
Abstract
From advertisers and marketers to salespeople and leaders, everyone wants to hold attention. They want to make ads, pitches, presentations, and content that captivates audiences and keeps them engaged. But not all content has that effect. What makes some content more engaging? A multimethod investigation combines controlled experiments with natural language processing of 600,000 reading sessions from over 35,000 pieces of content to examine what types of language hold attention and why. Results demonstrate that linguistic features associated with processing ease (e.g., concrete or familiar words) and emotion both play an important role. Rather than simply being driven by valence, though, the effects of emotional language are driven by the degree to which different discrete emotions evoke arousal and uncertainty. Consistent with this idea, anxious, exciting, and hopeful language holds attention while sad language discourages it. Experimental evidence underscores emotional language's causal impact and demonstrates the mediating role of uncertainty and arousal. The findings shed light on what holds attention; illustrate how content creators can generate more impactful content; and, as shown in a stylized simulation, have important societal implications for content recommendation algorithms.
Keywords
Everyone wants to hold their audience’s attention. Salespeople want prospects to listen to their pitch, and brands want consumers to watch their ads. Leaders want employees to read their emails, and teachers want students to listen to their lessons. Platforms want consumers to stay on their sites, and media companies want readers to consume more of their articles.
It's clear why. The further down a news story people read, the more advertising revenue that article generates. The longer audiences spend watching an influencer's videos, the higher the rate the influencer can command from brands. And the more an advertisement, email, or any other piece of content holds attention, the more consumers will learn about the product, service, or issue discussed (Ward, Zheng, and Broniarczyk 2022).
But not all content holds attention. Some articles captivate readers and encourage them to keep reading, while others lose readers’ interest after just a few sentences. Why? And how might the way content is written (i.e., the language used) shape whether audiences stay engaged?
A multimethod investigation begins to address these questions. Natural language processing of over 600,000 reading sessions from 35,000 pieces of content, combined with controlled experiments, illustrates how language holds attention. Language that is easier to process encourages continued reading, as does language that evokes emotion, but not all emotional language has the same impact. Instead, these effects are driven by the degree to which different discrete emotions evoke arousal and uncertainty. Consistent with this, anxious, exciting, and hopeful language all encourage reading, while sad language discourages it. A simulation highlights the implications of these findings for algorithms trained to sustain attention.
Our findings make four main contributions. First, they deepen understanding around what holds attention. While some research has examined what attracts attention (e.g., a catchy headline; Kim et al. 2016; Lai and Farbrot 2014) or drives word of mouth (for a review, see Berger [2014]), there has been less attention to how language sustains attention, or keeps people consuming content once they’ve started. We demonstrate the important role of emotional language and processing ease and show how different linguistic features shape content consumption through these key aspects. Along the way, we contribute to the emerging stream of work on consumer language research (Luangrath, Peck, and Barger 2017; Moore 2015; Packard and Berger 2017, 2021; Packard, Berger, and Boghrati 2023; Pogacar, Lowrey, and Shrum 2017; for reviews, see Berger et al. [2020] and Packard and Berger [2023]).
Second, the findings help improve content design. From advertisers and marketers to publishers and presenters, content creators don’t just want clicks or views, they want to hold the audience's attention. We show how simple shifts in language can encourage sustained attention. Further, while intuition might suggest that certain topics are just better at keeping people engaged (e.g., celebrity gossip as opposed to financial literacy), we show that how content is written can make up for some of these differences. Writing in the right ways can increase sustained attention, even for less engaging topics.
Third, the results highlight that what holds attention is not always the same as what grabs attention or encourages word of mouth. While language that projects certainty can increase likes and shares (Pezzuti, Leonhardt, and Warren 2021), for example, when it comes to sustaining attention, we show that emotions that make people feel certain are actually detrimental. Similarly, while some have argued that content that requires more cognitive processing should increase clicks (Kanuri, Chen, and Sridhar 2018), for holding attention, we show that content that requires more processing has the opposite effect. These differences highlight that retaining attention is a different type of engagement and that findings from one type of engagement may not necessarily carry over to others. Consequently, when developing content, managers should think carefully about which outcomes they care most about, and design with that in mind.
Fourth, our findings have important societal implications. Online content consumption has become a critical social issue. Disinformation and hate speech have been linked to negative outcomes for individuals and society (e.g., Choi, Gaysynsky, and Cappella 2020). Our results highlight language's critical role in this process. If angry and anxious content holds attention, as our simulation shows, training algorithms to maximize sustained attention (Newberry 2022; The Wall Street Journal 2021) may lead this content to be recommended, with potentially negative implications for consumer welfare.
