
Abstract
Spatiotemporal (ST) graph modeling has garnered increasing attention recently. Most existing methods rely on a predefined graph structure or construct a single learnable graph throughout training. However, it is challenging to use a predefined graph structure to capture dynamic ST changes effectively due to evolving node relationships over time. Furthermore, these methods typically utilize only the original data, neglecting external temporal factors. Therefore, we put forward a novel time-varying graph convolutional network model that integrates external factors for multifeature ST series prediction. Firstly, we construct a time-varying adjacency matrix using attention to capture dynamic spatial relationships among nodes. The graph structure adapts over time during training, validation, and testing phases. Then, we model temporal dependence by dilated causal convolution, leveraging gated activation unit and residual connection. Notably, the prediction accuracy is enhanced through the incorporation of embedding absolute time and the fusion of multifeature. This model has been applied to three real-world multifeature datasets, achieving state-of-the-art performance in all cases. Experiments show that the method has high accuracy and robustness when applied to multifeature and multivariate ST series problems.
Keywords
Introduction
Spatiotemporal (ST) series data typically involves temporal changes and spatial associations, and is used widely in various applications, such as environmental monitoring, 1 traffic analysis,2,3 power system state forecasting, 4 wind speed prediction, 5 and solar energy generation. 6 With the rapid development of sensor networks and mass storage technologies, the volume of collected ST series data has surged in recent years. Predicting ST series can aid in understanding trends in temporal and spatial changes, as well as interactions between different locations. This capability is crucial for forecasting future trends, devising effective management strategies to conserve resources, mitigate risks, enhance efficiency, and advance development across multiple domains.
Traditional statistical parameter models,7–9 such as the vector auto regressive (VAR) model and hidden Markov model, excel in learning temporal features. However, they face challenges in capturing complex spatial dependencies in multivariate time series. Machine learning (ML) methods like the k-nearest neighbor (KNN) approach can handle a larger amount of data, but the prediction results are affected by the type of manual feature extractions. Recently, deep learning (DL) methods, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs),10,11 have received significant attention from the academic community. While these models effectively learn temporal or spatial dependencies, they are typically suited for grid data, whereas practical data often involve graph structures, like social networks and urban road networks. These above-mentioned methods are less suitable for graph data, however, graph neural networks (GNNs) are adept at leveraging relationships between nodes and edges in graph structures, making them advantageous for handling non-Euclidean data. Nevertheless, GNNs currently face challenges in ST series prediction. Classical graphs are static and undirected, potentially limiting their ability to capture dynamic spatial dependencies (Figure 1(a)). Therefore, constructing dynamic graphs (Figure 1(b)) is essential to capture evolving relationships over time. Moreover, the states of variables are influenced by numerous features (Figure 2), underscoring the importance of fusing multiple variables to enhance predictive accuracy. Recently, some studies have shown that the adaptive graph achieves better results than those with static graph alone. Wu et al. 12 introduced a GNN-based model for multivariate time series, pioneering the use of learnable graph structures. To better capture ST correlations, some researchers have integrated multiple ST fusion modules to extract correlations across different time periods. 13 Also, dynamic adaptive graphs14,15 have been developed to learn evolving ST dependencies. Despite significant progress in ST prediction, these methods still face limitations, such as the inability to capture changing spatial relationships between nodes with only one learnable graph throughout training, insufficient integration of multiple features, or overlooking the impact of temporal patterns on ST prediction.

Example of a time-varying graph in a network. Take the traffic network as an example, nodes A, B, C, D, and E represent different districts. (a) Depicts a static graph constructed based on fixed connection relationships. (b) Illustrates a dynamic graph influenced by real-time traffic data, where node interactions vary over time.

