
Abstract
This paper explores the development of an algorithm for child welfare administration in Denmark. Based on an ethnographic study of the development process, we argue that scientists and IT developers enacted not one but multiple versions of “the” algorithm, and in this process, also engineered its multiple potential worlds. We conceptualize these as “algorithm-worlds”; specific sets of relations in which a version of the algorithm can exist and act. We illustrate three examples from our study: the algorithm as a docile tool within the world of child welfare casework; the algorithm as a data-connector within the world of public data infrastructure; and the algorithm as a data processor in the world of a legal assessment. We contend the merely foregrounding algorithms’ multiplicity risks underestimating their world-making power, whereas construing algorithms as powerful without attending to their processes of becoming renders them seemingly singular and universal. By combining recent work on the multiplicity of algorithms in STS with actor-network-theory studies on “heterogeneous engineering,” our approach, in turn, allows elucidating not only three different versions but also how each of these came with a distinct world of practice. We argue that these algorithm-worlds partially coexist, partially conflict or cascade.
Keywords
Introduction
When the [MLA-child] project was originally designed, we had an assumption that the world looks like this, so we can go out and act in it this way. And this assumption has just turned out to be so far from true. There have constantly been things that have affected us and made us think anew or change our assumption of what kind of world we should act into. (Project leader, May 2023)
In 2017, a pioneering group of interdisciplinary researchers in Denmark set out to develop and evaluate an algorithm based on machine learning to aid child welfare caseworkers. The idea was that a predictive risk-scoring technology could support professionals’ risk assessments when being notified of concerns about a child at risk of maltreatment and failure to thrive. However, as the epigraph suggests, instead of developing a technological object that would fit into an existing world, the researchers were confronted with the challenge of making their algorithm “fit” a changing world. To paraphrase Nick Seaver (2017, 3), the algorithm mutated by blending the social and the technical. The development involved meticulous efforts of negotiating different ontological versions of the algorithm with the specific worlds they would coshape. By enacting the algorithm in casework, as part of a public data infrastructure and in legal assessments, “the” algorithm became not one but many things, carving into existence not a singular algorithm-world, but multiple ones. Starting from our interlocutors’ bewilderment as to what world an algorithm would act into, this paper inquiries into the relations between different versions of the algorithm and their world(s).
Scholars in science and technology studies (STS) have long argued that technologies do not come into being as one single object but rather acquire and maintain existence through their flexibility. Technologies are “fluid” objects whose components may be interchangeable, yet they hold together in one (De Laet and Mol 2000). Technologies are more than one, yet less than many: they come in different versions, but do not multiply endlessly (Mol 2002). To apply this line of thinking for the case of developing new algorithmic systems, we observed how practices of planning, using machine learning, presenting, documenting, and assessing the algorithm also rendered it into three different objects: as tool, connector, and processor.
These enactments also configured distinct worlds of possibility for each algorithm version to work in (Law 2015). As the epigraph suggests, not only was the algorithm redefined multiple times, but also the “world” in which “it” would act in. Taking this observation seriously, we began viewing the researcher's attempts at developing the algorithm as both a case of multiplicity (Seaver 2017), and an indication of the heterogenous engineering of worlds for its multiple versions (Law [2012] 1987). By worlds we hereby mean the multiple realities emerging from “sets of relations” rather than a naturalist singularity, each algorithm-world came with distinct path-dependencies, aims and goals, and registers of valuation (Law 2015). While our ambition draws on Latour's quest for the tandem making of technology and society into a strong and durable assemblage (Latour 1996, 1990), it also departs from it by approaching world-making attempts as multiple, fragile, and ongoing, thereby bringing “heterogeneous engineering” (Law 1987) into dialogue with the notion of a “multiple ontology” (Mol 2002).
Not unlike the Portuguese shipbuilders of the 14th century described by John Law ([1987] 2012) who had to create associated technologies such as scales, metrics, and measuring devices for the ships to sail, we argue that our researchers and developers had to build versions of the algorithm along with practices of assessing, explaining, and supporting the technology. Unlike the shipbuilders, the researchers did not stabilize their algorithm into one solid technology (ship) and its associated elements (tools for navigating), but rather as different versions, highly interdependent on the practice that they crafted along to grant it existence. The new algorithm-worlds, as we call them, were not discovered, but forged into being as the researchers and other involved actors attempted to find ways of making the algorithm—in one version or another—exists. With the notion of algorithm-world we aim to foreground the power of extended algorithmic agency to assemble potential worlds.
Drawing on an ethnographic study of researchers’ endeavors to develop, test, and evaluate an algorithm for the Danish child welfare administration (MLA-child), we illustrate how multiple enactments of an algorithm invoke tentative algorithm-worlds. We illustrate three algorithm-worlds: (1) In the practices of child welfare casework, the algorithm was enacted as a docile tool that created a world for a new form of decision-support. (2) In attempts to merge public data infrastructures, the algorithm became a data-connector and created new rhythms and tactics for storing data. (3) In the practice of legal assessment, it emerged as a data processor, relieved of data itself, and capable of creating legal precedent. These are exemplary for the ways enactments of algorithms bring along possible algorithm-worlds, which are being coconfigured with the specific algorithm ontology. Some of the worlds we mention here have continued to exist beyond the lifetime of the algorithm. Indeed, it is important to note that five years into the MLA-child research project, the researchers eventually significantly altered their agenda: Rather than testing the algorithm on real-world cases and evaluating it through a randomized controlled trial, as they initially set out to do, they decided to run the algorithm on synthetic data and perform tests in experiment-like settings with caseworkers.
