
Abstract
Manufacturing industries involve both business processes and complex manufacturing processes. Predictive process monitoring techniques are effective for managing process executions by making multi-perspective real-time predictions, preventing issues such as delivery delays. Conventional predictive process monitoring for business processes focuses on predicting the next activity, next event time, and remaining time using single-task learning, which is costly and complex. For complex manufacturing processes, predictive process monitoring primarily aims to predict the remaining time, that is, product cycle time. However, single-task learning methods fail to capture all the variations within the historical process executions. To address them, we propose the multi-gate mixture of transformer-based experts framework, which leverages a transformer network within the multi-gate mixture-of-experts multi-task learning architecture to extract sequential features and employs gated expert networks to model task commonalities and differences. Empirical results demonstrate that multi-gate mixture of transformer-based experts outperforms three alternative architectures across five real-life event logs, highlighting its generalization, effectiveness, and efficiency in predictive process monitoring.
Introduction
Under the wave of Industry 4.0, the manufacturing industry is undergoing profound changes, with smart manufacturing becoming an inevitable trend. To achieve this transformation, manufacturing industries must not only introduce advanced production equipment and technologies but also comprehensively optimize and modernize their production processes. 1 The processes in manufacturing are diverse and complex, typically categorized into conventional business processes within enterprise information systems and intricate manufacturing processes within production workshops. To realize smart manufacturing, it is essential to implement comprehensive monitoring and management across all processes, which not only enhances production efficiency but also helps in timely identification and resolution of potential issues. This significantly boosts overall operational efficiency and competitiveness of the enterprise. 2
Predictive process monitoring (PPM) is an advanced management approach initially developed for business processes. By analyzing event logs recorded in process-aware information systems (PAISs), PPM predicts various performance aspects of ongoing process instances. 3 These predictions typically include the next activity prediction, the next event time prediction, the remaining time prediction, and other key performance indicators.4–7 These predictive tasks are interrelated, sharing the same input data source (historical event logs) and influencing each other’s outcomes. For example, the result of the next activity prediction directly impacts the prediction of the next event time, which in turn affects the remaining time prediction. However, most current research methods are based on single-task learning (STL), where separate models are trained for each task, or they only combine next activity and next event time predictions, rarely addressing more than two tasks simultaneously. In contrast, our previous work 8 was the first to explore multiple prediction tasks in PPM using a basic multi-task learning (MTL) framework. While this was a step forward, there were still limitations in terms of performance, complexity, and efficiency, which motivated the improvements presented in this article.
As smart manufacturing evolves, the application of PPM has expanded to manufacturing processes.9–12 Although manufacturing processes also consist of a series of activities, each with a duration and a set of resources, they exhibit unique complexities due to numerous parameters and variables such as product type. 13 Unlike business processes, the predictive monitoring for manufacturing processes primarily focus on the remaining time prediction, that is, the product cycle time, as timely product delivery is critical for manufacturing enterprises. 14 However, most studies in this area also focus solely on this single task without considering the potential performance improvements from related tasks.
To address these challenges, we introduce a novel MTL framework designed to achieve effective predictive monitoring across all processes in manufacturing. This framework aims to enhance the accuracy and generalization of PPM technologies, providing robust support for comprehensive automation in manufacturing. Currently, MTL has emerged as a crucial machine learning paradigm that significantly improves model generalization by sharing knowledge across multiple related tasks. In particular, the multi-gate mixture of experts (MMoE) method has gained traction in industry, 15 originating from the mixture-of-expert (MoE) architecture. 16 It employs multiple expert networks and gating mechanisms to enable effective information sharing and adaptively expert weighting tailored to the needs of different tasks. This architecture enhances the model’s generalization and prediction accuracy while maintaining task independence. Inspired by the auxiliary learning within MTL,17,18 we further explore the application of the MTL framework MMoE in predictive monitoring of manufacturing processes. Specifically, we employ the MTL to predict the remaining time by establishing auxiliary tasks that support this primary task. In our implementation, the next activity prediction and the next event time prediction serve as auxiliary tasks, while the remaining time prediction is treated as the primary task.
Additionally, most techniques used for the individual prediction tasks in PPM can generally be divided into two categories: conventional machine learning methods and deep learning-based approaches.7,19 In recent years, motivated by the superior capabilities of Transformer networks in natural language processing (NLP), PPM techniques, originally based on the machine learning, have evolved from the original RNN, LSTM, 20 attention-based model 21 to the current transformer-based models.22,23 The reason is that in manufacturing, the input to PPM is an event log of process executions recorded in PAIS or manufacturing systems (MSs). This log consists of multiple sequences of events with complex temporal ordering and dependencies, where each sequence represents a process execution. This allows each sequence of events to be treated like a sentence in natural language, enabling efficient feature learning using the transformer network.
Therefore, building on our previous research, 8 we propose the MMoTE (multi-gate mixture of transformer-based experts) approach, which integrates Transformer networks with the MTL framework MMoE to enable predictive monitoring in both business and manufacturing processes. Unlike our previous research, 8 the proposed MMoTE approach in this article addresses both the commonalities and distinctions between different tasks, reducing interference among weakly related tasks while enhancing feature sharing among strongly related tasks. Specifically, this approach leverages transformer networks to effectively extract both local and global features from process sequential data characterized by complex ordering and dependencies. Additionally, it employs the MMoE framework for achieving parallel learning of task-specific and shared feature representations. The approach helps to optimize the feature learning further and improve the model’s ability to recognize complex patterns, thereby improving performance and reducing computational resources in PPM of manufacturing.
In conclusion, this article presents the following contributions:
We introduce a technique, MMoTE, designed to be applicable across various types of processes, including business processes and manufacturing processes, for predictive monitoring. Extensive experiments on event logs from these process types validate its effectiveness. We present a scalable MTL framework that enhances performance by sharing information across multiple tasks in PPM, improving predictions for business processes, and supporting auxiliary learning to optimize PPM for manufacturing processes. We propose MMoTE, which integrates transformer networks with the MMoE framework, enabling efficient learning from diverse perspectives of event sequences and adapting to multiple tasks through gated units that manage expert networks.
The organization of this article is as follows. First, we discuss the relevant research work and offer a brief overview. Then, the “Preliminaries and problem statement” section introduces some fundamental concepts and the problem addressed in this article. Afterward, the “Approach” section provides an in-depth exposition of the proposed MMoTE approach. Extensive comparative experiments are conducted in the “Experimental evaluation” section to evaluate the performance of MMoTE. Finally, the “Conclusion and future work” section summarizes the article and suggests future work directions.
Related work
Predictive process monitoring technology
PPM belongs to the category of business process execution and monitoring, whose specific tasks can be divided according to different prediction goals: predicting the next event occurrence, 4 predicting the next event execution time, predicting the remaining execution time, 5 and predicting the specific outcome of a process execution (such as successful completion, failure termination and other specific states),6,7 and so on. Depending on the techniques used, they can be classified into conventional machine learning-based and deep learning-based approaches. Conventional business process prediction methods mainly include transition system-based process remaining time prediction,24,25 probabilistic finite automata, 26 Markov chain, 27 decision tree 28 to predict the next event, and random forest to forecast the outcome. 29 In contrast, Appice et al. predicted the next event and its duration time, along with the remaining time, respectively, through shallow machine learning methods. 5 Nevertheless, a limitation of such methods is its significant dependence on manual feature engineering, especially when low-level feature representations are required.7,30
With the evolution of deep learning technology, numerous approaches based on neural networks have emerged in recent years. These approaches streamline the process of manually selection and extraction of features, leading to significant enhancements in predicting business process execution based on extensive process execution logs. Rama-Maneiro et al. 31 systematically summarized these approaches and conducted exhaustive experimental evaluations. Depending on the type of neural network used, they can be categorized as recurrent neural network (RNN)-based,32,33 long short-term memory (LSTM)-based,20,34–36 attention mechanism-based,22,21 convolutional neural network (CNN)-based37,38 and generative adversarial networks (GANs)-based, 4 graph neural network (GNN)-based,39,40 and custom networks.41–44
