
Abstract
This article reviews recent studies applying machine learning (ML) approaches to biochar applications. We first briefly introduce the general biochar production process. Various aspects are contained, including the biochar application in the elimination of heavy metals and/or organic compounds and the biochar application in environmental and economic scopes, for instance, food security, energy, and carbon emission. The utilization of ML methods, including ANN, RF, and NN, plays a vital role in evaluating and predicting the efficiency of biochar absorption. It has been proved that ML methods can validly predict the adsorption effectiveness of biochar for water heavy metals with higher accuracy. Moreover, the literature proposed a comprehensive data-driven model to forecast biochar yield and compositions under various biomass input feedstock and different pyrolysis criteria. They said a 12.7% improvement in prediction accuracy compared to the existing literature. However, it might need further optimization in this direction. In summary, this review concludes increasing studies that a well-trained ML method can sufficiently reduce the number of experiment trials and working times associated with higher prediction accuracy. Moreover, further studies on ML applications are needed to optimize the trade-off between biochar yield and its composition.
Introduction
During the last decades, people gradually realized the importance of food security, ecological security, and reduction of greenhouse gas emissions; the biochar application in environment, resource, and agriculture-related fields has grown significantly, such as biochar is used in sustainable development with respective in carbon emission reduction, increasing soil fertility, and agricultural management. 1 However, what is the concept of biochar? According to the International Biochar Initiative (IBI) 2013, biochar is a solid good produced from biomass thermochemical transformation in anoxic conditions. The positive side of biochar application consists of alleviating environmental pollution, increasing resource use efficiency, reducing greenhouse gas emissions, and improving soil fertility. 2 These features further affirm the reason for the growing studies of biochar application.
Some literature reviewed the concepts of biochar from various perspectives; not only has recalled the biochar application but also introduced research findings and its associated production technologies of biochar. 3 They also summarized the current issues of biochar application in environment, energy, and agriculture-related fields. Meanwhile, a review of biochar from the perspectives of its production, interaction mechanism, computational approach, etc. briefly introduced how computational methods like artificial neural network (ANN) algorithms, machine learning (ML) approaches, and density functional theory (DFT) are associated with biochar application. Biochar could be used as an additive during adsorption processes, while the utilization of DFT calculations helps in the prediction effectiveness in biochar adsorption scenarios. 4 Since researchers want to use artificial intelligence to simulate the function features of the human brain and neural system in the aspects of learning and memorizing,5,6 ANN algorithms were therefore developed based on the analogy made between programming languages processing and human brain system. In other words, ANN models is a man-made algorithm via programming languages dealing with a specific task by replicating the brain's function. 7
ML is an artificial intelligence application that allows people predict outcomes using software without rigorous programming. 8 Moreover, an important feature of ML is the ability to learn from and deal with a complex and large, multidimensional dataset. 9 Neural networks (NN) and Random forest (RF) are two types of ML methods; in practice, NN and RF methods have been employed to monitor the part of polluting/poisonous substances in groundwater.10,11 These are two examples of how scholars applied ML to their interest topics. A study reported that the RF-based methods outperformed the ANN-based approach in terms of the ability to generalization. In specific, the RMSE reported by the developed model with all inputs was 3%–19% lower than the ones with partial inputs. 12 In terms of prediction accuracy, a better-developed model means could largely save the working loading in the experiment. For example, when studying the predicting problem of the performance of applying biochar to remove the considered metals, a better-developed model could base on biochar characteristics to pick effective biochar and keep the experimental workload nearly unchanged.
In addition, ML models can be employed to predict the nonlinear nexus of considered variables in complex systems.
13
However, the complex biochar-soil interaction and the limitation of the systematic dataset restrict researchers from improving the prediction of biochar efficiency based on an ML-based method, particularly regarding heavy metals (HMs) contamination. A Kriging-LFER model was developed based on more than 1500 datasets from previous studies, and their results showed that their model has an advantage regarding the accuracy and predicted results in an adsorption study, in specific, when using biochar as an absorbent, the prediction performance in terms of
We could see increasing studies on using ML methods on biochar. This review contributes to the literature on collecting updated papers regarding ML in the evaluation and prediction models of biochar applications and biochar yield. From the aforementioned examples, the application of ML does improve prediction accuracy. A better-developed model could significantly reduce the experiment workload in terms of prediction accuracy. The decreased experimental times feature means we can reach similar results with less expenditure. Furthermore, the updated research showed that a comprehensive data-driven ML model makes it possible to predict biochar yield and compositions under various biomass input feedstock and different pyrolysis criteria. Further related optimization studies are still needed in the aspects of the trade-off of biochar yield and its composition. In this direction, this review covers literature on ML in evaluation and prediction models for biochar applications. The first part of this review briefly introduces the related biochar production methods and application issues of biochar in the environment, resource, and agriculture-related fields. The introduces the applications of RF, NN, and ANN analysis and the updated studies results on ML applications followed. This review article provides researchers with results into the current stages in the assessment and prediction models of ML applications in biochar in a sustainable manner.
