
Abstract
Low-light conditions reduce brightness and contrast, obscure structural details, and amplify noise, which degrades visual quality and adversely affects downstream tasks, such as object detection and segmentation. Despite significant advances in deep learning-based enhancement, existing approaches still struggle to simultaneously balance brightness, detail preservation, and color fidelity. To address this, we propose a two-stage Retinex-based algorithm guided by multi-channel integrated feature optimization. Our main contributions are threefold. (1) We introduce a three-channel illumination decomposition strategy that models RGB illumination independently to mitigate color distortion. (2) We design a U-Net–based decomposition network with deformable convolutions, dual-layer attention, and selective-kernel fusion for multi-scale feature extraction. (3) We develop a two-branch fusion network incorporating detail enhancement, low-frequency filtering, and a curve-based illumination adjustment module for artifact-free enhancement. Extensive experiments on standard datasets show that our method outperforms state-of-the-art algorithms in terms of PSNR, SSIM, and NIQE. Furthermore, experiments on the ExDark dataset demonstrate that the proposed method improves object detection mAP to 0.193, representing a 67.8% increase over the original low-light images, thereby validating its effectiveness for downstream vision tasks.
Keywords
1. Introduction
In many real-world applications, such as security monitoring, autonomous driving, medical imaging and remote sensing, images captured under low-light conditions often suffer from insufficient brightness, low contrast, blurred details, and heavy noise. These degradations not only reduce visual quality but also hinder high-level vision tasks such as object detection and segmentation. 1 With advances in deep learning, low-light image enhancement has developed rapidly, leveraging neural networks to learn illumination estimation and restoration strategies directly from large-scale datasets.2,3 In this work, low-light conditions refer to scenes captured under insufficient illumination, typically characterized by low luminance, reduced contrast, and low signal-to-noise ratio (SNR), often accompanied by noise amplification and color distortion. Such conditions commonly occur in nighttime environments, poorly illuminated indoor scenes, and complex real-world scenarios. 4
Recent methods can be categorized as follows. Supervised learning approaches train models on paired low-/normal-light images to directly learn decomposition and enhancement mappings. Early representative works adopt Retinex-inspired decompositions or encoder–decoder structures to estimate illumination and reflectance from paired datasets.5,6 However, many supervised methods rely on a single-channel illumination estimate that is simply replicated across RGB channels, which can cause color distortions under complex lighting. 3 Reinforcement-based or exposure-learning methods cast enhancement as a sequential decision problem, where the network learns to adjust exposure or enhancement parameters through reward signals rather than pixel-wise loss. 7 These methods can flexibly adapt to varying lighting conditions and sometimes preserve details better without paired supervision. 8 Nevertheless, they often require carefully designed rewards and may be less stable during training. 9
Unsupervised approaches, based on adversarial training, learn enhancement from unpaired datasets by combining Generative Adversarial Networks (GAN) objectives with perceptual or cycle-consistency constraints.10,11 These methods tend to generalize better to diverse real-world scenarios but can produce artifacts or inconsistent color fidelity if discriminator or perceptual losses are not well balanced. 12
Zero-shot and test-time optimization methods derive enhancement mappings from the input image itself. 13 This method avoids dataset domain gaps and can operate in real time, but may struggle with extremely noisy or severely underexposed inputs.14,15 Motivated by the complementary strengths and weaknesses of these paradigms, we propose a two-stage Retinex-based framework that jointly leverages multi-channel illumination modeling and learned fusion to balance brightness recovery, color fidelity, and noise suppression.16,17
Despite significant progress, several challenges remain. 18 Many existing models struggle to balance brightness enhancement, detail preservation, and color fidelity simultaneously, resulting in blurry structures or unnatural colors. 19 Low-light images captured in complex scenes exhibit coupled degradations such as noise, blur, and non-uniform illumination, which remain challenging for traditional Retinex-based or single-branch models. 20 Models relying on single-channel illumination estimation inherently limit color accuracy, because illumination is not strictly uniform across RGB channels under real imaging conditions. Finally, encoder–decoder structures based on upsampling operations frequently introduce checkerboard artifacts that degrade visual quality.
To address these challenges, we propose a two-stage low-light image enhancement algorithm based on Retinex theory, incorporating multi-channel integrated feature optimization. In the decomposition stage, we introduce a three-channel illumination modeling strategy that separately learns the illumination distributions for the R, G, and B channels. This design effectively mitigates the color distortion commonly observed in single-channel approaches. A U-Net architecture serves as the backbone of the proposed decomposition network. 21 This backbone is augmented with deformable convolution and a dual-layer attention mechanism.22,23 These enhancements substantially strengthen the network’s capability for multi-scale feature extraction in low-light conditions. Consequently, the model achieves a more precise decomposition of reflectance and illumination components. In the fusion stage, a Detail–Low-Frequency Module (DLM) processing module inspired by PE-YOLO is employed to jointly enhance texture information and suppress noise. 23 Additionally, a learnable curve-based illumination adjustment module is integrated to achieve smooth and artifact-free brightness enhancement, avoiding the checkerboard effects associated with conventional upsampling.
