
Abstract
Recognizing handwritten Chinese documents can improve efficiency and productivity, which makes it a crucial task for power grid enterprises. This paper proposes a novel handwritten document recognition method to enhance recognition accuracy. First, spatial features are extracted from the input images using an inception module, which captures multi-scale spatial characteristics. Subsequently, a space channel parallel attention module is employed to emphasize significant features and suppress interference. The spatial features are then transformed by a bidirectional long short-term memory network, which predicts the probabilities of outputting Chinese characters. Finally, a transcription layer computes the prediction loss for each character, and the final prediction results are obtained after removing redundant placeholders. Validation experiments demonstrate that the accurate rate and correct rate of the proposed method reach 96.92% and 97.66%, respectively, indicating its effectiveness in capturing handwritten character features and improving accuracy, even under the challenge of diverse handwriting styles.
Keywords
Introduction
Power system operations and maintenance rely on handwritten documentation through inspection sheets, operation tickets, and defect records for critical information storage. These paper documents serve as repositories of essential data on equipment status, fault conditions, and remedial procedures—factors that directly affect power grid stability and safety. Advanced handwritten document recognition technology enables efficient digitization of historical records with automated data extraction and comprehensive analysis capabilities. This technological advancement enhances operational efficiency, minimizes manual data entry expenses, and provides vital support for equipment assessment, fault diagnosis, and predictive maintenance protocols. As a consequence, it accelerates the digital transformation of power enterprises.
Nevertheless, there still exist several significant challenges due to the inherent characteristics of Chinese handwriting.
High variety: the Chinese language has a vast number of characters, with over 6763 commonly used characters according to the national standard. Complex and similar structures: Chinese characters have complex structures that can vary significantly in their stroke formations, such as top-bottom, left-right, and enclosed structures. In addition, many characters are quite similar in structure but the meaning differs greatly, as shown in Figure 1. Various handwriting styles: handwritten Chinese characters exhibit a wide range of styles and deformations among different writers, including variations in size, stroke thickness, and the use of cursive script, making the same character appear significantly different when written by different people.
In addition, there are two more specific challenges in the handwritten documentation of power grid companies. On the one hand, the writing conditions are often challenging. For instance, during equipment inspections in production workshops, the recording staff may lack access to a desk to record their observations and are forced to write while standing. Consequently, the handwriting may be distorted compared to standard shapes. On the other hand, power companies often utilize specialized vocabulary that is not commonly encountered. Therefore, developing a specialized recognition model for power companies is essential to overcome these technical challenges.
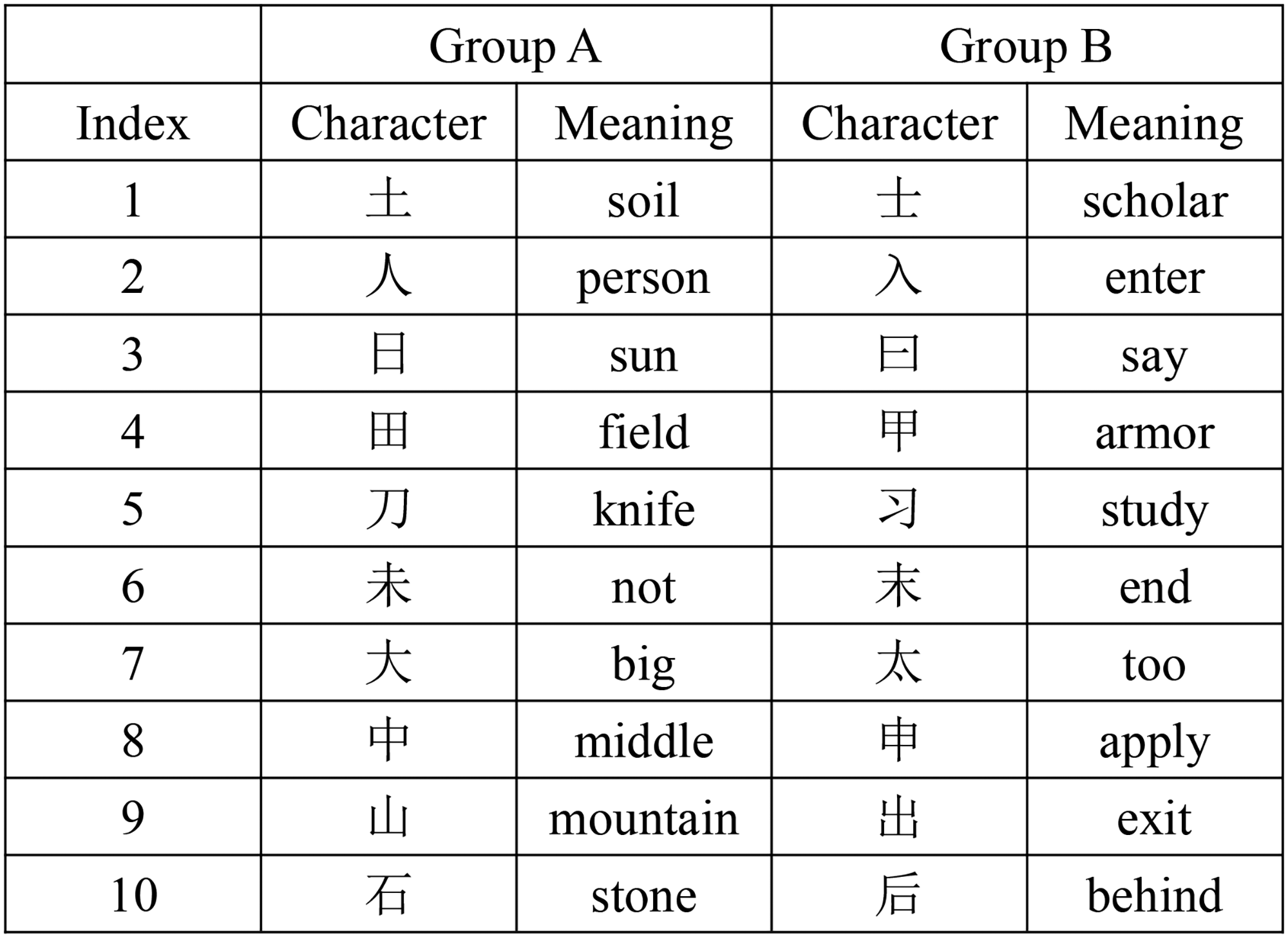
Character pairs with similar structure.
To address these challenges, numerous handwritten Chinese recognition methods have been proposed, which can be primarily categorized into traditional methods and deep learning approaches.
The traditional methods involve three main steps: image preprocessing, feature extraction, and classification. Image preprocessing techniques first enhance the image quality. After that, feature extraction captures distinctive characteristics of the characters, with structural and statistical descriptors. Finally, classifiers leverage the extracted features to recognize the characters. The three steps are separated and operated independently. Deep learning methods, different from traditional ones, recognize characters using end-to-end convolutional neural networks (CNNs). The CNN architecture, with its hierarchical layers of feature extraction and classification, can automatically capture the spatial relationships and local dependencies within the input image. As a result, they can learn the distinctive features and patterns that define each character. Compared to traditional methods, deep learning methods have greatly improved recognition performance.
