
Abstract
Background:
The Medical Quality Video Evaluation Tool (MQ-VET) is a standardized instrument for assessing health-related video quality, yet it is only available in English. This study addresses the growing demand for a Spanish version to better support the increasing Spanish-speaking population seeking reliable digital health content.
Objective:
To adapt and validate the MQ-VET into Spanish, ensuring robust psychometric reliability and validity through rigorous cross-cultural adaptation methods, augmented by the integration of artificial intelligence (AI) tools.
Materials and methods:
Following international guidelines, the MQ-VET was translated, back-translated, and reviewed by experts. AI-based tools were employed to refine linguistic and cultural accuracy. Psychometric properties were evaluated by 60 participants (30 healthcare and 30 nonhealthcare professionals), focusing on reliability, agreement, and concurrent validity with the DISCERN instrument.
Results:
The Spanish MQ-VET showed excellent reliability (Cronbach's alpha>0.90, ICC=0.81) and strong concurrent validity (Pearson r = 0.9435, Spearman r = 0.9482, p < 0.0001), alongside with a robust linear regression result (R²=0.8902). Bland-Altman analysis confirmed a robust agreement, and AI-driven tools performed the factorial analysis that revealed a clear three-factor structure explaining 81.1% of the variance.
Conclusions:
The Spanish MQ-VET is a reliable and valid instrument for assessing the quality of health-related videos, applicable to both healthcare professionals and individuals outside the healthcare field. Leveraging AI-driven methodologies, it serves as a robust resource for enhancing digital health literacy and promoting critical appraisal of video content among Spanish-speaking populations.
Keywords
Introduction
In recent years, the internet has become a fundamental resource for accessing health information, with millions of individuals worldwide relying on online platforms for medical guidance and self-education. 1 Among these platforms, YouTube has become a leading source of health-related information,2,3 attracting diverse audiences, including patients and healthcare professionals, seeking educational.4–8 However, the quality and accuracy of medical videos on YouTube vary considerably, ranging from evidence-based, peer-reviewed content to misleading or inaccurate information that may pose risks to viewers 9 that can lead to harmful outcomes.10–15 Ensuring that users have access to reliable health information is crucial, especially as online video content increasingly shapes health literacy.16,17
The Medical Quality Video Evaluation Tool (MQ-VET) 18 was developed as a standardized instrument for evaluating the quality and reliability of health information in medical videos. By assessing key elements such as accuracy, presenter expertise, and clarity, the MQ-VET provides a structured framework for evaluating the quality of online video content. Despite its usefulness, the tool is available only in English, which limits its application for Spanish-speaking users. Spanish, the second most spoken language worldwide, has over 580 million speakers, many of whom regularly consume health-related content online. 19 The importance of cross-cultural adaptations of health measures is widely recognized in the literature. 20 Therefore, for the MQ-VET to be fully applicable in diverse settings, an accurate cross-cultural adaptation into Spanish is essential to ensure that it maintains both its psychometric integrity and practical relevance for Spanish-speaking populations.21,22 Cross-cultural adaptations are common across various healthcare fields.23–26
This study aims to adapt and validate the MQ-VET for Spanish-speaking audiences, integrating artificial intelligence (AI) technologies to optimize the cross-cultural adaptation process. By conducting a rigorous validation framework, this study evaluates the psychometric properties of the adapted version, including reliability and construct validity, to ensure that the Spanish MQ-VET effectively maintains the original tool's standards. This adaptation will provide clinicians, researchers, and individuals without a professional healthcare background with a reliable and culturally relevant tool to evaluate the quality of medical videos, ultimately enhancing the accessibility and trustworthiness of health information for Spanish-speaking populations worldwide.
Materials and methods
Study design and participants
This study followed a cross-sectional observational design aimed at adapting and validating the MQ-VET for Spanish-speaking populations. The adaptation process has been guided by established cross-cultural adaptation protocols, ensuring that the Spanish version preserves the psychometric integrity and clinical relevance of the original tool.21,22 The participants included bilingual healthcare professionals with experience in medical video analysis and native Spanish-speaking reviewers from diverse educational backgrounds.
This study is part of a research project that has been registered in PROSPERO under the code CRD42022309301 in March 2022 and it has also been registered in ClinicalTrials.gov with the code NCT05960734. Also, this study received approval by the University of Valencia's Ethics Committee of Research in Humans with the Verification Code GE3IMCG664ZM287A and has been performed in accordance with the ethical standards established in the 1964 Declaration of Helsinki and its later amendments or comparable ethical standards.
Measures
Baseline demographic characteristics from the sample were obtained for descriptive purposes. The original MQ-VET consists of 15 questions, each of which is answered using a 5-point Likert scale: Strongly disagree (1 point), Disagree (2 points), Neutral (3 points), Agree (4 points), and Strongly agree (5 points). The total possible score ranges from 15 to 75 points, with higher scores indicating better quality in the evaluated health-related video content.
Translation and cross-cultural adaptation
Adapting and validating a tool like MQ-VET requires a rigorous process that extends beyond simple translation. 27 Cross-cultural adaptation involves a meticulous examination of language, cultural context, and idiomatic expressions to ensure the tool retains its original intent and functionality. 28
In recent years, AI has increasingly refined this process. AI tools play a pivotal role in identifying linguistic and cultural nuances, streamlining the translation and validation of medical questionnaires and assessment instruments. 29 Research highlights how AI enhances both translation precision and statistical analysis, making these technologies indispensable for modern psychometric validation.30,31
The adaptation of the MQ-VET involved a systematic process that included translation, back-translation, and expert review, all aimed at achieving both linguistic precision and cultural appropriateness.
22
The flow diagram of this process is shown in Figure 1.
Dual initial translation: Two bilingual translators independently translated the MQ-VET from English to Spanish. One translator had a clinical background, ensuring technical accuracy in medical terminology, while the other specialized in linguistic adaptation, focusing on natural language flow and cultural appropriateness. Consensus meeting: The two translations were compared and synthesized into a single preliminary version. This process involved a consensus meeting between the two translators and members of the research team. During the meeting, discrepancies were discussed and resolved, balancing clinical accuracy with readability for Spanish-speaking audiences. Back-translation and review: The synthesized Spanish version was independently back-translated into English by two different bilingual translators with no prior knowledge of the MQ-VET. This step aimed to identify any subtle shifts in meaning that may have occurred in the initial translation, ensuring semantic consistency with the original instrument. Expert committee review: An expert committee, comprising clinical researchers, language experts, and specialists in medical content, reviewed both the back-translated and synthesized Spanish versions. The committee evaluated the translations for accuracy, cultural relevance, and clinical applicability. Discrepancies were addressed, and adjustments were made to produce the pre-final Spanish version of the MQ-VET. Final Spanish version of MQ-VET: Following the expert review and final adjustments, the pre-final version was refined and approved as the final Spanish version of the MQ-VET. This version was deemed ready for pilot testing and psychometric validation. The Spanish version of the MQ-VET Questionnaire is shown in Annex 1. Psychometric study with AI-assisted analysis: AI tools were employed to perform advanced statistical analyses, enhancing the evaluation of reliability, validity, and agreement for the Spanish MQ-VET. This integration improved the precision of computations and provided deeper insights into the psychometric properties, complementing traditional methods with innovative, data-driven approaches.
