
Abstract
In recent years, the application of pretrained models in specialized domains has become increasingly important. Traditionally, adapting these models involved fine-tuning their parameters and structures through retraining. However, these fine-tuning methods can be inefficient, particularly when addressing data from specific domains or when modifications are needed in the lower layers of large-scale pretrained models. This study aims to investigate the effectiveness of using pretrained models with frozen weights for downstream tasks in the context of railway track detection, particularly focusing on the railway system. To achieve this, we employed a large-scale semantic segmentation model that had been pretrained on extensive datasets. The models utilized were kept with fixed weights, eliminating the need for retraining. We conducted a comparative analysis of various pretrained models sourced from different datasets to identify the most suitable model for the track detection system. The findings from our experiments revealed the performance metrics of the selected pretrained models, highlighting their effectiveness in the specific domain of railway track detection. Overall, this research demonstrates the practical applicability of pretrained models with frozen weights in specialized fields such as railway systems, offering insights into their usefulness and potential for improving detection algorithms in this domain.
Introduction
Recent deep-learning research has primarily focused on downstream tasks owing to their high generalization capability and adaptability to diverse environments.1–3 Deep-learning models pretrained on large-scale datasets can extract useful high-level representations and patterns, allowing them to adapt easily to several situations and new data. These pretrained models significantly reduce the time and computational resources required to train new data when applied to new domains, making them a popular choice for a wide range of tasks. The existing method of using deep-learning models for downstream tasks involves fine-tuning a part of the model that has previously learned to extract abstract features from large-scale datasets.4–7 Fine-tuning methods include initializing the weights of the deeper layers that contain high-level features and then further training the model on new data similar to the pretraining dataset.8,9 For datasets in which high-level representations of the network cannot be easily used, a method is employed to initialize more layers of the model before training.10–12 These fine-tuning methods allow developers to obtain models adapted to the desired data. Moreover, it is efficient to modify only the lower layers rather than initializing the weights of the entire model to perform the downstream task. In addition, by attaching specific modules or networks to high-level feature maps obtained from large-scale datasets through several iterations, it is possible to create models that can perform other subtasks desired by the user.13,14
Although this method can create deep-learning models capable of performing specific downstream tasks, there are limitations when using the latest pretrained deep-learning models. 2 Even though several large-scale datasets are publicly available, it is relatively difficult to learn weights when training on a dataset from a specific domain with low data similarity, requiring more layers to be newly trained. Moreover, recent deep-learning models that attain superior performance have grown in size, due to the trade-off between model complexity and accuracy. Therefore, they have significantly more parameters than the previous networks. The computational resources required to modify the lower layers of these latest models have increased dramatically compared to previous models, and there are limitations in learning and using them easily, depending on the model type and server environment.15,16
A recent trend in various research areas, such as natural language processing, computer vision, and speech recognition, is the increasing size of datasets and models to achieve better performance. This has led to the rise of large-scale models such as Large Language Models, Large Vision Models, and Large Vision-Language Models (LVLMs), which are trained on massive datasets.17–19 However, in large-scale models, it is often challenging to maintain a latent space that accurately reflects the characteristics of the original dataset when retraining on a new data domain, making it difficult to effectively learn the features of new datasets. As a result, recent deep-learning research trends have shifted toward using large-scale models with frozen weights directly for downstream tasks.20–24
In this study, we applied pretrained large-scale semantic segmentation models, commonly used in computer vision, to railway track detection algorithms. We used large segmentation models pretrained on large-scale datasets as input to the images acquired from railway vehicles and selected and compared the performance of the models that can detect railway tracks. This research enabled real-time track monitoring, allowing early detection and response to risks such as derailment and intrusion. Additionally, a detailed understanding of the condition of the track can help with maintenance planning, including track defects and obstacle detection. Further, improving the safety, efficiency, and sustainability of railway operations.
The proposed system offers significant advantages for railway maintenance by enabling continuous and real-time monitoring of track conditions. Specifically, maintenance vehicles equipped with an integrated track detection system can routinely patrol railway lines, identifying obstacles, debris, and structural damages such as cracks or misalignments. The early detection of these issues facilitates prompt interventions, thereby minimizing the risk of accidents and reducing service disruptions. Moreover, the system is capable of accumulating longitudinal data on track conditions, which allows for comprehensive analysis of wear and deterioration patterns over time. By comparing current track data with historical records, the system can identify gradual degradation, including the formation of minor cracks or uneven rail surfaces that may not be readily observable through manual inspections. This data-driven approach enables railway operators to accurately predict maintenance needs, supporting proactive maintenance scheduling rather than reactive repairs. Consequently, the implementation of this system enhances maintenance efficiency by reducing unplanned downtime and ensuring the consistent operation of trains. Early identification of track wear and structural defects also contributes to extending the operational lifespan of the tracks, as timely maintenance interventions prevent minor issues from escalating into more severe problems that would require extensive repairs or complete track replacements. Overall, this system not only improves safety standards but also optimizes maintenance costs and enhances the overall operational efficiency of railway services.
The remainder of this study is organized as follows. In “Railway track detection” section, we explain the semantic segmentation models and various pretrained deep-learning models that have been successfully applied to track detection and compare the performance of the deep-learning models based on the actual data acquired. “Experimental results” section presents the evaluation of the numerical performance of each model and the detection results when there is an obstacle. Finally, “Conclusions” section is presented.
Railway track detection
Semantic segmentation
Semantic segmentation, a deep-learning-based computer vision technology, is widely used in several industries and is becoming a mainstream technology in deep learning.17–19,25–31 Figure 1 shows the inference results of DeepLabV3+, 29 a representative semantic segmentation model, using the ADE20K 32 dataset for training.