Among the deep learning methods, approaches based on convolutional recurrent neural network (CRNN) 1 have made significant progress in character recognition, which effectively addresses the challenges of variable text length, complex layouts, and diverse writing styles. The key steps of CRNN are as follows: (a) Spatial feature extraction. First of all, a CRNN model uses convolutional layers to extract spatial features from the input image. The visual patterns and structures present in the document, such as the shape and stroke of the text are obtained. (b) Sequence modeling. After that, the spatial features are fed to the recurrent layers in the CRNN model, which allows the sequential and contextual information inherent in the text to be obtained. This sequential modeling generates a sequence of character predictions at each time step, which is crucial for handling variable-length text and recognizing characters in the correct order. (c) Connectionist temporal classification (CTC). The CTC module aligns the input image sequence with the output text sequence, even though their lengths are different. This is achieved by considering all possible alignments and finding the one that maximizes the probability. In addition, it also introduces a “blank” label to handle variable length inputs and outputs. In fact, CRNN approaches resemble the human cognitive process of reading text. Both involve step-by-step character recognition to build overall understanding, utilizing contextual information for alignment, and handling variable length inputs.
Despite CRNN’s notable achievements in printed character recognition, challenging writing conditions and variations in power grid documentation styles continue to present significant obstacles. Additional research remains necessary in the domain of handwritten power grid document recognition. This paper presents a novel method to address the challenges in handwritten Chinese character recognition for power grid applications. The key contributions are as follows: (a) An inception-based feature extraction approach is proposed, which fuses multi-scale spatial features extracted from different receptive fields. (b) A novel spatial channel parallel attention (SCPA) mechanism is introduced to enhance relevant features while simultaneously suppressing interfering features. (c) Extensive experiments have been conducted on two public datasets and a self-collected dataset from the power grid industry. The results demonstrate that our approach significantly outperforms existing methods in terms of both recognition accuracy and edit distance metrics.
Related work
Traditional handwritten Chinese character recognition methods
Traditional handwritten Chinese character recognition methods can be divided into two steps: feature extraction and classification. Common features include gradient features, vector features, Gabor features, etc. After that, the features are sent to classifiers, such as support vector machine (SVM), K-nearest neighbor (K-NN) algorithm, multi-layer perceptron (MLP), CNN, recurrent neural network (RNN), hidden Markov models (HMMs), and random forest (RF) algorithm,2,3 to identify and recognize the characters.
Liu et al. 4 proposed a quadratic discriminant function based on discriminative learning, which combines the quadratic discriminant function with discriminative learning algorithms, using minimal classification error as the evaluation criterion. Long and Jin 5 proposed an improved quadratic discriminant function classifier with a compact structure, which constructs a vector-based parameter subspace. This classifier employs linear discriminant analysis for dimension reduction, enabling the implementation of handwritten Chinese character recognition on embedded systems with low storage capacity. Zhu et al. 6 first recognized multiple substructures by density-based clustering. These substructures are then used to further recognize the overall character with a modified quadratic discriminant function (MQDF) classifier. Zhou et al. 7 proposed discriminative quadratic feature learning (DQFL), which mainly uses the statistical and spatial correlation of features to increase dimensionality; then, discriminative feature extraction (DFE) is employed to reduce it. Wei et al. 8 used sparse coding to compact the parameters of MQDF and constructed two compact MQDF classifiers using maximum likelihood-based and K-SVD methods. Ma et al. 9 developed an efficient two-dimensional Gaussian mixture model (GMM) HMM using the Kaldi toolkit. This system segments Chinese characters into basic components in horizontal and vertical directions according to hidden states, which is an improved version of 1D-GMM-HMM.
These traditional schemes have promoted the recognition of handwritten Chinese characters and have achieved promising results on specific datasets for a period of time. However, considering the complexity of actual applications, the accuracy of the models is far from enough. For example, Chhajro et al. 10 reviewed the performance of SVM, K-NN, MLP, CNN, RNN, and RF, and found that CNN models outperform RF, SVM, and MLP to produce reliable results in terms of optimal accuracy.
Deep learning-based handwritten Chinese character recognition methods
Compared to traditional methods, the deep learning framework has much more powerful learning capabilities, which better captures the features of the handwritten characters and thus improves the recognition accuracy. 11 Deep learning methods can be further divided into individual character recognition and text line recognition.