Types of Engagement
Before examining why certain content holds attention, it is important to distinguish retaining attention from other types of engagement (Table 1). One way of measuring engagement is through clicks, views, or other metrics that measure how many people were exposed to a piece of content (e.g., an article on recycling). Research has examined how headlines or advertisements attract attention, for example, influencing click-through or the number of views content receives (Kim et al. 2016; Lai and Farbrot 2014). Similarly, related work has explored how times of day and message features affect how many clicks links receive (Kanuri, Chen, and Sridhar 2018).
Types of Engagement.

But while attracting attention is important, it's not enough. The more of a piece of content consumers read, the more knowledge they gain (Ward, Zheng, and Broniarczyk 2022; also see Hidi 1990; Kintsch 1980). Further, focusing on short-term metrics like views and clicks leads to clickbait, or headlines that attract attention but do not necessarily lead people to consume the content. Indeed, companies like YouTube and Facebook use measures such as dwell time, or how long users spend consuming a piece of content, to better measure engagement, estimate relevance, and improve rankings and recommendations (Cramer 2015; Newberry 2022; Yi et al. 2014).
Consequently, beyond whether an article, advertisement, or other piece of content attracts attention, sustaining attention refers to whether that content holds attention. A catchy headline might lead someone to click on a link, for example, but once they open the article, how much of it do they actually read? Just the first few sentences or most of the article? Holding attention involves retaining the attracted attention, keeping audiences engaged.
Once someone has been exposed to content, they can also like it, comment on it, or share it with others. Some work has focused on what drives liking and commenting (e.g., Peters et al. 2013; Pezzuti, Leonhardt, and Warren 2021), while other work has focused on word of mouth and what drives social shares (for a review, see Berger [2014]). Social acceptance motives, for example, shape what people share (Chen 2017), as does interpersonal closeness (Dubois, Bonezzi, and De Angelis 2016). Similarly, products that are more publicly visible or triggered more by the environment are talked about more (Berger and Schwartz 2011).
But while things like shares affect diffusion, they say less about content consumption. It's easy to click a “like” button, or share online content without reading it (Gabielkov et al. 2016), so these actions say little about whether anyone actually consumed the content (i.e., considered the information inside). While getting lots of shares is great for diffusing an article on recycling, for example, it's tough for that article to change behavior if no one actually reads it.
Consequently, marketplace actors don’t just care about clicks and likes; they care about whether people actually consume their content. Holding attention deepens brand relationships, encourages learning, and drives purchase and choice (e.g., Schweidel and Moe 2016; Ward, Zheng, and Broniarczyk 2022). 1 Similarly, sustaining engagement increases opportunities to display ads and generate ad revenue (see Yan, Miller, and Skiera 2022).
So, what makes content more likely to sustain attention?
Sustaining Attention
While decades of research in education, psychology, and communication have examined topics such as how readers go from eye fixations to comprehension (Just and Carpenter 1980) or generate inferences about what a text is about (Graesser, Singer, and Trabasso 1994), there has been less work on sustaining attention. Some research suggests that people will be more engaged in topics they find personally interesting (for a review, see Hidi [1990]), but this says less about textual features that might encourage interest across people, regardless of topic.
Further, while a few papers have begun to explore textual features associated with interest (e.g., Schraw and Lehman 2001), this work has relied on forced reading paradigms. Rather than examining how much people read, laboratory participants are told to read an entire document and, at the end, report how interesting they found it (e.g., Schraw, Bruning, and Svoboda 1995). Such situations provide tight experimental control but are unrealistic. In real life, consumers don’t have to read an entire article and can opt out at any point. Further, it's not clear that the same things that shape reported interest after forced reading would apply when people can choose to stop reading whenever they want. While reasoned arguments might be rated as interesting if people are forced to slog through them, if they are too boring in real life, readers may just move on to something else. Consequently, what holds attention in actual content consumption remains unclear.
What Holds Attention?
We suggest that processing ease and emotional language are two key factors that sustain attention.
Processing Ease
In our context, processing ease describes how much cognitive effort text requires to process. Some research suggests that there are benefits to increased processing. In the context of clicking on social media links, for example, Kanuri, Chen, and Sridhar (2018) argue that links that require more cognitive processing should receive more engagement (i.e., clicks). Thus, one might imagine that textual features that increase cognitive processing should sustain attention and encourage continued consumption.
In contrast, we suggest the opposite. While there are certainly situations when more processing may be useful, in the context of continued consumption, we suggest that textual features that make content easier to process should have positive effects. Just as objects are more likely to keep moving when there is less friction, the easier something is to do, the more likely people are to continue doing it (Kool et al. 2010; Zipf 1949). Processing ease can also generate positive affect (Alter and Oppenheimer 2019), which could sustain attention and encourage continued consumption.