Conventional biochar production
With the growing awareness of ecological security, environmentally friendly, and food security, we see more and more studies exploring the positive role of biochar in the environment, resource, and agriculture-related fields. Conventional biochar production methods include many approaches; here, we name a few and the most common forms in subsections.
Pyrolytic carbonization
In pyrolytic carbonization, with the environment of an oxygen-starved, i.e. the circumstance of a limited oxygen supply or no oxygen, the decomposition of biomass occurs at the range of 300°C–900°C, which is generally less than temperatures 700°C. 15 Usually, pyrolysis contains three different statuses; with different status temperatures and residence time, the decomposition of biomass would produce liquid, gaseous, and solid products, respectively. 16 At first, slow pyrolysis means keeping the temperature at less than 500°C with the heating rate kept at a residence time of 0.05°C per second. Slow pyrolysis aims to maximize biochar yield; moreover, the low heating rates are features of slow pyrolysis with a relatively long residence time. 17 In contrast, fast pyrolysis demonstrated good advantages in producing bio-oil yield; the features of fast pyrolysis are very effective heating rates which are higher than 200°C per minute; the residence times are short. Lastly, biochar, liquid, and non-condensable gaseous products are produced within the intermediate temperature of around 500°C to 700°C and 2 to 10 s residence time. 16
Gasification carbonization
Gasification is another thermochemical conversion having an oxidizing agent participate.17,18 The temperature for Gasified carbonization is high, usually higher than 700°C. The residence time is short. The primary product generated from Biomass gasification is syngas. However, as a by-product of this process, 18 biochar retained from gasification could be utilized in a variety of application aspects due to its desirable features, e.g. small particle size; strong resistance toward chemical oxidation, etc. 3
Hydrothermal carbonization
Hydrothermal carbonization is another thermochemical conversion method to produce biochar. The biochar yields from hydrothermal carbonization are comparable with the ones from slow pyrolysis. Hydrothermal carbonization takes feedstocks heated to 200°C to 300°C temperature in closed conditions and maintained with low pressure. 19 Then, it took several hours for biochar related products to be produced by suspending the biomass in high-pressure water in the above circumstance. However, biochar from this process is usually low stable due to its alkane structures.9,12,20
Flash carbonization
The needed temperature for flash carbonization is around 300°C–600°C; at most 30 min is the required residence time. 21 The mechanism involves fire moving upwards while airflow moves downwards. 18 Therefore, feedstocks would convert to gaseous and solid products. Biochar yields from flash carbonization are close to those produced by slow pyrolysis.
In sum, biomass pyrolytic carbonization could be divided into internal/external heat, and spontaneous combustion according to the heat source; and slow/intermediate/fast pyrolytic carbonization for different heat transfer rates and residence time. For instance, slow pyrolysis takes a long residence time with a low heating rate. While, for intermediate pyrolysis carbonization, the residence time generally takes 5–30 min. The fast pyrolytic carbonization takes around 1–2 min to heat feedstocks of fine-grained biomass to 400°C–700°C because of its high heating rate. It is worth noticing that this bio-oil-targeted processing system requires feedstocks with less than 10% moisture content and short gas residence times which is less than 5 s. Among the above-mentioned biochar production technology, slow pyrolytic has the highest economic feasibility in terms of its biochar yield and technological maturity. 22 Though biochar yield from Hydrothermal carbonization is relatively high, the stability of biochar from the Hydrothermal process is usually low. Table 1 summarizes the comparison of the conventional approaches to generating biochar.
Conventional technology in generating biochar.

