
Abstract
In modern urban traffic systems, intersection monitoring systems are used to monitor traffic flows and track vehicles by recognizing license plates. However, intersection monitors often produce motion-blurred images because of the rapid movement of cars. If a deep learning network is used for image deblurring, the blurring of the image can be eliminated first, and then the complete vehicle information can be obtained to improve the recognition rate. To restore a dynamic blurred image to a sharp image, this paper proposes a multi-scale modified U-Net image deblurring network using dilated convolution and employs a variable scaling iterative strategy to make the scheme more adaptable to actual blurred images. Multi-scale architecture uses scale changes to learn the characteristics of different scales of images, and the use of dilated convolution can improve the advantages of the receptive field and obtain more information from features without increasing the computational cost. Experimental results are obtained using a synthetic motion-blurred image dataset and a real blurred image dataset for comparison with existing deblurring methods. The experimental results demonstrate that the image deblurring method proposed in this paper has a favorable effect on actual motion-blurred images.
Introduction
In road image surveillance, vehicles are the primary objects that require identification. License plate image recognition helps track vehicles and obtain vehicle owner information. 1 However, a license plate may not be accurately recognized owing to motion blur caused by the rapid movement of the vehicle. If there is a traffic accident or when a vehicle is being tracked, more time and cost will be spent if the image cannot be identified owing to blurring and afterimages. According to the research results of Kupyn et al., 2 image deblurring can improve the success rate of image recognition. If an image deblurring method based on deep learning is used to remove the motion blur of the monitor screen in advance, it can assist in image recognition and analysis, as well as restore information lost due to blurring.
Digital photography often captures defective, low-quality images, which may be caused by inappropriate camera settings or poor camera hardware. Common defects in images are mainly caused by dynamic blurring, which results from static shooting of moving objects or camera-shaking. The image deblurring method defines a blurred image as a convolution calculation using a blur kernel to perform a convolution calculation on a sharp image, which can be expressed as follows:

In research on image deblurring methods, traditional methods reduce the resolution of blurred images and make them clearer through different limitations and different priors.3–6 Fergus et al. 3 used a large number of image statistics to discover the law of image gradient distribution and proposed a mixed Gaussian model to simulate the law of gradient distribution, estimate the blur kernel, and restore the sharp image. Cho and Lee 4 proposed a convolution-like edge prediction method based on the method of Kupyn et al. 2 A shock-wave filter was used to enhance the edges of the image, and the sharpened image was then used to iteratively predict the sharpened edge. Whyte et al. 5 described the dynamics of the camera by using the rotation of the camera and pointed out that the blurred image caused by camera movement is a non-uniform blur; they then proposed a parametric model according to the problem of non-uniform blur. Hu et al. 6 found that it is not possible to estimate the blur kernel for the effective restoration of images in image regions with edge and gradient distribution rules and that the blur kernels obtained using different regions of the image are not consistent. Therefore, an image deblurring method using conditional random fields was proposed to obtain the most effective blur kernel area and to use a reasonable image area to estimate the blur kernel for deblurring.
Researchers have introduced learning-based methods for complex natural blurring. Sun et al. 7 proposed a patch enhancement method to collect clear patches with features similar to those of blurred images by learning a large number of clear images. They used these patches to replace the edges in the blurred image and then estimated the blur kernel with these edge-enhanced images to obtain a clear image. Xu et al. 8 combined traditional image optimization methods with deep convolutional neural networks (CNNs) to design a separable network structure. This network was divided into two main parts: a deconvolution network and noise reduction network. The deconvolution network extracts features and restores sharp images using a noise reduction network. Because there is no need to perform image preprocessing, end-to-end image deblurring is achieved. Isola et al. 9 and Zhu et al. 10 chose image-to-image conversion while ignoring the estimated blur kernel. The former requires multiple sets of image pairs corresponding to the sketch image and the target-generated image as a training dataset, while the latter does not require corresponding image pairs; it needs to collect a large number of target images with objects similar to the input image as a style-transformed training dataset.
Methodology
In this section, the research theory and framework of this study are presented.
U-Net
Encoder–decoder networks are frequently used in computer vision and have achieved good results in image deblurring methods. This network is a CNN architecture designed symmetrically with an encoder and a decoder. 11 The encoder downsamples the input image into a feature map with more channels and a smaller size while extracting shallow features with rich details, while the decoder upsamples the smaller sized feature map into a larger sized feature map with fewer channels and extracts deeper features. Ronneberger et al. 12 added a skip connection between the encoder and decoder networks, also known as a residual connection, whose main function is feature fusion. As the network becomes deeper, the downsampling process loses a significant amount of feature information. To ensure that the final feature map has sufficiently detailed information, the feature map extracted by encoder downsampling skips the multilayer network and directly connects with the decoder correspondence. The feature maps obtained by the corresponding decoder upsampling are fused with shallow and deep features that retain more detail. As the network structure drawing is similar to a U-shape, it is called a U-Net, as shown in Figure 1. The blue, gray, red, and green arrows represent the image convolution calculation, skip connection, max pooling, and deconvolution, respectively. The U-Net downsampling method adopts the max pooling method, which divides the image into several 2 × 2 rectangular areas, outputs the maximum value for each area, and reduces the amount of image data while retaining important information.

