
Abstract
The widespread research and implementation of visual object detection technology have significantly transformed the autonomous driving industry. Autonomous driving relies heavily on visual sensors to perceive and analyze the environment. However, under extreme weather conditions, such as heavy rain, fog, or low light, these sensors may encounter disruptions, resulting in decreased image quality and reduced detection accuracy, thereby increasing the risk for autonomous driving. To address these challenges, we propose adaptive image enhancement (AIE)-YOLO, a novel object detection method to enhance road object detection accuracy under extreme weather conditions. To tackle the issue of image quality degradation in extreme weather, we designed an improved adaptive image enhancement module. This module dynamically adjusts the pixel features of road images based on different scene conditions, thereby enhancing object visibility and suppressing irrelevant background interference. Additionally, we introduce a spatial feature extraction module to adaptively enhance the model's spatial modeling capability under complex backgrounds. Furthermore, a channel feature extraction module is designed to adaptively enhance the model's representation and generalization abilities. Due to the difficulty in acquiring real-world data for various extreme weather conditions, we constructed a novel benchmark dataset named extreme weather simulation-rare object dataset. This dataset comprises ten types of simulated extreme weather scenarios and is built upon a publicly available rare object detection dataset. Extensive experiments conducted on the extreme weather simulation-rare object dataset demonstrate that AIE-YOLO outperforms existing state-of-the-art methods, achieving excellent detection performance under extreme weather conditions.
Keywords
Introduction
Object detection plays a critical role in autonomous driving, as it facilitates the recognition and localization of diverse objects on the road, such as vehicles, pedestrians, and bicycles. Numerous researchers have made remarkable contributions to the field of autonomous driving. For instance, Dewangan and Sahu 1 wrote a comprehensive review in the field of autonomous driving, focusing on the advancements in intelligent vehicle system design and development across different stages, challenges, and domains. Liang and Huang 2 provided a comprehensive summary of pertinent techniques for 3D object detection in autonomous driving and discussed practical challenges and future development trends in this research domain. Dewangan and Sahu 3 proposed a new lane detection framework based on a two-layer deep learning approach for multiple images under different weather conditions. Xie et al. 4 developed a model predictive control algorithm that enables adaptable and dependable vehicle control through autonomous steering. Wang et al. 5 proposed a method for model predictive control based on variable prediction horizons, which enhances vehicle path tracking performance. Nevertheless, conducting object detection in extreme environments presents substantial challenges that demand overcoming various complexities and difficulties. These extreme scenarios severely impact visibility and image quality, including heavy rain, dense fog, intense light, and nighttime conditions. Consequently, they impose significant hurdles and adversely affect the performance of object detection algorithms. In such situations, achieving accurate and reliable object detection becomes particularly arduous due to the degraded image quality and reduced visibility, necessitating robust solutions to surmount these obstacles.
To tackle this formidable challenge, numerous researchers have dedicated their efforts to devising innovative methods and techniques to enhance object detection performance in extreme environments. These approaches encompass various aspects, such as image enhancement, domain adaptation, model optimization, and adaptive image enhancement. Dong et al. 6 proposed a multiscale denoising network for image enhancement. Similarly, Guo et al. 7 used deep networks to enhance images at the pixel level by formulating low-light enhancement as an image-specific curve estimation.
Haq et al. 8 propose an enhanced approach for stereo vision, addressing challenges posed by radiometric variations, particularly in textureless, occluded, and discontinuous regions. However, these methods are limited to preprocessing image enhancement and cannot achieve real-time end-to-end object detection tasks.
Recently, domain adaptation has emerged as a technique to improve object detection performance by leveraging domain transfer. Chen et al. 9 proposed image-level and instance-level domain adaptation components to reduce domain discrepancies and enhance the performance of the detector. Zhu et al. 10 introduced a novel domain adaptation method for object detection, focusing on aligning regions directly related to object detection in two domains to improve the performance of the detector. He and Zhang 11 proposed a method for object detection in unconstrained environments by leveraging domain knowledge learned from an auxiliary source domain with sufficient labels. Saito et al. 12 proposed a method for adapting detectors based on Faster R-CNN, leveraging strong local matching and weak global matching.