Applications of biochar
Many environmental-related problems are alleviated with the wide application of biochars. In the subsequent sections, we briefly introduce the consequence of biochar applications in food production, disease resistance, carbon emission reduction, and energy.
Biochar and food production
Regarding the role of biochar in food production, biochar influences the way that people manage farmland because the organic carbon content in the soil will increase due to the organic carbon and minerals in the biochar.1,2,31,32 Cultivating biochar into the soil positively affects soil properties not only on crop yield and fertility but also influences fertilizer conditions and water-keeping capacity. 33 Moreover, for soil with relatively poor properties, with the aid of biochar hydrogels, it is possible to convert degraded land into a fertile field. 34 Thus, biochar application might alleviate potential pressing issues in food production through the effect of increasing soil fertility. Therefore, using biochar as a soil amendment could promote crop yield. 2
Moreover, biochar also has a positive impact on fish products; the protein levels of Nile tilapia have been raised by adding biochar to the fodder. 35 The fear of a food crisis might be alleviated by increasing food production. In this subsection, we briefly introduce the application of biochar in food production from the perspective of biochar on crop yield. The amount of biochar utilization is also an essential factor in crop yield. In general, biochar affects crop yield positively; studies show that the influence of biochar is even more significant in less fertile land than in rich or less problematic ones. 36
Field research in the Amazon River within Brazil provided evidence on biochar and rice and sorghum yield. There was a 75% increment in grain yield after four growing seasons by applying biochar (11 t
Biochar and carbon emission reduction
The research on the utilization of biochar has been applied to control greenhouse gas emissions, increase soil carbon sinks, remediate contaminated soils, etc. In this subsection, our focus is on the development of biochar in the issue of carbon emission reduction.
We learned from the literature that biochar influences carbon and nitrogen transformation processes in soils. For instance, because of the negative priming effect, the application of biochar could reduce soil
Although reports have shown positive results of biochar application on soil N cycling, utilizing different management practices and application methods on soil with distinct properties might be the reason for literature reporting distinct effects on the application of biochar.54–56 Considering the cases of applying biochar to soil
In addition to how the utilization of biochar influences soil
Biochar and energy
In a fold of biochar applications and energy, biochar could be used as a new type of fuel, bio-slurry, also known as bio-oil. Using of bio-oil could help overcome some limitations that come from the application of biomass, including bad grindability, considerable transportation costs, and not working efficiently with coal. 2 Moreover, adding biochar microparticles significantly increased the burning rate of foamed emulsions. 62 In addition to bio-oil, charcoal is also considered a high-quality energy source because biochar and coal have comparable calorific values and H/C and O/C ratios 63 ; hence, biochar could serve as a potential alternative for fossil fuels. We learned from the literature that by (1) finding the best pyrolysis process and (2) enlarging the surface area via lowering the size of particles, biochar could have similar bursting characteristics and better calorific value than clean and pulverized coal.64,65 Furthermore, more research shows that the mixed burning of biochar and coal has better conversion efficiency and combustion characteristics than coal. The reason is that adding biochar could effectively lower the temperatures for fuel mixtures’ ignition and burnout.66–68 Taking this feature into consideration, we might conclude that large-scale biochar applications might be helpful in the alleviation of climate change. The reason is that the mixed burning of biochar and coal is better than using coal solely. Given that the coal-based plant is still a major way of generating electricity, the replacement of a certain portion of coal with a mix of biochar and coal might help reduce the climate change issue due to the utilization of coal. But there is one thing worth mentioning in this argument based on the assumption that the current coal-based plant is compatible with a mixture of biochar and coal.
Moreover, in the past decades, world economic development highly depended on the oil industry's flourishing and production. There might be an excess demand for the oil market. To alleviate the potential influence caused by above reasons, one possible solution for this problem is to substitute oil-based fuels with renewable bio-based fuels. 69 This subsection demonstrated that biochar could have much potential in the application of energy in the future.