The proposed network is optimized with a redesigned loss function that includes an illumination grayscale constraint, encouraging consistent and low-contrast illumination across channels and improving decomposition stability. To fully exploit reference images in paired datasets, reflectance and illumination components are jointly restored using the enhanced fusion module.
Recent research has highlighted that low-light image enhancement does not always lead to consistent improvements in downstream vision tasks. In some cases, enhancement artifacts may degrade detection or classification accuracy, and the impact is often category-dependent. 24 To address this issue, several studies have explored joint enhancement–recognition frameworks, which aim to optimize low-level image restoration and high-level semantic understanding in a unified manner. 25 These findings suggest that evaluating enhancement methods solely based on image quality metrics may be insufficient, and downstream task performance should be carefully considered.
Extensive experiments on standard datasets demonstrate the superiority of the proposed method. On LOL-v1 and LOL-v2-real, the algorithm achieves improvements in PSNR, SSIM, and NIQE over state-of-the-art methods including RetinexNet, 5 KinD++, 26 RRM, 27 R2RNet, 28 EnlightenGAN, 12 URetinexNet, 29 Diff-Retinex and LYT-Net.30,31 On unpaired datasets such as LIME, NPE, MEF, and VV, our method shows strong generalization and produces more natural enhancement results. Furthermore, validation on the ExDark dataset demonstrates that enhanced images can significantly improve object detection accuracy when combined with the DETR or YOLOv5 detector, confirming the method’s practicality in downstream visual tasks.32,33
2. Methodology
Building on the two-stage Retinex-based low-light image enhancement algorithm, we propose an improved multi-channel low-light image enhancement algorithm (MC-LLE) that performs multi-channel decomposition of illumination. As illustrated in Figure 1, the algorithm primarily consists of an image decomposition network and an image fusion network. In the image decomposition stage, based on the U-net encoder-decoder architecture,
34
a Multi-Scale Deformable Feature Fusion with Dual-Layer Attention (MSDFF) and a multi-feature fusion strategy are incorporated to decompose the input low-light image into a multi-channel reflectance image and a multi-channel illumination image. In the image fusion stage, histogram equalization is incorporated into the network as a prior. Specifically, the input low-light image is first processed by histogram equalization, and the resulting enhanced image is jointly fed into the fusion network (PX-DenseUNet) together with the reflectance and illumination components produced by the decomposition network. Formally, the histogram-equalized image serves as an auxiliary input branch, providing global intensity distribution priors that complement the learned reflectance and illumination representations during feature fusion. The fusion network adopts a DenseUNet architecture with a channel attention mechanism and is trained under the supervision of reconstruction and structural similarity (SSIM) losses. Multi-channel low-light image enhancement algorithm architecture.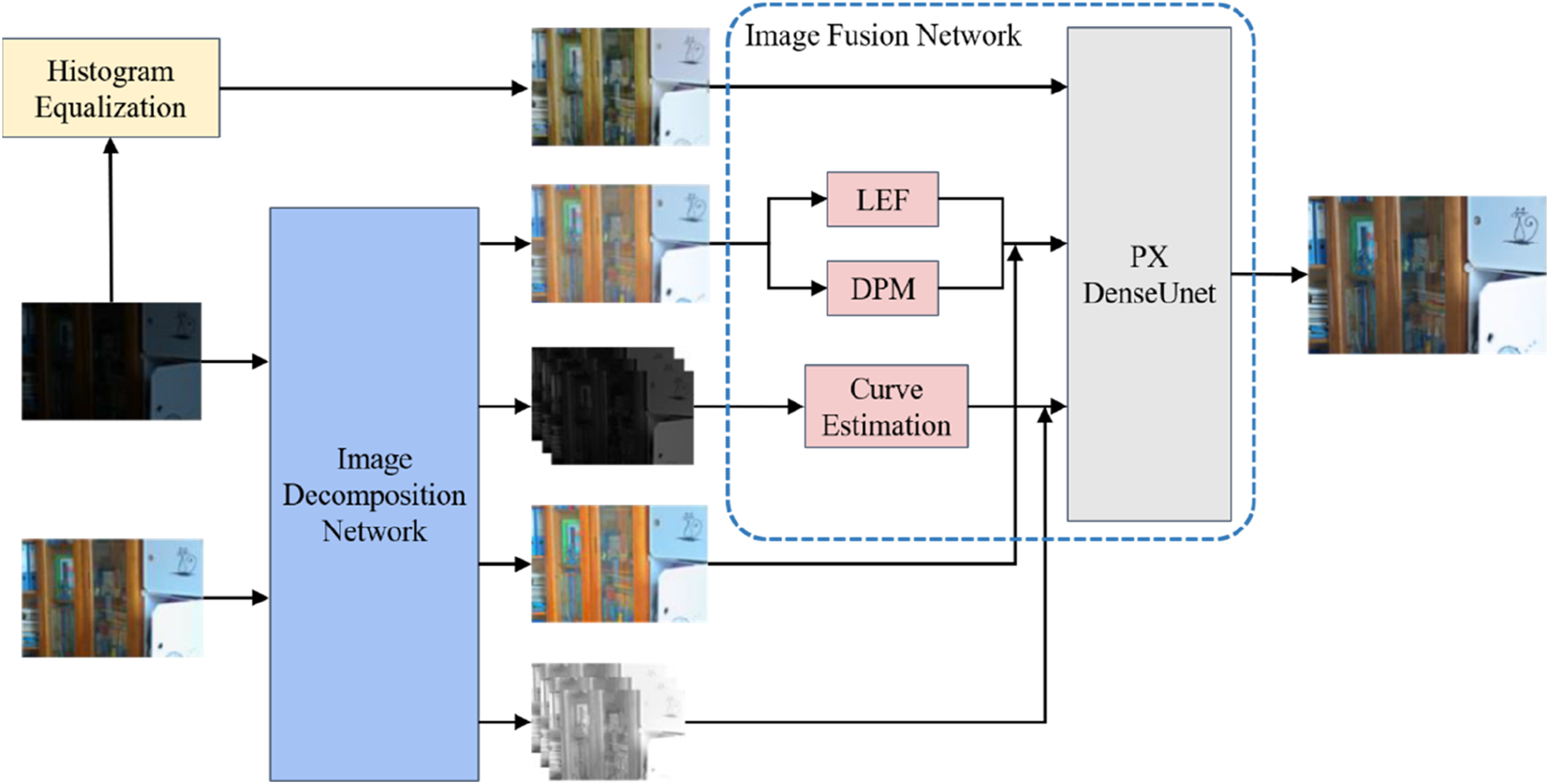
Specifically, the proposed PX-DenseUNet differs from standard DenseUNet in three aspects: (1) pixel reorganization is adopted instead of traditional upsampling to alleviate checkerboard artifacts; (2) a channel attention mechanism is embedded into each dense block to enhance feature selection; (3) multi-source inputs (reflectance, illumination, and histogram-equalized images) are jointly fused, enabling cross-domain feature interaction.
This design effectively integrates the color and texture information provided by histogram equalization into the final enhanced result, thereby alleviating color distortion and detail loss.
Additionally, the fusion stage employs a PX-DenseUNet-based architecture, integrated with a learnable curve estimation module, to perform joint optimization of reflectance and illumination components, enabling natural and artifact-free enhancement.
2.1. Image decomposition network
Traditional Retinex theory-based methods decompose low-light images into three-channel reflectance components and a single-channel illumination component. When fusing the illumination and reflectance components, these methods typically expand the single-channel illumination component to three channels through simple replication, followed by pixel-wise multiplication with the reflectance component. However, due to the nonlinearity of color channels and the complexity of low-light image data, this expansion approach tends to cause local color loss during the enhancement process.
To overcome the decomposition challenges, an improved illumination modeling strategy is introduced, as shown in Figure 2. This strategy models illumination independently for each RGB channel, enabling the network to learn channel-specific illumination distributions under diverse lighting conditions. This achieves more accurate estimation of the three-channel illumination components, thereby obtaining more precise reflectance components and effectively enhancing the generalization ability of the model for low-light image decomposition. In the subsequent image fusion stage, this strategy achieves nonlinear fusion of reflectance and illumination components within the RGB three channels which can be formulated as: The improved illumination modeling strategy.