Individual character recognition focuses solely on single characters. Cireşan and Meier 12 were the first to use a multiple column deep neural network for recognizing handwritten Chinese characters. Wu et al. 13 subsequently proposed a recognition method based on a relaxation CNN. Zhang et al. 14 combined deep learning with image decomposition to enhance the model’s recognition capabilities across different handwriting styles. Similarly, Zhong et al. 15 integrated the GoogLeNet with Gabor features to enhance the model’s recognition capabilities. Yang et al. 16 introduced the attention mechanism into handwritten Chinese character recognition, improving recognition accuracy by iteratively updating the text area of interest. Xu et al. 17 proposed a multiple comparison attention model, expanding a single attention map into multiple ones, and calculating attention for different local areas of the text separately. Li et al. 18 proposed a model for recognizing occluded single characters, using a CNN and a generative adversarial network (GAN) to repair the occluded parts, followed by character recognition using an improved GoogLeNet. Gondere et al. 19 proposed a CNN for a classification task for Amharic handwritten character recognition. By collecting handwritten documents, applying data augmentation to build the dataset, and using multiple-task learning to enhance model performance, promising results were achieved.
Text line recognition involves the relationships between different Chinese characters, making it more complex than individual character recognition. Text line recognition can be further divided into two main categories: segmentation-based and segmentation-free methods. The segmentation-based methods use image segmentation frameworks to divide a whole line of text into multiple characters and then recognize each character individually. Peng et al. 20 used a fully convolutional network for end-to-end line text segmentation, followed by character recognition. Chen et al. 21 introduced a novel learning method for segmenting and recognizing online handwritten Chinese text using a CNN as the core classifier. Wu et al. 22 combined a deep network-based language model with a traditional language model to improve the results of recognizing text lines. Wang et al. 23 used weakly supervised learning to predict each character with only string-level annotations. The segmentation-free method does not perform explicit segmentation and position prediction of characters, which better addresses character adhesion and is more efficient than the segmentation-based methods.
A typical segmentation-free method is CRNN, 1 which uses a CNN and an RNN for feature extraction, followed by decoding through a HMM or CTC. 24 In the work of Su et al., 25 each line of images was processed through a sliding window to extract features, and character HMM models were subsequently trained. Finally, the optimal string was determined based on the Viterbi decoding idea, ensuring the maximization of posterior probability. Du et al. 26 replaced the Viterbi decoding with a deep neural network to model the posterior probability of HMM states. In the CTC-based method, Messina and Louradour 27 proposed a multi-dimensional long short-term memory RNN that can recognize an entire line of handwritten Chinese characters without segmentation. Wu et al. 28 further proposed extracting context from multiple directions based on this. Liu et al. 29 introduced an SE module and residual structure into the network and used a context bundle search algorithm in CTC decoding, taking into account both semantic and visual information. Xie et al. 30 performed data augmentation on text lines and combined residual long short-term memory (LSTM) with CNNs, enhancing performance while accelerating speed.
In the last two years, some new attempts have emerged. Dan and Li 31 utilized particle swarm optimization to design a CNN for recognizing handwritten Chinese characters, where each particle represents a different network architecture, and the optimal architecture is found by iteratively updating these particles until the best one is identified. Xu et al. 32 utilized a CNN-based system to automatically evaluate penmanship in traditional Chinese handwriting. To increase usability, a mobile application was developed based on the CNN model, allowing users to assess their handwriting easily. Dong et al. 33 offered clear interpretability and an efficient learning approach. They developed the MetChar algorithm to optimize the weight distribution among fixed components and the HybridSelection algorithm to choose components and feed them into MetChar. These two algorithms facilitated the learning of the distance metric for handwritten Chinese characters. Ngo et al. 34 proposed an RNN transducer model for recognizing offline handwritten text in Japanese and Chinese. The model has three key components: a visual encoder using CNN and bidirectional LSTM (BiLSTM), a linguistic context encoder using embedded layers and LSTM, and a joint decoder that generates the label sequences. Min et al. 35 proposed a lightweight model based on shallow GoogLeNet and an error elimination algorithm. This improved shallow GoogLeNet reduces the number of training parameters while maintaining the depth of the Inception structure.
The proposed method
Algorithm framework
We propose a handwritten Chinese character recognition method based on CRNN to address the issue of handwritten document recognition in the field of power grid enterprises. As shown in Figure 2, this method extracts spatial features from the text images with CNN. The features are then used as the input of the BiLSTM for further processing, and the probability of outputting corresponding characters is reported. Finally, the transcription layer calculates the predicted loss of each character and removes any redundant placeholders to obtain the prediction results.