Biochar and removal of undesired substance
Biochar can be utilized in the issue of dealing with organic compounds. In polluted water, there are often volatile organic compounds, pesticides, nitrogen compounds, plastic raw materials, etc. These compounds are usually removed by adding oxidants such as Fenton's reagent,
In addition, biochar applications include the removal of heavy metals. With the advancement of technology, electroplating, mining, batteries, textiles, metal finishing, concentrates, fertilizers, leather, paper, and other industries are booming, making today's environment more affected by heavy metal (HM) releases than before, such as cadmium, chromium, lead, copper, mercury, etc. 3 However, long-term accumulation of this HM can have lethal effects on all organisms. To protect organisms from the risk of exposure to heavy metals, HM must be removed from various effluents by employing suitable techniques. The advantage of removing HM also reflects on the perspective of food security, which is not only concerned about the stability of food production but also should consider the food quality in terms of the portion of HM contains in crops. Polluted water may directly/indirectly affect the nearby farmland. From this point of view, removing HMs from contaminated water, therefore, plays a vital role in the chain of improving food security. Several typical processes can be used to remove HMs from industrial effluents, just name a few of those methods: ion exchange method, ultrafiltration method, flotation method, chemical precipitation method, reverse osmosis method, adsorption, etc.76,77 From the perspective of minimizing removal cost and fewer potential secondary issues such as sludge formation, disposal, etc., adsorption might be the best choice because it costs less and without further complications of secondary issues.
Computational study
With the computational progress in the last two decades, the rapidly increasing computing power equipped researchers with a better ability to investigate impacts on various fields. In particular, in deep learning, ML, or the bid data, large amounts of data are allowed to train the program to generate and efficiently provide a more accurate estimation. A better-developed model could significantly reduce the experiment workload in terms of prediction accuracy. For example, regarding the issue of effectively absorbing heavy metals, a model based on the biochars and metals properties to select more appropriate biochar can reduce experimental times. The decreased experimental times feature means we can reach similar results with less expenditure. Modeling software methods include Monte Carlo approaches, ML, Deep learning, ANN, Bayesian network methods, DFT, etc. 78 ANN and ML models with artificial intelligence features have been extensively employed in biochar applications in a variety of aspects. 3
Artificial neural network
