
Abstract
As the Internet and Internet of Things (IoT) continue to develop, Heterogeneous Information Networks (HIN) have formed complex interaction relationships among data objects. These relationships are represented by various types of edges (meta-paths) that contain rich semantic information. In the context of IoT data applications, the widespread adoption of Trigger-Action Patterns makes the management and analysis of heterogeneous data particularly important. This study proposes a meta-path-based clustering method for heterogeneous IoT data called I-RankClus, which aims to improve the modeling and analysis efficiency of IoT data. By combining ranking with clustering algorithms, the PageRank algorithm was used to calculate the intraclass influence of objects in the network. The HITS algorithm then transfers the influence to the core objects, thereby optimizing the classification of objects during the clustering process. The I-RankClus algorithm does not process each meta-path individually, but instead integrates multiple meta-paths to enhance the interpretability and clustering performance of the model. The experimental results show that the I-RankClus algorithm can process complex IoT datasets more effectively than traditional clustering methods and provide more accurate clustering outcomes. Furthermore, through a detailed analysis of meta-paths, this study explored the influence and importance of different meta-paths, thereby validating the effectiveness of the algorithm. Overall, the research presented in this paper not only improves the application effects of HINs in IoT data analysis but also provides valuable methods and insights for future network data processing.
Introduction
The digital era is characterized by an explosive growth in data quantity and connectivity demands owing to advancements in Internet of Things (IoT) technologies. 1 However, despite these advancements, the integration of heterogeneous IoT systems remains a significant barrier, leading to inefficiencies and underutilization of data potential. This study is motivated by the need to overcome these integration challenges to facilitate seamless data flow and interpretation across various IoT platforms. By developing an improved semantic interoperability framework, this study aims to enable a more comprehensive and effective utilization of IoT systems, enhancing both technical outcomes and user experiences. With this motivation, our approach leverages advanced methodologies to address key gaps in current research and paves the way for practical IoT applications in diverse domains.
The proliferation of the IoT across various sectors produces a deluge of real-time data, bringing to fruition the vision envisioned by Ashton 2 in 1999—a world in which every electronic object is interconnected with a unique digital identity. Defined in 2005 as an omnipresent and dynamic network, 3 IoT now seamlessly integrates into daily life, profoundly influencing it with applications stretching from autonomous driving to smart homes. Notably, the Trigger-Action Pattern (TAP) has emerged as a distinctive IoT application 4 enabling cross-domain interactions via user-customized Recipes, integrating the functionalities of disparate items. Such innovations have simplified and enhanced Recipe creation and usage, as evidenced by platforms such as IFTTT 5 and Integromat. 6 The rapid evolution of IoT has led to a surfeit of sensors and intelligent devices, embedding complex data into daily routines and forming intricate systems that complicate the search for specific resources. Consequently, efficient and intelligent data mining methods are indispensable for extracting meaningful information from the vast, cluttered, and noisy datasets of IoT.
As the application of the IoT and its TAP continue to expand, a vast quantity of TAP data is generated, 7 encompassing complex data sourced from the real world and composed of various types of objects and interactions. Utilizing the network structure as a fundamental unit for data processing ensures data integrity, forming what is known as a Heterogeneous Information Network (HIN).8,9 Heterogeneous Information Networks integrate multiple object types and their interactive data, effectively managing the complex data derived from TAP. 10 In studying HINs, researchers have discovered that cluster analysis of these networks can uncover valuable structural information.11,12 To enhance the trustworthiness of the clustering results, it is imperative to account for the interaction information between different object types, thus preventing the loss of data.
Traditional clustering methods rely mainly on the attribute features of objects, dividing networks into multiple subgraphs based on the features of adjacent objects, and grouping similar objects into the same clusters. The Learning with Local and Global Consistency algorithm 13 builds a similarity matrix based on network objects, propagates class label information until a global state is achieved, and then clusters objects with high similarity. Spectral clustering14,15 constructs a graph of network objects and assigns weights to edges based on object distances to cluster the graph, ensuring minimal weights between clusters and maximal weights within a cluster. DBSCAN, a density-based clustering method, 16 considers each object as a cluster center, extending it to attract low-density surrounding objects and is effective for noise-affected data to extract clusters of various shapes and sizes.
As interest in HINs has grown owing to their complexity and the diverse object types they contain, traditional methods for analyzing homogeneous networks have become increasingly inadequate. These conventional approaches struggle to capture the rich structural nuances present in HINs, as they often fail to account for the varied and complex connections between different types of data. To address these challenges, methods such as Semantic-Path Nonnegative Matrix Factorization (SPNMF) 17 have been developed. The SPNMF calculates object similarity within HINs using a similarity matrix for clustering and incorporates a reliability matrix to regularize the matrix decomposition process. However, while SPNMF introduces significant advancements, it does not fully adapt to the dynamic structures typical of IoT environments, which are a common context for HINs. Similarly, graph-based methods, such as the GN algorithm 18 and its more efficient variant, the Fast GN algorithm 19 by Newman, prioritize modularity and the optimization of intracluster connections. These algorithms focus on enhancing cluster cohesion and separation but can oversimplify complex intertype relationships. Such simplifications can lead to the loss of the crucial structural insights necessary for a deep understanding of HINs.
