
Abstract
Objective
The purpose of this study aims to develop a novel deep learning framework for exploring its application effect in the transition from non-contrast computed tomography (NCCT) to contrast-enhanced computed tomography (CECT) in breast cancer radiotherapy.
Materials and methods
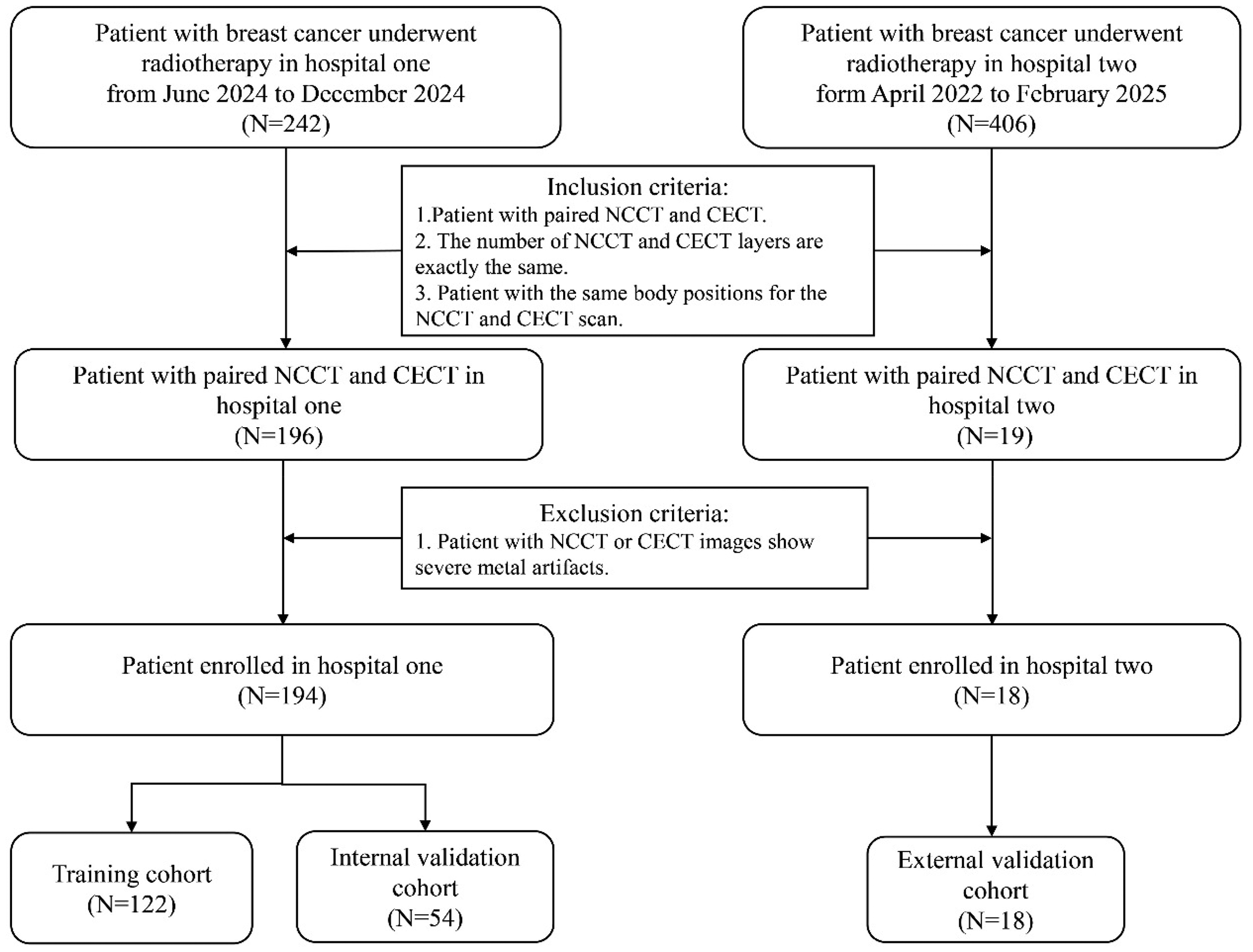
A total of 194 patients with a pair of NCCT and CECT including 176 patients from hospital one and 18 patients from hospital two were enrolled in this study which were divided into training cohort (122 patients), internal testing cohort (54 patients) and external validation cohort (18 patients). Pix2Pix, CycleGAN, RegGAN and SynDiff were used to develop image-to-image translation in this study. PSNR, SSIM and NMAE were applied to evaluate the performance of automatic models by comparing them with original in the three cohorts.