U-Net architecture. 12 .
Tao et al. 13 proposed the use of a residual block (ResBlock) 14 combined with the encoder–decoder network U-Net architecture, as shown in Figure 2, where conv is the convolutional layer and ReLU (Rectified Linear Unit) 15 is the activation function. ResBlock deepens the network and avoids the vanishing gradient problem. Deep features have a larger receptive field, which helps to solve the problem of dynamic blurring.

Structure of ResBlock. 13 .
Multi-scale architecture
Multi-scale architectures are widely used in deblurring research. Nah et al. 14 proposed a deep multi-scale convolutional neural network (MSCNN), as shown in Figure 3, for dynamic scenes in which the scale ranges from large to small. A Gaussian pyramid was used to process image scale changes, and the model used multiple ResBlocks to deepen the network in the series network architecture. However, this multi-scale architecture model is excessively large, which increases the difficulty of training and prediction. Kupyn et al. 16 proposed a faster and more efficient generative adversarial network (GAN) based on DeblurGAN1, which uses a feature pyramid network in the generator part. 17 The input images were directly processed by the generator for multi-scale operations in the GAN, which significantly reduced the operation time and model size.

Structure of MSCNN. 14 MSCNN: multi-scale convolutional neural network.
The aforementioned image deblurring methods are fixed multi-scale architectures for both training and prediction. Ye et al. 18 considered that the effect of deblurring was slightly inadequate for these fixed multi-scale architectures in naturally blurred images. Therefore, they proposed a scale-iterative upscaling network (SIUN) that could adjust the scale structure and number of iterations according to the degree of image blurring, as shown in Figure 4. SIUN uses U-Net with a residual dense network (RDN). 19 An RDN is a network that helps improve image resolution and allows the model to recover more details in the image.
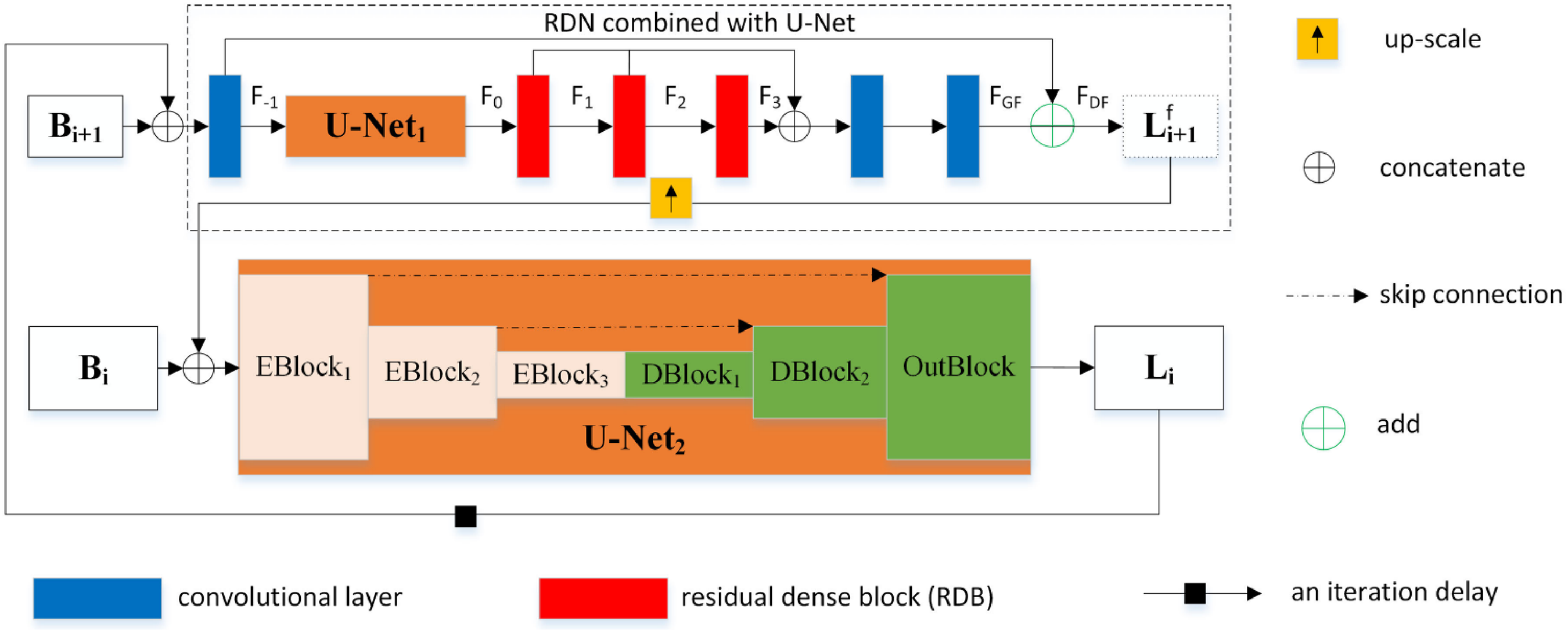
Network architecture of raise the scale and iterate. 17 .
The general multi-scale deblurring method involves inputting an image into the model, upsampling the deblurred image, and then inputting it to the next scale to continue the operation. This training method can only achieve single learning on a single scale, whereas Ye et al. 18 considered a scale as a scale iteration. The input image was first passed through the U-Net1 model combined with a residual dense block and upsampled to increase the scale. The upsampled image was then input into U-Net2 to obtain a scale iteration for a deblurred image. The SIUN training method can deepen the network compared with other fixed multi-scale architectures. The results show that the best model can be trained using three-scale iterations, and the best deblurring results can be obtained using four-scale iterations during the prediction. Compared with the previous fixed multi-scale architecture, a moderate-scale iteration strategy is more adaptable to naturally blurred scenes from different scenes, as used for training and prediction.
Dilated convolution
Dilated convolution is also called atrous convolution, which originated in the field of image segmentation.
20
Dilated convolution can expand the receptive field without losing features and can obtain more information from images or feature maps without increasing the computational burden. The receptive field refers to the area within the input space that is influenced by a specific feature of a CNN. More informally, it is the part of a tensor that after convolution results in a feature. The dilation rate was used to control the number of holes inserted between adjacent pixels in the convolution kernel. The area of the dilated convolution kernel is calculated as follows:


Schematic diagram of the convolution kernel of dilated convolution. (a) r = 1, (b) r = 2, and (c) r = 3.
Although dilated convolution can ensure a larger receptive field with the same parameters, it is not suitable for small objects in an image, because such a large receptive field is not required. In addition, it can be shown that the pixels of the convolution kernel that are calculated are not continuous. If several dilated convolution layers are used, certain pixels in the feature map may not participate in the calculation. This potential problem is known as the gridding effect. To solve these problems, Wang et al. 21 proposed hybrid dilated convolution (HDC). The HDC model uses mixes of several convolutions with different dilation rates, and the receptive field covers all areas to avoid holes. Figure 6(a) shows the grid effect when all the convolutional layers use a dilation rate r = 2, and Figure 6(b) shows the receptive field when using the dilation rate r = [1, 2, 3] for the convolutional layer.

Schematic diagram of dilated convolution. 21 (a) The grid effect when all the convolutional layers use a dilation rate r = 2. (b) The receptive field when using the dilation rate r = [1,2,3].
Network Architecture
This section considers the image deblurring preprocessing of an intersection monitor, which mainly aims to deblur a naturally blurred image, pre-eliminate the dynamic mode caused by the rapid movement of the vehicle, and restore the blurred graphics to a sharp image to improve image recognition accuracy.
Because there are usually only blurred images and the blur kernels are unknown, they are blind deconvolution problems. We propose a model that uses dilated convolution combined with U-Net to improve the effect of removing motion blur. The model is also combined with a multi-scale architecture, which refers to the SIUN architecture of Ye et al. 18 The image deblurring network architecture is illustrated in Figure 7.

The architecture diagram image deblurring network that uses dilated convolution combined with a U-Net to improve the effect of removing motion blur.
Upscaling iterative strategy
This subsection addresses the scaled-up iterative network architecture proposed by Ye et al.
18
to restore sharp images using iterative scale-up. To simplify the network model, the scale iteration is divided into upper and lower parts, such as the
Because the network model setting must splice two images of the same scale as the input, the blurred and deblurred images were spliced into an image with six channels. With input to the network for the first time, we did not have the same scale deblurred image of blurred image


