoconferencing. They lasted between 60 and 90 minutes and were recorded and fully transcribed.
We complemented the interviews with secondary data covering the entire time period with a variety of policy reports and strategy documents, videos, presentations and blogposts on London local and regional government websites, as well as blogs written by key city actors. Since secondary data covered information on 10 years of evolution, they allowed us to validate facts as well as inform the interpretation of interview insights. An additional secondary data source, especially for fact triangulation, were observational data in the form of field notes gathered via minutes and informal discussions while attending a total of 20 workshops, events, conferences and unconference sessions from November 2017 to July 2019. Observation data allowed us to capture the decision-making and related successes and ongoing challenges in developing capabilities within that period.
An abductive approach to data analysis was used without prior theory driving the analysis due to the limited prior research on capability development in city ecosystems (Tavory & Timmermans, 2014). Instead, we started screening the data looking for empirical evidence on the resources and capabilities that were being developed in London’s city data and how these combined to aggregate capabilities at the ecosystem level. We then sought themes and observations on capability development by creating a timeline of key notable events, interventions, technical developments, and actors. This resulted in identifying and mapping the development of two capabilities: data provisioning and data insights.
We then reconstructed the data around the two main capabilities of data provisioning and data insights at the aggregate ecosystem level and evaluated each according to how they were composed from resources and capabilities held at lower-level entities within the ecosystem. At the last step, we cross-examined the aggregation pattern of each capability alongside the literature on capabilities and ecosystems to understand, for instance, how practices of decision making, cooperation and resource mobilisation unfolded as the ecosystem capabilities emerged. This analytical work was an iterative process constantly moving between empirics and theory (Locke, Golden-Biddle, & Feldman, 2008).
Findings
We show how two ecosystem-level capabilities – data provisioning and data insights – were developed within the London data ecosystem to support city-level outcomes. We found evidence of all three aggregation processes – global, configural and shared – which occurred in sequence and varied in how they were organised and developed. We begin by describing the two capabilities and how they each emerged from combinations of lower-order resources and capabilities held in various parts of the ecosystem.
Ecosystem-level capabilities and city-level outcomes
The overall goals of the London city data ecosystem were ‘to lead data-driven innovation around public policy areas that will make a difference to London – things like pollution, school places’ (GLA 2). This was enabled by the development of two key ecosystem-level capabilities: data provisioning and data insights.
Data provisioning capability
Over more than a decade, London’s city data ecosystem developed the foundational infrastructures to support the provision of data to public bodies, private companies and citizens in London. Data provisioning is the capability to publish open data and securely share data that cannot be made publicly open with other organisations through various platforms. At the ecosystem level, data provisioning is a tangible and technical capability, drawing together the lower-order data architecture, data linking and data accessibility resources and capabilities needed to make city data available to users.
Data architecture resources are the ‘hard’ IT infrastructure and legacy systems used to collect, store and modify data. These are technical resources often held by individual organisations in the city data ecosystem – particularly the GLA or London boroughs – such as databases, master data management systems, data warehouses and data lakes. For example, one London borough applied ‘the vast volumes of data we hold as an asset to improve our service provision’ and to ‘shift the focus to predictive analysis, [which] could help us change the way we support people in future, [and] help us deliver better services at lower cost’ (London borough 1). The borough used their own databases to address urban development issues such as identifying fraudulent use of social housing and parking concessions for disabled people.
Individual organisations’ data architecture is held together by data linking, that is, the ability to establish connections between the IT systems of different organisations to ensure the ‘flow of data in the city’. This back-end capability consists of technical elements such as application programming interfaces (APIs) to connect disparate systems. For example, Transport for London (TfL) developed an integrated data model to link public and private transport data with other sources to support the delivery of mobility-as-a-service across the Greater London region.
Finally, data accessibility is a capability to ensure ‘seamless navigation for data users in the ecosystem’ by making data available and discoverable to users through data catalogues, registers, feeds, portals and dashboards. For example, in response to ‘getting constant requests for data sets locally from people that are interested in local perspective’ the digital and data team at a London borough introduced a public-facing dashboard showing street-by-street data on trees. When asked about the outcomes of this initiative, the head of data strategy reflected that ‘there are so many things where the [local authority open data] platform also gives us a different way of engaging with our communities that we didn’t think was possible’ (London borough 2).
Data insights capability
Data provisioning established the infrastructure for a new capability to emerge out of high interest in the use of data and their potential value. The ecosystem-level data insights capability is the ability to practise data-enabled decision-making, extract meaningful conclusions, and create value from city data, or, more simply, ‘a mindset for being data enabled and informed’. Data insights involves ‘spreading the art of the possible’ to increase adoption and value creation from city data for effective and efficient delivery of public services in the city. In contrast to data provisioning, data insights is primarily a non-technical capability based on skills, data sharing agreements, governance, and compliance frameworks.
