
Abstract
A growing body of research in psycholinguistics, corpus linguistics, and sociolinguistics shows that we have a strong tendency to repeat linguistic material that we have recently produced, seen, or heard. The present paper investigates whether priming effects manifest in continuous phonetic variation the way it has been reported in phonological, morphological, and syntactic variation. We analyzed nearly 60,000 tokens of vowels involved in the New Zealand English short front vowel shift (SFVS), a change in progress in which
1 Introduction
Sixty years of research in variationist sociolinguistics has provided us with a wealth of data and a reasonably detailed understanding of how many social and linguistic factors shape phonetic and phonological variation at the group level (e.g., Labov, 1994, 2001). The canonical methodology for this type of research is to perform some form of regression analysis to examine how various linguistic and extra-linguistic constraints operate on a single linguistic variable. One assumption underlying this approach is that each instance of variation is unique, unrelated to the preceding instance of the same variable from the same speaker (Tamminga, 2016). This assumption is at odds with findings from the literature in the so-called “third wave” of variationist sociolinguistics, which describes how individual speakers agentively use phonetic variants to construct different styles (Eckert, 2012, 2018). The main thrust of this literature is to claim that the meaning of a particular variant cannot be properly interpreted in isolation of the landscape of other variants with which it co-occurs. However, the methodological implication for variationist sociolinguistics is that instances of variation are, indeed, related to previous instances of variation, at least within a specific speech style. There have been some recent attempts to draw on these two sets of literature in order to better understand how multiple variants correlate and co-occur across large groups of speakers (e.g., Guy, 2013). This literature is concerned with correlating overall patterns of usage of variants across speakers; it does not look at usage as it unfolds in real time. Finally, there is a small but intriguing body of literature in corpus linguistics and sociolinguistics that considers the role of recency or “priming” as a motivation for the clustering of variants in real time in natural conversation. This literature aligns with the long-established finding from experimental psycholinguistics that when we talk or write, we have a strong tendency to repeat linguistic material that we have recently produced, seen, or heard (Bock, 1986; Branigan et al., 2000). This work has largely shown that repetition effects that occur in natural speech in real time are strikingly similar to those found in experimental studies of priming because they show that we have a tendency to repeat similar linguistic variants in quick succession in naturally occurring speech (e.g., Clark, 2018; Gries, 2005; Szmrecsanyi, 2006; Tamminga, 2016). Again, however, these studies have focused on the individual variable in isolation and simply asked: does a speaker’s previous realization of a linguistic variable influence their immediately following realization of that same variable?
These four strands of literature have each provided new information about the factors that constrain and promote phonetic and phonological variation and change. From variationist sociolinguistics we have learned how individual variables pattern and change at the community level, and from the others we have learned that individual variables might cluster together and influence each other as discourse unfolds (either as speakers engage in identity work constructing speech styles or as they are biased by their own recently produced utterances). When combined, the four strands of literature raise new questions. In this paper, we are interested in understanding the repetition or priming effect in more detail. How does this priming effect—which has been reported to operate at the level of the individual variable—manifest when the variable in question is part of a larger systematic change in progress occurring at the community level, such as a vowel chain shift? Do we see priming effects only within phonological categories, or across phonological categories too? Finally, how does priming interact with social factors that also variously motivate or constrain a chain shift in progress?
The rest of the paper proceeds as follows. In the following section, we provide a more thorough review of some existing work on priming in sociolinguistics and corpus linguistics that led to the research questions we propose here. We then describe the variable phenomenon under investigation in this work: the New Zealand English (NZE) short front vowel shift (SFVS). We describe the corpus we used and the steps we took to create a measurement of “shiftedness”: an index of participation in the vowel shift for each instance of each vowel. We present the results of a linear mixed-effects regression model; we structure the presentation of these results around our main research questions and so the discussion of our results is interwoven with their presentation. Finally, we present some general conclusions.
2 Priming or repetition effects in natural conversation
There is now a long line of research from experimental psycholinguistics showing that when we talk, we tend to reproduce the same linguistic structures that we have recently produced or heard. Within this highly controlled experimental paradigm, participants’ responses to a target stimulus are often influenced by an immediately preceding prime (e.g., Bock, 1986; Bock & Loebell, 1990; Branigan, et al., 2000). The question of whether this phenomenon exists to constrain variation in more natural dialogue has also received some attention. Gries (2005) explores variation in the British component of the International Corpus of English (which contains both spoken and written British English), and Szmrecsanyi (2005, 2006) examines repetition across five syntactic constructions using data from four large spoken corpora of English. Both studies find results that are in many ways similar to those from previous experimental work; at least with respect to the grammatical variables investigated, there is a clear and significant relationship between a speaker’s/writer’s previous use of a variant and the likelihood of the next instance of that variable being of the same variant.
A handful of studies also exist that consider the effects of priming or repetition as a motivating factor in variationist sociolinguistics, again with a focus on morphosyntactic variation. Crucially, these studies also incorporate social motivations on variation into the analysis too. For instance, in Weiner and Labov’s (1983) examination of variation in the agentless passive construction in English, the “mechanistic tendency to preserve parallel structure” (p. 56) was found to constrain this variation much more than any of the other social or linguistic factors considered in the analysis. Similarly, Poplack’s (1980) study of variation in plural marking in Puerto Rican Spanish among immigrants in the USA found that “the presence of a plural marker before the token favors retention of that token, whereas absence of a preceding marker favors deletion” (p. 63). Scherre and Naro (1991, 1992) found a similar tendency with subject–verb agreement and subject–predicate adjective agreement in Brazilian Portuguese. Finally, Travis (2007) reports evidence of syntactic priming in sociolinguistic variation, this time in an analysis of variation in overt subject expression in two dialects of Spanish (New Mexican and Colombian).
Morphosyntactic priming studies have added to our understanding of the cognitive processes operating on language use, showing that where morphosyntactic variation exists in language, an alternative form, once used, has a greater chance of reuse next time. The extent to which these same processes operate to constrain phonetic and phonological variation in natural speech is less clear, largely because most previous work exploring this question (using a corpus-based methodology) has drawn on data from corpora of dyadic conversations, meaning this work did not control for the well-established accommodation effect wherein the speech of two people in conversation becomes more similar over time (Babel, 2010, 2012; Bell, 1984, 2001; Delvaux & Soquet, 2007; Giles & Coupland, 1991; Giles et al., 1991). For instance, Clark (2014), in a study of recency effects in TH-fronting, simply ignored all tokens produced by the interviewer in the analysis. Tamminga (2016, p. 343), in a study of variation in ING and T/D deletion, states that “accommodation is an important phenomenon in its own right,” but that “its relationship to cross-speaker persistence is beyond the scope of this study.” As a result, Tamminga “exclude[s] pairs of tokens that are interrupted by speech from other conversational participants.” Neither of these approaches is terribly satisfying, as both fail to consider the possible (indeed, likely) effects of variants uttered by the interviewer or by an interlocutor on the following phonological variable, which may last beyond the next utterance.
There is one study that does attempt to disentangle potential priming effects from accommodation effects in a corpus of natural speech. Clark (2018) explored recency effects in phonology using speech data from a corpus of spoken monologues called the QuakeBox corpus (Clark et al., 2016). The QuakeBox project came about in the wake of the earthquakes that destroyed much of the city of Christchurch in New Zealand in 2010 and 2011. This collection of spoken stories is uniquely suited to this research question because members of the public were simply asked “tell us your earthquake story” and were then left alone to speak in a mobile recording studio. This means that we can reasonably establish the extent of within-speaker repetition without needing to consider any potential “interference” or accommodation towards an interviewer or interlocutor.
Despite the existence of previous work in corpus linguistics and sociolinguistics showing clear and replicable recency or repetition effects in natural speech, there has been hesitancy about labelling this phenomenon “priming.” For instance, Szmrecsanyi (2005, p. 144) explains “I avoid using psycholinguistic terminology (‘priming’, ‘prime’, ‘target’, etc.) a priori because a corpus-based study may be inappropriate to explicitly investigate psycholinguistic mechanisms such as production priming effects.” Similarly, Tamminga et al. (2016) and Tamminga (2019) avoid describing repetition effects in corpus data as “priming,” as they argue that in corpus data it is non-trivial to disentangle repetition effects that are motivated by priming from those that are motivated by mechanisms like style-shifting, especially if repetitiveness is characteristic of the style being displayed by the speaker. It may also be the case that psychological factors, such as memory retrieval or attention, affect a speaker differently at different parts of a conversation, potentially influencing repetitive behavior in some parts of the discourse only. For this reason, Tamminga prefers to separate the notion of “priming,” an underlying psycholinguistic explanation, from “sequential dependence,” a mechanism in which “the outcome of a sociolinguistic alternation in one moment directly influences the likelihood of a matching outcome some moments later” (Tamminga et al., 2016, p. 33). In contrasting priming from sequential dependence, Tamminga rightly observes that repetition alone is not evidence for priming in corpus data.
Clark (2018) addressed this challenge by outlining two key signatures of priming that are well attested in the experimental literature, then looking for those signatures as interaction effects in a statistical model predicting the likelihood of repetition of a variable form in corpus data. The first signature of priming is the decay effect: repetition effects motivated by priming decay over time so that larger time depths between the prime and target should lead to a decrease in the repetition behavior (Goldinger et al., 1992). Clark (2018) showed that as the time interval increased between two instances of medial /t/ in a speaker’s monologue, the likelihood of repetition between two instances diminished. The second signature of priming is the lexical boost effect. Clark (2018) showed that when two instances of medial /t/ occur sequentially, and both of those instances share the same word, if the first instance is realized as a voiced variant, the second instance is also more likely to be realized as voiced. 1 Clark (2018) explains that this interaction of lexical identity and phonological persistence is reminiscent of the lexical boost effect found elsewhere in research on syntactic priming (e.g., Hartsuiker et al., 2008; Jaeger & Snider, 2013). In this paper, we use the term lexical boost to refer to a possible strong priming effect when the prime and target share the same word (a usage that echoes Clark, 2018, and Tamminga, 2014, 2016). 2
Based on previous findings of repetition effects in corpus data, we have reason to hypothesize that two consecutive instances of language in natural speech may indeed function as the prime and target in much the same way as they do in more controlled experimental studies. The remainder of this paper builds on the groundwork already laid by Clark (2018), and so we use the terms “prime” and “target” to refer to the immediately preceding instance of a vowel variable (the prime) and the current instance (the target), and we again look for the characteristic signatures of priming in our analysis.
