
Abstract
Endogenous regressors can lead to biased estimates for causal effects using methods assuming regressor–error independence. To correct for endogeneity bias, the authors propose a new method that accounts for the regressor–error dependence using flexible semiparametric odds ratio conditional models; the approach requires neither parametric distributional assumptions nor tuning parameters for modeling endogenous regressors’ distributions conditional on the error term and exogenous regressors. Inference is achieved via optimizing the profile likelihood concentrating on the parameters of interest. The proposed approach requires no use of instrumental variables (IVs), observed or latent, that must satisfy the stringent condition of exclusion restriction. Nonnormally distributed endogenous regressors are required for model identification with a normal error distribution. The approach's flexibility in capturing regressor–error dependence increases the capability of IV-free endogeneity correction and provides opportunities to improve the accuracy of causal effect estimation. Unlike existing IV-free methods, the proposed approach can handle discrete endogenous regressors with few levels, such as binary regressors or count regressors with small means, and is thus applicable to a plethora of applications involving such regressors. The authors demonstrate the versatility of the approach for binary, count, and continuous endogenous regressors using comprehensive simulation studies and empirical data.
Keywords
In many empirical marketing studies, researchers need to control for regressor endogeneity when estimating population structural regression models representing causal relationships of interest. We refer to regressor endogeneity as whenever a regressor relates to the regression error term, causing regressor–error dependence. By contrast, an exogenous regressor is predetermined or controlled by researchers such that units are randomly assigned to different regressor values, rendering the regressor and the error term independent. Because many data are observational in nature, regressors are frequently not randomly assigned. In almost all of these applications, the assumption that all regressors are exogenous is debatable, if not untenable. For example, the error term (henceforth “structural error”) in a consumer demand model may include unobserved common market shocks or product attributes affecting marketing-mix regressors (e.g., price) (Villas-Boas and Winer 1999).
Endogeneity can greatly hinder unambiguous conclusions regarding causal effects. Estimation methods assuming all regressors are exogenous, such as ordinary least squares (OLS), can yield severely biased causal effect estimates when regressors are actually endogenous. The instrumental variable (IV) approach is traditionally used to correct for endogeneity bias but requires valid and strong IVs, which can be hard to find and validate in practice (Rossi, Allenby, and McCulloch 2005). Recent marketing literature also emphasizes the need for more flexible ways to handle regressor endogeneity (Dost et al. 2019; Zhang, Kumar, and Cosguner 2017).
This work aims to develop an IV-free joint estimation approach to correcting for endogeneity bias based on semiparametric odds ratio endogeneity (SORE) models. SORE addresses endogeneity bias by accounting for regressor–error dependence via joint modeling of these random variables. Specifically, we model the distribution of endogenous regressors conditional on the structural error and exogenous regressors using the semiparametric odds ratio (SOR) models (Chen 2004; Feit and Bradlow 2021; Qian and Xie 2011, 2014, 2015, 2022). Under SORE, this conditional distribution comprises two components: (1) the flexible odds ratio (OR) functions capturing the regressor–error dependence and describing the nature and magnitude of endogeneity unexplained by the exogenous control variables, and (2) nonparametric baseline distribution functions capturing the distributional features of endogenous regressors critical for proper correction of endogeneity bias. The likelihood function based on the joint distribution of the error term and endogenous regressors given exogenous ones is then derived and optimized to obtain the maximum likelihood estimation (MLE) of model parameters. We derive sources of identification for a range of OR functions encoding different identification strategies and demonstrate how to select appropriate ones empirically using likelihood-based model selection measures. SORE is applicable to both discrete (including binary and count) and continuous endogenous regressors without imposing parametric distributional assumptions on them, and permits endogeneity correction to be conditioned on exogenous regressors without imposing models on exogenous regressors.
The main contributions of SORE lie in the following aspects. First, SORE offers a general and flexible regressor-endogeneity bias-correction framework that increases the capability of IV-free endogeneity correction. We show that SORE provides likelihood-based counterparts of some extant IV-free methods, such as identification via heteroskedasticity and higher moments (Lewbel 1997; Rigobon 2003), and nests the recently proposed joint copula modeling (JCM) approach (Becker, Proksch, and Ringle 2021; Eckert and Hohberger 2023; Park and Gupta 2012; Tran and Tsionas 2021) as a special case. To correct for endogeneity bias, JCM assumes a Gaussian copula (GC) model (Danaher and Smith 2011) to capture regressor–error dependence. We show that, theoretically, JCM is a special case of SORE with particular forms of OR functions and baseline distribution functions and thus is fully nested within the SORE framework. By considering OR functions permitting both copula and noncopula dependence, SORE builds on the wide applicability of JCM and its recent extensions (Haschka 2022; Yang, Qian, and Xie 2022) and addresses broader types of regressor endogeneity, providing novel ways to identify causal effects.
Second, SORE provides a novel IV-free approach for handling discrete endogenous regressors that overcomes the limitations of existing IV-free methods. Among existing IV-free methods, only JCM can handle discrete endogenous regressors (Park and Gupta 2012). JCM views discrete endogenous regressors as realizations from underlying continuous latent variables and performs an inverse mapping from the cumulative distribution functions (CDFs) of endogenous regressors to the latent variables. One limitation of the approach and its recent extensions (Haschka 2022; Yang, Qian, and Xie 2022) is that endogenous regressors must contain adequate information, in that the number of unique values for these regressors cannot be too small (Eckert and Hohberger 2023; Haschka 2022; Park and Gupta 2012; Tran and Tsionas 2021; Yang, Qian, and Xie 2022). A plethora of applications involve discrete endogenous regressors that take on a small set of possible values. Examples include binary variables for coupon promotion and count variables with small means (e.g., the number of coupons redeemed by a consumer for durable goods). Theoretical challenges and empirical identification issues for nonparametric copula estimation due to plateaus in the inverse of empirical discrete CDFs have been documented in the literature (Genest and Nešlehová 2007). Unlike JCM, SORE provides specifications requiring no inverse mapping from the CDFs of endogenous regressors, thus avoiding the nonuniqueness of this mapping and the consequent model nonidentifiability issue for discrete endogenous regressors that JCM and its recent extensions encounter. Under SORE, handling discrete endogenous regressors is straightforward with simple-to-evaluate likelihood involving no latent variables.
Third, SORE offers certain estimation/inferential advantages over two-step IV-free methods. Unlike the two-step JCM procedures, SORE estimates model parameters in one step and has several important advantages shared by the recently proposed one-step JCM (Tran and Tsionas 2021), including greater estimation efficiency (smaller estimate variability) and improved capability to detect endogeneity by using all data simultaneously, availability of maximized likelihood for likelihood-based model comparisons, and direct estimation of standard errors without resorting to bootstrap resampling.
These benefits of SORE are not without costs. Misspecifying OR functions can introduce bias into endogeneity correction or cause model nonidentification. Although SORE allows for flexible modeling of dependence structures, we only consider OR functions built from two broad types of dependence structures, GC and log-bilinear (LB), that have proven identifiability and encompass a number of existing dependence models. Because model nonidentification causes singular Hessian matrices of the likelihood functions and huge standard error estimates, it is important to check the sizes of standard errors to detect potential OR misspecifications. Although model comparison can help select proper OR functions, model selection methods are not error-free and involve a trade-off between estimation bias and variance. For instance, the GC regressor–error dependence assumed in JCM is a flexible and robust model applicable in many marketing applications to capture relationships among variables (Danaher and Smith 2011; Eckert and Hohberger 2023). SORE provides OR specifications that generalize JCM to permit flexible forms of regressor–regressor dependence. However, if endogenous and exogenous regressors are indeed independent, JCM will outperform SORE because a simpler and correct model outperforms more general models. In general, estimation after selection from OR functions will underperform as compared with the case with an OR correctly chosen a priori based on substantive knowledge.
SORE can encounter identification issues. With a normal structural error distribution, nonnormally distributed endogenous regressors are required for model identification. When endogenous regressors are normally distributed, SORE estimates are biased toward OLS estimates with hugely inflated standard errors relative to OLS ones. Like IV and other IV-free methods, SORE is a large-sample procedure. Even if a SORE model is theoretically identified with infinite sample size, SORE may encounter weak empirical identification with nearly flat likelihood in a small sample. Such weakly identified models yield almost singular Hessian matrices and very large standard errors. Thus, it is important to check the sizes of standard errors to detect potential lack of empirical identification. The nonparametric baseline functions for continuous endogenous regressors can involve numerous parameters. To make the one-step estimation scalable to large problems, SORE employs a profile likelihood approach that eliminates these nuisance parameters altogether from the model estimation/inference. Still, the two-step JCM that adds generated regressors to control endogeneity requires no such special algorithm and is straightforward to implement with considerably less computation time for continuous endogenous regressors.
In the next section, we review the literature on methods for handling regressor endogeneity. We then describe the proposed methodology, followed by evaluations using simulated data and an illustration in a real data set. The article ends with a discussion.
Literature Review
As regressor endogeneity is such a prevalent and thorny hindrance to causal inference in observational studies, extensive work in economics, statistics, marketing, and other fields has explored remedies to mitigate this issue. Imbens (2020) reviewed the Rubin causal model using potential outcomes and the directed acyclic graphs with “do-calculus” (Pearl and Mackenzie 2018) for analyzing causal effects. The two frameworks are complementary with different strengths, but the Rubin causal model is considered to have closer connections to the causal models used in empirical economics and marketing research (Imbens 2020). In both frameworks, regressor exogeneity (or the closely related unconfoundedness/ignorability) is central in identifying causal effects for a host of methods, including regression adjustment, matching, and weighting (Imbens 2020; Robins, Hernan, and Brumback 2000). Relaxing the key assumption requires additional data or alternative assumptions. Our review focuses on causal inference methods that do not require regressor exogeneity. 1
IV Methods
As the classical approach to solving the issue of endogeneity bias (Li and Ansari 2014; Rossi, Allenby, and McCulloch 2005), the IV method replaces the assumption of regressor exogeneity with two alternative conditions for IVs: relevance and exclusion restriction. Weak IVs that lack sufficient correlation with endogenous regressors can cause estimation bias to a greater extent than the endogeneity bias. The untestable condition of exclusion restriction requires that IVs be uncorrelated with the error term and affect the outcome only through endogenous regressors. These two conditions are often in conflict, making it challenging to find and validate satisfactory IVs.
Structural Modeling
An alternative way to solve endogeneity bias is to augment the model of interest with a highly structured secondary model describing the exact data generating process for endogenous regressors based on economic theory (Chintagunta et al. 2006). However, theory rarely is detailed enough to prescribe all aspects of the data generating process. Furthermore, identifying structural models often relies on IVs (Chintagunta et al. 2006).
IV-Free Methods Using Generated or Latent IVs
Given the challenges in identifying satisfactory IVs or correctly specifying structural models, interest in developing IV-free econometric methods to address endogeneity issues is growing. These IV-free methods entail neither observing IVs nor specifying a correct structural model of endogenous regressors. Lewbel (1997) shows how to generate IVs based solely on the higher moments (HM) of regression data in the outcome model to correct for endogeneity bias due to error in regressors. Rigobon (2003) proposes an “identification through heteroskedasticity” (IH) procedure that exploits the heteroskedastic error structure to identify structural parameters. Despite requiring no IVs, the IH procedure does require the availability of a grouping variable across which the structural shocks are heteroskedastic.
Ebbes et al. (2005) propose the latent IV method that models an endogenous regressor as a sum of an exogenous component and an endogenous component. The latent IV method then assumes that the exogenous component is a function of a latent discrete exogenous variable. Ebbes, Wedel, and Böckenholt (2009) provide a detailed review of the three preceding IV-free methods. Wang and Blei (2019) propose a “deconfounder” approach to generating IVs using a latent factor model for multiple endogenous causes. Assuming no unobserved single-cause confounders, 2 the difference between an endogenous regressor and the estimated latent factor (also called a substitute confounder) is an IV for the regressor.
IV-Free Joint Estimation Methods
The preceding IV-free methods (HM, IH, latent IV, deconfounder) all decompose an endogenous regressor into exogenous and endogenous parts, and employ a critical assumption that the exogenous part includes generated or latent variables satisfying exclusion restriction or the related condition of exogeneity, which can be difficult to justify (Park and Gupta 2012).
An appealing alternative is to directly model regressor–error dependence using a copula without decomposing the endogenous regressors to exogenous and endogenous parts (Park and Gupta 2012). No condition of exclusion restriction or exogeneity is needed in JCM, which significantly increases the feasibility of correcting for endogeneity bias. Meanwhile, recent work also reveals boundary conditions of JCM. Becker, Proksch, and Ringle (2021) and Eckert and Hohberger (2023) show that JCM can yield biased estimates when GC misspecifies regressor–error dependence. Haschka (2022) shows that JCM implicitly assumes independence between endogenous and exogenous regressors and can yield significant bias when they are actually related. Haschka proposes a GC model on the error term and all regressors while extending JCM to panel data analysis. Becker, Proksch, and Ringle show that the two-step JCM can have substantial finite-sample bias and loss of power to detect endogeneity when the structural model includes the intercept term. To overcome some of the estimation drawbacks of the two-step JCM, Tran and Tsionas (2021) develop an efficient sieve estimation of JCM that maximizes the likelihood in one step and requires no bootstrap to obtain standard errors. Their approach uses sieve basis functions to approximate the unknown smooth marginal densities of continuous endogenous regressors, and its performance depends critically on the correct choices of the number of basis functions (i.e., the tuning parameter). They find that one-step estimation reduces standard errors of model estimates and improves the ability to detect endogeneity.
Like JCM and its extensions, SORE requires neither the exclusion restriction nor the exogeneity assumption imposed in other IV-free methods. While nesting JCM and all its recent extensions as special cases, SORE is not restricted to copula dependence, permits noncopula types of regressor–error and regressor–regressor dependence, and can handle binary endogenous regressors and count endogenous regressors with small means (Table 1). The one-step SORE estimation is not subject to the finite-sample bias issue in models with an intercept affecting the two-step JCM (Becker, Proksch, and Ringle 2021). Meanwhile, unlike the one-step estimation approach of Tran and Tsionas (2021), SORE requires no tuning parameters when modeling endogenous regressors nonparametrically and imposes no assumption of smooth marginal densities for endogenous regressors.
Comparison of SORE with Existing IV-Free Joint Estimation Methods.