We set I as the number of scale iterations
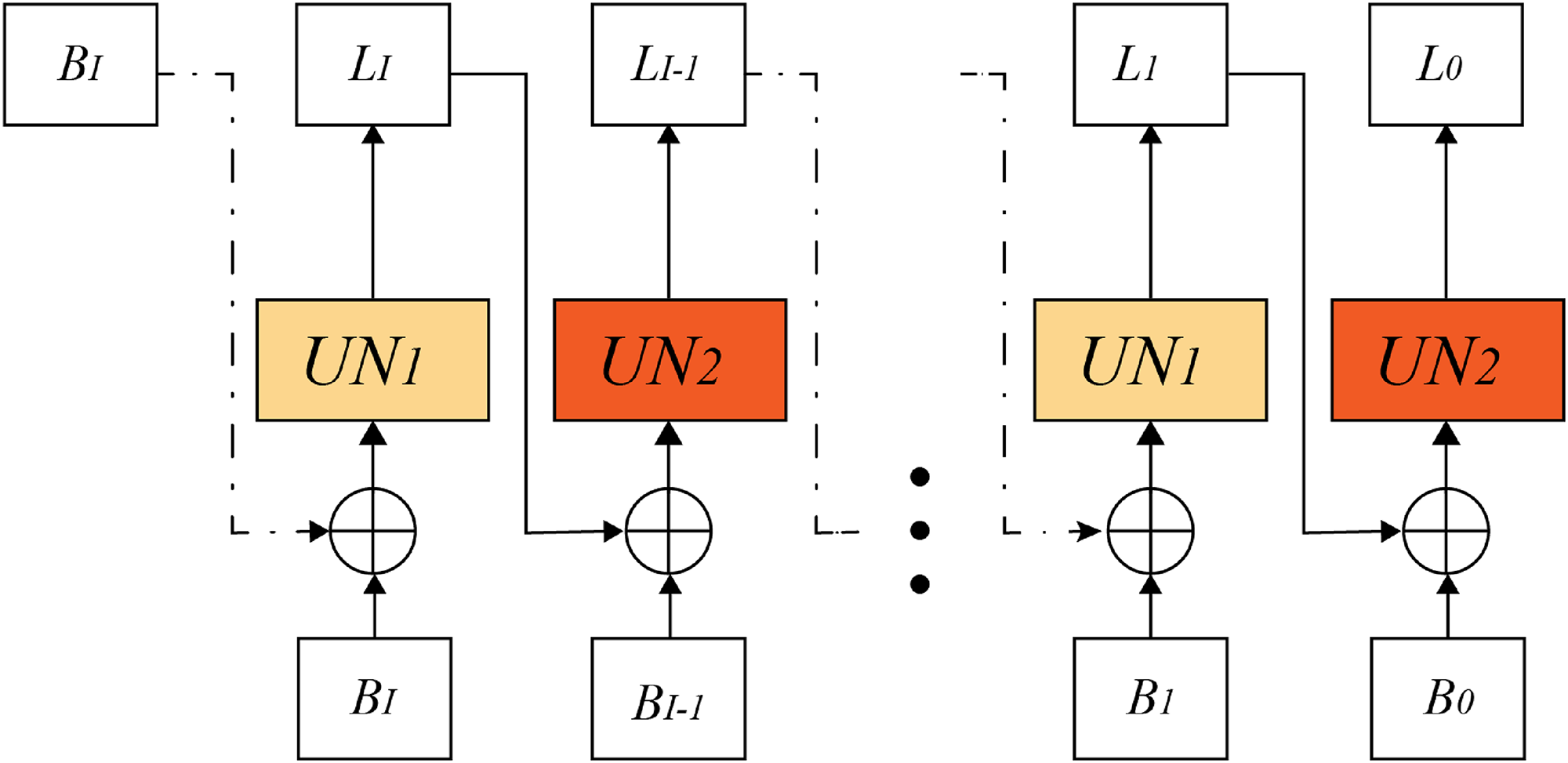
Schematic diagram of iterative design for scale-up.
U-Net with dilated convolution
Encoder–decoder networks are often used in deep learning image deblurring methods. Ronneberger et al.
12
proposed a U-Net with skip connections between the corresponding encoder and decoder. Tao et al.
22
added ResBlock
14
to U-Net to increase the network model depth. This study primarily refers to the U-Net used in the study of Ronneberger et al.
12
and improves on it. As shown in Figure 7, this study replaces all ReLU activation functions used in ResBlock, E-Block, and D-Block with LeakyReLU.15,23 In the encoder, a convolutional layer with a stride of 2 was selected for downsampling, and the feature map after each downsampling increases by twice the number of channels. For example, if the input image is w × h × c, then after an E-Block, it becomes a feature map of
This study uses a dilated convolution combined with a U-Net. Dilated convolution is used only in the encoder. The main purpose of this design is to capture more features at different scales and enhance feature extraction without increasing the number of additional parameters. Because dilated convolution inserts several holes into the convolution kernel according to the dilation rate, it may cause grid effects on the special map after several convolutions. To solve this problem, the HDC proposed by Wang et al. 21 is used to design a dilated convolution block (DilateBlock) with a dilation rate of r = [1, 2, 3], which consists of convolutional layers with dilation rates of 1, 2, and 3 in sequence. The dilated block uses a skip connection for feature fusion and splices the feature map output by each convolutional layer on the channel, as shown in Figure 9.

