
Abstract
Amid educational debates about generative artificial intelligence (GenAI), little research focuses on large language models’ (LLMs) reliability, which has important implications regardless of whether students are permitted to use LLMs in sociology classrooms. In this exploratory study, we focus on the intersection of GenAI and teaching and learning in sociology, asking: To what extent are LLM services, including ChatGPT, DeepSeek, and Gemini, reliable (a) with one another and (b) over (a short) time? We administered a sociology quiz with 20 multiple-choice questions of varying difficulty—and covering different topics, some of which are sensitive—to each of these LLM services over the course of two seven-day intervals: April 21 through 27, 2025, and June 13 through 19, 2025. The results indicate very high levels of reliability between LLM services and over these time intervals, but some unreliability mainly on two questions that were sensitive, required higher-level thinking, or both. Pedagogical and other implications are discussed.
Artificial intelligence (AI), which refers to machines (e.g., computers) said to perform tasks comparably to humans (McCarthy et al. [1955] 2006), has already transformed society and may be more impactful in years to come. Generative AI (GenAI), which includes large language models (LLMs) like ChatGPT, can provide quick and easy answers to questions and produce seemingly novel content. 1 LLMs may “revolutionize education” (Khan 2024), but the contemporary reality is empirically nuanced: A global report indicates more than half of students use GenAI regularly in their studies, with a sizable proportion acknowledging they use it inappropriately (Gillespie et al. 2025:90–91). Meta-analyses find that GenAI use is associated with greater academic or learning performance (e.g., Sun and Zhou 2024; Wang and Fan 2025), but some studies show that students “cognitively offload” academic work to GenAI (e.g., Gerlich 2025). A fundamental question for teachers and learners in deciding whether and how to use LLMs concerns their “trustworthiness,” which refers to LLMs’ accuracy, reliability, and other characteristics (Kaur et al. 2022; Li et al. 2023). There is no shortage of research examining LLMs’ accuracy (e.g., Hendrycks et al. 2020; Herrmann-Werner et al. 2024; Huber and Niklaus 2025), but there are far fewer studies on LLMs’ reliability (for exceptions, see e.g., Chen, Zaharia, and Zou 2024; Dima et al. 2025), let alone in pedagogical or sociological contexts. This is a salient lacuna because reliability is a prerequisite of AI trustworthiness (Kaur et al. 2022) and validity (Carmines and Zeller 1979) and is integral to teaching and learning—as well as assessments thereof.
In this study, we conceptualize reliability as whether an LLM service (e.g., OpenAI’s [2025a] ChatGPT) provides the same responses as other LLM services (e.g., DeepSeek 2025) and whether an LLM service provides the same responses over (a short) time. A few examples illustrate this topic’s pedagogical importance. To begin with an example inspired by news stories on an LLM service (Burman 2025; Forlini 2025), imagine that students are completing a paper on the sociological factors underlying the 1989 Tiananmen Square protests. The instructor allows students to use LLM services only to answer questions about historical context. Some students use DeepSeek, which was developed in China and is argued to be subject to state surveillance, and others use U.S.-based ChatGPT. To the extent students use only LLM services for historical context (uncritically), their papers may diverge on the origins of the protest because DeepSeek is hesitant to critique the Chinese state (Burman 2025; Forlini 2025), assuming it answers at all.
Even the same LLM service may provide disparate information at different points in time (e.g., Chen et al. 2024; see also Bail 2024; Davidson 2024). This is most obviously the case when an LLM service’s version is upgraded (Chen et al. 2024), as when Google (2025) upgraded Gemini 2.0 to 2.5. Yet it is also a possibility in the same version (e.g., Gemini 2.5) given that LLM services constantly tweak their models, including in response to user feedback (Chen et al. 2024). For instance, statistics students could all use the same instructor-provided prompts in Gemini 2.5 to get software code, but they may get different code across days or semesters.