CRNN LSTM CTC recognition framework. CRNN: convolutional recurrent neural network; LSTM: long short-term memory; CTC: onnectionist temporal classification; BiLSTM: bidirectional LSTM.
More importantly, to address the significant differences in writing styles among different individuals and the varying importance of features across different regions, we utilize the inception module and propose a “spatial channel parallel attention (SCPA)” module to better extract image features and improve recognition accuracy.
Feature extraction with inception and SCPA
Handwritten Chinese characters are characterized by complex structural patterns and diverse writing styles. Fixed receptive field feature extraction methods show inherent limitations in capturing such structural variations. To address these challenges, we propose an integrated feature extraction framework that combines Inception modules with SCPA. The inception module enables multi-scale feature extraction via parallel convolution branches, whereas SCPA enhances feature representation through spatial attention (SA) and channel attention (CA) mechanisms, leading to robust recognition performance.
As shown in Figure 3, the feature extraction process consists of five cascaded feature extraction units (
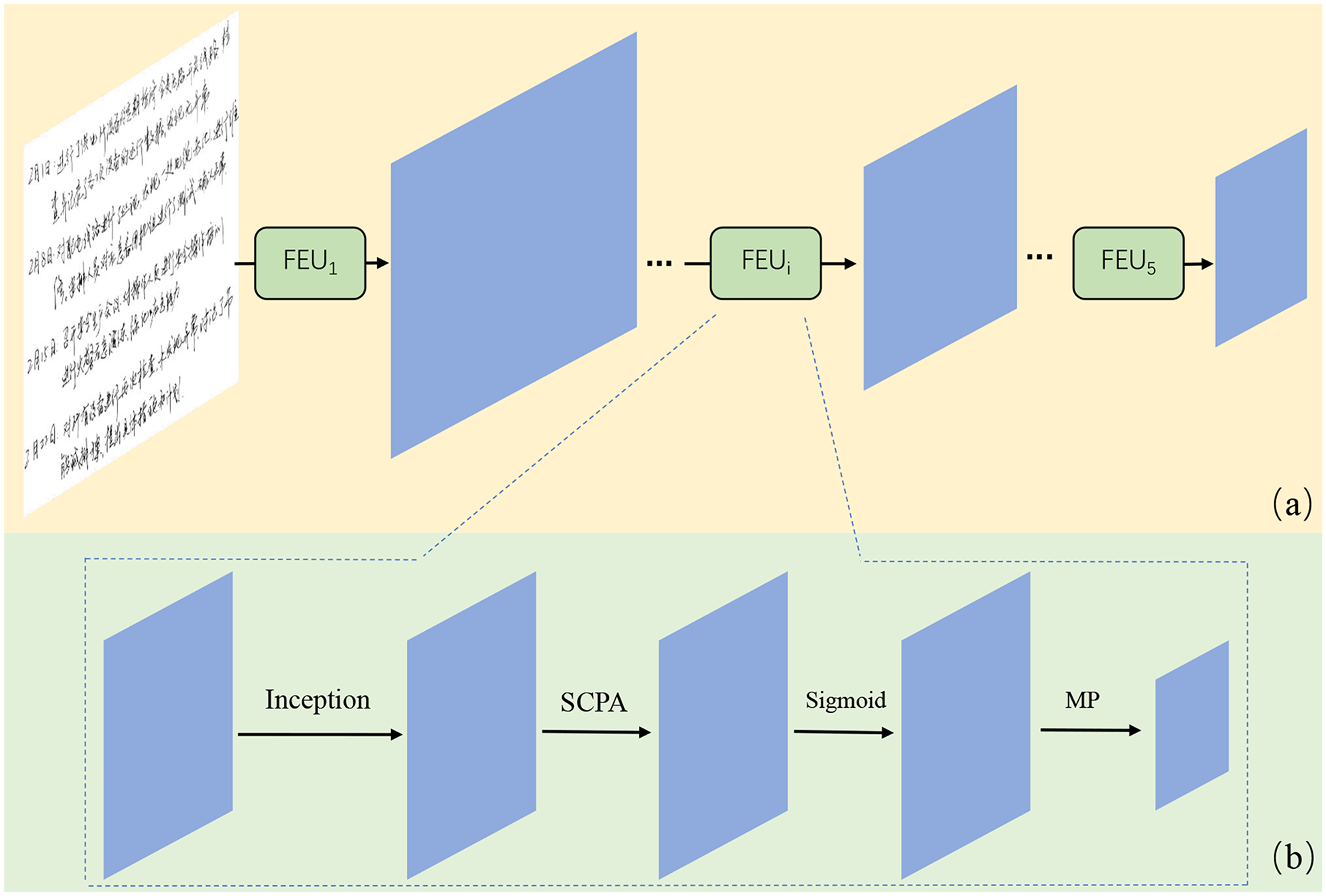
Feature extraction based on Inception and SCPA. SCPA: spatial channel parallel attention; MP: max pooling.