2.2. Image fusion network
2.2.1. Detail–low-frequency module (DLM)
To address noise characteristics and detail blurring during image fusion, inspired by PE-YOLO, 35 we propose a Detail–Low-Frequency Module (DLM) to jointly perform detail enhancement and noise suppression on the image reflectance component. The DLM module adopts a parallel architecture design, comprising two core sub-modules: the Detail Processing Module (DPM) for enhancing image texture details and the Low-Frequency Enhancement Module (LEF) for extracting low-frequency semantic information and suppressing high-frequency noise. This parallel design enhances the feature representation by jointly capturing high-frequency details and low-frequency structural cues, thereby improving the fidelity and robustness of the reconstructed images.
In the fusion network stage, the DPM module is utilized to enhance the image features derived from the decomposition network. As shown in Figure 3, the DPM adopts a dual-branch structure, including a context branch and an edge branch. The context branch captures global context information by establishing long-range dependencies, enabling global enhancement of image features. The edge branch calculates image gradients using Sobel operators in two different directions, effectively extracting edge information of image features and enhancing texture detail features of the image. DPM module architecture diagram.
The context branch employs a residual learning mechanism, to preserve abundant low-frequency information through skip connections. This branch contains two residual blocks. The first residual block increases the number of channels of the input feature from 3 to 32, while the second residual block reduces the number of channels from 32 back to 3. This bottleneck structure enables the model to aggregate contextual information while preserving low-frequency components through residual connections. Such design is beneficial for low-level vision tasks where both local detail and global structure must be retained. The calculation process of the context branch can be expressed as:

In the edge branch, the Sobel operator is used to compute discrete derivatives in horizontal and vertical directions, thereby approximating the image gradient for edge feature extraction. This branch applies Sobel operators in both the vertical and horizontal directions of the image, re-extracts edge information via convolutional filters, and employs residual connections to enhance information flow. This process is mathematically expressed as:

In addition to the DPM module, the fusion network also integrates the LEF module, specifically designed to extract low-frequency information from the reflectance component. The structural design of the LEF module is shown in Figure 4. For the input reflectance component LEF module architecture diagram.

2.2.2. Illumination component enhancement module
In the decomposition framework based on Retinex theory, the reflectance component carries the inherent structure and texture details of the image, while the illumination component determines the brightness distribution and overall atmosphere of the image. Effective enhancement of the illumination component is a key step in improving the visual quality of low-light images. Traditional encoder-decoder networks often introduce checkerboard artifacts during such tasks due to the non-divisibility issue in upsampling operations,
36
resulting in unnatural local patch-like effects in the enhanced image. To address this problem and achieve refined, adaptive adjustment of the illumination component, this study designs an illumination enhancement module based on learnable curve estimation, whose workflow is shown in Figure 5. Abandoning the traditional downsampling-upsampling paradigm, this module transforms the enhancement process into a pixel-level nonlinear curve mapping,
37
facilitating flexible and robust brightness improvement while maintaining smooth transitions across the entire image. Schematic diagram of curve estimation method.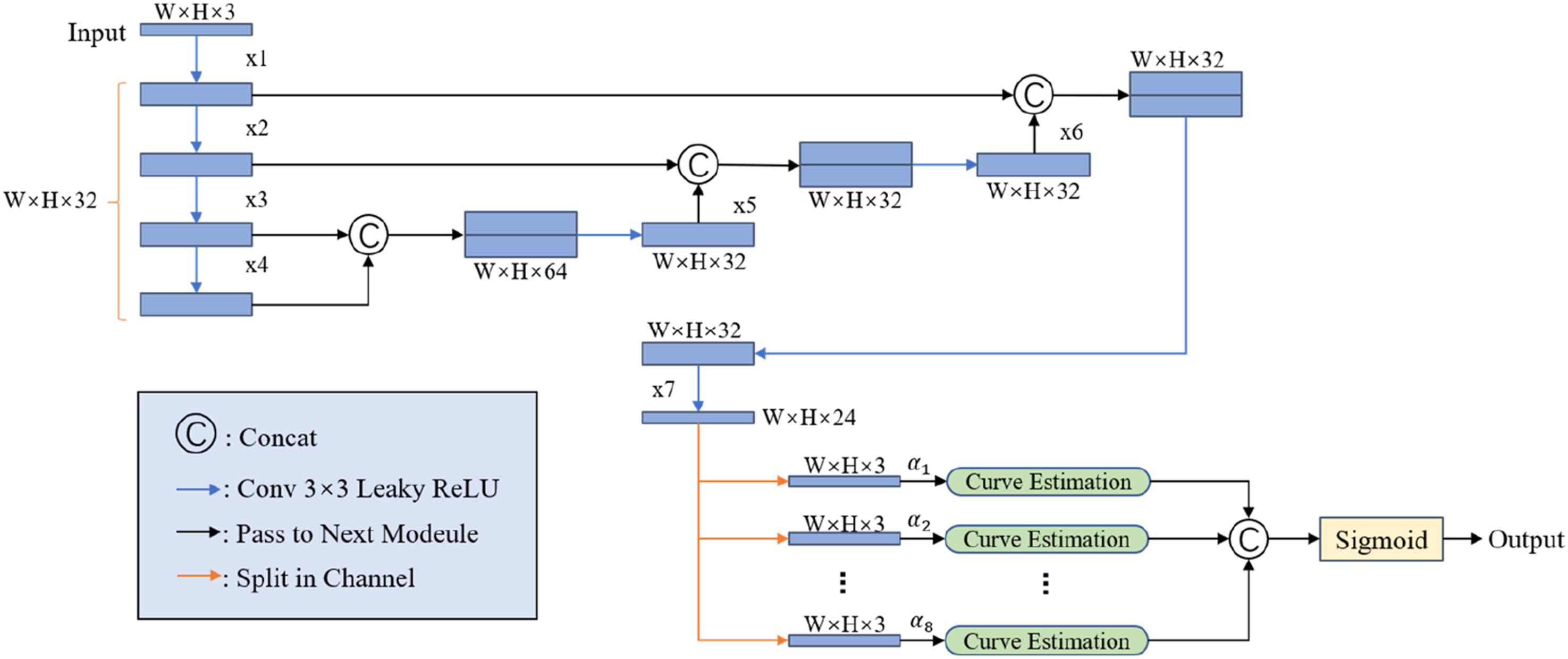
The illumination component image serves as the input to the curve estimation module. The module estimates eight sets of curve coefficients
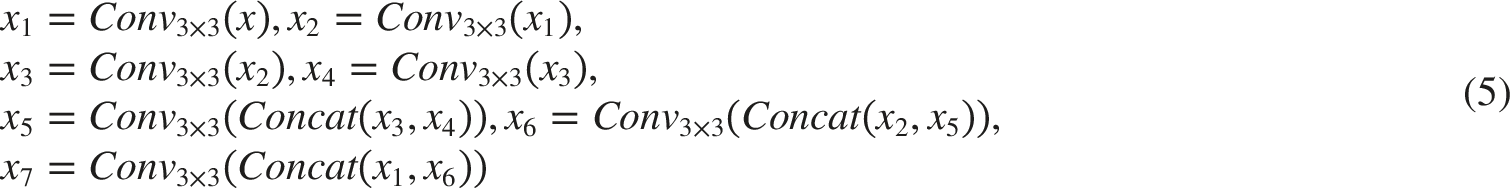
The feature map

2.3. Loss function design
To train the decomposition network more effectively, constraints must be imposed on the three-channel illumination components. During Retinex decomposition of the image, the decomposed reflectance component is expected to contain more of the image’s color information. Since the original input image can be obtained by pixel-wise multiplication of the illumination and reflectance components, enhancing color details in the output three-channel reflectance component implies reducing color details in the three-channel illumination component. Therefore, a grayscale regularization term is introduced to constrain the inter-channel consistency of illumination. The corresponding loss function is formulated as:

The loss function of the decomposition network, after incorporating the improved decomposition strategy, is the sum of the original decomposition network loss function and the illumination grayscale loss
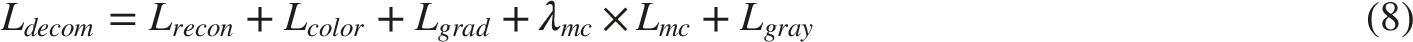
Quantitative evaluation of model performance under different values of

