
Abstract
In the era of rapid internet expansion and technological progress, discerning real from fake news poses a growing challenge, exposing users to potential misinformation. The existing literature primarily focuses on analyzing individual features in fake news, overlooking multimodal feature fusion recognition. Compared to single-modal approaches, multimodal fusion allows for a more comprehensive and enriched capture of information from different data modalities (such as text and images), thereby improving the performance and effectiveness of the model. This study proposes a model using multimodal fusion to identify fake news, aiming to curb misinformation. The framework integrates textual and visual information, using early fusion, joint fusion and late fusion strategies to combine them. The proposed framework processes textual and visual information through data cleaning and feature extraction before classification. Fake news classification is accomplished through a model, achieving accuracy of 85% and 90% in the Gossipcop and Fakeddit datasets, with F1-scores of 90% and 88%, showcasing its performance. The study presents outcomes across different training periods, demonstrating the effectiveness of multimodal fusion in combining text and image recognition for combating fake news. This research contributes significantly to addressing the critical issue of misinformation, emphasizing a comprehensive approach for detection accuracy enhancement.
Keywords
Introduction
In the era of advanced technology today, various types of information are rapidly transmitted over the internet, and the speed of dissemination is correspondingly swift. There has been a significant transformation in the dissemination methods, from traditional means such as newspapers, magazines, posters and television to the current internet-based communication. The process has evolved from one-way message delivery to users being able to engage in interactions on platforms, further spreading information through sharing and commenting. Social media platforms such as Twitter, Facebook and Line are among the most used platforms for news commentary.1–3 However, these platforms also witness a significant amount of fake news, which quickly spreads widely on social networks due to their low cost and high speed of dissemination. 4 Upon accessing information on the internet, users cannot accurately determine whether an article is real or fake news in the first instance. The content of an article is based on the information received by the author and written from their perspective, with various motivations behind the writing. These motivations can include malicious intent, political biases, the deliberate dissemination of incorrect information, and the fabrication of events. Such misleading information is collectively called “fake news,” 5 which can mislead users, leading to incorrect information and erroneous judgments. Incorrect information can become a threat as it spreads rapidly, 6 resulting in significant losses, especially on social media platforms. Examples include false claims about COVID-19 and fraud during the 2016 US presidential election, 7 both propagated extensively through social media, causing many users to make erroneous judgements. 8
The textual and visual information of fake news are closely related. Scholars have pointed out that articles with accompanying images not only attract readers’ attention but also enhance the persuasiveness of the content. Consequently, unlike in the past when fake news articles were primarily text-based, nowadays news articles and any content intended to capture public attention utilize highly provocative images to attract the masses, including fake news. Artificial intelligence (AI) technologies have become increasingly mature in recent years, therefore many researchers have focused on the issue of fake news detection employing various machine learning and deep learning techniques.
9
The accuracy of these methods has achieved impressive results, with some studies employing multiple levels and categories to identify fake news, using different machine learning and deep learning classifiers, resulting in accuracy rates of over 90%. Other scholars have used the characteristics of text, social media, and users to obtain features and identify instances of online bullying through different machine learning classification methods.
10
Numerous researchers have successfully employed AI methods in their studies of fake news detection. Therefore, this research will adopt an AI-based approach to detecting fake news and related studies. However, previous research on fake news detection has relied chiefly on single-text analysis or natural language processing techniques, with less emphasis on multimodal analysis and the combined analysis of textual and visual information. Neglecting either of these modalities may limit the comprehensive exploration of online fake news issues. Hence, this study employs a multimodal fusion approach, using different fusion techniques to merge textual and visual information features, aiming to improve the quality of fake news prediction. When using both text and images, data imbalance issues may arise, leading to an inability to accurately convey information. Therefore, we incorporated additional preprocessing methods in the experiments to enhance the final performance. The contributions of this research are as follows.
This study proposes a model using multimodal fusion to identify fake news, aiming to curb misinformation. The framework integrates textual and visual information, undergoing data cleaning before feature extraction. The model combines different modalities using a multimodal fusion approach, showing an advantage over single-modality methods like the Bidirectional Encoder Representations from Transformers (BERT). Using the Gossipcop and Fakeddit datasets, accuracy for title text features was only 63% and 83%, respectively, while for image features, it was 72% and 65%, indicating the need for a multimodal approach that achieves accuracy rates of 85% and 90%. The fusion of textual and image data significantly enhances accuracy and F1-score. Early fusion tests improved accuracy and F1-score by up to 15% and 17%, respectively. Late fusion tests further improved accuracy by an additional 3% and F1-score by 4%, resulting in a final accuracy and F1-score of 90%. The proposed model does not only achieve results comparable to deep learning architectures more quickly but also offers flexibility. The best F1-scores for the Gossipcop Dataset and the Fakeddit Dataset were 90% and 88%, respectively, after implementing joint fusion and late fusion together, demonstrating its potential for practical application in fake news detection.
Multimodal fusion
Multimodal fusion is the combination of multiple forms of information, such as text, speech, images, sound and waves, which can be considered different modalities. 11 Each modality has its way of representation and exhibits different patterns, but there may be mutual influence and complementarity among different modalities. The characteristics of multimodal data are redundancy and complementarity, and by effectively extracting feature information from each modality, richer information can be obtained.12,13 Multimodal fusion methods can be classified into three types: early fusion, joint fusion and late fusion. 12 Different fusion methods can affect the recognition performance of the model, and more details can be found in the ‘Multimodal fusion strategies’ section.
Multimodal fusion strategies
Feature fusion methods can be classified into three types:
Early fusion
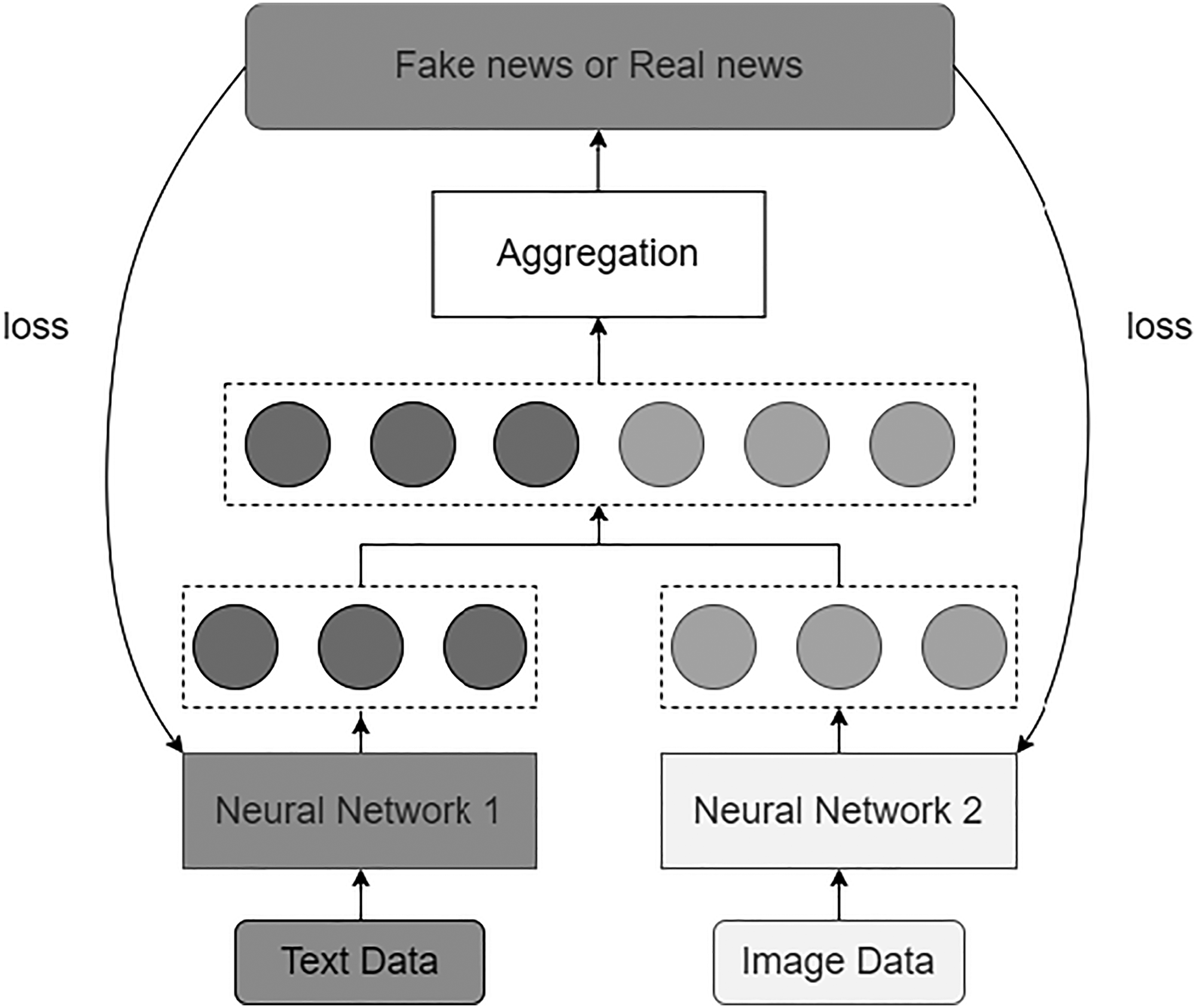
After extracting features from different modalities, the features are fused and inputted into the same model for training. This process is called rare fusion. In Figure 1(a), early fusion Type I refers to fusing the original features, while Type II refers to fusing features extracted through neural network methods.

