
Abstract
Information about the diploid genotype of a gene-modified or mutant laboratory animal is essential for breeding and experimental planning. It is also required for the exchange of animals between different research groups or for communication with professional genotyping service providers. While there are detailed, standardized rules for creating an allele name of a genome modification or mutation, the notation of the diploid genotype after biopsy and genotyping has not been standardized yet. Therefore, a uniform, generally understandable nomenclature for the diploid genotype of gene-modified laboratory animals is needed. With the here-proposed nomenclature recommendations from the Committee on Genetics and Breeding of Laboratory Animals of the German Society for Laboratory Animal Science (GV-SOLAS), we provide a practical, standardized representation of the genotype of gene-modified animals. It is intended to serve as a compact guide for animal care and scientific personnel in animal research facilities and to simplify data exchange between groups and with external service providers.
Introduction
Notation systems for genetically modified and mutant rodents (rats and mice) were initially developed decades ago 1 , 2 and are now updated yearly. 3 These internationally accepted MGI guidelines (Mouse Genome Informatics, The Jackson Laboratory, Bar Harbor, ME, USA) allow the accurate description and identification of any gene-modified allele and the accompanying background genome. In daily lab and husbandry work, these complex line and strain notations are frequently replaced by shorthand, especially when they are combined with relevant information about the diploid genotype. It is well known that the notation of the diploid genotype differs between and within animal research facilities and commercial genotyping providers and is far from being standardized. We observed this when we performed a random sampling of genotyping results from 11 German research facilities, four of which transferred their genotyping data automatically into their breeding databases (data not shown). This unsatisfactory situation can easily lead to critical errors due to misinterpretation of information. Furthermore, during data exchange, the genotype information needs to be customized for different parties, binding additional resources and introducing more error-prone steps. Examples of such ambiguous notations are the ‘+’ and ‘−’ symbols. Although in classical genetics the symbol ‘+’ was used exclusively to indicate the wild-type and the symbol ‘−’ a mutation (corresponding to enzyme not active), 4 ,5 nowadays the symbol ‘+’ is often used to indicate the presence of a transgene, while the wild-type allele, on the other hand, is on occasion indicated by ‘−’.6–8 Such ambiguous, even contradictory, use of one and the same symbol constitutes a grave problem as it does not allow a correct interpretation of the actual genotype without additional information such as a decoding table. The frequent exchange of gene-modified lines between research groups or animal research facilities means that this ambiguity is a severe source of errors. If notation-related mistakes result in wrong breeding and failed experiments this nomenclature problem is not only a financial but also an animal welfare and scientific problem.