This should play out at both the word and sentence level. The word “car,” for example, is relatively straightforward to process. It is short, familiar, and concrete, all of which should make it easy to read, parse, and comprehend (Connell and Lynott 2012; Kincaid, et al. 1975; Winkielman and Cacioppo 2001). In contrast, a word like “Australopithecus” is more difficult to process. It's longer, less familiar, and even someone who knows what it means would likely say that meaning is more abstract. Consequently, not only does it take longer to read and comprehend, but it requires more effort. This should discourage attention and decrease the likelihood of continued content consumption.
The same logic can be applied to larger chunks of text like sentences. Longer sentences generally require more effort to read, as do sentences that are more syntactically complex. While both “The cat on the hot tin roof meowed at my parents' house” and “The cat on the hot tin roof at my parents' house meowed” involve similar content, the second one has a taller parse tree (i.e., eight edges vs. six edges tall) because it takes more steps to get from the root, or top node, to the bottom-most node. Differences in syntactic complexity, in turn, can shape how easy sentences are to read and understand (Pitler and Nenkova 2008; Schwarm and Ostendorf 2005).
In summary, we suggest that textual features that require more cognitive processing should discourage sustained attention and reduce continued consumption. Further, the fact that we expect different effects for sustained attention than prior work found for clicks underscores our suggestion that sustained attention is distinct from other types of engagement (i.e., clicks) and involves different managerial insights.
Emotional Language
Beyond how easy text is to process, we suggest that emotional language will also shape whether content holds attention. Emotions can increase attention or flag that something is important and deserves further consideration (Easterbrook 1959; Vuilleumier 2005). In particular, we suggest that whether emotional language sustains attention will depend on the link between specific emotions, uncertainty, and arousal.
The role of uncertainty
Emotions vary in the degree to which they are characterized by uncertainty, or not knowing or being sure of something (Lerner and Keltner 2000; Smith and Ellsworth 1985). While some emotions (e.g., anger, pride) tend to be characterized by certainty and lead people to feel certain about their environment, others (e.g., anxiety, hope, surprise) tend to be characterized by uncertainty and uncertainty reduction (Lerner and Keltner 2001; MacInnis and De Mello 2005; Raghunathan and Pham 1999). When angry, for example, people tend to be certain about what they are angry about, but when anxious, people tend to be uncertain about what will occur.
Some work suggests that certain language can increase engagement. In the context of likes, comments, and shares, for example, Pezzuti, Leonhardt, and Warren (2021) find that brands whose social media posts use more certain words (e.g., “always,” “everything”) are liked, commented on, and shared more. Drawing on these findings, one might imagine that emotions associated with certainty (e.g., anger) might sustain attention.
In contrast, we suggest the opposite. While expressing certainty may increase likes or shares because it makes brands seem more powerful (Pezzuti, Leonhardt, and Warren 2021), in the context of holding attention, other aspects of certainty may be more impactful. In particular, uncertainty can increase attention and processing as people try to resolve what will happen (Tiedens and Linton 2001; Weary and Jacobson 1997). If someone feels anxious about whether it will rain, the accompanying uncertainty might lead them to consume information that resolves that uncertainty (e.g., checking the weather).
Consequently, we suggest that language related to uncertain emotions (e.g., anxiety) should hold attention and encourage content consumption compared with language related to certain emotions (e.g., anger). Further, the fact that we expect different effects for sustaining attention than prior work has found for likes and shares underscores the notion that holding attention is distinct from other types of engagement and involves different managerial insights.
The role of arousal
In addition to uncertainty, emotions also vary in their level of arousal or activation (Teeny, Deng, and Unnava 2020; Yin, Bond, and Zhang 2017). Arousal is a state of being physiologically alert, awake, and attentive (Heilman 1997). While some emotions (e.g., anger, excitement, anxiety) are characterized by high arousal, others (e.g., sadness, contentment) are low arousal.
While some work (Kanuri, Chen, and Sridhar 2018) finds no association between high-arousal negative emotion and link clicks, in the context of content consumption, we suggest that language related to high-arousal emotions should sustain attention and encourage continued consumption. A great deal of research finds that emotionally arousing stimuli attract attention (for a review, see Mather [2007]). Work using brain imaging and skin conductance, for example, finds that threat-related stimuli are particularly attention grabbing (Öhman and Mineka 2001), in part because of the arousal involved. Arousal may also lead to an increased state of vigilance (Pham 2004), which should help hold attention. Consequently, compared with low-arousal emotions (e.g., sadness, contentment), we suggest that language related to high-arousal emotions (e.g., anger, anxiety, excitement) should sustain attention and encourage content consumption.