We also note that in all of the work cited here, the approach has been to examine repetition or priming in the behavior of a single variable. Yet, we know that individual variables do not behave independently of each other, either because they cluster together to form speech styles and registers (e.g., Eckert, 2000) and/or because they are structurally related in an ongoing systematic change such as a chain shift (e.g., Labov et al., 1972). In this paper, we explore the evidence for priming as a motivating factor in the variation we see in the NZE SFVS.
3 The New Zealand English short front vowel shift
In NZE, the three short front vowel categories
We addressed these questions via a corpus study of spontaneous NZE speech. The following section details the data, dependent variable, and modeling procedure. We then reframe these research questions in terms of specific testable hypotheses.
4 Methods
4.1 Data and dependent variable
The data for this project came from the same source as Clark (2018): the QuakeBox corpus hosted by the New Zealand Institute of Language, Brain, and Behaviour at the University of Canterbury, New Zealand (Clark et al., 2016). We analyzed nearly 60,000 tokens of vowels involved in the NZE SFVS (
Our approach to the data diverged from typical sociophonetic practice in two respects. Firstly, typical sociophonetic practice focuses on tokens that are likely to be “well-behaving” to the exclusion of other tokens; for example, Hay et al.’s (2015) study of NZE short front vowels included only stressed tokens from content words no longer than two syllables. In the context of priming, however, it makes sense to assume that all tokens are relevant for priming—not merely those that are convenient for researchers to measure. As a result, our data set included unstressed vowels and vowels in function words in addition to tokens that are more likely to be “well-behaving.” We did exclude tokens that were actually “ill-behaving” (those that were misaligned by the forced alignment or mis-measured)—as opposed to those we merely suspect to be ill-behaving (due to being unstressed or in grammatical morphemes)—as these inaccurately measured tokens would distort our statistical analysis; we automatically excluded any tokens whose F1 or F2 measurements were more than two standard deviations outside the mean for that speaker and vowel category, and we hand-checked deviant tokens that remained after this exclusion to identify genuine outliers.
Secondly, it is common practice in sociophonetic research to model vowel height and frontness separately (or to model one dimension to the exclusion of the other), typically via the first and second formants. In reality, F1 and F2 display considerable covariation; they do not act independently. This is particularly important to note in the context of a study on priming where we might expect that the previous production of a vowel might have an impact on the production of the next instance of a vowel in that same category; for example, we would predict that an immediately preceding instance of
The shift index was calculated as follows, schematized in Equation (1) and Table 1. We first extracted vowel measurements from the QuakeBox corpus then normalized F1 and F2 measurements using the Atlas of North American English method, with the default G value (Labov et al., 2006). Next, for each vowel v, we calculated each speaker’s standard deviations for F1 and F2, and took the mean of those standard deviations (
Measures used in calculating the shift index for each vowel category v.
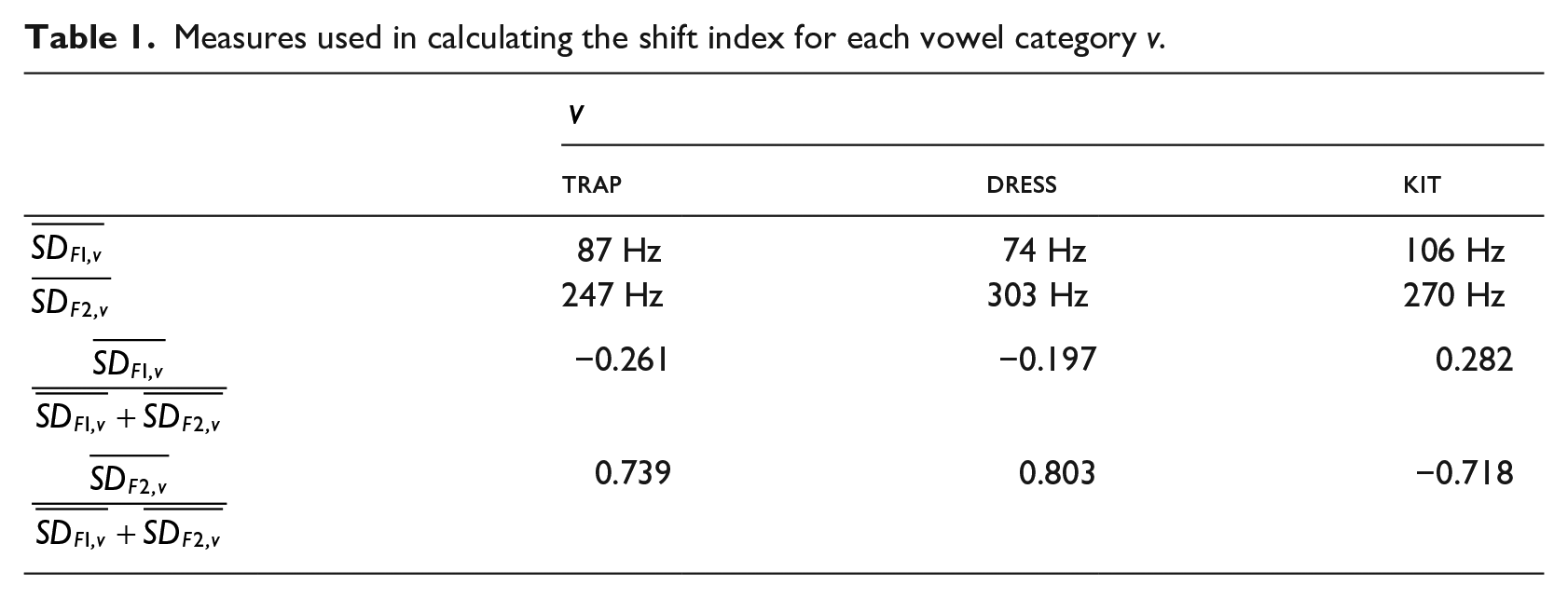
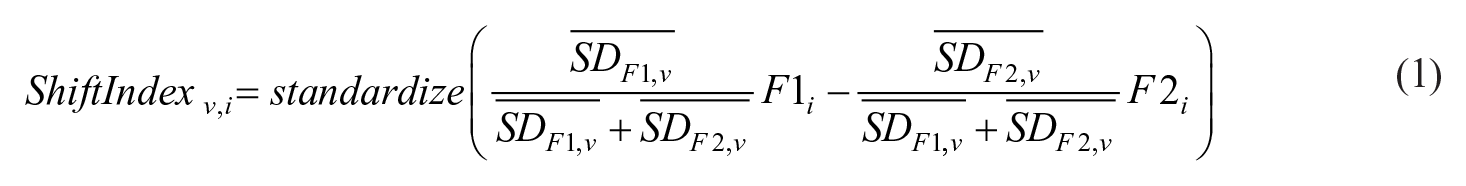