Multifeature fusion at different time points. The Figure illustrates how a future feature
The goal of this paper is to design a time-varying graph convolution network (TVGCN) to address the aforementioned issues, supporting multifeature information fusion, and dynamically capturing the correlations between variables. To achieve this goal, we use GCN, attention and dilated causal convolution (DCCN) and other techniques. Our proposed model shows state-of-art performance on three public datasets. The contributions of this article are outlined as follows:
We propose a novel TVGCN architecture for multifeature and multivariable ST series prediction. This architecture incorporates a time-varying attention mechanism to dynamically capture spatial relationship, and uses DCCN to model time-dependent relationship, and achieves multifeature fusion through convolutional neural networks. The TVGCN effectively learns dynamic spatial and temporal dependencies among multivariate and multifeature data. We employ a time embedding method to capture temporal patterns in practical applications, thereby enhancing prediction accuracy. The TVGCN model generates dynamic graphs that evolve with the ST series across all stages, including training, validation, and testing. Extensive experiments conducted on three real-world datasets demonstrate that our method can achieve state-of-art performance across different prediction horizons compared to baseline methods.
Related work
ST series prediction
Researchers have made significant strides in ST series forecasting. Initially, linear models16,17 were employed for time series modeling, but their prediction accuracy varied widely due to data fluctuations. Subsequently, traditional ML methods like KNN 7 and SVM 8 were utilized, but their applicability and flexibility were hindered by intricate feature engineering. 18 In recent years, DL models have demonstrated superior prediction accuracy in forecasting ST series. 19 One prominent DL model, DeepAR, 20 pioneered the use of RNNs for time series problems. However, during prediction, it adopts the predicted value from the last time step as input rather than the actual value, potentially causing discrepancies between training and prediction stages. To address this, techniques from natural language processing have been adapted. Moreover, Rangapuram et al. 21 proposed a deep state-space model using RNNs, where the current value depends solely on the present state, unlike DeepAR which relies on previous predictions or actual values. These models primarily focus on single-horizon forecasting. In contrast, Wen et al. 22 introduced a multihorizon forecasting model named multi-Horizon quantum recurrent network, capable of predicting values multiple steps in the future. While these methods effectively extract temporal features from data, they often struggle with spatial feature extraction. Addressing this limitation, Shi et al. 23 introduced the Conv-long-short-term memory (Conv-LSTM) model, combining LSTM and CNN architectures to analyze ST features. This model notably achieved success in rainfall prediction using radar echo data. Building upon this concept, subsequent ST series methods integrating CNN structures have emerged.24–26 Although these models can capture the dynamic ST correlations, they are only applicable to grid data.
Graph neural network
In practical applications, most data consist of graph data, and traditional DL methods often struggle to handle these effectively. Increasingly, researchers are turning to graph-based approaches for ST series prediction. To our knowledge, the STGCN 27 algorithm represents a pioneering effort in applying GCN to ST series problems. This model integrates time-gated convolution units and spatial convolution units to construct a fundamental ST convolution module, stacking multiple units and incorporating a residual module for enhanced performance. Inspired by the success of attention mechanisms across various domains,28–30 researchers have begun integrating them into ST sequence prediction models. Guo et al. 31 introduced attention into the core ST feature extraction module, creating ASTGCN. This method leverages temporal and spatial attention mechanisms to capture dynamic ST features, effectively extracting seasonal trends through multiscale temporal encoding. Despite its promising results, ASTGCN is constrained by its high computational complexity. Due to dynamic graphs’ superior ability to model evolving spatial relationships among nodes compared to static graphs, extensive research has been conducted in this area. Notable methods include MTGNN, 12 STFGNN, 13 Graph WaveNet, 14 PGCN, 15 and GCN-M 32 and others. Wu et al. 12 introduced MTGNN, which employs a graph learning module to analyze directional relationships among variables, utilizing multihop propagation and perceptual inflation to capture ST dependencies. Building on the adaptive adjacency matrix concept from MTGNN, Wu et al. 14 proposed Graph WaveNet, incorporating dilated random convolutions to capture long-term temporal dependencies. Li et al. 13 not only introduced dynamic spatial graphs but also employed an enhanced dynamic time warping algorithm to measure time series similarity, thereby constructing dynamic temporal graphs and integrating ST fusion. These models not only address static node connections but also propose learned and adaptive graphs based on network models. However, these studies have overlooked the impact of external temporal information on the periodicity or seasonality of spatiotemporal sequence predictions. More recently, Zuo J et al. 32 proposed GCN-M, which integrates multiscale temporal embeddings and dynamic graph structures, demonstrating that incorporating external time encoding enhances the capture of ST seasonal patterns.
Dilated causal convolution
RNNs or LSTMs are typically used for sequential data processing. However, recently, more researchers have found that CNNs can effectively handle sequence data, especially due to the limitations of RNNs or LSTMs. Since sequence data inherently follows a chronological order, traditional CNNs are not initially suited for this purpose, leading to the introduction of causal convolution. Yet, causal convolution often fails to capture extensive historical context. To address this challenge, Oord et al. 11 proposed DCCN to enhance the receptive field of causal convolution. DCCN achieves this by introducing “holes” in convolutional kernels, enabling dense feature extraction in multilayer CNNs. 24 Essentially, DCCN can capture long-term temporal dependencies without significantly increasing the number of parameters.
Motivated by the aforementioned research, and taking into account the irregular grid structure and dynamic ST correlations of ST series, we propose the TVGCN method for predicting multivariate and multifeature ST series. We utilize DCCN to model the temporal dimension and GCN based on attention mechanisms to model the spatial dimension. Furthermore, we enhance prediction accuracy by integrating multiple features and encoding time into learnable vectors using a specialized method.
Problem definition
Graph definition
A graph is a data structure that represents relationships between entities, where entities are represented as nodes and their relationships as edges. The definition of graphs varies depending on the problem at hand. For instance, in the context of expressways, we can define the traffic network on the expressway as a graph
Problem definition
Our main focus is on solving the problem of predicting ST series with multiple variables and features. For instance, we utilize historical traffic data from expressways, encompassing metrics such as traffic flow, average speed, and average occupancy rate, to forecast future traffic conditions. Given a historical ST series
Methods
In this section, we introduce the TVGCN architecture. We then detail the methodology for constructing a time-varying graph based on attention mechanisms and the concept of time embedding. Following this, we elaborate on graph convolution operations utilizing both a static adjacency matrix and a time-varying dynamic adjacency matrix. Finally, we discuss the implementation of ST sequence prediction using DCCN in conjunction with GCN.
Model architecture
The TVGCN architecture for predicting ST series is illustrated in Figure 3. It consists of an input layer, an ST convolutional layer, and an output layer. Initially, the absolute time of the time series is encoded using the Time2Vector method, learning its representation and then integrated with the sequence features. Subsequently, the L-length sequence is segmented into T-length input samples using a sliding time window approach. These samples undergo linear transformation followed by processing through the ST convolutional layer, which comprises K (where K is 3) ST blocks. Each ST block primarily includes two components: DCCN for temporal feature extraction, and TVGCN combined with static GCN for capturing spatial dependencies among nodes. The static graph reflects physical connectivity relationships, while time-varying graphs are derived from the T-length ST series based on attention scores. The TVGCN enhances the extraction of ST relationships across multiple ST layers. The output layer aggregates results using a Relu activation function and

