
Abstract
The objective of this work is to address the problem of detecting track intruders in railway systems using deep learning-based algorithms. Unauthorized entry onto railway tracks poses a significant risk of collisions between trains and humans. However, intrusion discrimination algorithms often suffer from a lack of learning data and data imbalance issues. To overcome these challenges, this research proposes an algorithm that combines generative models and classification networks. Generative models are utilized to generate synthetic intrusion data by learning the underlying distribution of available data and creating new samples resembling the original data. The augmented intrusion data is then used to train deep neural networks to accurately identify intrusions. The proposed algorithm is evaluated using real data sets, demonstrating its effectiveness in overcoming limited learning data and data imbalance issues. By augmenting intrusion data using generative models, the algorithm achieves improved accuracy compared to traditional approaches. In conclusion, the algorithm presented in this work provides a solution for detecting track intruders in railway systems. By leveraging generative models to augment limited intrusion data and utilizing classification networks for intrusion discrimination, the algorithm demonstrates improved performance in accurately identifying intrusions. This research highlights the potential of deep learning-based approaches in enhancing railway safety and recommends further exploration and application of these methods in real-world settings.
Introduction
Tracks are important parts of the railway infrastructure and the prime locations where collisions occur between trains and humans. Entry of unauthorized people onto the tracks can lead to a major accident involving their collision with a train. Damage to railway infrastructure by intruders is also possible. To prepare for such dangerous situations, urban railway institutions use real-time intruder-detection system that includes cameras installed on platforms. Recently, studies have been conducted to improve the accuracy and processing speed of these systems by applying deep learning-based algorithms.1–5
Artificial intelligence (AI) is a system in which computers infer, learn, and judge on their own by learning the rules and patterns of data. Therefore, it is essential for deep learning-based models, a type of AI technology, to secure a sufficient amount of data to achieve satisfactory performance. Therefore, in recent deep learning studies, methods for increasing the amount of learning data using data augmentation have been investigated.6,7 Methods for increasing the amount of data while maintaining its quality using a generative model are being studied. The generation model is a deep learning-based algorithm that generates data similar to the original data by learning, such that the input and output data are in the same dimension. These models have the advantage of generating data similar to real data. In addition, research is being conducted to design models to control data generation.8–12 As the use of these models can increase the quality and diversity of the generated data, research is being conducted to augment the data and improve the performance of algorithms in various fields.
The data required in this study consisted of images of people not on the track (normal state) and images of people invading the track (intruder state). Normal-state images are easy to acquire; however, the collection of intrusion-state images has several difficulties such as train suspension and other safety problems. Therefore, in this study, we propose a deep learning-based generation model that augments a small number of track-intrusion images that are difficult to secure. The proposed generation model can control the intruder data in various positions, thereby increasing the diversity of the learning data. When implementing an AI-based intrusion discrimination algorithm, the problem of performance degradation caused by a lack of learning data and an imbalance between the normal- and intrusion-state data can be solved using the proposed method.
The remainder of this article is organized as follows. The “Intrusion detection system” section describes the networks used to determine and track intrusion. The “Generative model-based data augmentation” section provides an overview of the data and generation models used to augment the training data. In the “Experimental results” section, the proposed scheme is applied to actual image data, and its effectiveness is demonstrated by comparing it with various neural networks. Finally, the conclusions are presented in the “Conclusions” section.
Intrusion detection system
Track intrusion detection
With the development of AI-based image recognition technology, the demand for risk detection systems using images is increasing, and research is actively conducted to detect intrusion using deep learning. The development of the railway industry and the significant increase in the number of tracks and users increased the demand for railway safety. To ensure the safety of railway passengers, various camera installations are being implemented on railway vehicles and platforms. These installations aim to enhance surveillance and monitoring capabilities, providing a means to detect and respond to potential safety hazards more effectively. Therefore, there has been significant research conducted on deep learning algorithms for detecting arbitrary intrusions in restricted areas of railway facilities.1–5 These algorithms utilize advanced computer vision techniques to analyze real-time video footage and identify potential security breaches. By employing deep neural networks, these algorithms can effectively recognize and classify various objects and activities, enabling the detection of unauthorized individuals entering restricted zones. In Cao et al., 1 a lightweight neural network is utilized, while Guo et al. 2 employed an SSD network to detect objects trespassing in prohibited areas of railway facilities. Furthermore, Pan et al. 3 explored the application of convolutional neural networks and multi-task learning techniques for this purpose. In Kapoor et al., 4 faster R-CNN is used as a detection method. Additionally, Chen et al. 5 proposed an algorithm that utilizes a two-stage network, initially recognizing railway tracks and subsequently detecting objects. However, most AI-based intrusion detection studies use object detection. Object detection aims to locate an object in an input image and output its coordinates. Therefore, to find a track intruder using object detection, it is necessary to determine whether the location of the identified person belongs to a track or a platform. In this study, we used a classifier instead of object detection to detect intruders without these additional modules. Classification is a task that aims to infer where the input image belongs among the specified classes; in this study, a classifier is learned to output which state is intrusion or normal. The classifier can predict the intrusion state by learning to comprehensively determine the area division of the track and platform, in addition to the location of the person.
Intrusion discrimination network
In this study, ResNet, 13 EfficientNet, 14 MobileNet,15–17 Vision Transformer, 18 and multi-layer perceptron (MLP) Mixer 19 were used as classifiers to determine intrusion. Research on the initial deep learning network structure is focused on improving the performance by deepening the layers. However, the deeper the layer, the smaller the effect of backpropagation, resulting in gradient vanishing, eventually reducing the overall performance. To overcome this problem, a residual block using a skip connection with ResNet, as shown in Figure 1, is proposed.