As a result of this calculation, each token of each vowel had a single measure of shiftedness with respect to the SFVS. Calculating and standardizing the shift index separately for each vowel permitted apples-to-apples comparisons of the shiftedness of vowel realizations, even if they belonged to different vowel categories. Note that we calculated the shift index between speakers rather than within speakers, meaning that, for example, a
To help visualize how variation in F1–F2 space translated to shift index variation, Figure 1 displays shift index axes for each vowel category. The symbols
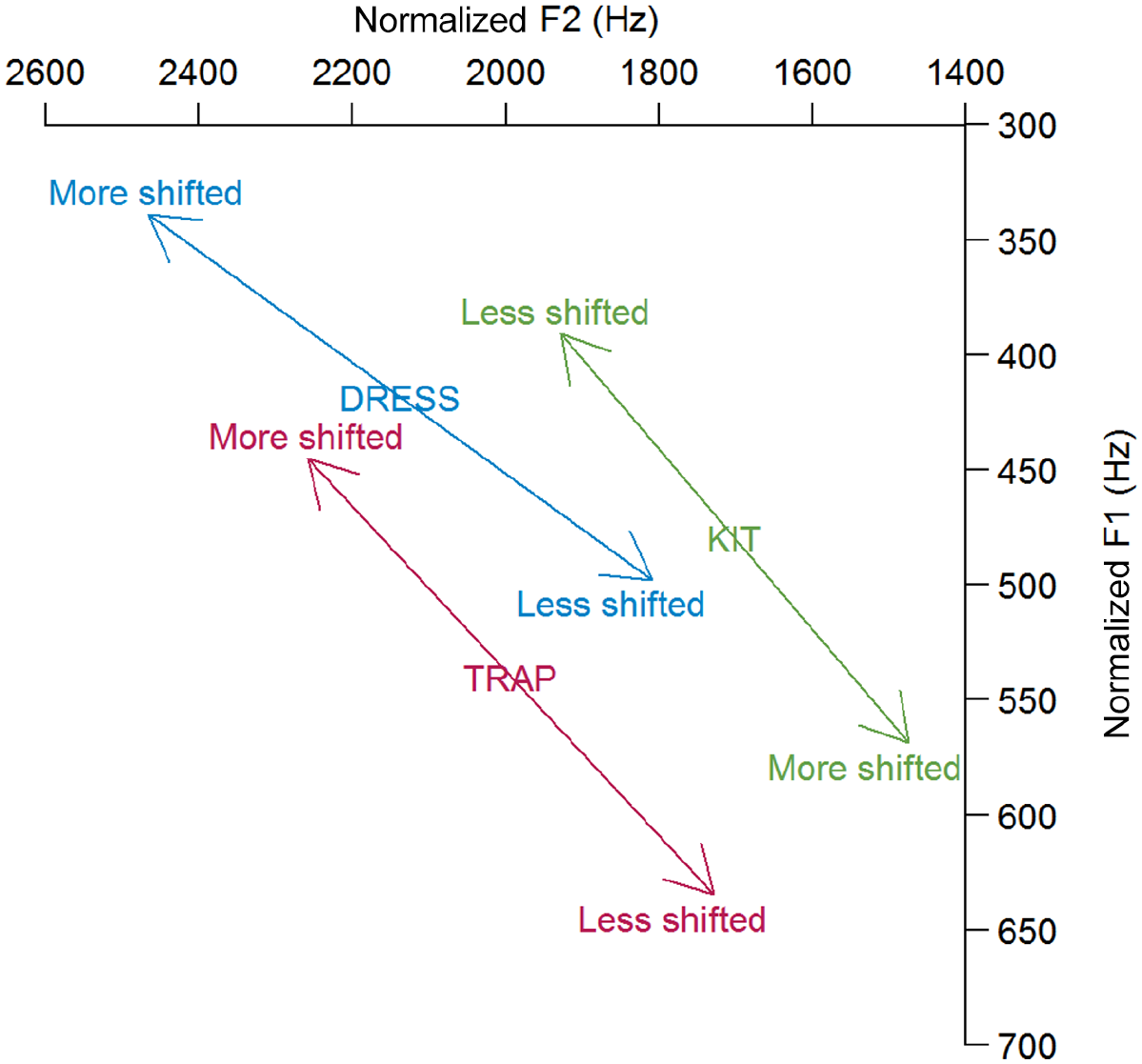
Shift index axes for the vowel categories in this study. For each vowel, the arrowhead at “Less shifted” marks a hypothetical token with a shift index of −1, the vowel symbol marks a token with a shift index of 0, and the arrowhead at “More shifted” marks a token with a shift index of +1; tokens varying perpendicularly to these axes would share the same shift index values. The
After calculating the shift index, we made a number of additional exclusions to the data. Firstly, since we modeled repetition by looking at how each token was affected by the immediately preceding token, we excluded each speaker’s first short front vowel token because the immediately preceding token, occurring before the recording started, was unknown. For the same reason, our model excluded outliers and tokens that immediately followed outliers. That is, if token i was an outlier, then the target shift index for token i was unreliable, and since the target shift index for token i served as the prime shift index for token i + 1, both tokens were excluded; since this did not affect the target shift index for token i + 1 (i.e., the prime shift index for token i + 2), token i + 2 was not excluded. Secondly, because we assume that exemplars are constructed at the level of the individual word (e.g., Docherty & Foulkes, 2014), we excluded tokens whose prime was in the same word as the target (e.g., the target
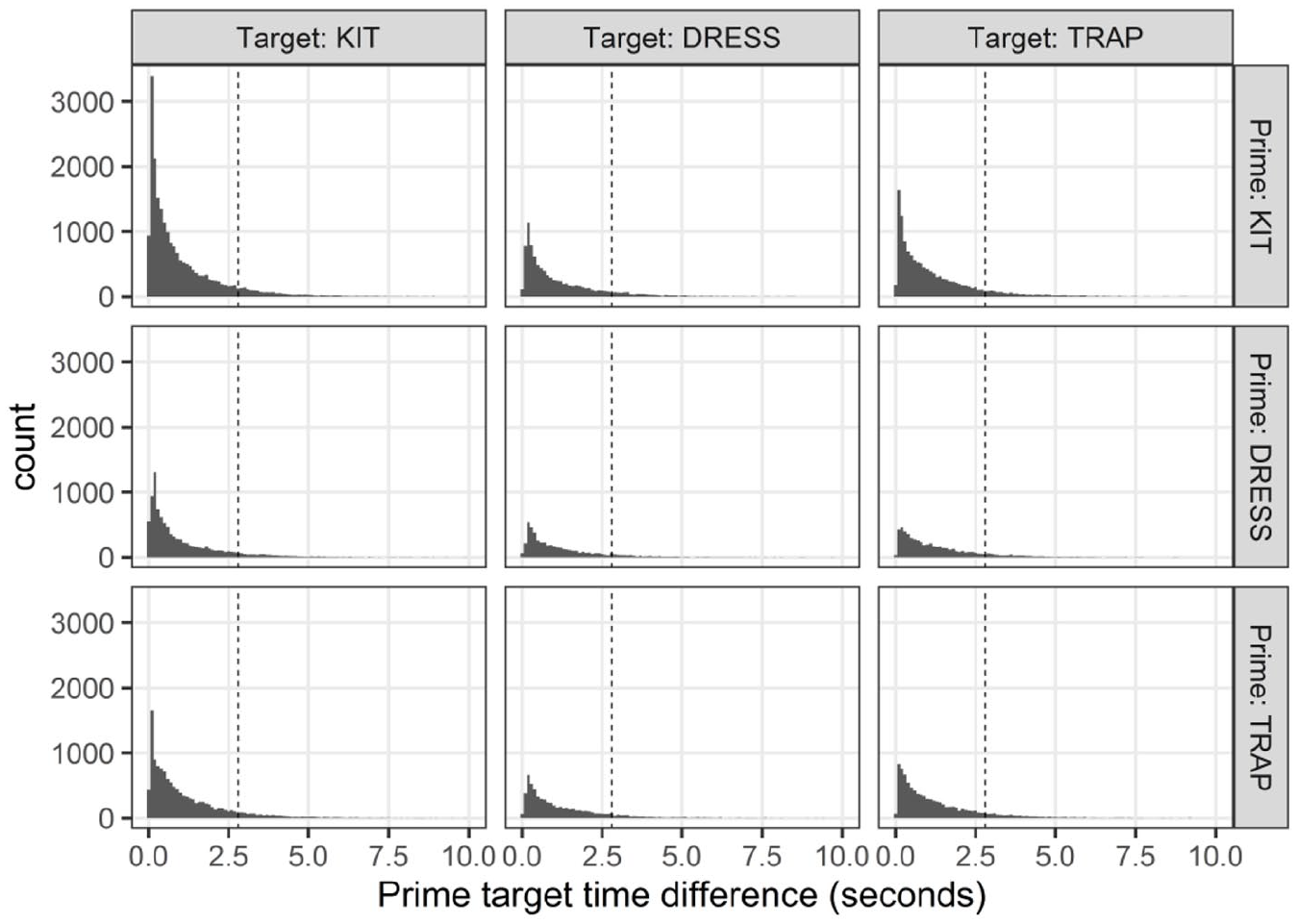
Prime target time difference distributions by target vowel category and prime vowel category. The dotted line marks the 90th percentile of overall distribution (2.8 seconds); tokens with a prime target time difference longer than this cutoff were excluded from the model.
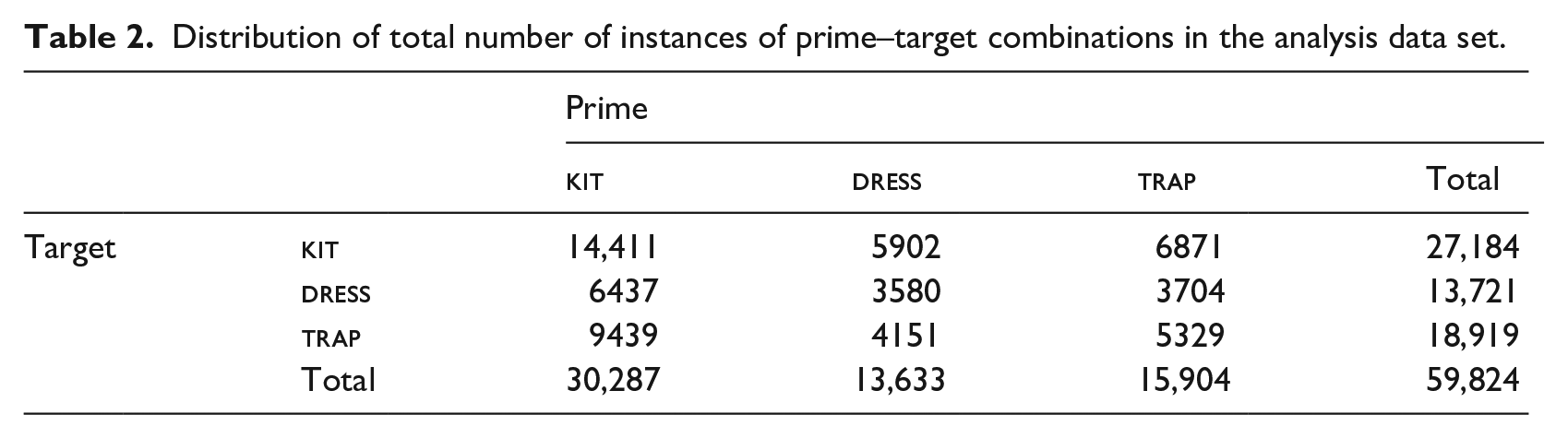
Distribution of total number of instances of prime–target combinations in the analysis data set.
4.2 Modeling procedure
We carried out statistical analysis via mixed-effects modeling in R (R Core Team, 2018) using the package lmerTest (Kuznetsova et al., 2016), which calculates significance levels using Satterthwaite’s (1946) approximation for degrees of freedom. The target shift index was the dependent variable in these models; for categorical predictors, contrasts were coded via treatment coding (i.e., treating one level as the “baseline” level). We started with a baseline model that was designed to address RQ1 and RQ2 (i.e., assessing priming in the SFVS, within and across vowel categories). This model included fixed-effects predictors corresponding to priming effects (RQ1): prime shift index (repetition effect), prime target time difference (decay effect), and prime target same word (lexical boost effect). The baseline model also included the vowel categories of the prime and target as fixed-effects predictors (RQ2), as well as random intercepts and random prime shift index slopes for individual speakers and target words. All of the fixed-effects predictors in the baseline model yielded significant effects.