Sun combined ranking algorithms with clustering to enhance each iteration. RankClus20–22 integrates clustering with ranking, providing rational cluster results, while NetClus, 23 based on RankClus, treats networks as star-shaped, clustering central objects based on ranking. However, it is limited to star-shaped HINs and requires prior knowledge of representative objects. To address these issues, the ENetClus algorithm 24 was proposed, which considers the relationships between same-type nodes in clustering. PopRank 25 ranks objects in HINs based on knowledge propagation and assigns popularity propagation factors to different connections. In sparse path HINs, link prediction 26 can be used to obtain the effective path information.
Research on IoT data processing is increasingly gaining traction as the heterogeneity and interoperability challenges of IoT data complicate application development and data management. The increasing research on IoT data processing, due to its heterogeneity and interoperation difficulties, utilizes technologies such as linked data 27 and ontologies. 28 Ganzha and others achieved interoperability across multidomain IoT platforms, identifying ontologies useful for cross-domain development. 29 Chen et al. proposed a recommendation model mapping social relations of items in low-dimensional spaces for recommendations. 30 Noura and others designed a semantic framework for automatically extracting key topics from IoT-related literature. 31 Shakya et al. developed an IoT-based ontology model that enhances road safety by harnessing wireless networks for more effective traffic management. 32 Elgazzar et al. examined the integral contribution of IoT to smart city infrastructures, addressing prominent challenges such as security and privacy. 33 Zhuang et al. pioneered the use of a particle swarm optimization algorithm to facilitate the integration of heterogeneous sensor data, thereby improving platform interoperability in the IoT landscape. 34
Recently, the TAP has been widely applied in IoT scenarios, allowing users to edit TAP rules (Recipes) based on their needs. Research on TAP focuses on syntactic analysis and application of Recipes. Research in this area primarily focuses on syntactic analysis and the application of Recipes, with Liu et al. developing a neural network model that translates Recipes into operational programs using natural language constructs, 35 alongside enhancements to user interfaces to simplify Recipe creation. 36 Efforts by Corno et al. 37 and Jiang et al. 38 to annotate Recipes with semantic web technologies and detect rule chains within Recipes have significantly improved user interaction and system capabilities, yet the application of HIN models for extracting structural data from TAP remains underexplored. Meanwhile, notable advancements in HIN clustering methods by El-Kishky et al., 39 Zhao et al., 40 and Liu et al. 41 have addressed personalized recommendation systems and drug–disease interaction predictions within HINs but face challenges with complex, sparse networks and restricted capabilities in harnessing semantic details from meta-paths. These developments underscore the need for more robust methods that can fully exploit the intricate and dynamic relationships within HINs, thus motivating our research to develop a more effective clustering approach that addresses these challenges.
In response to the growing complexity of HINs within the rapidly evolving IoT landscape, this study proposes a novel clustering method, I-RankClus. I-RankClus is designed to model and analyze the intricate structure of IoT data through the lens of a HIN, leveraging the distinctive TAP dataset. This approach significantly advances the field by employing path information within the HIN to refine the network's architecture, thus addressing a critical gap in existing methodologies. The primary objective of this study is to introduce and validate I-RankClus, which overcomes the limitations of existing approaches by utilizing a meta-path-based framework tailored for IoT data. This method aims to enhance clustering accuracy by integrating multiple meta-paths 41 that capture the complex and dynamic relationships between different types of objects within HINs, improve the interpretability of clustering results by leveraging the unique properties of each meta-path, and offer a scalable solution that adapts dynamically to the evolving nature of data and its interactions within IoT environments.
I-RankClus sets itself apart using meta-paths as a structural foundation for calculating the influence of different object types within HINs. By integrating multiple meta-paths, it captures the nuanced structure of HINs more accurately than single meta-path models, thereby significantly enhancing traditional methods. This study further validates this approach through comprehensive experimental tests using the IoT TAP dataset, demonstrating the effectiveness of I-RankClus in clustering and partitioning heterogeneous IoT data into meaningful clusters, thus confirming its potential to profoundly impact the processing and analysis of such data.
Our contributions can be summarized as follows:
Introduction of I-RankClus, a pioneering clustering method tailored for heterogeneous IoT data, which leverages the unique structure of HINs. Implementation of a novel approach that combines multiple meta-paths for influence calculation, providing a comprehensive representation of the network's structure. Extensive experimental validation demonstrating the superior performance of our method in clustering heterogeneous IoT data, marking a significant advancement in the field.
The structure of the remainder of this paper is organized as follows: Methods details the methodology behind I-RankClus, including the theoretical foundation and mechanics of the algorithm. Results presents the experimental setup, data description, and the results of our comprehensive testing, highlighting the effectiveness of the method. Finally, Conclusions discuss the implications of our findings and suggest directions for future research.
Methods
To achieve optimal clustering outcomes and enhance the network structure in the IoT, this section begins by initializing the dataset and constructing a bipartite information network grounded on central-type and attribute-type objects.
Below is a table of key symbols used throughout “Methods” section to help clarify the descriptions of our network model (Table 1):
List of symbols and their descriptions.

Note: This table elucidates the symbols utilized to represent various elements of the bipartite information network structure, facilitating a clearer understanding of the network model described.