To fully utilize the reference normal-light image, the reflectance and illumination components of the low-light image are restored and enhanced using the reflectance and illumination components of the reference image. The improved loss function of the fusion network is:
2.4. Experiments
All experiments are implemented based on the open-source KinD++ framework, with modifications to both the decomposition and fusion networks. 26 The decomposition network adopted the improved DeSK-Unet, and the three-channel illumination decomposition strategy is used. The loss function of the decomposition network is the one proposed in Section 2.3. For the fusion of the reflectance image, illumination image, and histogram equalization map of the low-light image, an improved network is used, and the loss function of the fusion network is the one proposed in Section 2.3.
2.4.1. Experimental environment and parameter configuration
All experiments in this study were implemented based on the PyTorch deep learning framework and conducted under a unified hardware and software environment to ensure comparability and reproducibility of results. The specific configuration is as follows: Operating System: Ubuntu 20.04 GPU: NVIDIA GeForce RTX 3090 (24GB) CPU: AMD R9-5900X CUDA: 11.3 cuDNN: 8.2 Deep Learning Framework: PyTorch 1.12
For training hyperparameters, the basic settings of the KinD++ open-source framework are adopted, with fine-tuning performed for the tasks in this work. The specific parameters are as follows: Optimizer: Adam Initial Learning Rate: 0.0004 Learning Rate Scheduler: ExponentialLR (gamma = 0.997) Batch Size: 10 Training Epochs: 250 Image Patch Size: 256×256
2.4.2. Datasets and evaluation metrics
To evaluate the proposed method, experiments are conducted on widely used low-light image enhancement datasets, including both paired and unpaired data.
2.4.2.1. Paired training datasets
The LOL-v1 and LOL-v2-real datasets are used for supervised training. LOL-v1 contains 500 paired images, with 485 for training and 15 for testing. LOL-v2-real includes 689 real-captured image pairs with more complex illumination variations and realistic noise characteristics.
These datasets cover diverse indoor and outdoor scenes under varying lighting conditions, enabling a comprehensive evaluation of model robustness. All experiments follow the official dataset splits for fair comparison.
2.4.2.2. Unpaired testing datasets
To further assess generalization, additional experiments are conducted on unpaired real-world low-light datasets. These datasets include diverse scenes such as nighttime and low-illumination environments without ground-truth references.
Evaluation on these datasets relies on no-reference metrics and visual comparison, reflecting more practical application scenarios.
The following widely recognized image quality evaluation metrics are used for quantitative analysis of the enhancement results: Peak Signal-to-Noise Ratio (PSNR): Measures the pixel-level fidelity between the enhanced image and the reference normal-light image, and higher values indicate better performance. Structural Similarity Index Measure (SSIM): Evaluates the similarity in structural information between the enhanced image and the reference image, whose values range from [0, 1] and higher values indicating better similarity. Natural Image Quality Evaluator (NIQE): A no-reference image quality evaluation metric; lower values indicate higher naturalness and better visual quality of the image. Mean Average Precision (mAP): Evaluated using the DETR detector on the ExDark dataset to measure the practical value of the enhanced images in object detection tasks.
3. Results and analysis
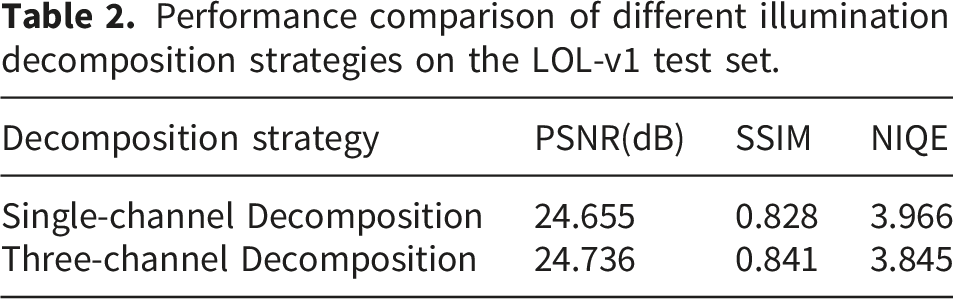
3.1. Validation of the effectiveness of the three-channel illumination decomposition strategy
Performance comparison of different illumination decomposition strategies on the LOL-v1 test set.

Qualitative comparison corresponding to Table 2. The three-channel illumination decomposition strategy effectively reduces color distortion and improves color fidelity.
The results show that after adopting the three-channel illumination decomposition strategy, all key metrics are improved. Compared with the single-channel version, the three-channel strategy yields moderate gains in PSNR (+0.081 dB) and SSIM (+0.013), indicating that the three-channel modeling leads to more accurate restoration of image structure and details. At the same time, the NIQE value decreased by 0.121, indicating that the enhanced image has a higher degree of naturalness. These results indicate that the three-channel strategy provides more accurate illumination estimation.
3.2. Comprehensive ablation study
To thoroughly evaluate the effectiveness of each component in the proposed framework, we conduct a comprehensive ablation study covering three aspects: (1) the decomposition network design, (2) the fusion network modules, and (3) the proposed loss function.
All experiments are conducted on the LOL-v1 test set under the same training configuration to ensure fairness.
3.2.1. Ablation study on the decomposition network
To validate the contribution of the proposed Multi-Scale Deformable Feature Fusion with Dual-Layer Attention (MSDFF) module and its internal components, we perform a progressive ablation study starting from a baseline U-Net architecture.
The evaluated components include: deformable convolution dual-layer attention mechanism selective-kernel (SK) fusion the overall MSDFF module
Ablation study on the decomposition network.