The paper proceeds as follows. In section two, we present current STS research of algorithms in public administration and outline our conceptual inspiration by heterogeneous engineering (mainly in the work of John Law [1987] 2012) and multiple ontologies (Mol 2002; Seaver 2017). Section three provides a brief description of our case. Section four illustrates our methodological approach and provides reflections of our role as participant-observers in the work of MLA-child. Section five encompasses the analysis, structured in three subsections, one for each enactment and algorithm-world. We conclude the paper by discussing how the three enactments relate to each other, arguing that although they produce different versions of “the algorithm,” they do not necessarily exclude each other, nor are they ever fully coordinated or commensurate at any point in time.
Studies of Algorithms in the Making
Scholars increasingly critique the use of algorithmic models for targeting, profiling, and predicting citizens, often at the expense of marginalized communities. Eubanks (2018), for example, argues these systems prioritize cost efficiency over social needs, surveilling, and policing the poor. Jørgensen and Nissen (2022) highlight how algorithms, when used to automate decision-making, shift accountability in social work. Several researchers have linked biased data in algorithmic systems to discriminatory outcomes (Dencik et al. 2019a, 2019b; Gillingham 2019; Redden, Dencik, and Warne 2020), while others (Leslie et al. 2020) note their role in austerity measures that harm citizens’ opportunities and the risk of replacing social work expertise with rigid algorithms. These important critiques highlight the potential harm of algorithmic decision support in child welfare administration contexts specifically. While recognizing these concerns, we agree with Lee et al. (2019) that such critiques inadvertently assume that properly designed, objective algorithms can ensure fairness. Instead of isolating the algorithm as something distinct from its sociomaterial context, we here follow their call to examine how algorithms reassemble the world through complex, interwoven practices of construction, application, and adaptation.
Existing studies of algorithms in STS can be broadly (and somewhat simplistically) sorted into either studies of algorithms in use or studies of algorithms in the making. Based on their study of situated valuations of an algorithm for identifying protein signatures, Lee and Helgesson (2020), for instance, suggest that algorithms’ agency is an effect of human–machine configurations, making the algorithm accepted as good in one situation, whereas it is disregarded as problematic in the next. In our own previous research on predictive algorithms in child welfare, we have elicited an interdependency across public engagement and changing perceptions of what counts as the “ethically good” algorithm (Ratner and Schrøder 2024). Other scholars, again, have tended to the ways in which algorithms are assembled into being as technology and humans engage with each other in practice (Savolainen and Ruckenstein 2024; Dahlin 2024; Schwennesen 2019; Lee et al. 2019; Lehtiniemi 2024). Thus, while STS research on the use of algorithms offers insight into the ethics and agency of algorithms, it also often assumes that the site of use already existed as a rather stable field of practice.
In this paper, we start from the assumption that both algorithm and its potential worlds are concomitantly in the making, before the algorithm is put to use. Rather than exploring how the algorithm becomes situated in existing practices, we shift focus toward the sociotechnical engineering involved in the development of algorithms and practices (Jaton 2017; Neyland 2016). As suggested in the Introduction, we are not looking for the engineering of one successful and durable “actor-network” that allows the algorithm to stabilize as a bounded and powerful technological entity. Instead, as Seaver (2018) notes, algorithms exist only through their practical and cultural enactments, making them inherently unstable, multiple, and interdependent with diverse and situated practices. Seaver (2017, 4) draws on Annemarie Mol's (2002) analysis of atherosclerosis in a Dutch hospital to propose algorithms as “multiples”—not “stable objects interacted with from many perspectives, but as the manifold consequences of a variety of human practices.” In this view, there is no singular bounded algorithmic entity that can be assessed according to ethical or fairness parameters, but rather various enactments of the algorithm, including those testing algorithms for social acceptability.
To understand how multiple enactments of algorithms bring into being potential algorithm-worlds, we combine insights from classic actor-network theory with more recent STS research on the multiple and variable existence of algorithms. Drawing on the notion of “heterogeneous engineering” (Law [1987] 2012), we understand algorithm-development as an effort to assemble diverse elements—code, humans, procedures, legal expertise, software, data—to form sets of relations that make it possible for the algorithm, in our case, to move toward a randomized trial. This allows us to approach “the” algorithm not as an isolated computational object but as embedded in the practices it is to inhabit and shape. This foundational relational and sociotechnical mode of thinking continues to influence STS studies of algorithms, for example, with scholars approaching algorithms “as culture” rather than “in culture” (Seaver 2017); as sociotechnical work (Dahlin 2024); or as operations of folding, that is, relating things previously unconnected (Lee et al. 2019). Our study builds on this stream of STS scholarship, emphasizing the need not to fixate the characteristics of algorithms in singular accounts (Suchman 2023; Lee 2021).
As we shall see in the subsequent sections, our interlocutors’ primary concern is not to make the different versions of the algorithm cohere as one single object, but to make them fully exist in each of the algorithm-worlds. This is a different form of multiplicity than the one Mol (2002) has introduced us to. Although Mol examines objects in rather established and routinized practices at the hospital, we are examining the making of a new object and the new practices that are enacting it, and in turn being shaped by it. This means that neither “its” existence as an object, nor the practices by which “it” is to be tested and potentially implemented, have been stabilized. In other words, we are dealing with practices that, rather than sustaining versions of an object, are trying to figure out its viability as a new practice. Like Jensen (2010) illustrates in his study of the development of the electronic patient record, the algorithm's existence varies in these practices. In our analysis we trace its stabilization, or lack thereof, in the researchers’ attempts to heterogeneously engineer both algorithm and practices. Rather than coordinating, discovering, or integrating multiple versions of the algorithms, we show how the algorithm is normalized (1) as a tool in social work practice; (2) tentatively tested for its abilities to connect data flows in municipal infrastructures; and (3) provisionally legitimized as a legal data processer. Each of these attempts, we argue, also enacts potential algorithm-worlds as (1) an updated casework toolbox, (2) a new public service data storage infrastructure, and (3) setting legal precedent.