Results
The SynDiff models achieved the highest PSNR values of 28.56 and 26.97 dB, the highest SSIM value of 0.943 and 0.940, the lowest NMAE value of 0.011 and 0.012 compared with Pix2Pix, CycleGan and RegGAN in the internal validation cohorts and external validation cohorts, respectively. The p-values of the Wilcoxon signed-rank test for the SynDiff model compared with the other three models in PSNR and NMAE were all less than 0.05 in the internal and external validation cohorts. The p-values of the Wilcoxon signed-rank test for the SynDiff model compared with the other three models in PSNR and NMAE were all less than 0.05 in the internal and external validation cohorts. The p-values of the Wilcoxon signed-rank test for the SynDiff model compared with Pix2Pix and CycleGAN in SSIM were all less than 0.05 and compared with RegGAN in SSIM were 0.091 in the internal validation cohorts and all less than 0.05 in the external cohorts.
Conclusion
SynDiff is a promising method to explore its application effect in the transition from NCCT to CECT in the breast-cancer radiotherapy.
Introduction
Breast cancer remains a significant global public health challenge, demonstrating a persistent rise in incidence with an annual increase of 1% in recent years.1,2 Radiotherapy become an important component of the multidisciplinary breast cancer management and it has been continuously developed and improved at all stages of breast cancer. 3 However, precision radiotherapy in breast cancer still faces critical challenges that conventional non-contrast computed tomography (NCCT) struggles to clearly delineate tumor micro-invasive boundaries and subclinical metastases due to the lack of vascular enhancement, leading to target delineation errors.4,5 Compared with NCCT, enhanced computed tomography (CECT) can effectively distinguish tumor neovascularization from the normal vascular system through dynamic contrast imaging, and increase its specificity by 12%. 6 Contrast agents highlight vascularized tissues, improving differentiation between tumor margins, postoperative changes and lymph nodes. This is especially critical for locating residual disease post-lumpectomy, detecting subclinical lesions or involved lymph nodes and defining boundaries in complex anatomy. The necessity for both scans arises from the trade-off between dosimetric accuracy (NCCT) and anatomic precision (CECT). Nevertheless, widespread clinical implementation of CECT faces some barriers. Compared with conventional X-ray examinations, the radiation dose of a single CT scan is significantly higher. For breast cancer patients who require multiple imaging evaluations, repeated CT examinations may result in a cumulative dose reaching the clinical concern threshold, thereby increasing the risk of secondary cancer. 7
In recent years, advances in deep learning have revolutionized medical image synthesis, offering unprecedented capabilities in generating high-fidelity anatomical and functional images. Generative adversarial networks (GANs) and variational autoencoders (VAEs) have demonstrated remarkable success in synthesizing realistic CT, MRI, and PET images from limited or multimodal inputs. 8 However, the existing generative models still exhibit significant limitations that traditional GANs may fabricate or remove critical medical features when matching target domain distributions. Studies have shown that when target domain data distributions are biased, generated images systematically add or eliminate disease features. 9 In addition, traditional diffusion models require thousands of iterative sampling steps, resulting in prolonged computation time that fails to meet real-time demands of radiotherapy planning systems. 10
Recent computer vision studies have adopted diffusion models based on explicit likelihood characterization and a gradual sampling process to improve sample fidelity in unconditional generative modeling tasks.11–13 However, the potential of diffusion methods in medical image translation remains largely unexplored, partly owing to the computational burden of image sampling and difficulties in unpaired training of regular diffusion models. 14 Moreover, most of the image synthesis research has employed the cycle-consistent generative adversarial network (CycleGAN) which was used to converting between two image domains, by transferring the image style in recent years. 15 Therefore, this study aims to develop a novel deep learning framework based on CycleGAN for exploring its application effect in the transition from NCCT to CECT in breast cancer.