The TVGCN architecture. Left side shows the overall structure of TVGCN, while the right side illustrates the detailed architecture of TVGCN.
When employing multiple consecutive DCCN layers, the choice of dilation coefficients primarily follows the HDC principle, 33 addressing the issue of grid-like effects. For instance, while the receptive field of dilation coefficients like [1, 2, 3] matches that of [2, 2, 2], the former optimally utilizes input information and yields superior results.
DCCN for time features extraction
The DCCN is chosen for extracting temporal features due to its benefits in parallelism, flexible receptive field adjustment, and gradient stability. Causal convolution achieves this by generating an output sequence through one-dimensional full convolution, ensuring that future predictions do not depend on future data. DCN is designed to expand the receptive field without increasing computational load. This is achieved by applying dilation, where zeros are introduced into the convolution kernel while maintaining the input unchanged. This dilation allows the network to observe longer series lengths without increasing computational complexity. After convolution and gate activation unit, the final representation of the input series
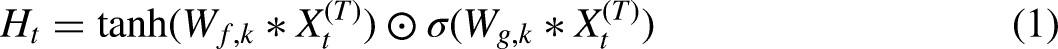
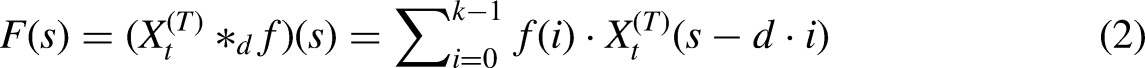
TVGCN for spatial features extraction
Time-varying graph construction with attention
Taking traffic flow on roads as an example, the correlation between traffic conditions at two locations dynamically changes due to various factors such as road structure, surrounding environment, weather fluctuations, and unforeseen incidents. Consequently, the mutual influence of different traffic states across locations also varies over time, illustrated in Figure 4. For instance, the interaction between a residence and a fast-food cafe might be significant in the morning but minimal in the evening. Relying solely on physical connections makes it challenging to learn spatially dynamic impacts. Therefore, to fully leverage the dynamic dependencies among nodes, we propose a dynamic adjacency matrix based on attention, which adaptively captures the evolving correlations driven by node data features:
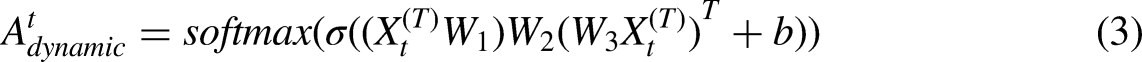