However, these domain adaptation networks may overlook potential informative features in the images while aligning the features of two distributions. Thus, a research hotspot enables networks to fully utilize original image information for image restoration. Huang et al. 13 alleviated image degradation by designing two subnetworks and proposed feature restoration to enhance image visibility. Li et al. 14 introduced a CNN-based image deblurring model capable of producing clear images, which can be seamlessly integrated into any detector to enable end-to-end detection capabilities. In pursuit of adaptive image enhancement, Liu et al. 15 proposed a small-scale CNN tailored for adaptive image enhancement, showcasing promising outcomes in object detection under extreme weather conditions.
Various extreme weather conditions give rise to unique physical characteristics, resulting in distinct properties and challenges in visual sensor imaging. The detection methods mentioned above lack comprehensive high-precision detection capabilities and sufficient stable generalization ability. Additionally, the scarcity of large-scale scene data under various extreme weather conditions poses difficulties for learning-based methods to achieve optimal performance through supervised training.
To address the detection challenges in extreme environments, this article proposes a novel object detection method called Adaptive Image Enhancement (AIE)-YOLO. It can adaptively enhance the quality of degraded images and effectively improve the detection performance under various extreme weather conditions. Specifically, an AIE module is proposed to dynamically adjust the pixel-level characteristics of degraded images, providing enhanced visual images for the subsequent detection network. This process effectively suppresses irrelevant background interference. The AIE module comprises a small convolutional block, a contrast filter, and a sharpening filter. Multiple weight parameters are predicted through the small convolutional block, which jointly adjusts and guides the two filters, resulting in improved image quality. Additionally, we propose a spatial feature extraction (SFE) module to adaptively adjust the weights of each feature position based on scene semantics. By integrating spatial attention mechanisms, the SFE module enhances the spatial semantic modeling capability of AIE-YOLO, thereby improving detection performance in images with complex backgrounds. Furthermore, we introduce a channel feature extraction (CFE) module to adaptively select and adjust the weights between feature channels. The CFE module incorporates a channel attention mechanism to focus on salient channel features and reduce reliance on nonsignificant channels, thus enhancing the overall performance of the model. Figure 1 illustrates the simplified end-to-end pipeline of our proposed AIE-YOLO, where an image taken in a dense fog road scene undergoes adaptive image enhancement through the AIE module before being subjected to object detection by the improved detector.

The simplified end-to-end pipeline of our proposed AIE-YOLO.
We construct a novel benchmark dataset named extreme weather simulation-rare object dataset (EWS-ROD) based on the publicly available ROD to address the challenge of scarce scene data in extreme weather conditions. EWS-ROD covers 10 types of extreme weather simulations, including torrential rain, fog, drop, darken, blur, brighten, snow, sunflare, darken and torrential rain, and drop and torrential rain. This dataset facilitates the evaluation and validation of the performance of existing object detection algorithms in extreme weather scenarios and further enhances the data diversity for extreme scene object detection tasks. Qualitative and quantitative experiments on the EWS-ROD dataset demonstrate that our proposed AIE-YOLO achieves outstanding performance compared to existing detection algorithms. Our main contributions are as follows:
A novel object detection method, AIE-YOLO, is proposed to address the challenges posed by extreme weather conditions and effectively adjust the quality of degraded images, significantly improving overall detection accuracy. An effective AIE module is designed to dynamically adjust the pixel-level features of degraded images, enhancing image quality and suppressing irrelevant background interference. To improve detection performance in complex backgrounds, we introduce an SFE module that adaptively adjusts the weights of each position in the image based on scene semantics. Additionally, a CFE module is proposed to adaptively select and adjust the weight parameters of feature channels, thereby enhancing the representation and generalization capabilities of AIE-YOLO.
Materials and methods
Extreme weather simulated ROD dataset
We construct a novel benchmark dataset called EWS-ROD, covering 10 categories of extreme scenes. EWS-ROD is built on the publicly available ROD dataset and aims to address the data scarcity issue for object detection tasks in extreme weather conditions. The ROD dataset, established and released by NullMax,
16
is a comprehensive dataset in the field of autonomous driving. It comprises 10,000 training images and 4000 validation images, offering a substantial collection for training and testing object detection models. The ROD dataset covers diverse scenarios, encompassing various road levels, such as highways, expressways, urban streets, and rural roads. Furthermore, the ROD dataset includes seven common representative object categories, namely cars, trucks, buses, pedestrians, bicycles, tricycles, and motorcycles. To simplify the object categories and enhance training efficiency, we initially group bicycles, motorcycles, and tricycles together as small vehicles to construct our EWS-ROD dataset. Additionally, we select 50% of the data from the ROD dataset to perform the simulation of 10 different extreme weather conditions. We utilized an image enhancement algorithm called automold that can simulate various climates and environments. This algorithm is developed based on Python's Numpy and OpenCV libraries, enabling the transformation of images to various climatic conditions and seasons. Data partitioning is as follows: 10% of the dataset was transformed into the torrential rain scene, another 10% into the fog scene, 6% into the dark and rainy scene, 6% into the drop and rainy scene, 5% into the drop scene, 5% into the darken scene, 5% into the blur scene, 1% into the brighten scene, 1% into the snow scene, and 1% into the sunflare scene. The images in the dataset are uniformly resized to

Ten types of extreme weather simulated ROD.