For example, Evermann et al. 32 first used a model composed of two hidden layers of RNNs to forecast the subsequent event. Cao et al. 33 initially constructed the Petri net and its related reachability graph according to the event log and then used the RNN with gate units to forecast the remaining duration time to increase the explainability. Tax et al. 20 presented an approach to predict the upcoming event and its duration time based on LSTM. Moreover, Camargo et al. 34 developed a model to forecast the event sequence to be executed in the future, their execution time, and the associated resource pool based on LSTM. Similarly, Navarin et al. 35 predicted the remaining time of PPM using LSTM networks. In addition to the existing process prediction methods based on RNNs, several studies integrated the attention mechanism as an optimization way to enhance the accuracy and efficiency of the prediction model. For instance, Bukhsh et al. 22 provided a ProcessTransformer model by using the self-attention mechanism, which adapts and optimizes the transformer network structure according to specific forecasting tasks and achieves the expected prediction effect. Likewise, Wickramanayake et al. 21 developed different attention mechanisms and combined them with LSTM to forecast the next event.
In addition, several methods have been presented based on other types of neural networks. For instance, Taymouri et al. 4 put forward an innovative adversarial training framework based on GANs that is designed to make predictions about the next activity and its timestamp. Di Mauro et al. 37 and Pasquadibisceglie et al. 38 investigated how to employ CNN for predictive monitoring of processes. Harl et al. 39 were the first to use gated GNN to make decisions more explainable in process outcome prediction. Weinzierl 40 also explored how gated GNN could be used to forecast the next event.
Several other approaches based on customized networks have been presented. For instance, Khan et al. 41 proposed a memory augmented neural network (MANN) and then employed it to make recommendations of the upcoming events sequence for an on-going case. Theis and Darabi 42 augmented a mined Petri net process model by incorporating a time decay function, using the execution time of activities within a process as the primary variable to construct successive samples of process states. Then, a prediction model is trained on this basis to predict future execution activities using deep learning techniques. Guo et al. 43 proposed a feature selection approach alongside a feature-informed cascade model to make predictions.
In addition to the above methods, other studies have explored new ways by combining prior knowledge, process structure and other domain knowledge, and integrate them into neural network models for process prediction. Di Francescomarino et al. 36 utilized the structure of the process execution trace and a priori knowledge to predict the sequence of forthcoming activities using LSTM. Rama-Maneiro et al. 44 proposed a method combining RNN with GCN to simultaneously learn spatio-temporal information from both process models and historical process logs.
The methods discussed above focus primarily on exploring how different neural networks or machine learning techniques can be used for effective feature learning to enhance prediction performance. However, these approaches are all based on the STL, that is, training the model on one prediction task at a time. While some methods aim to predict multiple aspects of an activity, such as the next activity, its associated time (i.e. next event prediction), and resources, none of these approaches are based on the MTL. Instead, they merely concatenate predictions across different tasks, without addressing them as distinct tasks through a MTL framework. In contrast, a few studies have explored concepts related to MTL in PPM, though they differ from the focus of this work, which addresses the simultaneous prediction of multiple tasks in PPM. For instance, Chen et al. 23 proposed a pre-training model that can be applied to different tasks individually but does not support the simultaneous prediction of multiple tasks, meaning it does not employ a MTL approach. Similarly, Cheng et al. 45 only focused on outcome prediction in call center scenarios, applying MTL by incorporating data from other modalities. However, their work did not address multiple prediction tasks within PPM itself.
Multi-task learning
Recently, MTL has attracted significant interest as a way to enhance machine learning model performance by training models on multiple tasks simultaneously. 46 By sharing feature representations, MTL captures commonalities among related tasks, offering a more human-like learning process than STL, though it also introduces new challenges. MTL has been applied across fields such as NLP, recommendation systems, speech recognition, and computer vision.
STL versus MTL
STL, which focuses on learning one task at a time, is the most common approach in machine learning. In STL (as shown in Figure 1(a)), each task is learned independently with no shared knowledge or transfer between tasks, requiring each task to be learned from scratch. Moreover, STL constructs independent models for each task, which may lead to high complexity and easy overfitting. In contrast, MTL enables multiple tasks to share the learned knowledge by sharing the underlying network and parameters. This sharing mechanism helps accelerate the learning process and improves the generalization ability of the model. Moreover, MTL introduces additional constraints and regularization terms to the model by simultaneously learning multiple tasks. This regularization effect helps reduce the risk of overfitting the model on a single task and improves performance. Currently, most of the PPM techniques are based on the STL, where the prediction tasks involving the next activity, the next event time, and the remaining time are learned separately to obtain each model (as illustrated in Figure 1(a)).
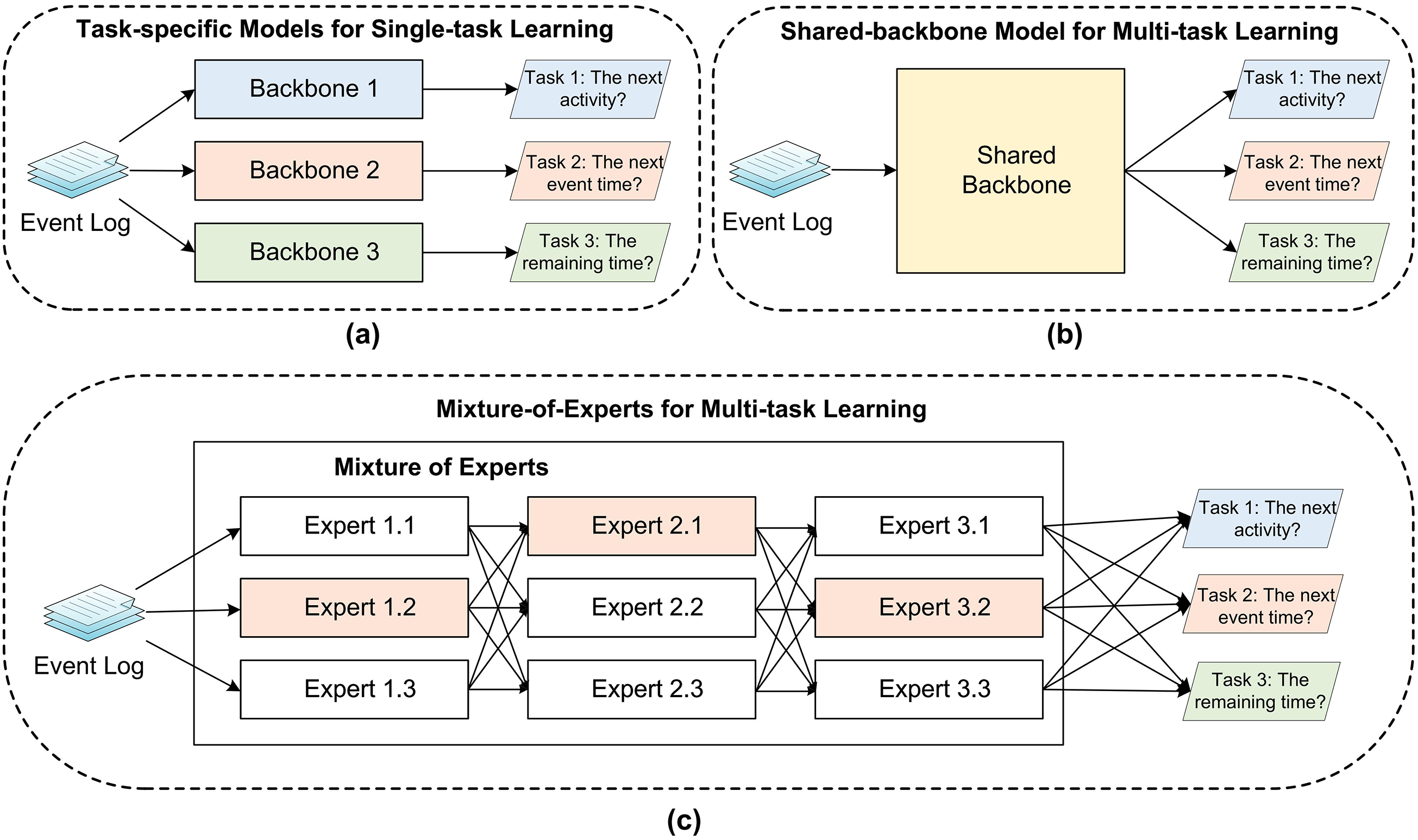
The difference among traditional single-task learning and two different multi-task learning frameworks in PPM: (a) task-specific models for single-task learning, (b) traditional shared-backbone model for multi-task learning, and (c) MoE for multi-task learning. PPM: predictive process monitoring; MoE: mixture-of-experts.
Hard parameter sharing of MTL versus Soft parameter sharing of MTL
Existing MTL methods are typically segmented into two groups, including hard parameter sharing and soft parameter sharing. Specially, the former involves sharing weights across multiple tasks, allowing simultaneous training to minimize multiple loss functions. Traditional MTL models use this approach, where multiple tasks share the same bottom network (as shown in Figure 1(b)). 8 While this reduces the risk of overfitting, it can increase model complexity and limit flexibility since all tasks use the same parameter set. The scalability of this framework can improve as the number of tasks increases. Soft parameter sharing involves using separate models for each task, but incorporating parametric relationships or differences into a joint objective function. Mechanisms like regularization or constraints encourage similarity or distance between task models, which aids knowledge transfer and efficient parameter use. This approach allows the multi-task model to leverage both commonalities and differences among tasks, improving performance and model quality for each task. MoE represents a significant advancement in flexible parameter sharing. Initially proposed by Jacobs et al., it divides a system into independent networks, each handling a portion of the data. 16 Shazeer et al. enhanced this concept with the Sparsely-Gated MoE layer, which integrates multiple experts and a trainable gating network. 47 This approach uses a divide-and-conquer strategy to address complex problems, improving efficiency and model generalization. Furthermore, Shazeer et al. applied MoE to natural language modeling and machine translation, while Riquelme et al. introduced the visual mixed expert (V-MoE) model for image classification. 48
The MoE model performs well in single-task scenarios but faces challenges in MTL due to complex inter-task relationships such as correlation and conflicts. 49 In MoE’s MTL framework (as shown in Figure 1(c)), multiple tasks share a common set of experts and a single gating network, which may lead to conflicts and inefficiencies. To address these issues, MMoE 15 was introduced, utilizing multiple gating networks to enable task-specific expert selection and better capture task relationships. 50 Unlike MoE, which relies on one gating network for all tasks, MMoE allows for different expert selections for distinct tasks. 51 As indicated by Wang et al., 52 MMoE enhances MTL by allowing task-specific adjustments to expert networks and improving the modeling of task relationships, thereby boosting overall performance. As a form of soft parameter sharing, MMoE uses soft gating networks to aggregate experts learned from different tasks, addressing negative migration problems effectively. It outperforms other methods, such as cross-stitch networks, 53 particularly in content recommendation. Various novel approaches based on the MMoE have emerged. For instance, Qin et al. 54 introduced the mixture of sequential experts (MoSE), which utilizes LSTM within an advanced MMoE framework to capture sequential user behavior. Zhang et al. 55 developed a dual-task model combining MMoE with bi-directional gated recurrent units (BiGRUs) for health status assessment and remaining useful life prediction, enhancing model versatility and dynamic task differentiation.
In the domain of MTL, despite variations in task definitions and sample characteristics, inherent commonalities are often observed among tasks. This is particularly evident in PPM, where tasks such as forecasting the execution time of future activities and the remaining time of an ongoing case frequently co-occur with the execution of subsequent activities. So, there is a correlation and commonality in the information characterization between the time-related prediction task and the next upcoming event prediction task. When the model commonality representation is strong, it tends to weaken the feature representation, while a strong feature representation is usually detrimental to the commonality representation. In order to share the same feature representations flexibly, the MMoE framework is chosen in this article to implement the PPM in manufacturing.
Preliminaries and problem statement
This section aims to provide clarity by introducing fundamental concepts and formal definitions pertinent in our study. Additionally, we outline the problem statement addressed in this article to facilitate comprehension.
Preliminaries
An increasing number of information systems in manufacturing, such as PAIS and MS, automatically record a large amount of historical process execution data. This data can be analyzed using process mining techniques to gain valuable insights and enhance process performance. In manufacturing systems, an event log details various aspects of business or manufacturing processes, including operational events and related data. Each execution of such a process denotes a distinct process instance or case. Building on this foundation, we now outline the relevant definitions of event logs.
In a process of manufacturing industry, an event signifies the completion or initiation of a particular production-related activity. An
(Process Trace)
A
(Process Instance)
Usually, a
(Event Log)
An
For example, consider a fragment of an event log from a simple automobile manufacturing process, which closely resembles a typical business process, as shown in Table 1. In this table, each row represents a distinct event, where the
Event log of a simple automobile manufacturing process.