Different spatial attention at different times. The darker line between nodes means greater attention.
Traffic data are physically associated with the road network. Suppose different locations on the roads as nodes, and the relationship between two nodes is determined by the connectivity between roads. Therefore, it is necessary to build the static adjacency matrix by the physical connection relationship on the road. As a result, in addition to the learnable adaptive adjacency matrix

Time-varying graph convolution network
The GCN primarily employs the concept of message passing, where nodes in the lower graph layer aggregate information from neighboring nodes in the upper layer to learn spatial dependencies. In our approach, this is realized through spatial domain graph convolution, where feature extraction occurs directly via convolutions between nodes and their neighbors. A multigraph is constructed to facilitate these convolution operations. Following the time-varying graph convolution, nodes can be represented as follows:


The schematic illustration of the proposed time-varying graph convolution can be seen in Figure 3. At each time step, the graph convolution involves two types of graphs. The left graph, depicted with black nodes at each time step, represents a static graph constructed based on physical connections. The right graph represents the time-varying graph, constructed using features that evolve over time.
External time embedding
Some ST data are influenced by absolute time factors, such as traffic conditions in different locations varying with the time of day, day of the week, and whether it's a weekday or weekend, all of which significantly impact prediction accuracy. Therefore, absolute time features including year, month, day, and hour can be embedded as vectors and incorporated into the network during training.
Time vectors can be embedded manually or through a functional method. Manual embedding requires specific rules tailored to different time series scenarios, with varying impacts on the same dataset. Hence, the paper adopts a general functional embedding method where time is embedded into vectors within the network for joint training and testing. In this study, Time2Vector
34
is employed for time embedding, inspired by positional encoding.
28
Unlike multiscale approaches used in other studies31,32 for extracting seasonal patterns, our method embeds time as vectors to provide a universal representation. Additionally, we use sine functions, and a linear term to separately capture periodic and nonperiodic trends in the data. This approach is straightforward to implement, avoiding the complexity of scale selection and adjustment, thus enhancing generality and facilitating integration into various model architectures. Moreover, this method demonstrates time scaling invariance (as confirmed in Kazemi et al.
34
). The specific formula is as follows:

Here is an example of time embedding, which provides further insight into equation 7 (further information are available in the source code on Github),
Input: The initialized TVGCN network, the node number N, batch size B, the size of the time window T, to maintain time synchronization among all nodes, absolute time is first extended according to node dimensions, and then extracted from the expanded dataset. Assuming absolute time includes four items: year, month, day, and hour, then the extracted absolute time is Normalize Create a tensor and fill the diagonal of the last two dimensions with the last dimension of Calculate Compute Concatenate Concatenate
Experiment
Our experimental verification is to answer the following questions:
Is our model competitive with other classical ST series prediction models? Is our model competitive with the current advanced graph-based models? Is our model stable across different time windows? Does our model improve accuracy through the integration of time data and multiple features? Is our model progressive with dynamic adjacency matrix constructed in the testing phase?
Our model is verified on three datasets, including a Toy dataset
34
and two multifeature and multivariables highway datasets, which is called PEMS04 and PEMS08 from California.
35
The key information of the three datasets is provided in Table 1. In addition to the ablation experiment of our model, we also compare it against the classical methods and GNN literature, including the aforementioned representative MTGNN model, a standard encoding and decoding LSTM model, and the basic autoregressive VAR model. All experimental results are averaged over at least five runs to ensure robustness. To maintain fairness, all models adopt the same training loop, datasets and evaluation process.
Datasets summary.