Notes: Tuning parameter refers to the bandwidth in the kernel estimator (Haschka 2022; Park and Gupta 2012) or the number of sieve basis functions (Tran and Tsionas 2021) used to model regressors’ marginal density functions.
Multivariate Modeling
SORE models the multivariate distribution of endogenous regressors and the structural error conditional on exogenous regressors, using the SOR model that we review here. Flexible multivariate models are sought in many fields (Danaher and Smith 2011). One example is the Sarmanov distribution, which combines disparate parametric marginals (e.g., exponential-gamma models for continuous variables, negative binomial models for discrete variables) into a multivariate distribution (Danaher 2007; Park and Fader 2004). Its limitations include that it does not scale well to many random variables, and the range of the correlation parameter capturing dependence can be less than the full range of (−1, 1). This is where the GC model has considerable advantage, as shown in the influential work of Danaher and Smith (2011). Park and Gupta (2012) used the GC model with nonparametric marginals for endogenous regressors. The SORE model nests both Sarmanov and GC as special cases, in that the latter two can be expressed as SORE models with particular forms of OR functions and baseline functions. Furthermore, only SORE simultaneously possesses all three of the following capabilities, crucial for addressing regressor-endogeneity bias: (1) it combines disparate univariate distributions into a multivariate distribution without imposing parametric distributional assumptions on endogenous regressors, (2) it provides flexibility in modeling various forms of dependence, and (3) it permits the multivariate distribution to be conditional on exogenous regressors.
Despite being a much more recent newcomer, SOR has demonstrated its power in modeling multivariate distributions (Chen 2004, 2007). Qian and Xie (2011) develop a new Bayesian method to address partially observed covariates in marketing models, which avoids evaluating the high-dimensional likelihood associated with multiple partially observed covariates and reduces the increase in computational workload from an exponential rate to a linear rate. SOR models have also been employed for robust and flexible data fusion (Feit and Bradlow 2021; Qian and Xie 2014) and secure business analytics preserving data privacy (Qian and Xie 2015). Qian and Xie (2022) adapt SOR models to simplify analyses of informative samples collected via endogenous selective sampling, which draws sampling units based on the outcome values to enrich sample information. However, none of these methods is designed to handle regressor-endogeneity bias. 3 Furthermore, we propose using the profile likelihood, which eliminates all the nuisance parameters in baseline functions from model inference. Finally, we demonstrate for the first time that SOR nests the commonly used copula models as special cases.
Methodology
The SORE Approach to Correcting for Endogeneity Bias
To illustrate the approach, we first consider the structural linear regression model 1. 2. 3. 
Assumption 1 states that Ei, i = 1, …, n, are i.i.d. with the marginal probability density function (PDF), fϕ(Ei), indexed by the parameter ϕ. A common choice for fϕ(Ei) is a normal density (0, σ2) (e.g., Ebbes et al. 2005; Park and Gupta 2012; Villas-Boas and Winer 1999). No restriction is imposed on the conditional distribution of the error term given regressors: Ei | Xi, Wi. The parameter of interest is θ = (α, β, μ, ϕ). Assumption 2 means no perfect collinearity among regressors. Unlike the exogenous regressors in W, whose distributions are ancillary to the parameter of interest θ, the distributions of the endogenous regressors in X provide information about θ via their associations with the structural error term under Assumption 3. Thus, the single-equation OLS estimation of Equation 1 ignoring these associations can lead to significant estimation bias, which can be viewed as a model misspecification bias because OLS incorrectly assumes Cov(Xi, Ei) = 0.
The SORE approach to handling endogeneity does not require additional data or the use of (observed or latent) IVs, but directly estimates the joint distribution of (Ei, Xi) given Wi. To simplify the exposition, subsequently we suppress the index i and consider the case of X containing one regressor. The next subsection will consider multiple regressors in X. Our approach expresses the joint distribution of (E, X) | W as
4