Event log of a simple automobile manufacturing process.
Since the aim of our study is to make predictions for the on-going case, it is necessary to establish the notion of a prefix trace to extract relevant features from them.
A
Using an on-going case as an illustration, the definitions of three related prediction tasks investigated in this study are simply described as:
(Next Activity Prediction)
Regarding the prefix trace
(Next Event Time Prediction)
Regarding the prefix trace
(Remaining Time Prediction)
Regarding the prefix trace
Problem statement
The problem addressed in this article involves predicting the next activity, the next event time, and the remaining time of an ongoing case at run-time, which is achieved by training a prediction model from the historical event log recorded in PAIS or MS. Based on the trained model, we can predict the next activity, event time, and remaining time for any ongoing process instance. The detailed utilization of MMoTE in real-world manufacturing scenarios is illustrated in Figure 2. From Figure 2, historical cases

Illustration of the multi-gate mixture of transformer-based experts (MMoTE) framework utilization in manufacturing.
Approach
Modeling preliminary
Considering an event log
Multi-gate mixture of transformer-based experts
This section delineates the MMoTE built upon MMoE and the transformer network for PPM in manufacturing. Compared to other frameworks of MTL, MMoE offers distinct advantages primarily in terms of its flexibility and efficiency. Specifically, through the combination of multiple expert networks, MMoE can capture richer feature representations, thus better adapting to complex process prediction tasks. Second, the design of the gating network enables the model to dynamically select the appropriate combination of experts for each task, which is particularly important when dealing with tasks with high variability. Finally, the modular design of MMoE makes the model easier to extend and optimize, which is crucial for evolving PPM scenarios. For the three prediction tasks mentioned earlier, including next activity prediction, next event time prediction, and remaining time prediction, the MMoTE proposed in this article can be applied to build a multitask fusion prediction model. During the prediction phase, this model facilitates multi-task parallel prediction on-line. The model structure of MMoTE comprises the following components, as shown in Figure 3.

