
Abstract
Introduction
The diagnostic boundaries between schizophrenia and bipolar disorder are controversial due to the ambiguity of psychiatric nosology. From this perspective, it is noteworthy that formal thought disorder has historically been considered pathognomonic of schizophrenia. Given that human thought is partially based on language, we can hypothesize that alterations in language may help differentiate between schizophrenia and bipolar disorder.
Method
In this exploratory study, we employed natural language processing techniques to identify differences in language abnormalities between patients with schizophrenia and bipolar disorder. The KoBERT and KoGPT language models were used to determine sentence acceptability, assessing how natural and therefore acceptable a given sentence is to the general population. In addition, semantic word networks were constructed for each group, and network measures were compared.
Results
Patients with schizophrenia or bipolar disorder used less acceptable sentences than controls. Post hoc analysis revealed that the schizophrenia group used less acceptable sentences than the bipolar disorder group. Furthermore, the semantic word networks of the three groups were significantly different in the three network measures. Post hoc analysis revealed a significant difference between the schizophrenia and bipolar disorder networks. The bipolar disorder network generally fell between the schizophrenia and control networks, except in terms of the average clustering coefficient.
Conclusions
Patients with schizophrenia and bipolar disorder showed significant differences in sentence acceptability as calculated by the language model, as well as in the network metrics estimated by semantic network analysis. Thus, language abnormalities may represent surrogate markers of thought disorders and help differentiate between schizophrenia and bipolar disorder.
Introduction
Schizophrenia and bipolar disorder are major psychiatric illnesses that have been traditionally considered distinct; schizophrenia is characterized by positive symptoms such as hallucinations and delusions, whereas bipolar disorder is marked by episodes of mania and depression. 1 Psychiatric illnesses are generally diagnosed based on committee-consensus diagnostic criteria outlined in the Diagnostic and Statistical Manual of Mental Disorders (DSM). 1 As a result, diagnoses are heterogeneous, and in some cases, the boundaries between schizophrenia and bipolar disorder are blurred. 2 Patients believed to have schizophrenia may later be re-diagnosed with bipolar disorder, and similarly, a diagnosis of bipolar disorder may change into schizoaffective disorder or schizophrenia. Because the nosology of mental illness is less clear than that of physical illness, it is imperative to accurately define the phenotype of mental illness. 3
From this perspective, thought disorder – traditionally considered a characteristic psychopathology of schizophrenia – is of significant importance. 4 Although thought disorders can also be seen in illnesses like bipolar disorder, they have been considered indicative of schizophrenia. 5 While scholars may disagree on the specifics of the relationship or hierarchy between language and thought, it is widely accepted that a portion of our thinking is organised through language. 6 Therefore, it is reasonable to assume that language plays a role in thought disorders, where human thinking is impaired. 7 Thus, language abnormalities may serve as surrogate markers for thought disorders. 8 According to the DSM-5 diagnostic criteria for schizophrenia, 1 disorganised speech corresponds to a formal thought disorder. It has already been recognised that there is a close relationship between schizophrenia, thought disorders and language. 9
Several language abnormalities have been identified in patients with schizophrenia. Typically, semantic abnormalities are well-recognised.10–12 Unlike healthy individuals who intuitively understand the meanings of words and sentences, patients with schizophrenia have impaired judgment about whether a linguistic expression is natural or awkward. 13 As a result, patients with schizophrenia differ from healthy individuals in their acceptance of linguistic expressions. Consequently, in severe cases, they may produce word approximations and make irrelevant or incoherent statements. Furthermore, pragmatic abnormalities, which indicate impairments in the skills underlying competence in contextual language use, 14 lead to difficulties in inferring the speaker's beliefs and mental states beyond their literal meaning.15–17
However, in contrast to schizophrenia, research on language in bipolar disorder is limited. This limitation likely stems from the nature of bipolar disorder; the recurrent mood episodes and frequent symptom changes make consistent language assessment challenging. Moreover, only few studies have focused on language and thought disorders in bipolar disorder. Because the Kraepelinian dichotomy has recently been questioned, 18 and thought disorders are also observed in patients with bipolar disorder, 19 it is imperative to study the language of patients with bipolar disorder. In addition, few studies have been conducted outside English-speaking countries. It is necessary to analyse the language of patients who speak languages other than English, given that previous research suggests that language abnormalities observed in schizophrenia may not be universally applicable across languages. 20 Moreover, there are significant typological differences between different languages. 21 Because Korean is a language isolate in comparative linguistics and has little similarity with English, 22 an independent study on the Korean population should be valuable.
In this exploratory study, we employed natural language processing (NLP) techniques to analyse language abnormalities among patients with schizophrenia and bipolar disorder in Korea. These increasingly popular techniques offer objective analysis, providing an edge over traditional language evaluations that might be challenging to quantify. In addition, many studies have demonstrated the impressive performance of NLP techniques in identifying various language disturbances occurred in patients with schizophrenia,23,24 distinguishing schizophrenia from controls 25 and even predicting the onset of psychosis among high-risk individuals. 26 However, few studies have focused on using NLP techniques to distinguish between schizophrenia and bipolar disorder, particularly in the context of formal thought disorder. In this study, our study objective was to investigate whether patients with schizophrenia and bipolar disorder in Korea exhibit more language abnormalities compared with the control group. Furthermore, we sought to distinguish the differences in language abnormalities between patients with schizophrenia and patients with bipolar disorder using NLP techniques, exploring the potential of language as a marker for distinguishing between two diseases.