Ethnography of an Algorithm in the Making
Approaching the MLA-child algorithm as a multiple object requires following it “there and elsewhere,” as Jensen puts it (2010, 4). At the beginning of 2021, the second author of the paper made an agreement with the MLA-child researchers to follow their work through ethnographic methods (Czarniawska 2007; Kitchin 2017). Even if the first author conducted most of the ethnography, and the third author contributed significantly to the conceptual development of the paper, we write “we” throughout the paper to designate our collective process.
At the time (2021), our methods were still constrained by the COVID-19 pandemic. We started out by conducting online interviews with each of the four researchers and by collecting archival material, consisting of project descriptions and media coverage of their research project. We continued to conduct monthly and open ethnographic interviews with the project leader (Czarniawska 2007), allowing us to learn about and document their adjustments and negotiations about what to do next and why. We supplemented these interviews with every trace we could find of the algorithm; conducting interviews with prior project members and key stakeholders as well as participating in seminars and meetings, where new actors, matters, and sites related to MLA-child emerged. Seaver (2017) introduces the trope of the scavenger to describe this ethnographic move. Altogether, we conducted 23 interviews, 30 hours of participatory observations, collected 47 project documents (339 pages), 21 media clips and articles, and wrote 70 pages of fieldnotes. In Table 1, we present a temporally ordered overview of the ethnographic activities we undertook while following the researchers from May 2021 to May 2023.
Overview of interviews and observations we conducted and documents we collected from 2021 to 2023.

As a part of our agreement, we planned to conduct interviews and observe the actual usage of the algorithm in child welfare casework during the fall of 2022 where the randomized trial was scheduled to begin. In anticipation of this, we did not rush to get offline and go to the researchers’ workplaces to observe them work. However, during the spring of 2022, one year into our research and well into phase two of the MLA-child project plan, their municipal partner pulled out of the project. We learned from the project leader that this was due to recurring public controversies regarding predictive algorithms in public administration (cf. Ratner and Schrøder 2024) and the strain on resources it would pull from other areas of work, if they were to take on a role as test municipality. Prior to and in parallel with this, several practical and legal issues—some of which played a role in our empirical account—challenged the continuation of the MLA-child researchers’ work. In June 2022, they decided not to test the algorithm on real cases and to postpone further work until plans had been readjusted and agreed upon. Taking their workload and challenges into account, we stopped negotiating for access and made our last interview with the project leader in the spring of 2023.
At this time of our research, we still had the sense that we had not gotten close to the algorithm. We had, for instance, not seen the code it was made of. However, rather than viewing the algorithm's effervescence as a methodological limitation of studying them ethnographically, we took it as a point in its own right (Seaver 2017). This made us pose the rather banal question: What is it that people do when they develop an algorithm? In our case, we found various “doings” of “the” algorithm: presenting at conferences, coordinating with municipalities, visualizing and negotiating infrastructures, and so on. To begin with, we were frustrated about this inconsistency between “the” algorithm and all the different representations of “it,” but eventually got intrigued by the inconsistency, and made it an object of analysis rather than a hindrance. While analyzing the MLA-child algorithm as sociotechnical imaginaries (Schiølin 2020), as a failure (Jackson 2014), as registers of valuing (Heuts and Mol 2013), and as calculative practices (Mennicken and Espeland 2019) were all considered as possible ways to go, we found that our case had taught us something quite significant about algorithmic development; for the code version of an algorithm to exist, numerous practices had to be redone, and various versions remained partial. To further analyze this, we ordered our accounts of the algorithm into the three enactments with the most distinct characteristics and traced what was done to further develop each of the three versions.
Multiple MLA-Child Algorithms and Their Worlds
Our analysis is structured in three subsections, each analyzing one enactment and the concomitant heterogeneous engineering of an algorithm-world. This is not to argue that an enactment always comes with the heterogenous engineering of one algorithm-world or that there is only one enactment per algorithm-world, but for reasons of clarity we illustrate one-to-one examples. The purpose is to illustrate the variations across enactments and their interdependencies with distinct algorithm-worlds.
Making a World for the Algorithm as a Tool
The purpose of this project is to develop a statistically based tool for a Danish context, to sharpen, support, and assist the assessment of a notification made by municipalities. The tool will be an addition to the professional assessment, made in the municipality and currently based on knowledge from theory, research, experiences, and law. (Resume—pilot project 2017)
This quote epitomizes what we identify as the first enactment of the algorithm as a vague idea of a “tool” that can “sharpen, support, and assist” professional assessments. In a short paper for a social work conference in 2018, the researchers constituted this tool-likeness with the following explanation: The statistical tool is intended as a supplement—an information-processing tool—to the professional caseworker's assessment of a notification, and not as a replacement of the professional judgement. (Short paper 2018)
The ability to process information statistically was presented as the novelty of the tool. As a tool, the researchers associated the algorithm to other inputs used for assessing a child's risks as made clear in a graph in the same short paper from 2018 (Figure 1).