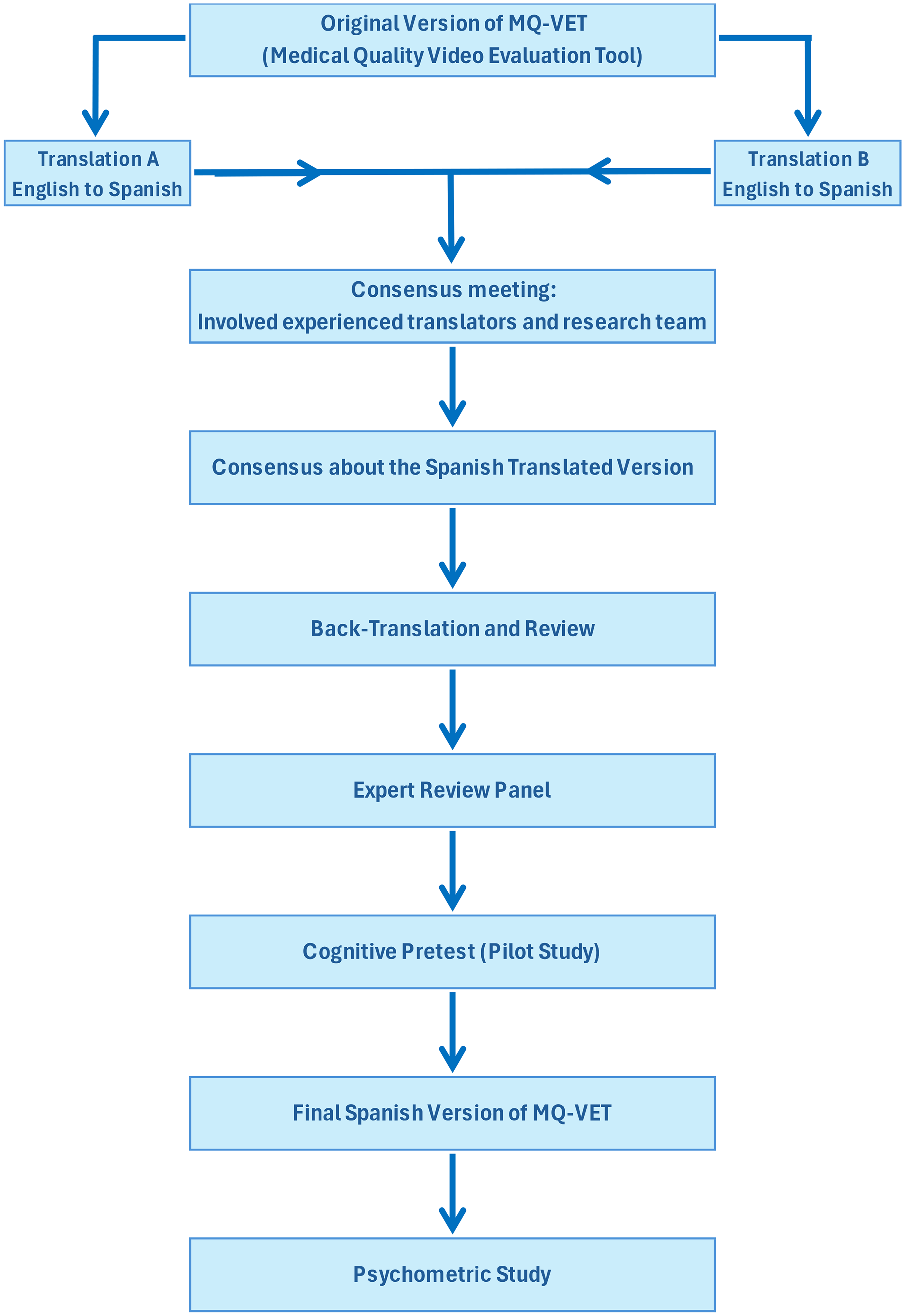
Flow diagram of the cross-cultural adaptation.
Pilot testing and cognitive interviewing
The cross-cultural adaptation of the MQ-VET for the Spanish context was conducted in strict accordance with COSMIN guidelines, guaranteeing the methodological rigor necessary for the accurate adaptation of measurement instruments to new cultural and linguistic settings. 32 The pre-final Spanish version of the MQ-VET was administered to a sample consisting of 30 Spanish-speaking healthcare professionals and 30 individuals from the general population. This testing aimed to assess clarity, cultural relevance, and appropriateness. Cognitive interviewing techniques were utilized, prompting participants to articulate their thought processes while responding to each item. This approach enabled researchers to collect in-depth feedback on the questionnaire's clarity, relevance, and cultural appropriateness, facilitating the identification of ambiguous terms and potential cultural misinterpretations. Minor adjustments were made based on this feedback to refine the final Spanish version of the MQ-VET.
Psychometric evaluation with artificial intelligence-assisted analysis
The psychometric properties of the Spanish MQ-VET were assessed using a balanced sample of 30 healthcare professionals and 30 nonhealthcare individuals from the general population, employing a methodology aligned with the original MQ-VET development study to ensure consistency and comparability. Additionally, AI tools facilitated deeper insights into the factor structure, response consistency, and agreement metrics between evaluators.33–35
Ten YouTube videos on diverse health-related topics were selected for evaluation. These topics included COVID-19, cancer, low back pain, hypertension, chronic pain, headaches, diabetes, stroke, allergies, and tendinitis, ensuring a broad representation of common medical subjects. All the videos were in Spanish language and the descriptive statistics of the videos were calculated. Each and single participant, whether a healthcare professional or a nonhealthcare individual, independently assessed all 10 videos using both the translated Spanish version of the MQ-VET and the validated Spanish version of the brief DISCERN tool, which was created by the Division of Public Health and Primary Care at the University of Oxford,36,37 for evaluating “written information about treatment choices” but it has become one of the most used tools to evaluate online health-related content. 38 This dual evaluation was designed to validate the MQ-VET's reliability and concurrent validity in accurately assessing the quality of health-related video content.