We computed the influence of both attribute-type and central-type objects using different meta-paths and integrated these single meta-paths into the influence ranking calculations, enabling us to obtain an influence ranking for the integrated meta-paths that encapsulates rich structural information. This ranking is then leveraged to refine the subsequent clustering efforts, with iterative computations performed until satisfactory cluster results are achieved.
Heterogeneous IoT information networks
Homogeneous information networks often fail to represent the complexities of network structures, prompting researchers to focus on HINs. An example of such a network is shown in Figure 1, which illustrates a HIN comprising three types of entities: conferences (V), authors (A), and papers (P). It includes two types of connections: papers presented at conferences (P-V) and papers authored by authors (A-P).

Structure diagram of a heterogeneous information network.
Concept of HINs: Consider an information network
Concept of dual-type information networks: Given two sets of entity types
Meta-path framework
In HINs, diverse types of entities are interconnected through various linkages. These linkages form pathways, known as meta-paths, which encapsulate distinct structural data of the network and may be depicted as sequences of binary relations between pairs of entities. Within a specified network
Furthermore, Meta-paths are pathways that connect diverse objects, encapsulating their informational relationships.42,43 In HINs, two objects can be linked by multiple meta-paths, each carrying distinct semantics. For instance, within these networks, while both SRS and SCS have attribute type S as their start and end points, the semantics they embody differ: SRS represents a complete process established via a Recipe, whereas SCS denotes a connection between two attributes of type S via the same Channel. In the context of the IFTTT website, Recipes are crafted by users, indicating that the SRS meta-path can signify the impact of user behaviors on the network structure. Conversely, Channels are service interfaces offered by third parties, meaning the SCS meta-path can reflect the influence of external providers on the network's architecture. Recognizing the significance of this influence offers valuable insights, particularly when determining how these connections impact the overall network.
Building on this understanding, our study explores how influence is quantified within a single meta-path. Within these structured paths in a HIN, substantial hidden information can be uncovered, thus aiding the computation of object influence.
44
Drawing inspiration from the PageRank algorithm,
45
which suggests that entities linked to high-influence nodes gain significant influence themselves, our analysis utilizes the PageRank concept to integrate objects connected via meta-paths into our comprehensive influence calculation framework. For instance, within the SRS meta-path, if an attribute-type object establishes a connection with another through a Recipe, the influence of the associated attribute objects is factored into the object's influence score, allowing high-influence objects to directly affect the influence of associated entities. Upon defining a single meta-path P, the influence of attribute-type objects calculated based on meta-path P is denoted by
The equation for 
To calculate the initial influence of attribute-type objects, we used the ratio of the number of meta-paths connected to the object to the total number of meta-paths in the entire network as the object's initial influence. The calculation method is as follows:
However, because some objects in the subgraph have no connecting paths to other objects, using equation 
Influence Calculation Based on the Integration of Multiple Meta-Paths Given the diversity of meta-paths in HINs,
46
relying solely on a single meta-path for calculations can lead to the omission of an object's structural information on other meta-paths, resulting in incomplete information. To avoid this issue, this study employed a linear weighting method
47
to integrate multiple single meta-paths for influence calculation. The equation for calculating the influence based on the integration of multiple meta-paths is represented as:
The magnitude of the path weights reflects the importance of the current meta-path in the calculation of influence, with the sum of all path weights equal to one, that is
When calculating the influence of attribute-type object S, individual meta-paths such as SRS and SCS can be selected for weighted integration SRS + SCS, maintaining the influence exerted by both users and third parties on the calculation. The choice of different path weights
In the selected dataset, a central-type object consists of multiple attribute-type objects. Attribute-type objects S can connect through the meta-paths SRS and SCS, and because of the inclusion relationship between attribute-type objects S and central-type objects C, extending these meta-paths yields the central-type object's meta-paths, CSRSC and CSCSC. Consequently, the integrated meta-path CSRSC + CSCSC can be derived.
Upon constructing a HIN G based on central and attribute-type objects, a matrix M is established to represent the relationships between objects within network G, which is expressed as follows:
To fully integrate the information of the central and attribute-type objects in the calculation of the central object influence, two rules are defined:
Rule 1: The influence of each central-type object is determined by both the quantity and influence of connected attribute-type objects. The greater the number of attribute-type objects connected to the central-type object, the greater is the influence. Similarly, the higher the influence of the attribute-type objects, the greater the influence exerted upon their connected central-type objects: When a central-type object is connected to multiple high-influence attribute-type objects, the attribute-type object weights Rule 2: If a central-type object is connected to other high-influence central-type objects through integrated and meta-path CSRSC + CSCSC, the influence of this central-type object will be enhanced.
According to Rule 2, equation is improved as follows:

When a central-type object connects to other high-influence central-type objects, its influence rises due to these high-influence connections.
For subsequent calculations, the resulting influence is normalized:
Trigger-Action patterns in IoT
The TAP is an application-oriented programming paradigm currently employed in the IoT whereby users can specify objectives using rules, obviating the need for writing complex programming codes. This allows individuals without programming expertise to effectively utilize them. Platforms such as IFTTT 48 and Zapier 6 have demonstrated the viability of TAP, 49 and the data utilized in this study originated from the IFTTT website.