Network overview
We propose a novel object detection architecture based on YOLOv8, as illustrated in Figure 3. The architecture primarily comprises three key modules: the backbone, neck module, and head module. The components and characteristics of the architecture are as follows:

The overall architecture of the proposed AIE-YOLO.
Backbone: The backbone network is the fundamental structure, utilizing the CSPDarkNet 17 architecture to extract features from the input image and generate feature maps at different scales. It typically consists of multiple convolutional layers aimed at capturing both low-level and high-level features. Within the backbone network, the C2f module is employed to enhance gradient flow, while the SPPF module is utilized for aggregating feature information across different scales. In the AIE-YOLO backbone network, three additional modules have been incorporated. The AIE module is responsible for image enhancement, the SFE module is dedicated to spatial feature information extraction, and the CFE module focuses on extracting semantic feature information.
Neck: The neck module is a crucial component positioned between the backbone and the head in the architecture. It efficiently performs top-down and bottom-up feature fusion by leveraging feature pyramid network 18 and path aggregation network, 19 which aggregate features of different scales and enhance feature representations. In AIE-YOLO's neck module, the CFE module is embedded after some feature fusion steps to further enhance the model's feature extraction capability.
Head: The head module generates three prediction heads responsible for predicting bounding boxes, class probabilities, and other relevant information for object detection. It utilizes a decoupled-head approach, employing two separate convolutional layers for classification and regression tasks.
Adaptive image enhancement module
We introduce an adaptive image enhancement module designed to dynamically adjust pixel features in road images according to varying scene conditions, thereby improving object visibility and reducing interference from irrelevant background elements, as depicted in Figure 4. This module comprises a CNN module, a sharpening filter, and a contrast filter. The CNN module analyzes input image data and forecasts the parameters essential for both image filters, facilitating effective image enhancement. The specifics of this module are outlined as follows.
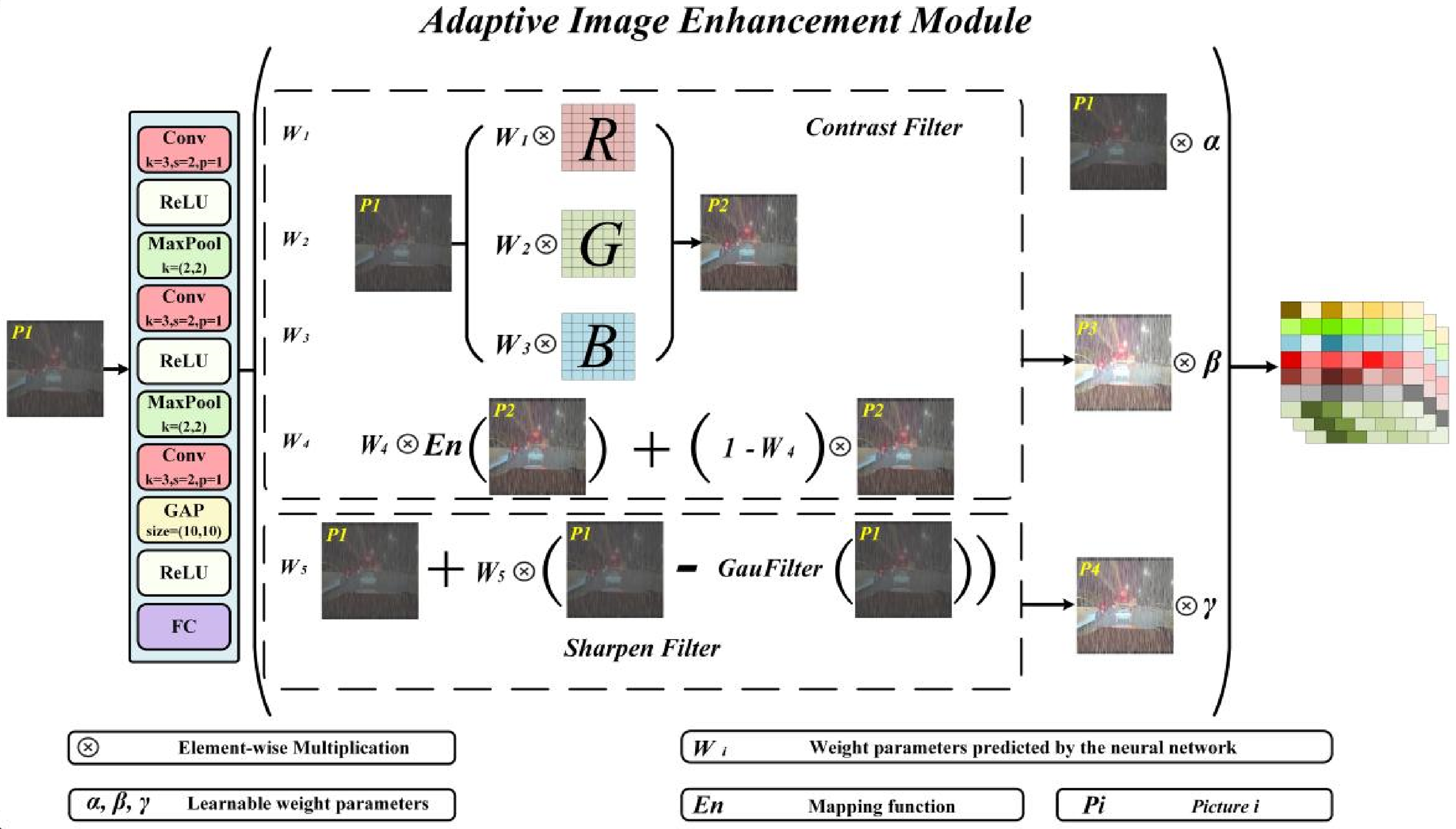
The proposed adaptive image enhancement module.
CNN module: The CNN module comprises three convolutional kernels, each sized at
Contrast filter: The contrast filter, also known as the contrast enhancement filter, is a digital image processing technique used to modify the contrast of an image. Its purpose is to increase or decrease the difference in intensity values between pixels to enhance the visibility and clarity of the image.