Method
Study subjects and materials
This study is a cross-sectional observational study investigating linguistic anomalies across patient and control groups. The reporting of this study conforms to STROBE guidelines 27 where applicable. The patient group included participants diagnosed with schizophrenia or bipolar disorder who completed clinical psychological tests at the Asan Medical Center from October 2020 to April 2022. The control group included participants who underwent clinical psychological tests during the same period and did not have diagnoses of schizophrenia spectrum disorders and other psychotic disorders or bipolar and related disorders. They had no psychiatric history suggesting psychotic symptoms or bipolarity, no impaired reality testing and no findings suggestive of thought disorder on the Rorschach test, as determined by an experienced clinical psychologist. Thus, the control group consisted mainly of participants with adjustment disorders with depression or anxiety.
The Asan Medical Information System was used to retrospectively extract the study subjects and their medical records. All participants spoke Korean as their first language and were able to complete over two hours of formal psychological tests, which included general intelligence tests, neuropsychological tests, the Rorschach test, 28 the Minnesota Multiphasic Personality Inventory 29 and other assessments. Participants were excluded if they had coexisting conditions that could affect their language abilities, such as autism spectrum disorder, dementia, organic brain syndrome, or severe intellectual disabilities. We collected demographic and clinical information, as well as information on the socioeconomic status, such as education, occupation and place of residence for all subjects. In addition, the results of the Korean Wechsler Adult Intelligence Scale-IV (K-WAIS-IV) 30 Short Form, Rey-Kim Memory Test-II (RKMT-II), 31 Kims Frontal-Executive Neuropsychological Test 32 and Word Fluency Test were collected.
For linguistic analysis, we chose to use written data despite the more common reliance on speech data in similar studies. Written data allows participants to correct mistakes and plan sentences more carefully, potentially reducing observable abnormalities in both patient and control groups. However, we selected written data precisely because it is unaffected by phonetic factors, allowing for a clearer focus on semantic abnormalities without interference from speech-specific errors. Additionally, this approach enables us to filter out common speech errors unrelated to thought disorders, thereby isolating more pronounced and relevant differences between groups.
The clinical psychological test at the Asan Medical Center included a free-write questionnaire that asks patients to write a short essay on a set of topics, in addition to standardized test measures. We used this questionnaire as the main text data. The questionnaire asks about the past week, and typical responses were diary-like free narratives with broad and non-specific content, believed to capture thoughts similar to free associations. Patient questionnaire responses were collected retrospectively from medical records and reviewed to exclude inappropriate data. Words, phrases, clauses and sentences that might expose personal information were de-identified and not included in the analysis. The free-write questionnaire is shown in Supplement 1.
However, questionnaire responses may not be sufficient to train a neural network that requires a large amount of linguistic data. Therefore, we used additional language data when neural network training was necessary. We used the responses from the Sentence Completion Test, commonly included in clinical psychological tests. The Sentence Completion Test contains 50 unfinished sentences to which the participant responds freely, making it suitable for linguistic analysis due to the relatively large number of sentences. Responses to the Sentence Completion Test were collected retrospectively from the original psychological test data. As with the free-write questionnaires, the responses were reviewed and de-identified for analysis.
This study was conducted in accordance with the Declaration of Helsinki. The research protocol was approved by the Institutional Review Board (IRB) of Asan Medical Center (IRB No. 2022–0622). It was exempted from obtaining informed consent as it solely involved the use of writing samples, which are standard components of the psychological evaluation at Asan Medical Center, and did not involve any invasive or potentially harmful procedures.
Evaluating the acceptability of sentences using language models
In NLP, the language model assigns probabilities to a given sequence of words, so-called a sentence. A well-trained language model on a set of linguistic material can reflect the inherent language rules that humans follow. Therefore, assigning probabilities to sentences can also be thought of as finding the most natural sentences. From this perspective, a language model can estimate how natural and acceptable a given sentence is, which can be used to quantify the appropriateness of a patient's sentences.
In this study, two language models were used: Bidirectional Encoder Representations from Transformers (BERT), released by Google in 2018, and Generative Pre-trained Transformers 2 (GPT-2), released by OpenAI in 2019.33,34 Bidirectional Encoder Representations from Transformers is based on the transformer structure and learns sentence representations using two unsupervised learning methods: Masked Language Model and Next Sentence Prediction. Generative Pre-trained Transformers 2 is based on a transformer structure and is trained by guessing the appropriate word to come next given the previous words. Unlike BERT, which learns in both directions, GPT-2 is trained in sentence order. Thus, it is expected to have a relative advantage in judging the order in which words appear in a natural sentence. In fact, GPT-2 was widely used to generate human-acceptable sentences. We used KoBERT (https://github.com/SKTBrain/KoBERT) and KoGPT (https://github.com/kakaobrain/kogpt), the Korean versions of BERT and GPT released by SKTBrain in 2019 and Kakao Brain in 2021, respectively. KoBERT was pre-trained on approximately 54 million Korean words from Wikipedia, learning the language rules inherent in Korean texts. KoGPT, on the other hand, was pre-trained on approximately 200 billion Korean words, allowing it to learn the language rules inherent in a much larger corpus of Korean texts.
First, we divided the subjects’ language data into sentences, and then assigned probabilities to each sentence using language models. Because KoBERT and KoGPT do not have a built-in function to calculate the probability assigned to a sentence, we masked each word from the beginning to the end of the sentence and calculated the difference between the model's predicted value and the actual value using the cross-entropy loss function. 35 The smaller the cross-entropy, the more similar the sentence is to a word sequence drawn from a probability distribution. This means that the sentence is more likely to be considered natural by a language model. Because cross-entropy is a logarithmic function, we used perplexity (PPL) values – expressed as an exponential function of cross-entropy – for average comparisons. We analysed the acceptability of the language of each group by comparing average PPL calculated on a sentence-by-sentence basis in the language data of the three groups: schizophrenia, bipolar disorder and controls. For KoBERT, some weights were randomised when the model was initialised; therefore, the same process was repeated 100 times to calculate PPL and the average value was used. For KoGPT, this process was not needed; therefore, we did not repeat the process.