Multimodal fusion Methods 12 .
Joint fusion or intermediate fusion
Joint fusion is a method that transforms data of different modalities into high-dimensional representations and performs fusion at the intermediate layers of the model. Its main advantage lies in the flexibility to choose the fusion location. Compared to early fusion, the critical difference in joint fusion is that the Loss value is returned from the prediction model to the feature extraction model in the neural network during the training process, creating better feature representations for each training iteration. In Figure 1(b), joint fusion is divided into two types: Type I indicates that both features require feature extraction. By contrast, Type II indicates that one of the features already contains the required information in the dataset and does not need to be extracted again.
Late fusion
Late fusion refers to the process of combining the results predicted by multiple models for different modalities to make the final decision. Therefore, late fusion is also known as decision-level fusion, as shown in Figure 1(c).
Fake news detection
Fake news spreads rapidly through platforms and social media, making dissemination faster, cheaper and more accessible. With the development of the internet, anyone can use the web or social networks to propagate their own messages or harmful content, leading to the rapid spread of fake news. Therefore, identifying fake news has attracted significant attention from researchers and has become an important research topic. Numerous studies have focused on using artificial intelligence methods for text detection to identify fake news. S. R. Sahoo et al. have conducted fake news research using the social media platform Facebook, 14 wherein they proposed a fake news detection method using machine learning and deep learning classifiers in the Chrome environment, yielding promising results with an accuracy rate as high as 99.4%. Other researchers have proposed deep learning methods for fake news detection, such as a hybrid convolutional neural network–recurrent neural network (CNN-RNN) approach 15 or enhanced deep learning long short-term memory (LSTM) techniques. 16
However, combining textual and visual information can provide various cues for fake news detection. 17 Therefore, fake news detection based on multimodal information has become a recent research focus.18–22 In the past few years, some studies have started investigating fake news's visual features.23,24 Since it is challenging to find images that match the fabricated stories when creating fake news, fake images inconsistent with the textual content are often used. 25 As online articles and news reports often include a significant amount of text and images, such as screenshots of news-related reports, message screenshots and any other visuals, extracting relevant features between images and text is crucial. Deep learning has achieved remarkable success in text classification, and in recent years, language pre-training models such as Embeddings from Language Model (ELMo), Generative Pre-trained Transformer (GPT) and BERT 26 have brought breakthroughs in text processing. Hua, J. et al. proposed the BERT-based back-Translation Text and Entire-image multimodal model with Contrastive learning (TTEC) 27 to address the challenge of detecting fake news, which suffers from low efficacy due to limited multimodal information and small data size. The experimental results demonstrate that TTEC achieves a macro F1-score of 0.805. Jing, J. et al. propose a progressive multimodal rumor detection model, 28 which consists mainly of a BERT-based text feature extractor, a transformer-based visual feature extractor and a progressive multimodal feature fusion process. The method achieved 83.3% accuracy on the Twitter dataset. Despite significant progress in multimodal fake news detection, several challenges remain. First, although some existing models attempt to improve performance by leveraging multimodal representations, they often utilize only the final layer of pre-trained models, such as BERT, 26 to realize text representations, neglecting the contextual information in multimodal representations. Second, despite efforts to combine representations from different modalities, the aggregation of visual and textual features is still inadequate. It requires utilizing the complementarity of information and the similarity between different modalities. Third, most current research investigates the performance of fake news detection on a single data type or specific domain datasets. However, research on the generalization ability of multimodal methods to domain-independent and domain-specific datasets is insufficient. Therefore, multimodal approaches can address the above questions and have become a popular topic in fake news detection in recent years.
Methodology
Research framework
This study aims to distinguish between fake news and real news using different fusion methods, as shown in Figure 2. The flowchart describes from top to bottom a fake news detection method that enhances accuracy through multimodal fusion technologies. It starts with analyzing the data sources, for example Gossipcop and Fakeddit, with a set of tools to scrub the data, which can be transformed into a format for the machine learning models.