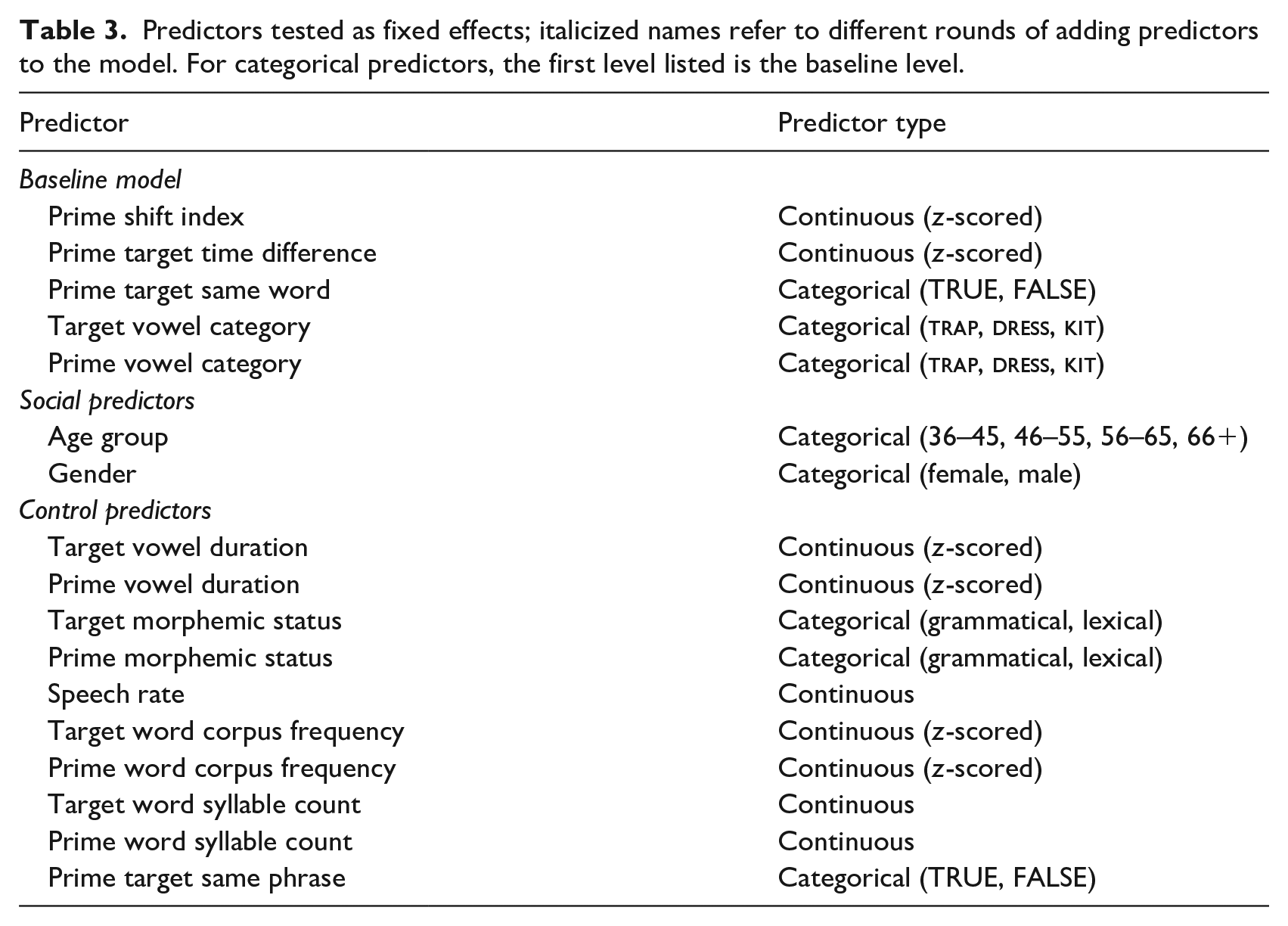
We then tested additional predictors in two rounds. In order to address RQ3, we tested social predictors available in QuakeBox: gender and age group. We then tested internal predictors to control for additional phonetic, phonological, morphological, and lexical effects influencing variation in the SFVS. Predictors were only added if the resultant model converged, did not suffer from excessive collinearity, 7 and significantly improved upon the fit of the previous model (assessed via a likelihood ratio test at α = .05); if multiple candidate predictors satisfied these criteria, the predictor that yielded the greatest improvement in model fit was added first, as measured by the Akaike information criterion (Akaike, 1974). When predictors were added to the model, by default they were added as four-way interactions with the prime shift index, target vowel category, and prime vowel category; where possible, these interactions were reduced to lower orders based on whether the higher-order terms significantly improved model fit. Table 3 shows the predictors that we tested by round. We report only the results from the final model.
Predictors tested as fixed effects; italicized names refer to different rounds of adding predictors to the model. For categorical predictors, the first level listed is the baseline level.
We note that while collinearity (the dependence of one predictor on another) is to be avoided in any multiple regression model as a matter of statistical due diligence, it was especially important in the present study given our research questions about the phonetic shape of the target being influenced by that of the prime. Models that suffer from collinearity overstate the effects of the collinear predictors; by avoiding collinearity in our models, we eliminated the possibility that any apparent priming effect was merely a statistical artifact. This statistical due diligence is thus necessary because it preserved the model’s inferences for the predictors corresponding to our core hypotheses (see below). We do recognize, however, that readers may wish to entertain different hypotheses about the data that spotlight different predictors than we did, given that we were unable to assess significance for predictors excluded due to collinearity. To that end, we have made the data for this analysis available at https://github.com/nzilbb/Priming-SFVS-Data so readers can assess alternative modeling procedures.
5 Hypotheses
Based on our research questions, we propose the following hypotheses.
As described in the preceding section, our modeling procedure was designed to test these hypotheses by first starting with the baseline predictors in Table 3 (corresponding to RQ1 and RQ2), then testing social predictors (RQ3), then testing control predictors that influence variation in the SFVS.
6 Results
Our model of the target shift index includes the baseline predictors (prime shift index, prime vowel category, target vowel category, prime target time difference, prime target same word), one social predictor (gender), and two control predictors (prime morphemic status, speech rate). 8 There were numerous significant higher-order interactions among these predictors, as the interaction of the prime shift index and target vowel category interacted with all other predictors. Online appendix A details the final model structure and output. As we discuss in more detail below, the model broadly indicates support for hypotheses 1 and 3, and partial support for hypothesis 2.
Readers should note that, as a result of the criteria for adding predictors, the exclusion of a given effect from a model does not necessarily indicate nonsignificance; predictors were not assessed for significance if adding them to the model caused non-convergence or excessive multicollinearity, and in fact, all of the predictors in Table 3 that were not included in the model were excluded due to multicollinearity. In other words, it is possible that some effects that influence variation in these vowels in this community are nevertheless excluded from the model because their inclusion causes the model to be untenable. To that end, we have made the data for this analysis available at https://github.com/nzilbb/Priming-SFVS-Data so readers can test how the modeling pans out differently under assumptions other than those that guided our modeling procedure.
In our model of the target shift index, the prime shift index was significant in all two-way and three-way interactions with the prime vowel category and target vowel category (ps < .001). As a result of these interactions, the main effect of the prime shift index is not meaningful on its own, so in the following section we address RQ1 and RQ2 at the same time.
6.1 RQ1 and RQ2: Priming of the SFVS, across and within vowel categories
The model of the target shift index indicated evidence of effects—repetition, decay, and lexical boost—that are key signatures of priming, across the SFVS as a whole. In other words, our findings indicate evidence to support hypothesis 1, as we demonstrate in this section. With respect to RQ2, these priming effects were also present both across and within vowel categories. However, these results ran counter to other expectations in hypothesis 2. Most notably, the cross-vowel priming results for SFVS vowels changing in opposite directions (
In Figure 3, the effect of the prime shift index on the target shift index is broken down into the nine possible prime–target combinations in our data. If hypothesis 2 were correct (more-shifted tokens should prime more-shifted tokens), a positive relationship of the prime shift index and target shift index should be replicated in all nine facets, given that the shift index increases in the direction of shift regardless of vowel category (Figure 1). Instead, this positive relationship is replicated in just five facets: all three within-category prime–target combinations, plus two cross-category combinations (
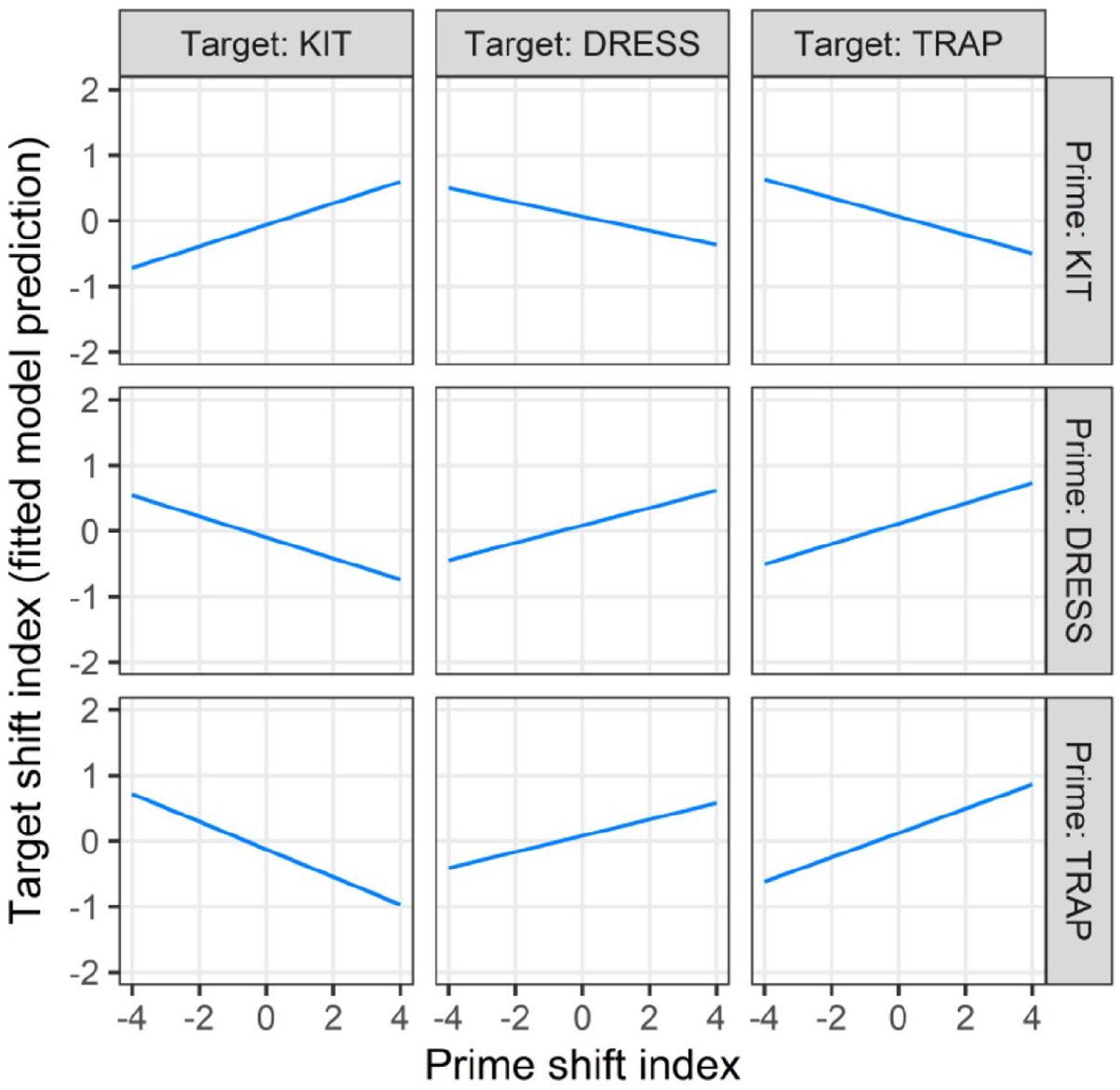
Predicted target shift index by the prime shift index, target vowel category, and prime vowel category.