Illustration for the multi-gate mixture of transformer-based experts (MMoTE) model structure.
Transformer Shared Bottom Module
A shared-bottom transformer module is employed to process sequential input from process traces, facilitating effective representation learning from the input. In this module, the sequential trace input
Considering trace
Trace embedding comprises two components, which are feature embedding and position embedding. As we know, one-hot encoding uses binary values (0 and 1) to represent different category states. For each category, only one dimension is set to 1 (indicating that the current category state is active), and the rest are set to 0. In a classification task, the dimension of the one-hot encoding vector increases dramatically as the number of categories increases, which leads to a high-dimensional sparsity problem. To solve this problem, one approach is to map
Especially, the transformer model employs a multi-headed self-attention mechanism in which each head’s parameters
Considering the attention mechanism with 
Muti-gate Mixture-of-Experts Module
This module consists of a mixture of multi-layer perception (MLP) experts with gating networks. Each expert of the MoE models different aspects for each task. Gating networks dynamically adjust the weights of the experts based on the input features to achieve task-specific feature combinations and expert selection.
Based on the last Transformer Shared Bottom Module, the input to the current module is 
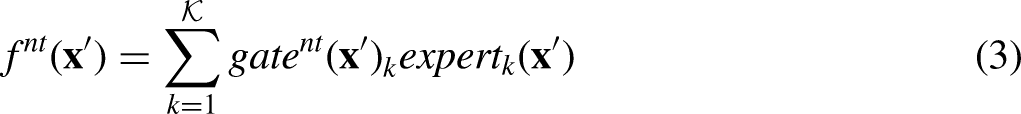




Multi-tower Module
In this module, each task corresponds to an individual tower, facilitating the independent optimization for multiple tasks. Such a configuration is frequently employed in MTL research due to its efficacy in accommodating tasks with diverse scales and data characteristics. After the MMoE module, for each task, we need to generate distinct outputs to derive three independent prediction outcomes. The process is described as follows:
The concatenated true output vector
Here,
Given that the MMoTE prediction model addresses multiple tasks, we need to compute the loss values for each task separately and subsequently aggregate them to construct the multi-task loss function. Primarily, the first defined task tackled in our study involves multi-classification prediction, necessitating the application of a multi-classification cross-entropy loss function to evaluate the disparity between the actual and true outputs for every input trace within an event log. Conversely, the remaining two tasks primarily involve regression predictions, warranting the use of a LogCosh loss function to quantify the difference. The loss function regarding the first task (i.e. the next activity prediction task) is described as follows:

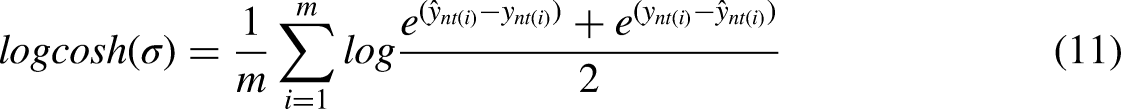


Once the prediction model is well-trained, the prediction model can be applied to the event sequence of an ongoing case, yielding multi-task prediction values for an ongoing process.
Experimental evaluation
Extensive experiments were conducted to validate the effectiveness and applicability of the MMoTE in manufacturing by utilizing five real-life event logs sourced from different processes (the business process vs. the manufacturing process). In particular, we developed the MMoE approach according to Ma et al. 15 and used the MTLFormer 8 as well as the ProcessTransformer approach (called STLFormer) proposed by Bukhsh et al. 22 to conduct the ablation experiments. For STLFormer, a distinct backbone network was created for each task based on the transformer network. For MTLFormer, a shared-backbone model was created for multiple tasks based on the transformer network. For MMoE, we constructed a network capable of addressing multiple tasks by facilitating automatic parameter adjustment through a gating mechanism positioned between shared and task-specific models.
Experimental setup
Datasets
In our experiment, we used five datasets with three different processes from the literature for evaluation. These datasets were sourced from the public 4TU research repository. Since there are few publicly available manufacturing process event logs, we used only the Production
56
event log in this article to prove that the proposed approach is also applicable to manufacturing process prediction. Additionally, the widely used Helpdesk
57
and BPIC2012
58
event logs were chosen to compare the evaluation metrics with previously proposed approaches, highlighting the performance advantages of our proposal. These datasets used in our experiment are described as follows and the detailed comparison is shown in Table 2.
Helpdesk: The real-life log comes from the ticket management process of the Helpdesk of an Italian software company. It consists of 4580 cases, 21,348 events, and 14 activities. The main attributes involve the Case ID, Activity, Resource, Complete Timestamp, and so on. BPIC2012: The real-life log comes from a Dutch Financial Institute, involving a loan application process for a personal loan or overdraft within a global financing organization. The log contains 13,087 cases, 262,200 events, and 23 activities. Because the event log is a merger of three intertwined sub-processes (the Application, the Offer, and the Workflow) where the first letter of each task name identifies from which sub process it originated from, three individual subsets of BPIC2012_A, BPIC2012_O, and BPIC2012_W based on BPIC2012 can be extracted to utilize in our experiment. Production: The real-life log originates from a manufacturing data of some products in a production workshop from January to March 2012. The log contains 225 cases, 4543 events, and 55 activities. The main attributes involve the Case ID, Activity, Start Timestamp, Complete Timestamp, Span, Work Order Qty, Part Desc., as shown in Table 3. Among them, the special Work Order Qty and the Part Desc. for the manufacturing process represent the quantity and type of products to be produced by this process.
Comparison of different datasets.

Fragment of production event log.