Although these examples focus on the possibility that LLM services are not reliable, it is equally—if perhaps not more—consequential for teaching and learning if they are highly reliable. This can yield homogeneous responses, for example, across users (Dell’Acqua et al. 2023), which complicates instructors’ assessment strategies and their evaluations of completed student work. From the perspective of Bloom’s ([1956] 1984) well-known taxonomy and its revisions (Anderson et al. 2001), which, respectively, propose that the evaluation of an existing idea and creation of something new represent the highest levels of learning, the foregoing undermines the purported benefit of GenAI to produce (seemingly) original content.
This exploratory study contributes to research at the intersection of multiple disciplines, including computer science, education, and sociology. Our primary research questions are: To what extent are LLM services—namely, OpenAI’s (2025a) ChatGPT, DeepSeek (2025), and Google’s (2025) Gemini—reliable (a) with one another and (b) over (a short) time in completing a sociology quiz? In answering these questions, our research speaks to sociological literature on AI (e.g., Bail 2024; Davidson 2024; Joyce et al. 2021), but it focuses on little-explored pedagogical implications, including in this journal (for an exception, see Judson 2025). Our study provides an evidentiary basis for future research and teaching applications in sociology.
Literature Review
To evaluate LLM services’ performance, researchers in computer science, education, and other disciplines input information through prompts via an advanced programming interface and less commonly, via the “chat” features of LLM services (e.g., ChatGPT). Researchers use multiple-choice questions, open-ended questions, and tasks as inputs and assess the quality of LLM services’ output, usually against benchmarks. The large body of research that focuses on LLM services’ accuracy uses “correct” or “best” answers on externally validated tests as benchmarks, sometimes also comparing LLM services’ output to random chance or humans’ performance. In the earliest study to incorporate sociology questions of which we were aware, the initial results were not promising: LLM services achieved little more than 60 percent accuracy on these (multiple-choice) questions (Hendrycks et al. 2020). Since that time, LLM services have performed very well on Hendrycks et al.’s (2020) broader benchmark, Massive Multitask Language Understanding (MMLU) [Maslej et al. 2025], so much so it has been updated with MMLU-Pro, which is more challenging (but does not cover sociology specifically) [Wang et al. 2024]. LLM services’ increasing accuracy is a larger trend, and LLMs have now surpassed humans’ abilities on multiple benchmarks, mainly across different domains, except “logical reasoning, such as arithmetic and planning” (Maslej et al. 2025:87, 94–95).
Other literature assesses LLM services’ performance through the lens of Bloom’s ([1956] 1984) taxonomy, which holds that learning occurs in stages (knowledge/remembering, understanding, application, synthesis, and evaluation). In one such study that uses a host of benchmarks requiring open-ended completion, Huber and Niklaus (2025:5217) show that LLM services “generally perform better on the lower end of the taxonomy,” such as in the “remembering” domain. Sallam et al.’s (2024) results reveal a similar pattern using students’ multiple-choice clinical chemistry exam scores as benchmarks. Herrmann-Werner et al. (2024) find that ChatGPT’s accuracy on psychosomatic medicine multiple-choice exam questions is excellent, but among the incorrect answers, its explanations reveal problems at the lower end of Bloom’s taxonomy (e.g., lack of understanding) according to their qualitative analysis.
Some of the foregoing and other research speaks to our study’s focus on LLM services’ reliability. For instance, the Huber and Niklaus (2025) study makes use of multiple LLM services, including GPT-4, Meta’s Llama, and Anthropic’s Claude3, and shows performance variation across these LLM services, suggesting some lack of reliability between these services. In a study more squarely focused on reliability, Dima et al. (2025:4) use several OpenAI “completion-style LLMs,” which “rely on a user prompt to generate text that completes or continues the text in the prompt,” and find a degree of unreliability between these LLMs. In these and other studies, there is also evidence that different versions of the same LLM service are not entirely reliable with one another (e.g., Dima et al. 2025; Sallam et al. 2024).