First, the introduction of deformable convolution leads to a noticeable improvement across all metrics. This gain can be attributed to its ability to adaptively adjust spatial sampling locations, allowing the network to better capture irregular structures and non-uniform illumination patterns commonly observed in low-light images. Compared with standard convolution, this flexibility is particularly beneficial for Retinex decomposition, where accurate separation of illumination and reflectance depends heavily on local structural fidelity.
Second, the integration of the dual-layer attention mechanism further enhances performance, especially in terms of SSIM. This indicates that attention mechanisms play a critical role in selectively emphasizing informative spatial regions and feature channels while suppressing irrelevant or noisy responses. In low-light conditions, where signal-to-noise ratio is inherently low, such adaptive feature reweighting significantly improves structural consistency and detail preservation.
Third, the inclusion of selective-kernel (SK) fusion introduces multi-scale adaptability into the network. By dynamically aggregating features from different receptive fields, the model becomes more capable of handling diverse illumination distributions and object scales. This results in improved detail reconstruction and a reduction in perceptual artifacts, as reflected by the steady decrease in NIQE.
Finally, when all components are integrated into the MSDFF module, the model achieves the best overall performance. This demonstrates that the combination of deformable sampling, attention-based feature selection, and multi-scale fusion forms a synergistic architecture. Rather than acting as independent enhancements, these components jointly improve the network’s ability to perform accurate and robust Retinex decomposition under challenging lighting conditions.
3.2.2. Ablation experiment of the fusion network modules
To evaluate the effectiveness of the proposed fusion-stage components, we analyze the contributions of the Detail–Low-Frequency Module (DLM) and the curve estimation module.
Ablation study on fusion modules.

When the DLM module is introduced independently, the model shows a clear improvement in SSIM and a reduction in NIQE, while the gain in PSNR remains relatively modest. This suggests that the primary contribution of the DLM module lies in enhancing structural fidelity and suppressing noise rather than directly increasing pixel-wise accuracy. This behavior is consistent with its architectural design: the detail processing branch strengthens high-frequency texture information, while the low-frequency enhancement branch captures global semantic structures and filters out noise. The parallel design enables the model to balance detail enhancement and denoising, which is crucial for perceptual quality.
In contrast, the curve estimation module significantly improves PSNR when applied alone, indicating its effectiveness in adjusting global illumination and restoring brightness. However, this improvement is accompanied by a slight degradation in NIQE, suggesting that brightness enhancement without proper structural guidance may amplify noise or introduce unnatural artifacts. This observation aligns with the nature of pixel-wise nonlinear mapping, which enhances intensity but lacks explicit constraints on structural consistency.
When both modules are combined, the model achieves the best performance across all metrics. This confirms that the two modules address complementary aspects of the enhancement problem: the DLM module ensures structural integrity and noise suppression, while the curve estimation module provides flexible and smooth illumination adjustment. Their integration enables the model to simultaneously achieve accurate brightness restoration and high perceptual quality, avoiding the trade-offs observed when each module is used independently.
3.2.3. Ablation study on the loss function
To validate the effectiveness of the proposed grayscale regularization loss Equation (7), we compare the model performance with and without this constraint.
Ablation study on grayscale regularization loss.
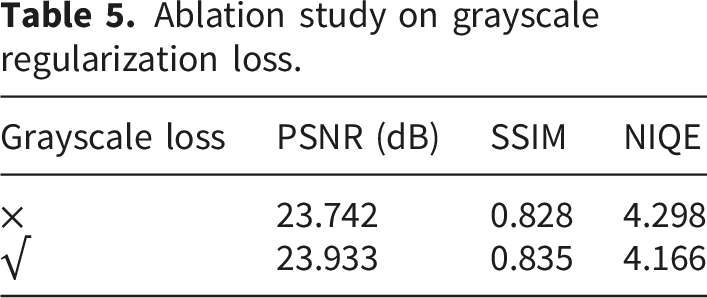
Specifically, introducing the grayscale constraint leads to consistent improvements in SSIM and a noticeable reduction in NIQE, while also yielding a moderate gain in PSNR. This indicates that the loss function not only stabilizes the decomposition process but also enhances the visual naturalness of the reconstructed images.
From a mechanistic perspective, the grayscale regularization enforces consistency among the RGB illumination channels, effectively constraining the illumination component to exhibit low inter-channel variance. This encourages the model to encode color information primarily within the reflectance component, which is more appropriate under the Retinex formulation. As a result, color distortion artifacts—commonly observed in single-channel or unconstrained illumination models—are significantly reduced.
Moreover, this constraint improves training stability by reducing the solution space of the decomposition problem. Without such regularization, the model may produce ambiguous decompositions where color information is inconsistently distributed between illumination and reflectance. By enforcing a physically meaningful prior, the grayscale loss leads to more reliable and interpretable decomposition results, ultimately improving downstream enhancement quality.
3.2.4. Overall component analysis
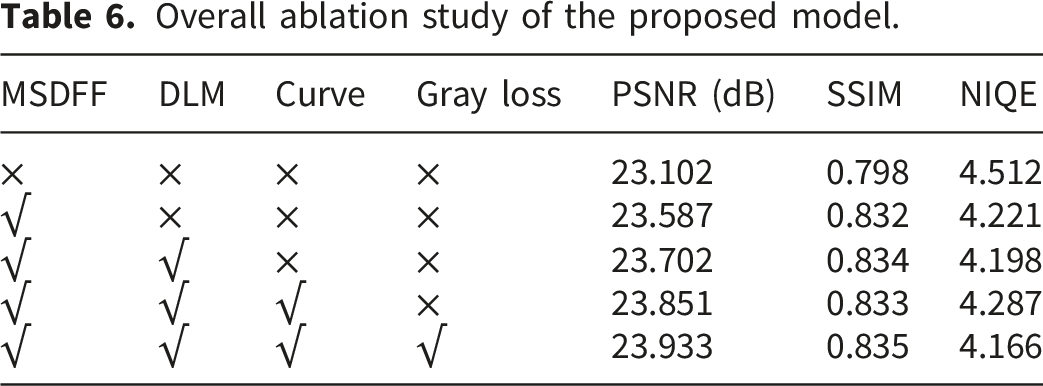
To further analyze the cumulative contribution of different components, we perform a combined ablation experiment by progressively integrating the major modules.
Overall ablation study of the proposed model.