Although fψ(X | E, W) is typically not of interest, a correctly specified model for fψ(X | E, W) is important because misspecifying this nuisance distribution can introduce bias into the estimation of the parameter of primary interest, θ. In practice, correctly modeling fψ(X | E, W) is challenging because (1) X can contain a mixture of continuous, discrete, or semicontinuous regressors; (2) X can exhibit complex distributional features, such as boundedness, discreteness, multimodality, skewness, and heavy tails, which are critical for model identification and so must be faithfully preserved in modeling; and (3) there exist various forms of regressor–error and regressor–regressor dependence structure. Standard parametric distributional forms for fψ(X | E, W) may fail to maintain important distributional features of endogenous regressors critical for model estimation, or even fail to achieve model identification (see the “Model Identification” section). For these reasons, we chose to model fψ(X | E, W) using a SOR model (Chen 2004; Qian and Xie 2011) as

Nonparametric modeling of the baseline function fλ(x | e0, w0)
To increase modeling robustness and automatically pick up important distributional features of endogenous regressors, we employ the nonparametric empirical modeling approach (Chen 2004) for the baseline function, fλ(x | e0, w0). Specifically, fλ(x | e0, w0) has nonzero probability mass p = (p1, …, pL) only on the uniquely observed X values, (u1, …, uL), in the data. To relax the constraint
Flexible modeling of the endogeneity via the OR function ηγ(x; e, w)
SORE also excels in modeling various forms of association between (E, W) and X via the OR function, ηγ(x; e, w). When X is a categorical variable, the OR function yields the familiar OR parameters in the multinomial logistic regression of X on E and W. When X is continuous, semicontinuous, or discrete taking infinite possible values (e.g., a count variable), the OR function also exists and can be motivated by relevant parametric counterparts of SORE. Consider that X | (E, W) follows the generalized linear models (GLM) (McCullagh and Nelder 2019):

The OR functions are also closely related to other familiar dependence measures. When (X, E) follows the standard bivariate normal distribution with Pearson's correlation coefficient ρ and marginal variances for X and E being 1, X | E follows a normal linear model, and according to the preceding result for GLMs, X | E has an LB form of OR function: ln ηγ (x; e) = γE(x − x0)(e − e0) with 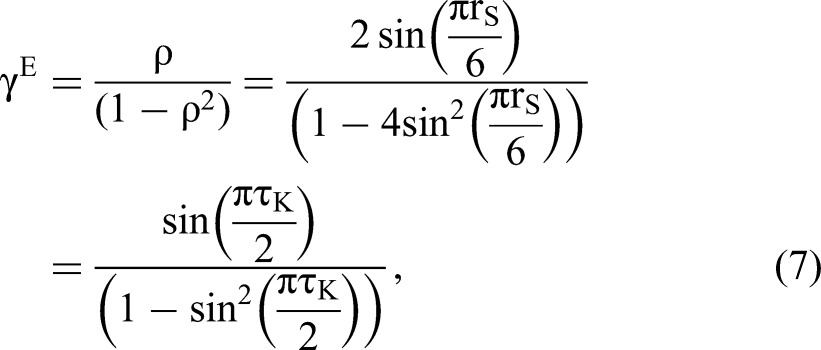
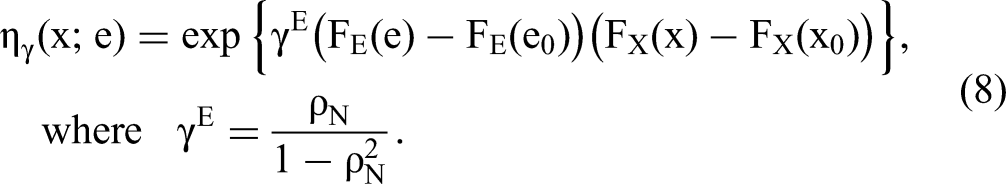

Modeling Multiple Endogenous Regressors
When X = (X1, …, XK) we consider a product of conditional distributions (Chen 2004)


Estimation and Inference
Given the data on a sample of n independent units, the log-likelihood under SORE is
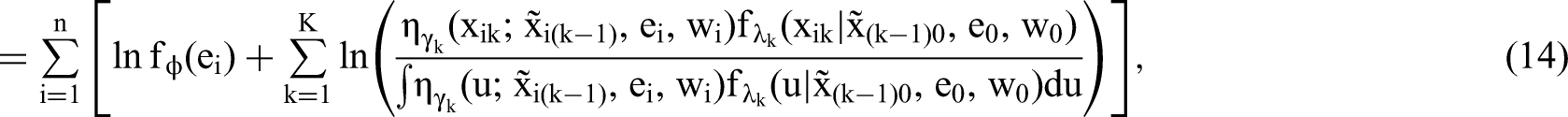

The preceding regular MLE procedure estimates all model parameters (θ, γ, λ). In practice, however, frequently only θ and γ are of interest, whereas the baseline function parameters in λ are nuisance parameters. The proliferation of parameters in λ due to multiple continuous endogenous regressors may make the regular MLE algorithm difficult to scale to large problems (Web Appendix A.1). In these scenarios, we propose a profile likelihood estimation that eliminates λ from likelihood. Define the profile likelihood 
Tests for Endogeneity
The log-OR parameter 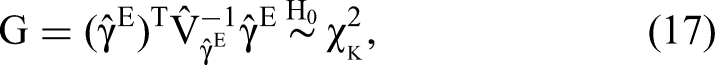
Model Identification
To understand the source of identification, reexpress the model in Equation 1 as

Model identification requires two conditions: (C1) the true correction term m(E | x, w) in the underlying population must not be perfectly collinear with x, and (C2) its sample estimate
W and X are independent
When exogenous regressors in W are independent of X,
Proposition 1 suggests that the first-order identification source of the preceding SORE model with an LB form of OR function is obtained via heteroskedasticity. 8 The identification via heteroskedasticity is akin to that proposed by Rigobon (2003). However, instead of prespecifying the grouping variable and the structure of heteroskedasticity as required by Rigobon (2003), SORE automatically detects the presence of heteroskedasticity via flexible modeling of the endogenous regressors’ distributions.
Assuming (1) X and W are independent, (2) we use an LB OR function on normal scores in Equation 8: ln ηγ (x; e) = γE(FE(e) − FE(e0))(FX(x) − FX(x0)), where FE(·) and FX(·) are normal scores, and (3)
Proof: See Web Appendix B.2.
For the preceding OR function with normal score transformation, the first-order identification comes from two sources: either (1) nonnormality of X so that
Assuming (1) X and W are independent, and (2) (X, E) follows a joint normal distribution with constant marginal variances, structural model parameters are not identified.
Proof: See Web Appendix B.3.
In this case, since C1 fails, we have neither heteroskedasticity nor nonnormality of X for identification. Perfect collinearity between m(E | x, w) and x will not only cause multicollinearity between
W and X are dependent
This case has similar identifiability requirements as when W and X are independent, and is covered in Web Appendices B.4 to B.7.
Comparison with the JCM Approach
Review of the JCM approach
Park and Gupta (2012) employed a JCM approach, positing a GC for the joint CDF of (X, E) as

