
Abstract
In recent years, machine learning (ML) has been increasingly applied to sports injury prediction, offering potential support for the early identification of risk and the optimization of preventive strategies. However, current studies face several key challenges, including the absence of standardized model development procedures and inconsistencies in data preprocessing, feature selection, and model evaluation across investigations. This narrative review systematically searched the literature published up to December 2024 in major databases (Web of Science, Scopus, PubMed, and SPORTDiscus) and synthesized the methodological progress in ML-based injury prediction. Specifically, it highlights critical stages in model development, including data preprocessing, feature engineering, model selection and comparison, evaluation metrics, and approaches to interpretability. The findings indicate that, while some ML models demonstrate promising predictive accuracy, their limited interpretability constrains clinical applicability. Furthermore, substantial heterogeneity among the included studies, such as differences in populations, injury sites, and risk factors, limits meaningful comparison of methodological performance. Future research should prioritize external validation in more diverse populations and real-world contexts while advancing interpretability and generalizability, thereby strengthening the translational potential of ML-based injury prediction. This review provides a structured framework and direction for researchers aiming to improve methodological rigor and clinical utility in this emerging field.
Introduction
In modern sports science, the prediction and prevention of sports injuries have emerged as critical areas of research. Evidence suggests that sports injuries are typically the result of multifactorial influences, 1 encompassing both extrinsic factors (e.g. training load, surface conditions, and equipment use) and intrinsic factors (e.g. anatomical structure, physiological state, and psychological resilience). Injuries are prevalent among both elite athletes and recreational participants, reflecting their widespread nature. 2 For professional athletes in particular, sports injuries can result in severe physical dysfunction, psychological trauma, and financial loss, 3 and in some cases may even force early retirement from competition. Therefore, accurate estimation of injury risk and timing using time-to-event or hazard-based models can inform prevention strategies, optimize training, and guide competition planning, thereby reducing injury incidence and supporting career longevity.
Accurate prediction and effective prevention of sports injuries depend on the systematic identification of multidimensional risk factors and a deep understanding of their complex interactions. 4 However, achieving this scientific goal presents dual challenges: first, human health status is characterized by significant interindividual heterogeneity and temporal variability 5 ; second, the occurrence and progression of sports injuries exhibit nonlinear dynamics and recursive feedback mechanisms. 6 Traditional statistical models are limited in addressing these complexities due to their insufficient capacity to capture nonlinear relationships, difficulty handling high-dimensional data, and inability to model intricate interactions among variables. Sports injuries arise not from simple linear summation 7 but from complex adaptive systems of interdependent determinant networks, 8 where minor changes can trigger significant and sometimes unpredictable outcomes. Therefore, to effectively identify and disentangle the multiple risk factors and their interactions underlying sports injuries, there is an urgent need to develop more sophisticated predictive models. These models must be capable of capturing nonlinear interrelations among risk factors while also extracting the most relevant variables associated with injury occurrence, thereby enhancing both predictive accuracy (i.e. alignment of predictions with actual outcomes) and consistency (i.e. model performance stability across datasets or conditions).
In recent years, machine learning (ML) techniques have been widely applied in the field of sports science, encompassing various domains such as performance analysis,
9
injury prediction,
10
and competition outcome forecasting.11,12 As a critical subfield of artificial intelligence, ML focuses on developing algorithms that enable computers to autonomously identify patterns and regularities from large-scale datasets, thereby facilitating data-driven prediction and decision-making.
13
Given the substantial economic value associated with improving the accuracy of sports injury prediction, particularly in enhancing athlete health management and optimizing training protocols, ML-based injury prediction has emerged as a cutting-edge research focus within the field of sports science.
2
Given this context, the present narrative review addresses two main objectives:
① The sequence of modeling procedures and core techniques involved in constructing ML-based sports injury prediction models. ② The prevailing issues and emerging trends in the application of ML to sports injury prediction.
Methods
This article adopts a narrative review approach and follows the Scale for the Assessment of Narrative Review Articles guidelines to ensure methodological rigor. 14 Given the interdisciplinary scope, methodological heterogeneity, and limited standardization observed in current applications of ML for sports injury prediction, a narrative review is particularly suitable for synthesizing insights and identifying emerging trends in the field.
A comprehensive literature search was conducted across four major academic databases: Web of Science, Scopus, PubMed, and SPORTDiscus up to December 2024. The search strategy combined English keywords such as “machine learning,” “athletic injuries,” “injury risk modeling,” “injury risk assessment,” “feature selection,” “model explainability,” and “artificial intelligence in sports,” using Boolean operators (AND, OR) to optimize retrieval.
To ensure relevance and analytical depth, studies were considered based on the following relevance criteria:
studies that applied ML techniques to sports injury prediction; involved athletes or specific demographic groups (e.g. youth and older adults); and articles that provided clear methodological descriptions and reported performance metrics (e.g. accuracy, area under the curve (AUC), sensitivity, and F1 score). Non-peer-reviewed works (e.g. conference abstracts and theses), studies lacking methodological detail, or those not directly related to injury prediction were excluded.