Data insights consists of three lower-order capabilities. The first is data collaboration, including data sharing skills, agreements and standards, aimed at ‘bringing people around to data sharing not as a burden, but as a culture’. For example, in the context of adult social care, the head of policy and insight at a London borough explained:
The problems we are facing now in public services, there has to be a systems response to that, and local authorities are just one part of that jigsaw puzzle. . . .so what is actually more exciting for me is sharing my data science capability at the local authority with other public sector bodies in the locality. . . [like the] clinical commissioning group, the health sector. . . . establishing a data capability and data science network across health and local government organisations. That’s really powerful. (London borough 10)
The second capability within data insights is data innovation, particularly through creating new applications and tools to support evidence-based decision-making. For example, GLA drew a map of London illustrating the future demand for school places in the capital, based on national educational data, regulatory performance, demographic trends and data on schools from the London boroughs. According to a policy analyst, the map ‘has been useful for school planners, and for parents looking for schools for their children’ (GLA 3).
Finally, data literacy encompasses both the technical skills of data specialists as well as the ability to understand the policy context in which data are used in terms of emerging ethics, norms and laws. When asked about a cross-borough data partnership to support children and adults who face risk outside of their home, the data and insight manager at one of the participating boroughs mentioned ‘cross-boundary data sharing to monitor youth violence, anti-social behaviour’ (which is an element of data provisioning) but also the data literacy needed as ‘we need to understand that people don’t live their lives in a boundary that we apply to a map that they don’t see’ (London borough 8). Data literacy includes the ability to change mindsets and for decision-makers to learn how to use decision-relevant data.
The aggregation of ecosystem-level capabilities
Resources and capabilities held by organisations such as the Greater London Authority (GLA), London boroughs and other actors aggregated to ecosystem-level capabilities in three distinct ways: global, configural and shared aggregation. Illustrations of each of these aggregation processes are outlined below and presented more fully in Table 1.
Aggregation processes of ecosystem capabilities.
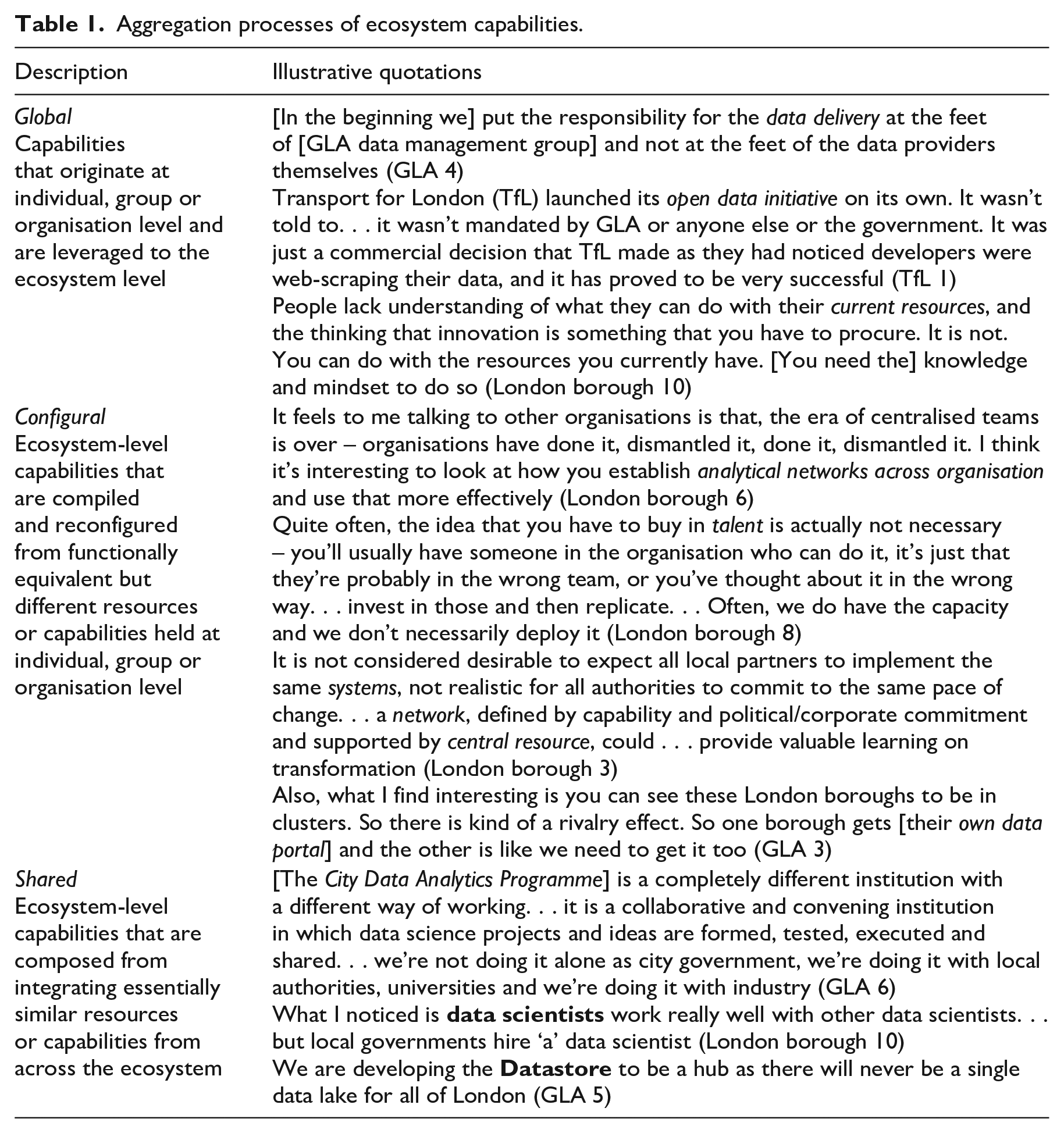
Global capabilities originate at the individual, group or organisation level, and are leveraged to the ecosystem level. When the London Datastore was first launched in 2010, the GLA’s own Data Management Asset Group, a team of technical and statistical staff, ‘simply uploaded the datasets as part of business-as-usual’ (Coleman, 2014). Other organisations, including data providers themselves, did not need to develop their own ability to publish data. This was handled by the GLA’s team and improved data provisioning for the whole system. Similar, easily observable, data provisioning capabilities were held by Transport for London (TfL) authority through its open data initiative, and by some London boroughs with their own data scientists. In all these examples, global capabilities originated and manifested at a single organisation or team but could be universally used across the ecosystem to deliver collective urban development outcomes.