The ANN algorithms have increasingly been employed in scientific research recently. ANN is a programming languages system dealing with a specific task by replicating the brain's function. It was developed the analogy made between programming languages processing and human brain system. 7 The reasons that utilizing ANN in the studies of the adsorbents related issue and adsorbates in liquid purification 79 lie in ANNs, a nonlinear statistical data modeling tool, could be utilized to investigate the complex nexus among the correlated/considered inputs and outputs. The output(input) values means the (in)dependent variables of the system under investigation. One of the advantages of employing ANN models is that we do not need to set any specification or ad hoc assumptions on interested variables and allow ANN to investigate the complex nexus; the other advantage is that ANN models could provide better predictions than the traditional adsorption models do at different operating conditions.
However, some people think that the ANN models are block-box models, given that a math expression between the outputs and inputs cannot explicitly answer the phenomenon to be analyzed and/or the reason that conventional models are inappropriate for conducting research.79–81 (While the pros of a black-box model are that the exact relations among variables are not mandatory, the cons are someone might argue we never know the proper functional form among variables that we are interested in.
Meanwhile, the reason that we shall not worry about the block-box models features is that ANN contains several interconnected nonlinear processing factors which “learn” to express and infer nonlinear nexus among the considered variables in the study.
82
As aforementioned, ANN was developed from the analogy between computer processing and the human brain. To mimic neurons are interconnected within the human brain, ANN is designed as composed of simple elements, neurons, which are interconnected given a certain structure. Figure 1(a) graphically shows the basic model of a neuron and how it is integrated with the next components. The mathematical expression of Figure 1(a), the equation (1) of Reynel-Ávila et al., is
79

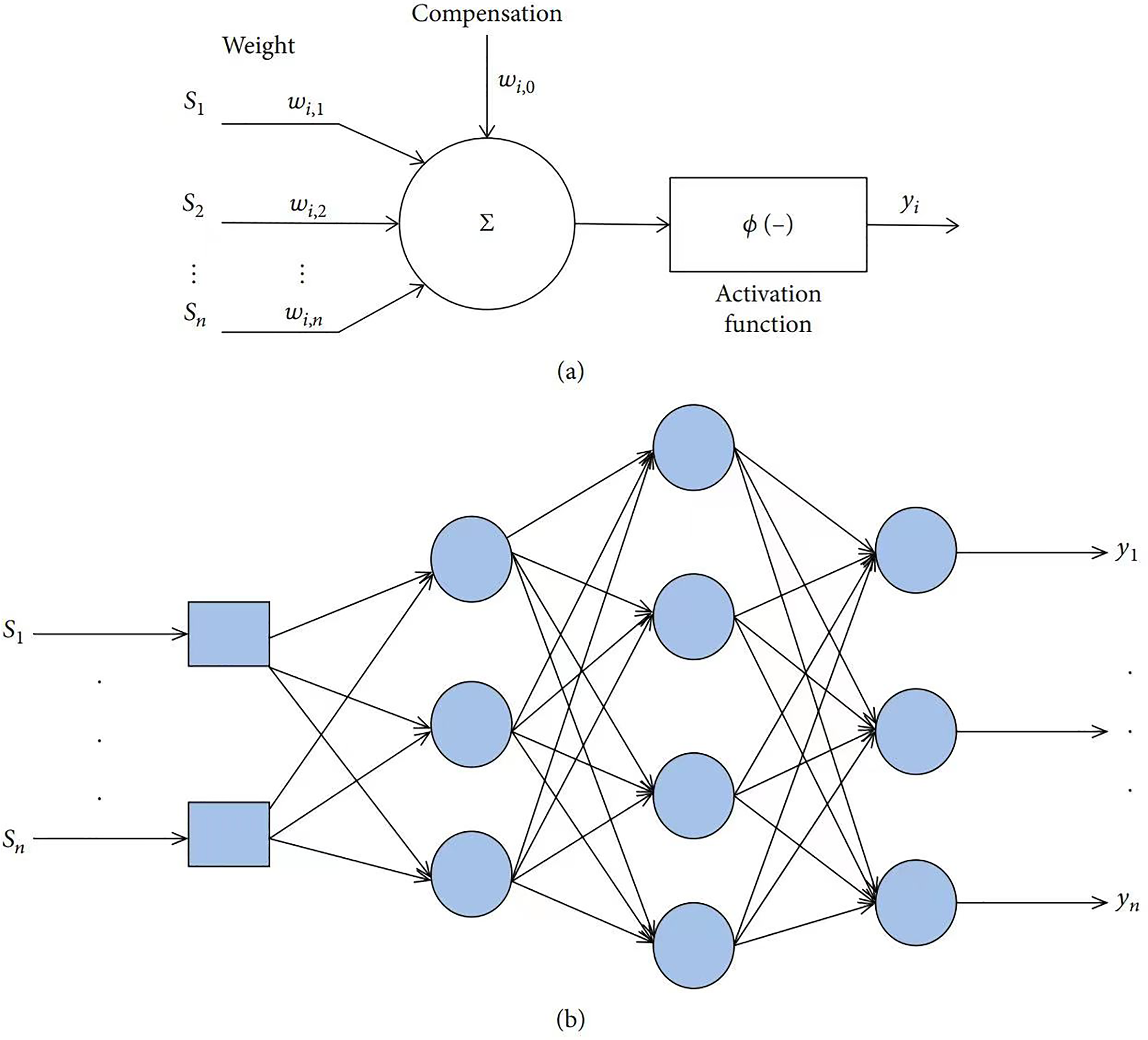
(A) the basic element of ANN: neuron; (B) a multilayer ANN model. Adopted from Ref. 79.
Figure 1(b) shows a multilayer ANN. The reason for constructing a multilayer ANN lies in reducing the nonlinear behavior issue that happened in applying a multivariable prediction system. 79 However, a critical issue in applying ANN is determining appropriate levels for hidden layers and their neurons. Figure 1(b) provides a framework to visually know the possible nexus among different layers in ANN, seeing that there might exist interconnection among layers. However, the researcher might not know the proper numbers of hidden layers, just as those circles in Figure 1(b). So, it recalls the importance of finding a satisfactory number of hidden layers and their neurons. For research utilizing a multilayer ANN structure, the independent variables are in the input layer, and the dependent variables correspond to the output layer. For an ANN with interconnected three-layered networks, the input neurons are sent out in the first layer. In the end, the output neurons from the third layer are by completing the transformation process in the second layer. Three categorized data are used in ANNs: training, validation, and testing. 3 The popular algorithm for training the ANN model is Levenberg–Marquardt (LM) approach. 3-4-2 is the most recognized network structure for the input, hidden, and output layers.
Zhu et al.
