
Abstract
With the rapid development of Internet and information technology, networks have become an important media of information diffusion in the global. In view of the increasing scale of network data, how to ensure the completeness and accuracy of the obtainable links from networks has been an urgent problem that needs to be solved. Different from most traditional link prediction methods only focus on the missing links, a novel link prediction approach is proposed in this paper to handle both the missing links and the spurious links in networks. At first, we define the attractive force for any pair of nodes to denote the strength of the relation between them. Then, all the nodes can be divided into some communities according to their degrees and the attractive force on them. Next, we define the connection probability for each pair of unconnected nodes to measure the possibility if they are connected, the missing links can be predicted by calculating and comparing the connection probabilities of all the pairs of unconnected nodes. Moreover, we define the break probability for each pair of connected nodes to measure the possibility if they are broken, the spurious links can also be detected by calculating and comparing the break probabilities of all the pairs of connected nodes. To verify the validity of the proposed approach, we conduct experiments on some real-world networks. The results show the proposed approach can achieve higher prediction accuracy and more stable performance compared with some existing methods.
Introduction
In recent years, the rapid development of communication technology and Internet have greatly accelerated the sharing and spread of information, they have also provided more convenience and options for individuals. Some individuals are connected to each other to form a network, and the network will become more complex with the increasing participant individuals. Extracting the relations between individuals from many of these networks for analysis has been a crucial research issue at present.1–3 In a network, a node can be used to represent a participant individual, and a link between two connected nodes is often used to indicate the existence of the connecting relation between them. In addition, a link can be regarded as a transmission path of information between nodes. Therefore, link prediction plays an important role in research of recommendation system and information spread.4–7
Link prediction can be normally used to predict the possibility if a link exists between two unconnected nodes based on the observable network structure.8–10 The problem can be divided into two categories: one is to detect the missing links that should exist in networks,11–14 these links may be missed in the process of data acquisition; the other one is to predict the potential links that will become real links in the future. 15 In recent decades, various link prediction methods based on similarity metrics and machine learning models have been proposed.16–18 Similarity-based methods can achieve good prediction accuracy with less time cost due to they predict the possibility that a link should exist or not in the network by analyzing the network structure, such as the connections and paths between nodes. Learning-based methods predict the links by model building and repeated calculation to achieve better prediction accuracy but they also take more time. However, most of link prediction methods ignore an important problem that may occur in data processing: some real links may be spurious links that should not exist in networks, which can have a negative impact on accuracy of networks and information dissemination.