The effect of the prime shift index on the target shift index was mediated by two other priming predictors: prime target time difference (decay) and prime target same word (lexical boost). The prime shift index had a significant negative interaction with prime target time difference, indicating that the strength of the repetition effect displayed in Figure 3 is mitigated by the amount of time between the prime and target. In particular, we can interpret the slope of the line in the target shift index–prime shift index Cartesian space as indicating the strength of the repetition effect, with steeper lines indicating a stronger effect of the prime shift index on the target shift index and thus a stronger repetition effect. Given that visual interpretation, Figure 4 demonstrates the strongest repetition effect when the prime target time difference is at its minimum, 20 milliseconds (since the darkest line has the steepest slope), a weaker effect when the prime target time difference is at its median, 670 milliseconds (since the medium-blue line has a shallower slope), and a weaker effect still when 2.8 seconds separate the prime and target (since the lightest line has an even shallower slope, nearly leveling off completely in some cells). In other words, these data exhibit a decay effect characteristic of priming.
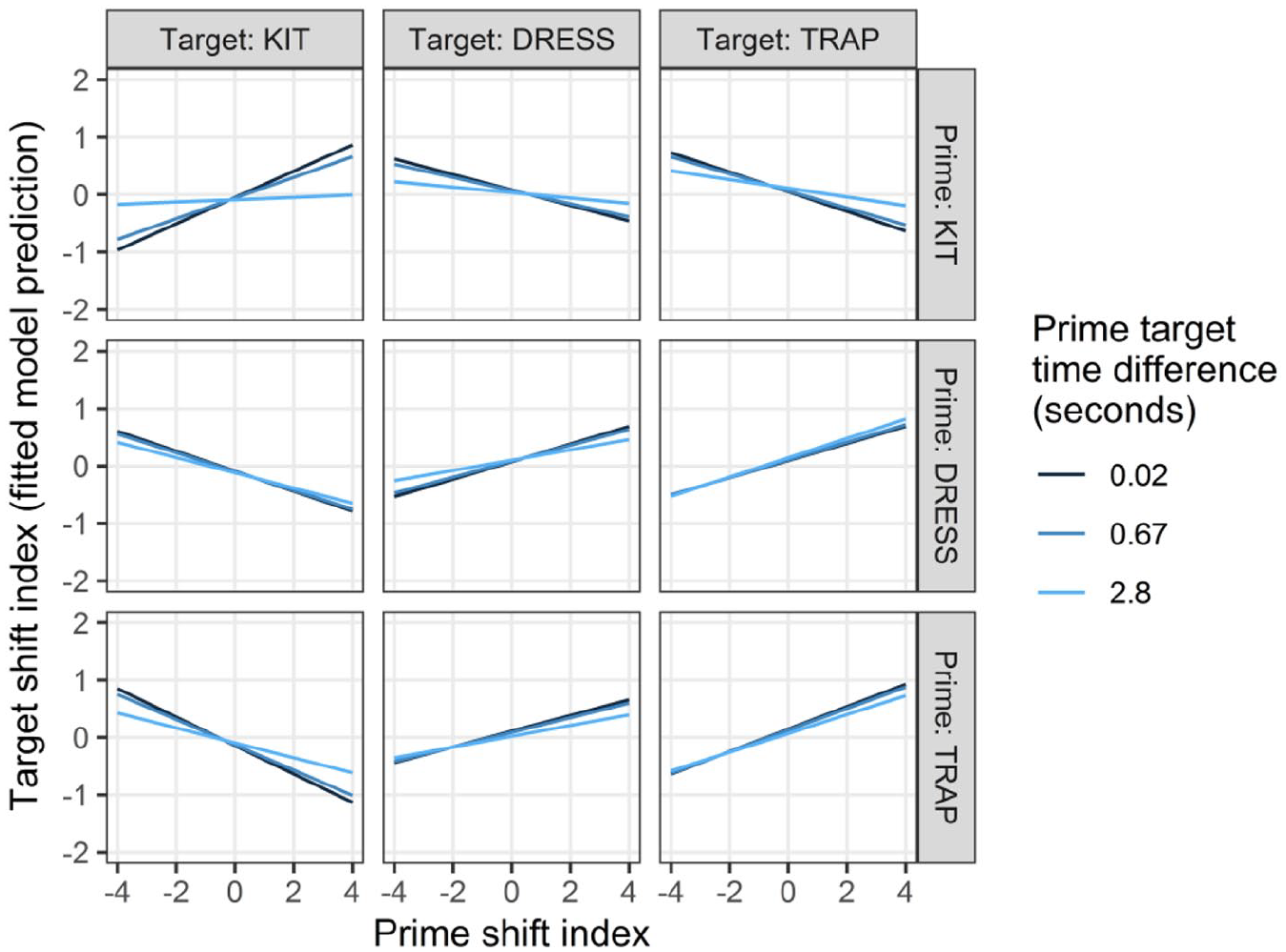
Predicted target shift index by the prime shift index, target vowel category, prime vowel category, and prime target time difference. The prime target time difference values at which lines are plotted represent the minimum, median, and maximum time differences in this data. (Color online only.)
This interaction was significant across all three-way and four-way interactions with the prime vowel category and target vowel category (ps < .001), meaning that this decay effect was present across all prime–target combinations, albeit with stronger decay effects for some prime–target combinations and weaker decay effects for other combinations. Moreover, this decay effect proceeds rather rapidly. The repetition effect is strongest at a 20 millisecond prime target time difference; when the time difference grows to merely 670 milliseconds, the repetition effect diminishes considerably, as evidenced by the shallower slopes of these lines.
The prime shift index also had a significant positive interaction with prime target same word, with a stronger repetition effect when the target word was a repetition of the prime word. In other words, these data exhibit a lexical boost effect characteristic of priming. Unlike the repetition and decay effects, this lexical boost effect does not appear to be mediated by the vowel category of the prime or target (although Figure 5 suggests a weak trend in this direction), as there were no significant three-way interactions between the prime shift index, target vowel category, and prime target same word (ps > .12). 9 Taken together, these results indicate support for hypothesis 1, as we find repetition, decay, and lexical boost effects that are often taken to be key signatures of priming in speech.