The Committee on Genetics and Breeding of Laboratory Animals of the German Society for Laboratory Animal Science (GV-SOLAS) tasked a subcommittee (the authors of this paper) to develop nomenclature recommendations for the notation of the diploid genotype of genetically modified mice and rats. These recommendations, presented here, are intended as an aid for recording results in routine genotyping of animals during breeding in animal research facilities. They are secondary to the mandatory adherence to the MGI guidelines for the description of mouse and rat lines and strains. Hence, especially when referring to constructs that can be modified by recombinases, a focus was placed on allowing the researcher to have the relevant information in the shortest and most practical way (as a post-typing result), even if this means that the notation may seem incongruent with the MGI nomenclature guidelines. In many instances, the MGI nomenclature will be complemented with a shorthand of the line name, which may support everyday work but does not allow unambiguous identification. To our knowledge, no rules for such shorthands apply and we do not provide any suggestions in that direction.
To achieve the goal of a notation for the diploid genotype, the following criteria were considered in the recommendations presented here:
Keeping the proven representation of the diploid genotype (e.g. formerly +/−) by use of a ‘/’; Use of self-explanatory notation elements wherever possible (e.g. ‘u’ for ‘unknown’ or ‘q’ for ‘questionable’); Uniform logic in comparable systems (e.g. Cre or FLP recombinase-mediated modifications); Providing the shortest possible notation; Avoidance of ambiguity even with complex constructs (e.g. multiple recombinase target sites); Openness to novel constructs; Compatibility of the syntax with the data import function of spreadsheet and database programs (e.g. avoiding ‘?’ and separator symbols).
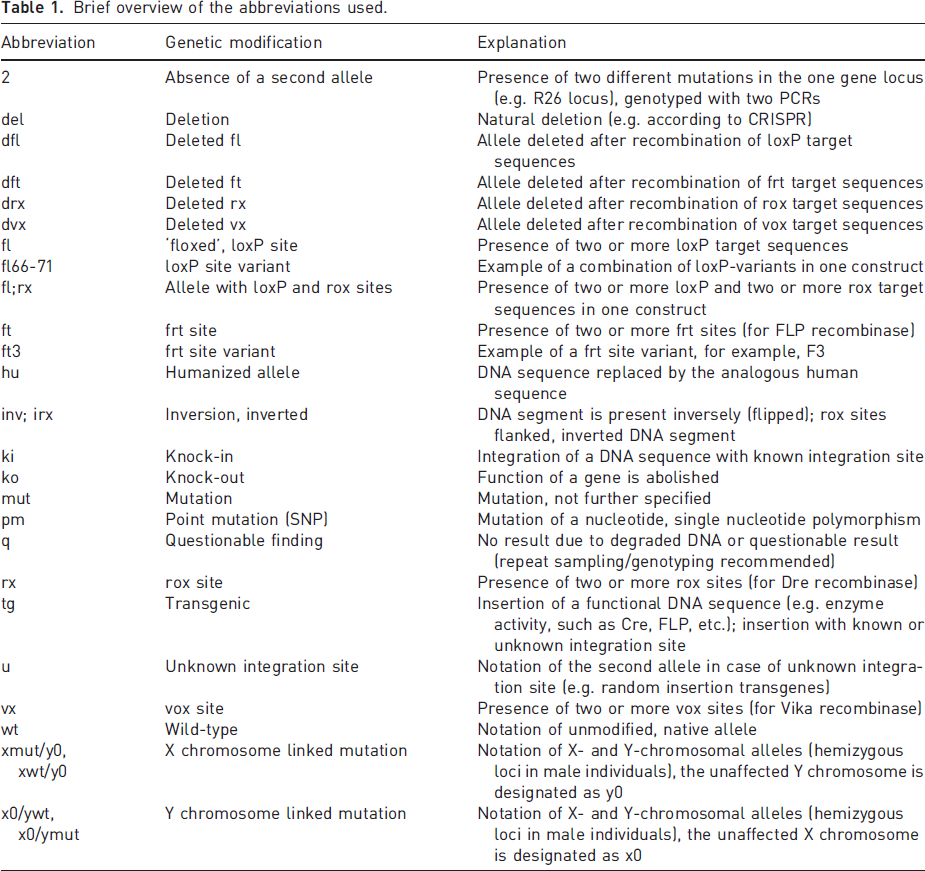
Following these criteria, the notation of the genotype documents the allele-specific genetics of the respective individual animal. Again, it does not replace the MGI guidelines, which represent the genetic changes and the background genome present in a respective line, strain or stock. The proposed nomenclature for the annotation of the diploid genotype reflects the result of the biopsy examination. It does not allow any conclusion on germline location, strain, cell type specificity or systemic presence. An overview of all proposed abbreviations is given in Table 1.
Brief overview of the abbreviations used.
Rules and general principles of genotype documentation
Rule 1. Unique designation of the wild-type allele
The wild-type allele is always referred to as ‘wt’. In heterozygous genotypes, this is always in second place.
Example 1:

Rule 2. The results of genotyping of both homologous chromosomes are given
The sister alleles are separated by ‘/’. Depending on the genotype, these can be two identical (homozygous) or different (heterozygous) alleles. Except for ‘wt’, the genotypes are provided in alphabetical order.
Example 2:

In the case of genetic modifications on the X or Y chromosome, a second allele is generally missing in male animals. Classical genetics defines such markers as hemizygous. The information of sex chromosome-based inheritance is important for further breeding. To provide clarity here, the corresponding genotypes should be completed with a preceding x or y. In most cases, the mutation is located on only one of the two sex chromosomes. Therefore, ‘x0’ or ‘y0’ is assigned to the chromosome not carrying the gene.
Example 3:

Rule 3. The allele deviating from the wild-type is named precisely and unambiguously
This rule applies provided that the nature of the genetic modification is known.
Example 4:

Rule 4. Recombinase genes in the genome are annotated with ‘ki’ or ‘tg’
Recombinase genes can be integrated into the genome by targeted mutagenesis or random integration. Thus, the designation ‘ki’ or ‘tg’ are used, respectively. In the latter case the location of the second allele is designated as ‘u’ for ‘unknown’ integration.
Example 5:

Rule 5. Recombinase target sites are indicated with two letters (fl, ft, rx and vx) and after recombination by a preceding ‘d’ (deletion) or ‘i’ (inversion). Multiple different sites separated by a ‘;’ in alphabetical order
Constructs with target sequences for recombinases (recombinase target sites) should be labelled with a unique identifier for the specific recombination target sequence. As a rule, the more relevant/precise information should be favoured over a more general one, as, for example, ‘ki’ over ‘mut’. Especially regarding constructs containing recombinase targets, it is not intended to combine, for example, ‘fx’ and ‘ki’ to describe the mechanism and result. With knowledge of the genetic construct and mechanism underlying an intended knock-in event, the more relevant designation is recommended, for example, ‘fl’ over ‘ki’. After a simple homozygous knock-in line has been established by recombination, the relevant information for intercrossing between lines may then be ‘ki’.
Example 6:

Representation of a deleting recombination.
In animals that have both, a ubiquitously expressed recombinase transgene (e.g. deleter-Cre) and a corresponding target allele, the deletion after activation of the recombinase is indicated by a preceding ‘d’ in addition to the recombinase-specific abbreviation (e.g. ‘dfl’) since only the recombination event but no longer the recombinase may be detected in the subsequent generation. In the case of stepwise generation of successive deletions in a mouse line, for example, first with Cre, then with Dre, this representation allows the development of the genotype over the generations to be reliably traced until the target genotype of the mouse line has been generated (see Figure 1).
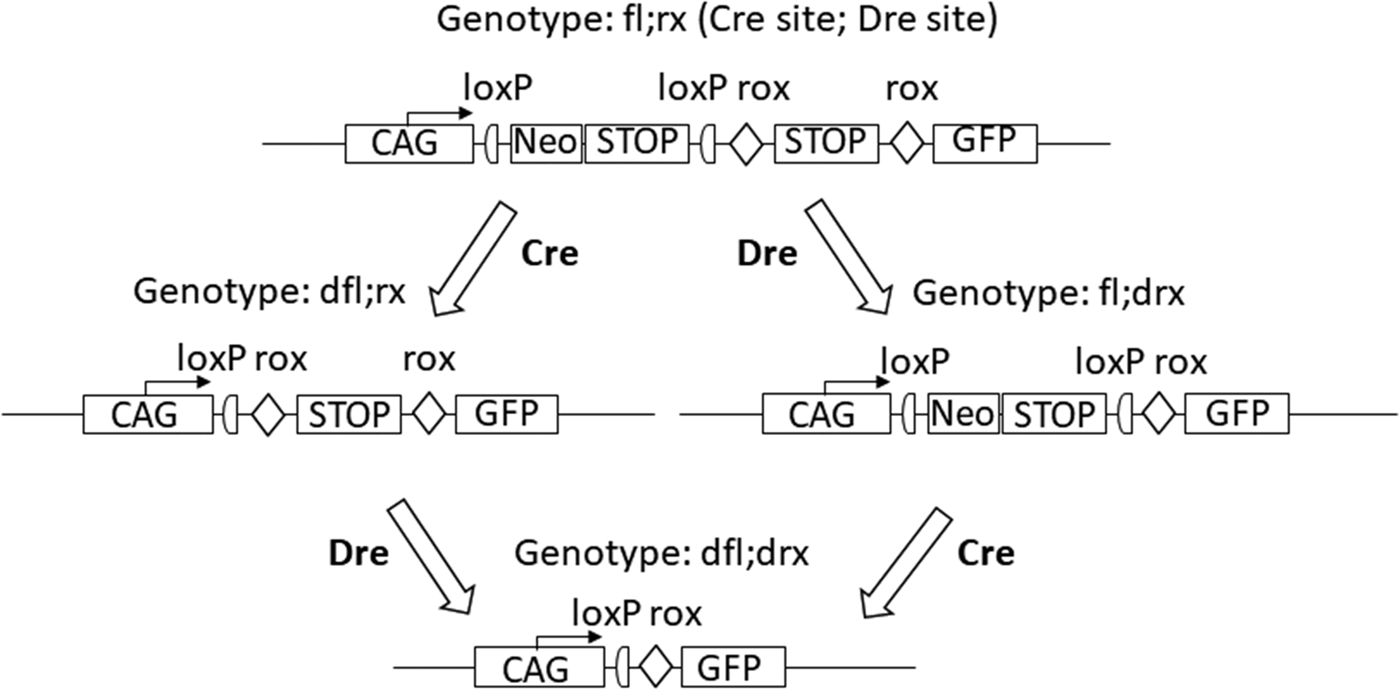
Stepwise, targeted generation of deletion mutants. By selective action of either Cre or Dre recombinase from the initial genotype fl;rx the genotypes dfl;rx, fl;drx and dfl;drx are obtained. CAG - promoter region showing the direction of transcription (here as an example: CAG - promoter), Neo - neomycin resistance gene, GFP - green fluorescent protein without its own promoter, STOP - cassettes with stop codons. In the construct dfl;drx, the transcription of the GFP protein is enabled by the corresponding CAG promoter placed in front of it.
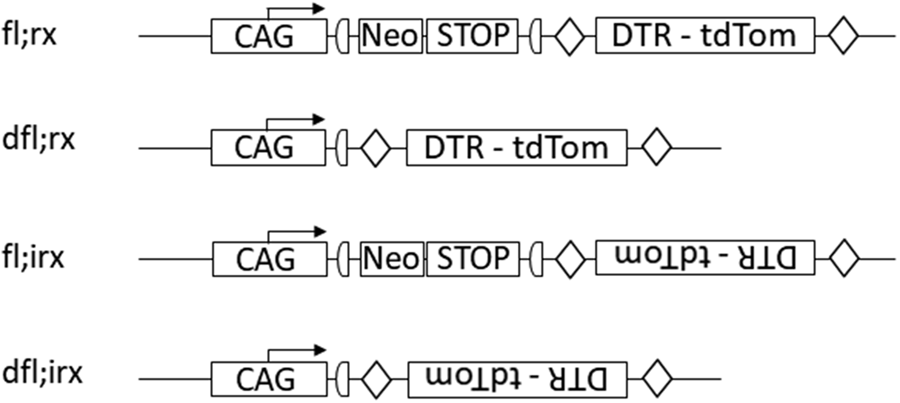