Following study selection, a qualitative synthesis was performed focusing on the types of ML algorithms employed, feature engineering methods, model evaluation strategies, reported predictive performance, and interpretability in practical sports contexts. This approach allowed for a structured assessment of current methodological trends, strengths, and limitations in the field.
Application of ML in sports injury prediction
For a long time, univariate analysis, which examines the effect of a single variable on sports injury risk, has been recognized as insufficient for revealing the complex mechanisms underlying injury occurrence.1,5,7 Such approaches fail to provide a comprehensive understanding of the deeper causes of injury. To achieve a more comprehensive understanding, multivariate methods that account for the interactive effects of multiple risk factors are essential. 5 Hamstring strain injury (HSI), one of the most common injuries among professional football players, 15 illustrates this complexity. Early research mainly relied on linear statistical approaches to explore risk factors and their interactions.5,16 However, these approaches often produced inconsistent results and limited predictive power. For example, while some small-sample studies suggested that eccentric training or flexibility interventions could mitigate HSI risk, 17 larger cohort studies and systematic reviews failed to confirm these findings.18,19 Similarly, the association between hamstring flexibility and injury risk remains controversial, with prospective studies reporting conflicting results.20,21 These inconsistencies highlight the limitations of traditional linear models in capturing the multilevel, nonlinear interactions inherent in musculoskeletal and sports injury systems. As noted by Bittencourt et al., 7 many risk factors for sports injuries exhibit highly nonlinear relationships, and traditional multivariate statistical approaches, such as logistic regression, are often inadequate for modeling these dynamic and interdependent interactions. In contrast, ML approaches provide a data-driven framework capable of identifying intricate, nonlinear relationships among multiple risk factors without relying on strict parametric assumptions, thereby offering a robust and flexible solution for enhancing injury risk prediction.7,16
Based on different learning paradigms, ML can be categorized into four main types: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Among these, supervised learning represents the most frequently applied approach in sports injury prediction research 22 (Figure 1). The objective of supervised learning is to predict corresponding labels based on known input features. Each “feature-label” pair constitutes a sample, and the model learns the mapping relationship between input features and labels in order to make accurate predictions on new data inputs. 23 For example, in predicting sports injuries, if the goal is to determine whether an athlete will sustain an injury, the label could be defined as “injury occurred” or “no injury,” while input features might include physiological and environmental variables such as age, weight, physical fitness level, sleep quality, and joint range of motion.
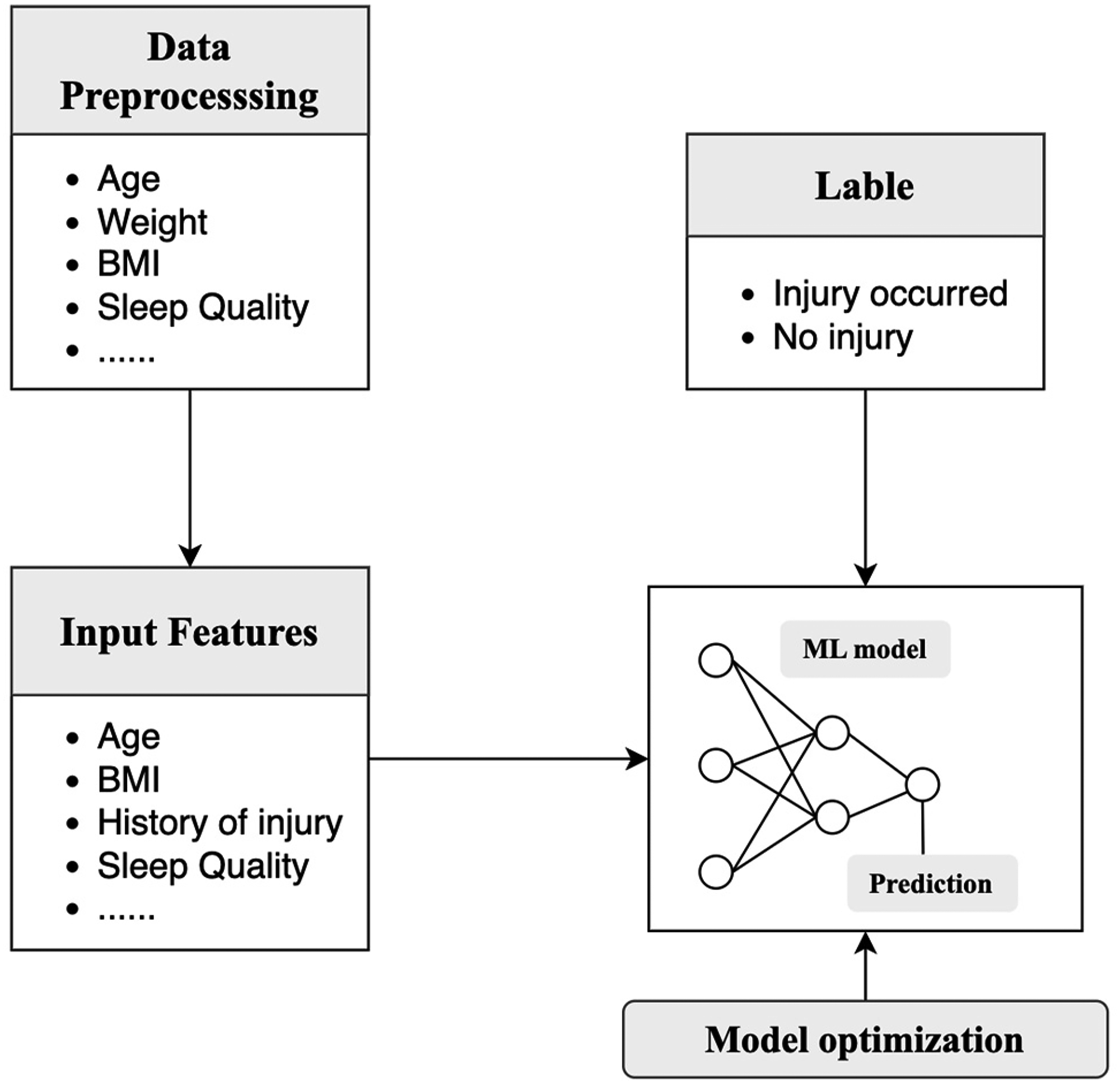
Supervised learning for sports injury prediction.