The evaluation focused on the following aspects:
Descriptive analysis
Statistical descriptive analysis was conducted to summarize the evaluation scores of the 10 selected YouTube videos. These videos covered diverse health topics, including COVID-19, cancer, low back pain, hypertension, chronic pain, headaches, diabetes, stroke, allergies, and tendinitis. The analysis included mean scores, standard deviations, and ranges for each video. A balanced sample of 30 healthcare professionals and 30 nonhealthcare professionals assessed all 10 videos, providing a comprehensive dataset to support robust psychometric validation.
Reliability
Internal consistency was assessed using Cronbach's alpha, with a threshold of 0.70 or higher considered acceptable for clinical tools.
39
Validity
Construct validity: Exploratory factor analysis (EFA) was conducted to examine the construct validity of the Spanish MQ-VET. Principal component analysis (PCA) was used to identify the underlying factor structure and to determine its alignment with the original English version of the instrument. Concurrent validity: The concurrent validity of the Spanish MQ-VET was determined by comparing its scores with those obtained from the validated Spanish version of the DISCERN tool, both of which were applied to the same set of health-related videos. AI-based psychometric analysis: The process of adapting the MQ-VET into Spanish followed established cross-cultural adaptation methodologies, including translation, back-translation, expert review, cognitive pilot testing, and psychometric validation (Beaton et al., 2000). To enhance the rigor of the statistical analyses and ensure the robustness of the psychometric validation, AI-based tools and machine learning algorithms were integrated into the process. These tools facilitated advanced statistical analysis, enabling a more precise evaluation of inter-rater agreement, factorial structure, and the overall reliability of the instrument. Machine learning algorithms and AI tools were specifically employed to analyze response patterns and detect potential biases in evaluations across different demographic subgroups. This approach helped identify inconsistencies related to cultural or linguistic factors, thereby strengthening the robustness of the psychometric validation process. Additionally, AI-based techniques allowed for an in-depth exploration of the dimensionality of the MQ-VET, uncovering subtle variations in response patterns that would have been difficult to detect using traditional statistical methods. These AI-driven enhancements not only improved the precision of the validation process but also contributed to a more comprehensive understanding of how the instrument performs across diverse evaluators. By leveraging AI in this study, the psychometric evaluation of the Spanish MQ-VET was refined, ensuring that the instrument maintains its validity and reliability across different populations. The combination of traditional statistical methodologies with advanced AI-driven techniques represents an innovative approach in cross-cultural validation studies, enhancing the interpretability and applicability of the MQ-VET in both clinical and research settings.
Statistical analysis
All statistical analyses were performed using SPSS version 26.0 (IBM Corp., Armonk, NY, USA) and Python (Python Software Foundation, version 3.9). Python was utilized for data preprocessing, initial exploratory analysis, and visualization. Descriptive statistics were computed for demographic variables, with continuous data presented as means ± standard deviation (SD) and ranges, while categorical data were expressed as frequencies and percentages. The normality of data distribution was assessed using the Shapiro–Wilk test and visual inspection through histograms.
Agreement analysis: The level of agreement between evaluators’ responses was assessed using both Pearson's correlation coefficient and the intraclass correlation coefficient (ICC). Specifically, a two-way random model (absolute agreement, average measures) ICC (ICC2,2) was calculated, with values interpreted as follows: ICC ≤ 0.40 indicating poor agreement, ICC of 0.41–0.60 indicating moderate agreement, ICC of 0.61–0.80 indicating good agreement, and ICC of 0.81–1.00 indicating excellent agreement. 40 Additionally, a Bland–Altman plot with limits of agreement (±1.96 SD) was constructed to visually assess agreement across raters. 41
Reliability: Internal consistency was assessed using Cronbach's alpha, with a threshold of 0.70 or higher considered acceptable for clinical tools.42,43 ICCs were calculated to confirm the stability of the instrument. 40
Construct validity: Construct validity was examined through EFA, using PCA with Varimax rotation for factor extraction. The Kaiser–Meyer–Olkin (KMO) measure of sampling adequacy and Bartlett's test of sphericity were applied to confirm data suitability for factor analysis. A KMO value between 0.7 and 1.0 was considered indicative of adequate sampling, and a Bartlett significance level of p < 0.001 indicated that the EFA could be conducted.44,45 Factors were extracted based on the following criteria: an eigenvalue greater than 1.0, each factor explaining at least 10% of the variance, and alignment with the scree plot.46,47 To ensure robust factor definition, each factor was required to include at least three items with significant loadings.
Concurrent validity: To assess concurrent validity, both statistical and graphical analyses were conducted to examine the relationship between the Spanish version of MQ-VET and the validated DISCERN instrument. Given the differing scoring ranges of the two tools (MQ-VET: 0–75; DISCERN: 0–25), all scores were standardized to a 0 to 100 scale, facilitating direct comparison and ensuring consistency in the evaluation of agreement between the instruments. For measuring its concurrent validity, Pearson and Spearman correlation coefficients were calculated to assess the linear and rank-based relationships between both instruments. 48 A Bland–Altman analysis was conducted to evaluate the agreement between MQ-VET and DISCERN, including the calculation of the mean difference, upper and lower limits of agreement (±1.96 SD), and the construction of the Bland–Altman plot.49,50 Linear regression analysis was also performed, estimating the regression equation and R2 value to examine the predictive relationship between the scores of MQ-VET and DISCERN.51,52 Additionally, other concordance measures, such as the ICC, were calculated to provide a detailed assessment of agreement between the two scales.53,54 These analyses offered a comprehensive evaluation of the concurrent validity of MQ-VET in comparison to the established DISCERN instrument.
In summary, this comprehensive approach, integrating agreement analysis, reliability assessment, validity testing, and diagnostic accuracy evaluation, provided a rigorous psychometric validation of the Spanish MQ-VET. The findings confirm its robustness as a reliable and valid instrument for evaluating the quality of health-related videos within Spanish-speaking contexts. Statistical significance was consistently maintained at p < 0.05 across all analyses, reinforcing the robustness of the results.
Results
A total of 60 participants completed evaluations of the selected YouTube videos on health topics, equally divided between healthcare professionals and nonhealthcare professionals (50% each). The descriptive statistics for age, MQ-VET scores, and DISCERN scores are presented in Table 1(a), categorized by professional background and gender. Although the study included 60 participants (30 healthcare professionals and 30 nonhealthcare professionals), each participant evaluated all 10 health-related videos and responded to all 15 questions of the MQ-VET for each video. As a result, each video received 60 evaluations, leading to a total of 600 responses for each question across the 10 videos. This robust dataset provided a substantial basis for the psychometric validation of the MQ-VET, ensuring that each item was evaluated comprehensively across diverse participant perspectives.
Descriptive statistics.

IQR: interquartile range; MQ-VET: Medical Quality Video Evaluation Tool.