The research most directly relevant to the present study is Chen et al.’s (2024) analysis of two versions of GPT (3.5 and 4) across seven different domains (e.g., math, medicine, visual reasoning, and answering “sensitive” questions) at two different points in time (March and June 2023). Chen et al. (2024) find a good deal of “mismatch” between these two versions, which they define as “how often, for the same prompt, the extracted answers by two versions of the same LLM service do not match.” Chen et al. (2024) furthermore show that LLM services’ performance can “drift” over time, including for answers to “sensitive questions,” which they define as “queries that LLM services are not supposed to answer directly.”
While synthesizing research design elements of previous studies (e.g., Chen et al. 2024; Hendrycks et al. 2020; Herrmann-Werner et al. 2024), the current research departs from extant studies in its focus on reliability in a pedagogical and sociological context. The exploratory nature of this study means we do not have preformulated hypotheses, but we might expect some unreliability between LLM services on “sensitive” questions (Chen et al. 2024) and those toward the upper end of Bloom’s ([1956] 1984) taxonomy (e.g., Huber and Niklaus 2025).
Materials and Methods
To answer our research question about LLMs’ reliability across services and over (a short) time, we compare three LLM services. Two of them, ChatGPT (OpenAI 2025a) and DeepSeek (2025), were chosen because of their popularity, long-standing (ChatGPT) or new (DeepSeek) at the time our research design was solidified. These LLM services are similar in that there are free versions of both—and are thus likely to be used by a broad swath of students (see Gillespie et al. 2025)—and both require a login. ChatGPT and DeepSeek are also similar in that both display known biases, but they may depart in their specific biases: Whereas some research indicates that ChatGPT has a liberal political bias (Motoki, Pinho Neto, and Rodrigues 2024), news articles discussed earlier suggest that DeepSeek has a pro-China bias (Burman 2025; Forlini 2025). This is pertinent to our selection of these LLM services and as discussed later, some of our quiz questions. The third LLM service, Gemini (Google 2025), differs from the others in that it was not free when our research began—but was free to us as part of our institution’s Google Workspace—and we know less about its specific biases.
The sociology questions we developed were guided by several considerations. In line with some previous research (e.g., Hendrycks et al. 2020; Herrmann-Werner et al. 2024), we developed multiple-choice questions, the answers of which are more amenable to reliability calculations. We attempted to avoid using existing questions outright because they may already be part of LLM services’ training data. In addition, some of our questions reference “sensitive” content, although we define this differently than Chen et al. (2024): Namely, sensitive content concerns politics and other matters, such as China’s alleged role in a COVID-19 cover-up, COVID-19 vaccines, “groupthink” among liberals, and socialism that may evoke bias. Finally, we attempted to develop questions at multiple levels of Bloom’s ([1956] 1984) taxonomy.
The questions we administered to LLM services appear in the Appendix. The first author wrote many of the 20 questions and answer choices, but some are from or adapted from test banks for an introductory sociology textbook, such as the stems for Questions 1, 4, 7, and 11 (Christensen et al. 2013), and for another textbook (Dixon, Singleton, and Straits 2023), such as Question 18. The questions are roughly ordered according to their placement in Bloom’s ([1956] 1984) taxonomy. For instance, Question 1 focuses on the rote memorization of the definition of sociology, with poor distractors. Questions 17 through 20 attempt to gauge the extent to which LLMs can apply, analyze, synthesize, and/or evaluate information; however, it is difficult, if not impossible, to gauge the “evaluation” domain with multiple-choice questions. A limitation of our study is that our questions were not externally validated beforehand, save for the second author informally answering draft questions, resulting in a revision to one answer choice, but we view this limitation as less central to our study on reliability than studies focused on validity.
LLM Prompting Process and Timeline
We administered our 20-question sociology quiz to the three LLM services through the chat features likely to be used by students. Prior to prompting each service for the quiz answers, the second author took steps to minimize the possibility of the LLM services using existing knowledge about the user or “remembering” answers to questions from previous days. First, she deleted previous chats from her accounts and changed the settings so that future chats would not remain. Second, she used our college’s virtual privacy network (Paloalto Global Protect [6.3.0-33]) and a privacy-focused browser (Mozilla Firefox 137.0.2), deleting cookies—stored pieces of information—after every session with each LLM. For instance, on the first day, she began a session with ChatGPT, saved the responses, cleared her chat history, logged out, deleted cookies, closed the browser, and then reopened the browser to start a session with DeepSeek. This process was repeated for each study day, but at best, it mitigates some methodological concerns noted earlier and is not foolproof: The second author’s logins to ChatGPT, DeepSeek, and Gemini all used her Google account, which may make use of data the second author cannot easily delete.