Materials and methods
Patients
In this study, we retrospectively reviewed the medical records of breast cancer patients who underwent postoperative intensity-modulated radiotherapy (IMRT) and volumetric modulated arc therapy (VMAT) at hospital one from June 2024 to December 2024 and hospital two form April 2022 to February 2025. The inclusion criteria in the study were: (1) Patient with paired NCCT and CECT, (2) The number of NCCT and CECT layers are exactly the same and (3) Patient with the same body positions for the NCCT and CECT scan. The exclusion criteria in the study were patient with NCCT or CECT images show severe metal artifacts. A total of 194 patients were enrolled in this study. Among them, 176 patients from the Wenzhou Medical University First Affiliated Hospital and 18 patients from the Ganzhou Cancer Hospital: 122 patients (70%) from hospital one for model training, 54 patients (30%) from the Wenzhou Medical University First Affiliated Hospital for internal testing, and 18 patients from the Ganzhou Cancer Hospital for external validation. Figure 1 illustrates the data collection and processing pipeline of our project. This study has been communicated with the review committee of this institution and has obtained their exemption approval.
The overview of data acquisition and processing.
Image acquisition and preprocessing
All patients underwent CT simulation with head-first supine positioning, scanning from the supraclavicular fossa (C3 vertebral level) to 5 cm below the inframammary fold, ensuring complete inclusion of bilateral breast tissue, internal mammary nodes, and axillary nodal regions. CT images were acquired on two radiotherapy-planning scanners: a Siemens SOMATOM (32 rows, 920 detector elements per row, 29440 total channels, 60 cm true scan field of FOV) and a Philips Brilliance Big Bore (16 rows, 52 detectors × 256 channels each, 13056 total channels, 60 cm true scan field of FOV). All examinations used 120 kV with automatic tube-current modulation; both non-contrast and contrast-enhanced series were reconstructed at 5 mm slice thickness in a 512 × 512 matrix using a soft-tissue kernel. Neither of these platforms employs a dedicated image noise reduction algorithm. Intravenous contrast was administered during the CT scan to enhance the visibility of target volumes. The contrast medium used was iodine-based, with a concentration of 300 mg/mL, an injection rate of 2.5 to 3.0 mL/s in hospital one and an injection rate of 2.0 mL/s in hospital two.
CT values from NCCT were clipped to the soft-tissue window [−40,400] HU to remove irrelevant air/background voxels and high-density artefacts. All images were resized to 256 × 256 pixels. Training was performed with the Adam optimizer. The initial learning rate was set to 0.0001 and the models were trained for a maximum of 100 epochs. A mini-batch size of 16 slices was employed. The model was implemented using Pytorch on an NVIDIA L20 GPU with 24 GB of memory. Training was stopped when the loss no longer decreased significantly. The final model was selected based on the best performance on the validation set. The images of all the patients in this study have been de-identified. The reporting of this study conforms to CLAIM 2024 guidelines. 16
Model establishment
Four models included Pix2Pix,
17
CycleGAN, RegGAN
18
and SynDiff
19
were used to develop image-to-image translation in this study. Pix2Pix and CycleGAN were established as the baseline models. RegGAN views misaligned target images as noisy labels, treating the problem as supervised learning with noisy labels. SynDiff is an innovative adversarial diffusion model designed for efficient and high-fidelity medical image translation across modalities. SynDiff's cycle-consistent architecture combines diffusive and non-diffusive modules for unsupervised training. The non-diffusive module estimates source images paired with corresponding target images in the training set, offering high-quality anatomical guidance for the diffusive module. Then, the diffusive module synthesizes target images through the conditional diffusion process. This combination allows SynDiff to learn effectively from unpaired training data, overcoming the limitations of paired-data requirements in traditional supervised learning approaches. Therefore, the SynDiff network is also used for the synthesis of CECT images of breast cancer. Figure 2 shows the network architectures of four models. For unsupervised learning, SynDiff leverages a cycle-consistent architecture that bilaterally translates between two modalities (A, B). For synthesizing a target image

Overview of four frameworks: (a) Pix2Pix, (b) RegGAN, (c) CycleGAN, and (d) SynDiff.
For SynDiff model, Ozbey et al.