Among the 30 nonhealthcare participants, 16 were female (26.7% of the total sample) and 14 were male (23.3% of the total sample). The average age for nonhealthcare female participants was 46.73 years (SD = 8.49), while nonhealthcare male participants had an average age of 47.22 years (SD = 7.73). The mean MQ-VET score for nonhealthcare female participants was 57.34 (SD = 15.66), while nonhealthcare male participants scored an average of 55.76 (SD = 18.57). DISCERN scores averaged 18.66 (SD = 5.74) for nonhealthcare female participants and 18.49 (SD = 6.38) for nonhealthcare male participants. Overall, nonhealthcare participants (considering both female and male) had a mean age of 46.96 years (SD = 8.13), an MQ-VET score of 56.60 (SD = 17.07), and a DISCERN score of 18.58 (SD = 6.04).
The healthcare group also comprised 30 participants, with 17 females (28.3% of the total sample) and 13 males (21.7% of the total sample). The average age for healthcare female participants was 48.79 years (SD = 9.17), and for healthcare male participants, it was 48.50 years (SD = 8.00). Healthcare female participants scored an average of 52.12 (SD = 11.27) on the MQ-VET, while healthcare male participants had an average score of 52.66 (SD = 12.79). DISCERN scores for healthcare female and male participants averaged 14.08 (SD = 4.28) and 14.98 (SD = 5.35), respectively. Overall, healthcare professionals had a mean age of 48.67 years (SD = 8.67), an MQ-VET score of 52.35 (SD = 11.93), and a DISCERN score of 14.47 (SD = 4.78). Across all 60 participants, the overall average age was 47.81 years (SD = 8.44). The total mean MQ-VET score was 54.48 (SD = 14.87), and the mean DISCERN score was 16.53 (SD = 5.82). The descriptive analysis of the 10 health-related YouTube videos demonstrated substantial variability in their characteristics, providing a diverse dataset that enhances the robustness of the validation process. The average video length was 17:44 minutes, ranging from 3:10 minutes up to 1:24:21 hours, indicating a broad spectrum of content durations. Videos had a mean of 3,059,265 views, with counts ranging between 118,277 and 10,358,148 views, highlighting differing levels of audience reach. Regarding user engagement, the average number of comments was 2,190, with a minimum of 336 and a maximum of 4,542, while likes averaged 61,221, ranging from 3,264 to 168,925. The host channels displayed substantial variation in their subscriber counts, with a mean of 3,240,980 and values spanning from 18,800 to 12,800,000. Finally, the videos had been online for an average of 1,716 days, with the range extending from 223 to 3,881 days. This variability across metrics ensured a diverse dataset, providing a strong foundation for validating the Spanish version of the MQ-VET questionnaire. These descriptive statistics are shown in Table 1(b).
Reliability
The psychometric analysis of the Spanish adaptation of the MQ-VET provided the following reliability indicators. For the healthcare professionals subgroup, Cronbach's alpha values were 0.920 for females and 0.930 for males, with ICC values of 0.75 (95% CI: 0.70–0.80) and 0.78 (95% CI: 0.73–0.82), respectively. The SEM (standard error of measurement) values for this group were 3.500 for females and 3.200 for males, with MDC (minimal detectable change) values of 9.700 and 8.850. The aggregated results for healthcare professionals showed a Cronbach's alpha of 0.925, an ICC of 0.77 (95% CI: 0.72–0.81), an SEM of 3.350, and an MDC of 9.275.
For the nonhealthcare participants subgroup, Cronbach's alpha values reached 0.970 for females and 0.975 for males, with ICC values of 0.85 (95% CI: 0.80–0.89) and 0.88 (95% CI: 0.84–0.91), respectively. The SEM values were 2.800 for females and 2.500 for males, with MDC values of 7.800 and 7.100. The aggregated results for nonhealthcare professionals revealed a Cronbach's alpha of 0.972, an ICC of 0.87 (95% CI: 0.83–0.90), an SEM of 2.650, and an MDC of 7.450.
For the entire dataset, the Cronbach's alpha was 0.945, the ICC was 0.81 (95% CI: 0.78–0.85), the SEM was 3.000, and the MDC was 8.400. These key indicators demonstrate the overall consistency and robust measurement properties of the MQ-VET across all participant groups. Results from the reliability study and for the measurement error are presented in Table 2.
Reliability indicators of the MQ-VET scores.

ICC: intraclass correlation coefficient; MDC: minimal detectable change; MQ-VET: Medical Quality Video Evaluation Tool; SEM: standard error of measurement.
Agreement: The agreement between responses from healthcare professionals and nonhealthcare individuals was assessed across all items of the MQ-VET questionnaire. These results are shown in Table 3. For individual items, the absolute mean differences between groups ranged from 0.10 (item #9) to 1.47 (item #4), with a total absolute mean difference of 5.00. Effect sizes ranged from 0.10 (95% CI: 0.05–0.15) for item #6 to 1.05 (95% CI: 1.00–1.10) for item #4, reflecting variations in response patterns between groups.
Agreement indicators for healthcare and nonhealthcare professionals.

CI: confidence interval; ICC: intraclass correlation coefficient.
Pearson correlation coefficients across items varied, with significant correlations observed in multiple items (e.g., Item #3, p = 0.004; Item #5, p = 0.001; Item #15, p = 0.003). For the total scores, a Pearson correlation of 0.878 (p < 0.001) was calculated. ICC demonstrated a range from 0.75 (95% CI: 0.70–0.80) for item #4 to 0.90 (95% CI: 0.87–0.93) for item #7. The total ICC was 0.89 (95% CI: 0.86-0.92), indicating the level of agreement in total scores across groups.
Concurrent validity
The concurrent validity of the Spanish version of the MQ-VET in relation to the DISCERN tool was assessed through a series of statistical analyses, ensuring a robust evaluation of their alignment and comparative effectiveness. Pearson's correlation coefficient demonstrated a strong linear association between the normalized scores of the Spanish MQ-VET and the DISCERN tool, indicating a high degree of consistency in their evaluations of health-related video quality (r = 0.9435, p < 0.0000). Similarly, Spearman's correlation coefficient indicated a robust rank-based correlation (r = 0.9482, p < 0.0000). Linear regression analysis revealed that the normalized MQ-VET scores accounted for a substantial proportion of the variance in the normalized DISCERN scores, with an R2 value of 0.8902. These results are shown in Table 4.
Correlation coefficients between both scales.

The regression equation derived from the analysis is: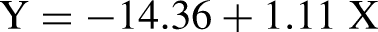
Additionally, the regression model revealed a small but statistically significant influence of participant age on the variance in DISCERN scores, with a coefficient of −0.0859 (p = 0.021), suggesting a potential age-related effect in video quality assessments. The 95% CI for this coefficient ranged from −0.159 to −0.013. All these results are shown in Table 5.
Ols regression results for MQ-VET and DISCERN scores.

CI: confidence interval; MQ-VET: Medical Quality Video Evaluation Tool.