Semantic word network analysis
In the previous section, we used language models to evaluate and compare the acceptability of language data of the patient and control to a typical Korean speaker. However, this does not provide specific information on the semantic abnormalities in the patients assessed. Therefore, we constructed and compared semantic networks based on the language data of the patients and controls. We first trained separate language models for the schizophrenia, bipolar disorder and control groups. Subsequently, we constructed word semantic networks for each group to facilitate comparison and analysis of the differences among them.
To train the language models, we first pre-processed the language data. We used the Open Korean Text (Okt) analyser included in KoNLPy – a Python library for Korean language processing 36 – to identify word boundaries through morphological analysis. Because including all conjugations of a word reduces the efficiency of analysis, we used the built-in functions of the analyser to restore them to the stem word. We then performed embedding with the FastText algorithm released by Facebook in 2017. 37 Similar to the Word2Vec algorithm released by Google in 2013,38,39 FastText performs embedding based on the pattern of words that occur together through a neural network structure, but the difference is that each word is analysed by breaking it down into smaller units of characters. Therefore, it tends to be robust toward unregistered words, which is advantageous for analysing linguistic data from patients with neologisms, etc. For embedding, we set the number of dimensions of the word vector to 32 and the number of epochs to 100 and used the default values for other parameters. The relatively small dimensionality of the word vectors was primarily due to the limited size of the text data.
After the embedding was completed, words are represented as vectors in space, and the semantic relationship between the word vectors can be calculated as cosine similarity. By calculating the similarity for each pair of words, a semantic network can be constructed with each word as a node and the similarity of the word as an edge. We constructed three distinct semantic networks using embedded word vectors from the schizophrenia, bipolar disorder and control groups, respectively. To prevent multiple comparisons and disturbance of the network by low-frequency words, we selected 30 most frequently used words across all parts of speech – nouns, verbs and adjectives – commonly used by the study participants to construct the semantic networks. This choice also aligned with our smaller word vector dimensionality. To intuitively understand the semantic network, the network was constructed using only nouns, verbs and adjectives, excluding particles and endings. Although “이다(is)” is a descriptive article, it has a unique status in that it has a conjugation unlike other articles, and in some cases, it can be viewed as an adjective; therefore, it was included as a node in the network. The full list of words used to construct the semantic word networks is shown in Supplement 2.
Once the semantic networks were constructed in each group, they were visualised using graphs and heatmaps, and then network metrics were calculated and compared. Moreover, we calculated the Jaccard similarity of each semantic network in schizophrenia and bipolar disorder to the semantic network in the control group. 40 For specific network metrics, we first calculated the average clustering coefficient, which indicates how well the nodes in the network are connected. In semantic networks, the clustering coefficient reflects the overall similarity of words. Since embeddings rely on the distributional hypothesis – that pairs of words occurring together are more likely to have similar meanings – a low average clustering coefficient in a semantic network (indicating low overall word similarity) suggests that word pairs occur less frequently together, implying a relatively wide variety of words used. In other words, this reflects the use of words that deviate more noticeably from the overall context. Next, we calculated the degree assortativity, which is the tendency of similar nodes to cluster together. In a network organised based on the similarity of word meanings, degree assortativity means that words with similar meanings are closely connected. Therefore, low degree assortativity suggests the presence of many random, semantically unrelated words in a sentence. Finally, we computed global reaching centrality (GRC), which indicates how hierarchically organised the network is. 41 Semantic networks are known to have a hierarchical structure,42,43 where words are organised and stored in the human brain in categories with similar characteristics. For example, under the superordinate category of vehicle, subcategories of cars and boats exist, each of which is further divided into vans, passenger cars, cruise ships, fishing boats, etc. A low hierarchy of semantic networks means that the organisation is relatively weak.
In this study, only one semantic network exists for each group, and we used the properties of neural networks to evaluate statistically significant differences between the networks. The neural network used in the FastText algorithm relies on random numbers to determine initial weights; therefore, the value of the embedded word vector varies slightly with each training. Repeating this process allows us to check whether the networks constructed from the populations are significantly different between the populations. In this study, the entire process was repeated 100 times, and the average values of each group were compared.
Statistical analysis
Analysis of variance and analysis of covariance were used to compare the three groups, and Tukey's honestly significant difference test was used for post hoc analysis. Chi-square test and Fisher's exact test were used to compare nominal variables. R version 4.1.3 44 and SciPy were used for statistical analysis, with a significance level of p < 0.05. The NLP algorithms were run in the Google Colaboratory Pro + environment.
Results
Information on study subjects and materials
After reviewing the medical records, 48 patients with schizophrenia, 52 patients with bipolar disorder and 48 controls were included in the study. There were no significant differences between the groups in mean age and gender composition of the subjects, respectively (F = 1.608, p = 0.204; χ² = 0.617, p = 0.735). The duration of illness was 8.53 [7.57] years in schizophrenia, 5.78 [5.14] years in bipolar disorder and 4.00 [4.65] years in control, with significant differences between the groups (mean [standard deviation]; F = 7.031, p = 0.001). The demographic information for the study subjects is shown in Table 1.
Demographics of study participants.