ResNet.
The residual block combines several layers into a single step and adds an input value to the output value. Thus, when calculating backpropagation, at least one value is output, even after differentiation, thus solving the gradient vanishing problem. 13
Methods for increasing the network size to increase the accuracy of the classifier have also been studied. The accuracy is improved with a larger width, larger height, and better resolution of the input image. However, several other parameters should be considered. A study using EfficientNet 14 confirmed that increasing the width, height, and resolution of the input image contributes to performance improvement and proposed an efficient model that could determine the optimal combination between the accuracy and computation time of the model using compound scaling (Figure 2), which simultaneously adjusts these three parameters.

EfficientNet.
MobileNet15–17 is a network created by Google for use in mobile devices; it has a low computational time and high performance. As shown in Figure 3, a study on MobileNetV1 was the first to propose a depthwise separable convolution, which involved a convolution operation for each channel of images; its calculation was 8 to 9 times faster. A study with MobileNetV2 proposed a linear bottleneck using projection layers to express high-dimensional information in low dimensions. Another study used MobileNetV3 with neural architecture search (NAS) to optimize the structure of the model and improve its accuracy.

MobileNetV1.
A vision transformer (ViT) 18 applies a transformer, which has become a standard for realizing good performance in the natural language processing field, to problems in the image processing and image understanding fields. ViT does not use convolution; therefore, it has a small number of parameters but shows results similar to those of conventional neural networks (CNNs). As shown in Figure 4, ViT divides the input image into patch units and renders each patch one-dimensional. Subsequently, class token and position embedding, which indicate the location of the patch in the input image, are added to the transformer encoder. The transformer encoder includes layer normalization, attention, and an MLP to extract the features.

Vision transformer.
The MLP-Mixer 19 is a model that uses only simple perceptron layers and not convolution and attention layers. In an MLP-Mixer, an image is divided into patches to form a new matrix. This matrix is transposed, as shown in Figure 5, and the operation is performed in both the lateral and column directions through the layer, repeating the process of passing through the MLP. Through this process, an operation similar to convolution without convolution is performed, and results similar to those of ViT are obtained.