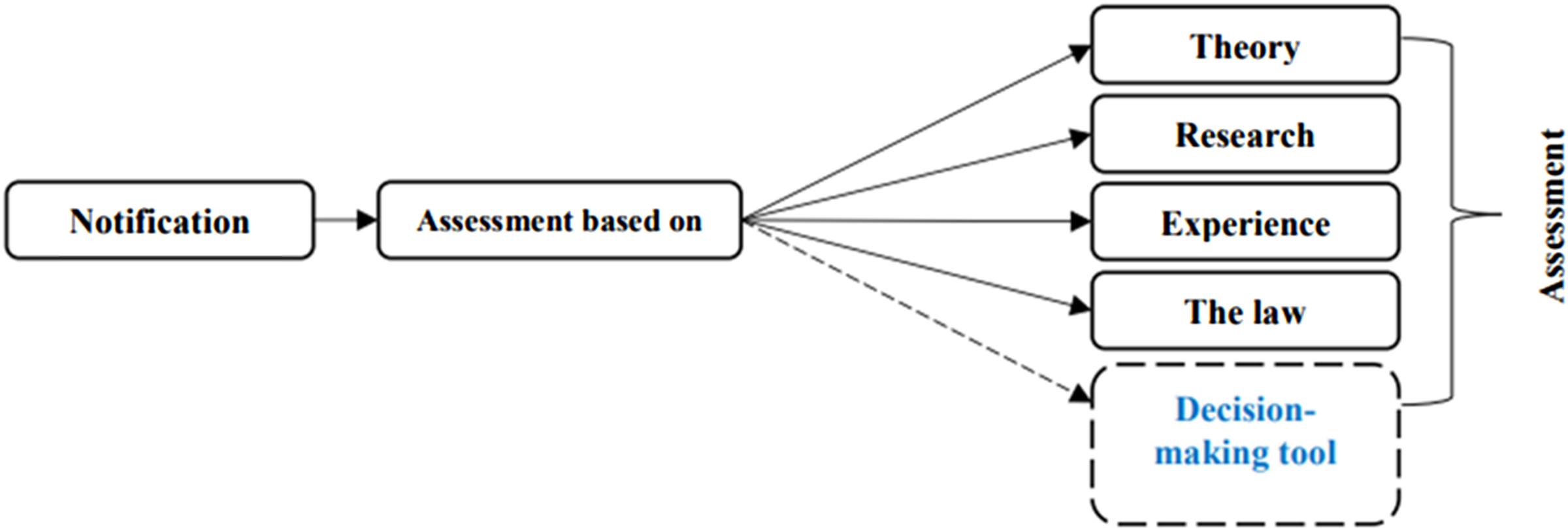
Illustration of the predictive algorithm represented as input and labeled a “Decision-making tool” in the child welfare caseworkers’ assessment process (Short paper 2018).
In this figure, the MLA-child algorithm is labeled “Decision-making tool,” depicted in a flow diagram as one of several inputs or procedures that compiles an assessment. Although the algorithm is labeled a “Decision-making tool,” the researchers continuously underline in project documents, at conferences, and in our interviews that it was never intended to automate any part of the decision-making process. Irrespective that the visualized algorithm was given an inaccurate name, the visualization places the algorithm alongside, not as an automatic replacement of, other inputs, that is, as one among many inputs to the caseworker's risk assessment of an incoming notification. Here, it is suggested that the algorithm as a tool becomes part of a rather elusive repertoire, alongside “the law,” “experience,” “research,” or “theory,” which together form the basis of the caseworker's assessment.
What are tools? Tools have a designated purpose; they are for something. Tools are purpose-specific, less often purely exploratory. Tools provide a temporal narration of what is done in sequence (“first do this, then do that”), making them instructive. But possibly most important here, tools are docile. Tools are optional in the sense that you can use them or not. Tools alone do not impose themselves on users. They are convenient rather than revolutionary. We might decide to use a wrench or try with our hands. The algorithm as a docile tool that is put in line with other resources caseworkers might use is here enacted as just another tool in their toolbox. Here, it does not intrude with, influence, or replace something that already exists. This was important to the researchers: “It can and may never stand alone” they wrote about the algorithm in bold writing in their project documents (Project description 2020, 8).
One way of heterogeneously engineering a world for the algorithm as a tool was to associate it with international examples of similar ambitions. The researchers, for instance, compared their algorithm in research conversations with international social work researchers with “risk models” in international research papers, describing the potential and challenge in a more statistical knowledge base for social workers (Søbjerg et al. 2020). More importantly, they enrolled the researcher Rhema Vaithianathan, who was known—and criticized (Eubanks 2018)—for her work employing machine learning to develop and implement a “predictive risk model” in New Zealand child protection services, as a member of their advisory board. In this way the tool was not only substantiated as a “risk model” but also as a recognizable and already internationally accepted tool with relevance for critical and applied research. This also implied a world where the algorithm was made accessible for international, academic scrutiny. Indeed, data scientists and a legal scholar questioned the algorithm for its biased code base and the regime of surveillance, control, and discrimination it might create (Twitter, archived material). Emphasizing the importance of researchers’ code of conduct to be transparent about how the algorithm (as a tool) was developed, the MLA-child researchers tried to dampen controversies by engaging in online debates, explaining the role of the algorithm as a support, not an automation.
They also did what they could to make the algorithm relevant and acceptable as a tool in Danish social work. For instance, they made what they called “a map of the qualitative landscape of assessments of notifications” with the purpose of understanding the “context in which the statistical model…will be used” (Report on prestudy 2017, 2). Continuously striving to discuss and explain their endeavors, they participated in and presented at national conferences on themes relating to algorithms and decision-making in public administration; they published papers and gave interviews in social work journals. In doing so, they would often enact the algorithm as “a statistical model,” naming it “the decision support” (Research paper in a Danish journal 2021) and underscore, for instance in their 2023 project description, that it is “not artificial intelligence,” because the algorithm does not learn from the real-time data it calculates (Project description 2023). Their plan to test the impact of the algorithm through a randomized controlled trial in four to six municipalities (Project description 2021) also linked the algorithm up with the “gold standard” of how to make this tool “evidence-based.” The algorithm as a tool created a world in which the caseworker's toolbox could be updated with new tools, a rather mechanistic version of casework.