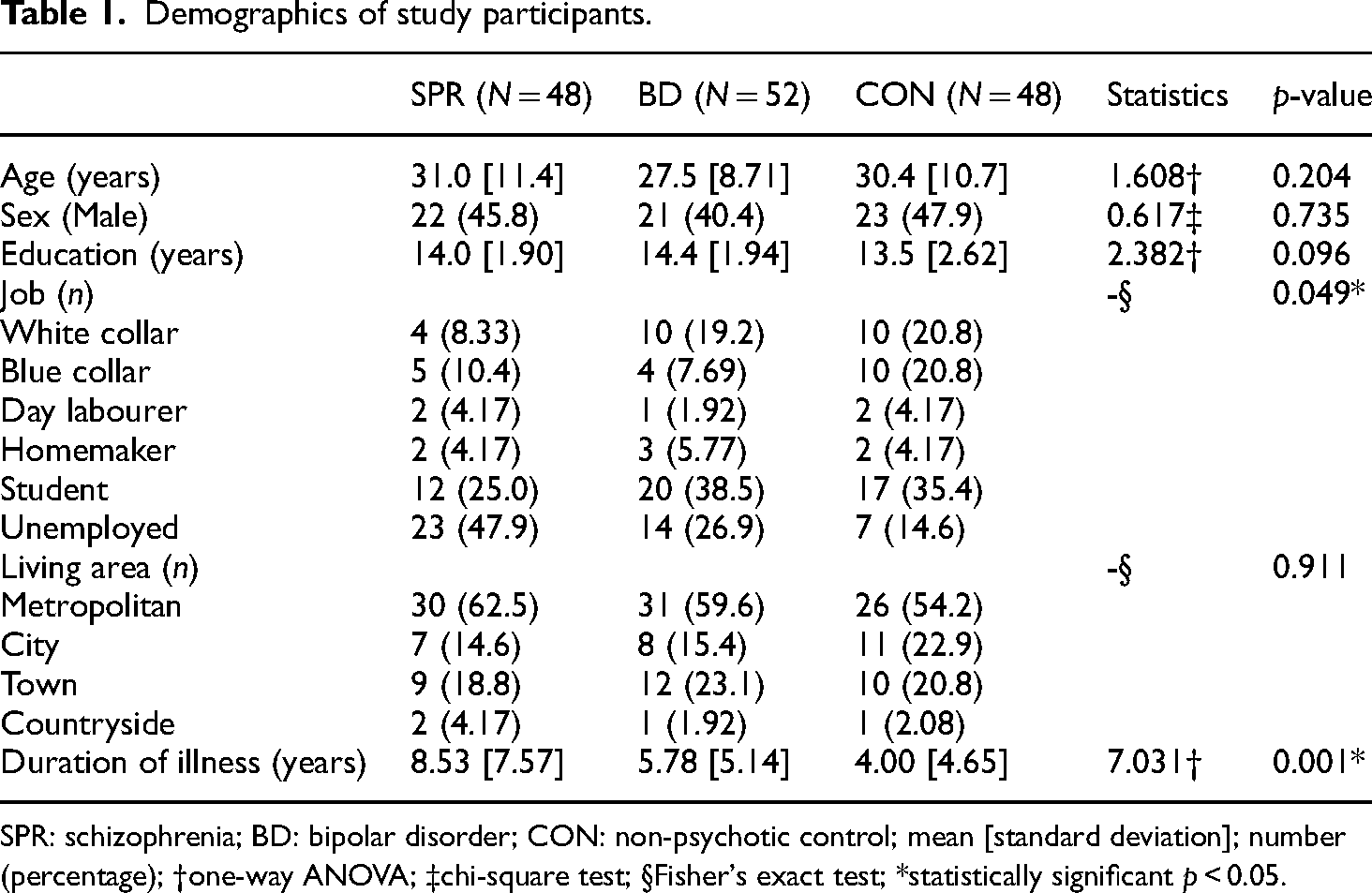
SPR: schizophrenia; BD: bipolar disorder; CON: non-psychotic control; mean [standard deviation]; number (percentage); †one-way ANOVA; ‡chi-square test; §Fisher's exact test; *statistically significant p < 0.05.
Overall, cognitive function tended to be worse in schizophrenia than in bipolar disorder and worse in bipolar disorder than in control. However, general intelligence – measured using K-WAIS-IV Short Form – did not show statistically significant differences between groups (F = 1.633, p = 0.199). Verbal intelligence – measured using VCI of the K-WAIS-IV or the Verbal Memory Index of the RKMT-II – was significantly different among the three groups (F = 6.900, p = 0.001). However, post hoc analysis showed significant differences only in patients with schizophrenia (p < 0.001) and showed no statistical significance in patients with bipolar disorder (p = 0.069) compared with the controls. Word fluency scores were significantly different in the three groups (F = 3.954, p = 0.023), but post hoc tests revealed no statistically significant differences. Detailed information on the cognitive function of the subjects is shown in Table 2.
Cognitive profile of study participants.