Based on the model, Park and Gupta (2012) developed two endogeneity-correction procedures. Both are two-step procedures. In Step 1, one estimates HX(X) either using empirical CDF or using
Advantages of SORE compared with the JCM approach
SORE is more general and flexible than the joint copula approach (Park and Gupta 2012) in the following aspects.
First, SORE nests the joint copula approach as a special case. When (E, X) follows the GC in Equation 21, their joint distribution has the following OR function: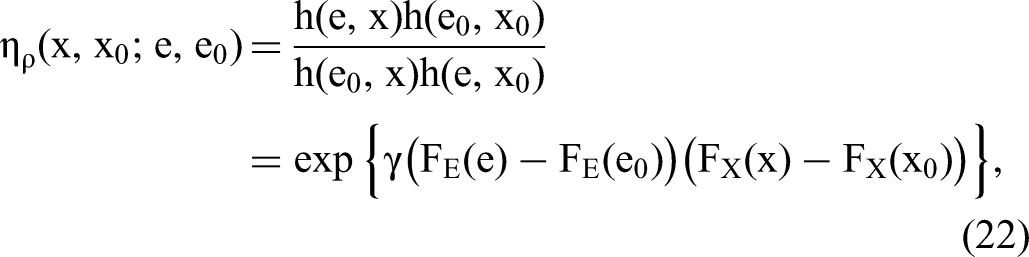
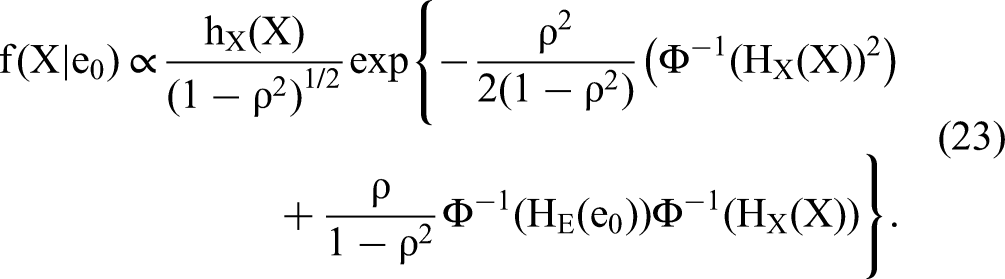
Second, SORE better handles discrete endogenous regressors. Genest and Nešlehová (2007) provide both theoretical results and empirical examples demonstrating that various properties fundamental to copula theory for continuous data are invalidated by discrete data. Specifically, the discreteness in the marginal probability distribution causes plateaus in the inverse of the discrete CDF. Consequently, the nonparametric copula model compatible with data, although it does exist, is not unique and thus encounters model identification issues. This nonidentification issue of the copula for discrete data can cause bias in the estimation of regressor–error dependence, which in turn introduces bias in structural model parameter estimates. This point can be illustrated as follows. Consider using latent copula data 
Third, SORE offers certain estimation/inferential advantages. Among the advantages of the one-step SORE estimation mentioned in the introduction to this article, we focus on the direct estimation of standard errors without resorting to bootstrapping. JCM can be estimated in one step by jointly estimating the nonparametric marginal distributions of endogenous regressors and other parameters. However, this is computationally challenging because the likelihood involves a large number of nuisance parameters in the nonparametric marginal distributions, although this can be made easier with density approximation under certain assumptions (Tran and Tsionas 2021). Park and Gupta (2012) estimate the model parameters in two steps, which simplifies estimation, but the inference requires bootstrapped standard errors. The nonparametric marginal-like baseline functions with parameters λ in SORE play the same role as that of the marginal distribution functions of endogenous regressors in JCM. SORE uses a one-step estimation by estimating all model parameters (θ, γ, λ) in one step,
10
using the profile likelihood to handle nuisance parameters λ.
11
Consequently, uncertainty arising from nonparametric baseline function estimation (i.e.,
Considerations in Specifying OR Functions
Since the baseline distribution functions in the SORE model for endogenous regressors are nonparametric, the focus of attention here is on the OR functions that capture regressor–error dependence. Table 2 lists the candidate forms for the logarithm of the OR function
Candidates of OR Functions.

Notes: Causal effect identification assumes the correct OR is in the consideration set and yields an identifiable model, which is weaker than assuming a candidate chosen a priori is correct.
Regressor–error (X–E) dependence
A key element in the OR specification is the X–E dependence. The GC model employed in JCM offers a versatile, robust, and logically consistent way to capture the regressor–error dependence irrespective of marginal distributions. One primary reason for regressor–error dependence is the presence of common omitted variables affecting both regressors and the error. As shown in Web Appendix D.1, when each of the error term and the (unbounded) latent copula data for the endogenous regressors can be expressed as a linear combination of the common omitted variables and a separate white noise term, 12 then the endogenous regressors and the error term will jointly follow the GC model. In addition to the theoretical plausibility, the GC model is empirically general and robust to capture dependence for most applications (Danaher and Smith 2011) as the model depends on the rank order of raw data only, and is invariant to strictly monotonic transformation of the endogenous regressors and the error. Thus, OR specifications assuming a GC X–E dependence are widely applicable and are good workhorse models for many marketing applications involving continuous endogenous regressors.
Similarly, GLMs are often used to capture nonlinear or nonadditive dependence structures for nonnormal, discrete, or bounded variables that linear additive models cannot handle (McCullagh and Nelder 2019). The LB OR functions for X–E dependence in Table 2 impose no distributional assumptions on endogenous regressors and nest corresponding GLMs as special cases. Because the LB OR functions require no inverse mapping from CDFs of endogenous regressors, they are good starting points for handling discrete endogenous regressors.
Overall, the GC and LB classes of OR functions are both broad, encompassing a number of existing dependence models and providing flexible and logically consistent models for X–E dependence free from constraints in marginal distributions. Model identifiability under these OR functions is established in the “Model Identification” section.
Regressor–Regressor (X–Z) dependence
Relevant regressors in Z should be included in the OR functions to ensure estimation consistency and improve estimation efficiency. Because both X and Z are observed, flexible forms of X–Z dependence can be used to guard against potential misspecifications. One approach is to specify a GC-type X–Z relationship. This is akin to positing a GC model on regressors as is done in Haschka (2022) and Yang, Qian, and Xie (2022). However, SORE is flexible and can model general forms of X–Z dependence using flexible LB OR functions. Even with only first-order terms of regressors, an LB OR function has the flexibility to capture nonlinear effects of Z on the mean of X (Qian and Xie 2022). Furthermore, polynomial or spline terms of regressors in Z can be introduced into the LB OR functions to approximate any smooth nonlinear effects of Z on X, in analogy to nonparametric regression models.
Selection of OR functions
The OR functions in Table 2 can be viewed as different ways to handle regressor endogeneity under different identifying assumptions. Thus, SORE offers a multimethod approach that considers all these OR functions in analysis to check robustness of estimation results. At times, one may need to synthesize results over different OR functions. Theoretical/substantive considerations of the underlying endogeneity problem can guide the process. Prior knowledge of a GC relationship between important omitted variables and endogenous regressors suggests a GC-type regressor–error dependence, whereas knowledge of error heteroskedasticity and/or differences in higher moments suggests that an LB form of regressor–error dependence is more appropriate.
In addition, SORE permits comparison of OR functions using likelihood-based model selection methods. As is always the case, model selection is not error-free (especially when the sample size is not large) and may benefit from incorporating substantive knowledge. The Akaike information criterion (AIC) and Bayesian information criterion (BIC) are the two most commonly used criteria for comparing models (Burnham and Anderson 2004). According to the AIC or BIC, the best-fitting model for each candidate OR function is obtained and compared with each other: the OR function resulting in the smallest AIC or BIC is selected as the best one. Model nonidentification may prevent finding the best-fitting model for an OR function. Causal effect identification assumes that the correct OR is included in the consideration set and yields an identifiable model, which is weaker than assuming any single OR function chosen a priori is correct and identifiable. Under the weaker assumption, any nonidentification of a misspecified OR can only result in a worse AIC or BIC for this misspecified OR and increase the chance that the correct OR is selected. As an unidentified model yields singular Hessian matrix and huge standard error estimates, empirical identification of the model can be checked by inspecting sizes of standard error estimates.
Simulation Studies
In this section, we conduct simulation studies to evaluate the performance of SORE to correct for endogeneity bias, and compare it with the joint modeling approach using GC. Simulation studies have multiple aims. First, because SORE nests JCM as a special case, we expect that its performance is on a par with the copula approach when data follow the copula model. Second, we evaluate SORE and the copula approach under alternative forms of endogeneity. Third, we evaluate SORE's performance for discrete endogenous regressors. Finally, we evaluate SORE's generalizability, flexibility, and robustness under misspecified or nearly unidentified models (Web Appendix D). Throughout the section, correct OR functions are used for estimation, unless noted otherwise.
Handling One Continuous Endogenous Regressor
In this study, we simulated data from two scenarios. In the first scenario, data were simulated from an underlying GC model as follows: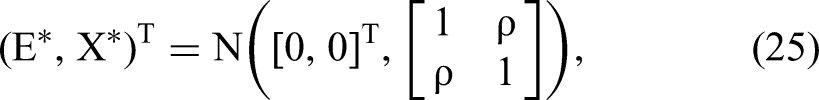


Results from 1,000 simulated samples are summarized in Table 3 in the “Under JCM Models” column. As expected, the OLS estimation yields large bias for the estimates of the structural model parameters (α, μ, σ). The ratio of the size of bias (i.e., the absolute difference between the true parameter values and the means of estimates) to the standard error, reported in the “tbias” column, shows a large bias (tbias >> 2) for all sample sizes. By contrast, both the copula and SORE eliminate the endogeneity bias. SORE has somewhat less variability of the estimates for (θ, γ), indicating greater estimation efficiency relative to the two-step estimation used in the copula approach. Table 3 also shows that the standard error estimates (in parentheses) computed from the Hessian matrix of the SORE model are close to the true standard errors.
Comparison of Estimation Methods with a Continuous Endogenous X.