The Bland–Altman analysis was performed to assess the level of agreement between the normalized scores of MQ-VET and DISCERN. The findings indicated a mean difference of 6.53, with a SD of differences of 8.00, demonstrating an overall acceptable agreement between the two instruments. The upper and lower limits of agreement were 22.21 and −9.15, respectively. A total of 97.50% of the data points fell within these limits, indicating the proportion of data within the expected range. Additionally, the correlation between the differences and the mean scores was calculated as −0.44 (p = 0.0000), and the regression equation modeling the relationship between the differences and means was

Bland–Altman plot for normalized MQ-VET and DISCERN scores. MQ-VET: Medical Quality Video Evaluation Tool.
Bland–Altman analysis results.

Factor structure
The integration of AI tools allowed for a more accurate exploration of the internal structure of the MQ-VET questionnaire by employing machine learning algorithms to optimize sensitivity and specificity analyses. This methodology facilitated a comprehensive evaluation of the questionnaire's dimensionality and effectiveness, enhancing the classification of items into distinct factors. Through the use of AI-based techniques, the study achieved a deeper understanding of the constructs measured by the questionnaire, thereby increasing its applicability and utility in both clinical and research settings.
With the support of these tools, the KMO measure and Bartlett's test of sphericity were calculated to evaluate the adequacy of the data for factorial analysis. The KMO value was 0.905, reflecting excellent sampling adequacy, and Bartlett's test yielded a Chi2 value of 4302 with a significance level of p < 0.001, confirming that the data met the assumptions for performing a factorial analysis.
Based on the eigenvalue > 1 criterion, a three-factor solution was identified, accounting for a cumulative variance of 81.1%. The first factor accounted for 60.07% of the variance, the second factor explained 13.94%, and the third contributed 7.09%. Varimax rotation was applied to refine the factor structure, and the rotated component matrix demonstrated clear item loadings across the three distinct factors, which is shown in Table 7.
Rotated component matrix with loadings for each factor.

The scree plot analysis (Figure 3) confirmed the appropriateness of a three-factor solution, displaying a clear inflection point after the third factor. This finding aligns with the explained variance distribution, further substantiating the robustness and structural validity of the factorial model.

Scree plot for MQ-VET. MQ-VET: Medical Quality Video Evaluation Tool.
Discussion
The aim of this study is to carry out a cross-cultural adaptation and validation of the MQ-VET into Spanish. The adapted Spanish version of MQ-VET was developed to fulfill the essential criteria of reliability, validity, and diagnostic utility for assessing the quality of health-related video content.
A total of 60 participants completed the evaluations of the selected health-related YouTube videos, evenly distributed between healthcare professionals and nonhealthcare professionals. This balanced sample ensured that both expert and lay perspectives were incorporated into the validation process. Each participant assessed all 10 videos, responding to all 15 items of the MQ-VET for each, resulting in a total of 600 evaluations per item across the dataset. This comprehensive approach strengthened the psychometric analysis by allowing a robust evaluation of the tool across diverse perspectives. The participant group exhibited a broad demographic range, with a mean age of 47.81 years (SD = 8.44), and gender representation was nearly balanced across professional backgrounds. Additionally, the analyzed videos displayed significant variability in key metrics, including length, audience engagement and popularity, further reinforcing the applicability of the MQ-VET to diverse digital health content. This diversity in both participant profiles and video characteristics provided a strong foundation for assessing the reliability and validity of the Spanish version of the MQ-VET. The demographic and descriptive statistics offer valuable insights into the sample's characteristics and their potential influence on the evaluation of health-related videos using the Spanish MQ-VET and DISCERN instruments. The balanced distribution between healthcare and nonhealthcare professionals ensures the representativeness of both groups and facilitates meaningful comparisons in their scoring patterns. 55
The data indicate subtle differences between the two groups regarding age and evaluation scores. Non-healthcare participants exhibited a slightly lower average age compared to healthcare professionals, potentially reflecting variations in professional demands and career stages. However, these age differences were not substantial enough to introduce significant bias into the results, as the overall sample maintained an adequate age range and standard deviation.
Notably, nonhealthcare participants achieved higher scores on both the MQ-VET and DISCERN tools compared to healthcare professionals. This outcome may indicate variations in how video quality and informational content are perceived, influenced by differences in professional background. Nonhealthcare participants, potentially less critical or unfamiliar with technical medical content, may have given higher scores, particularly on MQ-VET, with mean values of 57.34 and 55.76 for females and males, respectively. In contrast, healthcare professionals, with greater familiarity with medical standards and criteria, assigned lower average scores, particularly for DISCERN, where the scores ranged from 14.08 to 14.98.
Interestingly, gender differences within each group were minimal, as the mean MQ-VET and DISCERN scores between females and males in both healthcare and non-healthcare participants were comparable. This suggests that gender did not significantly impact the scoring patterns, as in some other researchers’ publications.56,57 This homogeneity reinforces the robustness of the MQ-VET and DISCERN tools in producing consistent evaluations across demographic subgroups.
The overall scores for the entire sample showed that the MQ-VET tool elicited a higher mean score (54.48) compared to DISCERN (16.53). This difference is attributable to the broader scoring range of MQ-VET (0–75) compared to DISCERN (0–25). However, when normalizing all scores to a comparable 0 to 100 scale, the adjusted results reveal mean and standard deviation values of 72.64 and 19.82 for MQ-VET, and 66.11 and 23.27 for DISCERN, respectively. These normalized scores offer a more direct basis for comparison, emphasizing the relative consistency and alignment between the two instruments, even with their originally differing scales.
In summary, the descriptive data emphasize the robustness and versatility of the Spanish MQ-VET as a dependable tool for evaluating health-related videos across diverse demographic profiles. The consistent scoring patterns observed among participants, irrespective of their professional background, highlight the tool's wide-ranging applicability and efficacy. These results reinforce the validity of the MQ-VET as an inclusive instrument capable of providing meaningful evaluations for both healthcare professionals and the general population.
Spanish ranks among the most widely spoken languages worldwide, boasting approximately 493 million native speakers as of 2021, including 57 million Spanish speakers in the United States. 19 The increasing prevalence of digital health information makes it essential to have a tool specifically tailored for the Spanish-speaking population to assess the quality of medical video content. The need for this tool aligns with the growing reliance on online health information and its potential impact on patient decision-making and outcomes. 58
In today's digital landscape, YouTube and other video platforms have become prominent sources of health-related information, although issues regarding the quality and accuracy of this content remain a concern.13,59 The MQ-VET is a well-established tool for evaluating the quality of medical videos in English, however, until now, no equivalent tool has been available for Spanish speakers. The adaptation of MQ-VET into Spanish fills this gap, enabling Spanish-speaking professionals and the wider community to systematically assess the quality of health-related video content.