Making a World for the Algorithm as a Data Connector
One thing is developing the [algorithmic] model. It's something entirely different to make it usable. (Project leader, December 2021)
The project leader's reflection on the difference between developing and making the algorithm “usable” speaks to another world-making attempt with a different enactment of the algorithm. To the project leader, usability first and foremost had to do with whether and how the algorithm could be relevant for caseworkers in their assessments of “notifications” of concern for children. Such notifications are most often submitted to the child protection department in an official template, but they can also take the form of a telephone call, an email, or an in-person conversation. In Denmark, the number of notifications increased significantly after it was made mandatory by law for publicly employed professionals to “notify” the municipality of any form of concern for a child's well-being or development.
Getting to the point where the algorithm could be used (or at least tested) for assessments of notifications, required a tedious process of connecting the algorithm to the municipalities’ data infrastructure. In this respect, the difference between “developing” and “making usable” hinged on the idea that the algorithm is already there, as computer code, and that something more must be done for it to become a part of work practices. To make the code into something “usable,” mathematical soundness and tool-like existence were not enough. Unlike a tool, it was not possible to simply grab the algorithm and use it. To use it, the code had to be connected to administrative case databases and “real-time” data from the child welfare department. This made the question of usability a matter of how the algorithm could be made into a connector of otherwise disparate data.
To make a world for the algorithm as a data connector, the researchers hired the software company “Digitize” that was tasked with developing a database from which the algorithm could pull data for its calculation of the risk score as well as an interface for the child welfare caseworkers to see the risk score. In a preliminary brainstorming of software, Digitize visualized a possible “architecture” of the data flows shown in Figure 2.
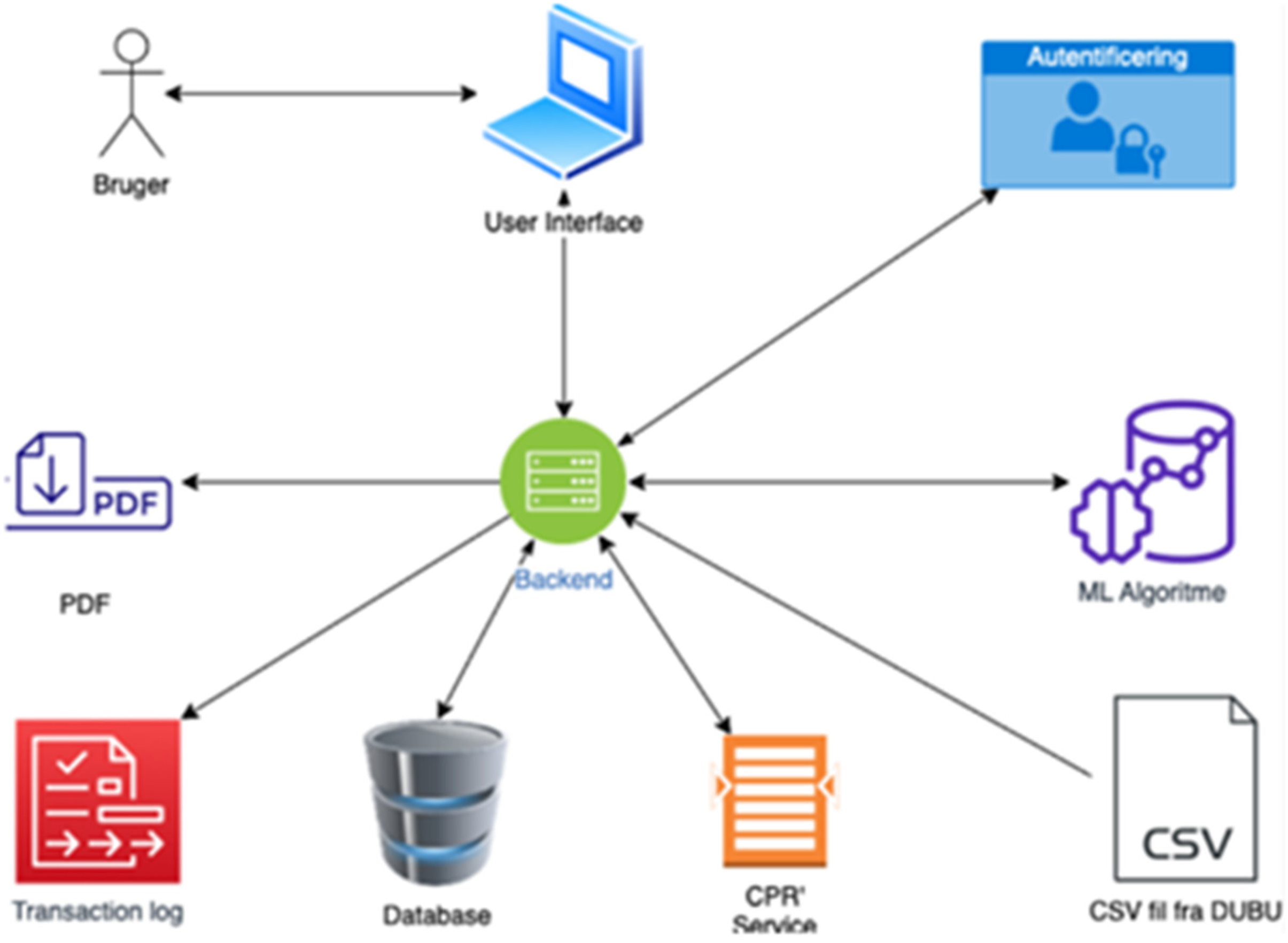
Illustration of a possible system architecture for the predictive algorithm (Digitize report, preanalysis 2022).