Dilated block design scheme.
Loss function
In the multi-scale image deblurring networks investigated by Nah et al.
14
and Tao et al.,
22
the loss between the output image and target image of each scale was added to the weight and calculated. In contrast to these methods, this study mainly refers to the lifting-scale iteration architecture proposed by Ye et al.,
18
in which one scale iteration is regarded as an independent deblurring subtask; it still has an effect even though the training process ends at any iteration. Therefore, only the difference between the final deblurred image and target image is calculated, and the mean absolute error (MAE) is selected as the loss function. The MAE is also called

Image dataset
The image deblurring networks used in this study were trained using the GoPro 14 dataset, and the GoPro and Lai 24 datasets were used for the prediction and comparison of the deblurring results.
Synthetic image dataset. For related image deblurring methods, the most commonly used synthetic GoPro dataset uses the GoPro Hero4 Black action camera to shoot 240 FPS of video and then uses the average number of consecutive frame rates to produce blurred images of varying intensities. The dataset consisted of 3214 pairs of clear and blurred images with a resolution of 1280 × 720 pixels. The training set consisted of 2103 image pairs, and the prediction set consisted of 1111 image pairs.
Real image dataset. The research motivation for this study was the deblurring of intersection monitor images. Predicted images must be obtained from blurred scenes. Therefore, the Lai dataset was selected to evaluate the naturally blurred images. This dataset contains 100 naturally blurred images obtained from Flickr, Google, previous literature, or photos taken by Lai et al. For these images to be suitable for most image deblurring algorithms, the image size must be less than 1200 pixels.
Experimental results and discussion
In this study, the deblurred and original sharp images were evaluated using the peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) of the image standards. The root-mean square error (RMSE), which measures the mean squared difference between the predicted and actual observed values, is given by







Dilated convolution combined with U-Net experiment
Next, for the architecture of dilated convolution combined with U-Net, two experiments were designed: “dilation rate strategy of mixed dilated convolution” and “network model of dilated convolution combined with U-Net,” to study how to design an image suitable for image multi-scale dilated U-Net for deblurring. The following experiments were based on the GoPro dataset 14 for training and testing. The PSNR in the table comparing the deblurring results is the average value, and the value with the best result is in bold.
Dilation rate strategy of mixed dilated convolution. The largest scale of the input image was 128 × 128 and the smallest was 32 × 32 for the image pyramid in the training network. The network model needs to adapt to the different scales of images at the same time, so that the dilation rate of the convolutional layer needs to be adjusted according to the image scale setting. To test and determine which type of DilateBlock combined with U-Net is more suitable for image deblurring, we used HDC to design DilateBlock and four different dilation rate strategies of
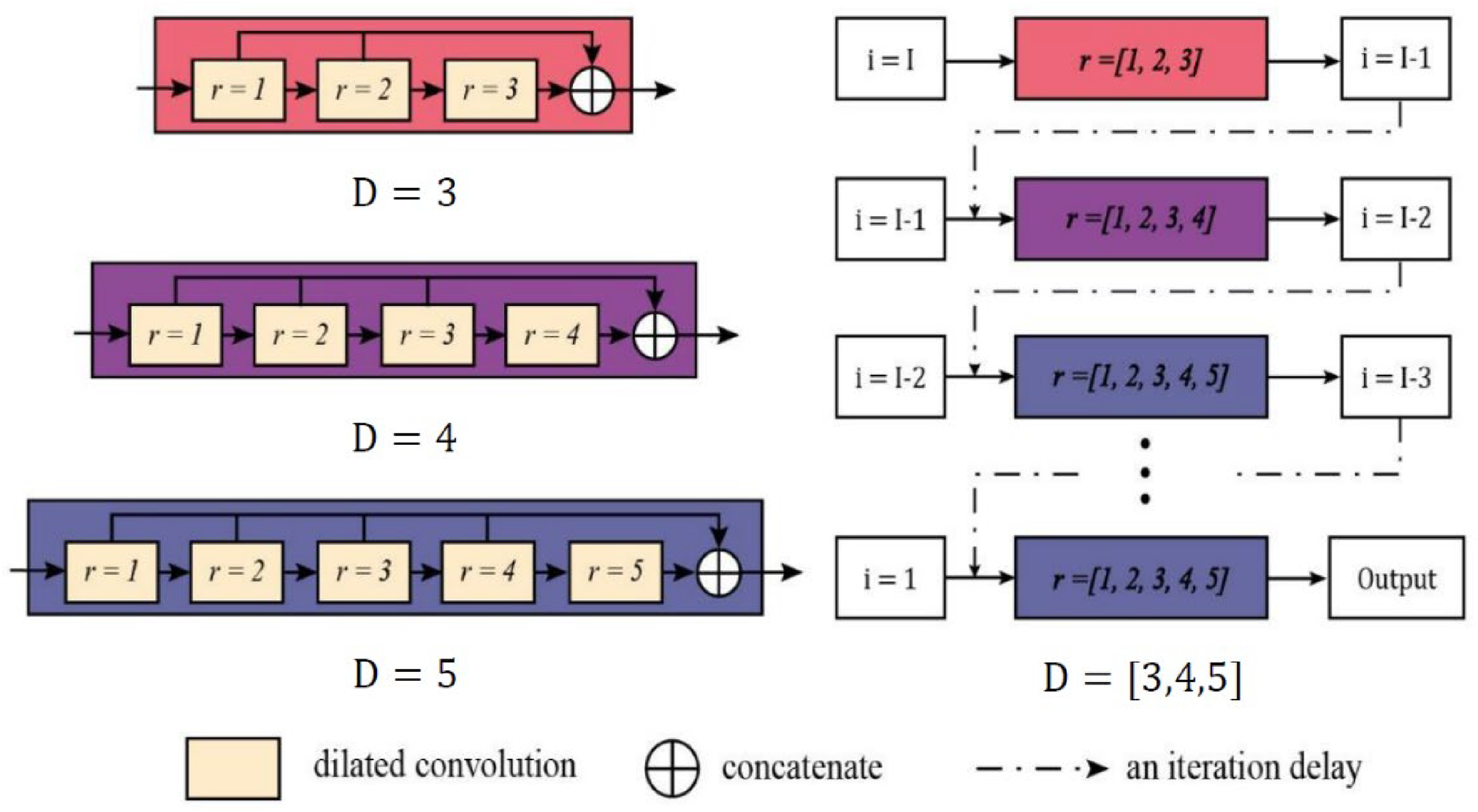
Schematic diagram of dilated convolution strategy.
As displayed in Table 1, using the pure dilation rate strategy, D = 3, to obtain the highest PSNR value of 30.05 dB and SSIM value of 0.869 is a more suitable dilation rate strategy for image deblurring.
Comparison of experimental results of dilation rate strategy.