Semantic segmentation.
As illustrated in Figure 1, semantic segmentation classifies each pixel in an image, identifies the object to which the pixel belongs, and accurately detects the location, shape, and boundaries of the objects. This segmentation information is used in autonomous driving to accurately distinguish between roads and pedestrians or in radiology to detect abnormalities in tumors or tissues in medical images such as magnetic resonance imaging or computed tomography. It has become an important tool for solving complex problems for a wide range of applications.33–39 If this technology is used in railway systems, it can create a maintenance system that detects and monitors the condition of tracks or analyze the flow of vehicles and passengers within railway stations from an operational management perspective. Furthermore, utilizing images captured by cameras mounted on railway vehicles in combination with segmentation models allows for the rapid real-time detection of potential hazards, such as pedestrians, animals, or other obstacles near the tracks, enabling the implementation of appropriate safety measures. Additionally, recognizing traffic signals and signs through semantic segmentation can enhance the performance of the signaling system. By identifying traffic lights and signs with known precise locations, the exact position of the railway vehicle can be determined, facilitating more efficient train scheduling and reducing the risk of collisions with preceding trains.
Semantic segmentation models with frozen weights for railway detection
Recent downstream tasks use a method of fixing the weights of certain or all the models. This is because it reduces the computational cost required for training, uses high-dimensional representations obtained from a wide range of datasets, and prevents overfitting while achieving efficient learning. Therefore, in cases with specific environments and requirements, such as railway track detection, finding pretrained models using similar domain datasets is important. To make learning more efficient for a new task, reduce the amount of data required for learning, and achieve high performance, comparing and selecting from various pretrained datasets and models is crucial.
This study aimed to apply deep-learning image segmentation to railway systems. Semantic segmentation technology is used to detect railway infrastructures, such as tracks, in real time from images acquired from cameras mounted on trains to detect obstacles, track defects, and other hazards. It also performs various auxiliary tasks, such as predicting the radius of curvature of the line. We conducted a large-scale experiment to detect railroad tracks using a large-scale model developed for semantic segmentation and various datasets used for pretraining the model. The results are shown in Table 1.
Results of segmentation system for railway detection.