Research framework.
Within the feature extraction phase, content text features, headline text features and image features are processed by the BERT and ResNet50 models, respectively. The BERT model is used to process textual data. Its bidirectional processing feature makes it particularly strong in text comprehension, enabling it to capture the subtle semantic differences in the context of news articles. The ResNet50 model is used for image data analysis and effectively identifies and processes visual information related to news through its deep residual network structure. This structure allows it to engage in deeper learning without causing training difficulties, which is very useful for extracting complex features from images. After feature processing, the flowchart delineates three fusion strategies: early fusion, joint fusion and late fusion, aimed at combining text and image features. Finally, these combined features are input into several machine learning models, including Support Vector Machine (SVM), Logistic Regression (LR), XGBoost (Extreme Gradient Boosting) and CatBoost, for the final fake news identification. In this process, both textual and pictorial contents within news data are considered to achieve greater accuracy in the veracity of news information. Furthermore, different machine learning models are employed to train and test the variability among different variables, ensuring the correctness of the information. This sequence of steps constitutes a framework for fake news detection that integratively utilizes text and image data. The following is a more detailed description within the research framework. The specifications of the system used in this study are presented in Table 1.
Development environment specifications.

Fake news-related datasets
Fakeddit dataset
This study uses the Fakeddit dataset 29 as the training dataset, which includes textual and image data of fake news across multiple categories, forming a novel multimodal dataset. The original paper categorized the samples in this dataset into binary, 3-class and 6-class classifications, with corresponding highest accuracies of 0.8909, 0.8890, and 0.8588, respectively. In this research, we experiment and compare using the binary labels from this dataset. In total, the dataset comprises 562,707 samples of both real and fake news data, with 39% (220,140 samples) representing fake news and 61% (342,568 samples) representing real news.
Gossipcop dataset
The Gossipcop dataset is provided by the Gossipcop website. The website contains records of various fake news articles and is considered a credible source. The dataset consists of a total of 21,666 samples. However, since the data collection for this dataset was conducted in 2019, some websites mentioned may have been taken down or are no longer accessible. Therefore, the pre-processed dataset used in this study contains fewer samples, as explained in the ‘Data pre-processing’ section. Of the available samples, 5196 are labeled as fake news and 16,470 are labeled as actual news, totaling 21,666 samples.
Gossipcop is a reputable dataset focused on celebrity news, offering verified true and false news, essential for studying fake news in a highly prevalent domain. Fakeddit, a novel multimodal dataset, includes extensive text and image data across multiple fake news categories with rich annotations, making it ideal for exploring multimodal fusion techniques. These datasets provide a broad coverage, diverse data types and credible information, essential for validating the effectiveness and generalizability to the model of this study.
Data pre-processing
As mentioned previously, the fake news datasets used in this study came from the Fakeddit and Gossipcop websites, and consisted of raw, unprocessed textual data. Tables 2 and 3 provide simple statistics of the data from the two sources. Although the datasets seem large, the amount of available data is significantly reduced after data cleaning. This is primarily due to many URLs failing to reconnect and losing various data instances.
Fake news datasets.
Train and test data.