In our method, we begin by applying adaptive weighting to the three color channels (red, green, and blue) of an RGB image at each pixel. This adaptive weighting is based on the local characteristics of the image and assigns different weights to the color channels. The purpose of this adaptive weighting scheme is to enhance the contrast in each channel based on their specific contributions to the image's overall appearance. Mathematically, this can be described as follows:
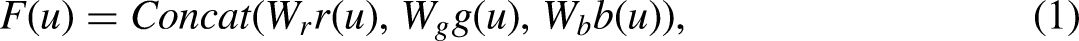
where
Following that, we proceed with contrast filter enhancement, which can be described by the following equation:


Sharpen filter: The main purpose of the sharpening filter is to enhance the edges and details of an image, making it appear clearer and sharper. It achieves this goal by enhancing the high-frequency components of the image. Considering that in extreme environments, details may often be obscured or blurred, using a sharpening filter can effectively alleviate this issue. The sharpening process can be described by the following specific formula:



where
To efficiently utilize the feature information obtained from the original image, contrast filter, and sharpening filter, we concatenate them along the channel dimension. Considering their varying importance, we apply adaptive weighting to these three feature maps before combining them. The formula for this operation is as follows:

where
Spatial feature extraction module
To improve the model's ability to extract spatial feature details in extreme environments where feature information tends to be blurry, we propose an SFE module. This module consists of a feature extraction branch and a spatial attention branch. The feature extraction branch is responsible for further extracting informative features from the input images. Meanwhile, the spatial attention branch leverages spatial contextual information to compute attention weights, enhancing the model's ability to focus on important spatial regions. It selectively amplifies relevant spatial features while suppressing irrelevant or noisy features, thus improving the discriminative power of the extracted features. Finally, the outputs of the two feature maps are adaptively weighted and concatenated. SFE module enhances the model's capacity to capture relevant spatial details and attend to regions with rich information. By integrating feature embedding and attention mechanisms, it effectively highlights discriminative spatial features, significantly improving the blurriness of feature information in extreme environments. The detailed structure of the proposed module is illustrated in Figure 5.