Visual comparison of the progressive integration of model components. From (c) to (g), the results demonstrate the incremental improvements in detail preservation, brightness enhancement, noise suppression, and color consistency.
Starting from the baseline, the introduction of the MSDFF module yields a substantial improvement across all metrics, confirming that enhanced feature extraction is fundamental to accurate Retinex decomposition. By improving the quality of the initial decomposition, subsequent enhancement stages are provided with more reliable inputs.
Adding the DLM module further improves SSIM and reduces NIQE, highlighting its effectiveness in refining structural details and suppressing noise during the fusion process. This indicates that even with a strong decomposition backbone, dedicated mechanisms for detail enhancement remain essential.
When the curve estimation module is incorporated, PSNR increases further due to improved brightness and contrast. However, a slight fluctuation in NIQE is observed when the grayscale constraint is not applied, suggesting that illumination enhancement alone may introduce minor perceptual inconsistencies.
Finally, with the inclusion of the grayscale regularization loss, the model achieves the best performance across all metrics. This confirms that enforcing illumination consistency is crucial for stabilizing the overall pipeline and improving color fidelity.
Overall, the progressive improvements observed in Table 6 demonstrate that each component contributes to a specific aspect of the enhancement task, including feature extraction, structural refinement, illumination adjustment, and color consistency. More importantly, these components operate in a highly complementary manner, forming a coherent and well-balanced framework rather than a simple aggregation of independent modules.
3.3. Comprehensive performance comparison with advanced algorithms
Performance comparison of paired datasets. (LOL-v1 and LOL-v2-real).

As can be seen from the results in Table 7, on the two mainstream paired datasets, the proposed algorithm in this work achieves the best performance in the PSNR and NIQE metrics, and also has strong competitiveness in the SSIM metric. Especially on the more challenging LOL-v2-real dataset, compared with other advanced algorithms, the proposed method further improves the PSNR by more than 4.767 dB and the SSIM by more than 0.011, significantly widening the performance gap and demonstrating the effectiveness of the multi-channel decomposition and enhancement strategy. Figure 8 shows the comparison of low-light image enhancement effects of different algorithms on the LOL-v1 dataset. It can be seen from the comparison figure that compared with other algorithms, the proposed algorithm in this work has less color loss and richer details when enhancing low-light images. Figure 9 presents a visual comparison of the low-light image enhancement effects of different algorithms on the LOL-v2-real dataset. It can be seen from the figure that RetinexNet, RRM and EnlightenGAN tend to produce unnatural images when enhancing low-light images. The enhancement results of the KinD++ and Diff-Retinex algorithms have the problem of insufficient image brightness. The enhancement result of the R2RNet algorithm has obvious color loss, and the enhancement result of the URetinexNet algorithm on the LOL-v2-real dataset shows good color and detail performance, but there is still obvious noise. Comparison of low-light image enhancement effects by different algorithms on the LOLv1 dataset. Comparison chart of low-light image enhancement effects by different algorithms on the LOLv2-real dataset.

To evaluate the practicality of the proposed method, we compare its computational complexity with representative approaches in terms of FLOPs and parameter count, as shown in Table 7.
The proposed MC-LLE achieves superior enhancement performance while maintaining relatively low computational cost. Compared with high-complexity methods, it requires significantly fewer FLOPs and parameters, while delivering better reconstruction quality than lightweight models.
These results indicate that the performance gains are achieved through efficient architectural design rather than increased model size. Therefore, the proposed method achieves a favorable performance–efficiency trade-off, making it suitable for real-world applications.
Comparison of NIQE values of different algorithms on unpaired datasets.

The comparison results of the algorithms on the MEF and VV datasets are shown in Figures 10 and 11. The enhancement result of RetinexNet has relatively serious color distortion and noise, while the enhancement results of the KinD++, RRM, and EnlightenGAN algorithms have obvious noise. Comparison of algorithm result images on the MEF dataset. Comparison of algorithm result images on the VV dataset.

3.4. Application validation in downstream visual tasks
To evaluate the practical value of the proposed method, we conduct object detection experiments on the full ExDark dataset, which contains 7,363 low-light images across 12 categories. To ensure statistical reliability, all experiments are repeated three times, and the mean ± standard deviation is reported.
Object detection results on the ExDark dataset.