Mixer layer of multi-layer perceptron (MLP)-Mixer.
Generative model-based data augmentation
The rapid development of deep learning-based algorithms enabled the solving of problems that were difficult to solve in many industries. As AI systems optimize algorithms based on data, they require a sufficient quantity of high-quality data. However, it is often difficult to obtain sufficient data. Recently, several studies have focused on data augmentation technology using generative models to solve the data-shortage problem. Further, studies have been reported to improve performance by increasing the amount of learning data of AI systems by generating difficult-to-collect data, such as data for liver lesion diagnosis, 9 three-dimensional face landmark data, 10 CT image data 11 of COVID-19 patients, and car driving image data. 12 Therefore, in this study, data were augmented using a generative model to solve the performance degradation caused by the limited collection of railway track intrusion image data.
The data used in this study include images of the track and platform as shown in Figure 6. The generation model outputs data with the same dimensions as the probability distribution of the input data but with different values. The generative adversarial network (GAN) proposed by Goodfellow et al. 20 in 2014 is a representative deep learning-based generative model that simultaneously competes and learns the generator generating the image; the discriminator determines whether the generated image is real or fake. Many reports21–25 have been published on image generation in the field of computer vision, and significant progress has been made based on GAN. In this study, we augmented the insufficient data using Pix2Pix, 25 which is used in the field of image-to-image translation. It generates images with different domains while maintaining features and information by changing the domain of the input image. Pix2Pix was the first to define image-to-image translation; it transforms an image into an image in a different domain, unlike a vanilla GAN, which generates an image with noise as the input. Pix2Pix uses U-Net 26 as a generator. U-Net is an autoencoder-based model that maintains the features and dimensions of the input data by reducing its dimensions, extracting key information, and expanding the dimensions again; however, it outputs different values, adding skip connections to better preserve information from the original. In this study, Pix2Pix is used to create people at the desired location. As shown in Figure 7, a black square is created at the location of a person and used as the input image, and the original image is used as the output image. The input and output images are used as training data for model generation. When a rectangle is placed at a desired position in the input image and input into a trained model, the generator creates a person to fit the background.

Intrusion and normal state examples.

Data augmentation using Pix2Pix.
The diffusion model
27
can calculate the probability distribution differently from the GAN-based generation model. This is a generative model that considers high tractability. Studies by Ho et al.
28
and Saharia et al.
29
showing high accuracy have been published and have received considerable attention. The network consists of a diffusion process that adds very little noise to the input image step-by-step to create the noise of the standard distribution, in addition to a reverse process that defines and learns the inverse process of each step as a parameter. Equation (1) is a basic loss function of the diffusion model.


Data augmentation using diffusion model.
Experimental results
To select a discriminant model that learns the characteristics of track-intrusion images well, the five discriminant models described in the “Intrusion detection system” section are learned, and their performance is evaluated using a previously secured dataset. Table 1 presents the performance results of the learned models.
Performance comparison by network model.

The experiment used data from three people to detect intrusions on the tracks. The dataset consisted of 241 images, with 191 training data and 50 test data. In a binary classification problem, the actual value and the value predicted by the model are represented by a 2 × 2 matrix, as shown in Table 2.
TP, FP, FN, and TN.

True and false indicate whether the predicted result is correct. Positive and negative indicate cases in which the model classifies the state as intruder or normal. The classification accuracy is the most widely used index for the data learning of neural networks and is defined by

Structures of five networks.
System specification.

The datasets are composed of images acquired from three tracks (A, B, and C), as shown in Figure 10.

Track images.
The dataset used in this study was collected from the Yongin EverLine, an operational subway system in South Korea. The training dataset consisted of 81, 82, and 28 samples for tracks A, B, and C, respectively, while the test dataset comprised 21, 21, and 8 samples for the same tracks. In the training data, there were 60, 60, and 20 samples of normal state images for tracks A, B, and C, respectively, and 21, 22, and 8 samples depicting intrusion events. For the test data, there are 15, 15, and 5 samples of normal state images for tracks A, B, and C, respectively, along with 6, 6, and 3 samples of intrusion images. Table 4 presents the results of the evaluation of the intrusion states of each of the three tracks using MobileNetV3.
Intrusion detection performance.

Results after data augmentation using Pix2Pix
Two experiments were conducted to augment the data using Pix2Pix. They include two cases: placing a black rectangle in the desired location for human creation on the input image (pix2pixA) and placing a rectangle with random noise (pix2pixB). Figure 11 shows an image generated using Pix2Pix after completing the training.

Images generated using Pix2Pix.
Figure 11(a) shows the result for Pix2pixA. Although a person has been created, it can be observed that the boundaries are blurred, and there is a lack of detailed description. Figure 11(b) shows the results of Pix2pixB; in this case, it can be confirmed that learning does not proceed well and has no form at all. The number of training data is increased by 500 with two pix2pix model variations. Table 5 lists the intrusion detection results obtained by learning MobileNetV3 using the augmented dataset.
Intrusion detection performance using two pix2pix model variations.

It may be confirmed that the performance of Pix2PixA is improved, while that of Pix2PixB is rather lower, compared to the method before enhancement. It may be seen that the quality of the generated image affects the performance of the track intrusion classifier. Therefore, in this study, Diffusion is used to improve the quality of the generated image. The structure of pix2pix in the experiment is shown in Figure 12.