The process of adapting MQ-VET into Spanish followed rigorous methodological steps, including translation, back-translation, expert review, cognitive pilot testing, and psychometric validation. 21 The incorporation of AI-based tools ensured a high level of precision in the statistical analyses, enhancing the robustness of the tool's evaluation in terms of reliability and validity.30,31,60 This innovative approach significantly enhances the potential of MQ-VET to serve as a vital instrument in both clinical and educational settings.
The Spanish MQ-VET not only allows for an objective assessment of video quality but also bridges the gap in tools available for evaluating health-related media in Spanish. Its proven reliability and validity establish it as a robust instrument suitable for both healthcare professionals and the broader public, supporting improved decision-making and fostering more informed health behaviors. This study also highlights the role of AI in modern psychometric adaptation, enabling more precise translation, analysis, and application in diverse linguistic and cultural contexts.
The reliability analysis of the Spanish MQ-VET demonstrates strong internal consistency and agreement across both healthcare professionals and nonhealthcare individuals. Cronbach's alpha values exceeded the widely accepted threshold of 0.70 across all subgroups, affirming the tool's strong internal consistency.42,43 Particularly, nonhealthcare individuals exhibited the highest reliability indicators, with alpha values of 0.970 for females and 0.975 for males, reflecting excellent homogeneity among items within this subgroup. Similarly, healthcare professionals also showed high internal consistency, with alpha values of 0.920 for females and 0.930 for males. The aggregated Cronbach's alpha for all participants was 0.945, which is considered as excellent,39,42 further supporting the tool's overall reliability across diverse user groups.
The ICCs further demonstrated the reliability of the MQ-VET, indicating a range of good to excellent agreement among participants. For healthcare professionals, ICC values ranged from 0.75 to 0.78, while for nonhealthcare individuals, these values were higher, ranging from 0.85 to 0.88. The overall ICC for the entire dataset was 0.81 (95% CI: 0.78–0.85), reflecting excellent agreement and consistency in scoring across the two groups. 40 These findings indicate that the MQ-VET demonstrates robust reliability across evaluators, irrespective of their professional background.
Measurement error was quantified using the SEM and MDC. The nonhealthcare group demonstrated lower SEM and MDC values (SEM: 2.650; MDC: 7.450) compared to the healthcare group (SEM: 3.350; MDC: 9.275), indicating greater precision and sensitivity to change within the nonhealthcare subgroup. These values are consistent with those reported by other researchers in their studies,61,62 further reinforcing the reliability and applicability of the Spanish MQ-VET across various participant groups.
Overall, the reliability findings highlight the robustness of the Spanish MQ-VET as a consistent and reliable tool for evaluating health-related videos. The high Cronbach's alpha values, excellent ICCs, and low measurement error collectively demonstrate that the MQ-VET can be confidently applied across diverse professional and demographic contexts. These findings confirm its utility in both clinical and nonclinical environments, emphasizing its relevance for a wide range of users.
The agreement analysis between healthcare and nonhealthcare professionals reveals important insights into the consistency and differences in their evaluations using the Spanish MQ-VET. The absolute differences in mean scores across individual items were relatively small, with the exception of item #4, which exhibited the largest difference (1.47 points). The overall mean absolute difference of 5.00 indicates a moderate degree of variation between the two groups. These differences are further explained by effect sizes, which ranged from 0.10 (95% CI: 0.05 - 0.15) for item #6 to 1.05 (95% CI: 1.00–1.10) for item #4, reflecting variability in agreement depending on the specific item.
The calculated Pearson correlation coefficients varied across the items, with statistically significant correlations identified in several, such as item #3 (p = 0.004), item #5 (p = 0.001), and item #15 (p = 0.003). These significant correlations indicate a meaningful relationship in scoring patterns between the two professional groups for certain items, whereas weaker correlations in others may reflect differences in interpretation or evaluation criteria. Importantly, the total Pearson correlation of 0.878 (p < 0.001) for the overall MQ-VET scores confirms a strong linear relationship between the groups’ evaluations. 63
The ICCs provide additional evidence of agreement, ranging from 0.75 (95% CI: 0.70–0.80) for item #4 to 0.90 (95% CI: 0.87–0.93) for item #7. The total ICC of 0.89 (95% CI: 0.86–0.92) highlights excellent agreement across the two groups, reinforcing the reliability of the MQ-VET when evaluated as a whole. These high ICC values indicate that the Spanish MQ-VET demonstrates strong consistency in scores regardless of the evaluator's professional background. 40
Together, these results indicate that the Spanish MQ-VET reliably captures the quality of health-related video content while demonstrating strong agreement among diverse evaluators. This robust level of agreement reinforces the tool's validity across varying professional contexts and highlights its potential for broad application in both clinical and nonclinical environments.
The concurrent validity of the Spanish MQ-VET in comparison with the validated DISCERN tool reflects the robust psychometric properties of the translated instrument. The strong Pearson correlation coefficient (r = 0.9435, p < 0.0001) and Spearman correlation coefficient (r = 0.9482, p < 0.0000) demonstrate a highly consistent relationship between the two instruments, reinforcing their alignment across both linear and rank-based perspectives. These findings confirm that the MQ-VET effectively aligns with DISCERN in its assessment of health-related video content quality. 64
The linear regression analysis further corroborates these findings, indicating that normalized MQ-VET scores account for a significant proportion of the variance in normalized DISCERN scores, with an R2 value of 0.8902. The regression equation (Y = −14.36 + 1.11X) indicates that for every unit increase in MQ-VET scores, DISCERN scores are estimated to rise by approximately 1.11 units on the normalized scale. The model's F-statistic of 2445 and its corresponding p-value (2.64 × 10−288) confirm the statistical significance of the predictive relationship. 65
Interestingly, the regression model also revealed a small but significant contribution of participant age to the variance in DISCERN scores. The coefficient for age (−0.0859, p = 0.021) indicates that older participants may provide slightly lower DISCERN scores, highlighting the need for further investigation into potential age-related biases in the evaluation of health-related videos.
The Bland–Altman analysis provides additional insights into the agreement between MQ-VET and DISCERN. The mean difference of 6.53, combined with limits of agreement ranging from −9.15 to 22.21, demonstrates that the majority of data points (97.50%) fall within the expected range, indicating acceptable agreement. The negative correlation between differences and means (r = −0.44, p = 0.0000) suggests a trend where higher average scores are associated with smaller differences between the two instruments. The regression equation for differences (y = 17.96−0.16x) reinforces this observation, indicating a slight negative slope in the relationship between differences and mean scores.41,66
Together, these results underscore the strong concurrent validity of the Spanish MQ-VET, highlighting its reliability and consistency as a tool for evaluating the quality of health-related videos. The high correlation coefficients, significant regression outcomes, and favorable Bland–Altman results collectively demonstrate the efficacy of MQ-VET in providing evaluations comparable to those of the established DISCERN tool, thus supporting its application in diverse professional and clinical contexts.