Overall, we train the prediction model for each technique using the five real-world datasets mentioned above. First, every dataset is preprocessed, and then it is used to train the model. We split each dataset in our experiment so that the first 80% of events are used for training according to the chronological order of the occurrences, and the remaining 20% are used as the test set so that we can evaluate how well each approach works. All approaches used in this study were implemented based on Python 3.8 and Tensorflow 2.5.0. The experimental environment is configured with Windows 10 operating system with two 12-core Intel Xeon 5118 CPUs (2.30 GHz) with 256GB of RAM and accelerated with three NVIDIA Tesla V100 GPUs.
Evaluation Metric
Since the next activity prediction task (i.e. Task 1) in PPM is a standard multi-classification problem, we evaluated the above techniques using four essential metrics: accuracy, precision, recall, and F-score. Additionally, because the next event time prediction task (i.e. Task 2) and the remaining time prediction task (i.e. Task 3) are regression prediction problems, we employed the mean absolute error (MAE) as an evaluation metric to assess both of them. Higher accuracy, precision, recall, and F-score values in classification problems typically indicate better performance of the classification approach. Conversely, in regression prediction tasks, a lower MAE number denotes a better prediction technique performance.
It is important to note that in manufacturing processes, which involve batch production, many activities are repeated within process instances. For such processes, the primary focus is on the remaining production time, which differs from the perspective of business processes. In this experiment, to evaluate the performance of the MMoTE in business process predictive monitoring, we measure performance metrics across three tasks for MMoTE and several other methods. However, for the manufacturing process, we consider only the performance metric of the remaining time prediction (Task 3). In our study, the first two tasks of the next activity prediction (Task 1) and the next event time prediction (Task 2) serve as auxiliary tasks, and the remaining time prediction (Task 3) is the target task, allowing us to assess the application of multi-task learning in predictive monitoring of manufacturing processes. Therefore, the experimental results for business processes and the manufacturing process will be presented separately below.
Experimental results on public business process logs
Our proposed MMoTE is trained using a
Comparison of approach effectiveness
A comprehensive comparison of MMoTE, MMoE, MTLFormer, and STLFormer demonstrates the effectiveness of MMoTE as proposed in this study. Specifically, the performance achieved by the MMoTE approach is obtained without hyperparameter optimization, which is sufficient to show that the performance of the approach in this article still has great potential. Table 4 describes the performance comparison of these four approaches on five datasets.
Comparison of different approaches on four datasets from business processes.
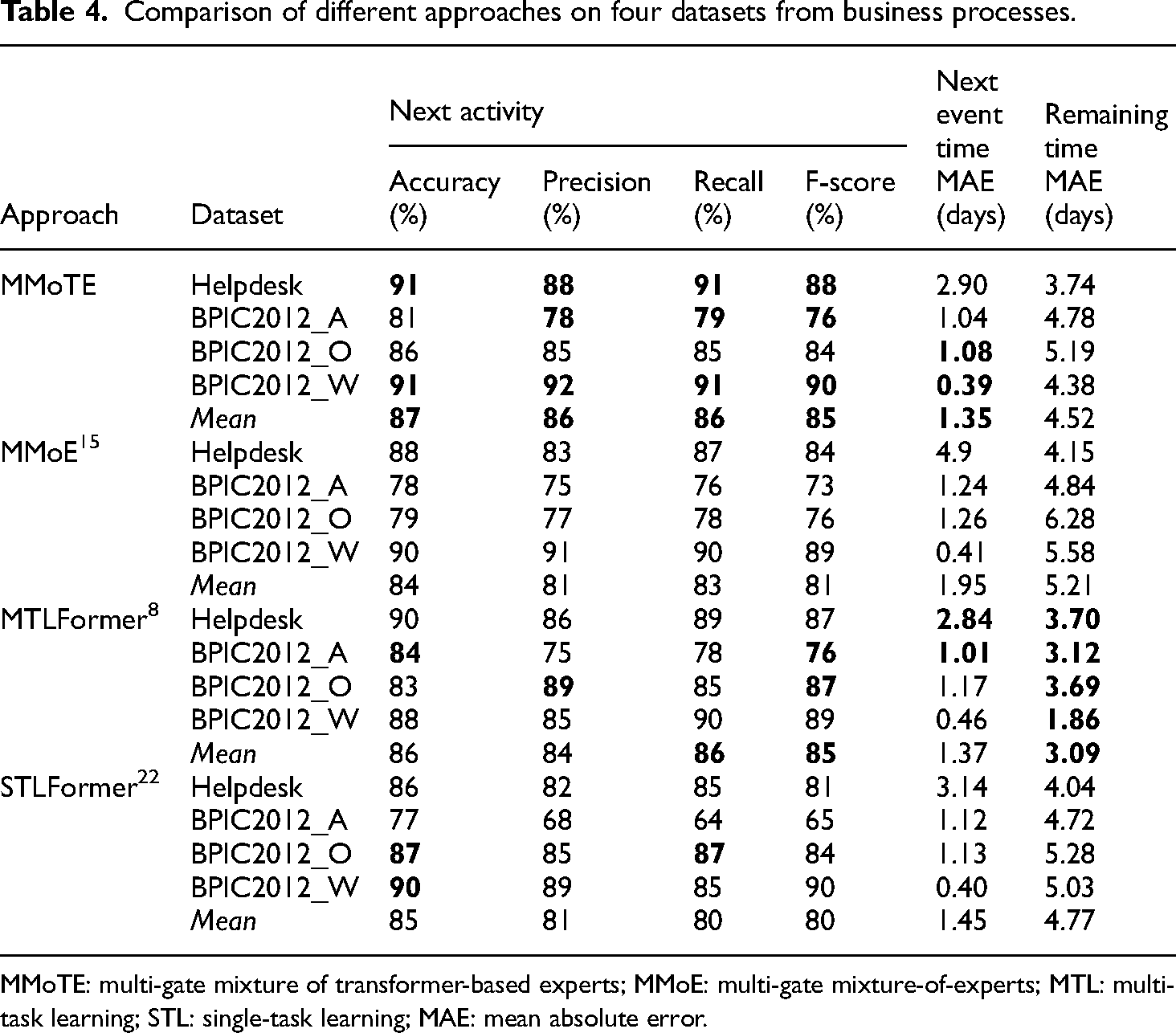
MMoTE: multi-gate mixture of transformer-based experts; MMoE: multi-gate mixture-of-experts; MTL: multi-task learning; STL: single-task learning; MAE: mean absolute error.
Secondly, we compare the performance of MMoTE, MMoE, MTLFormer, and other task-specific methods on these three individual tasks to evaluate them against the latest techniques in PPM. These task-specific methods are based on STL, where each approach is applied to a specific task, with a separate model trained for each task.
Comparison of different approaches in the next activity prediction task (higher is better).

MMoTE: multi-gate mixture of transformer-based experts; MMoE: multi-gate mixture-of-experts; MTL: multi-task learning; STL: single-task learning; RNN: recurrent neural network; LSTM: long short-term memory; CNN: convolutional neural network; MANN: memory augmented neural network; BERT: bidirectional encoder representations from transformer.
Comparison of different approaches in the next event time prediction task (lower is better).

MMoTE: multi-gate mixture of transformer-based experts; MMoE: multi-gate mixture-of-experts; MTL: multi-task learning; STL: single-task learning; LSTM: long short-term memory; MANN: memory augmented neural network.
Comparison of different approaches in the remaining time prediction task (lower is better).