Structure of Pix2Pix.
Results after data augmentation using diffusion
Four experiments were conducted to increase the data using diffusion in various ways. The four different cases are listed as follows: to create one person with one pose (DiffusionA), one person with four poses (DiffusionB), three people with one pose (DiffusionC), and three people with three poses (DiffusionD). The four poses are standing, walking, falling, and sitting. Each diffusion is learned in 2000 steps. A person is created on an empty track image and is used for data augmentation. Figure 13 shows an image generated using diffusion that completed the training.

Images generated using diffusion.
Figure 13(a) to (d) shows the results of DiffusionA, DiffusionB, DiffusionC, and DiffusionD, respectively. As shown in Figure 13, some images are well generated, but some images with unclear human shapes are also generated. The number of training data points is increased by 500 with four diffusions. Table 6 shows the results of intrusion detection using the augmented dataset.
Intrusion detection performance using four diffusion methods.

This is because an increase in diversity hinders the learning of diffusion, thereby lowering the quality of the generated image. Furthermore, among the four experiments, DiffusionA exhibited the best performance. The structure of diffusion in the experiment is shown in Figure 14.
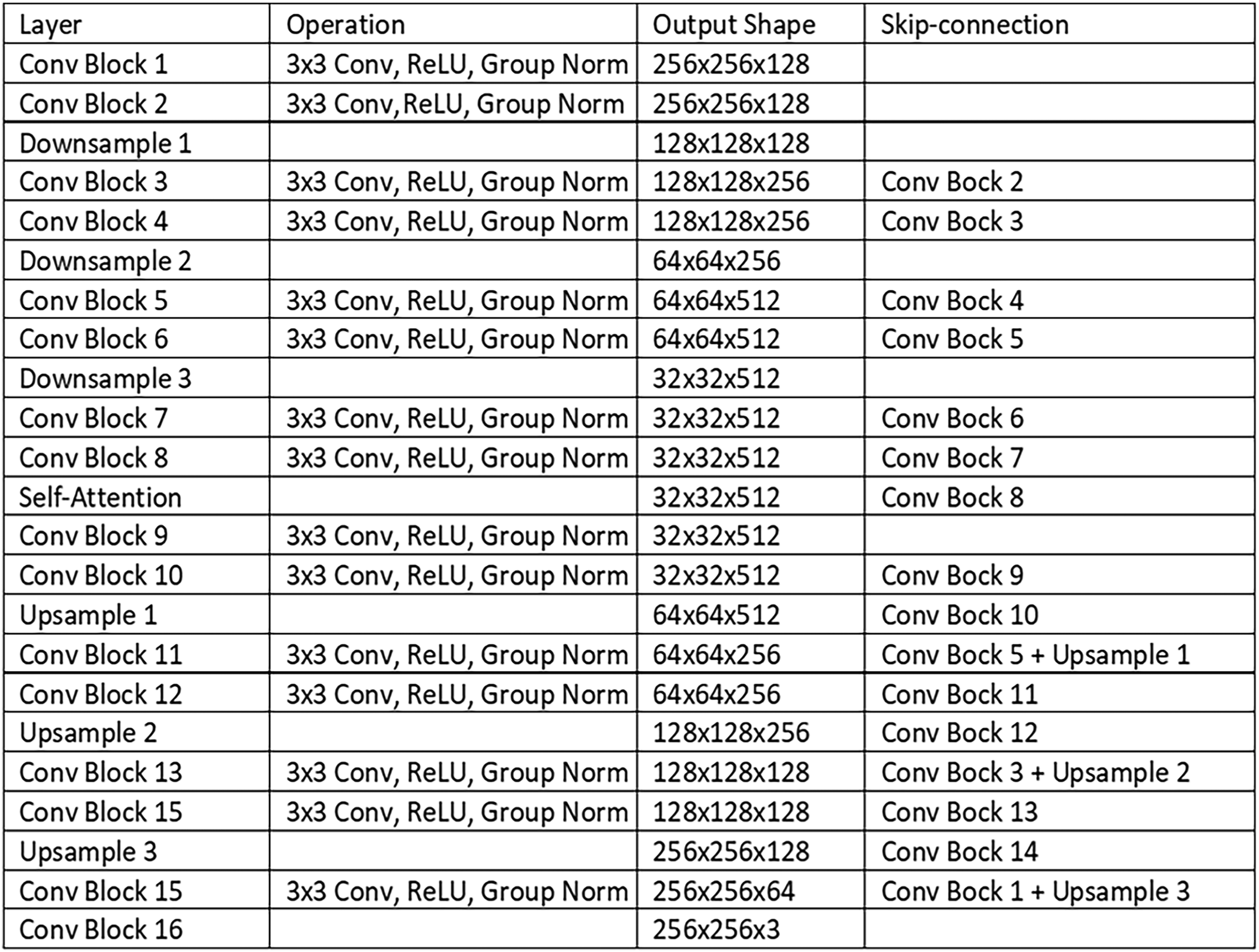
Structure of diffusion.
Discussion
The distinctive aspects of this study are as follows: in this study, we utilized a classifier for detecting intruders instead of employing additional modules for object detection. The classifier's objective is to determine the class to which the input image belongs. In this case, the classifier is trained to distinguish between intrusion and normal states. By considering not only the person's location but also the division of the track and platform areas, the classifier is able to comprehensively predict the intrusion state. Furthermore, in this article, the diffusion-based model does not generate the entire image from noise. Instead, it employs a diffusion process in which only the human portion of the input image is altered to noise.
Based on the findings of this study, the following are significant recommendations: Due to the computational demands of the diffusion process, sufficient learning time and computing resources are required. It involves performing numerous computations at each stage. Therefore, it is essential to consider allocating adequate resources for learning and generation and to carefully design experiments accordingly. Furthermore, it is necessary to have an evaluation metric that can assess whether the generated images are effective for the classifier's training. Since the visual quality of the generated images and the performance of the classifier with the generated images added as training data are not directly related, an evaluation metric that takes both of these factors into account needs to be developed.
Conclusions