9
applied RF and ANN with multi-layer to study the adsorption performance and efficiency of biochar application. Their multilayer ANN consists of 14 input variables; 8–28 hidden neurons; one output variable with a sigmoid activation function. The removal efficiency was the output variable; 14 input variables were categorized into four sets in terms of initial heavy metal concentration, heavy metal properties, operational conditions, and adsorbent properties, respectively. 353 adsorption data came from literature; 6 heavy metals, cadmium, copper, zinc, lead, nickel, and arsenic on 44 biochars were studied in this paper. Properties of biochar are critical factors in heavy metal absorbing issues. Regarding the model performance, they report that RF outperforms ANN by 28%, with
The ANN-based model has been widely applied to other engineering fields, a backpropagation ANN (BP-ANN) is constructed to more accurately identify the information of magnitude and location of the load resulting in a fixed beam plastic deformation. 83 An expanded dataset helps establish a well-developed BP-ANN model that could be used to improve the accuracy of prediction. Also, an ANN algorithm was performed to construct a prediction model of breakthrough extruding force regarding the great-scale extrusion operation. 84 The ANN model was reported to have better accuracy in prediction than the long-established finite element methods. Furthermore, the ANN-based model also demonstrated better accuracy in predicting the sound quality (SQ) of a high-speed permanent magnet motor (HSPMM). 85 The authors first employed the multiple linear regression (MLR) model as the bench model. The result of the MLR model shows it was good in prediction accuracy (the average error was 7.10%); however, the stability was poor. To improve prediction accuracy, the authors further utilized the algorithm-radial basis function (GA-RBF) neural network toward the prediction model of SQ. The GA-RBF model had better prediction accuracy and stability than the MLR model because the GA-RBF model reduced the average error rate and the standard deviation by 3.16% and 1.841, respectively. Although the currently developed model is only suited for evaluating and predicting the SQ of HSPMM, it still provides evidence that the ANN-based method demonstrated higher prediction capability than the conventional MLR.
Machine learning
ML is an artificial intelligence approach that enables systems to learn from and deal with a complex and large dataset with multidimensional; utilizing ML, people can improve and predict outcomes using software without rigorous programming.8,9 Classical ML algorithms are usually categorized into four: supervised learning, semi-supervised learning, unsupervised learning, and reinforcement learning methods. For a supervised ML algorithm, data scientists need to have a dataset with labeled observations to train algorithms to have desired outputs. 86
Supervised ML algorithms learn from labeled datasets, which are then used to predict future events. During training, using a pre-known dataset with associated labels, the learning algorithm can eventually provide predictions regarding new, unobserved observations. Multilayer perceptron neural network (MLP-NN) is an application of NN applied in supervised regression using the LM back-propagation approach as the algorithm for training. 87 Li et al. reported that their comprehensive data-driven model could forecast biochar yield and compositions under various biomass input feedstock and different pyrolysis criteria. They said a 12.7% improvement in prediction accuracy compared to the existing literature. 87 Their achievement shows that the trade-off between biochar yield and its composition could be predicted through a comprehensive ML model instead of relying on those complex and semi-empirical feature theoretical models; moreover, those theoretical models usually spent a lot of time to reach satisfactory results. Furthermore, the choice of the trade-off between biochar yield and biochar composition is feasible via the utilization of ML; it also means that the total cost of acquiring targeted biochar yield is reduced.
Figure 2 graphically shows the MLP-NN architecture. After the training process, the well-developed MLP-NN model can reduce the margin between the desired results and the network report. And further, reduce the prediction error in biochar application. Regarding an unsupervised ML algorithm, the labeled observations are not necessary for the dataset. Because the unsupervised ML method can explore the data and draw inferences for a hidden function via unlabeled observations. The semi-supervised model is literally between the unsupervised and supervised algorithms. Lastly, the Reinforcement approach consists of algorithms that take the estimated errors as rules of penalties (rewards). In specific, when the error is significant (small), the penalty is high (low), and the reward is low (high).

The application of multi-layer perceptron neural network on biochar prediction. Adopted from Ref. 87.