Data cleaning
After obtaining the dataset, this study first performs English tokenization on the data, filtering out punctuation marks, stickers, and hyperlinks and removing unnecessary noise. The data are then processed with stop word removal. 24 Lastly, an error-correction spell check is conducted to correct any misspelled English terms and replace them with the correct words, ensuring accurate interpretation and judgment when extracting data features.
Feature extraction
Word2vec and Doc2vec
This study utilizes two methods for text feature extraction: Word2vec 30 (word embeddings, word vectors) and Doc2vec 31 (sentence embeddings, paragraph vectors, Paragraph2vec). Word2Vec is used to transform words into vector space, capturing the semantic relationships between words within the context. Doc2vec represents features of sentences in a similar way that vectors represent individual words, mapping each sentence to a vector space where semantically similar sentences are positioned close to each other. By using Doc2Vec, the study can analyze the textual content at a document level, incorporating a broader context than Word2Vec's word-level analysis. This method allows the system to capture the essence of entire articles, aiding in the identification of fake news by analyzing how topics are discussed or presented in the document. The well-known natural language processing (NLP) library, Gensim, 32 obtains 50 Word2vec features for each text content and 50 Doc2vec features for each text content.
BERT feature vectors
In this study, BERT Base feature vectors with a dimension of 768 are obtained. BERT has two versions: the Base version used in this research, with a hidden state size of 768, and the Large version, which has a hidden state size of 1024. The number 768 represents the hidden state size, indicating that each token is transformed into a 768-dimensional vector. The result of outputs from all layers forms a three-dimensional tensor where the dimensions are the number of tokens, the hidden state size (768), and the number of layers (12).
Image feature vectors
How computers discern images is different from how humans perceive them. While humans can directly recognize the shape and color of an image, computers interpret images as combinations of numerical values. In other words, an image can be seen as an organized collection of numbers. In this study, the image model employs ResNet50 to extract the image features. ResNet50 is a widely used model known for its moderate size and excellent performance in recent years. The research extracts the 1000-dimensional vector obtained from the last convolutional layer of ResNet50 as the image features.
Fusion methods
This study combines two types of features, text and image, to enhance the accuracy and diversity of the model. There are three fusion methods: early, joint, and late. These three methods are introduced as follows.
Early fusion
This study employs the early fusion method using the Concat and Add
31
techniques, as shown in Figure 3.
(1) Concat
Early fusion.
In this study, the early fusion method uses the concat and add techniques, as shown in Figure 3. The following Equation (1) represents the concatenation of individual output channels: (2) Add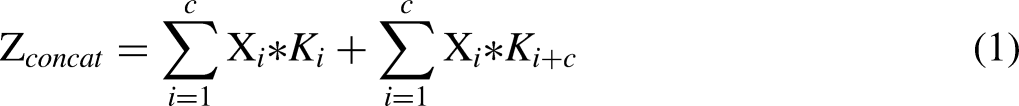
The add method involves adding the features together, keeping the number of channels unchanged. In this study, the dimension of the image or text features remains fixed, even when the amount of information increases. The add operation is performed by adding the corresponding features and then proceeding with the subsequent convolutional operation. Add can be considered a particular form of concat, where the computation is simplified compared to concat. If the number of channels is the same and followed by convolution, add is equivalent to concat followed by sharing the same convolutional kernel for corresponding channels. The following Equation (2) represents the addition of individual output channels:
Joint fusion
Joint fusion refers to transforming different modal data into high-dimensional feature representations and fusing them at the intermediate layer of the model. In this study, we employ text and image modal features. First, both modal data are transformed into high-dimensional vectors. Then, element-wise multiplication is performed, followed by a sum pooling operation. This yields the result of the joint fusion method, as illustrated in Figure 4.

Joint fusion.
Late fusion
Late fusion involves feature fusion using averaged fusion
33
and ensemble learning
34
methods, as shown in Figure 5.
(1)

Late fusion.
The results obtained from all classifiers are averaged to obtain the final prediction result. For example, if Classifier 1 predicts 60% as fake news and 40% as real news, and Classifier 2 predicts 35% as fake news and 65% as real news, taking the average of these results yields 47.5% as fake news and 52.5% as real news. Therefore, the result for this data instance is considered as real news.
(2)
Ensemble learning aims to generate a more robust model by integrating multiple models. It mainly consists of three methods: Bagging,
35
Boosting
36
and Stacking.
37
In this study, we employ the XGBoost
38
and CatBoost
39
methods for the final training. XGBoost and CatBoost are based on the gradient boosting–tree
40
framework in Boosting. Each training data item is assigned different weights in Boosting based on its difficulty. For example, if a wrong judgment is made in the first training, its weight will be increased in the following training to make it easier for the following estimator to extract. This process is repeated to train a stronger estimator and improve accuracy. CatBoost is a relatively new open-source machine learning algorithm in the Boosting method. Therefore, in addition to XGBoost, CatBoost is also used for classification prediction in this study.
Classification models
As mentioned previously, this study employs four different classification models to accurately distinguish between authentic and fabricated content to achieve the fake news detection process: Logistic Regression 41 (LR), Support Vector Machine 42 (SVM), XGBoost 38 and CatBoost. 39 LR analyzes the relationship between dependent and independent variables. In this study, LR is used to determine whether the content of the text and image dataset is fake news, making it suitable for binary classification. SVM is effective in solving classification and regression problems with high-dimensional features. It performs well even when the number of features exceeds the number of samples, and it exhibits high accuracy and strong capability regardless of the data size. XGBoost leverages Boosting techniques to combine multiple decision trees into a more robust predictive model, which can be used for classification and regression tasks, including predicting continuous numerical values. This approach enhances the accuracy and reliability of identifying fake news in text and image datasets. One of CatBoost's advantages is that it reduces the need for extensive hyper-parameter tuning, thereby lowering the risk of overfitting and making the model more generalizable. It is particularly well-suited for handling categorical and numerical features, which aligns perfectly with the requirements of this study.
Evaluation metrics
To accurately evaluate the performance of the fake news detection model, this study employs four key evaluation metrics: Accuracy, Precision score, Recall score and F1-score. The calculation formulas for these metrics are presented, respectively, as Equations (3), (4), (5) and (6). Recall, also known as sensitivity, is directly used in the F1-score calculation. Higher sensitivity improves the F1-score if precision remains constant. F1-score provides a balance between sensitivity (recall) and precision, offering a comprehensive view of a model's accuracy in both identifying positives and avoiding false positives.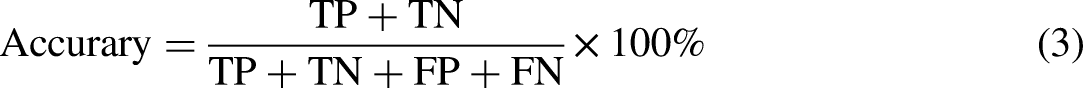