Inception multi-scale feature extraction
Handwritten documents exhibit various writing styles, including significant variations in size, stroke thickness, and ligatures. Therefore, multi-scale feature extraction is essential, and the inception module provides an efficient solution for this requirement.
As shown in Figure 4, the inception module consists of four parallel branches, each performing a distinct convolution or pooling operation on the input feature map Max pooling (MP): This branch performs
The features from these four parallel branches are combined along the channel dimension to produce an output feature map
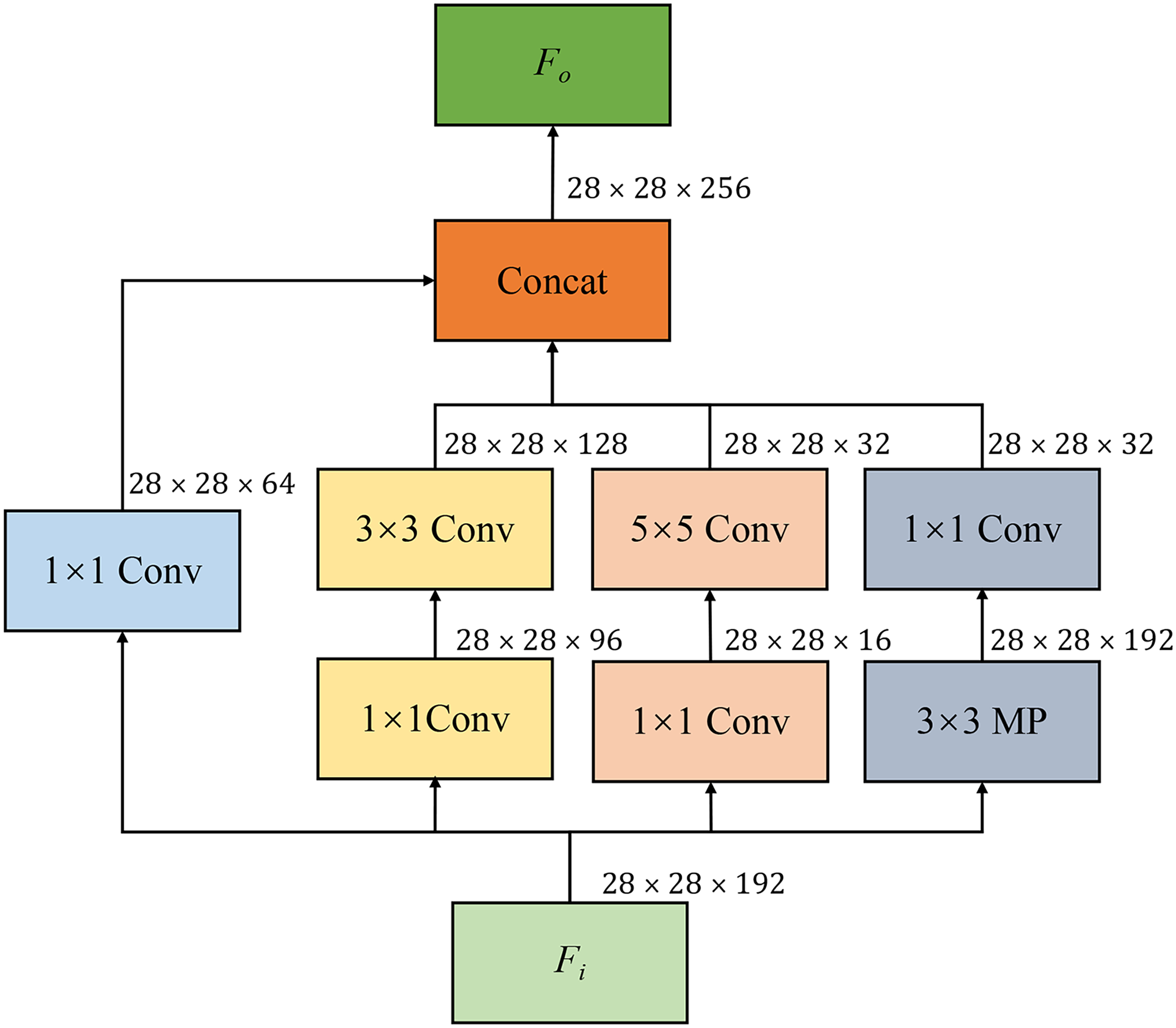
Inception module structure. MP: max pooling.
The
In a single inception module, the receptive fields are determined by the kernel sizes of
The inception module introduces additional computational complexity through its multi-branch architecture. Nevertheless, the computational overhead remains acceptable for character recognition tasks, which primarily operate in offline mode.
Spatial channel parallel attention
In addition to the inception module which provides various receptive fields, we also incorporate an attention mechanism to adjust the feature maps. This mechanism learns a set of weights to determine the importance of each location in the feature map. Mathematically, let