MMoTE: multi-gate mixture of transformer-based experts; MMoE: multi-gate mixture-of-experts; MTL: multi-task learning; STL: single-task learning; LSTM: long short-term memory.
Comparison across different prefix trace lengths
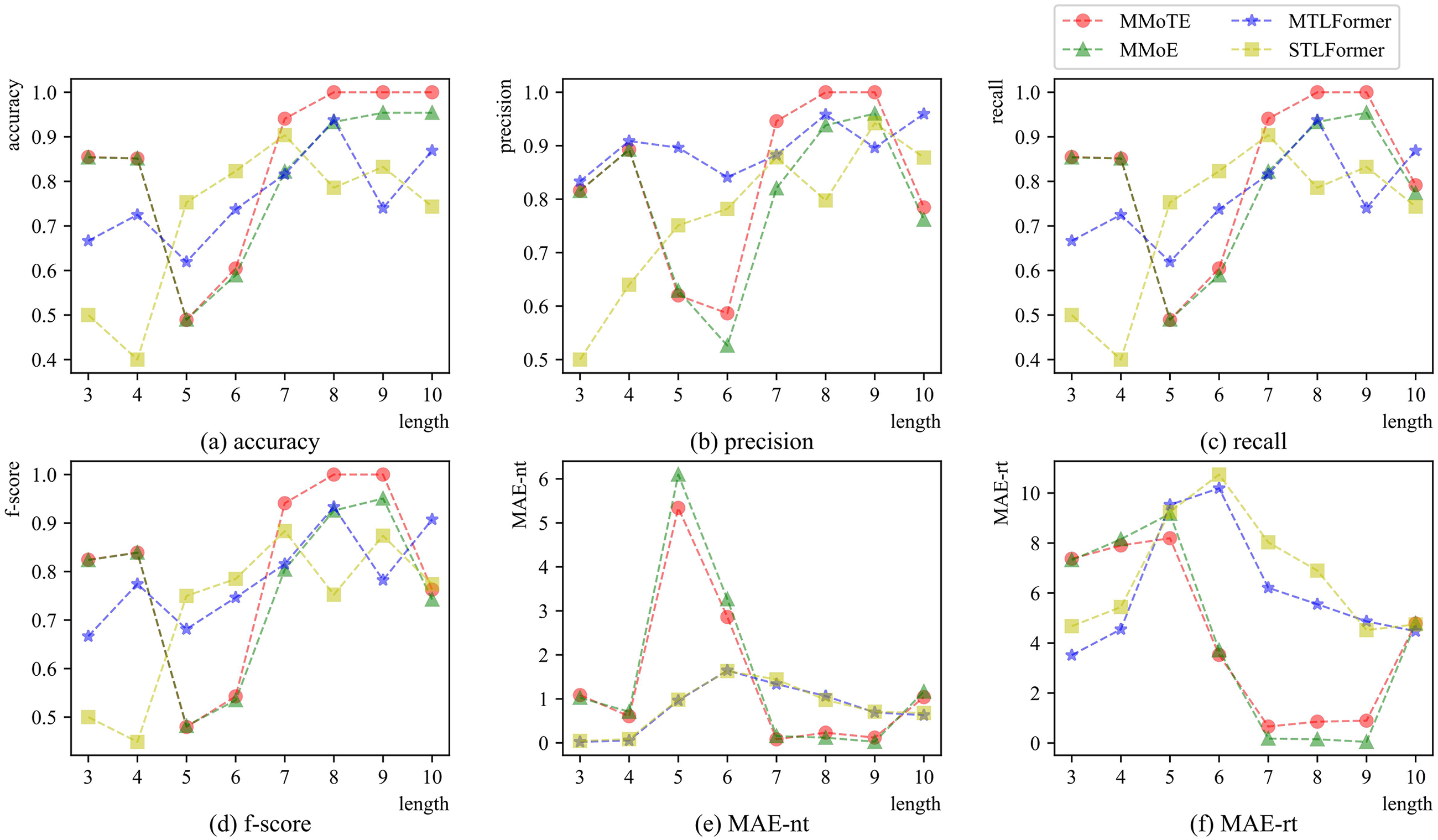
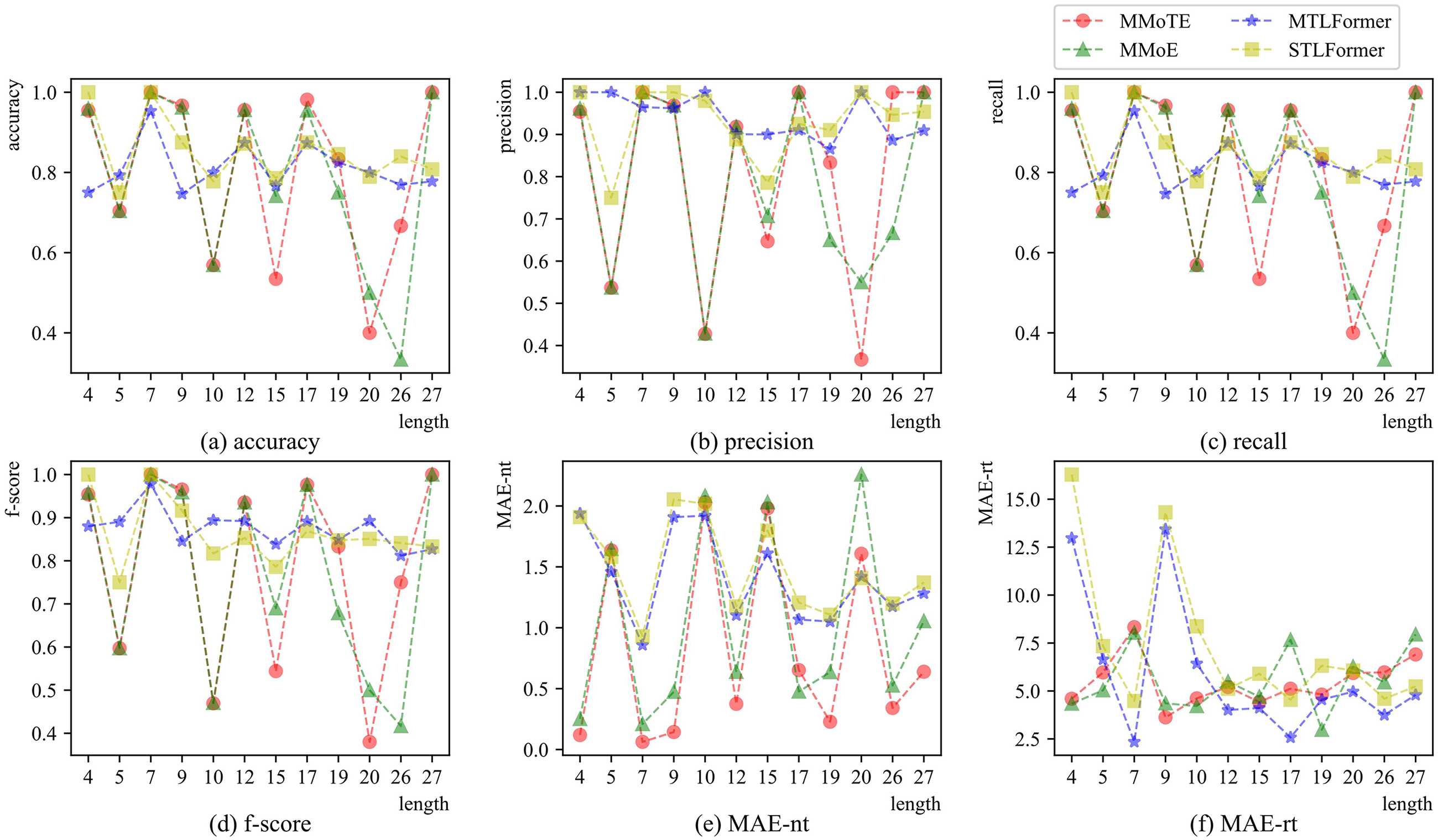
To further evaluate the performance of the four approaches, we analyze the predicted samples by their lengths, studying the performance of these approaches when predicting samples with different prefix trace lengths. Figures 4 to 7 present a comparative analysis and evolution of performance metrics for MMoTE, MMoE, MTLFormer, and STLFormer across all datasets as length increases in three tasks. Subfigures (a) to (d) illustrate the trends in accuracy, precision, recall, and F-score for Task 1 with increasing prefix trace lengths. Additionally, subfigure (e) demonstrates the changes in MAE (i.e. MAE-nt) for Task 2, while subfigure (f) shows the evolution of MAE (i.e. MAE-rt) for Task 3 as the prefix trace length increases. We analyze the performance from three perspectives: overall performance, the trend of change, and the magnitude of change (stability of prediction) on different datasets, as shown in Figures 4 to 7.

Comparison of prediction performance across different prefix trace lengths on the Helpdesk dataset.
Comparison of prediction performance across different prefix trace lengths on the BPIC2012_A dataset.
Comparison of prediction performance across different prefix trace lengths on the BPIC2012_O dataset.

Comparison of prediction performance across different prefix trace lengths on the BPIC2012_W dataset.
From Figure 4, the performance advantage of the MMoTE approach is significant on the Helpdesk dataset. As shown in Figure 4(a) to (d), MMoTE predicts higher values of accuracy, precision, recall, and F-score for Task 1 with different prefix trace lengths compared to the other methods. Conversely, the two MAE metrics associated with Tasks 2 and 3 (i.e. MAE-nt in Figure 4(e) and MAE-rt in Figure 4(f)) are significantly lower than those of other approaches. Regarding the change trends, MMoTE is more consistent with the MMoE approach, while MTLFormer aligns more closely with STLFormer. Regarding the magnitude of change, the MMoTE is more stable than the other prediction approaches. The values of all four metrics (Figure 4(a) to (d)) show a gradual increase with longer prefix trace lengths, particularly beyond a length of 8. However, for the MAE-nt and MAE-rt metrics (Figure 4(e) and (f)), the performance advantage of MMoTE becomes more pronounced as the prefix trace length exceeds 8, especially compared to MTLFormer. This may be due to the presence or absence of a crucial event in the prefix trace at the time of prediction.
From Figure 5, the performance advantage of the MMoTE approach is more prominent and better than the other three approaches when the prefix trace length is 7–9. Overall, the performance trends of MMoTE and MMoE exhibit remarkable similarity, while the variations in the performance between MTLFormer and STLFormer differ significantly for Task 1, as depicted in Figure 5(a) to (d). However, the trends for Tasks 2 and 3 show greater consistency, as depicted in Figure 5(e) and (f). Regarding the magnitude of change, the MTLFormer approach demonstrates the best stability across the six metrics for the three tasks.
From Figure 6, it is evident that the MMoTE and MMoE approaches exhibit similar trends, while MTLFormer and STLFormer also share similar patterns. The MMoTE approach shows more drastic change in Tasks 2 and 3 (Figure 6(a) to (e)), but demonstrates more stable performance in Task 3 (Figure 6(f)). In terms of the magnitude of change, the MTLFormer approach maintains more stable prediction performance in Tasks 1 and 2 (Figure 6(a) to (e)).
From Figure 7, the MTLFormer approach exhibits the significant performance advantages in Tasks 1 and 2 (Figure 7(a) to (e)). However, the MTLFormer approach demonstrates an even more pronounced performance advantage compared to the other three approaches in Task 3 (Figure 7(f)). Considering the overall change trend, the performance of both MTLFormer and STLFormer exhibits greater consistency in Tasks 1 and 2 (Figure 7(a) to (e)). Meanwhile, the difference between the two is more significant in Task 3 (Figure 7(f)). In contrast, the overall performance of MMoTE and MMoE on the three tasks is more consistent, except for the significant difference in prediction performance at the maximum length in Task 1 (Figure 7(a) to (d)).
Comparison of approach complexity and efficiency
To comprehensively evaluate the model complexity of the aforementioned four approaches, we compared their number of trainable parameters (i.e. model size) and the training time required across different datasets, as shown in Table 8. The number of trainable parameters (#params) refers to all the weights and biases that needed to be trained during model training. Note that the #params for the STLFormer approach are calculated as the sum of parameters in each model dedicated to three tasks.
Comparison of model size (1K = 1000) and training time across different approaches.