In order to solve the above problems, based on previous work on community detection, 19 a novel similarity-based link prediction approach via community detection is proposed in this paper, which can not only predict the missing links in the network, but also detect the spurious links. In the beginning, we define the attractive force for any pair of nodes to denote the strength of the relation between them. Then, a community detection algorithm is proposed to divide all the node into some communities according to their degrees and the attractive forces on them. Next, the link prediction approach based on the community structures is proposed, including two algorithms LPCA-P and LPCA-R. LPCA-P can be used to predict the missing links by calculating and comparing the connection probabilities of the potential links in a network, the higher connection probability of a potential link between two unconnected nodes means the two nodes are more possible to be connected. LPCA-R can be applied to detect the spurious links by calculating and comparing the break probabilities of the real links, the higher break probability of a real link between two connected nodes means the link is more possible to be a spurious link. Finally, experiments are conducted on some real-world networks and compared with some existing link prediction methods to verify the validity of the proposed algorithms.
The rest of this paper is organized as follows: In Section 2, we describe the current research work on link prediction. In Section 3, we define the attractive force for any pair of nodes in a network and propose the community detection algorithm. Then, we make detailed descriptions and explanations of our link prediction approach in Section 4, including the algorithm LPCA-P for missing link prediction and the algorithm LPCA-R for spurious link detection. In Section 5, we conduct experiments on some real-world networks and compare the results with some existing link prediction methods. Finally, we summarize the paper and forecast the future work.
Related work
Most of the existing link prediction methods focus on the prediction of the potential links between pairs of unconnected nodes according to the known network structure since they have been proposed. These methods can be basically divided into two categories, one is based on similarity metrics and the other one is based on machine learning.
The methods based on similarity metrics measure the importance of a potential link between two unconnected nodes by extracting local information or global information in a network. Local information may be the attributes of nodes such as age, interest or hobby that have been uploaded by users, or a few local characteristics of the network. Some typical methods are: the common neighbors (CN) index, 20 Adamic and Adar 21 (AA) index, Jaccard 22 index, Katz 23 index, and SimRank algorithm. 24 Moreover, inspired by these methods, Zhou et al. 12 defined the amount of resource for the nodes and calculated the amount of resource transmission of potential links by considering the common neighbors of unconnected nodes, they presented the resource allocation (RA) index. Dai et al. 25 constructed the belief vector for different types of links by calculating the belief of each node and measured the influence between different types of relations by comparing the similarity of belief vectors. Rafiee et al. 26 proposed a similarity-based link prediction algorithm CNDP to measure the similarity score of pairs of nodes by considering the clustering coefficient of nodes. These methods can generally achieve acceptable prediction results even if they are implementable, however, they perform unsatisfactorily on sparse networks. The similarity-metrics-based methods via global information mainly focus on the network topology structure, such as the paths between pairs of unconnected nodes, that have broader fitness and better robustness than the methods only used the attributes of nodes. Liu et al. 27 considered the distance between nodes in different communities of social networks and introduced the Hash method to calculate the similarity between nodes in different