IFTTT supports users in crafting workflows known as Recipes, by exploiting provided service interfaces. Triggers initiate and Actions execute predefined tasks automatically when user-specified Triggers are satisfied. These Triggers and Actions rely on services published by other websites on IFTTT, referred to as Channels. To create a Recipe, a user selects a Channel, chooses a service within to act as the Trigger, and similarly specifies an Action from the Channels available. Users can edit Recipes in natural language, with the Trigger, Action, and Recipe combining to form a complete task.
When creating a task, users must select a Channel to access the necessary services. However, they may not know which Channel contains the required services. Owing to the inherent ambiguity of natural language, search attempts often do not yield satisfactory results. Furthermore, as the number of Channels and similar service offerings increases, query results may become confusing, increasing the cost of search. 50 Consequently, clustering Channels can reduce search costs. All Channels on the IFTTT website are provided by third parties, and manually annotating data is labor-intensive and fails to effectively reflect the network's structural information. Thus, an appropriate clustering method is required to obtain the structural information of the network. This study presents a clustering approach for IoT TAP datasets that can economize network processing and aid in optimizing the network structure.
Research objectives and data model
Following the discussion on the impact of meta-paths in revealing hidden relationships and structures within the network, we elaborate on the specific network structure adopted for our study. This study constructs a bipartite information network structure based on experimental datasets from the IFTTT IoT platform. The defined bipartite network structure G = (V,E,W) categorizes node types into central types and attribute types. The central type is denoted as
Figure 2 illustrates the constructed bipartite network, highlighting the connections between central type objects (Channels) and attribute type objects (Triggers and Actions), which are unified under the Services category. This visual representation clarifies the interaction framework within our bipartite structure, setting the stage for computational analysis that follows.

CS bipartite heterogeneous information network.
Building on this structured network model, we introduced the I-RankClus algorithm through a detailed pseudocode representation. The purpose is to encapsulate our computational framework and outline the algorithmic steps that are essential for executing the proposed meta-path-based clustering method on heterogeneous IoT data networks (Table 2).
Pseudocode for I-RankClus.

This pseudocode outlines the core algorithmic steps undertaken by the I-RankClus method to cluster heterogeneous IoT data. By leveraging the influence scores calculated from the meta-paths, the algorithm effectively partitions the network into meaningful clusters that reflect the complex, underlying structure of the IoT data.
Following the pseudocode, it is crucial to understand the computational demands of the algorithm, especially as the scale of the data increases. The complexity analysis below outlines the time complexity involved in each phase of the algorithm, providing insights into the scalability and efficiency of I-RankClus when applied to large-scale IoT networks:
Ranking Phase: The time complexity for the ranking component is Mixed Model Estimation: This phase involves calculating the conditional probabilities for each link within the clusters, leading to a time complexity of Clustering Adjustment: Calculating the distance between each entity
Combining these components, the overall time complexity of the I-RankClus algorithm across all iterations is
Ranking and clustering methodology
Previous steps computed the influence of attribute-type and central-type objects based on meta-path information, successfully identifying key nodes with substantial influence. This foundation allows for the next phase of our methodology, in which we cluster these influential central-type nodes. Within each cluster, we employ the previously computed influence scores to establish ranking mechanisms—specifically intraclass ranking and conditional ranking. These concepts facilitate a layered analysis of node significance, thereby enhancing the granularity and relevance of our clustering outcomes.
Given the graph 
With the clustering results of the central-type objects established as 

Let
(1) E Step
Introduce the latent variable
We introduce a latent variable z that varies from
The log-likelihood function 
Expanding the joint probability 
Assuming independence between 
Thus, substituting back into the log-likelihood function,
This breaks down further to:
Given that the initial parameter values 
Breaking it down further gives: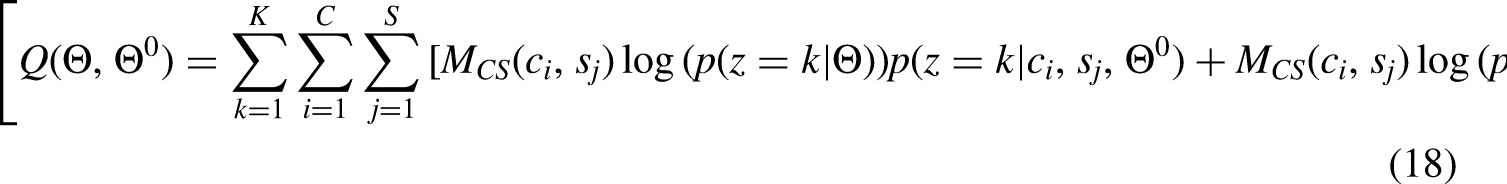
Here, 
With the uniform distribution assumption for 
Substituting back: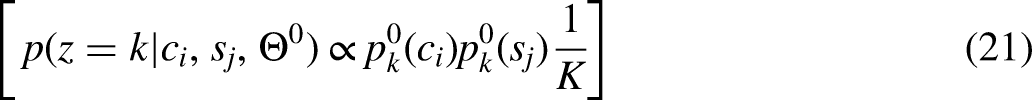
This equation can be interpreted as:
where
(2) M-step
In the M-step of the Expectation-Maximization algorithm, the main objective is to maximize the auxiliary function 
By setting the derivative of the auxiliary function with respect to (p(z = k)) to zero, and rearranging the terms, we arrive at equation 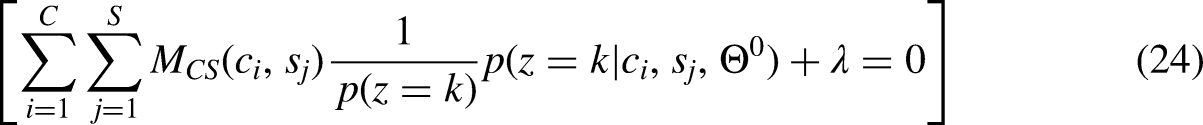
This equation provides a way to iterate toward an optimal value of 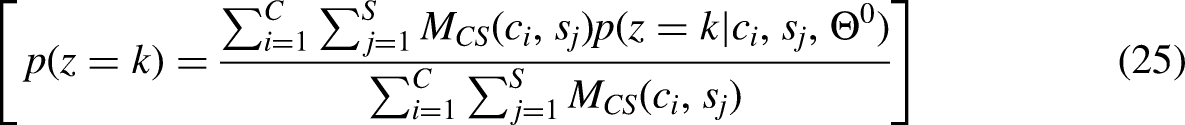
Finally, we applied Bayes’ theorem to calculate the parameter 
The computation process described above is reiterated until the parameter matrix
Following the estimation of parameters 
The cardinality of the 
After calculating these distances, each object c is strategically assigned to the cluster
Results
Experimental dataset
This study employs the publicly available IFTTT (If This Then That) dataset, which captures the TAP from the popular IoT platform, for the enrichment of research in this domain. 53 We invite the scientific community to access and utilize this dataset, available on the official IFTTT website or through research collaborations, to replicate our findings and extend research within this field.
The dataset encompasses 397 central entities, known as Channels, which are service providers, and 1988 attribute entities representing the Triggers and Actions, collectively termed Services. These components constitute a bipartite information network, illustrating the multilateral relationships between Channels and Services—where each Channel can be linked to numerous Services, and each Service is connected to a singular Channel.
Given the expansive nature of the dataset and its representation of complex IoT ecosystems, the experimental scenario focused on the strategic selection of core dataset components for detailed analysis. Recognizing the challenge presented by the sheer volume and varied data quality, approximately 80 of the most influential Channels were selected based on their centrality and prominence within the network. These selected Channels reflect a diverse array of IoT applications and are pivotal in our analysis because of their significant role in the network structure and dynamics. This subset not only depicts the typical functioning of various IoT services but also highlights the intricate interactions that form the backbone of IoT systems. This careful selection enhances the efficacy and clarity of the subsequent clustering analysis, ensuring a focus on the most impactful and informative aspects of the IoT network.