Experimental setup
We use three evaluation metrics, including mean absolute error (MAE), root mean squared error (RMSE) and mean absolute percentage error (MAPE).


Baselines
TVGCN is our proposed method. To evaluate our models, the experimental results were compared with other baseline methods in the following:
VAR: A well-known vector auto-regressive time series analysis method. LSTM: A special RNN model with long short-term memory. ASTGCN
31
: A frequency domain GCN model, which introduces ST attention into the model. MTGNN
12
: A general and typical GNN method aimed at multivariable time series data with graph learning. STFGNN
13
: An ST fusion GNN with various ST graphs for traffic flow forecasting.
Traffic datasets
At first, we conduct experiments on two multivariable and multifeature datasets in the traffic field, that is PEMS04 and PEMS08, which are significant in GNN research. The processed data are sampled at 5 -min intervals. The system deployed over 39,000 detectors on the expressways in several large cities of California. 35 Our experiment focuses on three main measurements, including total traffic flow, average occupancy rate, and average speed. Firstly, the time window is set to be 12, meaning we predict the traffic flow for the next 1 h. Table 2 shows the results of the baselines and our proposed model on the two traffic datasets with the time window length being 12. The prediction targets are the traffic flow values. For these experiments, to better compare those networks with GNN model, we directly include results obtained from other literature which can be seen in Table 2 with *. From the results we can see that deep neural network models outperform the traditional VAR model on 1 -h prediction, demonstrating the limited capability of traditional statistical methods in modeling nonlinear data with complex spatial relationships. Despite the simple structure of the LSTM model, the prediction results obtained by this method are not very satisfactory compared to the ST feature learning methods like ASTGCN, MTGNN, STFGNN, and TVGCN, mainly because the plain LSTM model fails to capture complex spatial relationships. By comparison, TVGCN gets the best results in all three metrics in both two tasks compared with the current advanced models. This means that constructing time-varying graphs in both the training and testing stages is effective. It appears that with the data changing, data-driven time-varying graphs can significantly improve robustness.
Results comparison on PEMS datasets with a time window length of 12.

VAR: vector auto regressive; TVGCN: time-varying graph convolution network; MAE: mean absolute error; RMSE: root mean squared error; LSTM: long short-term memory.
To prove the stability of the TVGCN network model, we perform experiments using time windows of 6, 12 and 24 respectively. That is, the traffic conditions for half an hour, 1 h and 2 h ahead are predicted respectively. The results are shown in Table 3. It can be seen from the table that across each fixed time length, the predictive effect of the DL methods obviously exceeds that of the traditional statistic method. With the increase of the time window length, the prediction accuracy of TVGCN gradually decreases. Nevertheless, our proposed TVGCN achieves the best prediction effect across all different time windows. While MTGNN's learnable graph method also yields promising results, a graph constructed solely during the training stage fails to accurately capture the evolving spatial dependencies between series.
Baselines comparison with different time lengths on PEMS04 and PEMS08 datasets.

VAR: vector auto regressive; TVGCN: time-varying graph convolution network; MAE: mean absolute error; RMSE: root mean squared error; MAPE: mean absolute percentage error; LSTM: long short-term memory.
Figure 5 shows the performance comparison of different methods as the prediction horizon increases, with (a) depicting results from the PEMS04 dataset and (b) detailing results from the PEMS08 dataset. As can be seen from Figure 5, prediction errors across various methods increase with longer horizons. This increase in difficulty stems from the greater length of the prediction, which poses challenges for accurate forecasting. Nevertheless, our method TVGCN consistently achieves superior prediction results across different horizons. Furthermore, methods focusing on temporal feature extraction, such as VAR and LSTM, demonstrate strong short-term prediction results. However, due to limitations in spatial dependency learning, these methods experience significantly increased prediction errors with longer horizons. In contrast, the MTGNN model, which considers both temporal and spatial relationships simultaneously, shows a slower increase in error with longer prediction lengths. Our proposed TVGCN outperforms all other methods in prediction accuracy across all horizon lengths, showcasing the efficacy of the ST prediction framework based on multifeature fusion, all-stage TVGCN, and DCCN in effectively capturing dynamic dependencies among multiple variables.