Configural capabilities are compiled and reconfigured from functionally equivalent but different resources or capabilities held at lower levels. For example, the London Datastore was revamped in 2014 to take account of different contributions and perspectives from data providers. Where the first version was a website providing only static datasets in csv formats controlled by the GLA’s team, the reconfigured second version was a data platform that provided static, structured and unstructured datasets supplied by different data providers. This reflected varying attitudes and capacities to sharing data by different organisations. As an informant from the GLA notes,
‘with London Fire Brigade there is no need to talk much because they put all the data on London Datastore, making it very simple. The police service is trickier because they have the risk of their data being misrepresented. So, they . . . . put some data on the London Datastore . . . like headline stats, but a lot of it is on their own website. (GLA 4)
Configural capabilities emerged as various resources and capabilities held at lower-level entities such as London boroughs, other public authorities, universities, or commercial firms were joined together through networks and clusters of collaboration to support the overall London city data ecosystem-level capabilities.
Finally, shared capabilities are composed from integrating essentially similar resources or capabilities from across the ecosystem. For example, in 2018, London’s data insights capability was consolidated into establishing a central City Analytics Programme (CAP). This not only created a shared training and upskilling provision for all of London’s public sector bodies through the creation of a Data Academy, but also normalised data sharing agreements between them. Although organisations might still each hire data scientists, these resources held by distinct organisations were compiled through the CAP to build a data insights capability at the overall ecosystem level. Shared capabilities require shared leadership and purpose. As a GLA representative explained, ‘CAP is how can we put in place these quite boring tedious bits of infrastructure in place that aren’t glamorous . . . ., but these are essential. . . for data sharing in cities’ (GLA 7).
The development of ecosystem-level capabilities
Figure 1 traces the evolution of the data provisioning and data insights capabilities over the study period. We discovered that the aggregation process for each of the ecosystem capabilities varied over time, with a global founding phase giving way to configural development and eventually to shared mature capabilities. We show how each of these phases required engagement from different ecosystem actors, and different ways of organising.
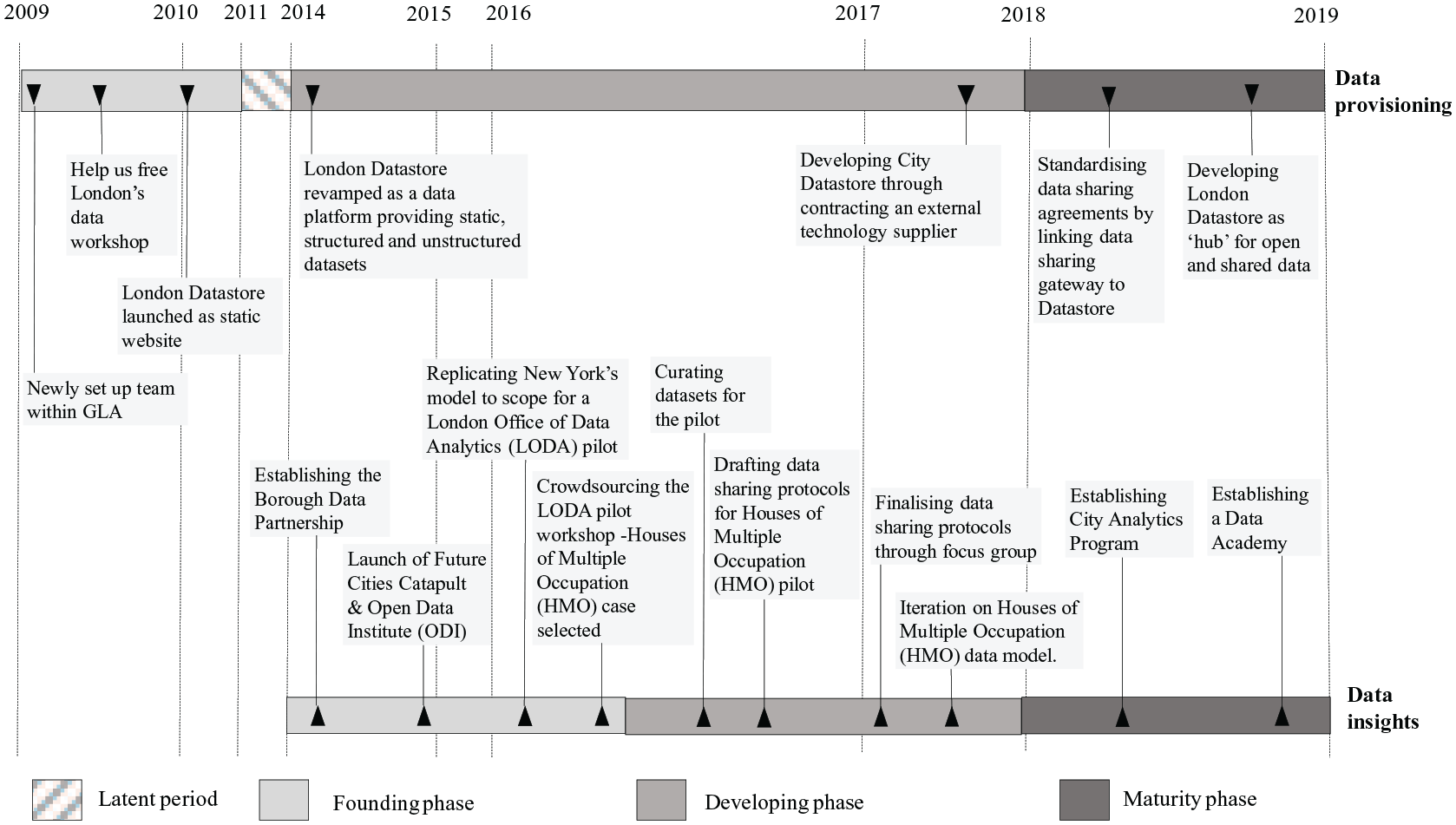
Timeline of capability development in London’s city data ecosystem.