The association between the endogenous regressor X and structural error is parameterized as γ, which has a true value of
Notes: Unless noted otherwise, the tables for simulation studies report the mean, standard deviation of estimates (SE), and relative bias (tbias) of the estimates over repeated samples. The average standard error estimates over the repeated samples using inverse Hessian matrix of the SORE model are reported in parentheses in the “SE” column. N.A. = not applicable.
In the second scenario, data were simulated in three steps: (1) generate E from N(0, σ2); (2) given E, generate X from a truncated normal distribution 
Results across 1,000 samples show that OLS yields significant bias for model parameter estimates (see the “Under SORE Models” column in Table 3). The copula reduces the bias of the OLS estimates to some extent, but significant bias remains.
Figure 1 plots transformed data X* = Φ−1(HX(X)) and E* = E for a random sample of 1,000 observations on X and E simulated using the three-step procedure outlined previously. A nonparametric locally estimated scatterplot smoothing (LOESS) regression line is also plotted, which shows a marked departure from the straight regression line expected if (X*, E*) follows a bivariate normal distribution. In this case, GC misspecifies the true dependence structure between X and E. The misspecification using GC results in the appreciable bias in model parameter estimates observed in Table 3.

Plot of Latent Copula Data.
By contrast, SORE with the OR function in Equation 28 properly models regressor–error dependence and consequently eliminates the endogeneity bias (Table 3). This demonstrates SORE's flexibility in handling alternative forms of endogeneity. Figure 2 plots the residuals from a LOESS regression of E on X for a random sample of 1,000 observations, demonstrating heteroskedasticity in

Heteroskedasticity.
Comparison of the OR Functions
As noted in the “Considerations in Specifying OR Functions” section, statistical model selection measures can be a useful tool to aid the OR function specifications. To evaluate the feasibility and effectiveness of using model selection measures to aid the OR function specifications, we conducted the following study.
We simulated data from models in Equations 25–27 for a sample size of 1,000. For each data set, we fit two SORE models: one with the correct OR function in Equation 8, denoted as “SOREC,” and the other one, denoted as “SOREM,” with the following misspecified OR function: ln(η(x; e)) = γ(x − x0)(e − e0). We then compute AICs and BICs of SOREC and SOREM, and the model with the smaller AIC or BIC is selected. We repeat the model estimation and comparison for 1,000 generated samples. Table 4 shows that over 1,000 simulated data sets of sample size N = 1,000, the AIC of SOREC on average is lower than that of SOREM by 8,706.1 − 8,689.8 = 16.3 (and for the BIC, by 8,871.9 − 8,855.6 = 16.3). In 98.4% of 1,000 simulated data sets, SOREC has a lower AIC or BIC than SOREM and is selected as the correct one. Table W14 in Web Appendix D.10 shows that SOREM with an incorrect OR cannot remove all the endogeneity bias in OLS estimates, resulting in biased parameter estimates and inconsistent likelihood-based standard error estimates, whereas SOREC using the correct OR yields consistent parameter estimates and standard error estimates. Overall, the finding that the AIC or BIC almost surely selects the correct OR in large samples demonstrates the feasibility of model selection measures to aid correct OR specification.
Comparison of OR Functions.

The effectiveness of comparing different OR functions using the AIC or BIC depends on information contained in the data to distinguish different endogeneity models. Table 4 reports results for sample sizes N = 200 and N = 500. Although SOREC continues to have a lower average AIC (BIC) than SOREM, the average difference in AIC (or BIC) between SOREM and SOREC becomes smaller for a smaller sample size. For a small sample size (N = 200), AIC or BIC selects the correct OR in 79.7% of 1,000 simulated data sets. This is expected because a smaller sample contains less information to distinguish different OR functions.
Correlated Exogenous and Endogenous Regressors and Comparison to IVs
We simulated data from the following joint model:

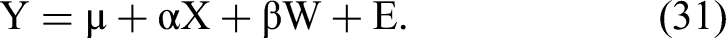

Estimation with Correlated X and W.