19
adopts a hybrid loss that couples adversarial learning with cycle consistency. Instead of the conventional denoising loss used in vanilla diffusion models, the reverse-diffusion steps are driven by an adversarial projector: a conditional discriminator Dθ is trained to distinguish between actual denoised samples Xt−k and synthetic ones
Model evaluation
All models were trained as slice-wise two-dimensional models. The dataset comprised 16574 slices for training, 7372 slices for internal testing, and 2091 slices for external test. Peak Signal-to-Noise Ratio (PSNR),
20
Structural Similarity Index (SSIM)21,22 and Normalized Mean Absolute Error (NMAE) were applied to evaluated the performance of automatic models by comparing them with original in the test data sets. PSNR is an important indicator for evaluating image or signal quality and mainly used to measure the similarity between the generated image and the real image. The higher the value of PSNR, the higher the similarity between the two images, which reflects the superior quality of the image. The PSNR is defined as:

In equation (1), is the peak signal, MSE(x, y) is the MSE of the image,
SSIM is an indicator used to measure the similarity between two images, mainly from three aspects: brightness, contrast and structure. The higher the value, the lower the distortion of the image and the more similar the two images are. SSIM value of 1 indicates a perfect concordance between two images.

In equation (2), μx, μy, σx, and σy are the mean value and standard deviation of the real image x and the image to be evaluated y, respectively.
NMAE is a widely-used metric for assessing image quality, quantifying the discrepancy between a generated image and its corresponding real image. It is calculated by taking the absolute differences between the true pixel values and the predicted pixel values, summing these differences, and then averaging them. A lower NMAE value indicates a higher degree of similarity between the generated and real images, thereby reflecting the superior performance of the image generation model:

Where x is the real image, y is the image to be estimated and n is the size of the image to be estimated.
Statistical analysis
All statistical analyses were performed using Python (version 3.10.13; https:// www. python. org/) and SPSS Statistics 27. The differences between the pseudo-enhanced CT images and the ground-truth enhanced CT images, and between models were all assessed using the Wilcoxon signed-rank test, as the comparisons were performed on paired observations.
Results
The patients were divided into three cohorts: 122 patients (70%) from hospital one for model training, 54 patients (30%) from hospital one for internal validation, and 18 patients from hospital two for external validation. Figure 1 illustrates the data collection and processing pipeline of our project.
Quantitative comparisons of the Pix2Pix, CycleGAN, RegGAN and SynDiff models are summarised in Table 1 (internal validation) and Table 2 (external validation). Table 1 shown that quantitative comparisons of the Pix2Pix, CycleGAN, RegGAN and SynDiff models in the internal validation cohort. In Pix2Pix, CycleGan and Reg models, the PSNR value were reached 27.56 dB vs. 28.39 dB vs. 28.51 dB in the internal validation cohorts, respectively. The SSIM value of three models were reached 0.932 vs. 0.936 vs. 0.937 in the internal validation cohorts, respectively. The NMAE value of three models was reached 0.012 vs. 0.011 vs. 0.011 in the internal validation cohorts, respectively. The SynDiff models achieved the highest PSNR values of 28.56 dB, the highest SSIM value of 0.943, the lowest NMAE value of 0.011 compared with other three models in the internal validation cohorts, respectively. The p-values of the Wilcoxon signed-rank test for the SynDiff model compared with the other three models in PSNR and NMAE were all less than 0.05 in the internal validation cohorts. The p-values of the Wilcoxon signed-rank test for the SynDiff model compared with Pix2Pix and CycleGAN in SSIM were all less than 0.05 and compared with RegGAN in SSIM were 0.091 in the internal validation cohorts. Figure 3 lists a visual comparison of the four models in internal validation cohorts.

Example breast CT scans from the study in internal test. Compared to the Pix2Pix, CycleGAN, RegGAN, and SynDiff models. Each column represents one model output, except the first column and the second, which are the Non-contrast enhance CT and contrast enhance CT (CECT).
Quantitative analysis of predictions from the trained models on internal validation.

Quantitative analysis of predictions from the trained models on external validation.

Table 2 shown that quantitative comparisons of the Pix2Pix, CycleGAN, RegGAN and SynDiff models in the external validation cohort. In Pix2Pix, CycleGan and Reg models, the PSNR value were reached 25.68 dB vs. 26.48 dB vs. 26.53 dB in the external validation cohorts, respectively. The SSIM value of three models was reached 0.924 vs. 0.927 vs. 0.928 in the external validation cohorts, respectively. The NMAE value of three models was reached 0.014 versus 0.013 versus 0.013 in the external validation cohorts, respectively. The SynDiff models achieved the highest PSNR values of 26.97 dB, the highest SSIM value of 0.940, the lowest NMAE value of 0.012 compared with other three models in the external validation cohorts, respectively. The p-values of the Wilcoxon signed-rank test for the SynDiff model compared with the other three models in PSNR, SSIM and NMAE were all less than 0.05 in the external validation cohorts. Figure 4 lists a visual comparison of the four models in external validation cohorts. Compared with Pix2Pix, CycleGAN and RegGAN, SynDiff is better able to accurately depict the size and shape of blood vessels and lymph nodes.