PSNR: peak signal-to-noise ratio; SSIM: structural similarity index measure.
Bold text indicates that its data is better than other data.
Network model experiment of dilated convolution combined with U-Net. According to the experimental results of the “Dilation rate strategy of mixed dilated convolution,” we have obtained a better dilation rate strategy, which is the pure dilation rate strategy D = 3 with one DilateBlock used to join U-Net. Dilated convolution can enhance feature extraction without adding additional parameters. We consider adding more dilated blocks to the U-Net; therefore, according to the architecture used in the experiment (dilution rate strategy of mixed dilated convolution), this experiment proposes four dilated U-Net strategies for comparison and determines a model of dilated convolution combined with a U-Net that is more suitable for deblurring methods.
The basic network architecture of this experiment is to add a dilated block with a pure dilation rate strategy of D = 3 to U-Net. Because the purpose of adding a dilated convolution is to strengthen the feature extraction of the coding, a dilated block is inserted before an E-Block. There are two U-Net models used in the network model, which are referred to as U-Net1 and U-Net2, respectively. The following are the proposed four dilated U-Net strategies, and the network model diagram of these strategies is shown in Figure 11.
A dilated block is added before the first E-Block of U-Net1 and U-Net2. A dilated block is added before and after the first blocks of U-Net1 and U-Net2. A dilated block is added before and after the first E-Block of U-Net1, and a dilated block is added before the first E-Block of U-Net2. A dilated block is added before all blocks of U-Net1, and a dilated block is added before the first E-Block of U-Net2.
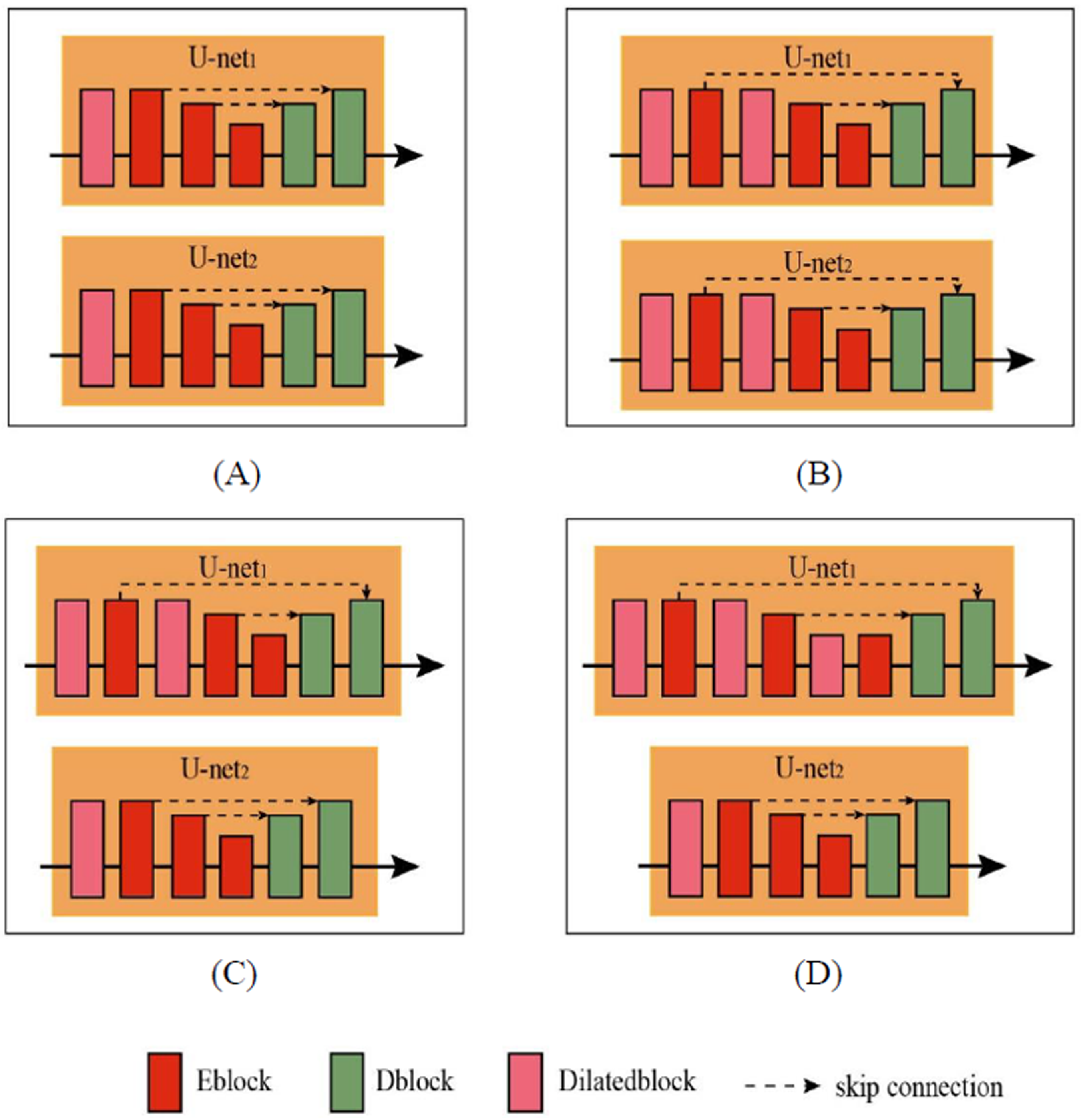
Schematic diagram of the network model of dilated convolution combined with U-Net.