Handling One Binary Endogenous Regressor
To examine SORE's ability to handle binary endogenous regressors, we performed the following simulation study. In the first scenario, data were simulated in three steps: (1) generate E from N(0, σ2); (2) given E, generate X from a binary logistic regression model: logit(P(X = 1 | E = e)) = λ0 + γe; and (3) given E = e and X = x, generate Y = μ + αx + e. We set σ = 2, λ0 = −2, γ = 2, α = 1, and μ = 0. The binary logit model in Step 2 is a SORE model with the OR function ln(η(x; e)) = γ(x − x0)(e − e0) and the baseline distribution f(X | E = e0) following a Bernoulli distribution with logit(P(X = 1 | E = e)) = λ0 + γe0.
Results across 1,000 simulated samples with sample size 200 and 1,000, reported in Table 6 in the “Under SORE Model” column, show that (1) the OLS estimates exhibit large bias, and (2) using the OR function ln(η(x; e)) = γ(x − x0)(e − e0), SORE detects endogeneity and corrects for endogeneity bias. As a large-sample procedure, SORE may encounter weak identification with nearly flat likelihood in small samples even when the OR function is correctly specified. For the smaller sample size (N = 200) with a binary endogenous regressor, 2 out of 1,000 generated data sets in our simulation yield almost unidentified models with huge Hessian-based standard error estimates (155.6 and 170.3) for
Estimation for Binary Endogenous X.
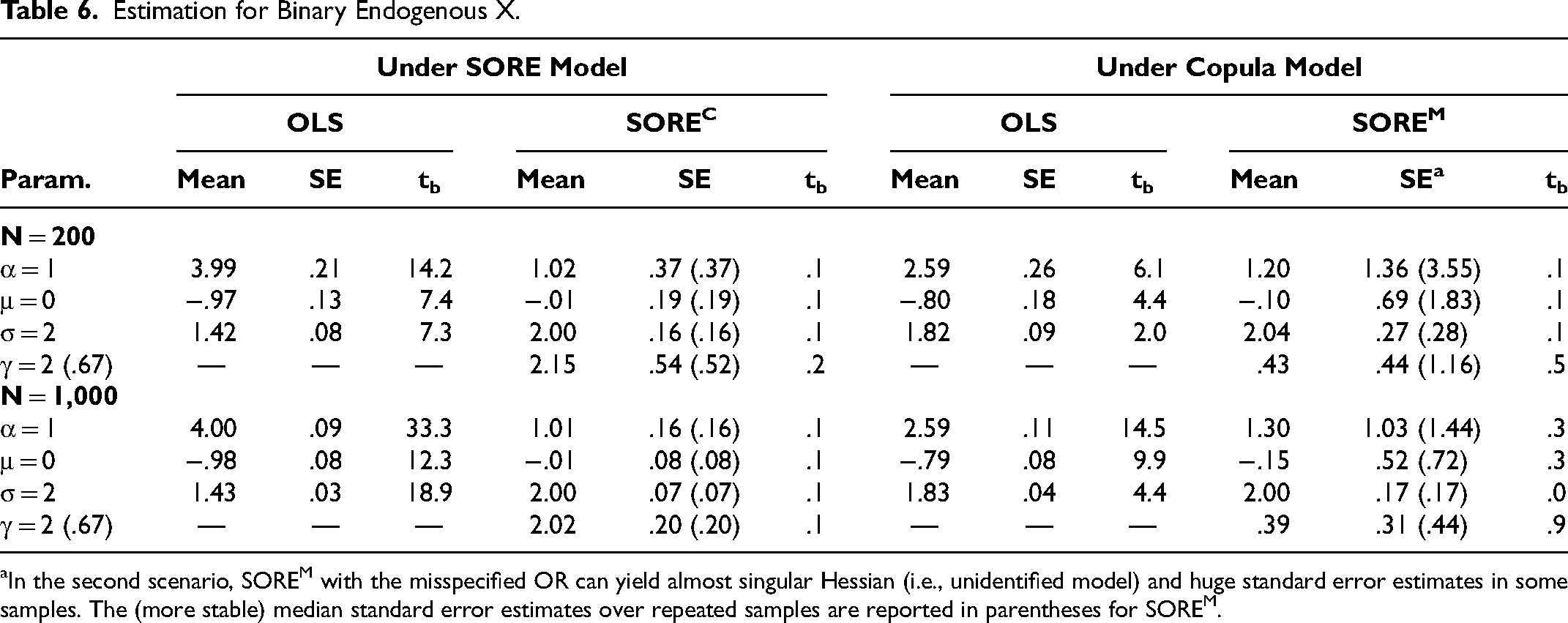
In the second scenario, SOREM with the misspecified OR can yield almost singular Hessian (i.e., unidentified model) and huge standard error estimates in some samples. The (more stable) median standard error estimates over repeated samples are reported in parentheses for SOREM.
In the second scenario, we simulated data from the copula model specified in Equations 25 to 27 except with X being binary and generated as X = 1 (0) if X* > 0 (< 0). This means HX(X = 0) = .5 and HX(X = 1) = 1. In the simulation, we set μ = 0, α = 1, σ = 2, and ρ = .5. Results across 1,000 simulated samples are reported in Table 6 in the “Under Copula Model” column and show that (1) the OLS estimates exhibit large bias, and (2) using the OR function ln(η(x; e)) = γ(x − x0)(e − e0), SORE reduces the bias in OLS estimates but significant bias remains. Similar to the first scenario shown previously, JCM cannot detect endogeneity and yields estimates with similar bias as OLS does. As Web Appendix E shows, the OR used previously in SORE is misspecified in the second scenario. With the misspecified OR function, estimation bias occurs and the standard error estimate for α in SORE is huge (approximately ten times of that of OLS estimates), suggesting model nonidentification issues. Thus, the simulation study illustrates the importance of correctly specifying OR functions and checking standard error estimates to detect potential OR misspecifications.
Additional Simulation Results
We conduct additional simulation studies to evaluate the generalizability, flexibility, and robustness of the proposed SORE methods. In Web Appendix D.1, we describe and demonstrate SORE's capability to handle omitted variables, reverse causality, and simultaneity. We further show that SORE can successfully correct for endogeneity bias for the cases of count endogenous regressors (Web Appendix D.2), endogenous regressors with mixture normal distributions (Web Appendix D.3), multiple endogenous regressors (Web Appendix D.4), and slope endogeneity (Web Appendix D.5). As shown in Becker, Proksch, and Ringle (2021), JCM can be subject to considerable estimation bias in finite samples when the structural model includes an intercept. Using exactly the same setting as Becker, Proksch, and Ringle, the simulation study in Web Appendix D.6 shows that SORE is free from the bias issue encountered by JCM, albeit having substantially larger standard errors when the sample size is small. We also consider the case of linear endogeneity in which a nonnormal endogenous regressor contains a normally distributed additive component causing regressor–error dependence. Haschka (2022) shows that, interestingly, JCM cannot handle linear endogeneity, resulting in bias opposite to that of OLS estimates with huge standard errors relative to those from the OLS estimation. Web Appendix D.7 shows that, like JCM, SORE is subject to the same model nonidentification issue (hugely inflated standard errors). Although such linear endogeneity is unlikely to hold in many empirical applications as noted in Web Appendix D.7, it is important to check model identification and inspect standard error estimates for signs of contraindications of SORE.
We also conduct simulation studies to evaluate the robustness of SORE to modeling assumptions. Web Appendix D.8 assesses the robustness of SORE to the assumption of normal error distributions. We find that SORE yields biased estimates and standard error estimates when the error distribution is skewed or has fat tails. SORE performs well for symmetric nonnormal error distributions without fat tails, yielding unbiased estimates with consistent standard error estimates. Web Appendix D.9 assesses the performance of unidentified SORE models. The adverse effects of unidentified SORE models include biased estimates centered at the OLS estimates and huge standard errors of the coefficients of endogenous regressors relative to those of OLS estimates. The latter adverse effect (huge standard error) can be used as a diagnostic tool to indicate the presence of empirically unidentified models. We also investigate the robustness of OR selection to error distribution misspecifications and find that OR selection using AIC or BIC is robust to symmetric nonnormal distributions and asymmetric nonnormal error distributions (Web Appendix D.11). Web Appendix D.12 shows that OR comparison can select the correct one with multiple and correlated endogenous regressors and that the misspecification of OR causes bias primarily on the coefficient of the endogenous regressor whose OR is misspecified.
Empirical Application
In this section, we apply SORE to the store sales data set used by Park and Gupta (2012) to demonstrate using JCM to handle price endogeneity when estimating the demand for paper towels. Our illustration aims to demonstrate the capability of SORE to (1) model more general forms of regressor endogeneity than that modeled by JCM, and (2) handle discrete endogenous regressors with a small number of levels that JCM is not designed for.
Handling Continuous Endogenous Regressors
The received data set
13
includes weekly store-level sales, retail price (price per roll of paper towels), feature advertising, and in-store display of paper towels at the category level for the two largest independent stores in Eau Claire, Wisconsin, from 2001 to 2005. All the preceding category-level variables (sales, retail price, feature advertising, and in-store display) are computed as market-share weighted averages of the respective Universal Product Code–level variables and take on continuous values. As in Park and Gupta (2012), we estimate the following demand model: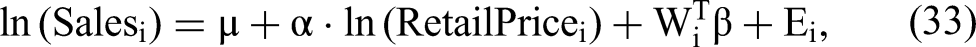
The endogeneity of retail price can occur because of unobserved product attributes or demand shocks that affect consumer demand and retailer pricing decisions. These unobservables are absorbed into Ei, causing the price–error dependence and the endogeneity of retail price. Thus, the OLS estimates of the preceding demand model are subject to potential endogeneity bias. Subsequently, we apply SORE to correct for potential price endogeneity, using the TSLS estimator as the benchmark to assess SORE's performance. As in Park and Gupta (2012), TSLS estimation uses the log retail price at the other store as an instrument for the log retail price at the focal store. Prices of the paper towels at the two stores are highly correlated (Pearson correlation coefficient = .83) because the two stores typically have similar wholesale product prices. Meanwhile, unobserved product attributes, including retailer decisions about shelf location and facings, are unlikely to be related to wholesale prices. Under this assumption, the log retail price at the other store can serve as a valid IV for the endogenous log retail price at the focal store in the estimation.
SORE requires no IVs. Like JCM, however, SORE requires modeling regressor–error dependence and sufficient nonnormality of the endogenous regressor (Corollaries 2 and 3 in Web Appendix B). The distributions of the log retail price at the two stores are both left-skewed and reject normality at the .01 level for both Shapiro–Wilk and Kolmogorov–Smirnov tests, suggesting that the log retail prices at the two stores are not normally distributed. Compared with JCM, SORE achieves identification under the weaker assumption that price endogeneity is of a form in the set of OR functions considered in Table 7, which include JCM as special cases. These OR functions relax the assumption of GC regressor–error dependence and the assumption of independence or GC relationship between exogenous and endogenous regressors imposed in JCM and its recent extensions. Meanwhile, the assumption that the regressor–error dependence follows either a GC or an LB structure is untestable. As noted in the “Considerations in Specifying OR Functions” section, these two classes of structures cover broad types of regressor–error dependence unconstrained by marginal distributions of endogenous regressors; they cover the widely applicable GC dependence and broaden it to even greater scopes of regressor endogeneity. Specifically, that section shows that GC dependence is a plausible model for explaining regressor endogeneity due to omitted variables. Furthermore, as shown in Web Appendix D.1, regressor–error dependence follows the GC OR function when the regressor (price here) and these omitted variables (or a linear combination of these variables) jointly follow a GC model. This assumption is empirically plausible given that the GC model is flexible and applicable in many marketing applications to capture relationships among variables (Danaher and Smith 2011; Eckert and Hohberger 2023; Park and Gupta 2012). Meanwhile, because GLMs are frequently used to model dependence in practical data analysis, it is also plausible to assume that the error term relates to the price via an LB OR function, which captures price–error dependence via distribution-free GLMs for dependence and, like the GC model, captures the dependence irrespective of marginal distributions.
Model Selection.