MMoTE: multi-gate mixture of transformer-based experts; MMoE: multi-gate mixture-of-experts; MTL: multi-task learning; STL: single-task learning.
Firstly, it is observed that the #params for MMoTE and MMoE consistently remain below 100K (1K = 1000) across all datasets, while the model sizes of MTLFormer and STLFormer are larger than 100K on all datasets. Furthermore, the MMoE approach exhibits the smallest model size on all datasets, followed by MMoTE, STLFormer, and MTLFormer. This indicates that the MMoE framework possesses a distinct advantage in MTL. Despite utilizing the Transformer network, which typically results in an increased number of model parameters, the model size of MMoTE remains smaller compared to STLFormer and MTLFormer, both of which also employ the transformer network. Secondly, it is found that the training time of MMoE is the lowest across all datasets, while MMoTE, MTLFormer, and STLFormer exhibit similar training times. This may be attributed to the fact that the latter three methods are all based on the transformer network. Considering both metrics, the #params values for MMoTE and MMoE are comparable, indicating similar model complexity. However, there is a significant difference in training time, which may be due to the transformer network requiring more time to learn the features in trace from these datasets.
Parameter analysis of MMoTE
For MMoTE, three key parameters significantly impact process predictions: the number of experts, the number of units in each expert network, and the number of heads within the multi-head attention mechanism. To investigate the effects of these parameters on model performance, we conducted experiments using datasets from the above business processes. The number of experts denotes the capability of capturing the difference among different tasks. We evaluated the impact of this parameter on MMoTE performance by changing the number of experts to 2, 4, 8, 16, and 24. The number of units denotes the number of hidden layer units in the expert network of MMoTE. We evaluated the impact of the hidden feature length on MMoTE performance by changing the number of units to 4, 8, 16, 32, and 64. Lastly, the number of heads within multi-head attention mechanism indicates the number of different information sources that MMoTE can focus on simultaneously during parallel input sequence processing. We evaluated the effect of the multi-head attention mechanism on MMoTE performance by varying the number of heads to 2, 4, 8, 16, and 32.
The parameter analysis on the Helpdesk dataset
From Figure 8(a), it is evident that as the number of experts increases, the performance of MMoTE in Tasks 2 and 3 shows a consistent trend, indicating that these tasks may share many features and have a strong correlation under this parameter. Within the selected range of this parameter, Task 1 achieves optimal performance with four and 16 experts, while Tasks 2 and 3 both reach their best performance with 16 experts. In Figure 8(b), the performance of Task 1 peaks with 8 units and then gradually declines as the number of units increases. This suggests that Task 1 achieves optimal results with 8 units, while Task 2 achieves near-optimal results with either 8 or 32 units, and Task 3 performs best with 32 units. From Figure 8(c), Task 1 reaches optimal performance with 4 heads, at which point Task 3 also achieves optimal results, while Task 2 attains near-optimal performance. In summary, the optimal performance points for Tasks 1, 2, and 3 vary, indicating different sensitivities to these parameters.

Performance analysis with different parameters of multi-gate mixture of transformer-based experts (MMoTE) on the Helpdesk dataset.
The parameter analysis on the BPIC2012_A dataset
As shown in Figure 9, the performance of MMoTE in Task 2 remains relatively stable with changes in the three parameters, indicating that this task is less sensitive to these parameters. In contrast, the performance of MMoTE in the other two tasks shows more noticeable variations, especially in Task 1. Specifically, from Figure 9(a), although the four metrics for Task 1 show inconsistent trends, an optimal parameter can still be identified when the number of experts is 16. For Tasks 2 and 3, the optimal results are achieved when the number of experts is 24. In Figure 9(b), both Tasks 1 and 2 achieve optimal results when the hidden feature length is 8. However, Tasks 2 and 3 attain their best performance with a hidden feature length of 32, while Task 1 performs the worst at this setting. Figure 9(c) shows that Tasks 1 and 2 both achieve optimal results with four heads, whereas Task 3 requires only two heads for optimal performance.

Performance analysis with different parameters of multi-gate mixture of transformer-based experts (MMoTE) on the BPIC2012_A dataset.
The parameter analysis on the BPIC2012_O dataset
As depicted in Figure 10, the performance trends of MMoTE across three tasks generally align with the increase in the values of the three parameters, indicating a strong correlation among these tasks. This suggests that they may share some vital features, and as the parameter values vary, these shared features may influence the performance of MMoTE in a similar manner. Furthermore, it reflects that the sensitivity of MMoTE to these three parameters is comparable across the three tasks. Within the given range of parameter variations, the optimal parameter values for the three tasks can be easily identified, specifically when the number of experts is 16, the number of units is 16, and the number of heads is 4.

Performance analysis with different parameters of multi-gate mixture of transformer-based experts (MMoTE) on the BPIC2012_O dataset.
The parameter analysis on the BPIC2012_W dataset
As shown in Figure 11, the performance of MMoTE in Task 2 remains relatively stable with changes in the three parameters, indicating that this task is less sensitive to these parameters. In contrast, the performance of MMoTE in the other two tasks shows more noticeable variations, especially in Task 3. Specifically, as shown in Figure 11(a), Task 1 achieves the optimal performance when the number of experts is 4. For Tasks 2 and 3, the best results are obtained when the number of experts is 16. In Figure 11(b), Tasks 2 and 3 achieve the optimal performance when the number of units is 8, while Task 1 achieves its second-best performance at this value, with its optimal performance at 16 units. Figure 11(c) shows that Tasks 1 and 3 achieve optimal performance when the number of heads is 2. At this value, Task 2 achieves its second-best performance, which is nearly identical to its optimal performance when the number of heads is 16.

Performance analysis with different parameters of multi-gate mixture of transformer-based experts (MMoTE) on the BPIC2012_W dataset.
In summary, the optimal parameter settings for different tasks in MTL can vary and sometimes conflict. Therefore, it is crucial to consider the similarities and differences between tasks and their sensitivity to parameters in our proposed MMoTE approach. By finding a balance, we can enable multiple tasks to achieve or approach optimal performance simultaneously.
Experimental results on the public manufacturing process log
We conducted this experiment by using the production dataset from a real workshop. Due to the limited availability of publicly accessible comparison methods, we did not perform a fair comparison with other methods. Instead, we randomly optimized hyperparameters for the four approaches: MMoTE, MMoE, MTLFormer, and STLFormer, and selected the best-performing hyperparameter combinations for each method. Additionally, we implemented the remaining time prediction (single-task) methods based on LSTM and GRU. Since the focus in predictive monitoring of manufacturing processes is primarily on the remaining time prediction, this experiment exclusively compares the MAE (i.e. MAE-rt) for Task 3.
Comparison of approach effectiveness, complexity, and efficiency
Although this experiment focuses solely on the performance of remaining time prediction (Task 3), Tasks 1 and 2 are still necessary for the MMoTE approach as auxiliary tasks. The MMoTE approach employs MTL to predict the remaining time of the manufacturing process, similar to the MMoE and MTLFormer methods. Table 9 presents the prediction performance, model complexity, and training_time across different approaches on the Production dataset in Task 3. As shown in Table 9, the MMoTE approach achieves the best performance, followed by MTLFormer, STLFormer, MMoE, GRU, and LSTM. Regarding model complexity (#params), the MMoE approach maintains the lowest complexity, while MMoTE, STLFormer, LSTM, and GRU are comparable in this aspect. In contrast, the model complexity of MTLFormer significantly increases. In terms of training_time, the MMoE approach requires the least time, followed by STLFormer, LSTM, GRU, MMoTE, and finally, MTLFormer. A comprehensive analysis of both #params and training_time reveals that model training time does not always increase proportionally with model complexity. This discrepancy may be due to various factors such as computational resources and dataset characteristics affecting the training time.
Comparison of model size (1K = 1000), training time, and remaining time prediction across different approaches on the production dataset.