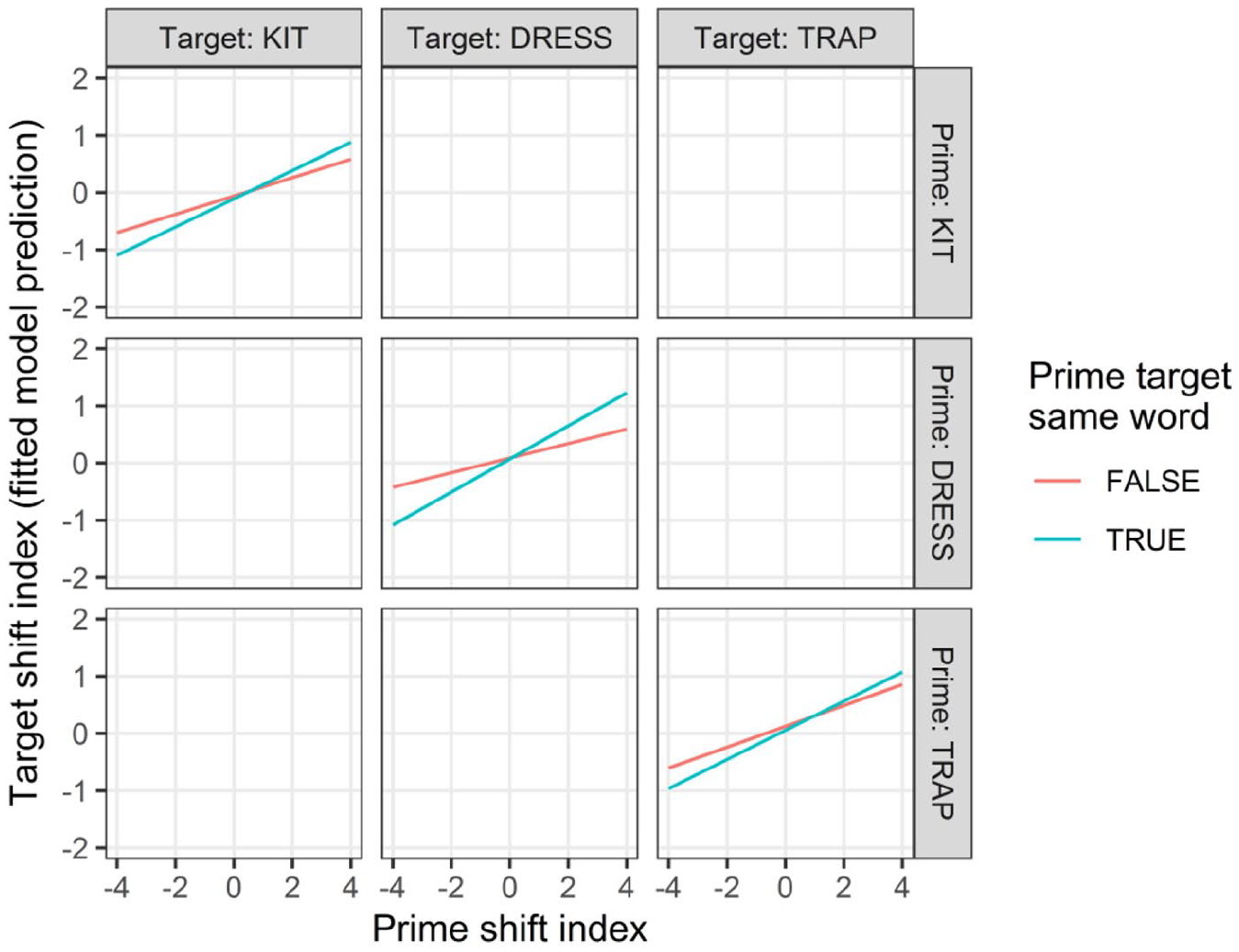
Predicted target shift index by the prime shift index, target vowel category, prime vowel category, and prime target same word.
Readers may wonder whether the effect of the prime shift index is driven by interspeaker variation rather than intraspeaker priming, with some speakers having more shifted vowels overall than other speakers and all speakers hitting their own targets repeatedly. Mitigating against this interpretation is our inclusion of speaker as a random effect in the model. If the variation in our data were merely interspeaker variation, then the random intercept of speaker would “soak up” all of this variation, leaving nothing for the effects of the prime shift index to account for (Tamminga, 2016); instead, the prime shift index shows up as significant in our model. We thus reject the claim that the repetition effect is the result of interspeaker variation. 10
6.2 RQ3: Priming and social factors
Before discussing the effect of gender on priming behavior, it is worth mentioning that women were more shifted (i.e., further along in the NZE SFVS) than men overall (see Figure 6), with the largest difference between men and women in the
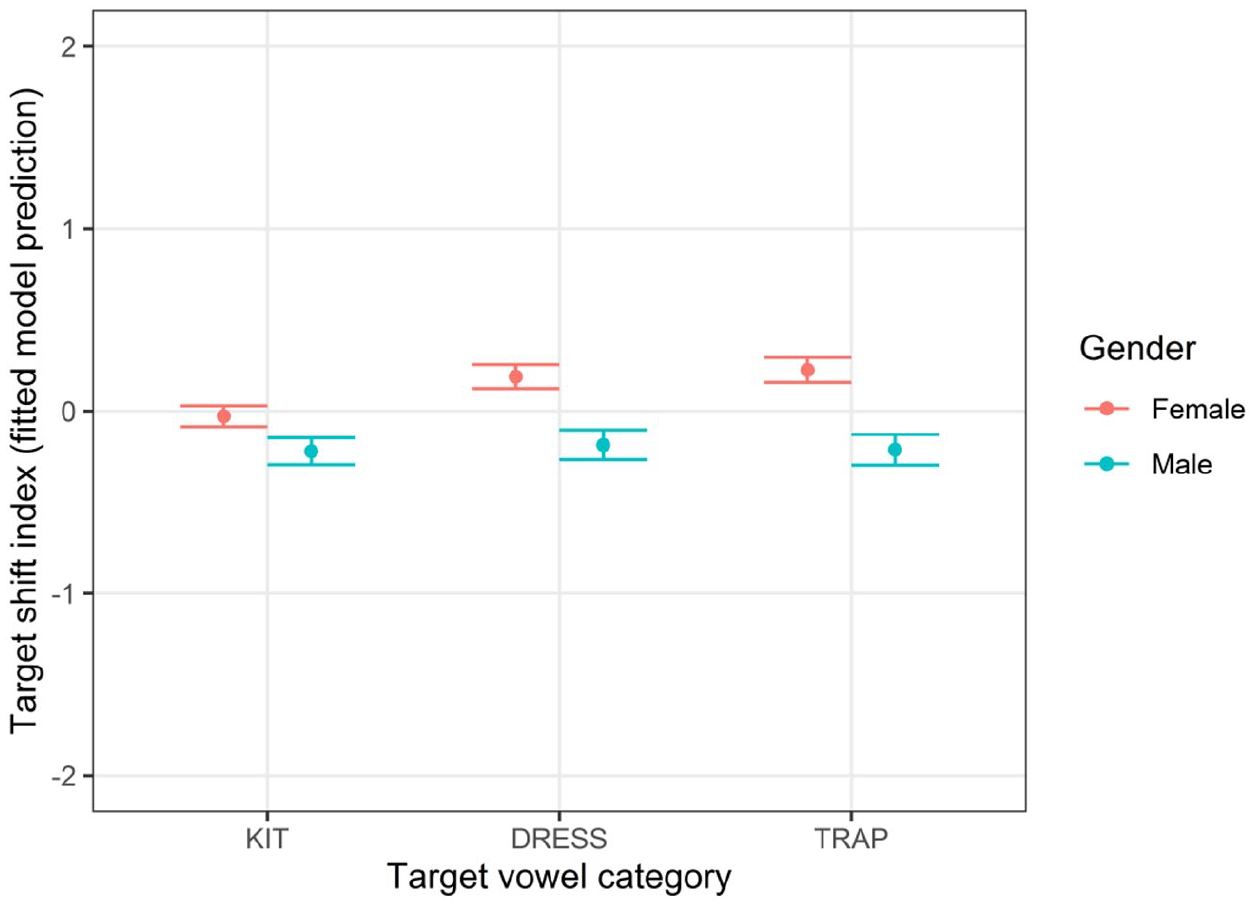
Predicted target shift index by gender, with 95% confidence bars.
The model included significant interactions between the prime shift index and gender, indicating that priming behavior did not apply uniformly across gender. In particular, the repetition effect was stronger among men than women, although this pattern is more pronounced in some prime–target combinations than others. For example, as Figure 7 shows, men’s repetition effect is stronger than women’s with
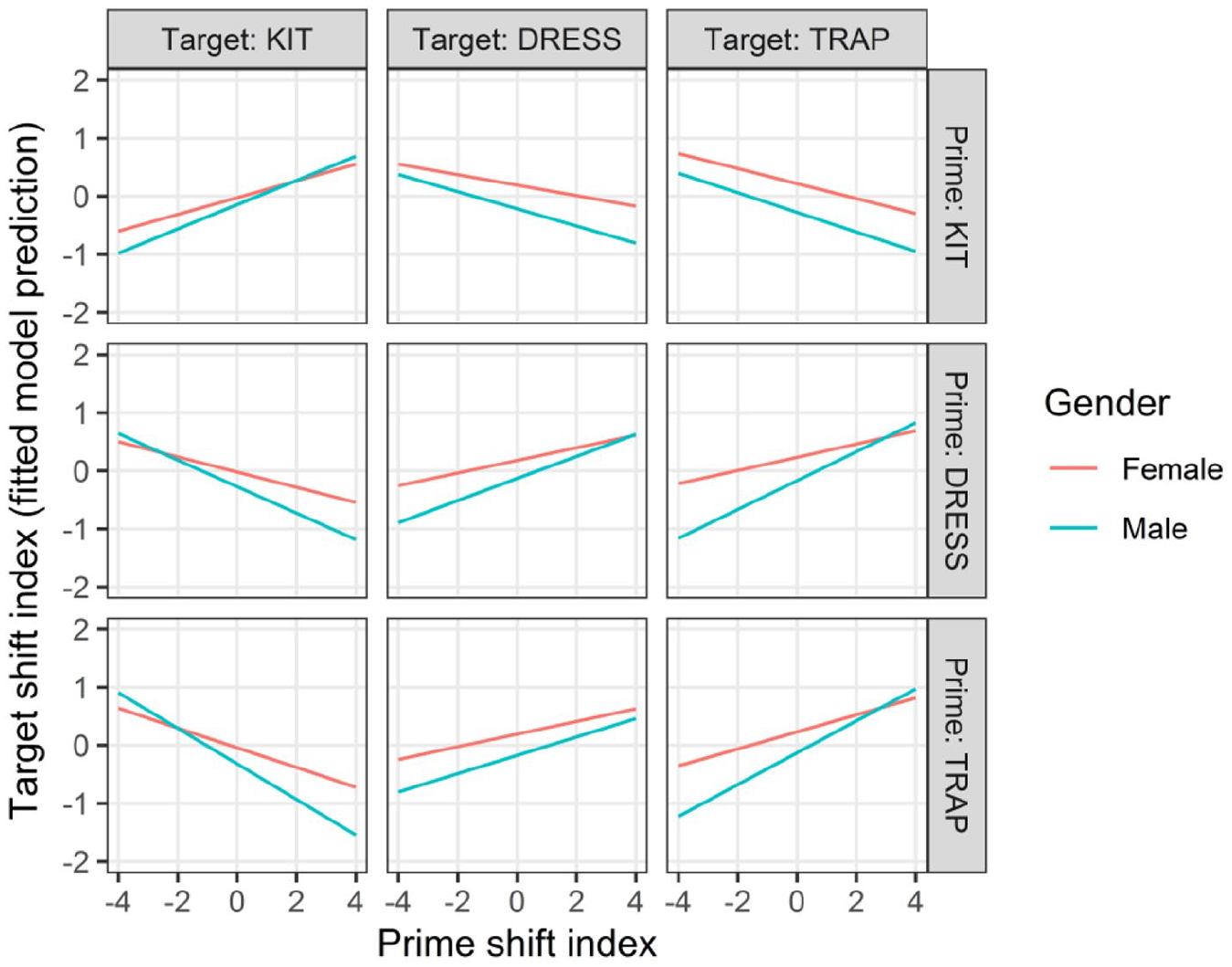
Predicted target shift index by the prime shift index, prime vowel category, target vowel category, and gender.