Regarding utilizing ML in improving biochar applications. With sufficient information, it allows for a more profoundly explore of its factors and the nexus among biochars and targeted impurities since the understanding of the behavior of the process is increased with an increase in the utilization of information. ML technology is one of the desirable alternatives for high-order complexity modeling systems. 88 Taking employing biochar for the adsorption of impurities as an example, the amount and quality of information are essential in developing predicted models with the capability to describe the adsorption of undesired substances from sewage. 89
Among several algorithms used in developing empirical models for adsorption, ANNs are widely adopted in modeling adsorption processes. It is viewed as a well-established technique. Ghaedi and Vafaei 90 not only strengthened the suitability of ANN in modeling the adsorption process but rephrased the importance that new approaches need sequentially examined and validated in alike research. In addition to ANN models, in the adsorption field, RF, an ensemble ML technique, is regarded as a welcoming alternative due to it can identify nexus among considered variables in a fairly small dataset, which is not surprising in adsorption processes.88,91,92 RF incorporates reaction variables from an association of simple estimators to form decision trees. The correlation between decision trees could be reduced by bootstrapping, and a randomized variable selection approach. Furthermore, the variance of the model is decreased through the RF method as well. 93 Besides the adsorption field, ANN and ML could be employed to explore computational discoveries in materials science. 94
The feasibility of applying the RF model in predicting C-char and biochar yield was studied by Zhu et al. 12 The authors also examine the influence of the variation of biomass properties and the criteria in the pyrolysis process; 245 datasets of biochar yield and 128 datasets of C-char were collected from the literature. Figure 3 shows the structure of using ML in biochar application using in this paper. As shown in the upper panel of Figure 3, based on critical factors of biomass, the authors categorized the dataset into 4 groups, respectively: (1) the structural elements of biomass; (2) elements compositions of biomass; (3) the pyrolysis criteria; (4) the particle dimension of biomass. Thereafter, the authors utilized the hyper-parameters of the RF algorithm to retrain the prediction model in C-char and biochar yield with distinct input variables. The bottom-left panel of Figure 3 visually shows how the RF is employed in the prediction model in C-char and biochar yield. Given that subsamples are randomly drawn with replacements from the dataset, the training process through the decision tree with different subsamples is performed to enlarge each tree to its most considerable possible degree via a bootstrap replicate of the training subsamples; furthermore, the average values of all label variables in the node were provided in each leave node. After we averaged the obtained estimated results from all trees, the data were divided into two groups: training data and test data with an 80 to 20 ratio, as shown in the bottom-right panel of Figure 3. The 80% training data were used to find the most good-fit hyper-parameters with cross-validation. Then, finally, the model with the most good-fit hyper-parameters was retrained and tested using that 20% reserved testing data.

The structure of using ML on biochar application. Adopted from Ref. 12.
Their results suggested that prediction accuracy was increasingly associated with the magnitude of information on the pyrolysis procedure. The more information, the higher the prediction accuracy is. Moreover, for different considered targets, the developed model with varying input variables might reflect distinct different tendencies in the models’ prediction ability. Specifically, in predicting biochar yield, the
A RF approach was compared with the ANN method in modeling the adsorption of methylene blue within orange dregs.
88
Using more than 200 independent experimental data, the authors utilized seven input variables, including rotation, salinity, solution pH, and temperature, to predict the three considered variables, the

Structure of an RF-based prediction model. Adopted from Ref. 88.
Zhang et al. 95 investigated aqueous adsorption prediction using an NN-LFER model, which is an ML modeling procedure borrowing the idea from NN, i.e. neural networks, and from pp-LFERs, where pp stands for the abbreviation of poly-parameter and LFERs mean linear free energy relationships. Their dataset was collected from the literature, including more than 160 organic chemicals on 30 polymeric resins, 50 biochars, 35 granular activated carbons, and 34 carbon nanotubes. Compared with previously published results, the optimized NN-LFER models demonstrated exciting accuracy, and the model's overall prediction was significantly improved. The model's root mean square error (RMSEs) show less deviation than the published models. Furthermore, when considering pore volume and BET surface dimension as descriptors for adsorbents, prediction results were improved. Lastly, the authors pointed out that the prediction bias of existing MLR models might be able to lower if the model considers adsorbents features and the equilibrium concentration.
A Kriging-LFER model was developed in predicting resin and biochar's adsorption capacity of organic elements.