Architecture of spatial feature extraction module and channel feature extraction module.
Channel feature extraction module
We design a CFE module with the objective of extracting important information from different channels of feature maps and enhancing the network's feature extraction capability in extreme environments. The channel information extraction module consists of two main components: a feature extraction branch and a channel attention branch. The feature extraction branch is responsible for further extracting feature information from the input data. By leveraging the channel attention mechanism, the module effectively captures and emphasizes the most discriminative channel features. It selectively amplifies informative channels while suppressing less relevant ones, allowing the model to better understand the unique contributions of different channels and adaptively highlight the most relevant features. Finally, the outputs of the two feature maps are adaptively weighted and concatenated. The CFE module improves the model's ability to capture relevant channel details and focus on channels with rich information. By integrating feature embedding and attention mechanisms, it effectively highlights channel features with discriminative power, enhancing the model's extraction capability of abstract feature information. The specific structure of the module is illustrated in Figure 5.
Result
This study comprehensively evaluated object detection performance in extreme driving environments using the EWS-ROD dataset through comparative experiments and ablative studies. To measure the accuracy and robustness of the models, we utilized various evaluation metrics, including mean average precision (mAP) at Intersection over Union (IoU) threshold 0.5 (mAP@0.5), mAP at IoU threshold 0.75 (mAP@0.75), and mAP across IoU thresholds from 0.5 to 0.95 (mAP@0.5:0.95). These comprehensive metrics assess our model's object detection capabilities under challenging driving conditions.
Experimental environment
To ensure the reproducibility and validation of our proposed network model, we conducted experiments using the following settings. All experiments were performed on a computer running Ubuntu 18.04, equipped with an Intel i9-12900KF processor and an NVIDIA® GeForce RTX 3090 GPU with 24 GB VRAM. The system has 32 GB of memory. The experimental environment was set up with Python 3.9 and the deep learning framework PyTorch 1.13.1, along with Cuda version 11.6. We initialized the learning rate to 0.001 and set the weight decay decay coefficient to 0.0005. The momentum parameter was set to 0.937. The batch size for training was set to 32. These selected experimental settings were intended to ensure reliable and effective evaluation of the model's performance.
Evaluation metrics
Table 1 presents the classification of real and predicted scenarios, where true positives (TP) stands for true positives, representing cases where both the predicted and real scenarios are positive. False positives (FP) refers to false positives, indicating cases where the predicted scenario is positive, but the real scenario is negative. False negatives (FN) represents false negatives, indicating cases where the predicted scenario is negative while the real scenario is positive. Lastly, TN denotes true negatives, representing cases where both the predicted and real scenarios are negative. The evaluation metrics used in this research include average precision (AP) and mAP. The mAP serves as the primary performance measure for object detection algorithms and is widely employed to evaluate the effectiveness of object detection models. A higher mAP value indicates superior detection performance on the given dataset. The precision-recall (P-R) curve is constructed by plotting precision on the vertical axis and recall on the horizontal axis. The area under the P-R curve (AP) corresponds to the AP value, while mAP is the average of the AP values across all categories. Furthermore, IoU quantifies the overlap between predicted and ground truth bounding boxes, providing an important measure of detection accuracy. The performance metrics in this study follow the standard COCO
32
style metrics. mAP@0.5 signifies the mAP value computed with an IoU threshold of 0.5, whereas
Confusion matrix.

Based on the provided confusion matrix in Table 1, we can define the precision (P) metric as the ratio of TP to the sum of TP and FP, expressed as

where n represents the number of classes.
Ablation experiments on EWS-ROD
In this study, we present AIE-YOLO, an advanced object detection method specifically designed for optimal performance in extreme weather conditions. AIE-YOLO incorporates our novel AIE, SFE, and CFE modules, each playing a crucial role in dynamically improving image quality, enhancing spatial semantic modeling, and emphasizing important channel features. To validate the significance of our contributions, we will conduct meticulous ablation experiments, systematically evaluating the impact of each module on the model's performance in challenging weather scenarios. The experimental results are recorded in Table 2.
Ablations analysis on the EWS-ROD dataset.