MMoTE: multi-gate mixture of transformer-based experts; MMoE: multi-gate mixture-of-experts; MTL: multi-task learning; STL: single-task learning; LSTM: long short-term memory; GRU: gated recurrent units.
Comparison across different prefix trace lengths
To further evaluate the aforementioned approaches, we analyze their performance in remaining time prediction (Task 3) at different prefix trace lengths. Figure 12 illustrates the variation in MAE performance (i.e. MAE-rt) for the six different approaches at different stages of process execution (i.e. different lengths of prefix traces). Some approaches, such as STLFormer and LSTM, exhibit a rapid decrease in MAE-rt initially with increasing prefix length, followed by stabilization. In contrast, approaches like MMoTE and GRU show relatively stable MAE changes across the entire length range, indicating higher prediction stability. From different stages, the MMoTE approach demonstrates superior performance over larger continuous length intervals (i.e. [11, 29] and [64, 78]) compared to other methods. The MTLFormer approach performs best in intervals like [0, 10] and [54, 63], while the MMoE approach excels in the [30, 53] range. This phenomenon may be attributed to the varying ability of different approaches to learn and adapt to data features as specific events occur during process execution. The MMoTE approach likely captures and utilizes critical information in the data more effectively across most stages, maintaining a performance advantage over larger length intervals. In contrast, MTLFormer and MMoE may perform better at specific stages or under certain data characteristics, resulting in relatively better performance within certain length intervals.

Comparison of remaining time prediction performance across different prefix trace lengths on the production dataset.
Parameter analysis of MMoTE
Similarly, we conduct experiments on the production dataset to investigate the impacts of the above-mentioned key parameters, the number of experts, the number of units in expert network, and the number of heads within the multi-head attention mechanism, as shown in Figure 13. From Figure 13(a), as the number of experts increases from 2 to 16, the MAE-rt initially rises and then falls, indicating that a greater number of expert networks does not always lead to improved performance. Performance peaks with 16 expert networks, where the MAE-rt is at its lowest. However, when the number of experts increases further to 24, the MAE-rt begins to rise again, suggesting that too many expert networks can make the model overly complex and reduce predictive performance. This indicates that while increasing the number of expert networks enhances the model’s capacity to learn both shared and task-specific information, excessive expert networks may lead to overfitting or instability during training. From Figure 13(b), as the number of units increases from 4 to 8, performance improves. The task reaches its peak performance with 8 units, where the MAE-rt is at its lowest. However, as the number of units increases further to 64, overall performance begins to decline. This suggests that an appropriate number of units allows the model to capture the complexity of the task effectively while avoiding overfitting. From Figure 13(c), regarding the multi-head attention mechanism, two heads deliver the best performance and then the MAE-rt gradually rises as the number of heads increase, demonstrating that adding more heads does not improve performance for this task. This suggests that a simple attention mechanism is sufficiently effective, and too many heads can make the model overly complex and difficult to train.

Performance analysis with different parameters of multi-gate mixture of transformer-based experts (MMoTE) on the production dataset.
Sensitivity analysis of model performance to process complexity
To provide a more comprehensive comparison of our proposed MMoTE across different types of processes in manufacturing, we conducted a sensitivity analysis of the model’s performance in relation to process complexity. Specifically, we began by examining the event log characteristics that represent process complexity and then focused on analyzing the overall performance of MMoTE across event logs with different process complexity. As we known, event logs can reflect the complexity of the actual process execution. As indicated in Table 2, the characteristics that best represent process complexity are the number of activities (i.e. number of activities), the number of case variants (i.e. number of variants), the maximum case length (i.e. Max. case length), and the average case length (i.e. Avg. case length). From this table, we observe that the most complex log is the Production log from a manufacturing process. This further proves that manufacturing processes are more complex in manufacturing, followed by business processes. Next is BPIC2012_W, followed by Helpdesk, and finally the similar levels of complexity between BPIC2012_A and BPIC2012_O. As shown in Tables 4 and 9, for the most complex process, that is, the production log, MMoTE outperforms all other approaches. Similarly, among the event logs of business processes, Table 4 indicates that MMoTE achieves the best performance on BPIC2012_W, followed by Helpdesk, then BPIC2012_A, and finally, BPIC2012_O. This performance ranking aligns with the complexity of these processes. Therefore, we can conclude that the performance of MMoTE is highly sensitive to process complexity, with its performance advantage becoming more pronounced as the complexity of the process increases.
Conclusion and future work
This study introduces an approach MMoTE, a MMOTE, to address the predictive process monitoring in manufacturing. Manufacturing involves not only various business processes but also more complex manufacturing processes. For business processes, PPM requires multiple prediction tasks, such as the next activity, the next event time, and the remaining time. In contrast, for manufacturing processes, PPM focuses more on the remaining time prediction (i.e. the cycle time). Given the diversity and complexity of manufacturing processes, single-task prediction methods may not sufficiently capture all variations within the historical process executions. Thus, we developed MMoTE to create a more comprehensive predictive process monitoring method suitable for different types of processes in manufacturing industry. MMoTE leverages the feature extraction capabilities of the transformer network and the dynamic, flexible parallel learning capabilities of the MMoE framework as well as a sequence of expert networks with a gating mechanism. By effectively handling the complex and variable data characteristics in various processes of manufacturing, MMoTE provides accurate and reliable predictions. This enables manufacturing enterprises to better monitor and control operations, promptly identify potential delays or issues, and make necessary adjustments to enhance production efficiency. Evaluations on five datasets from different processes show the effectiveness, generalization, and efficiency of MMoTE in PPM of manufacturing.
In our current study, MMoTE incorporates modules with general scalability, notably the expert network, which can be enhanced by replacing the existing simple MLP with more advanced sequence modeling networks, such as those based on the transformer or LSTM, or hybrid models combining both. Additionally, both the shared bottom and tower networks offer opportunities for further optimization to improve scalability. Future research will explore different sequences and combinations of these modules to enhance model performance. We also plan to investigate performance improvements by incorporating heterogeneous tasks and examining the effectiveness of multi-modal information fusion between diverse tasks in PPM, inspired by Cheng et al. 45
Footnotes
Authors’ contribution
Jiaojiao Wang: conceptualized and drafted the work; Yao Sui conducted the experiments; Chang Liu analyzed the data; Xuewen Shen prepared the outline, and Zhongjin Li and Dingguo Yu supervised the manuscript. All authors were involved in the writing, reviewing, and editing of the manuscript.
Declaration of conflicting interests
The author(s) declared that they have no potential conflicts of interest with respect to the research work reported in this paper.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work is supported by the National Natural Science Foundation, China (nos. 62002316, 62206241, and 61802095), the Key Science and Technology Project of Zhejiang Province (no. 2021C03138), the National Natural Science Foundation of Zhejiang Province, China (no. LY22F020021), and the Medium and Long-term Science and Technology Plan for Radio, Television, and Online Audiovisuals, China (no. 2022AD0400).