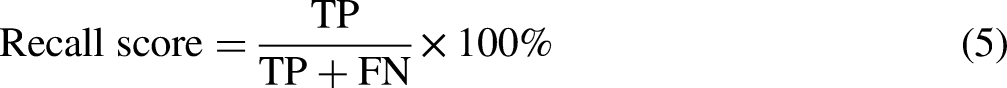

Experiments
As mentioned previously, this study employs four different classification models, LR, SVM, XGBoost and CatBoost, to accurately distinguish between authentic and fabricated content, aiming to achieve effective fake news detection. Each of these models is chosen for its unique strengths and methodologies, making them suitable for various aspects of data classification involved in the detection process. To optimize the performance and accuracy of these models, specific parameters and settings were utilized. The image shape is set to (64, 64, 3), which accommodates the three color channels in the images. For text data, the shape is set to (100). The embedding dimension is configured at 128 to effectively capture the semantic information in the text data. The models are designed with 64 hidden units, a dropout rate of 0.3 to prevent over-fitting, and a learning rate of 0.001 to ensure stable training. The training process runs for 10 epochs with a batch size of 32. In terms of the network layers, the architecture is detailed as follows: the image processing component comprises 50 layers, the headline processing part consists of 13 layers, the body text processing also includes 13 layers, the fusion and classification part incorporates 3 layers. These configurations collectively contribute to the robustness and efficiency of the fake news detection models used in this study.
Through the research framework presented in Figure 2, this section encompasses four experimental scenarios and their results. Experiment #1 aims to study the impact of single-modal data and data imbalance on the accuracy of fake news detection algorithms. Its purpose is twofold: to determine how the disproportion between fake news and real news in the dataset affects the reliability of prediction results and to evaluate the effectiveness of single-modal data balancing techniques in achieving balanced representation and more accurate classification outcomes. The primary focus of Experiment #2 is to examine the effectiveness of different fusion methods, specifically Concat fusion and Add fusion, in the context of early fusion for fake news detection. It aims to explore how varying the dimensionality of image features and combining them with text features affects the model's performance in terms of accuracy, F1-score, and recall, particularly across different sizes of datasets. The research investigates the optimal combination of text and image data to improve the detection of fake news.
Moreover, Experiment #3 primarily investigates the effectiveness of the joint fusion method in the classification and prediction of fake news. It aims to determine how the combination of features transformed into high-dimensional vectors at the intermediate layer of the model impacts the overall performance, as measured by accuracy and F1-score, in different datasets (Gossipcop and Fakeddit). The study seeks to understand the improvements in fake news detection accuracy and precision when employing this joint fusion strategy. Experiment #4 primarily aims to explore the effectiveness of late fusion methods, specifically the averaged fusion method and ensemble learning method, in the classification and prediction of fake news. It focuses on determining how these late fusion techniques, which involve averaging results from separate classifiers for image and text information, impact the accuracy, recall rate and F1-score of fake news detection in different datasets. The goal is to assess whether these late fusion methods provide an improvement in identifying fake versus real news.
Experiment #1: data balancing comparison using a single-modal approach
The final purpose of Experiment #1 is to separately incorporate all textual and image single-feature information into past classification models such as LR, SVM, XGBoost, and CatBoost for comparison. First, the data undergo basic feature processing separately, with text features extracted using BERT and image features extracted using ResNet50 to obtain 1000-dimensional vectors. We integrate and compare the results obtained from different features to provide a basis for comparison and judgment in subsequent feature fusion experiments. Previous research has extensively used single features to identify fake news, with most studies focusing on text recognition. Studies using single-image recognition for fake news detection are relatively scarce. Therefore, this paper aims to observe whether conclusions drawn from text and images affect the research results, further subdividing the text into title and content features.
However, the data used in this study exhibit a significant imbalance in the proportion of fake news to real news. Table 4 presents the quantities of imbalanced and balanced datasets, and the original data are split into training and testing sets. In the training dataset, there is a notable disparity between the proportions of fake news and real news, especially in the Gossipcop Dataset, where the ratio of fake news to real news is 3:17. The data imbalance can potentially affect accuracy. There is a need to employ data balancing techniques to achieve reliable accuracy and obtain the most accurate predictive results. After data balancing, the number of fake and real news in the Gossipcop Dataset is determined to be 10,846, resulting in a 1:1 ratio. Similarly, in the Fakeddit Dataset, the number of fake news is adjusted to match the number of real news, resulting in 29,826 instances for both classes, also with a 1:1 ratio. The ratio of the training set to the test set is 8:2.
Data balancing—imbalanced versus balanced dataset quantities.

The results and improvements in model recognition performance after data balancing can be observed in Tables 5 and 6. From Tables 5 and 6, it can be observed that in the case of using imbalanced data, when using pure textual BERT features, the F1-score reaches a maximum of 0.82 in the Fakeddit Dataset, surpassing the value of 0.73 in the Gossipcop Dataset. Furthermore, when solely utilizing image features (ResNet50), as presented in Table 6, the highest F1-score in the Gossipcop Dataset is 0.77, outperforming the 0.72 in the Fakeddit Dataset. Consequently, it can be inferred that in imbalanced scenarios, pure textual recognition outperforms pure image recognition, especially in the case of the Fakeddit Dataset.
Comparison between balanced and imbalanced data—title text feature.

Comparing balanced and imbalanced data—image feature.