aModel with smallest AIC.
bModel with second smallest AIC.
Notes: MLL = maximized log-likelihood. AIC = 2d − 2MLL, where d is the dimension of (θ, γ). BIC yields the same model selection results as AIC and is thus not presented. M5 and M3 yield SORE counterparts of JCM and its extensions assuming GC regressor–regressor dependence, respectively.
To select proper OR functions, we adopt a standard model selection approach that treats all OR functions in Table 7 as equally possible a priori, and relies on the AIC or BIC to select OR functions. 14 Propositions in the “Model Identification” section inform the sources of identifications for the selected OR functions. It is important to check whether empirical identification is achieved for particular OR functions given the data at hand. We will inspect standard errors from SORE with the selected OR functions to verify empirical identification and check for signs of weakly identified or unidentified models or misspecified regressor–error dependence.
The OR functions in Table 7 permit both GC and non-GC (LB) dependence for both regressor–error (Price–E) and regressor–regressor (Price–W) relationships. For example, M2 in Table 7 specifies GC Price–E dependence and LB Price–W dependence with
Table 7 reports AICs for all SORE models. For the ith SORE model in Table 7, we define Δi = AICi − AICmin, where AICi and AICmin denote AIC for the ith model and the best model in the consideration set, respectively. A rule of thumb is that models with Δi < 2 have strong data support; models with 4 ≤ Δi ≤ 7 have considerably less support; and models with Δi > 10 have no support (Burnham and Anderson 2004). Table 7 shows that M1 has the smallest AIC and is the best model. According to the rule, the SORE model M2, the second best model, yields a comparable AIC as the best model in Store 2 (Δi ≈ 2), and less so in Store 1 but cannot be ruled out (Δi ≈ 7). Interestingly, SORE M1 has smaller AICs than M2, suggesting that LB explains regressor–error dependence better than GC. All other SORE models have no support (Δi > 10). Table 8 reports the estimation results of M1 and M2 together with OLS and TSLS. Our implementation of TSLS using Stata yields price estimates that are consistent with those reported in the original article on the direction of potential bias in the OLS estimates but with somewhat different sizes. For Store 1, the OLS, TSLS, SORE M1, and SORE M2 estimates (with standard errors in parentheses) for the price coefficient are −.676 (.151), −1.128 (.224), −1.193 (.194), and −.947 (.204), respectively. JCM yields a similar estimate to that of SORE M2 and so is not reported. The price coefficient from OLS is substantially greater than that from TSLS, suggesting the presence of price endogeneity. The Hausman test for endogeneity from TSLS also confirms price endogeneity (p = .004). The OLS price coefficient estimate is biased likely because the unmeasured product characteristics captured in E can cause a positive correlation between E and Price, leading to upward bias (meaning less consumer price sensitivity) in the OLS estimate of the price coefficient. Price coefficient estimates from both SORE M1 and M2 show greater price sensitivity than the OLS estimate, suggesting that both models correct price endogeneity. SORE M1's price estimate (−1.193) is closer to the TSLS price coefficient estimate (−1.128), consistent with the fact that M1 outperforms M2 in AIC. In fact, 95% CIs for the price coefficient estimate from both TSLS and SORE M1 exclude the OLS estimate, whereas that from SORE M2 does not. The standard errors of SORE models are comparable to those of TSLS and only slightly larger than those of OLS, showing no signs of weak identification.
Paper Towel Sales Estimation Using SORE Models.
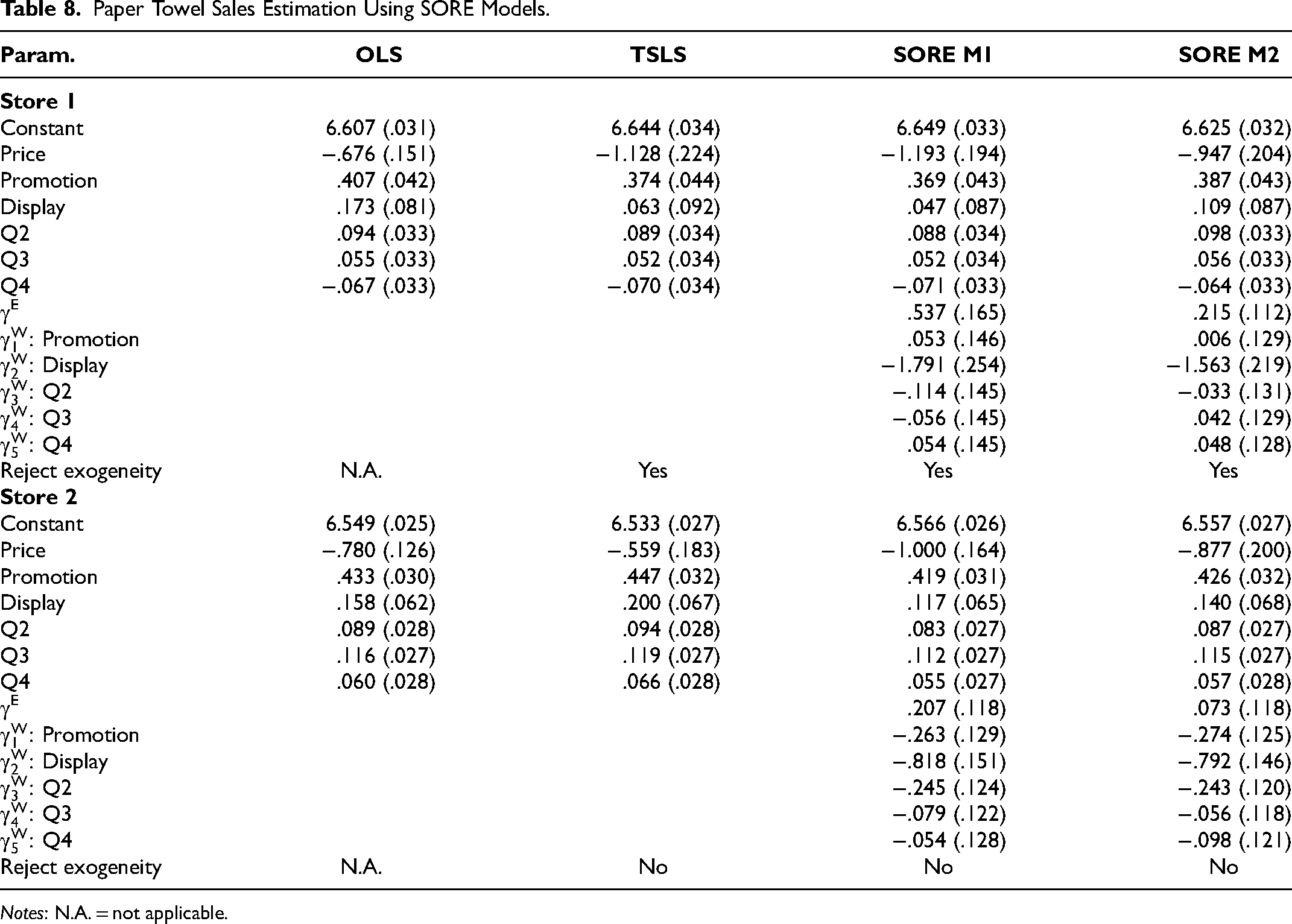
Notes: N.A. = not applicable.
Both estimates of γE in SORE M1 and M2 are positive, consistent with the positive correlation between price and unmeasured product characteristics. The Wald test for the null hypothesis of
Results from Store 2 show no presence of price endogeneity. The Hausman test from TSLS as well as the endogeneity tests from both SORE M1 and M2 all fail to reject the null hypothesis of price endogeneity. In this case, the differences in price coefficient estimates from different methods can be attributed to sampling variability. In particular, 95% CIs from TSLS and SORE M1 and M2 all include the OLS price coefficient estimate.
Handling Discrete Endogenous Regressors
To illustrate the capability of SORE to handle discrete endogenous regressors, we create new price variables by grouping the retail price into discrete levels. We first create a count price variable, PriceQuarters, by rounding the detrended retail price to the nearest price in the multiple of quarters (i.e., $.25) and then taking its logarithm. Thus, PriceQuarters can be considered as a count variable as it takes nonnegative integers before taking logarithm and has no theoretical upper bound. Figure 3 shows the histogram of exp(PriceQuarters) for Store 1 (Store 2 is similar). We then create a two-tier price variable PriceHigh, which equals 1 if the retail price is at least $1.00 and equals 0 otherwise.

Histogram of exp(PriceQuarters) in Store 1.
We then estimate the demand model with PriceHigh or PriceQuarters as the price variable, and continue to use TSLS as the benchmark. TSLS estimation uses the same continuous IV (the detrended log retail price in the other store), as used in the preceding subsection. TSLS can be applied to binary and other types of discrete endogenous regressors in the same way as for continuous endogenous regressors (Wooldridge 2010, chap. 5). To avoid nonuniqueness of inverse mapping from CDFs of discrete endogenous regressors, SORE considers the following OR functions with LB regressor–error dependence for ln ηγ(PriceHighi; Ei, Wi):