With a structure that mirrors the complex interactions endemic to IoT devices and applications, the dataset delineates the varied IoT services (397 Channels) and specific actionable conditions (1988 Services) within these frameworks. The interplays among Channels and Services are depicted as network edges, encapsulating the specific TAP rules designated by IFTTT's user base.
For our analysis, we initially imported the dataset into a Neo4j graph database54,55 to manage its intricate, interconnected data structure. Figure 3 illustrates the relationships between these entities as constructed in the Neo4j graph database. This system allows each Channel and Service to be articulated as a node, with their interrelations defined as edges. The dataset then underwent preprocessing to validate its quality and coherence by eradicating duplicates or incomplete records.
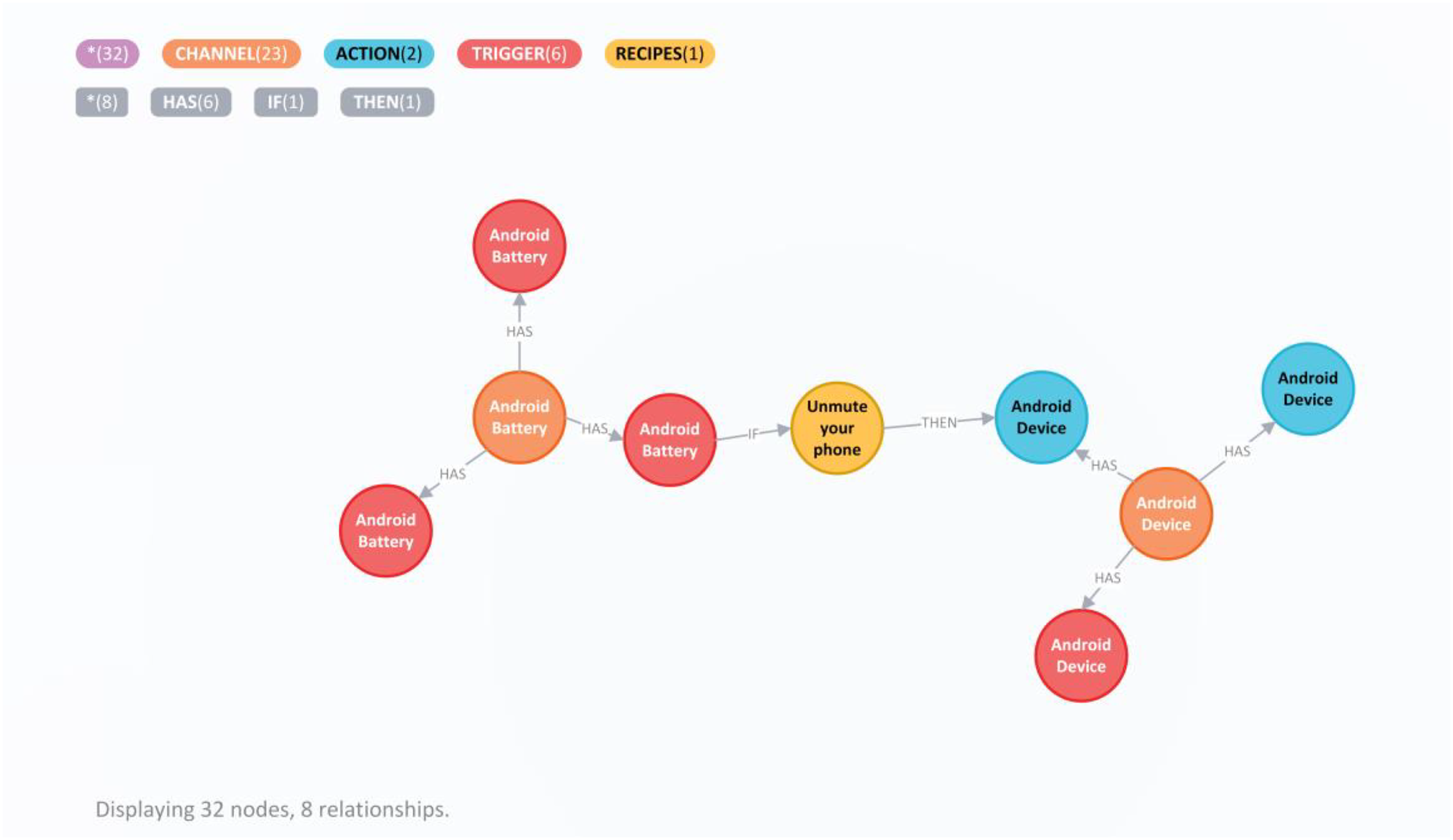
Schematic diagram of IFTTT data storage in Neo4j graph database.
Experimental methodology and data clustering
The objective of this study was to conduct a cluster analysis 56 of central entities. Considering the vast quantity of entities in the dataset and the varying information quality due to certain central entity connections, approximately 80 central entities of higher value were selectively integrated into the dataset to achieve more distinct clustering results. Before delving into the specifics of the I-RankClus clustering method used for this refined dataset, it is pertinent to outline the computational environment that supports our experiments (Table 3).
Experimental setup specifications.

The experimental environment detailed in Table 3 facilitates the processing and analysis of the IoT data. We then utilized the I-RankClus clustering method on the refined dataset. This approach leverages a meta-path-based framework to ascertain the influence scores of nodes, thereby enabling the categorization of Channels and Services into meaningful groups. The process from raw data to final clustering outcomes is illustrated in Figure 4, providing a detailed overview of the transformation of the datasets into a structured graph, evaluation of node influence, and application of the I-RankClus algorithm. The detailed description and availability of the IFTTT dataset highlight the transparency and reproducibility of our research, fostering further advancements in IoT data analysis.
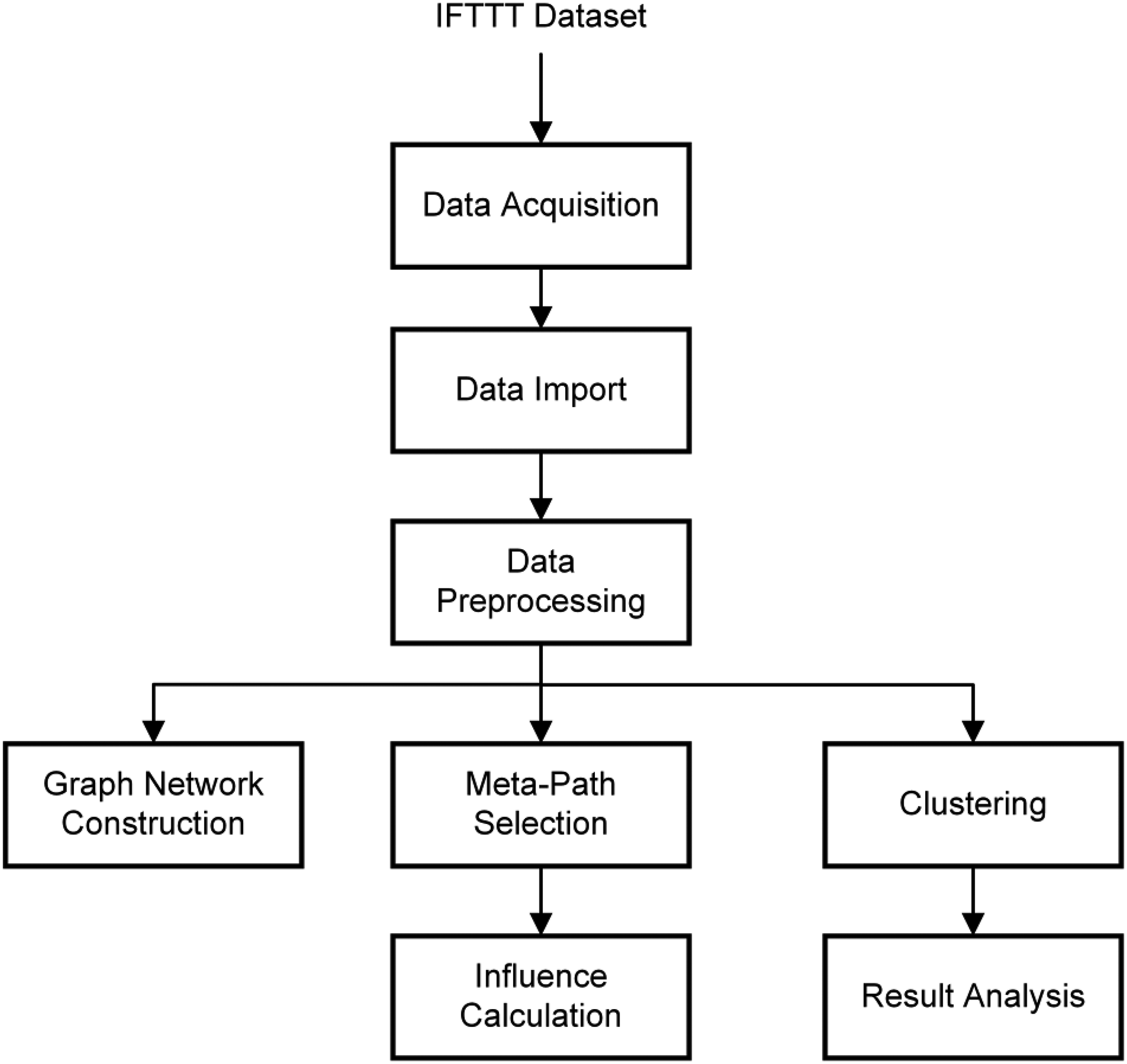
Process diagram of data processing and clustering.
Evaluation of algorithm performance
The evaluation process for the I-RankClus algorithm's performance was conducted in the same computational environment as outlined in Table 3, ensuring consistency across all tests. This structured setup involved experimental trials designed to systematically compare various configurations and settings. These trials included comparisons of different meta-paths (SRS, SCS, and their combination SRS + SCS) and varying path weightings to determine their impact on clustering quality in terms of Compactness (CP) and Separation (SP).