As shown in Figure 5, the proposed SCPA consists of three parallel branches: CA, SA, and the original feature branch. Given an input feature


Spatial channel parallel attention.
Figure 6 presents the pipeline of CA. The input feature The feature first undergoes max-pooling and average-pooling operations in the spatial dimension, resulting in features The MLP outputs, The input feature

The SA mechanism operates similarly, as shown in Figure 7.
The input feature The input feature


Channel attention. MP: max pooling. AP: average pooling. MLP: multi-layer perceptron.
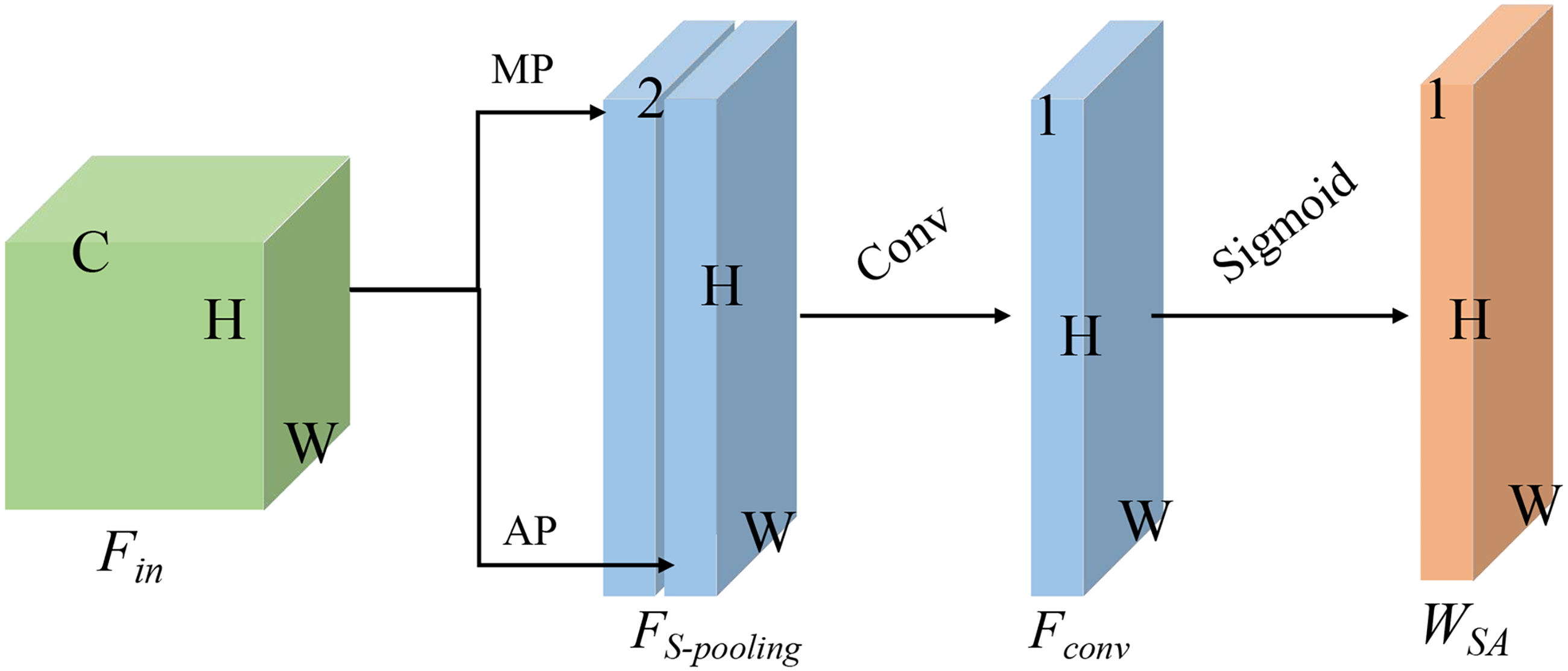
Spatial attention. MP: max pooling. AP: average pooling.
Through this design, SCPA enhances feature representation and consequently improves recognition accuracy. On the one hand, SCPA incorporates parallel SA and CA mechanisms, enabling the model to selectively emphasize relevant spatial locations and channel-wise features in the input data. The integration of these complementary attention mechanisms facilitates more effective data representation and discriminative feature extraction. On the other hand, SCPA preserves the original input features in its output pathway. This design ensures the retention of essential characteristics in diverse input data, particularly for variations in writing styles and patterns.
BiLSTM recurrent layer
After extracting spatial features, sequential modeling is essential for modeling temporal dependencies in handwritten text. The BiLSTM recurrent layer addresses this requirement by processing feature sequences bidirectionally. Its ability to maintain both preceding and succeeding contextual information, coupled with its memory mechanism, enables the effective handling of variable-length sequences and connected strokes in handwritten characters.
As shown in Figure 2, the spatial features extracted from convolutional layers are reshaped into sequential representations. These features are then processed through a BiLSTM network to generate character-level probability distributions over the predefined character set. The bidirectional architecture enables comprehensive modeling of long-range contextual dependencies within the sequence.
Figure 8 illustrates the architecture of the BiLSTM network, where

BiLSTM structure. LSTM: long short-term memory; BiLSTM: bidirectional LSTM.
The LSTM unit architecture, illustrated in Figure 9, comprises essential components for controlling information flow:
A forget gate that regulates the retention of previous state information. An input gate that modulates the incorporation of new information into the cell state. A cell state that serves as a memory mechanism for long-term information propagation. An output gate that filters the cell state information for hidden state generation.