In their illustration of a possible architecture, the algorithm on the right side of the figure is entitled “ML algorithm” and visualized as a brain with a graph. The algorithm is one of several elements to be connected with both preexisting (e.g., the two municipal registers) and new elements (e.g., the new database and user interface). The software named “backend” acts as the center that enables these connections between otherwise unconnected software and databases. From this illustration, we get the sense that the algorithm is useable only insofar as it achieves this connectivity, necessary to transform disparate data points into a risk score, accessible for caseworkers (“bruger” = users).
A connector can be a mechanical piece that assures a sealed passing of electricity from one cable to another. Connectors, while enabling transmission, require distinct standardized formats to connect and seal. In electronic circuits, connectors are imperative pieces without which the successful transfer of electricity is disrupted. The algorithm as a connector thus is not optional (like a docile tool), but integral; it enables movement between data points that have previously not been linked. In this enactment, the algorithm is a passage point, essential for the transmission and transformation of data. Like other infrastructural components, the algorithm as a connector moves to the background, being less a matter of choice in casework practices than an invisible and inconspicuous backstage component. As shown in the visualization (it is not in the center), it has moved into the infrastructural background (Star 1999). Instead of the algorithm being front and center, here, the algorithm is meant to do the invisible footwork of connecting and transforming data. As a data connector, the algorithm requires something, it demands something: a certain format or standard for data, and at a specific time. Therefore, it has effects on how data is stored, what formats can be used, and thus should be produced in the future.
As a connector in a larger infrastructural arrangement, the algorithm is contingent upon data flows across different software owners and data providers. To make this world of municipal data infrastructure pertinent for the algorithm as a connector, Digitize and the MLA-child project's data manager spent a considerable amount of time trying to access anonymous test data, necessary for the development of a data flow diagram. For Digitize to know which “user interface” and which “database” to develop, they had to know what data looked like. In an interview, the data manager described to us why this was difficult: I mean, we only need a sample, some flat csv files that the software will transform to a SQL database. But, for [Digitize] to do this, they need to know what these flat csv files look like. And my job has been to find some test data for this. First, we thought that the municipality could give us anonymized data, but they don’t have the competencies or time for that…This data, it moves, but it stems from the municipality and then, then it is registered somewhere and ends with NetCompany and KOMBIT and then the municipality gets it back…It's NetCompany that provides Testville municipality with data…or, first the [municipality's] notification gets registered with KOMBIT who delivers data to NetCompany. (Data manager, January 2022)
All Digitize needed was anonymized data in a “flat csv file” format. However, the infrastructural components—the data formats, the databases, the various software companies, and the municipality—were not adjustable enough to be connected into a new data flow, let alone provide a sample of anonymized data. With no test data, there was no database to connect with the computer code.
Parallel to these attempts to engineer connections between local test data and the algorithm as code, the researchers also discovered that their assumptions about which data Danish municipalities have available for the algorithm did not hold. First, the municipal archives for notifications did not go two years back, as they had trained the algorithm to assume. This they solved by testing whether the algorithm's precision would change with only a one-year history on each child rather than a two-year history (fieldnotes, October 2021). Most critically, they found out that the municipal case system, containing digitalized notifications, was not updated with real-time data but was updated at an interval of around 24 hours. This created what they termed a “time lag problem” (Data Manager, January 2022), meaning it was impossible to pull real-time data for the algorithm. Given that risk assessments have to be undertaken within 24 hours of municipalities receiving a notification, this set-back was critical. Once it proved impossible to gain access to “real-time” notifications, the researchers readjusted their endeavors and tried to engineer a world for the algorithm wherein it could connect its computer code with the 24-hour delayed local test data. Eventually, and as we described in the case presentation, Testville retired from the collaboration. However, the algorithm as a connector created a world where new data storage mechanisms and rhythms would have to be developed and adhered to. Neither the algorithm as connector, nor the new data storage world were durable, and the collaboration with the local municipality was ultimately adjourned.
Making a World for the Algorithm as a Data Processor
The MLA-child researchers could have made a mere research project, aiming to develop and evaluate the algorithm on synthetic data, but they also, in the original research plan, wanted to test the algorithm in actual casework through a randomized trial. This entailed enrolling a law firm in the engineering of a world for the algorithm as a legal method of processing citizens’ data. In a document titled “Background for legal assessments,” the MLA-child researchers described their ambitions in the following words: The data protection impact assessment must identify and evaluate the risks and consequences for the data subjects arising from the processing of personal data in the project and establish effective measures to mitigate them…[whereas the legality review is to] examine whether the research project had a legal basis for processing the personal data…[as well as] whether the municipalities’ potential future use of [the algorithm] complies with administrative law principles. (Background for legal assessment 2021, 2)
As the quote foregrounds, the MLA researchers are forging connections with several laws and legal questions, all concerned with data processing. During legal assessment, as we show below, the algorithm became a data processor that was (1) detached from protected “training data”; (2) had limited access to data; and (3) became a potential blueprint for future algorithms.
First, while an algorithm based on machine learning would not exist without data from which to extract patterns and learn to infer (Amoore 2013), this algorithm-world hinged on establishing a detached version of the algorithm. It became a “mathematical formula” that is “free of personal data” (Review of Administrative Legality 2021, 15). As it says in the analysis of possible consequences of employing the algorithm in casework: “The personal data [used to train the algorithm] has never left the research server [at Statistics Denmark], and after development is complete, only the mathematical formula (algorithm) has been extracted” (Consequential analysis 2021, 21). The legal ontology of the algorithm was one where it existed independently of training data, a hollow shell that could process data but was itself devoid of them.