We utilized an established IoT dataset, processed as described previously, and performed multiple runs with each configuration to ensure robustness and variability control in our findings. The effectiveness of each configuration was further examined by altering the weights assigned to individual meta-paths, providing insights into how different information prioritization affects the clustering results, thereby allowing us to optimize the algorithm for better precision and recall.
To evaluate the performance of the algorithm, we employed CP and SP as performance metrics. Compactness represents the average distance from each object within a cluster to the centroid of that cluster; the lower the CP value, the closer the objects are within a cluster, indicating a better clustering quality. The CP value can be deduced using equations (29) and (30):

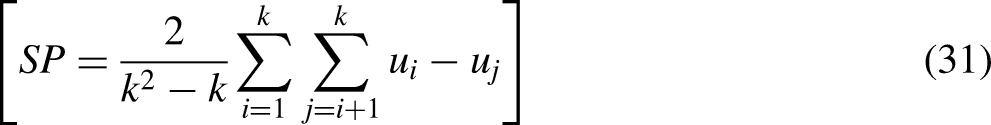
Performance comparison of singular and composite meta-paths.

The data in Table 4 indicate that the SRS meta-path outperforms SCS in clustering efficacy, suggesting that SRS better captures the relationship between objects and incorporates more effective path information. This performance difference implies that user behavior encapsulated by the SRS meta-path offers more pertinent insights into network structures than SCS.
Furthermore, the composite meta-path demonstrates superior performance over the singular meta-paths, achieving the lowest CP value and the highest SP value. These results attest to the ability of the composite meta-path to provide richer information and reflect network structures more effectively.
To investigate the impact of path weighting on the performance of the composite meta-path SRS + SCS, with a total path weight of 1, weights were adjusted in increments of 0.1, resulting in a variety of outcomes as detailed in Table 5, where 1pw and 2pw denote the path weights for SRS and SCS, respectively.
Performance comparison at various path weights for composite meta-paths.

The analysis in Table 5 elucidates that different path weightings distinctly affect clustering outcomes; the best performance is achieved when the weights for SRS and SCS are set to 0.7 and 0.3, respectively. This finding demonstrates that the preponderance of the SRS meta-path within the composite leads to improved clustering results. Conversely, as the weight attributed to an individual meta-path approaches 1, the composite method increasingly resembles the use of a singular meta-path, and the algorithmic performance diminishes.
To compare the accuracy of the clustering algorithms, we introduced the F-Measure metric, calculated as shown in equations (32)–(34):


Comparative performance of various clustering algorithms.

As shown in Table 6, the performance of the I-RankClus algorithm is clearly superior to that of both K-means and DBSCAN in terms of F-Measure and SP values. Despite a slightly lower CP value compared to DBSCAN, it still exceeded that of K-means, indicating the algorithm's superior ability to extract effective structural information from the dataset. Subsequent analysis of the experimental results of the I-RankClus algorithm reveals that selecting diverse meta-paths to compute influence distinctly affects the clustering outcomes. Meta-paths encompassing a broader array of path information consistently surpass those based on a single meta-path. Furthermore, the application of varied path weights to each individual meta-path also notably affected the results. In comparison to other clustering algorithms, I-RankClus has been proven to process datasets with greater efficacy, thereby confirming the validity of the algorithm.