Basic long short-term memory (LSTM) unit structure.
The spatial features are processed through the BiLSTM layer as follows:
The two-dimensional spatial features from the CNN are transformed into a one-dimensional sequence, preserving spatial relationships. The sequence elements are processed bidirectionally through forward and backward LSTM units. Hidden states from both directional processes are concatenated to form a comprehensive feature representation capturing bidirectional contextual information. This integrated processing maintains spatial coherence while incorporating temporal dependencies, essential for modeling connected strokes and variable-width characters.
The spatial features require reshaping before serving as input to the BiLSTM network. Initially, these features have dimensions of
The BiLSTM architecture implements adaptive information filtering through its gating mechanisms, enabling effective modeling of long-range dependencies in character sequences. Its integration of bidirectional processing and memory mechanisms provides robust handling of variable-length patterns inherent in handwritten Chinese characters.
CTC transcription layer
Conventional sequence recognition approaches based on softmax classification mandate rigid one-to-one input–output alignments, presenting significant challenges for handwritten Chinese character recognition with its inherent variations in writing styles and character lengths. The CTC 24 transcription layer overcomes these constraints through its blank token mechanism, eliminating the requirement for explicit sequence alignment. This formulation enables flexible sequence-to-sequence mapping, making it particularly suitable for processing variable-length handwritten text representations.
The transcription layer processes the probability distributions generated by the recurrent layer, mapping them to character sequences through maximum likelihood estimation at each position. Contemporary neural networks typically employ softmax activation, which enforces strict one-to-one alignment between input features and output probabilities. Such alignment constraints require fixed-length representations and precise spatial correspondence between input images and output sequences. These requirements prove particularly challenging given the inherent variability in handwriting styles. To address this limitation, we implement the CTC framework, which utilizes blank tokens and sequential modeling to handle variable-length sequences and misaligned predictions effectively.
In such a manner, the CTC framework addresses sequence recognition challenges through implicit alignment learning, eliminating the requirement for explicit input–output correspondences. Its blank token mechanism efficiently processes variable-length sequences, providing robust performance for handwritten Chinese character recognition where conventional Softmax-based approaches struggle with stylistic variations.
Loss function
The primary objective of text recognition is to minimize the divergence between predicted sequences and ground truth labels, naturally suggesting the application of character-level cross-entropy loss.
However, conventional character-level cross-entropy loss necessitates exact alignment between predictions and ground truth labels, which proves impractical for handwritten character recognition given the inherent variations in writing styles and character lengths. The CTC loss framework addresses this limitation by incorporating blank tokens, enabling end-to-end sequence learning without requiring explicit temporal alignment between input features and target labels.
To be specific, the input image undergoes convolutional processing to extract spatial features. These spatial features


Utilizing the path formulation described above, the CTC loss function is formulated as the negative log-likelihood over the entire training set, eliminating the need for explicit character alignments:

Experiments
Implementation details
Extensive experiments were conducted using the CASIA-HWDB dataset
36
and ICDAR-2013 dataset
37
. The CASIA-HWDB dataset contains over 3,000,000 isolated character samples, while ICDAR-2013 comprises 91,000 samples. The PowerHW dataset, collected from power grid enterprise maintenance records, represents our proprietary dataset. This dataset contains more than 40,000 characters across 1572 distinct categories, contributed by 35 different annotators. All document images underwent binarization to standardize imaging quality. Figure 10 illustrates the character “electricity” from the PowerHW dataset, demonstrating significant variations in writing styles across different annotators. The experiments utilize a

Examples of the Chinese character of “electricity” in PowerHW.
All experiments were conducted on a server equipped with an Intel Core I9-10900F CPU, 64 GB RAM, and an NVIDIA GeForce RTX 3090 GPU. The model was implemented in PyTorch and optimized using the Adam algorithm. The training process consisted of 500 iterations with a batch size of 32, using an initial learning rate of
Levenshtein edit distance is introduced to evaluate the performance of the method, where accuracy rate (AR) and correct rate (CR) are used.

The meaning of the notations are as follows:
Results of the proposed method
The recognition results on real handwritten paperwork are first presented in Figure 11. It can be noticed that, Figure 11 (a) shows the original handwritten characters with a large number of connected and simplified strokes, which brings difficulties and challenges to the recognition. The recognition results of the proposed method are shown in Figure 11(b), which demonstrates that the vast majority of the results are correct. To be specific, the incorrect recognition results are shown in Figure 11(c), where errors occur due to personal writing habits, particularly ligatures that make the character more similar to another one in structure.

Recognition results of PowerHW: (a) handwritten image, (b) results, and (c) error analysis.
We also evaluate the results using quantitative metrics. Table 1 compares our method with mainstream approaches in terms of AR and CR. On HWDB, our method achieves 96.92% AR and 97.66% CR. On ICDAR2013, the AR and CR values of the proposed method reach 92.67% and 93.18%, respectively. On PowerHW dataset, a specialized dataset for handwritten documents in power companies, we obtain 96.49% AR and 96.85% CR.
Accuracy comparison of mainstream methods.