It is important to note that in constructing ML-based injury prediction models, researchers do not simply input raw datasets directly into the model for analysis. Instead, a structured modeling process must be followed. This process typically includes three key stages: data preprocessing, feature engineering, and model optimization.
Construction of sports injury prediction models based on ML
Data collection
The key to data collection lies in the comprehensive and systematic acquisition of multidimensional risk factors associated with sports injuries. Although ML methods can integrate a large number of variables and develop complex predictive models, the sheer number of included risk factors does not necessarily translate into improved model performance. For instance, in two studies on lower-limb injury prediction, a model incorporating 135 risk factors achieved an AUC of only 0.70, 24 whereas another model with just 32 risk factors reached an AUC of 0.91. 25 Table 1 summarizes the ML-based sports injury studies included in this review, with risk factors spanning demographic characteristics (e.g. sex, height, weight, and injury history), psychological and perceptual variables (e.g. sleep quality and emotional exhaustion), and physical performance measures (e.g. dynamic postural control and Y-balance composite). Notably, the majority of included studies (n = 9, 69%) focused on non-contact injuries occurring during training or competition. This emphasis aligns with current ML modeling approaches, as non-contact injuries are more closely linked to quantifiable individual-level features, such as training load, fatigue, physiological parameters, and performance metrics, making them more amenable to data-driven prediction. However, this focus has resulted in relatively limited attention to contact injuries, which are also prevalent in team sports but are largely determined by contextual factors, such as intensity of player interactions, tactical positioning, and on-field dynamics. These factors are difficult to capture through conventional physiological or individual metrics, thereby constraining the applicability of existing ML models to contact injuries.
Overview of machine learning studies on sports injury prediction.
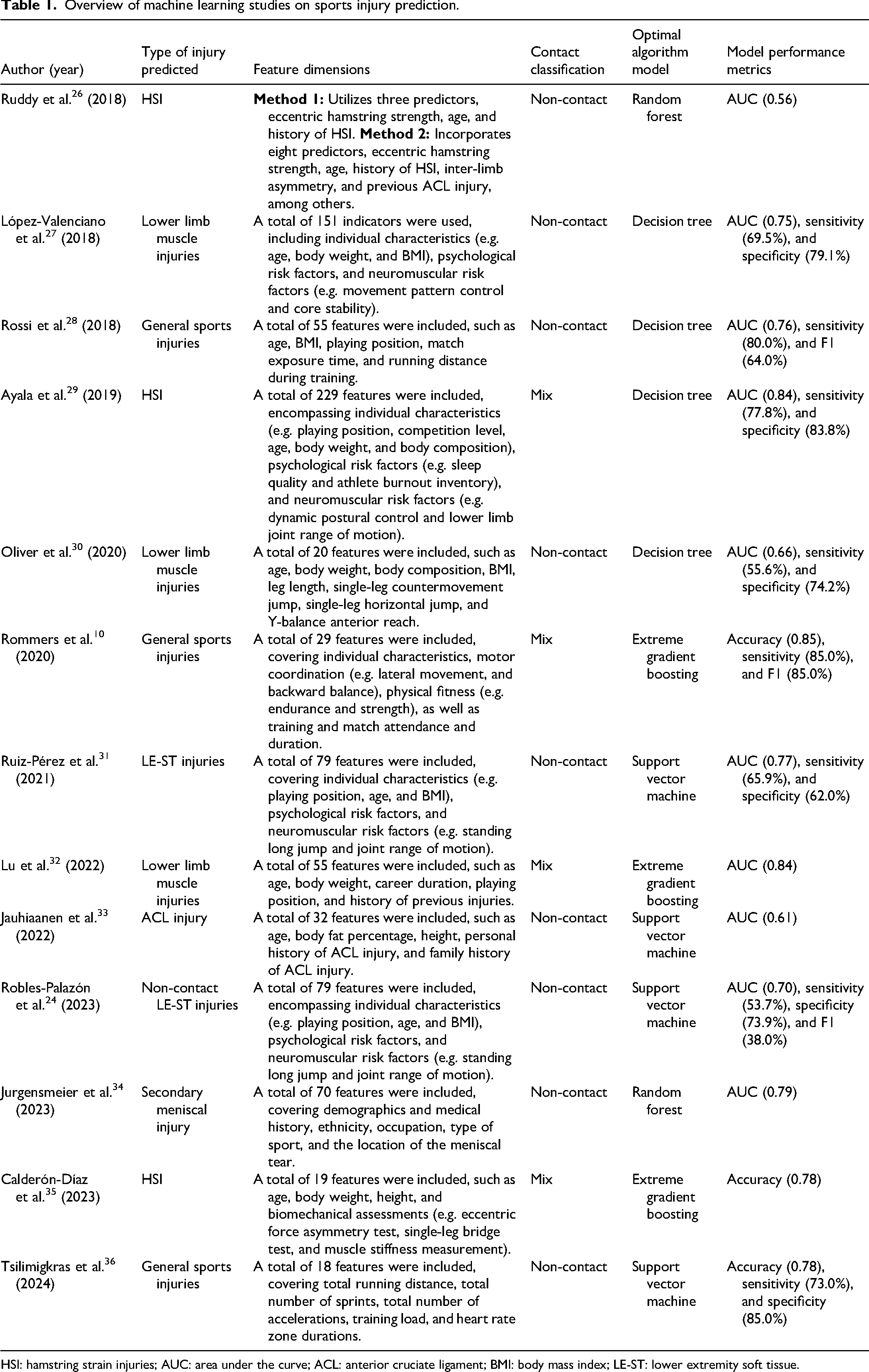
HSI: hamstring strain injuries; AUC: area under the curve; ACL: anterior cruciate ligament; BMI: body mass index; LE-ST: lower extremity soft tissue.
To address these limitations and further exploit the richness of heterogeneous data, recent advances have proposed more sophisticated data fusion strategies. For instance, Tsilimigkras et al. 36 constructed spatiotemporal correlation features by computing the Pearson correlation coefficient between a 7-day rolling average of training load (e.g. weekly running distance and acceleration events) and static biomechanical parameters such as knee internal rotation angle. This “load-joint stress correlation feature” captures the dynamic interplay between workload and joint susceptibility, and its predictive utility for lower limb injuries has been verified