communities, it could make dynamic link prediction by collecting the change of local nodes information. Akiba et al. 28 put forward an algorithm for K shortest route between any two nodes in networks, and the algorithm has been successfully used in link prediction. Liu et al. 29 presented the method of superposed random walk (SRW) by superimposing T-step and preorder results based on the concept of local random walk. Zhang et al. 30 measured the inter-similarity by employing the local diffusion processes and proposed a bi-directional hybrid diffusion method for identifying missing and spurious links in bipartite networks. These methods can normally achieve higher prediction accuracy than the methods using local information, however, they need to take more time.
The methods based on machine learning can predict the possibility of potential links becoming real links via building machine learning models. Scellato et al. 31 defined some new features based on the original network features and proposed a supervised learning framework to predict new links of friends-friends and places-friends. Zhou and Jia 32 characterized the similarity of any pairs of unconnected nodes by considering the knowledge quantity of the nodes on the paths between them and proposed the knowledge-dissemination-based link prediction (KDLP) algorithm for link prediction based on knowledge dissemination mechanism. Pech et al. 33 introduced robust principal component analysis (robust PCA) for link prediction on dense networks by completing the adjacent matrixes of networks. Williamson 34 presented a Bayesian nonparametric approach for link prediction on sparse networks that combined structure explanation with predictive performance. Muniz et al. 7 proposed weighted criteria by combining contextual, temporal and topological information to improve the link prediction accuracy. Singh et al. 35 presented a community detection algorithm to divide the network into clusters and further proposed a missing link prediction approach based on information diffusion. These methods need to train the data and deploy parameters in advance, and the trained models have great influence on the final prediction accuracy.
Moreover, a few link prediction approaches have been proposed specifically on detecting spurious links in network.36–41 Pan et al. 38 defined a structural Hamiltonian for a network and calculated the conditional probability to detect spurious links. Samei and Jalili 40 used two novel similarity metrics based on the hyperbolic distance of node pairs to predict missing and spurious links in multiplex networks. They further combined intralayer similarity with interlayer relevance to rank the links to predict whether there are spurious links. 41 These works are effectively promoting the research of spurious link detection.
Community detection based on the attractive force between nodes
Problem description
For an undirected network
In view of the deviation in the process of network data acquisition, especially on some large-scale networks, some links that should exist in the network may be ignored (missing links) and some links that should not exist may be misdeemed as real links (spurious links). To address this problem, we define connection probability (
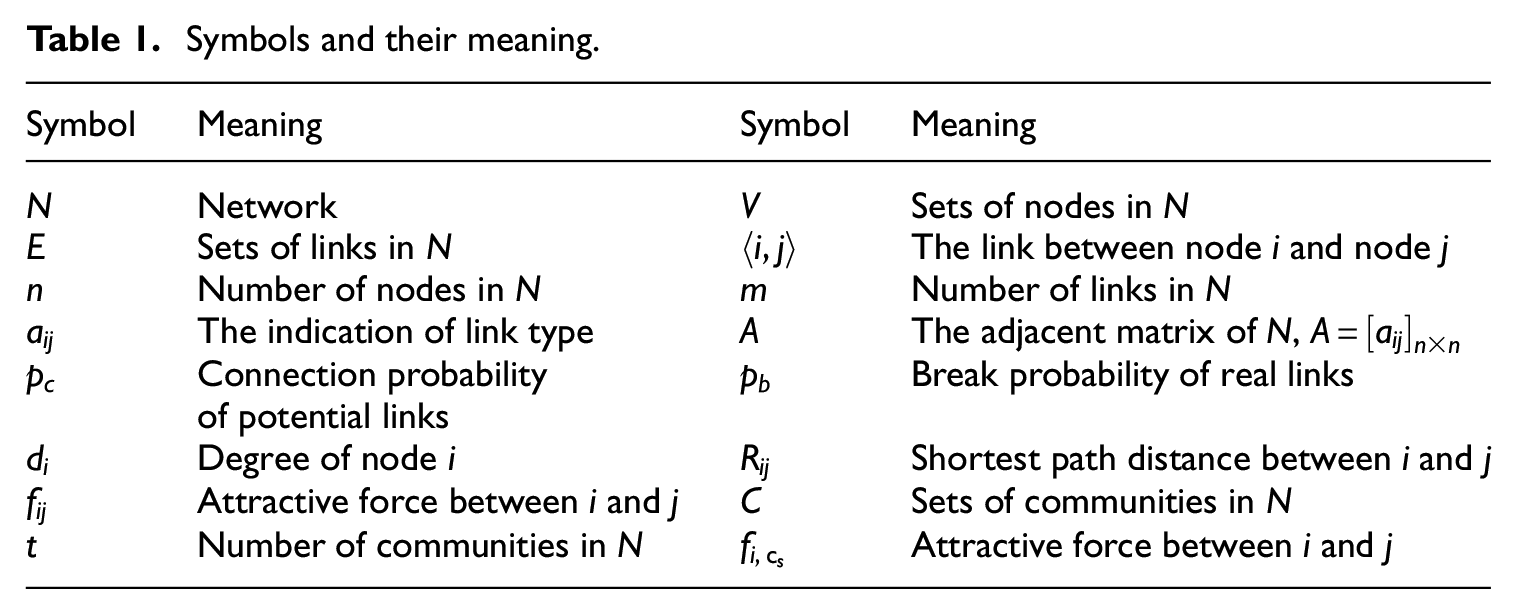
Table 1 shows the symbols used in this paper and their meaning.
Symbols and their meaning.
Before calculating the probabilities for missing link prediction and spurious link detection, we need to divide all the nodes into some communities based on the attractive force between nodes. Details will be described in the following.
The attractive force between nodes
In order to measure the strength of the relation between any two nodes in network
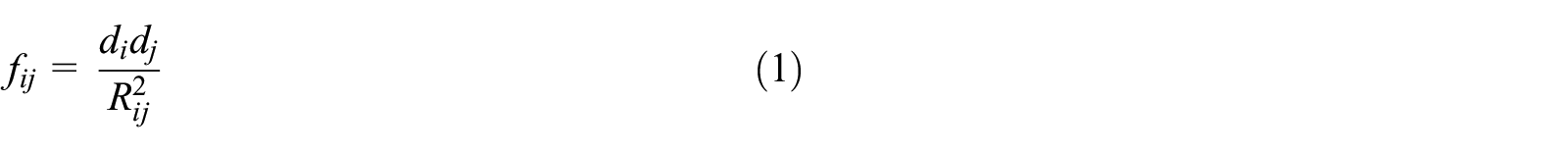
where
The numerator in the right side of equation (1) should be the product of the mass of node
Community detection
Due to there are