Second, attempting to determine what this new data would be, the law firm compared the algorithm to current data processors, the caseworkers, who have limited amount of access to data. The legal enactment of the algorithm was thus to process the adequate amount of data, which was defined as the same amount of data as a caseworker has access to. “[The algorithm's] data merging is lawful, as the Decision Support system will not access any other data systems or personal data beyond those the social worker is legally authorized to access and process as part of their routine casework” (Review of Administrative Legality 2021, 8). The algorithm is, for instance, assessed as a process of “archiving,” of “documenting,” of “providing descriptions to citizens of what data is stored,” and of “providing a legal justification for decisions regarding interventions” (Review of Administrative Legality 2021).
What does it mean to enact the algorithm as a data processor? The term data processor usually describes a natural person or organization that processes data on behalf of a data controller, the person or organization whom data belongs to. In legal speech, this person is often a third party that is contractually obligated to process data under agreed-upon terms and conditions (European Commission 2026. As a data processor, an algorithm is neither a discrete tool that is optional, nor a background component that is unavoidable but inconspicuous; it is a formally tasked and visible unit that can be accountable and responsible. By linking the algorithm's operations to familiar regulatory frameworks and practices—such as those governing archiving, documentation, and justification of decisions—its potential disruptive novelty is assessed and rendered as a manageable and lawful extension of the current system.
The potential algorithm-world for the algorithm as a data processor involved not only assessing it according to several corpuses of law but also establishing past, present, and future documentation of the algorithm. The legal assessments produced timestamped documents, accessible from the research project's webpage. These documents systematically relate the algorithm's data processing capacities not only to existing regulatory frameworks but also to earlier decisions; statements made by the ombudsman and legal scientific publications. Creating a world for the algorithm as a data processor included creating public-facing archives of development steps and proving legitimate practices. Assessing the algorithm in terms of known data processes renders it assimilable within the legal system. This alignment serves to enact the algorithm as comparable to existing data processors, requiring legal methods of assessment and effectively making its operations appear as an extension of familiar, regulated processes rather than a disruptive innovation. The algorithm is hereby enacted as comparable to other technologies in the practice of legal assessment. Indeed, in the review of the algorithm's administrative legality it is stated that: When municipalities process personal data through the Decision Support [the algorithm], such processing is carried out under the ordinary legal bases for processing. For the question of the legal mandate for processing data, it is therefore of no independent significance, which IT solution the municipality is using to process data. This includes employing the Decision Support [the algorithm] for processing personal data. (Review of Administrative Legality 2021, 14)
The world for the algorithm as data processor was one of establishing a legal precedent for future algorithms to come, by establishing the algorithm as a continuationof preceding human and digital technologies. The algorithm as a processor was a pioneer to future algorithms and created a provisionary world of many more to come. Indeed, as this legal assessment was later overturned by other legal assessments, it was not a strong and durable world.
Discussion of the Multiplicity of Algorithms and Their Worlds
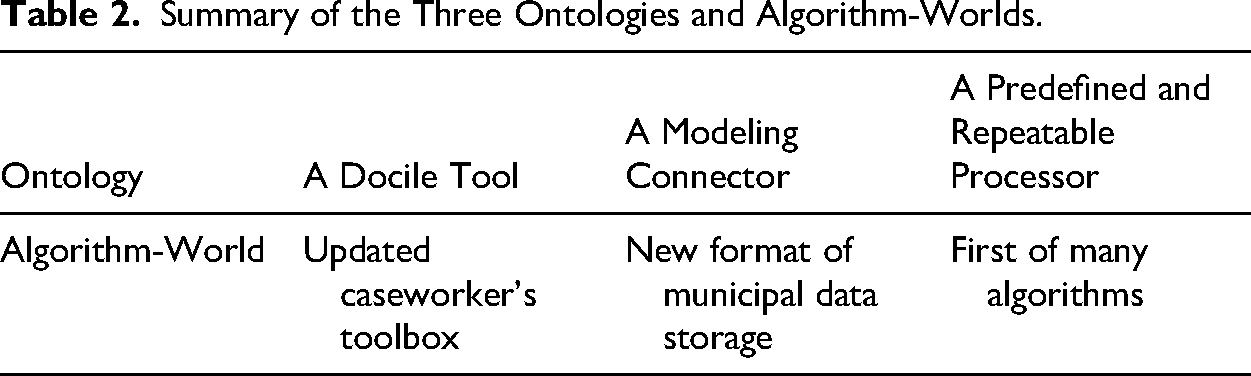
Observing and staying with the MLA-child project, we shed light on researchers’ multifaceted attempts to bring “an” algorithm into being that could support decisions in child welfare casework. We identified not one but three enactments of the algorithm and argued that not only was the algorithm a moving target but so were the potential algorithmic worlds that would be engineered around it. We have shown how the algorithm became a docile tool in presentations to social workers, an unnoticed data connector for an infrastructure of data systems, and a data processor in legal assessments. Table 2 summarizes the three enactments and worlds. The algorithm as a docile tool created a world in which casework is a toolbox with specific inputs and outputs, while the inner workings can be altered. The algorithm as a data connector modeled a world with new data formats and storage rhythms. Lastly, in our analysis we found the algorithm to be enacted as a data processor that had to be neatly defined and emptied for its content to be replicable for future assessments. In this version, the algorithm created a world for coming algorithms; this one was the first of many.
Summary of the Three Ontologies and Algorithm-Worlds.