The vertical axis in Table 1 represents the deep-learning models used in the experiment, and the horizontal axis represents the datasets used for pretraining. For this experiment, 338 images were directly acquired from the Osong Railway Test Line in South Korea, which consisted of 211 straight-track images and 127 curved-track images. The test line was established to evaluate new railway infrastructure and technologies, with the goal of addressing theoretical issues and gathering practical operational data before deploying them on the main line. This site was chosen for its capability to provide test images under a range of driving conditions. Pretrained models were used in the MMSegmentation open-source toolbox. 56 In Table 1, “S” (Success) indicates that the model trained on that data set can detect tracks in the test data set, and “F” (Fail) indicates that the model failed to detect tracks. “None” indicates that no pretrained model exists. Table 2 lists the specific configurations of the systems used in the experiments.
System configuration.

The methods that successfully find the tracks are BiSeNetV1, 45 DeepLabV3, 33 DeepLabV3+, 29 PSPNet, 52 and SAN. 53 These models are neural networks for semantic segmentation that classify pixels into meaningful classes and use the overall contextual information of the image to achieve more accurate segmentation results. They employ modules and structures, such as the Pyramid Pooling Module (PPM), Atrous Spatial Pyramid Pooling (ASPP), and bilateral segmentation networks, and have shown excellent performance on several major benchmarks. Regarding the detailed differences among the five models, BiSeNetV1 45 is a bilateral segmentation network model developed for real-time tasks. It consists of two parallel network streams: the Spatial Path generates high-resolution feature maps to preserve object boundary information, whereas the Context Path, with a deeper network, learns rich semantic information. It aims to eliminate bottlenecks arising from using deep networks and has an efficient structure that uses a simple structure and few parameters. Figure 2 shows the simple structure of the BiSeNet model.
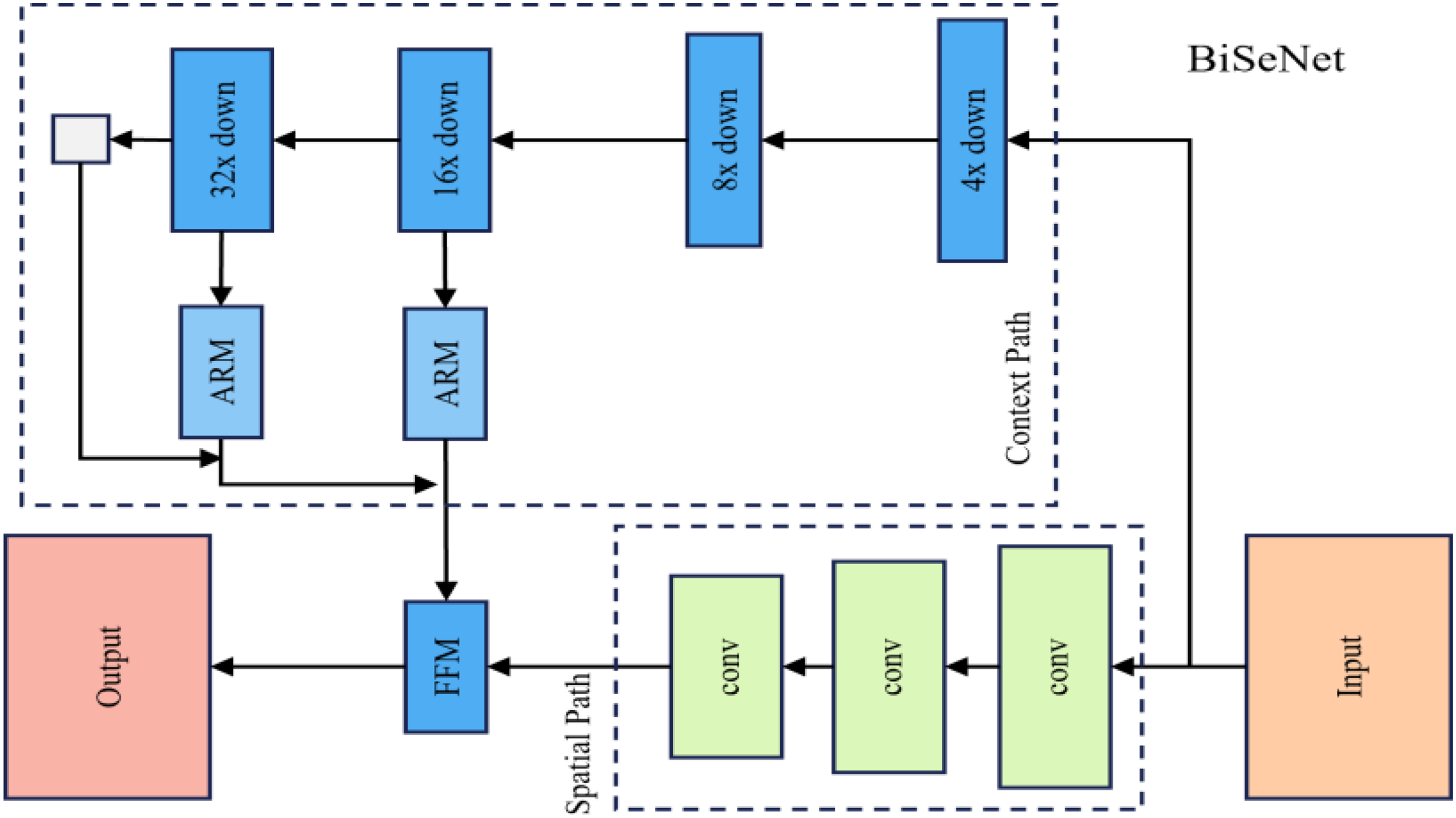
Bisenet architecture.
The second model that successfully detects the tracks is DeepLabV3, 33 which uses an ASPP module to achieve a wide range of receptive fields. Using Atrous Convolution layers with different dilation rates, the model can effectively recognize objects of various sizes while reducing the computational cost. The third model, DeepLabV3+, 29 is an extended version of DeepLabV3 in which a decoder module is added to the ASPP module, further improving its performance. This model uses a decoder module to combine low- and high-resolution representations, generating a more refined segmentation map and improving the accuracy around object boundaries. The fourth model, PSPNet, 52 is a pyramid-scene parsing network. PSPNet does not rely solely on local information for prediction but uses a PPM to extract multiscale information with pooling windows of various sizes, as shown in Figure 3.