AR: accurate rate; CR: correct rate.
The bold values represent the best performance metrics in each column.
In addition, we evaluate the robustness of the proposed model. As shown in Figure 12, we add Gaussian noise with zero mean (

Curves of accuracy versus noise. Three subfigures, arranged from left to right, illustrate the data obtained from the CASIA-HWDB, ICDAR 2013, and PowerHW datasets, respectively. AR: accurate rate; CR: correct rate.
Analysis of the Results
The superior performance can be attributed to two key architectural components. On the one hand, the inception-based feature extraction module effectively handles writing style diversity by fusing multi-scale spatial features from different receptive fields. This multi-scale approach enables better adaptation to various handwriting characteristics through multiple kernel sizes, providing comprehensive feature representation at different scales.
On the other hand, the SCPA mechanism significantly enhances feature quality by simultaneously utilizing SA and CA. This dual attention mechanism effectively enhances relevant features while suppressing interfering ones, maintaining the essential characteristics of input features while providing more accurate feature representations for subsequent BiLSTM and CTC modules.
Comparison with state-of-the-art methods
The proposed method is compared with current mainstream methods, including Wang et al., 38 Wu et al., 22 Wang et al., 39 Xie et al., 30 Wu et al., 28 Peng et al., 20 Fang et al., 40 , and Du et al. 41 The experimental results are presented in Table 1.
Our method demonstrates superior performance across all datasets. On HWDB, it achieves an AR of 96.92% and a CR of 97.66%, surpassing all compared methods. The improvements over the second-best approach are 1.57% and 1.72% for AR and CR, respectively. On ICDAR2013, the method yields an AR of 92.67% and a CR of 93.18%, outperforming existing approaches with margins of 0.29% and 0.44% for AR and CR, respectively. On PowerHW, a specialized dataset collected from power enterprises, our method attains an AR of 96.49% and a CR of 96.85%. These results exceed the second-best performance by 0.60% and 0.33% for AR and CR, respectively. This quality gain proves the advantage of the proposed method.
Ablation study
The proposed method utilizes inception for feature extraction and SCPA for feature fusion. We evaluate the contribution of each module through ablation experiments on the PowerHW dataset.
To assess the effectiveness of the inception module, we compare its performance with single-size convolutions. Table 2 presents this comparison, excluding
Ablation study on feature extraction.

AR: accurate rate; CR: correct rate.
The proposed method utilizes inception for feature extraction and SCPA for feature fusion, and the contribution of each module is verified through a series of ablation experiments. The experiment is conducted on the PowerHW dataset.
Table 3 presents the ablation study of different attention mechanisms: (a) no attention, (b) SA only, (c) CA only, and (d) the proposed SCPA. The results show that the baseline model without attention yields the lowest accuracy, while incorporating attention mechanisms consistently improves performance. Notably, the proposed SCPA, combining both SA and CA, achieves superior performance compared to models using either attention mechanism alone.
Ablation study on attention mechanisms.

AR: accurate rate; CR: correct rate; SCPA: space channel parallel attention.
Discussion
Contribution
This study introduces an innovative approach that addresses the complexity of diverse writing styles and enhances the recognition accuracy of handwritten Chinese characters in power enterprise documents. The proposed method integrates the inception module and a specialized SCPA mechanism to effectively extract multi-scale features from handwritten images. The BiLSTM layers perform sequence prediction for character recognition by capturing both past and future context in the sequence data, enabling high-precision character transformation and prediction. In the final stage, the CTC layer computes the prediction loss. Experiments on the CASIA-HWDB dataset, the ICDAR2013 dataset, and our custom PowerHW dataset have yielded impressive results, with the AR reaching 96.92% and the CR reaching 97.66%. These superior performance metrics validate the effectiveness of our proposed method.
Weakness
The CRNN approach first utilizes CNN to extract spatial features from the image and then employs RNN/LSTM to construct a temporal model from the spatial features. This approach performs effectively on text with standardized layout and formatting.
However, in handwritten documents, various non-standard patterns frequently occur, such as skewed writing, modifications, and misalignment, as shown in Figure 13. Our future research will focus on addressing the challenges of handwritten Chinese character recognition in complex document layouts with irregular formatting and structure.

Weakness and failure cases of the proposed method: (a) skewed writing, (b) modifications, and (c) misalignment.
The CRNN approach first utilizes CNN to extract spatial features from the image and then employs RNN/LSTM to construct a temporal model from the spatial features. This approach is relatively well-suited for recognizing text with a standardized layout and formatting.
Conclusion
This paper proposes a character recognition method for handwritten documents in power systems, addressing the challenges of diverse writing styles and improving recognition accuracy. The method incorporates the Inception module and SCPA in the convolutional layer to effectively extract features from handwritten images. The recurrent layer employs BiLSTM to transform and predict character probability outputs, while the transcription layer calculates prediction loss for final results. Experiments on the CASIA-HWDB dataset, ICDAR2013 dataset, and our custom PowerHW dataset demonstrate that the AR and CR accuracies reach 96.92% and 97.66%, respectively. Ablation studies confirm the effectiveness of both the inception-based multi-scale feature extraction and the SCPA mechanism, while comprehensive experiments validate the method’s robustness.
Nevertheless, the proposed method shows limitations when processing poorly formatted characters, including skewed writing, modifications, and misalignment. Future work will focus on improving handwritten Chinese character recognition in unstructured document layouts.
Footnotes
Acknowledgment
Not applicable.
Authors’ contribution
Dajun Xiao and Xialing Xu: study conception and design; Lianfei Shan and Tao Liu: data collection; Dajun Xiao, Tao Liu and Xin Li: analysis and interpretation of results; Xialing Xu and Yue Zhang: draft manuscript preparation. Xialing Xu, Xin Li and Yue Zhang reviewed the results and approved the final version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Science and Technology Project of State Grid Corporation of China (Central China Branch) (No. 52140023000P).