However, in balanced scenarios, the improvement in the F1-score is relatively modest when using pure textual BERT features. By contrast, with pure image features (ResNet50) in Table 6, the F1-score reaches a remarkable 0.88, a 16% improvement, demonstrating that in balanced conditions, pure image recognition surpasses pure textual recognition, with the most significant impact seen in the Fakeddit Dataset.
After balancing, the Gossipcop Dataset shows an improvement of 11% in accuracy and 24% in precision but a decrease of 19% in recall, resulting in a decrease in overall accuracy. The overall F1-score has improved by a maximum of 8%. In the Fakeddit Dataset, the balanced dataset shows improvements of up to 2% in accuracy, 2% in precision, 4% in recall and 2% in F1-score. This indicates an increase in the proportion of correctly predicted fake news, with improvements observed in all metrics. Compared to the Gossipcop Dataset, the Fakeddit Dataset had a smaller imbalance in the original data between true and fake news, resulting in a maximum difference of 4% after balancing the data.
This study presents the results in terms of accuracy and F1-score. Overall, the results show improvements in all single-feature recognition methods but decreased recall, indicating an increase in false predictions for true news. It is observed that the overall improvement in the Gossipcop Dataset is larger than in the Fakeddit Dataset, which is due to the larger disparity in the true and false news proportions in the Gossipcop Dataset compared to the Fakeddit Dataset. Therefore, balancing the data can significantly enhance the overall performance, and the more imbalanced the data, the poorer the results. When faced with real-world scenarios with highly imbalanced data, data balancing technology can be used to improve the reliability and accuracy of the fake news detection systems. Based on these comparative results, in subsequent experimental research, we will use balanced data for model training and conduct further comparisons and analysis of the outcomes.
Experiment #2: early fusion for fusion classification and prediction with each information
This study used two methods to perform the experiment under early fusion. The first method is the Concat fusion method, and the second is the Add fusion method. The following two sections provide introductions for each method, with comparisons using the Concat and Add fusion methods.
Comparison using Concat fusion method
The text and image data are combined and concatenated when using the Concat fusion method. In this study, some modifications were made when concatenating the image features. The image features consist of a total of 1000 vector features, and they were divided into three groups: Fake News All Text Features + the first 300 vectors, Fake News All Text Features + the first 500 vectors, and Fake News All Text Features + all 1000 vectors, where Fake News All Text Features include both title text features and body text features. The results of these fusion methods were compared and presented under four classifiers, as in Table 7. The following provides a detailed explanation of the experimental results of the fusion approach.
Performance of concatenation of title text features, body text features, and three different image vector features (300 vector features, 500 vector features, 1000 vector features) in four classifiers.
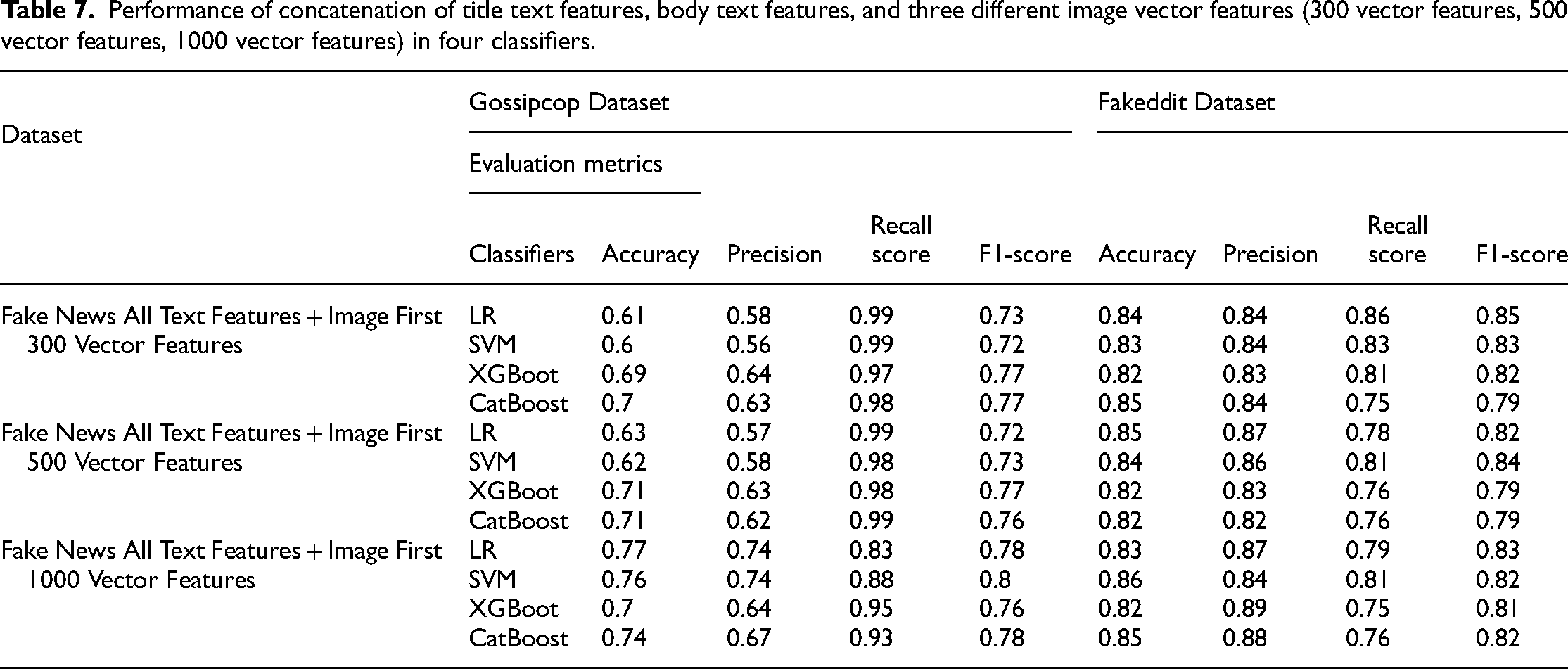
Using different dimensional image features in combination with all text features, the results in terms of F1-score indicate that in Gossipcop Dataset, the combination of text features and the first 1000 vector features of the image outperform the combination of text features and the first 500 vector features, which in turn outperforms the combination of text features and the first 300 vector features. The respective F1-scores are 0.8, 0.77, and 0.77. The difference between the 1000-dimensional image vectors and the 500-dimensional and 300-dimensional image vectors is 0.03, indicating that reducing the dimensionality of the image features is not suitable when the dataset is small. In the Fakeddit Dataset, the F1-score shows that using text features combined with the image's first 300 vector features outperforms the combinations with the first 500 and 1000 vector features, respectively. The F1-scores obtained are 0.85, 0.84, and 0.83. The difference between the 300-dimensional image vectors and the 500-dimensional and 1000-dimensional image vectors is 0.01 and 0.02, respectively. This suggests that when the dataset is large, the dimensionality of the image features can be reduced from 1000 to 300 to decrease model complexity.
Comparison using Add fusion method
In this experiment, the Add fusion method maintained the same number of channels. The title and text information were added together, and the image was fused using 1000 vector features. The results are presented in Table 8, and further explanations are provided as follows.
Performance of Add fusion method on four classifiers.