PSPNet architecture.
The extracted information is then combined for use in the final prediction. This allows the model to combine local and global information effectively. Lastly, SAN 53 is the Side Adapter Network, which reflects the new trend in Downstream Tasks of adding learnable modules to LVLMs such as CLIP without fine-tuning the model. The side adapter network is attached to the frozen CLIP model, where it fuses some of the features and predicts the mask proposals and attention bias to generate the final segmentation map.
The large-scale models were pretrained on eight different datasets: ADE20K, 32 Cityscapes, 40 COCO-Stuff 10k, 41 COCO-Stuff 164k, 41 Mapillary Vistas, 42 Pascal Context, 43 Pascal Context 43 59, and Pascal VOC. 44 These datasets contain urban scenes and include classes important to our research, such as roads and tracks. Among these, ADE20K, 32 Cityscapes, 40 and Pascal Context 43 contain diverse urban scenes and classes such as roads and tracks, but models trained on these datasets failed to detect the tracks successfully in the experiments. However, models trained on the Pascal Context 43 59 dataset, which includes 59 key classes out of 459 Pascal Context classes, can successfully detect tracks. The datasets that offered models with success in track detection, namely COCO-Stuff 10k, 41 COCO-Stuff 164k, 41 and Mapillary Vistas, 42 also provided a variety of indoor and outdoor urban scenes, along with classes for tracks.
The ADE20K 32 dataset, which included a variety of scenes, was used as a representative dataset for segmentation in the experiments. The models trained on this dataset have a high-level understanding of indoor, outdoor, natural, and urban scenes. Cityscapes 40 is a dataset designed for the semantic understanding of urban street scenes recorded in 50 cities and includes a variety of objects such as people, vehicles, and buildings, making it the most widely used dataset for pretraining models. COCO-Stuff 10k 41 and COCO-Stuff 164k 41 are datasets based on the well-known COCO 2017 dataset with additional annotations for semantic segmentation. COCO Stuff 10k contains 10,000 images with pixel-level annotations, whereas COCO Stuff 164k contains 164,000 images. Figure 4 shows the images that represent the COCO Stuff dataset.