using random forest classifiers with Shapley additive explanations (SHAP) value analysis, ranking among the top contributing features. Additionally, building on the work of Rodas et al. 37 and López-Valenciano et al., 27 a growing body of research has explored signal-level fusion of biomechanical and physiological data. Specifically, features such as peak ground reaction force during landing are normalized and concatenated with heart rate variability (HRV) indices at the model input layer. Employing self-attention mechanisms allows the model to learn contextual dependencies, such as attenuating the influence of mechanical stress signals when high HRV suggests low injury risk. This approach overcomes the limitations of naive feature stacking. While some traditional statistical models may perform comparably or even better in certain contexts,38,39 integrating diverse and high-dimensional data in ML approaches allows for modeling of complex interactions, offering potential improvements in predictive performance and generalizability across varied athletic populations.
Data preprocessing
Data preprocessing is one of the most crucial factors influencing the generalization performance of supervised ML algorithms. 40 Of the included studies, 10 (77%) reported preprocessing procedures,24,26,27,29–35 such steps—commonly recommended in ML practice—are considered essential for enhancing data quality, which in turn can improve model performance. 41 As Li Mu, author of Dive into Deep Learning, aptly stated, “Data scientists spend 80% of their time processing data.”
Injury datasets are typically derived from reports by professional coaching staff27,31,35 or from publicly available databases, 32 and are therefore prone to missing, duplicated, or erroneous records. Common approaches for addressing these issues include case deletion, mean substitution, k-nearest neighbor (KNN) imputation, and multiple imputation. However, detailed documentation of data-cleaning procedures remains scarce in the literature. For instance, Robles-Palazón et al. 24 reported correcting 32 erroneous entries, including a physiologically implausible vertical jump height of 256 cm, but did not specify the correction method applied. Similarly, Jurgensmeier et al. 34 briefly noted the presence of missing data in their dataset and stated that multiple imputation was used, yet provided no further details. In contrast, Jauhiainen et al. 33 offered a more comprehensive description of their data-cleaning process, which included excluding five athletes with more than 50% missing data, applying KNN imputation to address 9029 missing values across 478 athletes, and using regression-based imputation informed by self-reported values to estimate missing height and body mass data. These examples suggest that data cleaning may be an underappreciated step in sports injury research, with processes often lacking in systematic rigor and transparency. Nevertheless, this stage is critical for ensuring data quality, enhancing model generalizability, and supporting the reproducibility of research findings.