The quiz administration was conducted over two seven-day intervals: The first was between April 21 and April 27, 2025 (inclusive); the second was between June 13 and June 19, 2025 (inclusive). Our primary longitudinal interest concerns LLM services’ reliability over seven days, so we attempted to standardize the process for each day in the interval. The second author prompted at approximately the same time of the day for each interval (e.g., late afternoon in April and early morning in June). The initial prompt was the same except that the specific LLM service’s name was referenced (e.g., “Hi [ChatGPT, DeepSeek, Gemini]”). Importantly, the second author did not provide any feedback, written or in the form of emojis, to the LLM services that could be used for training purposes; she simply thanked them at the end of the sessions. However, a difference between the two seven-day intervals is that the second author queried each LLM service about its model and version number during the June interval only.
Save for minor standardization differences between the two seven-day intervals, our study could theoretically speak to some reliability differences between the April and June 2025 intervals. Yet a more confounding factor is the LLM service version because the seven-day interval in June may have corresponded to version changes. As Chen et al. (2024) note, “when and how these models are updated over time is opaque.” Our first seven-day study interval (in April 2025) likely made use of the following general versions, based on the best publicly available information: ChatGPT (GPT-4o), DeepSeek (V3), and Gemini (2.0) (Google Cloud 2025; OpenAI 2025b). When we asked each LLM service about its model and version in June 2025, as previously described, DeepSeek consistently provided an answer—and the same one (V3)—but there was greater response variability for ChatGPT and Gemini. ChatGPT indicated its version as GPT-4-turbo and in one case, the GPT4.5-turbo model, sometimes muddying the water with responses such as the following: “
Data Structure, Coding, and Analysis
Our data are structured such that the sociology quiz questions are the primary units of analysis, the responses of which we coded into numerical values as follows: A = 1, B = 2, C = 3, D = 4, and no response = 0. One observation is excluded from our analysis because a question was not asked of a model one day. Our data set includes responses by LLM service (n = 3), day (n = 7), and interval (n = 2) for a total of 42 additional variables: for example, ChatAD1 for ChatGPT’s responses in April, “A,” on Day 1, and so on. Using the “kap” command in Stata 16.1 for “[m]ore than two ratings, constant number of raters” (StataCorp 2019:1208), we calculate Kappa values to determine the interrater reliability between the three LLM services and within each LLM service between the seven days in each interval; higher Kappa values indicate greater interrater reliability. We also highlight qualitative differences in LLM services’ textual responses. Finally, we calculate the overall percentages of agreement, which serve as additional measures of reliability.
Results
Beginning with the first part of our research question, the interrater reliability between ChatGPT, DeepSeek, and Gemini is high, reflecting widespread answer agreement among these LLM services. The combined Kappa values, which are averages of individual kappas for each quiz answer and nonresponse in our study (see StataCorp 2019), range from 0.91 to 1.00 across the 14 days of our study. These high levels of reliability must be viewed in the context of a multiple-choice quiz (Wang et al. 2024), but they are not due to chance, based on our analyses.
There are two main questions on which the LLM services did not agree on the answers, both of which are located toward the middle of Bloom’s ([1956] 1984) taxonomy. The first is Question 13 in the Appendix, which attempts to gauge application of the concept of discrimination (“D” in the answer key). The question stem includes a statement about the “Chinese government’s alleged role in covering up the origins of the [COVID-19] virus,” which was explicitly designed to potentially elicit bias based on news reports (Burman 2025; Forlini 2025). Twice, DeepSeek did not answer this question, responding as follows: “Sorry, that’s beyond my current scope. Let’s talk about something else” (DeepSeek 2025 [April 21 and 27, 2025]). One day, Gemini also did not answer, stating, “Sorry, something went wrong. Please try your request again” (Google 2025 [June 13, 2025]). Once, ChatGPT indicated that the answer was “A: Racism” (OpenAI 2025a [April 25, 2025]).