For a non-core node, if it is attracted by only one community, it can be divided directly into this community, if it is attracted by multiple communities, it should be divided into the community with greater attractive force. Repeat the above process until all the nodes in the network are divided into communities. Algorithm 1 describes the details of community detection.

The time complexity of Algorithm 1 is

A sample network-Karate club social network.
The approach for missing link prediction and spurious link detection
The proposed approach will be described in two parts, one part is used for predicting the missing links from all the potential links and the other one is applied to detecting the spurious links from all the real links.
Predicting the missing links from potential links
For a potential link
We first consider the case that the distance between node
When node

where
Such as node 7 and node 11 of Karate club social network, they belong to the same community, and
If the distance between node
After the connection probabilities of all the potential links are calculated, we can select some potential links with great connection probabilities as the missing links in the network. Algorithm 2 describes the details of missing link prediction (LPCA-P).

Detecting the spurious links from real links
For a real link
When node
When node
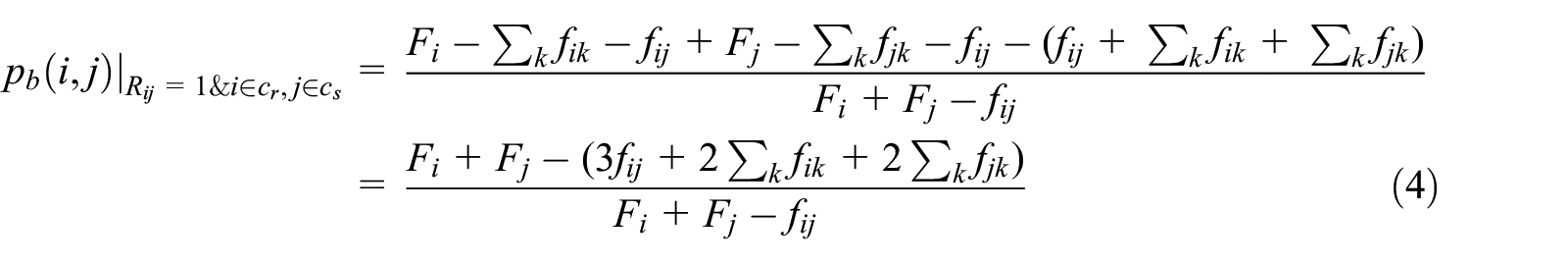
Such as real link
After the break probabilities of all the real links are calculated, we can select some real links with great break probabilities as the spurious links in the network. Algorithm 3 describes the details of real links prediction (LPCA-R).

The time complexity of Algorithm 3 is
Experiments
In this paper, we use some real-world networks for experiments to verify the proposed approach. In order to evaluate the prediction accuracy, we select AUC as the evaluation indicator and compare the results with some existing algorithms.
Experimental setup
Seven real-world networks are used to conduct experiments to verify the proposed approach, including Dolphins network, 42 American College Football Network, 43 Neural network, 44 Eu-core network, 44 Political blogs network, 46 Co-authorships network in network science, 47 and P2P Gnutella 08 network. 45 Table 2 shows the basic information of these networks.
The basic information of experimental data sets.

AUC (Area Under the Receive Operating Characteristics Curve) is a common evaluation index of link prediction. It can be used to evaluate the accuracy of link prediction by measuring the times that the probability of a link in the test set is larger than the probability of a link randomly selected from the validation set after many times comparisons. 48 The formula is defined as equation (5):

where
In addition, to verify the prediction accuracy of our method, we select some classic algorithms and newly proposed algorithms as comparison algorithms, including CN index, AA index, RA index, CRA algorithm, 49 RWR algorithm, 50 and KDLP algorithm. The detail descriptions of these comparison algorithms are in following:
(1) CN index evaluates a potential link between two unconnected nodes by counting their common neighbors, it can be defined as equation (6):

where
(2) AA index can be regarded as a variant of CN index and it endows the common neighbors with more weight if they have lower degree. It can be defined as equation (7).