Another essential component of data preprocessing is feature scaling. Demographic variables (e.g. age, height, and body mass) typically fall within relatively narrow ranges, whereas derived training indicators (e.g. running distance and number of accelerations) may span several orders of magnitude; without scaling, models are likely to become biased toward the latter. Commonly used methods include min–max normalization and z-score normalization. Among the 13 studies included in this review, seven studies (approximately 54%) explicitly reported their scaling strategies. Four studies employed automated processing via the Weka software package,24,27,30,31 an open-source ML and data-mining platform that integrates preprocessing, modeling, evaluation, and visualization functions. 42 Two studies applied z-score normalization,26,33 and one study used min–max normalization. 35 However, nearly half of the studies did not report their scaling procedures, which may reflect the perception of scaling as a default step or reliance on automated software routines. Such inconsistencies not only limit reproducibility but also weaken the comparability of results across studies.
Feature engineering
The primary goal of feature engineering is to construct models that are more parsimonious and interpretable, while reducing the risk of overfitting, thereby enhancing model accuracy, stability, and explainability. 43 Its core value lies in extracting information most relevant to the prediction task from complex raw data, rather than merely performing data cleaning or preprocessing. In the context of sports injury prediction, a large number of demographic, physiological, psychological, and performance-related indicators are often difficult to be directly applied to modeling. Through feature engineering, these redundant and complex data can be transformed into more interpretable and predictive variables. Among the reviewed studies, seven studies (54%) explicitly reported the use of feature engineering approaches: four studies employed the Weka software for feature processing,24,27,30,31 two studies utilized ML-based feature selection methods,28,34 and one study combined manual feature construction based on domain expertise with algorithmic feature selection. 36 The diverse applications of feature engineering in sports injury prediction suggest that this field remains at an exploratory stage, where methodological choices reflect not only the complexity of data characteristics but also inherent tradeoffs in research design. Nevertheless, several limitations exist. Feature processing based on the Weka platform largely relies on built-in algorithms, which allow for rapid feature selection and transformation in small-scale datasets but suffer from “black-box” limitations that restrict interpretability and reduce clinical relevance. 44 Conversely, ML-based feature selection methods (e.g. recursive feature elimination and regularization) are more effective in controlling noise and redundancy in high-dimensional settings, thereby improving generalizability. However, such methods are highly dependent on sample size and parameter tuning, and the resulting “key features” may lack medical plausibility if not grounded in domain expertise, leading to the risk of being “statistically significant but biologically implausible.”
Evidence from the healthcare prediction domain has shown that integrating expert knowledge with ML in feature engineering can significantly reduce model complexity while maintaining or even slightly improving predictive performance, as well as enhancing clinical interpretability. 45 Similarly, Tsilimigkras et al. 36 recently applied this combined strategy in predicting muscle injuries among elite soccer players. By incorporating domain-specific features—such as the acute to chronic workload ratio (ACWR) and the deviation of maximum from average (DEV)—together with support vector machine-based feature selection, they achieved promising predictive performance (accuracy = 0.78, sensitivity = 0.73, and specificity = 0.85). Such approaches highlight that combining domain knowledge to identify candidate variables with algorithmic methods for efficient selection and dimensionality reduction may represent a promising direction for future research in sports injury prediction, striking a balance between model performance and interpretability.
Beyond the methodological tradeoffs discussed above, another critical limitation lies in the scope of feature engineering, particularly the underrepresentation of external environmental factors. External environmental factors may play a significant role in the occurrence of sports injuries.7,46 However, current studies on feature selection exhibit notable limitations, primarily due to an overemphasis on internal risk factors (e.g. physiological indicators and anatomical structures), with insufficient consideration of external environmental variables. In fact, none of the studies included in this review incorporated external factors such as climatic conditions, field quality, or training environment. This research bias may result in a skewed understanding of injury mechanisms, as sports injuries typically occur in dynamic training or competition settings where internal and external factors interact. Neglecting these key external variables in predictive models may reduce model accuracy and impede a comprehensive understanding of injury mechanisms.
Model selection and training
As discussed in the “Application of ML in sports injury prediction” section, supervised ML algorithms have become the mainstream approach in sports injury prediction research. Among the studies included in this review, tree-based models, such as decision trees,27–30 random forests,26,34 and extreme gradient boosting,10,32,35 were employed in nine studies (70%) and demonstrated the highest predictive performance, as measured by AUC. This suggests a general preference for tree-based models within the field of sports injury prediction. The inherent interpretability and visualization capabilities of these models enable sports medicine practitioners to gain a more intuitive understanding of the decision mechanisms underlying injury occurrence, thereby providing practical insights for clinical application and risk intervention. Although deep neural networks have exhibited superior predictive performance in certain tasks,47,48 their “black-box” nature limits mechanistic interpretability, which likely explains their less widespread use compared to tree-based models in most sports science studies.