COCO Stuff dataset sample 41 .
Mapillary Vistas 42 is a dataset containing a variety of outdoor street scenes, as shown in Figure 5. This includes scenes with diverse geographic locations, weather conditions, times of day, and road types. It also provides information on vehicles, pedestrians, signs, roads, and railway tracks.

Mapillary Vistas dataset sample 42 .
Pascal Context 43 is an extension of the Pascal VOC dataset, consisting of more than 400 classes, and is used to evaluate large-capacity models in semantic segmentation learning. The Pascal Context 59 dataset is a subset of the Pascal Context, which selects the 59 most frequent classes. Although it is limited to 59 classes and can be used for specific tasks, it mitigates learning difficulties owing to the sparse class distribution of the original Pascal Context. Pascal VOC 44 is a dataset provided by the PASCAL Visual Object Classes Challenge that includes various indoor and outdoor scenes, natural environments, and objects such as people.
Experiments on railway detection using pretrained models showed that the models trained on the COCO-Stuff 10k, COCO-Stuff 164k, Mapillary Vistas, and Pascal Context 59 datasets could detect railway tracks. However, the model trained on the original Pascal Context dataset, which has a smaller dataset compared to diverse classes, could not detect the railway tracks. The model trained on the Pascal Context 59 dataset, which has a number of reduced classes but provides more information on frequent objects, can detect railway tracks. Additionally, the models trained on COCO-Stuff 10k, COCO-Stuff 164k, and Mapillary Vistas, which provide a variety of street-level scenes and annotations, can detect railway tracks. Although the pretrained models using the four datasets successfully partitioned the tracks, researching methods to enhance the model's generalization capabilities through techniques such as transfer learning, data augmentation, and domain adaptation is also a highly important area of study. These techniques can improve the performance of deep-learning models across various environments, including railway systems, and will facilitate their effective application in diverse fields. Table 3 presents some of the segmentation results of deep-learning models that detect railway tracks successfully.
Segmentation result images.

The inference models used were further divided into various submodels based on factors such as the type and depth of the Model Backbone, the number of GPUs used for training, and the amount of training performed. The results of the models with the best qualitative performance are presented.
Experimental results
Numerical experiment results
To evaluate the numerical performance of each model, the railway tracks in the test videos were analyzed at the pixel level, and the precision, recall, and F1 score (harmonic mean of Precision and Recall) were calculated using equations (1), (2), and (3), respectively:

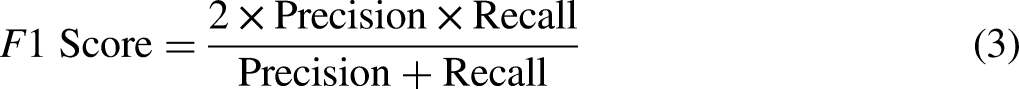
We employed five pretrained semantic segmentation models containing 32 different variants for the numerical experiments. We then compared the inferred tracks from each model with the ground truth and calculated the precision, recall, and F1 scores, as shown in Table 4.

Railroad test images and ground truth.
Experiments for each model.