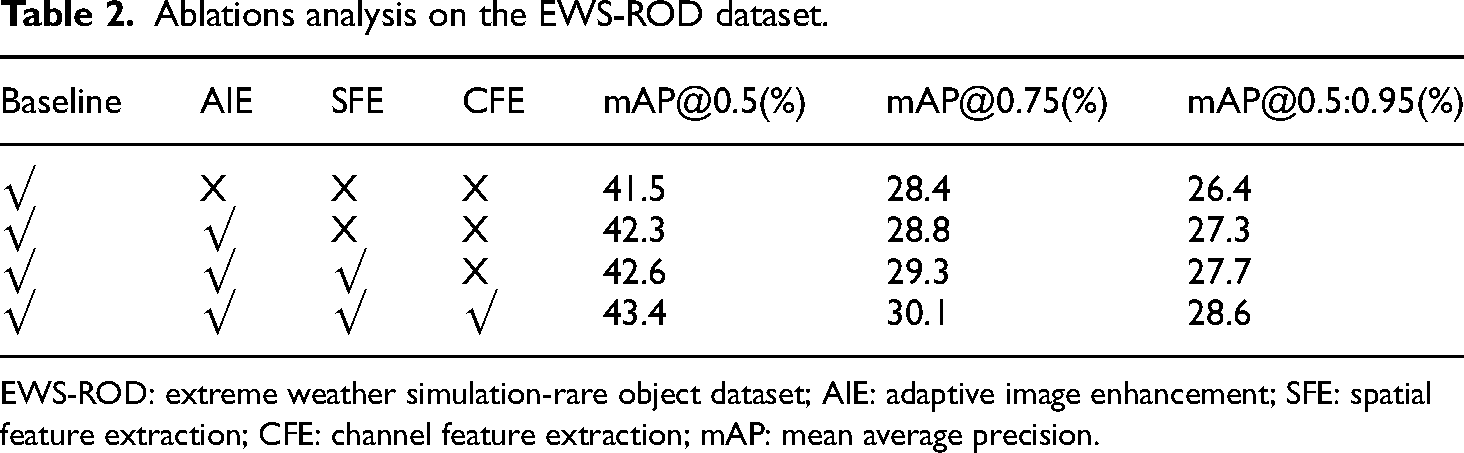
EWS-ROD: extreme weather simulation-rare object dataset; AIE: adaptive image enhancement; SFE: spatial feature extraction; CFE: channel feature extraction; mAP: mean average precision.
Based on the results in Table 2, we can evaluate the significance of each module in the AIE-YOLO object detection method. The AIE module increases mAP@0.5 from 41.5% to 42.3%, improves mAP@0.75 from 28.4% to 28.8%, and raises mAP@0.5:0.95 from 26.4% to 27.3%. These results demonstrate that the AIE module significantly enhances feature information in images, thereby improving object detection performance. Subsequently, the introduction of the SFE module further enhances performance, with mAP@0.5 reaching 42.6%, mAP@0.75 increasing to 29.3%, and mAP@0.5:0.95 rising to 27.7%. This highlights the SFE module's ability to better capture spatial information of objects, contributing to an overall improvement in accuracy. Additionally, the introduction of the CFE module demonstrates its significant impact on model performance. The mAP@0.5 reaches its highest value of 43.4%, mAP@0.75 further increases to 30.1%, and mAP@0.5:0.95 rises to 28.6%, underscoring the importance of CFE in emphasizing relevant channel features and leading to enhanced detection accuracy. Overall, the comprehensive evaluation metrics for the complete AIE-YOLO model clearly reflect the critical contributions of each module. The AIE, SFE, and CFE modules collectively enhance object detection accuracy under extreme weather conditions. These results validate the importance and effectiveness of each module in achieving superior object detection performance.
To validate the effectiveness of each filter in the AIE module, we conducted ablation experiments on the filters. The experimental procedure is as follows: we first removed the sharpen filter from the AIE module of AIE-YOLO, then removed the contrast filter, and finally added both filters back in. The results are shown in Table 3. Analysis of the experimental results indicates a significant decrease in performance after removing the contrast filter and sharpening filter. This thoroughly validates the effectiveness of these two filters for our task.
The ablation experiment of the AIE module conducted on the EWS-ROD dataset.

EWS-ROD: extreme weather simulation-rare object dataset; AIE: adaptive image enhancement; mAP: mean average precision.