The founding phase: global aggregation
The founding phase of London’s city data ecosystem began with small teams joining together to gather resources and lead change. For data provisioning, this was a newly set-up team within the GLA in 2009, and for data insights, this was a new community of practice in the form of the Borough Data Partnership. Each of these teams were driven by a central objective – to ‘set free’ London’s data – which required the creation of new capabilities. The GLA actively encouraged London’s developer community ‘to go ugly early’ and permitted their in-house team to obtain the administrative datasets they needed from various departments within the GLA to release the first version of the London Datastore in 2010. The Borough Data Partnership, formed in 2014, drew together data analytics starts-ups, London’s 33 boroughs, the GLA, third sector and community organisations to participate and showcase leadership in advanced data analytics and insights, ‘forcing the pace on what new data to open up, and why’.
Maintaining openness at the ecosystem level – whether reporting project proceedings and failures, or publishing of open datasets – was integral to capability development in the founding phase. For example, in 2009, GLA hosted the ‘Help us free London’s data workshop’ to interact with London’s developer community and draw on their needs, demonstrating an active listening exercise. This act of ‘openness’ was further maintained post launch of the London Datastore in 2010, where the team at GLA publicly stated that
We will use our Twitter account and Google Group to post updates on progress with new datasets as they come in. And don’t forget additional functionality on the site means you can now suggest a dataset that you would like to see in London’s Datastore and we will do our best to get it for you. (Coleman, 2010)
Participation in these activities was largely voluntary for London boroughs and developers, demonstrating low coordination levels between members of the ecosystem and a reliance on capabilities from a single team.
Capabilities first developed through global aggregation processes in the case of both data provisioning and data insights. As mentioned above, the 2010 version of the London Datastore was a global capability held by a single entity – the GLA team – and deployed to improve data provisioning across the city’s other authorities. The data insights capability was also global in this phase, as the teams and individuals within the Borough Data Partnership held the key skills and relationships needed ‘to both increase capacity in the areas of data release and analytics in local authorities’.
The main way in which global aggregation occurred was through the extension and/or replication of resources to new areas of application. For example, in 2010, the team at the GLA extended federated datasets within the organisation onto the public website. The early London Datastore was designed as a ‘simple website as opposed to the platform model to achieve this early start’. Mobilising resources through leveraging existing resources was perceived as simpler and ‘making the user journey for the developer and technologists easier to navigate”, rather than navigating “large bureaucratic structures’.
Such resource leveraging was also evident in the founding of data insights, which sprung out of activities that supported data provisioning. The new city-level data analytics community of practice was drawn together from the skills and innovative data insight projects that were being implemented within various teams at different London boroughs to give initial momentum to the city’s open data movement.
The developing phase: configural aggregation
By early 2014, 580 datasets had been published on the London datastore, reaching the limits of administrative datasets that could be simply made open by the GLA team. Similarly, after a few successful years, the Borough Data Partnership had ‘outgrown its usefulness’, as London boroughs developed their own teams, moving away from the original community of practice. Interviewees pointed to impatience with publishing ever-increasing numbers of datasets, some of which they saw as redundant. Having exhausted the possibilities for leveraging existing resources, the GLA began to open up collaborations with a wider range of organisations to ‘stimulate creative use of resources at different parts in the ecosystem’.
In the developing phase, new organisations such as the Open Data Institute (established 2015) and the Future Cities Catapult (established 2014) began to play leading roles in creating value from data on the London Datastore. Each provided different expertise required for the overall development of data provisioning in the city. The leading role of these new organisations was highlighted in one of the Mayoral press releases at the time: ‘These organisations play a vital part in the mission to unlock the supply of statistics and ensure that it is used to maximum effect in the pursuit of economic, environmental and social value’ (London City Hall, 2014).