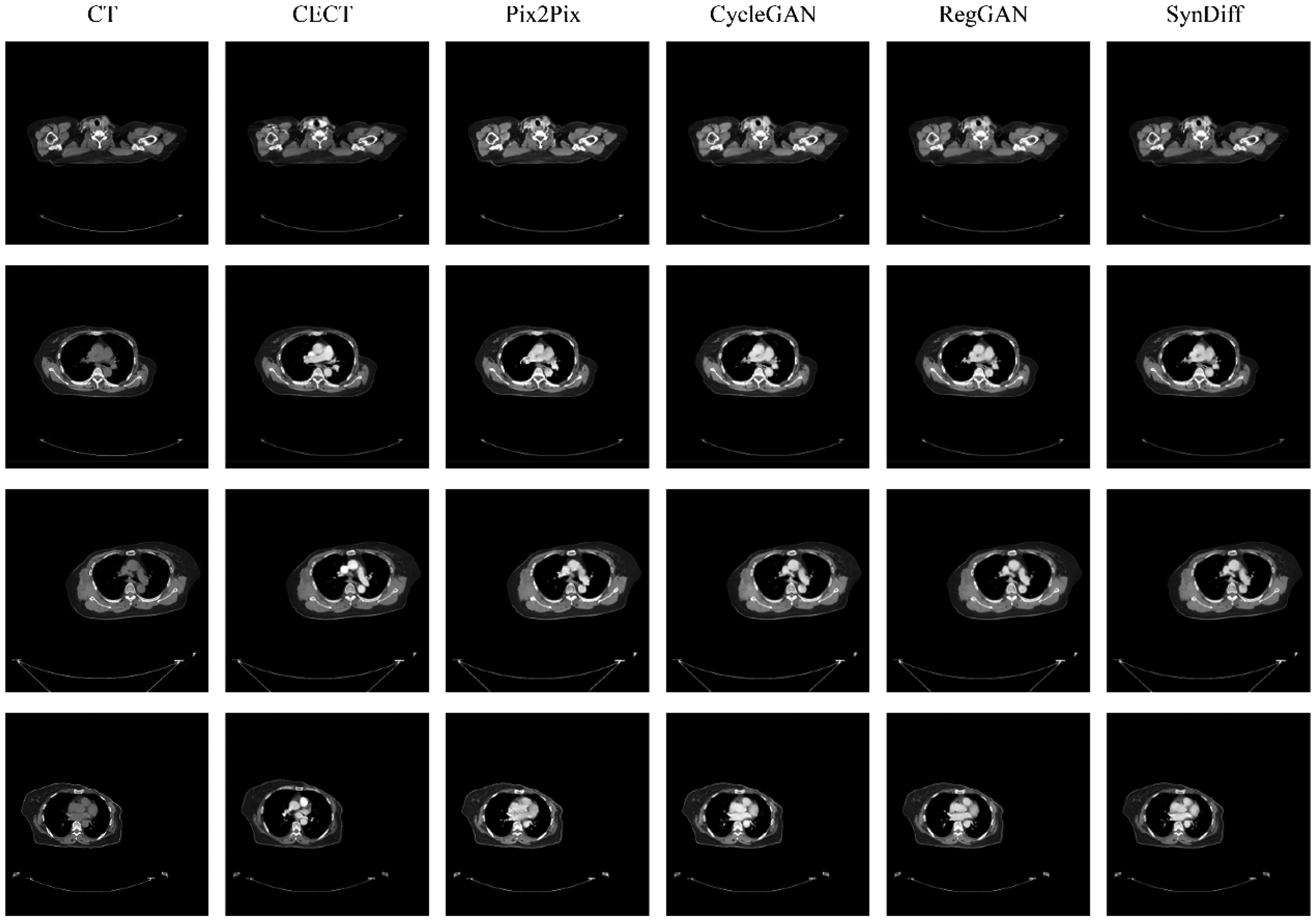
Example breast CT scans from the study in external test. Compared to the Pix2Pix, CycleGAN, RegGAN, and SynDiff models. Each column represents one model output, except the first column and the second, which are the Non-contrast enhance CT and contrast enhance CT (CECT).