We can entertain at least two hypotheses for this surprising gender effect: stylistic cohesion and shift boundedness. The first hypothesis posits that this result is simply caused by speakers’ use of similar variants in successive productions reflecting their projection of styles. For this to be the case, we would need to imagine that men in New Zealand project more cohesive styles than women, hence there is less priming among the women (for some vowel combinations) because there is less consistency in shiftedness of prime–target combinations. This account seems unlikely, as the broad claim that men maintain more cohesive styles than women is generally not reflected in the literature on style. Our skepticism aside about this hypothesis aside, it would be supported by a finding that style-shifts are associated with diminished priming behavior. 11
An alternative hypothesis for this finding that the priming effects are stronger (for some vowel combinations) among men may be related to the fact that women appear to lead men in the SFVS overall (Figure 6; see also Hay et al., 2015). If there are more women than men for whom the shift is nearing completion, then their productions are likely to be less variable than the men’s, meaning that they have less room to prime themselves because their primes start out from a more shifted position than men’s primes do. This hypothesis would be supported by a finding that younger speakers, who are further advanced in the shift in apparent time (Hay et al., 2015), have smaller repetition effects. Unfortunately, we were unable to directly test this interpretation in this data set given the due-diligence approach to collinearity adopted by our modeling procedure (see Section 4.2), since models that attempted to add age group as a predictor suffered excessive collinearity. Further investigation is needed to assess these hypotheses and shed greater light on the effects driving the interaction of priming and social factors in the present data.
In summary, these results indicate support for hypothesis 3 (as far as is possible with only one social variable), as we do observe differences in priming behavior for women and men. However, it is not immediately clear why these differences occur.
6.3 Control predictors
The model of the target shift index also included two significant control predictors that were not directly related to any of our hypotheses: speech rate
12
and prime morphemic status. As mentioned above, these predictors were included to control for additional linguistic factors influencing variation in the SFVS. With respect to speech rate, in most prime–target combinations, the repetition effect is diminished with a faster speech rate; this pattern is reversed for two prime–target combinations, as for
With respect to the morphemic status of the prime word, in most prime–target combinations, the prime exerts a stronger effect on the target when the prime is a lexical morpheme than when the prime is a grammatical morpheme (Figure 8). This effect is strongest for
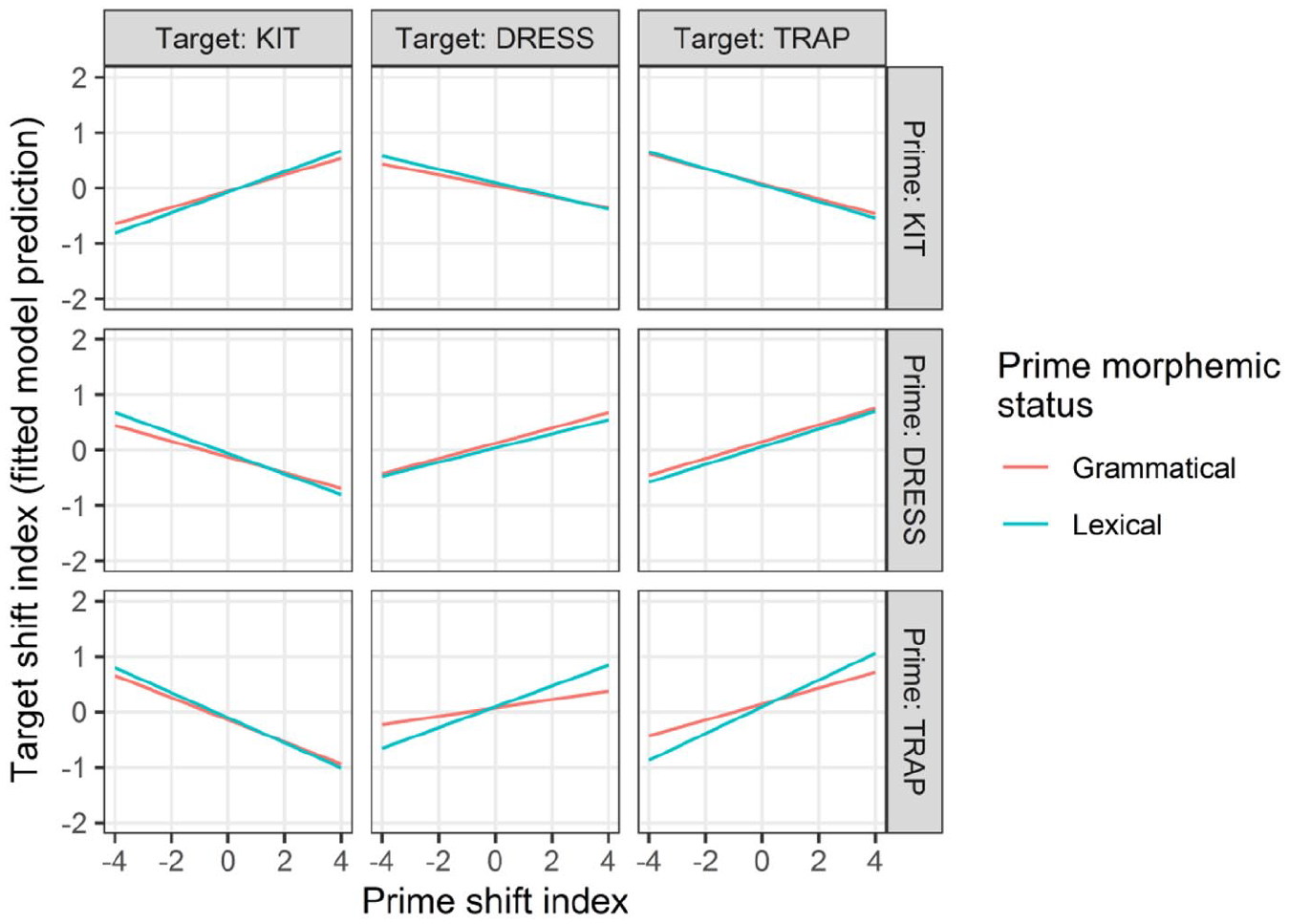
Predicted target shift index by the prime shift index, target vowel category, prime vowel category, and prime morphemic status.
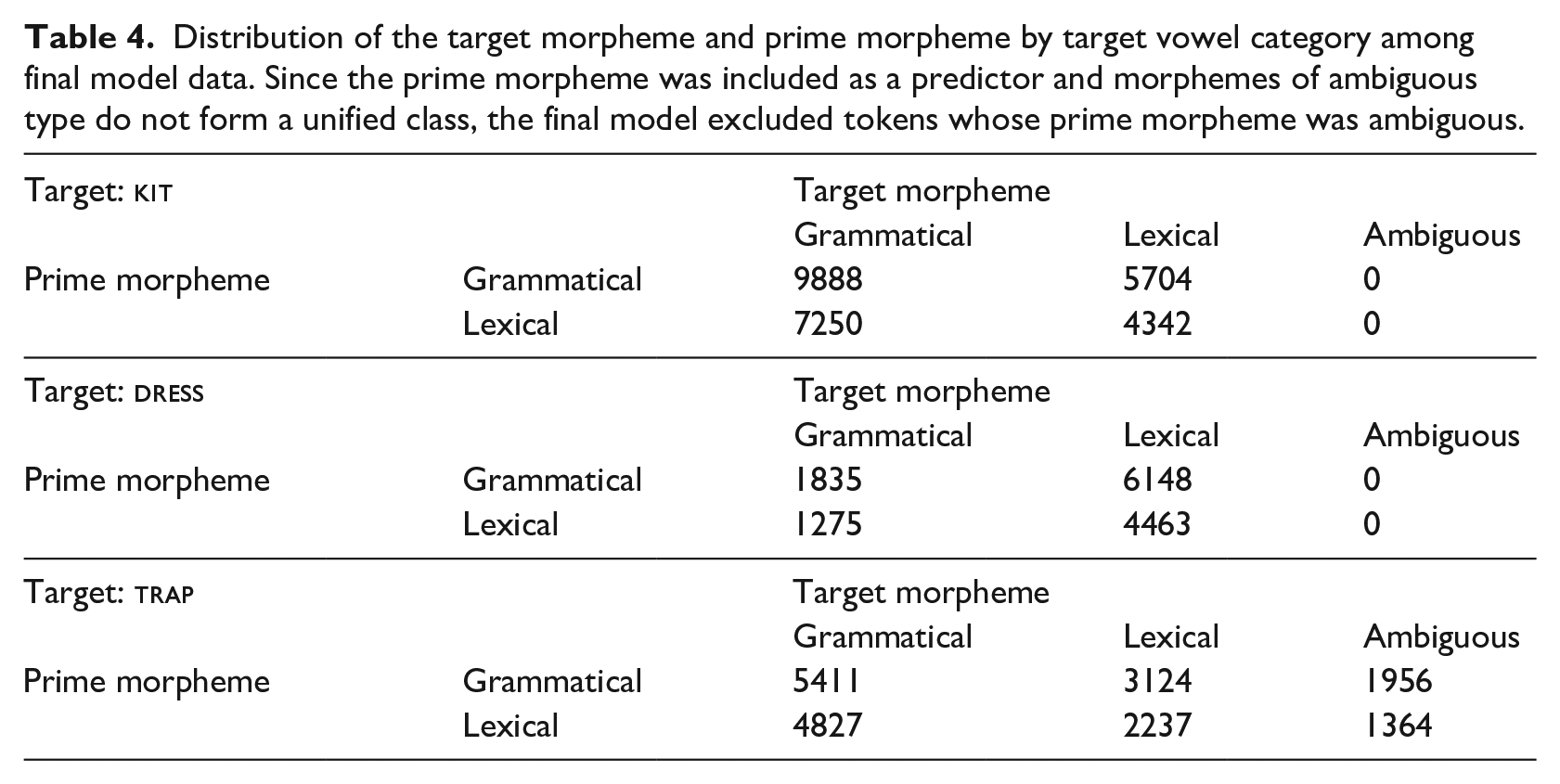
Distribution of the target morpheme and prime morpheme by target vowel category among final model data. Since the prime morpheme was included as a predictor and morphemes of ambiguous type do not form a unified class, the final model excluded tokens whose prime morpheme was ambiguous.