Ecosystem capabilities grew and evolved through learning-by-doing, iteration, deliberate attempts at process improvement, and feedback from a wider range of participants. For example, in 2016–17, the London Office of Data Analytics (LODA) – a pilot collaboration between the GLA, Nesta (a think tank), 12 London boroughs and a data science firm – commissioned projects to develop and support data collaborations across London’s public sector bodies. One of these was a project to use machine learning models to identify unlicensed houses of multiple occupation (HMOs); identification would improve inspection and licensing of unsafe housing. The predictive algorithm of the HMO project underwent constant iteration to be successful, first by the data science firm, followed by one of the London boroughs with strong data science capacity that proposed an alternative working model. Notably, this involved feedback from users as the iterated algorithm was ‘fed with inputs of domain knowledge from the intended frontline workers’, rather than solely relying on ‘scientific knowledge of data scientists’. The project leader for this pilot described the involvement of the many organisations involved in the pilot as a ‘fused leadership’ style, drawing on a variety of resources, perspectives and expertise.
In this phase, ecosystem-level capabilities emerged through a configural process, where experimentation and pilot projects were led by multiple actors leading to ‘pockets of focussed collaboration’. There was acceptance of differences in the capacities and interests of different organisations, and constructive rivalry between some London boroughs to grow their own data science capabilities. At the ecosystem level, capabilities were mainly developed through modification of existing capabilities by either substituting, complementing, or divesting lower-level resources. In the HMO pilot, for example, the data science firm was substituted by the London borough’s in-house data science capacity. More broadly, the data insights capability was also developed through reconfiguration of data science staff and expertise. Many boroughs emphasised the importance of secondments and work shadowing, ‘upskilling and developing a set of skills through secondments rather than recruitments . . . seconding data scientists into local government. And once local staff is trained, they are seconded to another local authority. So, you keep on paying it forward’ (London borough 1).
Different actors led different projects in an entrepreneurial spirit. This diffused and legitimised value creation from city data through getting ‘quick and visible wins. . .to demonstrate that investment will pay off’. Activities like the HMO pilot, diffusing data science skills through secondments between London’s boroughs, and organising a user community around the London Datastore, all required diffused and distinctive resources in different parts of the ecosystem, illustrating a configural process. However, as the configural process continued, the multiple views and capacities of participating organisations also fuelled frustration with misaligned goals and the pace of change. For example, the GLA and Nesta spent nearly 5 months to draft a data sharing agreement that met the requirements of data governance officers at 12 London boroughs. Their difficulty to meet the boroughs’ expectations drove the GLA to take more control and to renew its central position in the ecosystem. Similarly, in an attempt to complete the development of a data sharing portal as part of the datastore in-house, the GLA recruited and integrated a number of developers and engineers into their own team instead of relying on technical capabilities from an external technology supplier. This signalled a shift from a configural to a shared aggregation process.
The maturity phase: shared aggregation
By 2018, both data provisioning and data insights were visibly established as ecosystem-level capabilities. The datastore was becoming more sophisticated, while interest in publishing and sharing data had expanded to most London boroughs, many of which had implemented their own open data portals or publishing platforms. Meanwhile, lessons from the various pilots had shown that systematic data-driven collaborations within the city had to be enabled by expertise in all technical aspects of data, together with project management, legal support and data governance functions. To overcome differences in data attitudes and capacities between boroughs, tech firms and other public bodies, the GLA became more active in centrally directing the city data ecosystem.
In 2018, the GLA pooled the necessary resources to establish the permanent City Analytics Programme (CAP). The CAP consisted of a new analytics lab, and an information governance capacity responsible for providing support in data sharing agreements and leading the legal function. It also had a Data Academy, where the GLA consistently attempted to address ‘skills gaps’ and understand where they could ‘either spread knowledge or intervene with opportunities’ to consolidate skills and capacity across the city data ecosystem. In this phase, the data insights capability matured as shared legal, ethical and skills practices around data were normalised by all despite being centrally managed by the GLA.
Around the same time, the GLA exerted more control over data provisioning. After initially contracting an external supplier to develop a new City Datastore (a platform to securely share data that cannot be made open) as part of the London Datastore hub, in 2018, they decided to terminate this contract, internalise the capability and build the City Datastore in-house by recruiting specialist developers. The city data manager at the GLA explained:
it is great to work with tech companies. . . . allowed us to understand what was important, what wasn’t . . . . but one of the learnings I have had is the ability to create your own backend scripts, your own APIs and your own data flows and organisation of your data storage – it isn’t something that we could buy-in from the big corporations or from SMEs . . . . we need to have it in-house; we need to have that expertise. (GLA 5)
Data provisioning emerged when the various idiosyncratic requirements by each organisation were gradually integrated into shared overarching processes. For example, an online data sharing tool routinised the process of data sharing:
It is like a workflow system. . . It simplifies and makes it much more routine . . . so programme managers of projects can do that rather than . . . refer to [their own] legal services all the way through . . . . where data sharing agreement can take 2½ years to go through all the different organisations, using that tool, you can do it in 3 months. (GLA 2)
Thus, while each London borough might have their own resources such as programme managers or data scientists, the GLA drew these local resources together to integrate them into a larger whole. Both data provisioning and data insights were aggregated through shared processes at the ecosystem level during the maturity phase.