Qualitatively, we observed that the self-attention mechanism helps to enhance the overall performance of the model, particularly in preserving finer details and improving image reconstruction quality. For example, the NMAE is significantly reduced from 0.012, indicating a more accurate reconstruction. Similarly, the PSNR is 26.94 dB, suggesting better image quality with less noise. The SSIM also shows a noticeable improvement is 0.94, reflecting that the images generated are more structurally similar to the ground truth. The results indicate that the SynDiff model's capability to focus on important features, leading to better overall image quality across all evaluated metrics.
Discussion
In this study, SynDiff model exhibited the highest PSNR of 26.97 dB, SSIM of 0.940, and lowest NMAE of 0.012 in external validation cohorts. The results of Wilcoxon signed-rank test show that the differences between the SynDiff model and other models are mostly significant. There was no significant difference between the SynDiff model and the RegGAN model with a p-value of 0.091 in the internal validation cohorts. However, the difference was significant in the external validation. This might be due to the insufficient amount of internal data. The results show that the Syndiff model can better maintain the integrity of the structure and it can also achieve high image quality while reducing the reconstruction error.
To our knowledge, SynDiff network is the first successful example of unsupervised translation in NCCT to CECT based on diffusion modeling. Moreover, Pix2Pix、CycleGAN and RegGAN networks was also developed as baseline models in this study. Pix2Pix requires well-aligned paired images, which are not always available. 17 Cycle-consistency-based models, such as CycleGAN can handle misaligned images but are prone to producing multiple solutions, making them sensitive to perturbation and thus not ideal for high-accuracy medical image-to-image translation tasks. The CycleGAN, first introduced by Zhu et al., 23 features two generators and dual discriminators. This structure enables CycleGAN to convert images between domains without paired-dataset supervision.24–29
In this study, CycleGAN improves significantly over Pix2Pix, particularly in terms of PSNR, demonstrating its ability to better preserve structural and visual quality through unpaired image-to-image translation. RegGAN performed better, with a PSNR of 28.51 dB and SSIM of 0.937. Our Diffusion model outperform these baselines. The problem with NMAE and PSNR is that when calculating the differences in pixels at each location, their results are only related to the two-pixel values at the specific position rather than the pixels at any other location. That is to say, these two methods of calculating only treat the image as isolated pixels and ignore some of the visual features contained in the image content, especially the local structural information of the image. To a large extent, image quality is a subjective feeling in which the structural information significantly impacts people's subjective feelings. SSIM was proposed to solve the problem of NMAE and PSNR mentioned above, and when SSIM calculates the differences between two images at each position, instead of taking one pixel from each of the two images at that location, one pixel from each area is taken. Our SynDiff performed well, achieving an SSIM value of 0.943 and 0.940.
This study still has certain limitations. Firstly, our dataset is relatively small, and the external validation only included 18 patients. Therefore, we will increase the data volume to enhance the stability of the model in the future. Second, the network in this study was trained on 2D slice. Thirdly, this study only included three intensity metrics: SSIM, PSNR, and NMAE, and did not include Feature Similarity Index (FSIM) or other perceptual loss metric. Finally, this study did not conduct a plan design based on the generated CECT to compare the differences. In future studies, dose calculations will be conducted to compare the differences between the generated CECT and the original CECT.
Conclusion
In this study, four deep learning networks were investigated for synthesizing CECT images from NCCT. Through experiments, it was found that the results of the SynDiff method were superior to those of other models. In conclusion, SynDiff is a promising method to explore its application effect in the transition from NCCT to CECT in breast cancer.
Footnotes
Ethics approval and consent to participate
The studies involving human participants were reviewed and approved by the Scientific Research Ethics Committee of Ganzhou Cancer Hospital. All procedures were conducted in accordance with local legislation and institutional requirements; the need for informed consent was waived because of the anonymous nature of the data.
Author contributions
C.X., and J.Z. contributed to the study conception and design, C.C., and Y.X. prepared materials and collected data. C.X. analyzed the experiments. The first draft of the manuscript was written by J.Z. and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data are available upon reasonable request from the corresponding author due to privacy/ethical restrictions.