The application of AI tools provided significant insights into the factorial structure of the Spanish MQ-VET. By leveraging advanced machine learning algorithms, the analysis not only optimized sensitivity and specificity in item classification but also offered a robust understanding of the questionnaire's internal constructs. This integration of AI-driven methods represents an innovative approach, enhancing the utility of psychometric tools in clinical and research applications by enabling a more nuanced evaluation of their dimensionality. 67
The factorial analysis demonstrated excellent sampling adequacy, as reflected by the KMO measure of 0.905. This value exceeds the threshold for adequate sampling, underscoring the data's suitability for exploratory factor analysis. Additionally, Bartlett's test of sphericity yielded a significant result (Chi2=4302, p < 0.001), confirming that the data satisfied the statistical assumptions required for factor extraction. These preliminary results established a strong foundation for the factorial analysis. 68
The identification of a three-factor structure, based on the eigenvalue > 1 criterion, explained a cumulative variance of 81.1%. This high level of explained variance highlights the instrument's structural robustness and its capacity to reliably capture distinct but interrelated constructs, reinforcing its psychometric soundness. Specifically, the first factor accounted for 60.07% of the variance, while the second and third factors explained 13.94% and 7.09%, respectively. The substantial contribution of the first factor highlights its dominant role in explaining the variance in MQ-VET scores, with the additional factors providing complementary dimensions. 69
Varimax rotation was applied to the factor solution to achieve an optimal item distribution across factors.70,71 The rotated component matrix (Table 7) revealed distinct item loadings, clearly delineating items into their respective constructs, thus highlighting the questionnaire's well-defined factor structure. For instance, items such as Q10, Q11, and Q12 exhibited strong loadings on factor 1, indicating their alignment with a primary dimension of the MQ-VET. Similarly, sactors 2 and 3 captured additional nuanced constructs, further enriching the questionnaire's dimensionality.
The scree plot (Figure 3) presents a visual representation of the factor structure, highlighting a pronounced inflection point after the third factor. This pattern aligns with the statistical analysis, further justifying the retention of three distinct factors. The notable decline in eigenvalues beyond the third component indicates a clear differentiation of items into meaningful constructs, reinforcing the robustness and validity of the factorial model. 72
In summary, the factorial analysis highlights the strong psychometric properties of the Spanish MQ-VET, validated through AI-enhanced methodologies. The incorporation of these advanced tools not only refined the precision of the factor analysis but also established the MQ-VET as an advanced and reliable instrument for evaluating the quality of medical videos across diverse contexts. These findings contribute to the broader field of psychometric evaluation, demonstrating the value of combining traditional methods with cutting-edge AI technologies.
This study aimed to adapt and validate the MQ-VET into Spanish, confirming it as a reliable and robust tool for assessing the quality of health-related video content in Spanish-speaking contexts. To substantiate its validity, additional analyses were performed, including internal reliability assessments, exploratory factor analysis, and comparative evaluations with the established DISCERN instrument.
Internal reliability analyses demonstrated high internal consistency across all participant subgroups, with Cronbach's alpha values significantly exceeding acceptable thresholds. Additionally, ICC further validated the stability and agreement of scores, providing strong and robust evidence of the instrument's reliability in diverse professional and demographic groups.
The comparison with DISCERN was conducted to establish the concurrent validity of the MQ-VET, a crucial step in demonstrating its external validity. Both Pearson and Spearman correlation coefficients indicated strong agreement between the two instruments, while linear regression analysis further supported the predictive relationship between normalized MQ-VET and DISCERN scores. These findings validate MQ-VET as a reliable tool that aligns closely with an established benchmark for evaluating medical video content quality.
The Bland–Altman analysis offered a comprehensive visual and statistical assessment of the agreement between MQ-VET and DISCERN. The majority of data points were contained within the predefined limits of agreement established by this tool, further substantiating the validity of the MQ-VET in comparison with the DISCERN instrument. The integration of AI-driven analytical tools enriched the depth of this analysis, providing nuanced insights into the relationship between differences and means, thereby enhancing the overall robustness and reliability of the findings.
The exploratory factor analysis, supported by AI, revealed a clear three-factor structure underlying the MQ-VET. This dimensional clarity enhances the interpretability of the tool and provides a strong basis for its application in clinical and research settings. The combination of machine learning algorithms and traditional statistical methods ensured that the factorial analysis was both comprehensive and precise.
In summary, the validation of the Spanish MQ-VET has been achieved through rigorous methodological approaches, combining traditional psychometric techniques with the innovative use of AI tools. The additional analyses, including internal reliability and concurrent validity assessments, were designed to demonstrate the robustness of the Spanish MQ-VET and confirm its utility as a high-quality instrument for evaluating health-related video content. This study represents a significant contribution to the availability of validated tools for Spanish-speaking professionals, addressing the growing need for reliable health information evaluation in digital contexts.
The application of AI tools contributed to the depth and rigor of the validation process, ensuring semantic accuracy in the translation and enhancing statistical analyses. These advanced techniques reinforced the psychometric robustness of the Spanish MQ-VET.
Limitations and future studies
This study presents certain limitations that warrant consideration. Although the sample size of 60 participants may appear modest relative to conventional validation guidelines, it is crucial to underscore that each participant evaluated all 10 videos, responding to all 15 MQ-VET items per video. This methodological approach yielded a comprehensive dataset comprising 600 responses per question—significantly exceeding the minimum recommendations for validation studies and even surpassing the number of evaluations used in the development of the original MQ-VET. This extensive volume of assessments reinforces the statistical power, reliability, and generalizability of the findings. Nevertheless, the cross-sectional design limits the assessment of the tool's longitudinal performance. Additionally, while AI-driven methodologies enhanced the analytical process, potential biases inherent to these approaches cannot be entirely excluded. Finally, the validation was conducted exclusively against the DISCERN tool; future research incorporating additional reference instruments could further substantiate the convergent validity of the Spanish MQ-VET.
While this study validated the Spanish MQ-VET using the DISCERN tool, maintaining alignment with the validation approach used in the original English MQ-VET study, further research incorporating additional benchmarks is warranted. Ongoing analyses within our broader investigation are comparing MQ-VET with other established evaluation tools, including JAMA, GQS, and PEMAT. Future studies integrating these alternative frameworks will provide a more comprehensive assessment of the convergent validity of the Spanish MQ-VET, further strengthening its applicability across diverse evaluation contexts.