Summary of findings
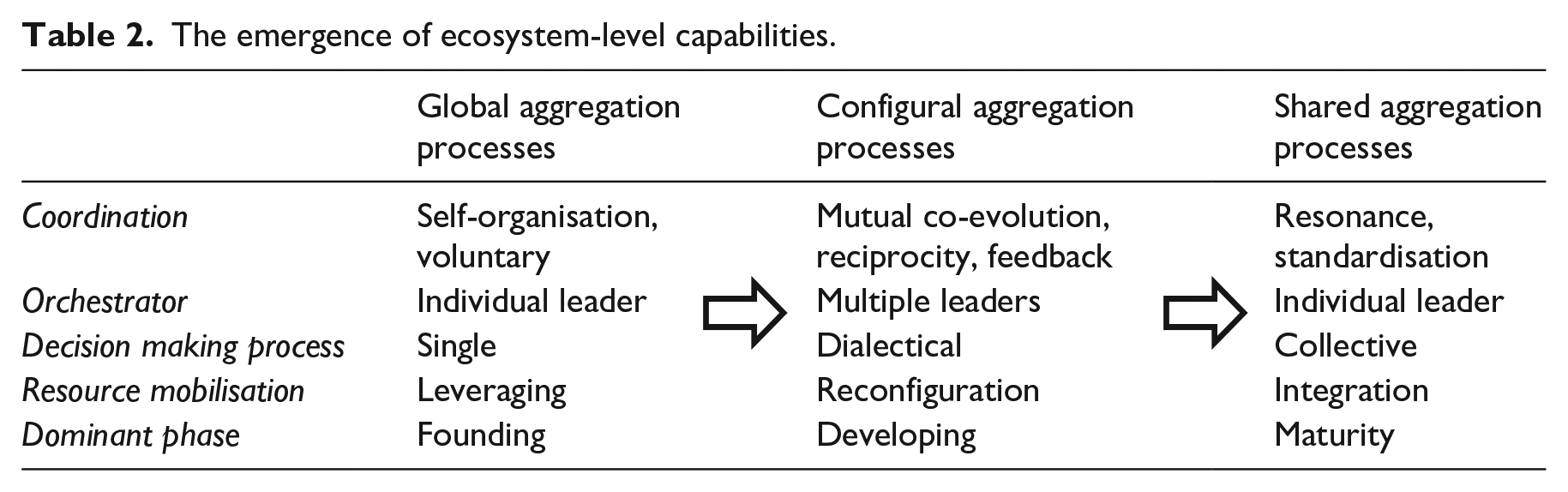
Our analysis demonstrated that the pursuit of city-level outcomes led to the development of two ecosystem-level capabilities: data provisioning and data insights. Each of these emerged at the higher level through a sequence of global, configural and shared aggregation processes. Table 2 summarises our findings in a conceptual framework mapping the emergence of ecosystem capabilities through three distinct aggregation processes, as outlined further below. In global aggregation (column 2 of Table 2), individuals and teams within a single authority gathered pre-existing resources and began to leverage these to lay the foundations across the city. Capability development was structured by a single orchestrator and decision-maker, which invited other organisations to voluntarily participate and self-organise within the founding phase. Next, in a configural aggregation process (column 3), a wider range of actors gradually developed capabilities through a dialectical process of reciprocity and feedback. Multiple orchestrators co-evolved the capabilities by experimenting and reconfiguring distinctive resources and capabilities from across the ecosystem. In the final maturity phase, an individual orchestrator again took control of a shared aggregation process (column 4), integrating resources and standardising processes to generate resonance and momentum towards a collective goal.
The emergence of ecosystem-level capabilities.
Discussion and Implications
This study asks how ecosystem-level capabilities develop in smart cities. In common with other ecosystems, smart city ecosystems need to manage cultural and structural tensions where sustainable outcomes require collaboration, but all participating organisations have their own priorities. In addition, smart city ecosystems need to overcome technical challenges due to the exponential growth and complexities of data generated by urban systems, as well as the need to deliver collective city-level outcomes. We began by asking how capabilities may be different at the ecosystem level compared with the organisational level. Although contemporary research is recognising the multi-level nature of capabilities in organisations (Salvato & Vassolo, 2018), this is the first study to examine how ecosystem-level capabilities emerge in smart city ecosystems. We drew on Kozlowski and Klein’s (2000) multi-level theory, and demonstrated that ecosystem capabilities develop through global, configural or shared aggregations of resources and capabilities held at lower organisational levels. Our study holds implications for both the literature on organisational capabilities and for smart cities research and practice.
Organising ecosystem-level capabilities
We extend the organisational capability literature by drawing on multi-level theory to understand the emergence and organisation of capabilities at the ecosystem level. Paying close attention to where resources and capabilities are initiated and manifested sheds new light on ecosystem-level as opposed to organisational-level capability development.
The capabilities literature tends to focus on the structures and mechanisms at the organisational rather than the ecosystem level (Felin, Foss, Heimeriks, & Madsen, 2012). In the context of ecosystems, given the absence of a formal hierarchical authority, the development of capabilities residing in different parts of the ecosystem is not automatic. This rather must be a deliberate activity, which our study explains by showing how resource mobilisation and coordination mechanisms vary in different aggregation processes. While a single organisation is more likely to manage a global or shared aggregation process, ecosystems still have to balance cooperation, tensions and multi-level governance challenges across a wide range of organizational actors (Gupta et al., 2020; Hannah & Eisenhardt, 2018). Our findings on the three different aggregation processes provide clues on how best to mobilise resources and shape cooperation in the ecosystem.