In this study, the results are presented and expressed in terms of accuracy and F1-score values. In the Add fusion method, for the Gossipcop Dataset, the best accuracy achieved was 0.84, and the best recall was 0.95, indicating that 95% of the true fake news cases were correctly identified as fake news. The best F1-score value was 0.87, representing a balanced result of precision and recall. Conversely, for the Fakeddit Dataset, the best accuracy achieved in the Add fusion method was 0.87, showing a 1% improvement compared to using a single feature. The best recall was 0.88, slightly lower than the Gossipcop Dataset performance. The best F1-score was 0.84, indicating that the Add fusion method improved accuracy and F1-score compared to individual models.
By combining textual and image features, the model can gain a more comprehensive understanding of the news content, thereby enhancing the accuracy and reliability of fake news detection. This multimodal fusion approach overcomes the limitations of single-modal information capture by providing richer data features for precise classification. However, the Concat fusion method involves handling a large number of high-dimensional features, which may increase the computational cost and training time of the model. Additionally, an excessive number of features can lead to model overfitting, especially when the training data are insufficient. Although the Add fusion method is computationally simpler, it may not fully utilize the complete information from each modality. Therefore, this experiment suggests that when dealing with smaller datasets, such as the Gossipcop Dataset, the Add fusion method can achieve the best F1-score with simpler computations. For larger datasets, such as the Fakeddit Dataset, the Concat fusion method can be employed, which, despite being more computationally complex, allows for fuller utilization of the complete information from each modality.
Experiment #3: joint fusion for fusion classification and prediction with each information
In this study, each feature was transformed into high-dimensional vectors and fusion at the intermediate layer of the model, completing the joint fusion method. That is, text and image modal features are transformed into high-dimensional vectors and predictions are made using LR, SVM, XGBoost, and CatBoost classifiers. Table 9 presents the results obtained from the two datasets individually and the comparative results. In this joint fusion, the best results can be seen with an F1-score of 0.9 for the Gossipcop Dataset and an accuracy of 0.89 for the Fakeddit Dataset.
Performance of the joint fusion method across four classifiers.

We can see that using the joint fusion method has achieved noticeable improvements in the experiment. For the Gossipcop Dataset, the accuracy increased from 0.84 to 0.85, and the F1-score increased from 0.87 to 0.9. For the Fakeddit Dataset, the accuracy increased from 0.87 to 0.89, and the F1-score increased from 0.85 to 0.88. Compared to Experiment #2, we can observe that in the Gossipcop Dataset, the F1-scores using the Joint Fusion technique are superior to those of the Early Fusion's Concat and Add methods, with F1-scores of 0.9, 0.8 and 0.87, respectively. Similarly, in the Fakeddit Dataset, the F1-scores using the Joint Fusion technique also outperform the Early Fusion's Concat and Add methods, with F1-scores of 0.88, 0.5 and 0.84, respectively. By using Joint Fusion, which integrates features from different modalities at the intermediate layers, the results are clearly superior to those of the single-modal methods in Experiment #1.
Experiment #4: late fusion for fusion classification and prediction with each information
This study conducted the late fusion using the averaged fusion method and the ensemble learning method. The following two sections explain the two methods.
Averaged fusion method
The averaged fusion method obtains results separately for image and text information using individual classifiers. The study uses the weights from the last layer of the model to make a judgment. The results are then averaged, and the predicted label is determined based on which category has a higher proportion of averaged scores—either fake or real news. Table 10 presents the detailed numerical results and explanations for the averaged fusion method in late fusion.
Performance of averaged fusion method on four classifiers.

Using the averaged fusion method in the Gossipcop Dataset, the best accuracy achieved was 0.85, with a recall rate of 0.99. This means that only 1% of the fake news data were incorrectly predicted, which is a relatively high proportion. The best F1-score obtained was 0.81. In the Fakeddit Dataset, the accuracy reached its highest value of 0.9, the best of all the methods in Experiments #1–4. When considering accuracy alone, this method is suitable for the Fakeddit Dataset. The results also show that multimodal fusion strategies significantly outperform single-modality methods in Tables 5 and 6 in terms of accuracy and F1-scores.
Comparison using ensemble learning method
In late fusion, the ensemble learning method integrated predictions using single-feature recognition. This study employed two methods, namely, XGBoost and CatBoost. Table 11 presents the results and comparisons for all experiments.
Ensemble learning performance in four classifiers.