Taken together, rather than suggesting that any emotional language should hold attention and increase content consumption, we make a more nuanced prediction. Whether emotional language sustains attention will depend on the degree to which it is linked to specific emotions that evoke (1) uncertainty and (2) arousal. While anxious (high arousal and uncertainty) language should hold attention, for example, sad (low arousal) language should discourage it. Anger is high arousal and low uncertainty, so its effect should lie somewhere in between and should depend on the confluence of those two aspects in a particular situation. Similar effects should hold for positive emotions (e.g., excitement vs. contentment).
Empirical Tests
A multimethod approach, employing both field data and controlled experiments, tests these predictions. First, natural language processing of over 600,000 page-read events from over 35,000 pieces of content examines whether consumers are more likely to continue reading texts that should be easier to process or contain more emotional language, and whether different specific emotions (e.g., anxiety, sadness) have different effects (Study 1).
Second, follow-up experiments (Studies 2 and 3) test specific emotions’ causal impact and the underlying process. They examine how emotional language shapes continued content consumption and whether, as hypothesized, these effects are driven by uncertainty and arousal.
Study 1: Natural Language Processing of over 35,000 Pieces of Content
Our first study uses natural language processing to analyze the consumption of over 35,000 pieces of content. We examine whether people are more likely to continue reading writing that is easier to process (e.g., because it uses shorter sentences or more familiar language) and uses more emotional language. In addition, we examine whether different specific emotions (e.g., anger vs. sadness) have different effects.
Data
A major content intelligence company provided a representative random sample of page-consumption events (i.e., instances when a user opened an article) over a two-week period from nine sites that together cover a wide range of topics (i.e., global and local news, business, sports, technology, fashion, and lifestyle content). 2 While confidentiality prohibits us from revealing the exact publishers, outlets like CNBC, the Wall Street Journal, Minnesota Star Tribune, and Jezebel provide some sense of the types of content examined. At the time of data collection, the sites used had fixed layouts (i.e., content was laid out the same way across articles), did not have ads within the text, and were nonresponsive (i.e., regardless of whether an article was read on phone, desktop, or other device, content was not reformatted based on viewport size, and line breaks were the same). This characteristic of the data simplified the analysis by eliminating the need to accommodate differences in a reader's screen size or page breaks. The final data set involved 649,129 page-consumption events from 35,448 articles. See Table W1 in the Web Appendix for summary statistics.
Processing Ease
We measure processing ease in four ways. First, to test whether shorter words and sentences (which should generally be easier to process) sustain attention, we use the standard Flesch–Kincaid approach to measure text readability (Kincaid et al. 1975). This approach uses word and sentence length to capture how easy content is to read (i.e., what grade level it is appropriate for). Second, to test whether syntactic simplicity encourages continued consumption, we measure parse tree height, a standard approach in the computer science and linguistics literatures (Pitler and Nenkova 2008). Finally, to test whether familiar or concrete language (which should be easier to process; Connell and Lynott 2012; Winkielman and Cacioppo 2001) sustains attention, we use word ratings from Paetzold and Specia (2016). To facilitate interpretation, we multiply Flesch–Kincaid and parse tree height scores by −1 such that higher scores on readability and syntactic simplicity indicate that the text should be easier to process. We predict that readability, syntactic simplicity, linguistic familiarity, and linguistic concreteness should all make content easier to process and thus sustain attention and encourage continued content consumption.
Emotional Language
While we focus on specific emotions, one might wonder whether all emotional language sustains attention, and whether positive or negative content has different effects. Consequently, before exploring specific emotions, we conduct two simpler specifications: one that groups all emotional language together and one that separates positive and negative language. To do this, we measure emotional valence using Linguistic Inquiry and Word Count (LIWC; Pennebaker, Booth, et al. 2015; Pennebaker, Boyd, et al. 2015).
We also measure language linked to specific emotions. Specific negative emotions are easier to distinguish from one another than positive emotions (Keltner and Lerner 2010), and more sophisticated natural language processing tools exist to extract negative emotions from text, so we focus on specific negative emotions (we explore specific positive emotions in more detail in Study 3). There are reliable, well-validated tools to measure anger, anxiety, and sadness, so we focus on those. While LIWC's positive and negative emotion categories have been validated, the specific emotion categories have less empirical support. Consequently, rather than simply measuring the presence or absence of individual words, we rely on a more continuous approach developed by Mohammad and Bravo-Marquez (2017) that allows for more accurate variation (LIWC provides similar results; see Web Appendix Table W5). They gave raters four pieces of content and asked which had the highest and lowest intensity of different specific emotions (i.e., anger, anxiety, and sadness). Then, they performed machine learning on this training set and used a variety of features (e.g., word embeddings, affect lexicons) to extrapolate responses to a broader set of content.