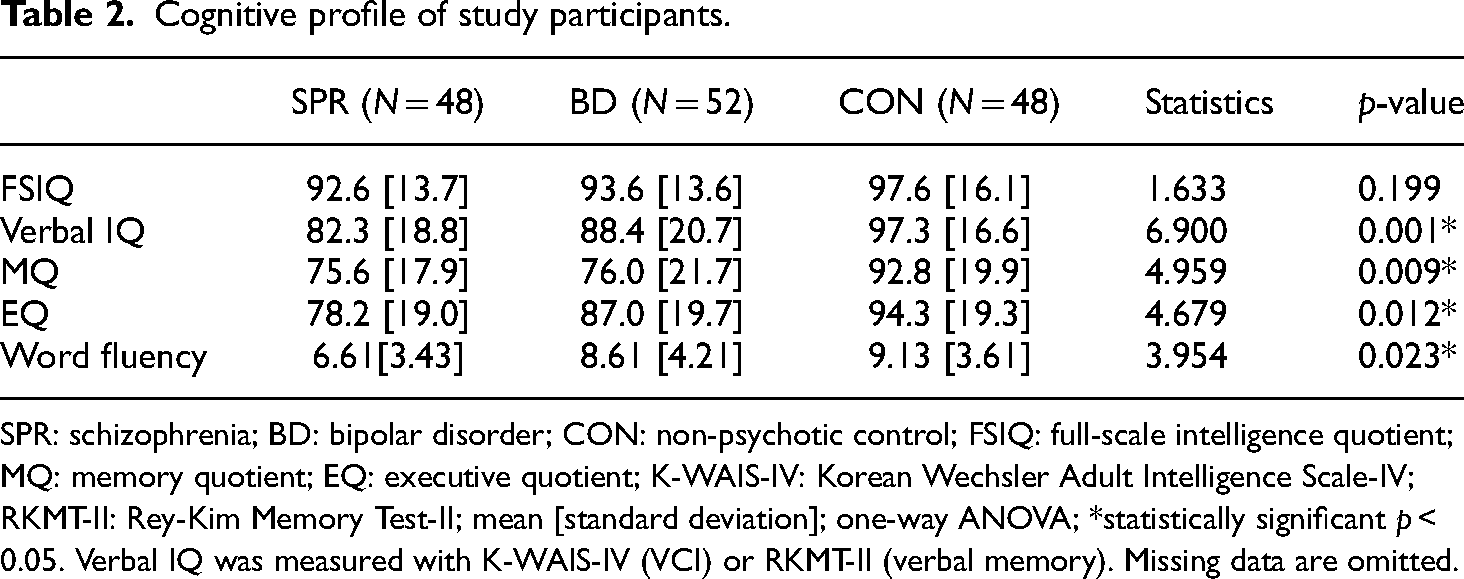
SPR: schizophrenia; BD: bipolar disorder; CON: non-psychotic control; FSIQ: full-scale intelligence quotient; MQ: memory quotient; EQ: executive quotient; K-WAIS-IV: Korean Wechsler Adult Intelligence Scale-IV; RKMT-II: Rey-Kim Memory Test-II; mean [standard deviation]; one-way ANOVA; *statistically significant p < 0.05. Verbal IQ was measured with K-WAIS-IV (VCI) or RKMT-II (verbal memory). Missing data are omitted.
Acceptability of sentences evaluated using language models
The acceptability of 299 sentences from the schizophrenia group, 367 sentences from the bipolar disorder group and 333 sentences from the control group was evaluated using the language model. Mean perplexity (PPL) values calculated by using KoBERT were 3.68E + 04 [3.69E + 04], 3.58E + 04 [2.14E + 04] and 3.59E + 04 [2.22E + 04] in the schizophrenia, bipolar disorder and control groups, respectively, with significant differences (F = 11.48, p < 0.001). Post hoc analysis showed that mean PPL of the schizophrenia group was significantly greater than that of the bipolar disorder (p = 0.001) and control (p = 0.001) groups. Even after adjusting for the general intelligence of the subjects, significant differences in mean PPL remained between the three groups (F = 11.49, p < 0.001). Post hoc analysis showed that mean PPL of the schizophrenia group was significantly greater than that of the bipolar disorder (p < 0.001) and control (p < 0.001) groups. When adjusted for verbal intelligence, a significant difference in mean PPL existed between the three groups (F = 11.49, p < 0.001), with mean PPL in the schizophrenia group being significantly greater than that in the bipolar disorder group (p = 0.011), but not statistically different from the control group (p = 0.732). A plot of average PPL calculated using KoBERT on the language data of schizophrenia, bipolar disorder and control subjects is shown in Figure 1. Despite statistically significant differences in mean PPL, the bars overlap due to large variances.

Perplexity calculated by using the KoBERT in study participants.
Next, we calculated the sentence PPL using KoGPT. The PPL calculated by KoGPT was often tens of times higher than the median, unlike that by KoBERT. These values can be considered outliers. Therefore, we removed 2.5% of both extremes of the distribution before calculating mean values. The calculated mean PPL values were 56.9 [81.6], 41.9 [37.9] and 39.6 [47.0] in the schizophrenia, bipolar disorder and control groups, respectively, which were significantly different (F = 7.956, p < 0.001). Post hoc analysis showed that mean PPL of the schizophrenia group was significantly greater than that of the bipolar disorder (p = 0.003) and control (p = 0.001) groups. No statistically significant difference was observed between the bipolar disorder and control groups (p = 0.847). This trend was maintained after adjusting for the general intelligence of the subjects, with the three groups showing a significant difference in mean PPL (F = 7.951, p < 0.001). Similarly, post hoc analysis showed that mean PPL of the schizophrenia group was significantly greater than that of the bipolar disorder (p = 0.003) and control (p = 0.001) groups. When corrected for verbal intelligence, a significant difference in mean PPL between the three groups remained (F = 7.954, p < 0.001), with mean PPL of the schizophrenia group being significantly greater than that of the bipolar disorder (p = 0.006) and control (p = 0.004) groups. A plot of mean PPL calculated by using KoGPT from the language data of schizophrenia, bipolar disorder and control groups is shown in Figure 2. Similar to KoBERT, despite statistically significant differences in mean PPL, the bars overlap due to large variances.