Per-category analysis reveals that performance improvements are category-dependent. Objects with strong structural features (e.g., car, bus) benefit more, while texture-sensitive categories (e.g., bicycle) show smaller gains. This suggests that enhancement artifacts, such as over-smoothing or contrast distortion, may negatively affect certain categories.
Overall, the proposed method improves both visual quality and downstream detection performance, while maintaining stable generalization across detectors.
According to the test results, all enhancement algorithms can effectively improve the object detection performance under low-light conditions. Among them, the proposed multi-channel illumination enhancement algorithm in this work achieves the highest mAP (0.193), which represents a 67.8% performance improvement compared with directly using the original low-light images. These findings indicate that the enhanced images generated by the proposed algorithm in this work not only possess higher visual quality but also provide higher-quality and more discriminative visual information for downstream advanced computer vision tasks, thus having important practical application significance.
4. Discussion
This work presents a two-stage Retinex-based framework integrating three-channel illumination decomposition with multi-scale fusion and dual-layer attention. The method further employs a parallel Detail–Low-Frequency Module (DLM) and a learnable curve-based illumination adjustment in the fusion stage. Collectively, these design choices seek to improve brightness restoration, color fidelity, and detail preservation under challenging low-light conditions.
Mechanistically, modeling illumination per RGB channel allows the network to capture non-uniform and color-dependent lighting effects that are not well represented by a single-channel approximation. Similarly, the multi-scale dynamic feature fusion and dual-attention modules facilitate complementary aggregation of semantic and low-level cues: attention weighting emphasizes informative spatial–channel locations, while deformable convolutions enable adaptive receptive fields for local structure recovery. In the fusion stage, the parallel detail and low-frequency branches decouple texture enhancement from denoising, and the learnable curve mapping enforces smooth, artifact-free luminance adjustments at the pixel level.
Empirically, the combined architecture yields consistent gains in both fidelity and perceptual metrics. For instance, adopting the three-channel decomposition improved PSNR and SSIM on the LOL-v1 test set (+0.081 dB and +0.013, respectively) and reduced NIQE. Moreover, applying the enhanced images to a downstream DETR and YOLOv5 detector resulted in a substantive mAP increase on ExDark, indicating the practical benefit for high-level vision tasks.
While the proposed method demonstrates strong performance across various benchmarks, it is important to further analyze its limitations under more challenging conditions.
In extremely low-light scenarios, where the signal-to-noise ratio is severely degraded, the model may still exhibit slight noise amplification and limited structural recovery. This is mainly due to insufficient reliable information in the input, which makes accurate illumination–reflectance decomposition more difficult. As a result, noise may be amplified along with useful signals, and fine structural details may not be fully preserved.
In addition, although the proposed modules improve robustness in most cases, their effectiveness may decrease under highly uneven illumination or severely underexposed regions. The current model also introduces moderate computational overhead compared to lightweight methods. Future work will focus on improving robustness under extreme conditions while further optimizing model efficiency.
5. Conclusion
To address the challenges of insufficient brightness, detail degradation, color distortion, and noise in low-light image enhancement, this paper proposes a Retinex-based framework that integrates multi-channel illumination decomposition with a two-stage fusion strategy. The method models illumination independently across RGB channels and combines decomposition and fusion networks to achieve robust enhancement under complex lighting conditions.
The core contributions of this work lie in three aspects. First, a three-channel illumination modeling strategy is introduced to overcome the limitations of traditional single-channel assumptions, significantly improving color fidelity. Second, a multi-scale feature extraction mechanism incorporating deformable convolution and dual-layer attention is designed to enhance decomposition accuracy. Third, a fusion framework integrating a Detail–Low-Frequency Module (DLM) and a learnable curve estimation module is developed to jointly optimize structural details and illumination adjustment.
Extensive experiments on both paired and unpaired datasets demonstrate that the proposed method consistently outperforms existing approaches in terms of PSNR, SSIM, and NIQE. In addition, evaluations on the ExDark dataset show that the enhanced images substantially improve object detection performance, achieving a 67.8% increase in mAP compared with original low-light inputs, which highlights the practical value of the proposed method for downstream vision tasks.
Despite these promising results, the proposed method still has limitations in extremely low-light scenarios and introduces moderate computational overhead. Future work will focus on improving robustness under severe illumination degradation, reducing model complexity through lightweight design, and exploring joint optimization strategies that better align low-level enhancement with high-level vision tasks.
Footnotes
Ethical considerations
This study did not involve human participants, animal experiments, or any biological samples requiring ethical review.
Author contributions
Zhiwen Wang conducted the programming tasks, performed primary data analysis. Yulong Qiao supervised the overall study, and critically reviewed and refined the manuscript for submission. Yan Cang contributed to formal analysis, investigation, and drafted the initial manuscript. All authors contributed to the research and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All datasets used in this study are publicly available and can be accessed as follows: • LOL-v1 and LOL-v2-real datasets: These paired low-light/normal-light image datasets are available at https://www.github.com/albrateanu/LYT-Net/tree/main/PyTorch. These datasets were used for supervised training of the proposed model. • LIME, NPE, MEF, and VV datasets: These unpaired datasets for generalization testing are available at https://www.github.com/weichen582/RetinexNet. • ExDark dataset: This low-light object detection dataset is available at ![]() . It was used to evaluate the impact of image enhancement on downstream object detection tasks. All datasets were accessed and used in accordance with their respective terms of use. No new datasets were generated during the current study.
. It was used to evaluate the impact of image enhancement on downstream object detection tasks. All datasets were accessed and used in accordance with their respective terms of use. No new datasets were generated during the current study.