In Table 4, the pretrained models are composed of different model structures, backbones, epochs, and datasets. R18 uses the ResNet18 backbone, whereas R50 and R101 use ResNet50 and ResNet101, respectively. Pre indicates that the backbone model used has been pretrained on the ImageNet-1000 dataset. ViT-B16 refers to the ViT Base model, and ViT-L14 is the ViT Large model with more parameters. The “D” notation indicates the degree of downsampling, where D8 means the output of the backbone is downsampled by a factor of 8. An epoch represents the number of training iterations. The models were trained using the COCO-Stuff 10k, COCO-Stuff 164k, Mapillary Vistas, and Pascal Context 59 datasets. To evaluate the model performance, precision, recall, and F1 scores are reported in Table 4, and the number of parameters is included to compare the model complexity.
The best-performing models in each model structure used either the ResNet101 backbone or the CLIP ViT-L14. These backbones have the most parameters and are complex; however, they can learn better representations for object discrimination, resulting in the highest segmentation performance. The model with the highest performance was the SAN model, which achieved an F1 score of 0.85. This model has the highest FLOPs but the least learnable parameters. This is because it is trained by attaching a learnable module in parallel to a pretrained CLIP model, which has a large capacity but a small module size, leading to high FLOPs but a smaller overall model size. The second-best-performing model was PSPNet, which achieved an F1 score of 0.79. The model with the lowest FLOPs of 0.12 T and a below-average number of parameters is BiSeNetV1 with a ResNet18 backbone. There is a trade-off between model performance and complexity. The model that achieves the best trade-off is PSPNet with a ResNet101 backbone, whereas the CLIP ViT-L14 backbone-based SAN model outperforms the other models both qualitatively and quantitatively. Figure 7 presents a comparison of the FLOPs, parameters, and F1 scores for the different models.
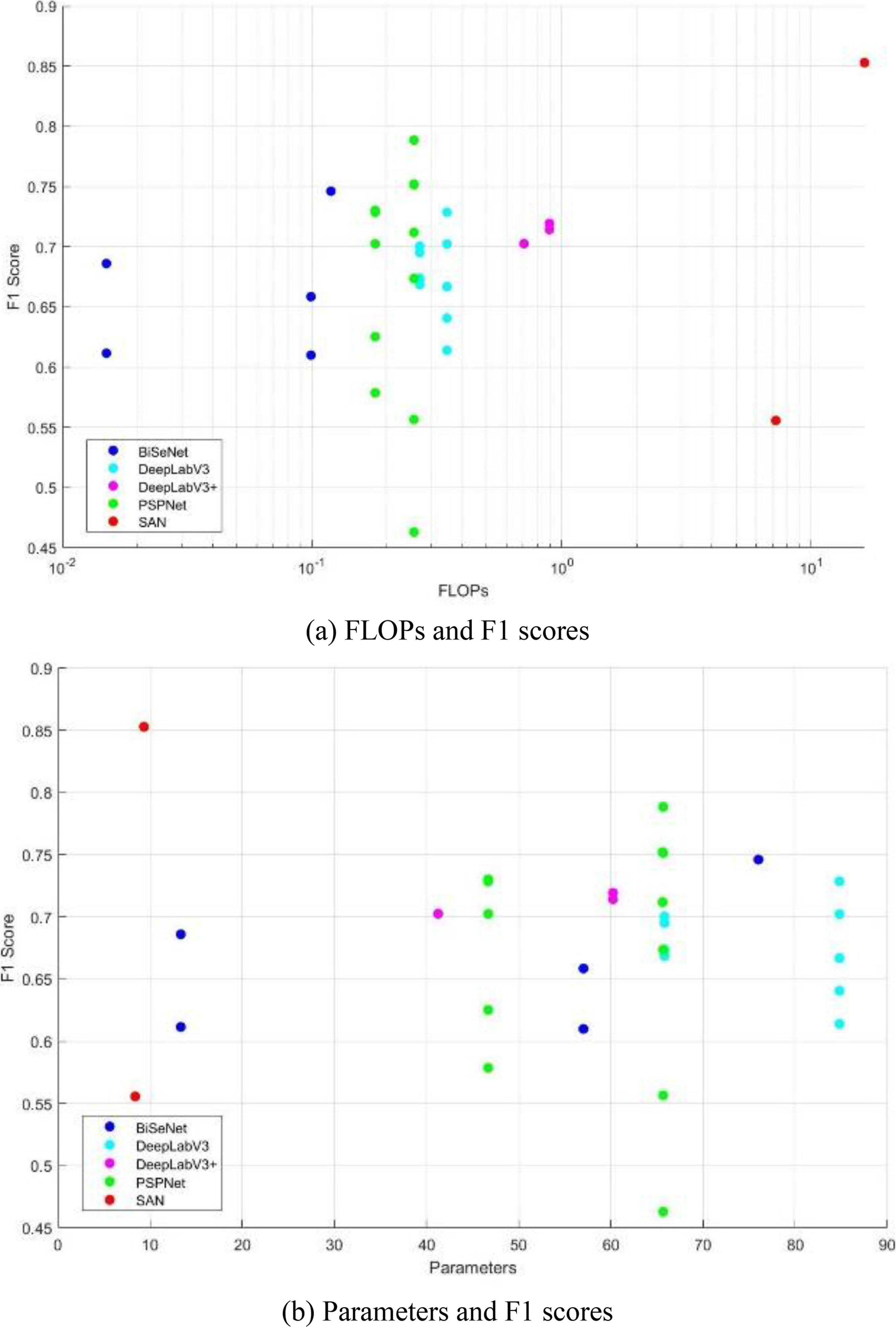
Experimental results.
Results in the presence of obstacle
If an obstacle is present on the track, the track detection system is likely to be affected. To analyze the impact of obstacle size on detection performance, we introduced virtual obstacles and evaluated the performance of five pretrained semantic segmentation models. As shown in Figure 8, virtual obstacles with pixel dimensions of 32 × 32, 85 × 69, and 191 × 156 were placed in the images, and experiments were conducted using the models with the highest F1 scores.