It can be observed from Table 2 that Strategy C yields the highest PSNR value of 30.45 dB and SSIM value of 0.918, which is a more suitable image deblurring network.
Comparison of experimental results of a network model of dilated convolution combined with U-Net.
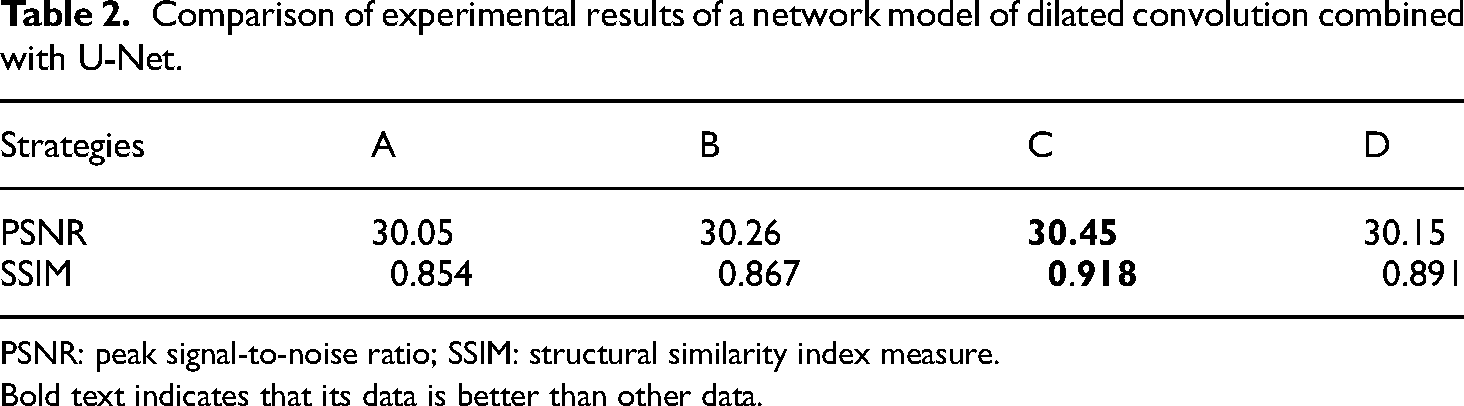
PSNR: peak signal-to-noise ratio; SSIM: structural similarity index measure.
Bold text indicates that its data is better than other data.
Experimental results of model test
The network models were trained and tested using the Keras library based on the TensorFlow learning framework, and implemented on a computer with an Intel Core i7-8700 CPU, an NVIDIA GeForce RTX 2070 GPU, and 16 GB of RAM. By training 2000 epochs using Adam optimization, the learning rate scheduler was 1e−4, 3e−5, 5e−6, and 1e−6, and the learning rate was updated according to the loss at the moment of training.
Although Ye et al. 18 and Tao et al. 22 have provided the weights that were trained, these weights are retrained by the computer used in this study for testing. In their published papers, Ye et al. 18 and Tao et al. 22 showed that the deblurring results on the GoPro dataset were PSNR values of 30.22 and 30.26 dB, respectively.
Test data using artificially blurred images
This study compares our network model with recent deep learning-based image deblurring methods and uses the recognized artificial synthetic blur GoPro dataset 14 for testing. The PSNR, SSIM, and time values in Table 3 are the average (avg) and standard (std) values, and the values with the best results are in bold. It can be seen from Table 3 that in the deblurring results of the artificially synthesized blurred images, the proposed method obtains a PSNR of 30.45 dB(avg) and SSIM value of 0.918(avg), and the deblurring effect has a better performance compared with other methods. The following analyzes the differences between this study and other methods through a deblurred image comparison chart, as shown in Figures 12–14.