Before formally training predictive models, one critical challenge is class imbalance. In nearly all prospective studies on sports injury prediction, the number of injury cases is substantially smaller than the number of non-injury cases.26–28,30,31,33 For instance, in the study by Rossi et al., 28 the training set included 279 non-injury cases but only seven injury cases, yielding an imbalance ratio (=minority class/majority class) as low as 0.03, which indicates an extreme imbalance. To address this issue, commonly used strategies include the synthetic minority oversampling technique (SMOTE), random oversampling, and random undersampling, among which SMOTE is the most frequently applied. The core idea of SMOTE is to generate synthetic samples in the feature space of minority instances (e.g. injured athletes) through interpolation, thereby alleviating class imbalance and enhancing the model's ability to identify injury risk. Nevertheless, the effectiveness of SMOTE remains a matter of debate in the literature. For example, Ruddy et al., 26 López-Valenciano et al., 27 and Jauhiainen et al. 33 reported that, compared with baseline models, the application of SMOTE did not significantly improve AUC or overall predictive performance. In contrast, studies by Rossi et al. 28 and Ruiz-Pérez et al. 31 demonstrated that SMOTE substantially increased model sensitivity and overall predictive accuracy. Notably, the prospective study by Rommers et al. 10 offers an informative counterpoint: with a naturally balanced dataset of 734 elite youth soccer players (368 with injuries), the model achieved high performance (accuracy = 0.85 and sensitivity = 0.85) without employing any resampling techniques. This finding suggests that when class distributions are balanced, models can directly learn stable decision boundaries. By contrast, in highly imbalanced contexts, the performance gains observed with SMOTE may reflect a modification of data distribution rather than a genuine improvement in predictive capacity. Therefore, future research should further examine the role of SMOTE in sports injury prediction to determine whether its reported benefits truly enhance model generalizability or merely compensate for distributional artifacts.
During model training, cross-validation is a commonly used technique,27–30,35 especially suitable for the small- to medium-sized datasets often seen in sports injury prediction studies. This approach repeatedly partitions the training and validation sets, thereby improving sample utilization and reducing the model's reliance on a single data split. In hyperparameter optimization, cross-validation is frequently employed as a performance evaluation technique, helping researchers select better parameter combinations and ultimately enhancing the model's stability and generalization ability.
Model evaluation
The goal of evaluating ML models is to quantify their generalization capacity to unseen data, thereby ensuring their effectiveness and reliability in practical applications. In sports injury prediction, tasks can be broadly divided into classification (e.g. determining whether an athlete will sustain an injury) and regression (e.g. estimating an athlete's injury risk score). For classification models, the confusion matrix serves as a fundamental analytical tool that visually illustrates the relationship between predicted and actual class labels (Table 2). From this matrix, a range of key performance metrics can be derived, including accuracy, precision, sensitivity (recall), specificity, and the F1-score, each offering insight into different aspects of model performance. 49 In this study, the confusion matrix is presented following the convention predominantly used in medical and clinical research, where actual outcomes are displayed as columns and predicted outcomes as rows. 50 This differs from the ML convention (rows for actual and columns for predicted), and acknowledging this distinction is essential to avoid misinterpretation in interdisciplinary contexts. The common formulas for evaluation metrics are shown in Table 3.
Confusion matrix for sports injury prediction.

TP: true positive; FP: false positive; FN: false negative; TN: true negative.
Performance metrics commonly used in sports injury prediction models.

TP: true positive; TN: true negative; FP: false positive; FN: false negative.
While the aforementioned metrics provide valuable insights into model performance, they are inherently threshold-dependent. To complement these metrics and evaluate the model's overall discriminative ability, AUC is also widely adopted in prediction studies. 51 Among the 13 included studies, 10 (77%) reported AUC as an evaluation metric. According to established standards, 52 most of these models (50%) demonstrated fair performance (AUC 0.70–0.79),24,27,28,31,34 while two studies reported the highest AUC.29,32 However, in clinical decision-making, AUC is typically interpreted alongside sensitivity and specificity, 30 allowing for a more comprehensive evaluation of model utility. To facilitate cross-study comparison, Table 4 provides a synthesis of reported accuracy, sensitivity, specificity, and F1-scores across the included studies.
Summary of model performance across studies.

Although AUC is widely employed in clinical research to evaluate model discrimination, greater model complexity does not necessarily translate into superior AUC performance. Existing evidence suggests that ML approaches are not always superior to traditional logistic regression in sports injury prediction. For example, Jauhiainen et al. 39 reported that, in predicting (anterior cruciate ligament (ACL)) injuries among elite female athletes, logistic regression achieved a higher AUC (0.65) than random forest (0.63), although both methods demonstrated poor discriminative ability and were largely unable to distinguish injured from non-injured individuals. Similarly, Oliver et al. 30 found that, when predicting injuries in elite male youth soccer players, logistic regression and ML yielded nearly identical AUC values (0.661 vs. 0.663), again indicating limited predictive performance. Even more strikingly, Ruddy et al. 26 observed that both approaches produced AUC values approaching randomness (AUC < 0.6) when applied to Australian elite football players. Nevertheless, it is important to note that comparable AUC values may mask substantial differences in sensitivity and specificity across methods. In Oliver et al.'s study, logistic regression heavily favored non-injury classification (sensitivity 15.2% and specificity 97.7%), whereas the ML model markedly improved sensitivity (74.2%) at the expense of specificity (55.6%). This indicates that, within the same prediction task, ML models provided a more balanced identification of high-risk individuals.