The other question for which the answers mainly diverged is Question 15, asking about the clearest point of theoretical agreement between Max Weber and Georg Simmel. This question requires analysis and is likely one on which sociologists would not agree because it arguably has two correct answers: “B: Verstehen is an important practice in order to examine people’s behavior,” as indicated in the answer key in the Appendix, and “A: The size of the network or group of which one is a part is central to understanding people’s behavior.” Whereas Deep Seek consistently answered “B” across all days, ChatGPT and Gemini’s responses waxed and waned between “A” and “B.” In the seven-day interval in June 2025, for instance, ChatGPT consistently answered “A,” but Gemini consistently answered “B.” At the midway point of this interval (Day 4), these LLM services, respectively, explained their answers as follows: The correct answer is:
A.
•
•
• While Weber emphasized
The most clear point of agreement between them would be:
B.
•
•
Let’s look at why the other options are less accurate:
A.
Turning to the second part of our research question, the interrater reliability within each LLM service across study days is also very high. Table 1 presents the combined Kappa values across days by LLM service for each of the two intervals, which are presented separately because these intervals are not completely comparable. Looking first at the seven-day interval in April 2025, the combined Kappa values across LLM services range from 0.94 to 0.97 (rounded), meaning that each LLM service provides highly consistent answers across these days. During the seven-day interval in June 2025, the combined Kappa values range from 0.94 to 1.00, with ChatGPT and DeepSeek each exhibiting the highest possible levels of interrater reliability.
Combined Interrater Reliability (Kappa) across Days by Large Language Model Service and Seven-Day Interval.
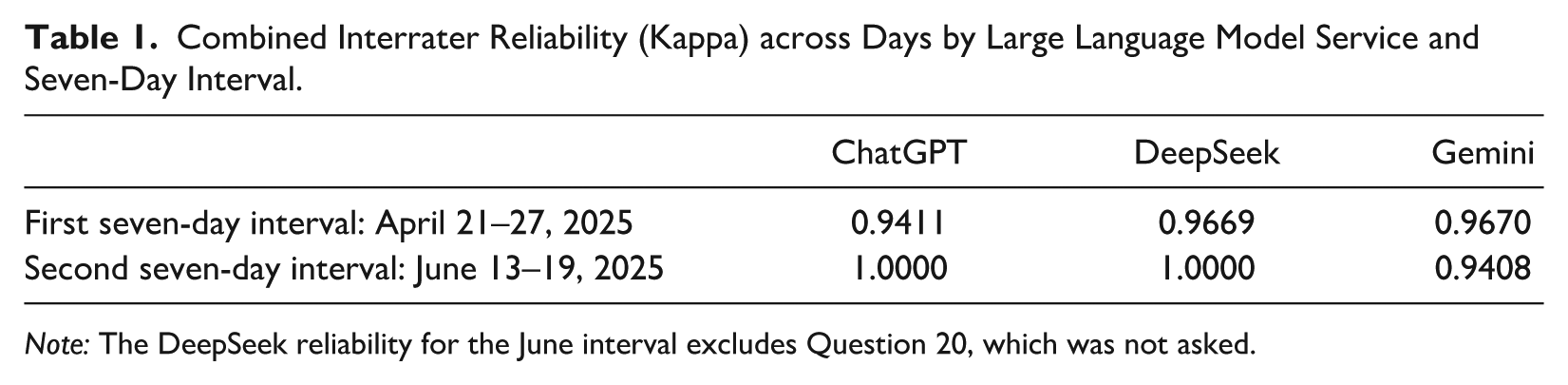
Note: The DeepSeek reliability for the June interval excludes Question 20, which was not asked.