Perplexity calculated by KoGPT in study participants.
Results of semantic word network analysis
Independent language models were created based on 2,479, 2850 and 2515 sentences of the schizophrenia, bipolar disorder and control groups, respectively. Each model was used to construct a semantic word network. One network was created per group in each iteration. The top 30 high-frequency words used to construct the semantic networks accounted for 37.1% of the total words in schizophrenia, 36.3% in bipolar disorder and 36.6% in the control group. Analysis of variance revealed that the semantic networks differed significantly on all three network metrics (average clustering coefficient, degree assortativity and GRC) (F = 1074.2, p < 0.001; F = 1509.3, p < 0.001; F = 75.7, p < 0.001). Post hoc analysis showed that the groups were significantly different from each other on all measures. For degree assortativity, semantic networks were more disassortative in schizophrenia than bipolar disorder and controls, with a significant difference between schizophrenia and bipolar disorder (p < 0.001). Global reaching centrality was higher in the semantic networks of controls than patients with bipolar disorder and patients with schizophrenia; consistently, a significant difference was observed between patients with schizophrenia and patients with bipolar disorder (p < 0.001). However, for the average clustering coefficient, although a significant difference was observed between the semantic networks of patients with schizophrenia and patients with bipolar disorder (p < 0.001), the order was patients with bipolar disorder, controls and patients with schizophrenia. Finally, a comparison of Jaccard similarity showed that the semantic networks of patients with schizophrenia were significantly less similar to the semantic networks of controls than those of patients with bipolar disorder (t = −50.8, p < 0.001). The results of semantic network analysis for the study subjects are shown in Table 3, and the semantic networks constructed in each group are shown in Figures 3 and 4. The difference between the semantic networks of patients with schizophrenia and bipolar disorder is shown in Figure 5.

Semantic networks visualised as circular graphs.

Semantic networks visualised as heatmaps.

Difference in networks of schizophrenia and bipolar disorder.
Semantic network analysis of study participants.
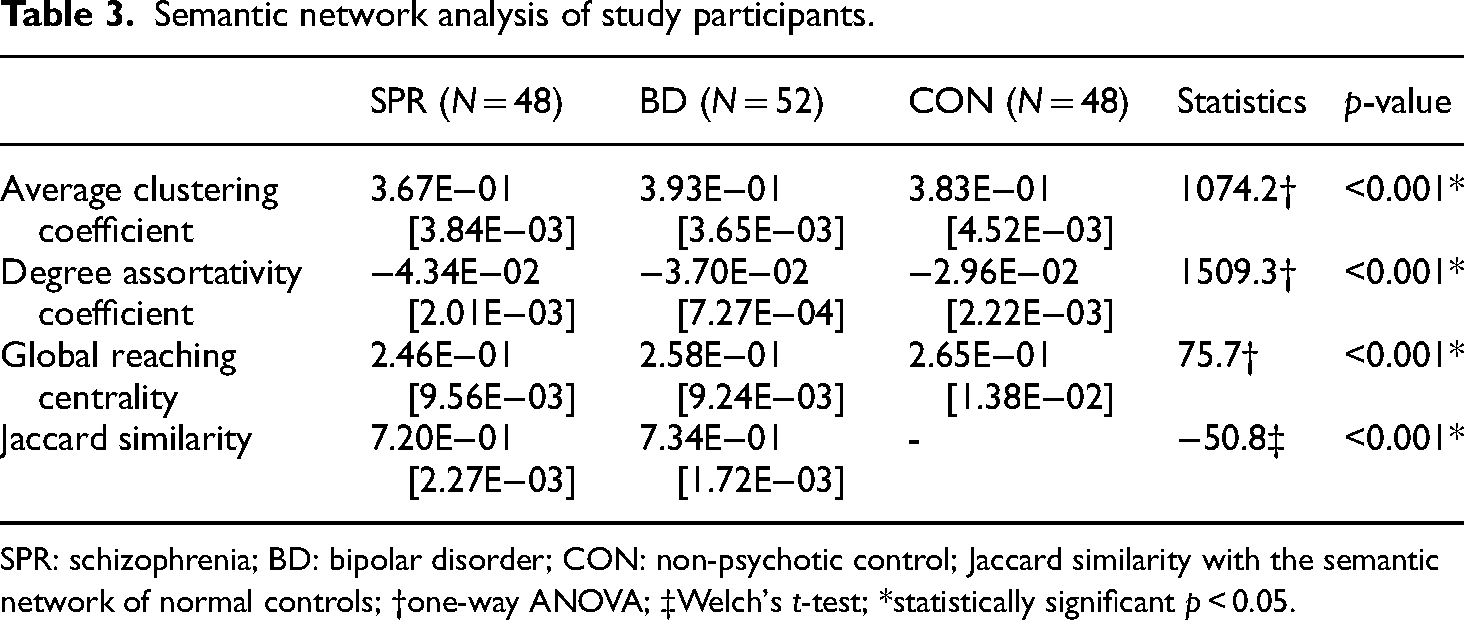
SPR: schizophrenia; BD: bipolar disorder; CON: non-psychotic control; Jaccard similarity with the semantic network of normal controls; †one-way ANOVA; ‡Welch's t-test; *statistically significant p < 0.05.