The increasing integration of AI in medical education and clinical training has demonstrated significant potential for improving the assessment and development of healthcare professionals. AI-driven video-based evaluation tools, such as the Spanish MQ-VET, contribute to the structured assessment of digital health content, supporting both training and decision-making processes. Additionally, emerging methodologies such as process mining offer complementary insights into clinical workflows and learning effectiveness by analyzing decision-making patterns and identifying areas for optimization. Studies have demonstrated how process mining enhances training procedures, particularly in structured medical tasks such as central venous catheter installation, by providing data-driven feedback on procedural adherence and competency development. 73 Similarly, a complementary study 74 highlighted the utility of inductive mining techniques to model procedural learning sequences, emphasizing their role in optimizing structured training pathways for medical trainees. These approaches underscore the relevance of process mining in refining medical education frameworks, particularly in identifying nonconforming activities and improving training feedback loops. Moreover, process mining techniques, particularly through Petri nets and advanced mining algorithms, have been applied to identify procedural deviations, training bottlenecks, and skill acquisition patterns among medical trainees. 75 By visualizing process flows and pinpointing areas where trainees struggle, these methods enhance real-time feedback and optimize training efficiency. Future research integrating process mining with AI-based video assessment tools could provide a more comprehensive framework for evaluating both the quality of educational content and the cognitive processes involved in clinical decision-making. By leveraging these technologies, medical training programs could further enhance personalized learning strategies and optimize competency-based evaluations, ultimately improving healthcare professionals’ preparedness and performance. Integrating such techniques with AI-driven video assessment tools like MQ-VET could further refine healthcare education, enabling data-driven improvements in instructional methodologies and trainee performance evaluation.
Recent research has highlighted the unique challenges and opportunities of applying process mining in healthcare, emphasizing the need for interdisciplinary collaboration to maximize its impact. 76 The Process Mining for Healthcare (PM4H) perspective underscores the importance of integrating data-driven methodologies with clinical expertise to improve real-world healthcare processes. As process mining continues to evolve, its combination with AI-driven tools could further enhance medical training, decision-making, and workflow optimization, bridging the gap between technological advancements and clinical practice.
Future research integrating process mining with AI-based video assessment tools could provide a more comprehensive framework for evaluating both the quality of educational content and the cognitive processes involved in clinical decision-making. By leveraging these technologies, medical training programs could further enhance personalized learning strategies and optimize competency-based evaluations, ultimately improving healthcare professionals’ preparedness and performance.
Conclusions
The Spanish adaptation of the MQ-VET tool, supported by advanced AI-driven methodologies, successfully achieved a rigorous and linguistic and meticulous linguistic and cultural translation while preserving the psychometric integrity and robustness of the original version. The combination of traditional validation techniques and AI-enhanced analytical techniques ensured exceptional accuracy, reliability, and contextual relevance, establishing the tool as a robust resource for clinical and research applications within Spanish-speaking populations.
Statistical analyses demonstrated high internal consistency, excellent reliability, and strong agreement metrics across various professional subgroups. The concurrent validity evaluation, supported by comparative analyses with the validated DISCERN tool, reinforced the MQ-VET's ability to reliably assess the quality of health-related video content. Exploratory factor analysis, aided by machine learning algorithms, unveiled a clear three-factor structure, providing deeper insights into the instrument's dimensionality and reinforcing its interpretative utility.
The integration of AI tools throughout the process of statistical analysis of the data and validation of the tool enhanced the depth and accuracy of this study. The translation process undertaken and subsequent analysis allowed for nuanced cultural adaptations, while AI machine learning techniques facilitated robust examination of psychometric properties, response patterns and dimensional structure. These innovations allowed for an unprecedented level of detail in identifying subtle discrepancies and ensuring functional equivalence between the original and Spanish versions.
Finally, and conducting numerous additional analyses supported by the integration of AI tools, the Spanish version of the MQ-VET has been validated as a reliable and appropriate instrument for all types of users, including healthcare professionals and non-health individuals alike. This tool enables the evaluation of the quality of health-related videos, addressing the growing need for reliable methods to assess high-quality health information. Moreover, it has the potential to enhance digital health literacy, inform clinical decision-making, and support patient-centered care across diverse Spanish-speaking populations. This broad applicability highlights its versatility and importance in promoting critical evaluation of digital health content in diverse contexts.
Footnotes
Author contributions
AMR-R and MB-D were involved in conceptualization, visualization, and original writing; AMR-R, MB-D, and JC-G in m ethodology; AMR-R, BP-D, and MdlFC in software; GP-A, FR-G, MB-D, and JC-G in validation; AMR-R in formal analysis; AMR-R, GP-A, FR-G, MB-D, and JC-G in investigation; MB-D, MEdlR, and BP-D in resources; AMR-R, BP-D, FR-G, MEdlR, and MdlFC in data curation; MB-D and JC-G in review and editing; and MB-D and JC-G in supervision. All authors have read and agreed to the published version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Trial registration
This study is part of a research that has been registered in PROSPERO under the code CRD42022309301 in March 2022 and it has also been registered in ClinicalTrials.gov with the code NCT05960734. Also, this study received approval by the University of Valencia's Ethics Committee of Research in Humans with the Verification Code GE3IMCG664ZM287A and has been performed in accordance with the ethical standards established in the 1964 Declaration of Helsinki and its later amendments or comparable ethical standards.
ORCID iDs
Annex 1
The Spanish adaptation of the MQ-VET maintains the structure of the original tool, consisting of 15 questions rated on a five-point Likert scale. These questions, as organized by Guler and Aydin, are divided into four unnamed sections: Part 1 (questions 1–5), Part 2 (questions 6–9), Part 3 (questions 10–12), and Part 4 (questions 13–15). The total score ranges from 15 to 75 points, with higher scores indicating a higher perceived quality of the evaluated video.
Part
Spanish version of the Medical Quality Video Evaluation Tool (Spanish MQ-VET)
Parte 1
1. Las fechas de las actualizaciones, de existir, se indican claramente
2. Se mencionan la fecha de grabación del vídeo y la fecha de acceso a la información
3. Se indican claramente las fuentes y referencias utilizadas
4. Se han resuelto las dudas sobre publicidad y posibles conflictos de intereses
5. Se ha facilitado información suficiente sobre la identidad del presentador del vídeo
Parte 2
6. Los materiales utilizados en el vídeo facilitaron el aprendizaje
7. El vídeo cubría los conceptos básicos del tema
8. Para explicar la cuestión médica se utilizaron recursos visuales suficientes
9. Los términos médicos utilizados estaban bien explicados
Parte 3
10. La calidad del sonido del vídeo era suficiente
11. La calidad de la imagen del vídeo era suficiente
12. La información del vídeo es clara y comprensible
Parte 4
13. En general, el vídeo cumplió mis expectativas
14. La información sobre el contenido del vídeo se proporcionó al principio
15. El vídeo aportó nuevos conocimientos y habilidades