This experiment was conducted with balanced datasets and involved comparisons. First, when using a single BERT feature with only the title text (Code A), the highest accuracy achieved is 0.84. When using a single image feature (Code B) and extracting data with ResNet50, the accuracy of the Gossipcop Dataset information can reach 0.76. However, compared to the accuracy of text recognition alone, the accuracy is relatively lower, with a recall of 0.97. In early fusion, concatenating the data using the Concat method (Codes C, D, E), the highest accuracy can reach 0.85, with the best F1-score of 0.82. However, when using the Add method (Code F) in early fusion, the highest accuracy can reach 0.87, with the best F1-score of 0.83. Using the joint fusion method (Code G), the accuracy can reach 0.89, and the F1-score can reach 0.88. Finally, in late fusion, using averaged fusion (Code H) and the ensemble learning method in this experiment, the accuracy can reach 0.9, but the best F1-score is only 0.84. Based on the pure use of accuracy to explain the results, accuracy is improved from Codes A to H. It can be concluded that using multimodal approaches is an effective method to improve accuracy. Furthermore, when comparing XGBoost and CatBoost, CatBoost demonstrates higher accuracy.
This experiment was conducted with balanced datasets and involved comparisons. First, when using a single BERT feature with only the title text (Code A), the highest accuracy achieved is 0.84. When using a single image feature (Code B) and extracting data with ResNet50, the accuracy of the Gossipcop Dataset information can reach 0.76. However, compared to the accuracy of text recognition alone, the accuracy is relatively lower, with a recall of 0.97. In early fusion, concatenating the data using the Concat method (Codes C, D, E), the highest accuracy can reach 0.85, with the best F1-score of 0.82. However, when using the Add method (Code F) in early fusion, the highest accuracy can reach 0.87, with the best F1-score of 0.83. Using the joint fusion method (Code G), the accuracy can reach 0.89, and the F1-score can reach 0.88. Finally, in late fusion, using averaged fusion (Code H) and the ensemble learning method in this experiment, the accuracy can reach 0.9, but the best F1-score is only 0.84. Based on the pure use of accuracy to explain the results, accuracy is improved from Codes A to H. It can be concluded that using multimodal approaches is an effective method to improve accuracy. Furthermore, when comparing XGBoost and CatBoost, CatBoost demonstrates higher accuracy.
In the aforementioned experiments, the classification training time for each model varied. The recognition time for a single text feature was the least, at 56 min and 34 s. The recognition time for a single image feature was 1 h and 9 min. For Early Fusion using the Add method, the training time was 1 h and 25 min. Joint Fusion required a minimum of 1 h and 19 min, and Late Fusion using the Averaged Fusion method took at least 1 h and 17 min. Using the Gossipcop and Fakeddit datasets, when employing a single recognition method, the F1-score for title text features was 79% and 84%, respectively, while for image features, it was 80% and 88%. However, in multimodal experiments, the F1-score reached 90% and 88%. That is, the multimodal experiments significantly improved the F1-score, achieving up to 90%, highlighting the effectiveness of multimodal fusion in enhancing fake news detection accuracy.
Conclusions
This study proposes an effective model for detecting fake news by combining different modalities using a multimodal fusion approach. This model can handle natural language tasks compared to the deep learning text recognition method BERT. Using a single feature is challenging in the context of fake news detection. The Gossipcop and Fakeddit datasets from the FakeNewsNet dataset were used to compare and validate the proposed model. When using a single recognition method, the accuracy for title text features was 63% and 83%, while for image features, it was 72% and 65%, respectively. The results show that text features’ accuracy is higher than image features. This could be because fake news content often utilizes diverse images, and the image features extracted by ResNet50 may not capture the relevant features related to fake news. This suggests that the accuracy of image features in a single recognition model is lower, which is a reasonable phenomenon.
Although the performance of single-feature recognition is unsatisfactory, it still plays a specific role in fake news detection. Subsequent experimental results demonstrate that a multimodal fusion approach can significantly improve accuracy. This study compares feature fusion models and finds that feature fusion recognition methods can effectively enhance model accuracy. In the early fusion tests, the accuracy and F1-score can be improved by up to 15% and 17%, respectively, compared to single features. In the late fusion tests, an additional 3% improvement in accuracy and 4% in F1-score can be achieved, resulting in a final accuracy and F1-score of 90%. It is also observed that integrating both fusion methods leads to higher results. After implementing joint fusion and late fusion together, the best F1-score for Gossipcop Dataset and Fakeddit Dataset were 90% and 88%, respectively. In conclusion, the experimental process and results confirm that multimodal fusion enhances the results in fake news detection, and the overlapping use of two fusion methods achieves the optimal F1-score.
The fusion of textual and image data forms the dataset for fake news identification in this paper. The proposed model and method ultimately contribute to improving judgment in practical applications of fake news identification. Recognizing fake news is a challenging process; however, this research observes that using different feature extraction and fusion methods can enhance accuracy and F1-score in the identification process. Therefore, in future practical applications for discerning fake news issues, the framework proposed in this paper can be utilized. It not only achieves results comparable to deep learning architectures more quickly but also provides flexibility in combining different features to achieve ideal confirmation and diagnostic analysis.
As the presentation of news information becomes increasingly diversified, future research should explore the integration of fake news in the form of images and audio. In training models that combine visual and auditory news content, the complexity of the image content, the accuracy of the correspondence between audio and visual content, and the labeling techniques will all impact the overall training results of the model. In other words, the quality and quantity of the video data used for training will significantly affect the effectiveness of fake news detection models. The challenge of developing multimodal fake news detection models that can handle text, images, audio or videos while balancing generalizability and computational efficiency remains a limitation of the current technology, yet it presents an area for further development.
Footnotes
Author contributions
Conceptualization: S.-Y.L. and Y.-H.C.; methodology: S.-Y.L., Y.-C.C., and Y.-H.C.; software: Y.-H.C. and S.-H.L.; validation: Y.-C.C. and S.-H.L.; formal analysis: Y.-H.C.; investigation: Y.-H.C.; resources: S.-Y.L.; data curation: S.-Y.L. and Y.-H.C.; writing—original draft preparation: S.-Y.L., Y.-C.C., and Y.-H.C.; writing—review and editing: S.-Y.L., Y.-C.C., and K.-M.C.; visualization: Y.-C.C. and K.-M.C.; supervision: S.-Y.L. and Y.-C.C.; project administration: S.-Y.L., Y.-C.C., and K.-M.C.; funding acquisition: S.-Y.L. All authors have read and agreed to the published version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this paper.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the National Science and Technology Council, Taiwan, under Grant numbers of 109-2410-H-197-002-MY3, 112-2410-H-A49-087-MY2, and 112-2221-E-216-005.