Taken together, these findings suggest that while ML approaches may not consistently outperform logistic regression in terms of AUC, their capacity to substantially enhance sensitivity may be more aligned with the clinical priorities of sports injury prediction, 53 where the accurate identification of high-risk athletes is often more critical than maximizing overall discriminative accuracy.
Model interpretation
In the development of sports injury prediction models, interpretability plays a pivotal role in identifying key factors that influence injury risk, such as training intensity, frequency, duration, as well as individual characteristics such as body mass index (BMI) and injury history. A deep understanding of the model's decision-making mechanisms not only facilitates the formulation of scientific and personalized prevention or intervention strategies by coaches, sports medicine specialists, and healthcare professionals but also enhances the credibility and transparency of the model in real-world applications. In recent years, SHAP, a model-agnostic interpretability method grounded in game-theoretic Shapley values, has been widely applied in the field of sports injury prediction.10,24 The notable advantage of SHAP lies in its ability to quantify the marginal contribution of each input feature to individual predictions and to visually capture the nonlinear relationships between feature values and predicted injury risk, thereby improving model transparency and interpretability. 54 However, it is essential to emphasize that SHAP values represent the model's internal assessment of the “importance” of features (i.e. potential risk factors for injury) and reflect statistical associations between input variables and prediction outcomes rather than direct causal relationships with real injury events.54,55 For example, in a given injury prediction model, if SHAP analysis identifies training intensity as a major contributing factor and assigns it a high SHAP value, this only indicates that training intensity substantially influences the model's risk prediction. It does not imply that increased training intensity directly leads to a higher injury risk. In practice, injury risk is often shaped by the complex interplay of multiple variables, such as an athlete's physical condition, psychological state, and prior injury history. These variables may interact under specific contexts to influence injury outcomes, but the mechanisms linking them are not necessarily causal. Therefore, while SHAP provides valuable quantitative insights into feature importance, its interpretation must be contextualized with domain expertise. Caution must be exercised to avoid misinterpreting statistical associations as causal inferences in applied settings.
Beyond providing general insights into feature importance, interpretable methods such as SHAP offer significant potential for enhancing the clinical utility of predictive models for specific injury types. For instance, in the ACL injury prediction model reported by Jauhiaainen et al., 33 multiple ML models were trained, yet the average predictive performance was modest (mean AUC = 0.63), and SHAP-based explanations were not applied. In this context, integrating conventional feature importance metrics with SHAP values can substantially improve both the interpretability and operational relevance of the model. Specifically, decision rules can be extracted from tree-based models (e.g. “Age > 23 years and single-leg eyes-closed standing time < 20 s indicate elevated risk”), and SHAP values can be employed to quantify the marginal contribution of each feature within these rules (e.g. SHAP value for age = 0.32, balance ability = 0.45). This combined approach enables clinicians to more precisely identify modifiable risk factors, thereby supporting targeted interventions such as balance training, and ultimately enhances the model's practical applicability and interpretative value in predicting specific injury outcomes.
Discussion
This narrative review provides a comprehensive overview of the research progress in the application of ML to sports injury prediction, with particular attention to the key components involved in model development and evaluation. These components include model selection and comparison, data preprocessing techniques, the application of core algorithms, evaluation metrics, and model interpretability. By integrating findings from existing studies, this review aims to offer scientific and structured guidance for researchers in this domain. Overall, existing studies indicate that effective implementation of feature engineering plays a pivotal role in enhancing model performance. Moreover, compared with traditional modeling approaches such as binary logistic regression, ML-based injury prediction models demonstrate superior sensitivity and greater practical applicability.