Comparative experiments on EWS-ROD
To validate the effectiveness of the proposed AIE-YOLO model, we replicated a wide range of object detection algorithms and conducted comprehensive comparative experiments. The primary objective was to compare its performance with various object detection models across a range of evaluation metrics. Through these experiments, we aimed to demonstrate the superiority of our proposed approach in addressing the challenges of object detection under extreme weather conditions. As shown in Table 4, our approach outperforms all other single-stage and two-stage object detection models, achieving the best performance across the metrics of mAP@0.5, mAP@0.75, and mAP@0.5:0.95. Specifically, compared to the best-performing two-stage model, Cascade-RCNN, 22 our method demonstrates superiority by 1.7%, 1%, and 1.5% in terms of mAP@0.5, mAP@0.75, and mAP@0.5:0.95, respectively. Moreover, when compared to single-stage models, our approach shows even more significant improvements. Compared to the baseline YOLOv8, it achieves higher mAP@0.5 by 1.9%, mAP@0.75 by 1.7%, and mAP@0.5:0.95 by 2.2%. Similarly, when compared to RT-DETR, 31 our approach exhibits superior performance with 4.9% higher mAP@0.5, 5.4% higher mAP@0.75, and 5.5% higher mAP@0.5:0.95. These comparative results firmly establish the effectiveness of AIE-YOLO in object detection under extreme environmental conditions.
The quantitative experimental results on the EWS-ROD dataset.

EWS-ROD: extreme weather simulation-rare object dataset; AIE: adaptive image enhancement; mAP: mean average precision.
To further demonstrate the effectiveness of our modular approach and model, and to make the analysis more objective, we selected four representative methods and embedded the AIE module into these four methods. We selected these models based on the following considerations: cascade R-CNN and FCOS represent classic examples of two-stage and one-stage object detection models, respectively. The reason for choosing YOLOv6 and YOLOv7 is because they are the latest models in the YOLO series, which are widely used in the field of object detection. By conducting experiments with these models, we can demonstrate more convincing experimental results. As shown in Table 5, after incorporating the AIE module, the mAP@0.5, mAP@0.75, and mAP@0.5:0.95 metrics of these four methods all showed improvement, demonstrating the effectiveness of our AIE module. At the same time, our overall model still represents state-of-the-art results, validating the effectiveness of the methods we proposed.
Verify the effectiveness of AIE by using different baselines on the EWS-ROD dataset.

AIE: adaptive image enhancement; mAP: mean average precision.
We also conducted a comparative analysis of our model with the single-stage YOLO series models v5 s, v6 s, and v8 s, as well as the two-stage Faster R-CNN model, in terms of both speed and parameter count, as depicted in Table 6. After analysis, the following conclusions can be drawn: YOLOv8 s exhibits the fastest speed, while YOLOv5 s stands out as the most lightweight option. Our method slightly lags behind other models in terms of speed and parameter count due to the incorporation of adaptive image enhancement modules and attention mechanisms. However, compared to the Faster R-CNN model, our method still holds significant advantages.
The inference speed and parameter count of our proposed method are compared with other methods.
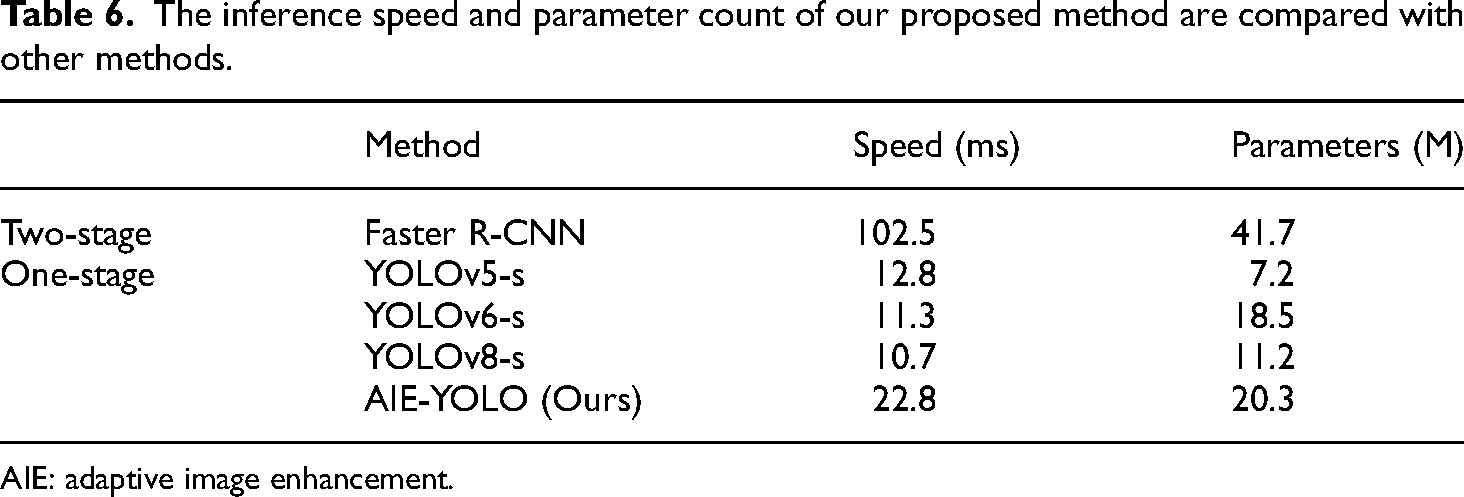
AIE: adaptive image enhancement.