Direct overall comparisons between these two seven-day intervals risk conflating time and LLM services’ versions, particularly for ChatGPT and Gemini, and interval differences may be due to still other factors. Nevertheless, two sets of responses are notable: First, during the June 2025 interval, DeepSeek did not refuse to answer Question 13 (about China and COVID-19), as it sometimes did during the April interval; instead, it consistently answered “D: Discrimination.” Second, ChatGPT consistently answered “A” in response to Question 15 (about Weber and Simmel) in June 2025, but it answered “B” to the same question three out of seven times in April. At the midpoint in April (Day 4), ChatGPT responded “B,” explaining: The correct answer is:
B.
Both
Finally, looking at reliability from another perspective, 263 times, or 94 percent of the time, ChatGPT, DeepSeek, and Gemini completely agreed on the quiz answers, based on the 279 levels of agreement we calculated between services (20 quiz questions × 7 days × 2 intervals – 1 observation because a question was not asked). These LLM services are also internally consistent over these short time intervals. For instance, across the seven days of the April interval, Gemini provided the same answer to each quiz question 138 times, or 99 percent of the time (138/140). As another example, across the seven days of the June interval, ChatGPT provided the same answer to each quiz question 100% of the time. The few instances in which we observed some unreliability may be due to the nature of the questions, as we discuss in the following.
Discussion
Amid ongoing debates about GenAI, our research examines whether three LLM services—OpenAI’s (2025a) ChatGPT, DeepSeek (2025), and Google’s (2025) Gemini—are reliable with one another and over (a short) time in completing a sociological quiz. The results indicate high levels of reliability across these services and within each service over seven-day intervals. Yet this widespread agreement may not be cause to celebrate. Our study has the clearest pedagogical implications for the use of multiple-choice quizzes and exams in the classroom (see Sallam et al. 2024): Instructors employing these assessments may see response homogeneity if students use these LLMs. Our study thus adds empirical weight to the growing chorus calling on educators to develop suitable AI practices and policies (Judson 2025) and/or attempt to “AI-proof” their assessments.
The high levels of agreement across LLM services and over time for questions at the lower end of Bloom’s ([1956] 1984) taxonomy are not surprising, considering previous research on LLMs’ accuracy (e.g., Herrmann-Werner et al. 2024; Huber and Niklaus 2025). The two primary quiz questions on which the services diverged (Questions 13 and 15), including over time, were either “sensitive,” as we define it here (e.g., political or similar content), required higher-level thinking from the perspective of Bloom’s ([1956] 1984) taxonomy, or both. Based on our results, however, we cannot say that LLM services face challenges in consistently answering questions toward the top of Bloom’s ([1956] 1984) taxonomy. One way future research could better speak to this is by posing open-ended questions and essay prompts to multiple LLM services over time.
In this study, LLM services’ textual responses to questions with diverging answers—and to the question we posed about the model and version number—leave more to be desired and speak to literature on AI trustworthiness (e.g., Kaur et al. 2022; Li et al. 2023). LLM services’ lack of (consistent) transparency about their models and versions has implications for reproducibility not just in GenAI research (e.g., Bail 2024; Davidson 2024; Li et al. 2023) but also in teaching: For instance, instructors who permit their students to use AI may require students to log their work, but even with LLM service and temporal standardization, students’ logs may not be reproducible due to different versions they use and other (unknown) factors.
Bearing in mind the already noted limitations of this exploratory study, the most important of which is its inability to effectively control for extraneous factors, the results of our study highlight some of LLM services’ strengths and weaknesses in particular contexts. Teachers and learners may not be fully aware of these strengths and limitations when deciding to use LLM services or actually using them. And although reliability is a methodological strength of the LLM services for the purposes herein, it may be a pedagogical limitation for instructors.
Footnotes
Appendix
Acknowledgements
The authors thank Zeynep Mirza for her initial research idea suggestion and discussions about the project; we also thank Daina Harvey and Andrew S. Fullerton for their comments on an earlier draft.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was partly funded through a J.D. Power Center grant from the College of the Holy Cross for the second author to work as a research associate during the 2024–2025 academic year; it was also partly funded through the first author’s professional developmental account via the College of the Holy Cross Provost’s Office during summer 2025.