Comparison of deblurring results of GoPro dataset.

PSNR: peak signal-to-noise ratio; SSIM: structural similarity index measure.
Bold text indicates that its data is better than other data.
In Figure 12, the blurred image of the car advertising billboard, numbers, and text cannot be recognized because of dynamic blurring. After comparing our method with other deblurring methods, the edges of the numbers in the image obtained were clearer, which is helpful for the identification of information on advertising billboards.
This study is expected to be applied to the image deblurring of intersection monitors. From the image in Figure 13, it can be seen that the numbers on the license plate in the original image are blurred owing to dynamic blur, and it is almost impossible to distinguish them clearly. The deblurring results of our method restore the numbers on the license plate to a degree that can be viewed directly, which is better than the other methods of restoring numbers.
In the blurred image shown in Figure 14, ringing is generated owing to dynamic blurring. Taking the feet shown in the figure as an example, the deblurring results of the other methods still exhibit ripples and edge distortion. The deblurring method used in this study almost completely suppresses these phenomena and is closer to the original sharp image than the other deblurred images.
Test data with naturally blurred images
The research goal of this study is to help intersection monitor images deblur, and the predicted blurred image comes from a real blurred scene. To test whether the network model in this study can adapt to natural blurring, the recognized Lai dataset 24 was used to carry out testing. Because these images originated from real blurred scenes, there are no correct and sharp images; the difference cannot be calculated, and the resulting images were evaluated. We can only examine the image deblurring results with the naked eye. Compared with the other methods, the method proposed in this paper is more effective for the removal of natural motion blur, and the deblurring results of naturally blurred images are shown in Figures 15–17.



Figure 15 shows a naturally blurred image captured in a dark indoor scene. Under conditions of insufficient light, the facial features of the blurred images become blurred and unclear. Although the method proposed by Kupyn et al. 16 has a good deblurring effect on human faces, the edges of the facial features are not sufficiently sharp. The glass mouth also appears as ripple waves, making the image blurry. Our method achieves better edge restoration.
The blurred image in Figure 16 produces afterimages owing to dynamic blurring. Almost all other deblurring methods sharpen the afterimages of blurry images, making the text appear more blurred. Although the method used in this study cannot completely restore a sharp image, it effectively removes most afterimages.
After comparing the deblurring results in Figure 17, it was found that although some methods can make the text clearer, edge distortion still occurs. Compared with other methods, the deblurring results in this study can moderately suppress afterimages.
Conclusion
In the related literature on deep learning for deblurring motion-blurred images, the use of multi-scale architecture uses scale changes to learn the characteristics of different scales of images. The scale recurrent network can share network weights at different scales to reduce the number of parameters and make full use of the feature information. The multi-scale number of iterations can be adjusted according to the variety of blurred images, as compared with other fixed multi-scale architectures.
The multi-scale modified U-Net using the dilated convolution deblurring method proposed in this study was compared with other image deblurring methods. The PSNR was 30.45 dB in the test of artificial synthetic blurred data using our method, and the deblurring effect was better than that of other performance methods. The results show that our method can effectively suppress damage to afterimages and ripple problems. Although the experiment of the natural blur dataset test could not obtain a numerical evaluation, according to the results of the naked-eye observation, it was found that our network model can adapt to naturally blurred images, especially blurred text and images with insufficient light, and can obtain better deblurring results.
Footnotes
Acknowledgements
The authors thank the anonymous referees for their helpful comments and suggestions.
Authors’ contributions
Xiao-Pei Shi and Song-Yih Lin were responsible for the conception and design, acquisition of data, analysis, and interpretation of data, drafting the initial manuscript and revising it critically for important intellectual content. Min-Lang Yang was responsible for the conception and design, and interpretation of data and reviewing all drafts of the manuscript. Chung-Chi Huang and Jen-Chun Lee were responsible for the experiments of the manuscript. All authors read and approved the final manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Author biography
Jen-Chun Lee is the professor and vice president of Maritime College at National Kaohsiung University of Science and Technology.