We noticed fundamental differences between the emergence of ecosystem capabilities from lower-level resources or capabilities that are essentially similar (shared aggregation) from those that are different (configural aggregation). As summarised in Table 2, configural ecosystem-level capabilities emerged through a dialectical process characterised by fragmented projects and alliances, experimentation, feedback and mutual co-evolution between multiple subsets of actors (Brous, Janssen, & Herder, 2019; Hou & Shi, 2021; Van de Ven, 2007). In contrast, shared ecosystem capabilities emerged through what Dattee, Alexy and Autio (2018) call resonance, that is, a self-reinforcing clarified, standardised and shared vision that attracts momentum and resources.
This matters because whether ecosystem-level capabilities are aggregated from similar components (shared) or different ones (configural) needs to be supported by appropriate resource mobilisation and coordination mechanisms to deliver ecosystem-level outcomes. Bowman and Ambrosini (2003) built on Teece et al. (1997) to explain how resource mobilisation links business and corporate-level resource-creating configurations within an organisation. Our extension is to show how resource mobilisation based on leveraging (extending or replicating existing resources to new areas of application), reconfiguration (transforming and recombining different assets and resources), or integration (bringing together similar resources though pooling and centralisation) result in different aggregation processes and determines how higher-level capabilities emerge. Previous research has shown that city-level projects require city-level capabilities, which draw on a diverse range of resources usually involving extensive combination of resources, resource transfer and acquisition of new resources (Lee et al., 2014; Mora et al., 2017). Our study illustrates how by outlining which resource mobilisation mechanisms are most appropriate due to the way in which the ecosystem capabilities are aggregated.
Finally, our analysis challenges the common perspective in the smart cities literature that ecosystem capabilities are largely held by a central authority and shared with the broader ecosystem in direct analogy to how capabilities work in the organisational context (Chong et al., 2018; Linde et al., 2021). In effect, our findings reveal that ecosystem-level capability development is more distributed, with city authorities leading at some points in time while wider ecosystem actors lead in others. Notably, while city authorities orchestrate the ecosystem in both the early and late phases, they did this in quite different ways (see Table 2). Under global aggregation, a single decision-maker initiated and managed the resource leveraging process across a variety of voluntary participants. But when the capabilities had matured, the metropolitan authority’s role was to lead the integration of shared resources, as the value proposition became clearer and more standardised, and gained support within the city.
Implications for smart cities research and practice
Given the large number of smart city projects taking place, we draw attention to critical aspects of capability development in smart cities. Current literature suggests that the eventual city-level capabilities will depend on institutional complexity, size of the city, specific managerial challenges and other contextual factors (Lee et al., 2014; Meijer et al., 2016; Meijer & Rodríguez Bolívar, 2016). This literature remains silent on how the overall capabilities in city ecosystems emerge from resources and capabilities held by individual entities within the ecosystem. Our analysis shows the who, how and what of ecosystem capability development, summarised in Table 2.
The findings highlight that to support resilient city-level outcomes, smart city projects should consider how resources and capabilities need to manifest across the city ecosystem rather than being tightly controlled by lead metropolitan authorities or by private actors that might withdraw their involvement. Many smart city ecosystems cannot progress beyond agile pilots because they tried to scale up immediately from global to shared ecosystem capabilities and didn’t go through the vital configural aggregation process. Our analysis underlines the need for experimentation, wider involvement, broader range of perspectives and learning through configural aggregation to be able to reach maturity and deliver shared outcomes. For example, the gradual development of data provisioning in London can be contrasted with other approaches to city data platforms (e.g. commercial data marketplaces, city monitoring dashboards) that did not reach the same level of integration and eventually disconnected from city outcomes (Barns, 2018). Other examples and comparative case studies like those by Giest (2017) and Mora et al. (2019) point to difficulties of scaling up under-resourced pilots, lack of fundamental data sharing and legal capacities within cities, and the outsourcing of data analytics.
Our analysis further underlines the importance of strategically switching between top-down and bottom-up approaches as smart city projects progress, first to establish their initial scope and then to experiment with and learn from wider use of resources, expertise and feedback within the city ecosystem (Kornberger et al., 2017; Mora et al., 2019). Similar phases of development marked initially by ‘senior officials providing impetus . . . later significantly shaped by cross-functional teams’ were observed in seven European cities (Lekkas & Souitaris, 2023, p. 1653). Likewise, in a case study of Russian cities, the organisation progressed from a formal core, through a ‘shadow culture’ stage, and to a final stage characterised by standardisation (Khodachek, Aleksandrov, Nazarova, Grossi, & Bourmistrov, 2023, p. 1640). While these studies have confirmed similar trajectories of organisation, our contribution lies in the different ways in which ecosystem capabilities were aggregated across levels during smart city development. Smart cities are characterised by data complexities and rapidly evolving technologies with unknown outcomes, though the aggregation processes we observed are likely to be relevant in other types of ecosystem as well.