Discussion
In this exploratory study, we investigated language abnormalities in patients with schizophrenia and bipolar disorder compared to controls. Given that language abnormalities are thought to be closely linked to thought disorders, we sought to determine whether these patterns differed between patients with schizophrenia and those with bipolar disorder. The NLP analysis consisted of two steps: first, we used language models (KoBERT and KoGPT) to assess the acceptability of sentences in schizophrenia, bipolar disorder and control groups by quantifying the probability of word occurrence. Although language models were not designed for assessing sentence acceptability, they can be used to approximate sentence occurrence probabilities in practise. The acceptability of sentences computed from both language models was significantly worse in the patients with schizophrenia and bipolar disorder than in controls. This is not surprising given that language models mimic human language comprehension and thought disorder is primarily defined based on failure to comprehend by the listener, that is, the psychiatrist. The differences in sentence acceptability were more pronounced in analyses using KoGPT, which was trained on vastly more text than the KoBERT and is believed to perform better.
Moreover, we further analysed the language models to understand how the semantic networks of the actual words appear, rather than simply judging patient sentences as abnormal. Although this study was exploratory due to limited data, we found significant differences in the semantic networks of patients with schizophrenia, bipolar disorder and controls using three different network metrics: average clustering coefficient, degree assortativity coefficient and GRC. First, the semantic networks of patients with schizophrenia showed a lower average clustering coefficient than the semantic networks of patients with bipolar disorder. A low average clustering coefficient indicates that a relatively wide variety of words is used in the sentence; therefore, a lower average clustering coefficient suggests that patients with schizophrenia use a more varied vocabulary, potentially deviating more from the overall context, compared to patients with bipolar disorder. Interestingly, the semantic networks of controls showed an average clustering coefficient between that of the schizophrenia and bipolar disorder groups, an unexpected result. Since the proportion of high-frequency words used in network construction did not differ significantly across the three groups, it appears that variations in word usage patterns are mainly influenced by low-frequency rather than high-frequency words. Consequently, the interpretation of average clustering coefficient has somewhat limitations. Second, the semantic networks of patients with schizophrenia, bipolar disorder and controls were all disassortative, meaning that nodes in the network tended to connect with others that were dissimilar, as has been previously observed. 45 However, the semantic networks of patients with schizophrenia showed greater disassortativity than those of patients with bipolar disorder. Because the degree assortativity in semantic networks increases with the clustering of semantically similar words, it is conceivable that patients with schizophrenia used more random, unrelated words. Third, GRC, which measures the hierarchical organisation of a network, was lower in the semantic networks of patients with schizophrenia than in those of patients with bipolar disorder. Typically, semantic networks have a hierarchical structure, with higher-level categories leading to lower-level categories.42,46 A low GRC suggests that this stratification is not well achieved in schizophrenia, which may partially explain the over-inclusive thinking of patients with schizophrenia. However, we did not address the specific network distribution of individual words. Studies have suggested that words such as “I” and “you” have different meanings in patients with thought disorders 47 ; given that patients with schizophrenia have problems with the boundaries of the self, 48 further research from this perspective could be considered.
In summary, this study showed that patients with schizophrenia and bipolar disorder not only exhibit more language abnormalities than controls but also significant differences between themselves. As discussed in the introduction, thought disorder is considered a characteristic psychopathology of schizophrenia and is closely related to language abnormalities. Therefore, the results of this study suggest that language abnormalities, and by extension, the presence or absence of thought disorder, may be helpful in differentiating between schizophrenia and bipolar disorder. In particular, the semantic network findings of poor average clustering coefficient and GRC suggest that in patients with schizophrenia, the language abnormalities are mainly concentrated in semantic abnormalities, which is consistent with the findings of other studies. These semantic abnormalities may be characteristic of thought disorders.
Notably, compared with controls, patients with bipolar disorder exhibited relatively more language abnormalities, which are believed to reflect thought disorder. One possible explanation for this finding is that the language abnormalities examined in this study are not an accurate representation of traditional thought disorders. As discussed in the introduction, language abnormalities in thought disorders are often considered disorganised language, including loosening of association, derailment and poor language content. However, the language models in this study mainly evaluate the awkwardness of a given sentence based on acceptability. Semantic network analysis also has a slightly different perspective, because it distinguishes between variations in the semantic relations of words represented in the mental world. The definition of thought disorder has changed slightly over time, making it difficult to categorise certain language abnormalities as thought disorders. Another explanation suggests that bipolar disorder might manifest thought disorders to some extent, with formal thought disorders potentially being a shared feature of both schizophrenia and bipolar disorder. 19 From this perspective, thought disorders might be more pervasive across the affective and psychotic spectrum, encompassing both schizophrenia and bipolar disorder.49,50 However, despite the diagnostic ambiguity and mixed findings, the clinical utility of the traditional Kraepelinian dichotomy is clear.51,52 Given that studies have found fundamental differences between the language of schizophrenia and bipolar disorder,53,54 further investigation is warranted.
This study has several limitations. First, the number of subjects was insufficient. Because the questionnaires were collected from patients who underwent clinical psychological tests in the hospital, the number of subjects was small. Therefore, the power to test the hypothesis that there are differences in language abnormalities in patients with schizophrenia and patients with bipolar disorder is lacking. In addition, in the case of the semantic network analysis results, overfitting may have occurred in the process of training the neural network due to the small amount of data input. Nonetheless, we believe that our exploratory study unveiled potential avenues for employing language as a tool to comprehend psychopathology. Moreover, if overfitting happened, we believed that such a network can still represent given text samples, although not generalizable in wider patient population.