Drawing on John Law's work ([1987] 2012), we argue that algorithms require heterogeneous engineering—efforts at enrolling various actors in a project in order to be successful. With Annemarie Mol (2002) and Nick Seaver (2017, 2018), we illustrate that algorithms are sociomaterial and always more than one. This discussion section aims to explain how those two approaches in tandem can offer new insights into the study of algorithmic systems in STS. Namely, we propose that “only” focusing on the multiplicity of algorithms may miss out on the heterogeneous world-making that is part of developing algorithms, while a focus on the successful network-building around algorithms might reduce them to technical objects and overlook that algorithms are not only one thing (Lee 2021; Suchman 2023). Importantly, as Annemarie Mol states, when analyzing multiplicity, we must not fall into the fallacy of finding everything to be more than one. Rather, things may be “more than one but less than many” (Mol 2002, 82). In relation to algorithms, this means that while we are able to trace the multiple versions of an algorithm through the different practices they are enacted in, versions are not endless. An algorithm is more than one thing, but still an object of related practices. Although we agree with Suchman (2023) to be critical of the “thingness of algorithms,” we also argue that it is worth retaining some of algorithm's presence when attempting to capture their role in making algorithm-worlds.
STS has long established that objects are neither stabilized nor singular (De Laet and Mol 2000; Mol and Law 1994). In this case of an algorithmic technology and drawing on Jensen's work (2010), we argue that when viewed as objects, algorithms are not only multiple but also partially existing. While the “thingness” (cf. Suchman 2023) of the three figurations is heuristically distinct—a tool, a connector, and a processor—they are neither pure objects nor do they exist independently of each other. For example, in the practice of municipal infrastructure, the algorithm was not a lone-standing tool that was simply added like a puzzle piece, but rather a “fluid” object (Mol and Law 1994) whose existence did not hinge on fixed components but rather on its flexibility. While interface, data, and temporalities could be partially exchanged or omitted, “the algorithm” remained (cf. De Laet and Mol 2000). This leads us to argue that the STS tenet of multiplicity also implies varying degrees of existence when studying algorithms in the making. In doing so, we call for attention to how and where to locate the practices that carve out, or fail to carve out, the thingness of algorithms and their spaces to gain and maintain agency.
As stated previously, the algorithm in question is not fully realized in any of those versions. Now, we might be tempted to make a judgment that if any of the three algorithm-worlds had come into being, or had been better coordinated, the algorithm might have succeeded. We refrain from making this judgment and instead argue that an analysis of algorithms as both multiple and world-making is crucial for understanding current algorithmic practices. Such an analysis is particularly timely in a moment marked by the rapid proliferation of algorithmic initiatives across an expanding range of social problems and public services, where algorithms are increasingly envisioned as stable, finished objects that can improve existing practices. Our case from Danish child welfare is illustrative of a broader tendency, especially pronounced in welfare states and public-sector contexts, in which algorithms are developed through heterogeneous practices that coconstitute multiple, partially overlapping worlds. Attending to these dynamics allows us to grasp not only why algorithms so often remain unfinished or contested, but also how they nonetheless actively participate in shaping infrastructures, sociolegal worlds, and professional discretion.
In our case, it revealed that the three versions are perpetually parallel, existing partially together. We did not observe one version taking over after the other. This means that it is not wrong to claim that an algorithm is a tool for assessment practices in child welfare administration; however, this is only true in this particular world and insofar as it is associated with other “tools.” It is also true that an algorithm is a connector or a processor as long as each remains in its own “world” in which it can act. We therefore emphasize that the relationship between worlds and algorithm varies. Some algorithmic figurations are less conflicting than others: the algorithm as a tool can coexist quite neatly with it as a processor, but not as a connector (it stands by no longer docile). The algorithm as a connector also conflicts with the algorithm as a processor because, as such, it must be predefined and repeatable.
With our analysis, we also introduced three terms for what algorithms can be: a tool, a connector, and a processor. We propose that these terms are situated in practical enactments of this algorithm, yet might be useful to others as they specify what we talk about when we talk about algorithms. Introducing terminology for algorithms drawn from their concrete practical forms contributes to overcoming the universal “thingness” ascribed to them (Suchman 2023), without reducing algorithms to the circumstances of their production. Algorithms create worlds, as we have argued in this article. The terms introduced here—tool, connector, processor—serve to specify our vocabulary related to algorithms. It matters what terms we think through algorithms with; they are as much vehicles of writing as they are expressions of specific and potentially conflicting local logics (Law and Mol 2020). An algorithm cannot be a docile tool if it also inscribes new data storage formats to public authorities. It cannot be a pure container stripped of all data while also serving as a usable tool to public servants. The three ontologies identified here carry their own local logics and remain incommensurable. Moreover, the terms we use here are by no means conclusive; there are several more versions possible.
With these insights, we join the reasoning of STS scholars (Seaver 2017; Lee 2021; Jaton 2017) who underline the importance of not stabilizing algorithms as “a thing” (Suchman 2023). If we do so, we fail to account for how societies are transforming with the present urge for algorithmic solutionism. As many scholars have pointed out, this seems like a dystopic vision, making the world as we know it a mere parenthesis. However, we can also choose to view this as the reason why we do not have to fear the algorithm takeover. Algorithms are not sudden events “hitting” the welfare state, but slow, meticulous processes, becoming embedded—or not—in existing practices, infrastructures, and legal precedence.
Footnotes
Acknowledgments
We express our sincere gratitude to the interlocutors at the MLA-child project for their generosity in taking time to share insights, perspectives, and thoughts as well as patiently explaining their practices. Their contributions have enriched the scope and depth of our research. Additionally, we greatly appreciate all the prosperous discussion about this paper since we have been involved in as researchers in the ADD project. And finally, we extend our gratitude to the VELUX FOUNDATIONS (Algorithms, Data & Democracy Jubilee Grant) and our previous affiliations with Aarhus University for supporting this research.
Author Contributions
Ida Schrøder has conducted the ethnographic study, analyzed the material, and engaged in conceptual development. Helene Friis Ratner initiated the project, conducted the first rounds of interviews, and participated in developing the paper's framework and analysis. Laura Kocksch engaged in conceptual development. All authors have contributed equally to the writing of this manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Velux Fonden (grant number Algorithms, Data & Democracy Jubilee Grant).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.