Performance comparison with the increase of horizon. (a) PEMS08 and (b) PEMS04.
To validate the efficacy of the key components in our proposed model, we conducted ablation experiments on the PEMS04 and PEMS08 datasets, as shown in Table 4. Our proposed model achieves the best performance when employing GCN, dynamic adjacency matrix during in both training and testing phases, and multifeature fusion. By comparing the results in the second and third columns of the table, we can see that the time-varying adjacency matrix is significant to improve our model's performance. Additionally, multifeature fusion through convolution enhances prediction effectiveness compared to using single features alone. Furthermore, experiments indicate that excluding dynamic adjacency matrices during testing leads to poorer performance on both PEMS04 and PEMS08 datasets. Notably, our observations during experiments show that while training errors remain minimal, testing errors increase, highlighting the diminished generalization ability when the time-varying adjacency matrix is constructed solely during training. The rightmost column in Table 4 compares experiments using a standard convolutional network versus a DCCN network under identical receptive field conditions. Results demonstrate that DCCN consistently outperforms CNN, emphasizing the importance of constructing a DCCN module.
Ablation study of key components of TVGCN on PEMS datasets.

TVGCN: time-varying graph convolution network; DCCN: dilated causal convolution; MAE: mean absolute error; RMSE: root mean squared error; MAPE: mean absolute percentage error.
The structure of the DL model proposed in this study is somewhat complex, so it is necessary to evaluate the computational complexity of the DL models. Table 5 shows the computational complexity of several DL methods mentioned before, including training time, validation time, testing time, and parameter count. In Table 5, GCN-CNN is a network model where DCCN is replaced by CNN. For fair comparison, the batch size of all DL models is set to 32. It can be seen that MTGNN has the highest number of parameters due to the multiple stacked modules and convolutions. Although TVGCN has a larger number of parameters due to the adjacency matrix constructed by the attention mechanism, compared to GCN-CNN, dilated causal convolution significantly reduces parameter count under the same receptive field, thus saving time and computational resources. The smaller number of entries in the PEMS08 dataset compared to PEMS04 results in a minor difference in training time. However, despite the substantial difference in training time between LSTM and TVGCN, their prediction times are comparable, indicating TVGCN's ability to quickly predict results once adequately trained. Moreover, parallel convolution operations in TVGCN facilitate faster processing of long sequences, a critical advantage for applications requiring real-time predictions.
Computation time for PEMS data.