Conclusions
This study introduced the I-RankClus algorithm designed specifically for dual-typed information networks, using integrated meta-paths to enhance the clustering process within the context of the IoT. Our key findings revealed that the integration of diverse meta-paths significantly improves precision and influence transmission in clustering efforts, outperforming conventional techniques such as K-means and DBSCAN, which often fail to fully contextualize the complexities inherent in IoT datasets.
However, this research has several limitations primarily concerning its applicability to static datasets. The dynamic and continuously updating nature of IoT data presents challenges that the current iteration of I-RankClus does not address. This underlines an immediate avenue for future research—to modify and adapt the I-RankClus framework to accommodate real-time data analysis, which is crucial for practical IoT applications.
To further support the I-RankClus algorithm as a robust tool for IoT data handling, future studies should explore the parameter sensitivity of the meta-path integration process to refine its adaptability and effectiveness. Moreover, implementing the algorithm in other IoT application areas, such as smart city infrastructures or healthcare systems, could provide additional insights and potentially open pathways to new clustering methodologies tailored to specific IoT challenges.
Footnotes
Acknowledgements
The authors would like to express my sincere gratitude to OpenAI's ChatGPT for its invaluable assistance in summarizing and refining the related work section in the Introduction of my paper (see Section 1). The insights and language enhancement provided by ChatGPT were instrumental in articulating complex ideas and ensuring clarity of expression. This support was pivotal in enhancing the overall quality of the manuscript.
Author Contribution Statement
Li Lai: software, validation of results, formal analysis, data curation, and review and editing of the manuscript.
All authors have read and agreed to the published version of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program of China, Basic and Applied Basic Research Foundation of Guangdong Province, 2018 Guangzhou Leading Innovation Team Program (China), 2019 Guangdong Special Support Talent Program – Innovation and Entrepreneurship Leading Team (China), (grant number 2021YFB3301702, 2023A1515011712, 201909010006, 2019BT02S593).
Author biographies
Kuo Zhao, PhD, is an Associate Professor at the School of Intelligent Science and Engineering, Jinan University. His primary research areas include blockchain, big data intelligence, cybersecurity, cloud computing, and the Internet of Things. He has published over 100 papers, including more than 30 SCI-indexed papers, and has been cited over 610 times on Google Scholar (as of March 2020). He has led several national and provincial research projects, including those funded by the National Natural Science Foundation and key projects in Jilin Province. As a project leader, he has received a Second Prize in the Jilin Provincial Science and Technology Progress Award. As a key contributor, he has received a First Prize in the Ministry of Education's Science and Technology Progress Award, a First Prize in the Jilin Provincial Science and Technology Progress Award, and a Second Prize in the Seventh National Teaching Achievement Award. He was selected as a Top Innovative Talent in the third batch of Jilin Province and a Leading Talent in the Jilin Province Young and Middle-aged Scientific and Technological Innovation Team. In September 2019, he was invited by the Third Section of the General Office of the Central Committee of the Communist Party of China to submit policy recommendations on “From Blockchain to Distributed Ledger - Challenges and Opportunities.”
Huajian Zhang is an undergraduate student at the School of Intelligent Systems Science and Engineering, Jinan University. His research interests include artificial intelligence, deep learning, big data, and the Internet of Things. He has been involved in four major innovative projects.
Jiaxin Li, born in 2002, is an undergraduate student at the School of Intelligent Systems Science and Engineering, Jinan University. His main research interests include machine learning and computer vision.
Pan Qifu, born in 1998, is a master's degree candidate at the School of Intelligent Systems Science and Engineering, Jinan University. His main research directions include deep learning, machine learning, and large language models.
Li Lai is currently a graduate student majoring in artificial intelligence at Jinan University, Guangdong, China, since 2022. He obtained his bachelor's degree in information management from Jiangxi University of Finance and Economics. His primary research interests include privacy computing and large language models, focusing on the integration of federated learning and blockchain, as well as the theoretical and technical aspects of large language model applications.
Yike Nie is a graduate student at the School of Intelligent Systems Science and Engineering, Jinan University. His main research direction is knowledge graphs. He has participated as a project member in the National Key Research and Development Program and has won the third prize twice in provincial programming competitions.
Zhongfei Zhang, PhD, is affiliated with the School of Management, Jinan University. His publications include many articles in the journals such as Advanced Engineering Informatics, International Journal of Production Research, IET Collaborative Intelligent Manufacturing, Science Progress, Journal of Mechanical Engineering, etc. His research directions include smart manufacturing system management, production logistics synchronized control, and social manufacturing. His projects include: Guangdong Basic and Applied Basic Research Fund Project: Research on Credible Intelligent Synchronized Decision-Making Mechanism and Multi-Objective Optimization Method for “Production-Transportation-Inventory” in Industrial Parks (Project No. 2023A1515011712); National Natural Science Foundation of China (NSFC) Project: Business Meta-space Driven Hyper-cyclic Optimal-state Evolution Method for Distributed Synchronized Manufacturing System (DSMS) (Project No. 52375498); and The Fourth Batch of Xijiang Innovation Team Project in Zhaoqing: Intelligent Rechargeable Stereo Parking Garage Based on the Internet of Things, 2022.1-2024.12.