Table 9 reports the estimation results. For Store 1, the coefficient estimates (standard errors) for PriceHigh from OLS, TSLS, SORE2, and SORE1 are −.012 (.031), −.677 (.232), −.347 (.046), and −.348 (.044), respectively. These estimates and standard errors cannot be compared with those reported in Table 8 for the continuous endogenous regressor Price because the binary and continuous regressors are on different scales and have different meanings. Nonetheless, we observe a similar finding of upward bias of the OLS price coefficient estimate, as compared with the TSLS price coefficient estimate. In the binary case, the price endogeneity is so large that the OLS price coefficient estimate is close to zero. TSLS changes the price estimate from −.012 to −.677 with the Hausman test concluding strong price endogeneity (p < .001). SORE1 has a smaller AIC than SORE2 (Table 9), suggesting that LB captures the relationship between Price and other regressors better than GC, although both yield almost identical price estimates. SORE1 yields a price estimate of −.348 that is relatively close to the TSLS price coefficient estimate and within the 95% CI from TSLS: −.677 ± 1.96 × .232 = (−1.132, −.222). The estimate of γE is 1.428 (SE = .336), resulting in a high statistical significance supporting price endogeneity (p < .001). TSLS has substantially greater standard errors than SORE, likely because of the reduced IV strength (a weaker correlation between log retail price in Store 2 with the binary regressor PriceHigh in Store 1, compared with that between the log retail prices of both stores). Thus, the difference in price estimates between SORE and TSLS in Store 1 likely results from less precise estimation using a weak IV. The small standard errors of SORE also indicate no issues with model identification. Overall, the analysis validates SORE's ability to handle binary endogenous regressors.
Estimation Results with Discrete Endogenous Regressors.
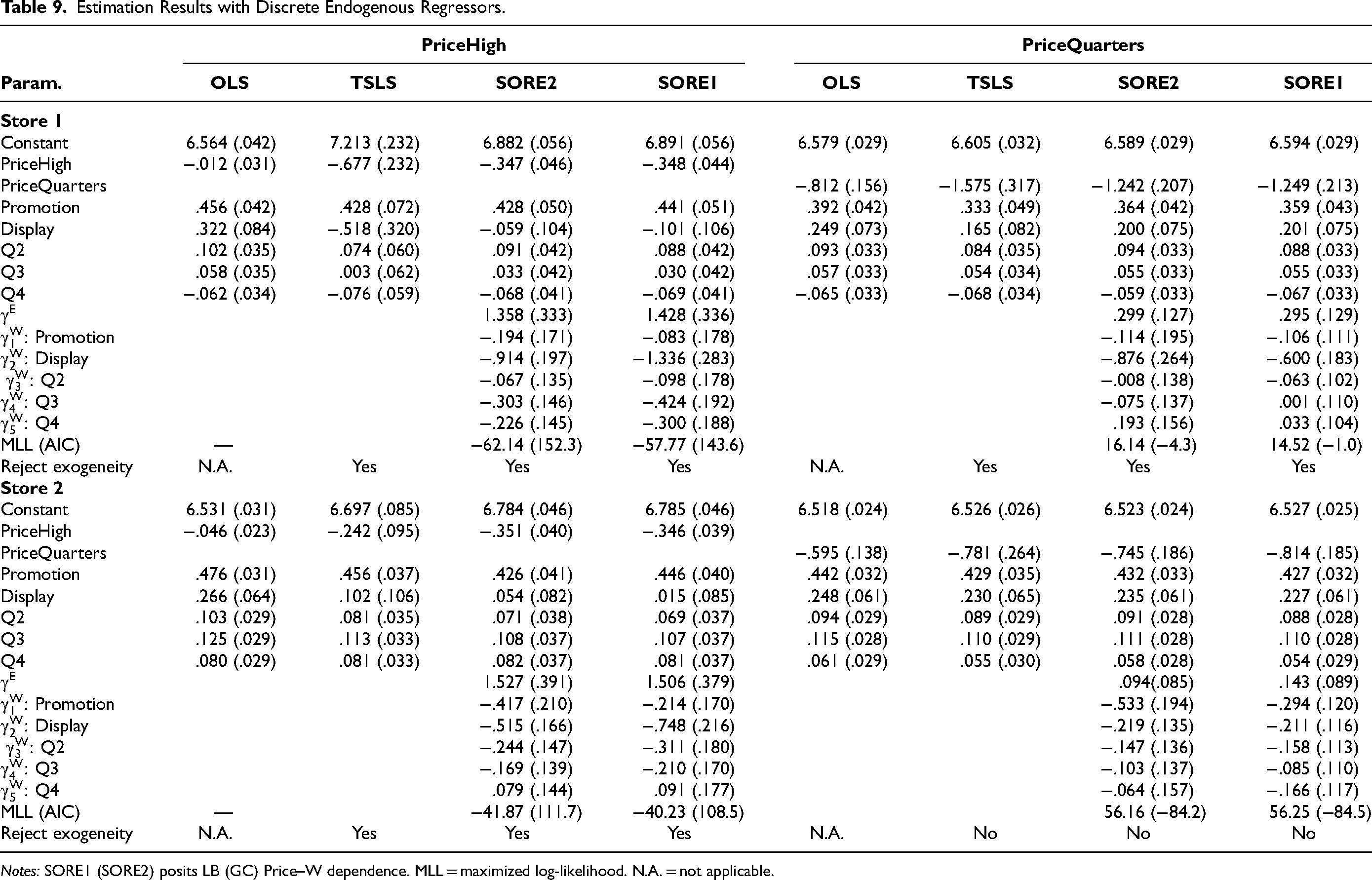
Notes: SORE1 (SORE2) posits LB (GC) Price–W dependence. MLL = maximized log-likelihood. N.A. = not applicable.
For Store 1, the estimates (standard errors) for PriceQuarters from OLS, TSLS, SORE2, and SORE1 are −.812 (.156), −1.575 (.317), −1.242 (.207), and −1.249 (.213), respectively (Table 9). We similarly find that the OLS price estimate has substantial upward bias and is outside of the 95% CI of the TSLS price estimate: −1.575 ± 1.96 × .317 = (−2.20, −.95). SORE can detect price endogeneity and yield a price estimate reasonably close to the TSLS estimate and within its 95% CI. Furthermore, the SORE price estimate has a smaller standard error than TSLS, due to the weaker IV used.
In Store 2, SORE1 and SORE2 yield almost identical AICs and similar price coefficient estimates. Compared with Store 1, price coefficient estimates from TSLS and SORE are even closer to each other, supporting the validity of the SORE estimates. Furthermore, Hausman tests for endogeneity using TSLS confirms that PriceHigh is endogenous (p < .01), but PriceQuarters is not (p > .01) in Store 2. SORE1 (SORE2 is similar) produces similar endogeneity test results: p < .001(
Conclusion
Proper study design and best data collection (including observable instruments) should always be considered first for causal inference before resorting to poststudy estimation methods. However, ideal study design or data collection frequently is not achievable (e.g., for ethical reasons, poor external validity of experiments, lack of good IVs). Given the challenges in implementing ideal study designs and identifying valid IVs to control for endogeneity bias, developing feasible IV-free bias-correction methods is a viable and attractive alternative, when no ideal study designs or good IVs are available.
We propose a novel IV-free joint estimation approach to correcting for endogeneity bias due to regressor–error dependence. The approach employs flexible SORE models for the conditional distribution of endogenous regressors given the structural error and exogenous regressors, and obtains all parameter estimates in one step by maximizing the joint likelihood of endogenous regressors and structural error given exogenous regressors. 15
The empirical application illustrates that SORE either handles situations that existing IV-free methods cannot deal with or provides opportunities to improve the accuracy of causal effect estimation, and can be useful in several ways. First, empirical researchers can use SORE to handle discrete endogenous regressors more effectively. The application to the paper towel data shows that SORE yields plausible price coefficient estimates when the pricing variable has only a few levels (Table 9), demonstrating the unique capability of SORE to handle discrete endogenous regressors with few levels. Second, researchers can use SORE as a device to discover novel identification strategies. We derive a new identification strategy encoded by the LB OR function and illustrate its use in the application. We envision that more novel identification strategies will be motivated and discovered in the SORE framework. Last, SORE can be used as a multimethod approach to improve the robustness and quality of causal inference (Papies, Ebbes, and Feit 2022). The development of SORE moves toward this goal by nesting JCM in a more general framework that permits both copula and noncopula regressor–error dependence. Robustness of causal estimation can be assessed by comparing results from OR functions supported by theoretical considerations or selected by model selection measures. In the paper towel application, comparisons of different OR functions using AIC find some evidence favoring the LB regressor–error dependence (Table 7). Both TSLS and the best SORE model (M1) assuming the LB regressor–error dependence selected by AIC yield 95% CIs that exclude the OLS price estimate in Store 1, whereas that from the best SORE model (M2) assuming GC regressor–error dependence does not (Table 8). Despite these numerical differences, the price estimates from the two selected SORE models in Store 1 are both reasonably close to the TSLS price estimate. Furthermore, the TSLS, two selected SORE models, and JCM all (1) find price endogeneity and yield price estimates showing greater price sensitivity than the OLS price estimate in Store 1, and (2) find no price endogeneity in Store 2, 16 demonstrating the robustness to the assumed regressor–error dependence structures.
SORE has notable limitations and avenues for future research. SORE requires nonnormally distributed endogenous regressors for model identification. Despite the use of profile likelihood to eliminate nuisance parameters, SORE for continuous endogenous regressors can demand considerable computation time. For continuous endogenous regressors, it is straightforward to implement with minimal computation time the generated regressor copula endogeneity correction approach (Park and Gupta 2012) and the two-stage generated regressor copula approach (Yang, Qian, and Xie 2022). The latter approach is also able to handle normally distributed endogenous regressors. The proposed likelihood-based model selection to compare different OR functions does not incorporate prior beliefs. Bayesian approaches can be more suitable for this purpose as well as for handling large parameter spaces and weak model identification problems. This work considered two broadly applicable dependence structures: GC and LB. Studying new classes of OR functions could expand the applicability and capability of SORE. Finally, extending SORE to panel data is an important research avenue.
Supplemental Material
sj-pdf-1-mrj-10.1177_00222437231195577 - Supplemental material for Correcting Regressor-Endogeneity Bias via Instrument-Free Joint Estimation Using Semiparametric Odds Ratio Models
Supplemental material, sj-pdf-1-mrj-10.1177_00222437231195577 for Correcting Regressor-Endogeneity Bias via Instrument-Free Joint Estimation Using Semiparametric Odds Ratio Models by Yi Qian and Hui Xie in Journal of Marketing Research
Footnotes
Acknowledgments
Coeditor
Peter Danaher
Associate Editor
Fred Feinberg
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors would like to acknowledge grant support from the Social Sciences and Humanities Research Council of Canada (grant 435-2018-0519, grant 435-2023-0306), the Natural Sciences and Engineering Research Council of Canada (grant RGPIN-2018-04313), and the U.S. National Institutes of Health (grant R01CA178061).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.