CNN: convolutional neural network; TVGCN: time-varying graph convolution network; LSTM: long short-term memory.
Bold indicates the least amount of time spent and underline indicates the second least.
Toy dataset
To evaluate the impact of incorporating time data on prediction accuracy, we employed a multivariate ST dataset named Toy Dataset, which includes absolute time information and draws inspiration from.
36
This dataset comprises sine-wave series with multiple variables exhibiting strong interdependencies. Each ith time series is defined as shown in equation 11. We utilized the Time2Vector technique
34
to encode absolute time into a vector format, which was then embedded as an additional feature in the network, following the methodology outlined in section External time embedding. The absolute time information, including year, month, and day, was extracted and normalized to a [0,1] range. Subsequently, this normalized time data was incorporated into the coding function described in equation 7 of section External time embedding. Finally, the time sequence was encoded into a vector of specified dimensions and integrated into the network as additional features for learning.
Table 6 presents the results of various methods using time windows of 6, 12, and 24. TVGCN represents our proposed model, while TVGCN-E denotes our proposed approach incorporating additional data encoding. Across Table 6, we observe a general trend of decreased prediction accuracy as the time window increases for most methods. However, our proposed TVGCN consistently achieves optimal results at each fixed time length. Moreover, employing the Time2Vector method for encoding absolute time also contributes to enhanced prediction accuracy. This underscores the effectiveness of integrating supplementary time data into the network to improve model performance.
Baselines comparison with different lengths of time window on toy dataset.
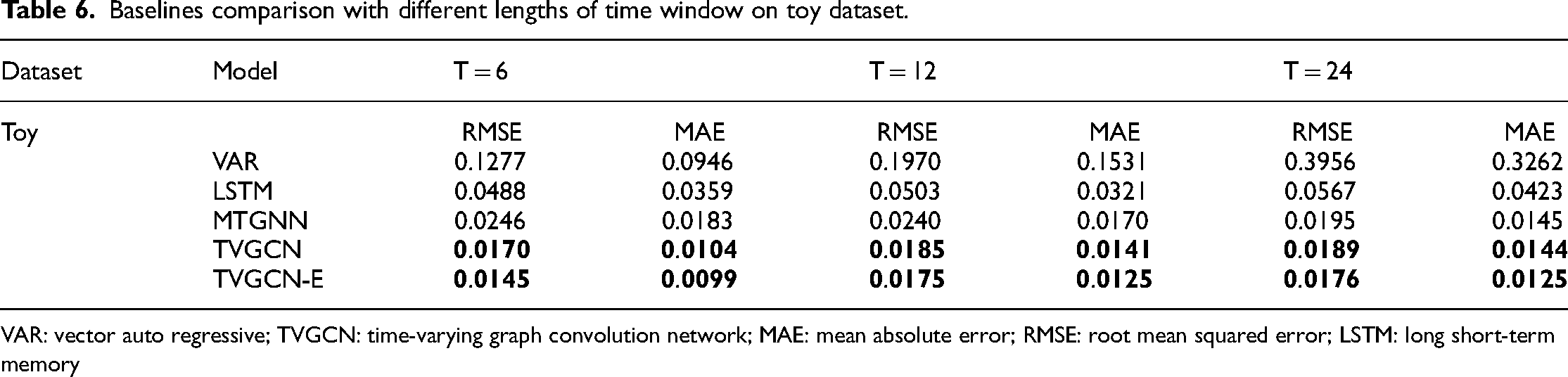
VAR: vector auto regressive; TVGCN: time-varying graph convolution network; MAE: mean absolute error; RMSE: root mean squared error; LSTM: long short-term memory
It can be seen from equation 11 that the influence coefficient between different nodes varies with the magnitude of

Discovering spatial relationships from data: (a) Relationship between the constituent elements of the first four series in the toy dataset. (b) Time-varying adjacency matrix at t within the interval (1406, 1412). (c) Time-varying adjacency matrix at t within the interval (1420, 1426).
Conclusion
This paper introduces a novel ST architecture for predicting multifeature and multivariable time series. Our approach integrates a TVGCN with DCCN to capture dynamic dependencies among nodes across different time periods. Time-varying graphs are constructed using attention mechanisms between nodes in spatial dimensions. The temporal information is added to the spatial features to get good ST fusion effect. In addition, multifeature fusion through convolution is used to improve the accuracy. Experiments on three real-world datasets show that our proposed method can achieve state-of-the-art performance.
In the future, we plan to extend this ST prediction model to more complex domains such as climate and energy forecasting. While our proposed method has shown promising predictive results, there remains room for improvement in computational complexity, particularly in generating dynamic adjacency matrices. Future directions include exploring efficient techniques like matrix sparsification. Additionally, considering the heterogeneous nature and semantic properties of nodes in practical applications would further enrich the graph construction process.
Footnotes
Acknowledgments
The authors would like to express their gratitude to all those who helped them during the writing of this manuscript. The authors owe their sincere gratitude to friends and colleagues who gave them much enlightening advice and encouragement.
Author contributions
FS designed the work, obtained the dataset, performed the experiments, and drafted the work. AZ and KC edited the manuscript, performed the experiments, and organized the data. Pro H analyzed the data, revised the manuscript, and confirmed the authenticity of all the original data. All authors have read and approved the final version of the manuscript.
Data availability statement
Data availability at https://github.com/sunfeiyan666/time_series_data.git. Code availability: ![]()
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, Defense Industrial Technology Development Program (Grant Nos. 72072092 and JCKY2020601B018).