Second, the control group did not consist of typical healthy controls but was composed of participants with adjustment disorders involving depression or anxiety. Since patients with depression 55 or anxiety 56 may also exhibit some degree of language disturbances, this may reduce the observed differences between the schizophrenia or bipolar disorder groups and the controls. As a result, our findings may primarily reflect more pronounced language abnormalities. Nonetheless, we believe that our results distinguishing language abnormalities between patients with schizophrenia and bipolar disorder remain valid, as well as our comparisons with the control group, since we carefully reviewed the presence of formal thought disorders in the control participants.
Third, we did not analyse the pragmatics, which is considered important in patients with thought disorders. In clinical practise, irrelevant speech is often viewed as disorganised language. In this context, irrelevance refers to the telling of inappropriate stories at the discourse level, that is, pragmatic abnormalities. However, analysis from a pragmatics perspective requires a much larger amount of linguistic data because it requires discourse-level analysis. Therefore, in this study, which was analysed with a limited amount of data, we mainly focused on semantic abnormalities.
Fourth, the clinical condition of the patient group was not considered. The nature and severity of symptoms may affect the language use patterns of the patients, and there may be differences in language use between patients in the acute phase and those in remission. The study population was limited to patients who had undergone clinical psychological tests; however, only patients who had passed the acute phase and cooperated were included. In addition, medication was not considered. Some medications, such as antipsychotics, can affect the cognitive function of patients,57,58 and even in the short term, excessive drowsiness can cause difficulty in completing questionnaires. It would be helpful to minimise possible errors and identify language abnormalities if linguistic analysis is performed after controlling for the patient's clinical condition.
Fifth, we did not distinguish between bipolar I and bipolar II disorders, which have different clinical presentations. The two disorders are known to differ not only in prognosis and course but also in cognitive functioning. 59 In particular, according to the DSM, bipolar disorder type II should be absent of psychotic symptoms. Given these clinical differences, bipolar I and II disorders should be considered separate diagnoses. Therefore, it would be better to distinguish the two conditions as separate groups in language analysis. In this study, owing to the small number of participants, we could not distinguish between bipolar I and II bipolar disorders and analysed them together as bipolar disorder to maintain maximal statistical power as possible.
Finally, there are inherent limitations of the different evaluation methods used in this study. In the case of NLP techniques, the awkwardness of a given sentence is first evaluated through a language model, but this has the limitation that it does not distinguish between traditional semantic, syntactic and pragmatic abnormalities. This is because linguistic models, by their very nature, only learn context from the given data without considering grammatical rules or sentence structure. However, a well-trained semantic model can effectively identify abnormalities in a sentence even without this traditional knowledge of grammar. In fact, long before the advent of modern NLP techniques, it was already suggested that probabilistic processing alone could identify semantic and syntactic regularities in sentences. 60 In the case of semantic network analysis, there is a question of whether the word vectors embedded by the neural network fully reflect the meaning of the word. The embedding algorithm used in this study and similar publicly available algorithms are based on the distributional assumption, which may not reflect the complex sentence structure of Korean language. However, in linguistics, the function of a word is usually closely related to its distribution; considering that many applications developed based on publicly available embedding algorithms have shown excellent performance in various NLP tasks, we believe that the word vectors used to analyse the semantic network in this study are not far from the actual semantic phenomenon.
Conclusion
In conclusion, using NLP techniques, we found that patients with schizophrenia and bipolar disorder exhibit more language abnormalities than controls, and that significant differences exist in the language abnormalities between patients with schizophrenia and patients with bipolar disorder. Semantic word network deficits were more prevalent in patients with schizophrenia than controls. These results suggest that thought disorders and language abnormalities, which are traditionally considered characteristic findings of schizophrenia, may help to distinguish between schizophrenia and bipolar disorder. Although further exploration is required, language abnormalities serving as surrogate markers of thought disorders may be utilized in classification models to assist clinicians in differentiating between psychiatric disorders. A well-designed follow-up study is expected to enhance our understanding of the pathophysiology of patients with schizophrenia and patients with bipolar disorder and contribute to clinical practise.
Supplemental Material
sj-docx-2-sci-10.1177_00368504241308309 - Supplemental material for Semantic abnormalities in schizophrenia and bipolar disorder: A natural language processing approach
Supplemental material, sj-docx-2-sci-10.1177_00368504241308309 for Semantic abnormalities in schizophrenia and bipolar disorder: A natural language processing approach by Young Tak Jo and Yeon Ho Joo in Science Progress
Supplemental Material
sj-docx-3-sci-10.1177_00368504241308309 - Supplemental material for Semantic abnormalities in schizophrenia and bipolar disorder: A natural language processing approach
Supplemental material, sj-docx-3-sci-10.1177_00368504241308309 for Semantic abnormalities in schizophrenia and bipolar disorder: A natural language processing approach by Young Tak Jo and Yeon Ho Joo in Science Progress
Footnotes
Acknowledgements
This manuscript is based on the doctoral dissertation of the first author, Young Tak Jo, who received his PhD from the University of Ulsan.
Authors’ note
Consent: Given that this study was a retrospective chart review, the risk to participants was minimal. Moreover, obtaining consent from all participants was not feasible due to its retrospective nature. Therefore, the Institutional Review Board at Asan Medical Center waived the requirement for written informed consent. Data availability: Due to local legal restrictions, supporting data are not available.
Author contribution
Young Tak Jo: Conceptualisation, Methodology, Formal analysis, Investigation, Data curation, Writing – original draft; Yeon Ho Joo: Conceptualisation, Supervision, Writing – review & editing.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical considerations
This study was approved by the Institutional Review Board of Asan Medical Center (IRB number: 2022-0622) on 10 May 2022.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Research Foundation of Korea (NRF-2022R1F1A1067605).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.