This study proposed a method to augment training data using deep learning-based generative models to improve the performance of discriminant models that recognize people intruding on railway tracks; this intrusion is a representative hazard in the railway field. Deep learning-based algorithms perform well only when a sufficient amount of data is secured; however, the task of acquiring images with human intrusion on the track can pose many risks. To address this problem, experiments were conducted, demonstrating that augmenting data with generative models learned to generate people on empty-track images improves performance. This study experimentally confirmed MobileNetV3 as the most suitable deep learning-based discrimination model. In addition, the accuracy of the track intrusion discriminator was significantly improved by augmenting the training data through learning to create people at the desired location using diffusion as a generation model. Therefore, the proposed method not only addresses the lack of data for deep learning-based track-intrusion discrimination systems but also improves the accuracy of the system.
Footnotes
Acknowledgements
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIP; Ministry of Science, ICT & Future Planning) (NRF-2021R1F1A1052074). This was supported by Korea National University of Transportation Industry-Academy Cooperation Foundation in 2023.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Research Foundation of Korea, Korea National University of Transportation Industry-Academy Cooperation Foundation (grant number NRF-2021R1F1A1052074).
Author biographies
SooHyung Lee received the BS and MS degrees in railroad electrical and electronics engineering from Korea National University of Transportation (KNUT), Uiwang-si, Gyeinggi-do, Korea, in 2021 and 2023, respectively. Since 2023, he has been with ALCHERA Corporation, Seongnam-si, Gyeonggi-do, Korea. His current research interests include deep learning, generative model, and intelligent railroad system.
Beomseong Kim received the BS and Combined MS and PhD degrees in electrical and electronic engineering from Yonsei University, Seoul, Korea, in 2009 and 2015, respectively. From 2015 to 2017, he was a senior researcher with the LG electronics Corporation, Seoul, Korea. From 2017 to 2020, he was a manager with the SK telecom Corporation, Seoul, Korea. Since 2020, he has been with the Gyeonggi University of Science and Technology, Siheung-si, Gyeonggi-do, Korea, where he is currently an assistant professor. His current research interests include machine learning algorithm, sensor fusion system, and autonomous control for robot.
Heesung Lee received the BS, MS, and PhD degrees in electrical and electronic engineering from Yonsei University, Seoul, Korea, in 2003, 2005, and 2010, respectively. From 2011 to 2014, he was a managing researcher with the Samsung S1 Corporation, Seoul, Korea. Since 2015, he has been with the railroad electrical and electronics engineering at Korea National University of Transportation (KNUT), Uiwang-si, Gyeonggi-do, Korea, where he is currently an associate professor. His current research interests include computational intelligence, biometrics, and intelligent railroad system.