(3) RA index is similar to AA and it can be defined as equation (8).

(4) CRA algorithm considers both the common neighbors between two unconnected nodes and the common neighbors between the three. It can be defined as equation (9).

where
(5) RWR algorithm is based on random walk, it assumes that some particles can walk randomly between any two nodes, and the importance of a link can be measured by counting the number of times that particles pass in it at a certain number of rounds. It can be defined as equation (10).

where
(6) KDLP algorithm defines the knowledge quantity for each node by calculating its H-index and weights the links in a network based on knowledge dissemination between nodes. It is defined in equation (11).

where
Table 3 shows the time complexity of algorithms. Compared with the comparison algorithms, the approach proposed in this paper has less time complexity.
The time complexity of algorithms.

Experimental results of missing link prediction
In the experiments of missing link prediction, we divide all the potential links of a network into two parts, one is the validation set which account for
The AUC results of missing link prediction on data sets by different algorithms when

According to the AUC results shown by Table 4, the proposed algorithm LPCA-P can achieve top two prediction accuracy on most of the experimental networks except for Eu-core network and Political blogs network when
In order to verify the performance of algorithms when more misinformation exists in a network, we further increase the value of

Changes of the AUC results in missing link prediction on experimental data sets by different algorithms with the increasing
According to the results shown in Figure 2, the proposed algorithm LPCA-P can achieve and maintain high prediction accuracy with the increase of
Experimental results of spurious link detection
Like the experiments of missing link prediction, we select some potential links which account for
The AUC results of spurious link detection on data sets by different algorithms when

According to the AUC results shown by Table 5, it is obviously that the proposed algorithm LPCA-R can achieve top two prediction accuracy on all the seven experimental networks when

Changes of the AUC results in spurious link detection on experimental networks by different algorithms with the increasing
It can be observed from Figure 3 that the proposed algorithm LPCA-R can achieve higher prediction accuracy than the comparison algorithms, except for KDLP algorithm, in real links prediction on the seven networks. However, KDLP algorithm performs best on Eu-core network, Political blogs network, and Co-authorships in network science. According to the results, the proposed algorithm LPCA-R and KDLP algorithm can achieve satisfactory and stable prediction accuracy on large-scale network, such as Political blogs network, Co-authorships in network science and P2P Gnutella 08 network, other algorithms underperform on these networks.
Conclusions
In this paper, a link prediction approach based on community structure and the attractive force between nodes is proposed to predict the missing links and detect the spurious links in social networks. Firstly, the attractive force between any two nodes is defined to measure the strengths of the relation between nodes in a network. In addition, the nodes with local maximum degree are chosen as the core of communities and other nodes can be divided into these communities depending on the attractive force between them and communities. Then, the approach is described, which contains two algorithms LPCA-P and LPCA-R. LPCA-P calculates and compares the connection probability of each potential link to predict whether it is a missing link, and LPCA-R calculates and compares the break probability of each real link to detect whether it is a spurious link. Finally, we conduct experiments on seven real-world networks to verify the validity of the proposed approach and compare with some existing algorithms. The experimental results demonstrate that the proposed approach can achieve satisfactory and stable prediction accuracy compared to the comparison algorithms in missing link prediction and spurious link detection. In the future, we will try to further improve the performance of our approach on large-scale networks and plan to use distributed computing to reduce time consumption.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the National Social Science Foundation of China under No. 14BGL007, the Fundamental Research Funds for the Central Universities under No.3072020CFW0910, the Postdoctoral Science Foundation of Heilongjiang Province under No. LBH-Z18052, and the Social Science Fund of Heilongjiang Province under No. 19GLC160.