Finally, we draw attention to the scale of outcomes as a critical difference between ecosystem and organisational-level capabilities. Research in sustainability management has more broadly shown how regional innovation ecosystems are particularly successful at addressing environmental issues at the regional scale (Bowen, Bansal, & Slawinski, 2018). Contributing to this line of research, we show the importance of city-level capabilities in generating city-level outcomes. Our specific case of the city ecosystem is particularly well suited to support urban development outcomes at the geographical scale of the city in contrast to a platform-centric view on smart cities (Bayat & Kawalek, 2023; Visnjic et al., 2016). Specifically, London’s case shows that tackling city-level goals such as urban transport or energy system sustainability requires city-wide mobilisation of data provisioning and data insights capabilities.
Limitations and future research
The study of London’s data ecosystem reveals processes of capability development for over a decade but shares limitations with other single-case, qualitative process studies of ecosystems. The size and complexities pose realistic restrictions in terms of how comprehensively data can be collected to capture different perspectives within the boundaries of the city environment. Our retrospective approach to capturing the fullest range of resources and capabilities within the ecosystem since 2010 was based on sources that still might not include initiatives and practices that have taken place within London’s 33 separate boroughs.
Furthermore, single cases will always have some limits to generalisability. London’s central metropolitan authority oversees functions that link a multitude of lower-level local authorities and front services. It would be interesting to consider how ideas from our study can apply to other cities not challenged by the complex institutional structures and devolution of power in London. Different forms of eventual ecosystem-level capabilities could be realised in urban environments with less complex structures that can coordinate resources more centrally. Further interesting insights could be observed in other public service ecosystems, such as public health, where the ecosystem is dotted with multiple actors imcluding regulators, scientists, health providers and private firms.
The conceptual boundaries of our study also lead to questions for future research. First, to simplify our exposition, we focused primarily on two levels of analysis within the city ecosystem, that of individual organisations (which we called the lower level) and of the ecosystem as a whole (the higher level), and particularly how high-level phenomena emerged from lower-level characteristics (Costa et al., 2013; Kozlowski & Klein, 2000). We recognise that capability development may rely on nested processes spanning more than two levels such as micro, meso and macro levels (Salvato & Vassolo, 2018). The task remains for research to explore these dynamics, not only in the study of organisational capabilities within ecosystems, but also in the direct and indirect influence of sub-organisational units such as individuals and teams on ecosystem outcomes.
Second, our case ended with a maturity phase characterised by integration, standardisation and shared capabilities. This may not be the end of the ecosystem capability process, as it still has a sense of momentum, or what Dattee et al. (2018) call ‘resonance’. It remains to be seen whether this phase led by the metropolitan authority will again reach natural limits, as occurred in the transition from the founding to the developing phases. Future research will need to assess whether capability development in ecosystems like smart cities can reach a stable and long-lasting maturity phase, or whether a successful ecosystem requires the stimulation of repeated cycles of configural and shared aggregation processes. An alternative pathway could be that the shared capabilities we observed are simply an extra phase in the capability lifecycle required as ecosystems align capabilities without hierarchy, ultimately leading to the lack of development that Helfat and Peteraf (2003) observed in the maturity phase.
Third, future studies might explore how capabilities can co-evolve in smart cities as a coherent set of practices to achieve sustainable city-level outcomes. We largely treated data provisioning and data insights as parallel capabilities, although we recognise that these capabilities were interrelated and initially developed in sequence. This is because data provisioning established the backbone for the new capability of data insights to emerge out of high interest in the use of data and their analytical value. Multiple projects have planted the seeds for new capabilities in different areas within cities, though we were unable to trace their relationships within the scope of this work. Studies of how organisations transition between capabilities (like Prange, Bruyaka, & Marmenout, 2018) could provide a further starting point to explain the interrelations and linkages between capabilities at the city-ecosystem level.
Conclusion
The paper focuses on the emergence of ecosystem-level capabilities in smart cities and how they are aggregated from resources and capabilities held by individual teams and organisations within the ecosystem. Smart cities have compelling prospects to support the delivery of city-level outcomes, but this technological revolution needs to be organised in order to realise the urban sustainability potential. We help explain how by identifying two specific ecosystem-level capabilities that evolved progressively to support London’s city goals and showing how they were developed and by whom. On the surface, the ecosystem capabilities of data provisioning and data insights may look highly technical, but our case reveals broader insights on the process and organisation of ecosystem-level capabilities in smart cities. In contrast to the prevailing view of a dominant orchestrator in smart cities that shares capabilities, we draw on multi-level theory to argue that ecosystem-level capabilities move through phases of being aggregated through global, configural and shared processes. We further find that the type of aggregation determines the leader, and co-ordination and mobilisation mechanisms, as well as influencings the achievement of city-level outcomes.
Footnotes
Acknowledgements
We are grateful to the anonymous reviewers, special issue editors and editor-in-chief for their constructive and supportive comments throughout the reviewing process. We extend our gratitude to Dr Giuliano Maielli and the scholars at the Organisation Theory Research Group (OTREG) at Judge Business School, University of Cambridge, for their feedback on the manuscript. We are further grateful to the numerous participants who were interviewed as part of the research at different stages. An earlier version was presented at the 80th Annual Meeting of the Academy of Management (AoM 2020).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article. The research was part of Dr Gupta’s doctoral project that was supported by a scholarship from the School of Business and Management, Queen Mary University of London. The manuscript was completed during Dr Gupta’s tenure as a Research Fellow at the London School of Economics on the Interface Reasoning for Interacting Systems (IRIS) project funded by the UK’s Engineering and Physical Sciences Research Council (EPSRC Grant EP/R006865/1).