However, the present study also highlights a critical limitation in existing sports injury prediction research, namely the issue of sample selection. Most available models have been developed within relatively narrow contexts, predominantly focusing on elite male athletes, and are largely confined to sports such as football,10,26–31,35,36 basketball, 32 and handball. 27 This sample specificity constrains the external validity of these models, leading to potential systematic bias or distortion in predictive performance when applied to other populations. For instance, Bogaert et al. 56 demonstrated that sex differences substantially undermine model generalizability, as sex-specific models achieved higher AUCs (male: 0.62; female: 0.65) compared to the pooled “all-sample” model (0.56). Such limitations are not confined to sex differences alone but also extend to variations in competitive level. A one-year prospective study in runners of different performance levels revealed that injury-related risk factors varied according to running skill, 57 suggesting that prediction models developed for elite athletes may not be transferable to other athletic populations. Moreover, although many injury prediction models have demonstrated strong predictive performance, interpretability remains a major challenge in current research, limiting the practical application of these models in real-world scenarios. For instance, a traditional statistical study examining concussion risk among American football players found that teams with animal mascots appeared to have a lower injury rate. 58 While this conclusion did not arise from an ML model, it underscores the broader issue of spurious correlations and questionable causal inferences that may also emerge in data-driven research. To bridge the gap between algorithmic prediction and clinical application, this study proposes a three-stage closed-loop validation framework for the dynamic monitoring of training load and injury risk, coupled with individualized intervention. The framework draws on the work of Tsilimigkras et al. 36 in elite football players, who reported that sudden increases in high-speed and sprint running distances, as well as elevated heart rate metrics, may indicate heightened risk of muscle injury. Based on these insights, they introduced ACWR and DEV features to quantify short-term peaks and long-term cumulative deviations in training load. Building on this feature engineering, the present study systematically integrates ACWR and DEV into the prediction, intervention, and feedback stages to enable dynamic assessment and validation of injury risk. In the prediction stage, ACWR, DEV, and related features serve as input variables for supervised learning models, such as decision trees or random forests, to perform weekly injury risk assessments. High-risk individuals are identified using empirically validated probability thresholds (>60%), capturing both single-session workload spikes and cumulative deviations that may contribute to injury. During the intervention stage, individualized load management is applied to high-risk athletes, such as reductions in high-intensity training; these strategies have been demonstrated in the literature to effectively mitigate the impact of acute peaks and cumulative workload deviations on injury risk. In the feedback stage, injury incidence and subjective measures (e.g. fatigue, sleep quality, and training satisfaction) are continuously recorded, and model accuracy and intervention effectiveness are systematically evaluated using statistical approaches, such as mixed-effects models. The results inform iterative optimization of model parameters and training strategies, thereby enhancing the framework's scientific rigor and external applicability. Similarly, a recent study by Hwang et al. 59 demonstrated that ML models built on early rehabilitation data (3 months postoperatively) from ACL reconstruction patients effectively predicted patient-acceptable symptom state at 12 months, achieving an AUC of 0.84. These findings further support the feasibility and potential value of individualized interventions guided by early dynamic rehabilitation indicators.
This narrative review has several limitations. First, unlike systematic reviews or meta-analyses, narrative reviews inherently involve subjective decisions in study selection and weighting, which may introduce bias in the presentation of evidence. In addition, as the application of ML in sports injury prediction remains an emerging field, the available body of literature is limited. Consequently, we did not restrict our search to specific injury types or particular ML algorithms, which resulted in considerable heterogeneity among the included studies. Although most studies reported AUC values, direct comparisons of AUCs across studies do not provide a reliable assessment of the relative performance of different ML approaches, given variations in study populations, injury sites, included risk factors, and modeling strategies. These factors collectively limit the extent to which generalizable conclusions can be drawn.
Conclusion
This narrative review summarizes the current progress in applying ML to sports injury prediction, with a particular emphasis on the critical roles of feature selection, model development, performance evaluation, and interpretability in model construction. Although existing studies demonstrate promising potential, most models have been developed within single cohorts and lack external validation, raising substantial concerns regarding their generalizability and stability. Future research should therefore prioritize systematic validation across more diverse populations and real-world contexts, while further enhancing model interpretability to strengthen clinical translatability and practical utility.
Footnotes
Acknowledgements
The authors would like to thank all scholars whose work contributed to the development of this review. Artificial intelligence-assisted tools (ChatGPT and OpenAI) were employed exclusively for improving the readability and language of this manuscript. No AI tools were used in data analysis, study design, or drawing scientific conclusions.
Ethical considerations
The study was approved by the Ethics Committee of the Institute of Neuroscience and Cognitive Psychology at Anhui Polytechnic University (AHPU-PED-2022-001). Informed written consent was obtained from all participants prior to their involvement in the study.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Author contributions
Jin Yuan and Quanwen Zeng: Conceptualization. Jin Yuan, Zhengzhou Cong, and Quanwen Zeng: Data curation. Jin Yuan and Jun Li: Formal analysis. Jin Yuan, Quanwen Zeng, and Zhengzhou Cong: Investigation. Jun Li, Yong Zhang, and Zhengzhou Cong: Methodology. Yong Zhang: Project administration. Yong Zhang: Supervision. Jin Yuan: Writing—original draft. Jin Yuan, Quanwen Zeng, Yong Zhang, and Jun Li: Writing—review and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was support by the following funding: Key Project of Humanities and Social Sciences in Anhui Province Universities (2023AH050883 and 2024AH052247), Major Project of Philosophy and Social Sciences in Anhui Province Universities (2023AH040116), “Six Excellence and One Top-notch” Talent Training Innovation Project of Anhui Province (2020zyrc034), and Outstanding Research Team of Universities under Anhui Provincial Department of Education—“Cognitive Neuroscience Innovation Team” (2022AH010060).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
No new data were generated or analyzed in this study. All data cited in this review are available from the referenced sources.