14
Their data includes 1750 adsorption experiments, containing 30 polymer resins, 50 biochars, and 73 organic compounds. Compared to a published NN-LFER model, the Kriging-LFER model demonstrated better accuracy concerning the prediction of performance for adsorption. The
It is pointed out that ML models can predict the complex nonlinear nexus between dependent and independent variables within complex systems. 13 However, the complex biochar-soil interaction and the limitation of the systematic dataset restrict researchers from conducting a well-trained ML-based biochar effectiveness prediction model, particularly regarding heavy metals (HMs) contamination. To provide the prediction of the efficiency of HM immobilization in the environment of biochar-improved soils, they developed three ML models, NN, supporting vector regression (SVR), and RF. The advantages of using ML models are that both linear and nonlinear complex correlations with the interested objectives can be identified, and ML models also think about the largest probable concerning factors simultaneously. Moreover, the ML model can provide more accurately predicted targets of interest than the general statistical analysis and provide a particular convenience in the evaluation of the effect of biochar utilization in a specific soil environment.
Therefore, to evaluate their effectiveness on HM immobilization in the environment of biochar-improved soils, Palansooriya et al. considered 20 input variables regarding four perspectives, namely (1) biochar features and pyrolysis criteria; (2) physicochemical characteristics of biochar-related soil; (3) trials conditions for experiments; (4) HM properties. Based on their reported results from RF, SVR, and NN models, regarding the prediction of the efficiency of HM immobilization, the optimally adjusted RF model was the best algorithm among SVR, NN, and RF approaches. The testing and training
Conclusions
ML is a suitable numerical method for evaluating and predicting models for biochar applications; multiple studies have shown that ML-based models have been widely used in biochar applications.
Among the ML methods, the related use of ANN is increasing over time. However, when applying the ANN model to study adsorption-related problems, a dataset with sufficient experimental information about the adsorption system is important in developing a statistically reliable ANN model. The literature shows that some authors have reported using ANNs with a wide range of variables; for instance, output variables adopted final adsorbate concentration or percent removal, resulting in models that may incorrectly predict the performance of the considered adsorption model. Therefore, training with intensive data in adsorption is essential for obtaining reliable ANN models. Lastly, solving the over-training in the training phase and applying global optimization methods are the key issues in bringing the ANN models into research questions.
As discussed in the ML introductory section, RF has been viewed as a good alternative to ANN models because of its ability to identify the nexus between variables in relatively small datasets. Moreover, some authors have reported that RF is slightly better than ANN. In terms of prediction accuracy, a better-developed model means could significantly reduce the experiment workload. For example, regarding the issue of effectively absorbing heavy metals, a model based on the biochars and metals properties to select more appropriate biochar can reduce experimental times.
Furthermore, a comprehensive data-driven model could forecast biochar yield and compositions under various biomass input feedstock and different pyrolysis criteria. They said a 12.7% improvement in prediction accuracy compared to the existing literature.89 This shows that the trade-off between biochar yield and its composition could be predicted through a comprehensive ML model; moreover, the choice of the trade-off between biochar yield and biochar composition is feasible via the utilization of ML. It also means that the total cost of acquiring targeted biochar yield is reduced. We also know that the ML methods might be applied to the energy and food security field, though these directions might need further studies.
Even though this review does not profoundly introduce the detailed process of those studies, this paper provides a relatively comprehensive review of the updated ML utilization in science and the environmental and economic scope, which could be the indexation of ML application in the interested field. Lastly, further studies on ML applications are helpful in the optimization of the trade-off between biochar yield and its composition.
Footnotes
Acknowledgments
The guest editors thank Dr Chi-Chung Chen at Taiwan's Council of Agriculture and Dr Bruce A. McCarl for their insightful comments and supports.
Author's contributions
Dr Meng-Wei Chen designed the study. Dr Meng-Shiuh Chang conducted the comparable analysis. Dr Chih-Chun Kung summarized the results and drafted the manuscript. Dr Yuehua Mao and Shuyin Hu collected references and make the figures.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We thank the National Natural Science Foundation of China (41861042; 72163006).
Author biographies
Meng-Wei Chen received his PhD in the Indiana State University is currently working at Nanjing Audit University. His research interests include renewable energy development and climate change.
Meng-Shiuh Chang received his PhD in Texas A&M University and is the professor of Hubei University. His research interests include econometric analysis and time series.
Yuehua Mao is currently working as a research associate in the University of International Business and Economics.
Shuyin Hu is the Master student under the supervision of Dr. Chih-Chun Kung.
Chih-Chun Kung received his PhD in Texas A&M University and is the professor at Jiangxi University of Finance & Economics. His research interests include bioenergy, mathematical programming, and emission offset.