Obstacles on the tracks.
Table 5 presents the F1 scores for each obstacle size, as well as the performance differences compared to the case without obstacles. DeepLabV3 was minimally affected by small- and medium-sized obstacles but experienced a significant performance drop with larger obstacles. In contrast, SAN showed minimal impact from obstacles across all sizes. Table 6 presents the actual track detection results based on obstacle size.
Experimental results according to obstacle size.

Segmentation results by obstacle size.

Conclusions
In this study, we investigated recent trends in deep-learning research and examined the applicability and utility of models pretrained on large-scale datasets within specific domains. These models demonstrate the capability to extract high-level features from diverse patterns and offer the advantage of retaining the latent characteristics of existing datasets while enhancing adaptability to new domains through weight freezing. As a case study, we applied pretrained semantic segmentation models to detect railway tracks in a railway system. We conducted both qualitative and quantitative comparisons of various pretrained models to identify the most suitable one for track detection and evaluated the practical applicability of these state-of-the-art deep-learning technologies.
Furthermore, by facilitating real-time monitoring of track conditions, this system enables the early detection of obstacles, cracks, and wear, thereby enhancing the operational safety of railway systems. Maintenance teams can respond in a timely manner to identified issues, reducing the likelihood of service disruptions and accidents. The system also supports proactive maintenance by collecting long-term data on track conditions, allowing operators to predict maintenance needs and prevent high-cost repairs.
In conclusion, this study demonstrates how pretrained deep-learning models can be effectively applied to specific downstream tasks, such as railway track detection. As deep-learning technology continues to advance, the adoption of such models is expected to expand across various industries. This research establishes a foundation for future applications and highlights the potential for improving both operational efficiency and safety in the railway sector.
Footnotes
Author contributions
All authors contributed to study conceptualization, statistical analysis, and writing of the study. Seungmin Lee participated in acquisition of data and designed the research. Beomseong Kim and Heesung Lee participated in the analysis and interpretation of data and funding acquisition.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Research Foundation of Korea (NRF) Grant funded by the Korea Government (MSIT) (No. RS-2022-00166346).