7 Discussion
Previous work exploring repetition or recency effects in corpora of natural talk have taken a variable-centric approach and asked: does a speaker’s previous realization influence their following realization for a given variable feature in language? This previous work has largely shown that repetition effects that occur in natural speech in real time are strikingly similar to those found in experimental studies of priming. However, while these findings represent a useful first step in broadening our understanding of whether and how priming might operate to constrain variation in natural speech, they are limited in their focus on single variables in isolation; we argue that a single-variable approach to priming misses an important part of the picture given strong empirical evidence that variables do not behave independently of each other, either because they form part of a speech style or because they are structurally related, as in the case of vowel shifts.
While holding constant a number of known social and linguistic predictors of variation on the NZE SFVS, and including random effects of word and speaker, our model revealed a repetition effect such that the phonetic shape of each instance of the NZE SFVS could be predicted in part by the phonetic shape of the previous instance. Importantly, this repetition effect also interacted with both the time difference between the prime and the target (i.e., decay) and the repetition of the same lexical item in the prime and target (i.e., lexical boost) in ways that are to be expected if this repetition effect is at least partially motived by priming.
This repetition effect occurred both within vowel categories and across vowel categories in the SFVS, such that the phonetic shape of (for example) an instance of
A social factor, gender, was found to influence the overall production of the NZE SFVS in expected ways, with women leading the shift. More importantly, gender also interacts with priming effects, suggesting that priming does not necessarily apply uniformly across all social groups. There is, of course, no reason to expect that priming should be different across different social groups and so the existing psycholinguistic literature on individual speaker differences in priming does not consider this (as discussed above, the argument is often that differences in working memory or, depending on the priming task, reading strategy, account for these differences). However, in the case of a sound change in progress that is socially conditioned in a community, it may well be the case that the social and the cognitive constraints operating on that sound change interact with one another. Again, in line with Clark (2018), this paper suggests that there may be good reason to suspect that social factors can and do constrain priming behavior.
This study also has methodological implications for research in language variation and change, arguing in favor of often-overlooked phenomena and data. Ours is hardly the first variationist study finding a priming effect (Clark, 2014, 2018; Poplack, 1980; Scherre & Naro, 1991, 1992; Tamminga, 2016, 2019; Travis, 2007; Weiner & Labov, 1983), although it is unique in examining priming in continuous phonetic variation. Given that accounting for the factors influencing language variation and change is a central pursuit of variationist theory (i.e., the constraints question of Weinreich et al., 1968), this body of work strongly suggests that variationist researchers should at least attempt to include priming predictors as control variables in their statistical models (we say “attempt” because doing so may not always be statistically feasible). In addition, this study’s approach to vowel data diverged from typical sociophonetic practice in two ways (see Section 4.1). We declined to exclude tokens that are usually excluded on suspicion of being “ill-behaving” (unstressed vowels, vowels in grammatical morphemes), and we measured vowel shifts along tilted axes using vowel-specific combinations of F1 and F2, in contrast to the usual approach of modeling F1 and F2 separately (e.g., Hay et al., 2015) or Labov et al.’s (2013) approach of using the same tilted axes for multiple variables. In particular, the inclusion of as many tokens as possible allowed us to detect a difference in the strength of the repetition effect according to prime morphemic status. We suggest that future sociophonetic research should be more open to including tokens in grammatical morphemes so future research can better illuminate the role that grammatical morphemes play in vowel change. 14
7.1 What underlies these phenomena?
It remains an open question which mechanism(s) underlie the findings we have presented here. We can think of at least three possible accounts, which we label “articulatory,” “psycholinguistic,” and “socio-stylistic.” None are sufficient on their own to fully explain the phenomena we have presented here, and, following Tamminga (2019), there is reason to believe these mechanisms are not mutually exclusive. We have already discussed and rejected a fourth possible explanation—that the repetition effect is an artefact of interspeaker variation—on the grounds that any baseline interspeaker variation is accounted for by the random intercept of speaker in our model.
The “articulatory” account explains these findings as a function of articulatory setting (e.g., jaw height): within a given stretch of discourse, speakers adopt a baseline jaw setting that is relatively higher or lower than their overall jaw setting, meaning two consecutive SFVS tokens are likely to be produced with the same jaw setting and therefore a similar height. The finding that most supports this account is the particular patterns of priming across vowel categories, with high and front
The “psycholinguistic” account explains the findings in terms of mechanisms that are usually labeled “priming” (in the specific psycholinguistic sense of the term “priming”) as opposed to “recency” or “persistence.” One such mechanism relies on spreading activation. When speakers use a high and front SFVS prime, it increases the resting activation level of exemplars with a matching acoustic representation, within the exemplar distribution for that word (with this additional activation for the prime decaying over time); as a result, when the speaker retrieves a target, they are more likely to retrieve an exemplar similar to that of the prime. In this account, a word match between the prime and target also increases the likelihood of retrieving a target similar to the prime, because the target is being retrieved from the exemplar distribution corresponding to the most recently activated lexeme. Most crucially, the decay that we see is highly indicative of spreading activation, so it is really the decay effect that most clearly adds weight to our interpretation of these results as priming.
16
The “psycholinguistic” account thus provides a natural explanation for the effects found in our data: repetition, lexical boost, and—perhaps the effect that most closely resembles those found in the priming literature more generally—decay. The cross-category priming effects in our data are also reminiscent of the phenomenon reported by Travis et al. (2017), wherein within-language priming of variable subject expression was stronger than cross-language priming. A similar mechanism could perhaps apply to vowel variables coexisting in a monolingual speech community, for example if the speech community considers variation in
The “socio-stylistic” account explains these findings in terms of the construction and maintenance of sociolinguistic styles and registers (e.g., Eckert, 2000). Similar phonetic variants of socially meaningful variables exhibit temporal clustering as speakers project cohesive styles, with covariation among variants of different variables that are bound together through bricolage (e.g., Eckert, 2008), enregisterment (e.g., Agha, 2004), or some other means of conveying social meaning through covariation. As speakers move through the discourse, they agentively alter their variation to reflect and constitute different topics, stances, styles, and levels of formality (Eckert, 2018). While the socio-stylistic account straightforwardly explains the repetition effect, it fails to adequately explain the other core priming effects: decay and lexical boost. While a longer prime target time difference means a greater likelihood of a switch in styles, registers, etc., between the prime and target, the plausible time-scale of such an effect conflicts with our findings; it seems implausible that there should be much difference between a 20 millisecond delay and a 670 millisecond delay in terms of switching styles. Likewise, the socio-stylistic account cannot explain the lexical boost effect. Although individual lexical items may be suffused with particularly strong indexical meanings, such as the intensifier/determiner hella triggering an association with Northern California (Bucholtz et al., 2007), the lexemes in our data for which the target word matched the prime word were overwhelmingly function words (e.g., that, it, is, and) that are unlikely to be the site of lexically specified social meaning-making. Finally, while the socio-stylistic account focuses on covariation of different variants, it likely would not predict the specific patterns of priming across vowel categories found here. Given the historical association of
8 Conclusion
Although the driving mechanism for these findings remains an open question, we have demonstrated that continuous phonetic variation is indeed subject to intraspeaker priming, exhibiting repetition, decay (albeit on a shorter time-scale), and lexical boost effects that are characteristic signatures of priming. We also find that priming takes place across vowel categories that are interrelated by their membership in the NZE SFVS, although in a direction that potentially suggests articulatory motivations (peripherality) rather than social motivations (chain shifting and indexical linkages). Contrary to typical theories of priming that are predicated on spreading activation and assume only individual differences in priming behavior, we find evidence for differential priming behavior between women and men. In summary, the present research adds to a growing body of literature highlighting the important role that intraspeaker priming plays in shaping sociolinguistic variation.
Supplemental Material
sj-pdf-1-las-10.1177_00238309211053033 – Supplemental material for Intraspeaker Priming across the New Zealand English Short Front Vowel Shift
Supplemental material, sj-pdf-1-las-10.1177_00238309211053033 for Intraspeaker Priming across the New Zealand English Short Front Vowel Shift by Dan Villarreal and Lynn Clark in Language and Speech
Footnotes
Acknowledgements
The authors would like to thank members of the New Zealand Institute of Language, Brain and Behaviour for their feedback and support, as well as audiences at the New Zealand Linguistics Society, Sociolinguistics Symposium 22, and the University of Delaware Department of Linguistics and Cognitive Science. All errors are ours entirely.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a Royal Society of New Zealand Marsden Research Grant (13-UOC-032).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.