Perceptual comparisons
In extreme weather conditions, our proposed AIE-YOLO aims to enhance the accuracy of road object detection by adaptively addressing the challenge of degraded visual image quality. To intuitively demonstrate the effectiveness and superiority of our method, we prepared 10 types of road images captured under extreme environmental conditions, including torrential rain, fog, drop, darken, blur, brighten, snow, sunflare, darken and torrential rain, and drop and torrential rain. For each of these extreme weather images, we utilized YOLOv8 and AIE-YOLO for object detection and compared the results through visualizations. As shown in Figure 6, it is evident that AIE-YOLO consistently outperforms YOLOv8 in various extreme weather conditions,

The visualization results under 10 extreme weather conditions.
demonstrating its advanced performance. When comparing it with the Ground Truth, it is noticeable that YOLOv8 exhibits many instances of missed detections, false positives, and misclassifications. In contrast, AIE-YOLO shows relatively stable results with better accuracy and recall rates.
Conclusions
In this article, we proposed AIE-YOLO, a novel object detection algorithm aimed at improving the accuracy of road object detection under extreme weather conditions and addressing the problem of degraded visual image quality. The algorithm incorporates an adaptive image enhancement module that dynamically adjusts pixel features based on scene conditions, enhancing object visibility and suppressing irrelevant interference. Additionally, a spatial feature extraction module improves spatial modeling capabilities in cluttered backgrounds, while a channel feature extraction module enhances representation and generalization capabilities. The construction of the EWS-ROD dataset further strengthens research on extreme weather scenarios and contributes to evaluating future algorithms. Extensive experiments on the EWS-ROD dataset demonstrate that AIE-YOLO outperforms existing methods, making it an effective solution for object detection in extreme weather conditions. Our work enhances the safety and reliability of autonomous driving. It takes a significant step toward improving the robustness and applicability of object detection technology in real-world extreme weather conditions. While our proposed method can dynamically adjust the pixel features of road images based on different scenario conditions, these adjustments are still reliant on predefined weather scenario conditions. This implies that our algorithm may not fully encompass the variability of actual complex weather conditions. Enhancing the model's generalization capability to make it applicable to the majority of complex weather situations is thus our next planned endeavor.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China under grants 62072211, 51939003, and U20A20285.
Author biographies
Qianren Guo received his BS degree from the School of Science and Information Science, Qingdao Agricultural University, China, in 2022, and he is currently pursuing master's degree from the College of Software, Jilin University, China. His research fields include deep learning, machine vision, semantic segmentation and object detection.
Yuehang Wang received his BS degree from the College of Computer Science and Technology, Wuhan University of Science and Technology, China, in 2018, and his MS degree from the College of Software, Jilin University, China, in 2021. He is pursuing a PhD at the College of Computer Science and Technology, Jilin University, China. His research fields include deep learning, Internet of Things, machine vision and object detection.
Yongji Zhang received his BS degree in electronic information engineering from the College of Defense Education, Heilongjiang University, China, in 2019, and his MS degree from the College of Computer Science and Technology, Jilin University, China, in 2023. He is currently pursuing a PhD at the College of Computer Science and Technology, Jilin University, China. His main research interests are computer vision and motion, such as applications of machine vision, video frame interpolation, and Internet of Things.
Minghao Zhao received his MS in computer science and technology from Jilin University, China, in 2020. He is pursuing a PhD at the College of Earth Sciences, Jilin University. His research interests include machine learning, remote sensing image processing, and machine vision.
Yu Jiang is an associate professor with the College of Computer Science and Technology, Jilin University, China. He received his MS and PhD degrees from the College of Computer Science and Technology, Jilin University, China, in 2005 and 2011, respectively. His research fields include Internet of Things, intelligent transportation, artificial intelligence, and machine vision.