Designation of genotypes for constructs built inversely to the reading frame. CAG - promoter region showing the direction of transcription (here as an example: CAG - promoter), Neo - neomycin resistance gene, STOP - cassettes with stop codons, DTR - tdTom - cassette with diphtheria toxin receptor and fluorescent protein tdTomato without its own promoter. In the construct dfl;rx transcription of DTR-tdTomato is activated by the corresponding CAG promoter placed upstream.
Once the generation of a new mouse line is complete, these animals are designated as a new line using the appropriate MGI nomenclature (e.g. tm1 becomes tm1.1).
Recombinase-mediated deletions are not identical to deletions in the classical sense (by natural base pair loss) or deletions mediated by CRISPR/Cas. In addition to the desired deletion, at least one copy of the respective recombinase binding site (e.g. flox-site) always remains in the genome. Such specific alleles extended by the abbreviation ‘d’ (e.g. dfl or drx) are consequently composed of the deletion and a knock-in of a foreign DNA sequence. The strict distinction alerts the user not to consider a genotype with ‘dfl’ as a simple deletion. The clear assignment of genetic modifications to ‘del’ or ‘dfl’ also simplifies the classification of animals with genomic deletion as ‘natural’ versus genetically modified. In the case of CRISPR/Cas mediated deletion, no foreign sequences remain in the genome, therefore being treated as a ‘natural’ deletion in the context of the genotype and noted as ‘del’.
Example 7:

b. Representation of target site variants.
For simplicity, the abbreviation ‘fl’ symbolizes all genomic situations in which sites can be recombined by Cre. However, for constructs with different loxP-variants, further specifications may be required, for example, fl5171 13 or fl66-71. 14 Combinations of loxP-variants in a construct will be separated by ‘-’, for example, fl66-71. The respective deletion or inversion following recombination are again indicated by an additional ‘d’ or ‘i’ at the corresponding position, leading to dfl66-71 or ifl66-71, respectively. This rule also applies to other modifications of recombination sites, for example, FLP target sites (e.g. F3). 15
Example 8:

c. Representation of an inverting recombination.
Constructs with a cassette that is inverse to the promoter sequence (flipped) are indicated by a preceding ‘i’; after inversion into the correct reading frame, the ‘i’ is omitted. The same applies to a starting configuration in transcriptional orientation: ‘fl’ becomes ‘ifl’.
Example 9:

d. Representation of multiple recombination features and recombination events.
Constructs with sites for more than one recombinase are identified by the respective abbreviation, sorted in alphabetical order and separated by a semicolon. The indication of recombination is performed positionally for the respective enzyme, as given in example 12.
Remaining target sequences or other gene cassettes are not considered when naming the genotypes, such as one rox and one loxP site each as well as the GFP cassette in the genotype ‘dfl;drx’ as in Figure 1.
Example 10:

Example 11:

Example 12:

Rule 6. Each genetically modified region of a mouse line is recorded only once in the database
The single-entry rule also applies to complex genetic constructs where the results of several independent PCR reactions must be combined into one result (see Figure 3, as well as Supplementary material Figure 1 online, annotating the final allele ‘fl;rx’ instead of separate presentation of genotyping results of the neomycin resistance gene (Neo) and green fluorescent protein (GFP)). This facilitates correct selection of suitable animals for subsequent matings without the need for additional background information.
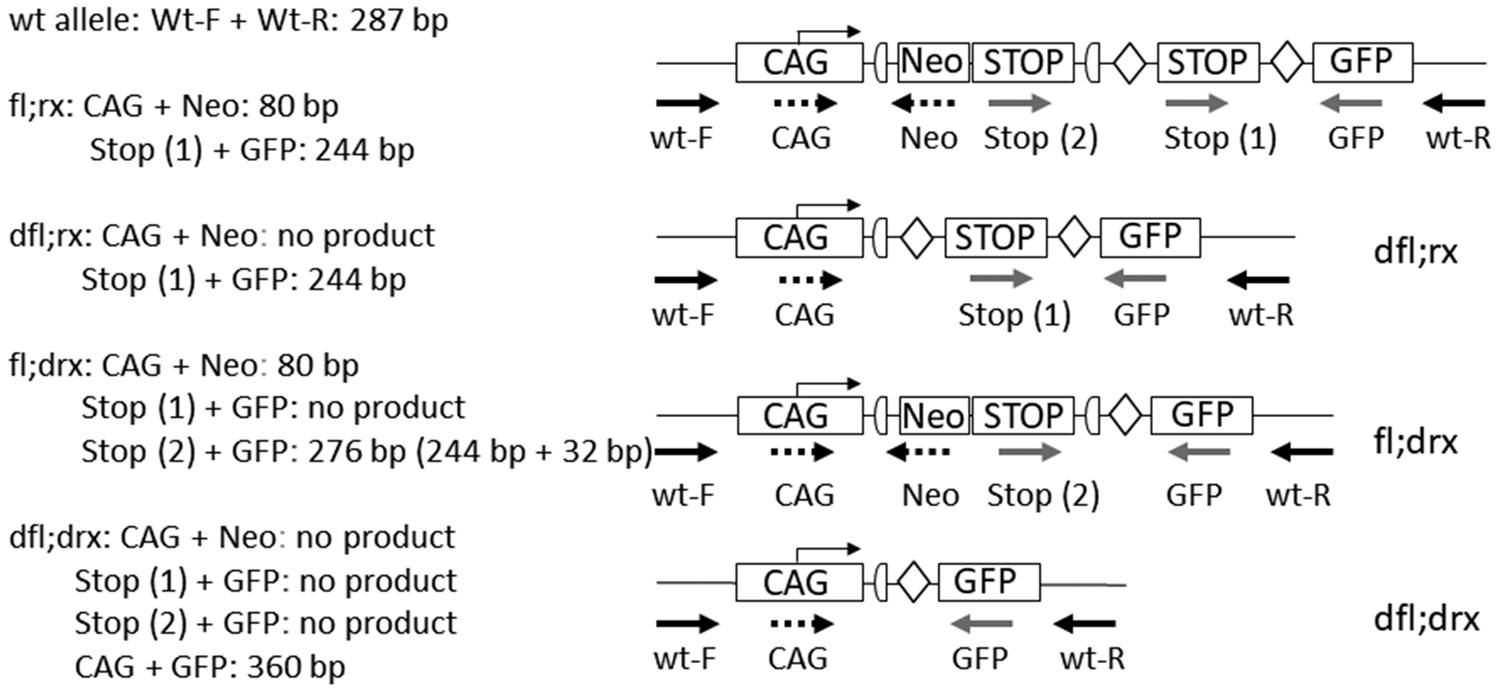
Combination of different genotyping results into one final record of alleles presented in Figure 1. Derivation of the final genotype of a complex construct from Figure 1 based on the results of multiple independent polymerase chain reaction (PCR) analyses. The length of a loxP site in this figure is 34 bp. Therefore, the PCR product for stop-GFP is larger by this value for the fl;drx genotype than for dfl;rx or fl;rx. The arrows each represent a PCR primer in the corresponding orientation (forward, reverse).
As shown in Figure 3, the results of the genotyping are presented in compressed form. They result logically from the respective matings of the parents.
Example 13:

Rule 7. The combination of two genetically unrelated, gene-modified alleles located at the same locus leads to two database entries, with a ‘2’ for the second allele
For certain experimental setups two different modifications have been introduced into the same locus (e.g. R26-hM4D (fl/fl) and R26-ChR2 (fl/fl); Figure 4) and crossed together to obtain heterozygous animals for both modified alleles. Examples of such a situation are the various insertions into the Gt(ROSA)26Sor locus (commonly known as Rosa26 or R26 locus). 17 In contrast to the representation of the two alleles of a gene with multiple possible recombination outcomes (yet still all located within the same construct) as described in rule 6, the genotypes of two independent mutations present in the same locus but on sister chromosomes need to be recorded separately. Since the second, homologous, allele is occupied by the allele of the other, different mutation, the position of the second allele is marked with ‘2’. The ‘2’ here indicates the presence of a second, unrelated, construct at the identical location on the sister chromosome. Exceptions are genotypes with a wild-type allele or other alleles unambiguously distinguishable from each other (e.g. fl/wt) if these can be clearly derived from the respective mating scheme (see example 15, and Figure 4(b)).
Example 14:

Example 15:
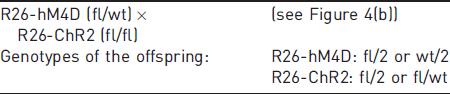
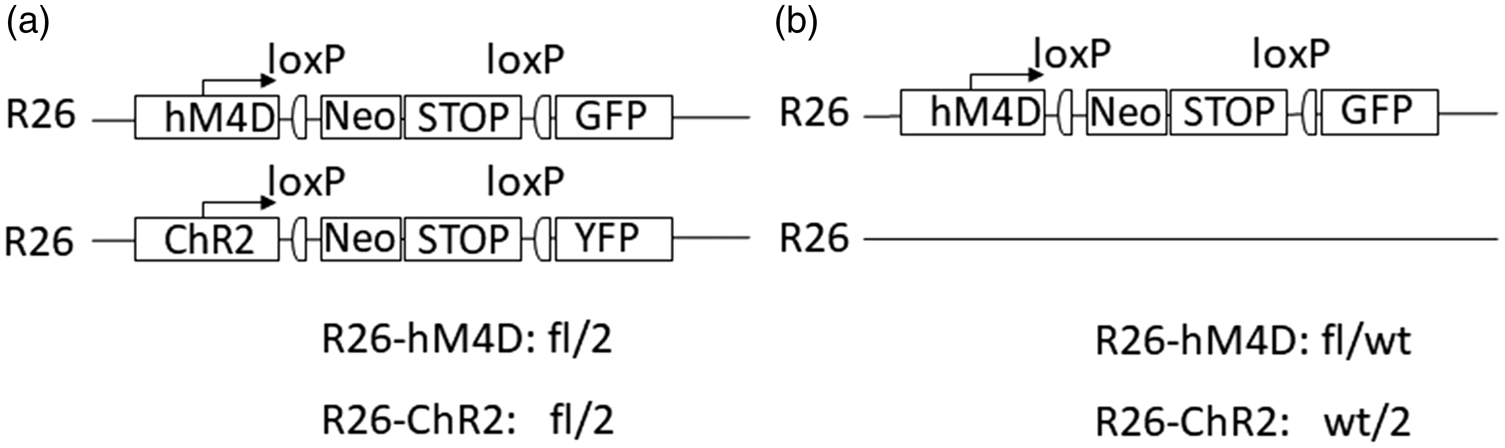
Genotype options of parents with different, genetically unrelated constructs in the identical corresponding allele position. Mating of parents with two different, genetically unrelated constructs located at identical positions in the genome (e.g. in the R26 locus) results in offspring which may possess both genetic constructs simultaneously (and no wild-type allele). The genotypes are then referred to as ‘fl/2’ for both markers and recorded independently (a). Depending on the mating scheme, in the case of positive detection of the wild-type allele, the genotype is either ‘fl/wt’ or ‘wt/2’ (b).
Rule 8. Use of the character ‘q’ to indicate questionable, ambiguous findings
Occasionally, due to technical problems, the genotype cannot be determined beyond doubt. This is the case if the DNA sample is already highly degraded and larger PCR products are no longer amplified, but short PCR products are still detectable. Should the wt and mut allele be represented as one longer and one short DNA fragment, the failure of the larger product may lead to misinterpretation with respect to genotype. Suboptimal PCR conditions may also lead to preferential amplification of the short PCR product. For such situations, the abbreviation ‘q’ is used for the allele that cannot be identified, indicating that re-genotyping is suggested. Instead of a ‘?’, a ‘q’ for ‘question mark’ is used here to ensure database compatibility.
Example 16:

Rule 9. Unknown integration site of a genetic modification is annotated with a ‘u’ for the second allele
If the integration site of a genetic modification is not known, in contrast to known integration sites, no specific primers can be generated with which the wild-type allele can be detected. Breeding of such animals may lead to offspring carrying the transgene on one or both alleles. However, this cannot be determined by conventional PCR.
In the case of proof of the presence of genetic modification, no statement can be made about the second allele. The value ‘u’ for ‘unknown’ is assigned for this situation. This means that either the wild-type allele or a second allele of the corresponding genetic modification is present.
Although classical genetics defines exclusively the X- and Y-chromosomal markers described under rule 2 as hemizygous, constructs with unknown integration sites that can be classified genetically in a completely different way are also regularly described as hemizygous. 18
Example 17:

Rule 10. Annotation of genotyping results must allow for automated exchange with third parties and transfer into animal husbandry databases
The automated transfer of genotyping results from an external finding is done either via a csv or a txt file (see also Supplementary Figure 2). Beforehand, the respective possible allele combinations (e.g. wt/wt, fl/wt, etc.) must be released separately in the database for each mutation. Since the name of the mouse line is irrelevant for the data import, only the exact sample ID and the mutation name are required for the successful assignment of the results.
The following requirements must be met in the livestock database:
All permissible genotypes for the respective mutation must be defined and released separately for each mutation; The mutation name must not contain special characters, such as ‘?’ (question mark), ‘_’ (underscore), ‘/’ (slash) or ‘,’ (comma), as these lead to problems in assigning the analysis results or in computer-aided processing.
The following information must be available at the analytical laboratory:
Sample ID, identical to the sample name in the database; Spelling of the mutation name, identical to the mutation name in the database, including spaces, upper and lower case; Permissible genotypes for the respective mutation stored in the database.
Discussion
The MGI guidelines provide a standardized way of naming and identifying different mouse lines, stocks and strains.1–3 The latest large addition to this rule set was the result of the endonuclease revolution, 19 starting with Zinc finger and Tal-effector nucleases and eventually leading to the CRISPR/Cas technology. Having a compatible nomenclature system for naming mutant lines (for review: Sundberg and Schofield 20 ) and, as proposed here, for the diploid genotype of the individual animal has several benefits for everyday lab work. The consistent designation of animal-related data among researchers helps to prevent confusion and errors when communicating about or referring to specific mouse lines and breeding results. With the nomenclature system recommended here, researchers can easily identify the specific diploid genotype of individuals of a specific mouse line. This information is critical for understanding the phenotype and behaviour of each line, as well as for comparing results between different studies. It also supports the appropriate breeding of the animals, applying Mendelian rules. 21 A standardized genotype notation system makes it easier to track the history and origin of each individual mouse, which is vital for ensuring that mouse lines are properly maintained, stored and shared between different research groups. 22 For instance, we know of designations for diploid genotypes having been changed over time, making historical analyses of pedigrees unnecessarily complex or even impossible. A standard notation system further streamlines the necessary documentation and data-sharing when animals are exchanged between labs and institutions or when external genotyping services are used. This helps to promote collaboration and speed up the pace of scientific discovery. Furthermore, the proposed genotype notation system makes it easier to electronically manage and organize data related to genetically modified animals. Such management systems help to reduce errors and improve the accuracy of data analysis and overcome paper-related error-prone data exchange throughout the whole scientific data pipeline from the decision for an animal experiment to consistent storage of scientific data and animal-derived specimen in tissue repositories.
Our recommendations do not intend to replace the MGI guidelines for allele, stock and strain designation but serve as an addition to make genotype recording, in most cases after genotyping by means of molecular biology methods, consistent over labs and institutions. We do not address the fact that in many research animal facilities abbreviations for line names are common. While these are used together with a genotype notation, we do not see an easy consensus on how such common names and abbreviations should be generated and how to deal with established abbreviations and common names, especially since many of these names are easy to remember and hence support communication about lines, for example, Tiger, Confetti. 23 , 24
Being a source of concern for a long time, a standardized nomenclature for the notation of the diploid genotype has surprisingly not been considered so far. Therefore, we also aim at a harmonization of genotype notation enabling the community of researchers generating and using gene-modified and mutant rodents to establish in their respective institutions a clear record of present and past animal genotypes. We also believe that further discussion is necessary about this particular aspect of nomenclature. This discussion could also take place within the established International Committee for Standardized Genetic Nomenclature in Mice.
Overall, we are confident that the rules for the standardization of notation of the diploid genotype, as presented here, are compatible with everyday lab work and will help to improve the efficiency, accuracy and transparency of research involving genetically modified mouse lines. Finally, it will help to adhere to the 3R principles in terms of reduction and refinement.
Footnotes
Acknowledgments
This manuscript has been prepared on behalf of the Committee on Genetics and Breeding of the German Society of Laboratory Animal Science (GV-SOLAS). We especially thank our committee colleagues Nadine Baumgart, Jutta Davidson, Franz Iglauer, Boris Jerchow, Ingrid Renner-Müller and Johannes Schenkel for their multiple inputs, discussions and corrections.
Data availability
The data underlying examples and figures are available from the corresponding author upon reasonable request.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Swiss 3R Competence Centre (Project 3RCC-003-o2018).
Supplementary material
Supplementary material for this article is available online.