We use Mohammad and Bravo-Marquez’s (2017) approach to measure the amount of angry, anxious, and sad language in each sentence, averaging across sentences to get a score for each paragraph. (In the Web Appendix, see Table W2 for summary statistics, Table W3 for correlations between variables, and Table W4 for example paragraphs that score highly on each dimension. 3 )
Dependent Variable and Analysis Strategy
While one could model reading an article as a function of textual features of the entire article, behavior can’t be influenced by content that hasn’t been read, so it's important to focus on content that appears before a user stopped. Further, article-level analysis ignores within-article variation (e.g., some paragraphs use lots of anxious language, whereas others do not).
Consequently, we take a more fine-grained approach, examining whether a user continues reading (i.e., moves to the next paragraph) based on the text of each paragraph. To capture paragraph-to-paragraph consumption, we measure how far down the page a user scrolls (see the Web Appendix for a more detailed description and example). This is determined using code embedded on the publishers’ sites and executed on the user's browser when an article is loaded (i.e., for each consumption event). The code records the pixel position a user scrolls to on the page, defined as the top position that is visible on the user's screen, starting from 0 and increasing up to the length of a given article. We then map pixel length to position within the article using a custom CSS selector, unique to each site. 4 The conversion from pixel length and selection of sites with nonresponsive layouts ensures that recorded content consumption is independent of site layout and consistent across devices, screen resolutions, and window sizes. Table W7 contains descriptive statistics for the page-consumption events.
We conceptualize each page-consumption event, i, as a sequence where at the end of each paragraph the user either continues consuming content or stops. We denote the action made after paragraph j of session i as Yij, in which Yij = 1 if the user continues to the next paragraph and Yij = 0 if they do not. We assume that the probability of continuing past paragraph j in session i is a function of the paragraph-level content variables and control variables. Formally, we estimate individual i's probability of continuing past paragraph j as: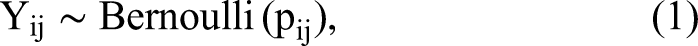

This analysis is consistent with a discrete-time survival analysis. Effectively, we model the “time” (measured in paragraphs) until someone stops reading, recognizing that some individuals may read the entire article. 5 For an individual who is observed to stop reading after seeing paragraph T, this likelihood is given by decisions to continue reading after paragraphs 1, 2, …, T − 1 and to stop consuming after paragraph T. If the predictor variables were assumed to be constant, our analysis would be equivalent to assuming that the time until an individual stops reading the paragraphs of an article follows a geometric distribution. Similar methods have been used to model binge viewing (Schweidel and Moe 2016) and clickstream behavior (Moe 2006; Sismeiro and Bucklin 2004).
Control Variables
While we are interested in emotional language and processing ease, external factors (e.g., device, publisher), aspects of the article (e.g., topical content), reader progression (e.g., how much they have read so far), and other aspects of the paragraph (e.g., topical content) may also shape reading, so we control for them to test alternative explanations and robustness of the effects.
Device
Different types of people may use different devices (e.g., mobile vs. desktop), or use different devices at different times, and the device itself may impact behavior (Ransbotham, Lurie, and Liu 2018). To control for these possibilities, we use dummy variables to control for whether users read an article on mobile, desktop, or tablet (.5% of page reads are from an unknown device).
Publisher
Different publishers may attract different types of people, attract people when they have more or less time to read, or publish articles that encourage differential attention. To control for these possibilities, we use publisher-specific fixed effects.
Temporal controls
Time of day (i.e., early morning, morning, afternoon, evening and overnight) or day of week may also impact attention, so we include fixed effects for each.
Article content
Beyond external factors, aspects of the article itself may also shape attention. Before reading an article, consumers are usually exposed to its headline or a brief summary. This content may impact who starts the article, when they read it, and their initial interest level. We control for this in two ways.
First, we control for topical focus. Articles about certain topics may attract different types of people, attract people when they have more time to read, or impact attention in other ways. The websites in our data set include the article's headline or a related summary in the article's URL. As an illustration, an article in the Wall Street Journal entitled “IKEA Sales Boosted by China” is associated with the URL https://www.wsj.com/articles/ikea-sales-boosted-by-china-1410246927. We extract the article summary (in this case, “ikea sales boosted by china 1410246927”) for each article and perform topic modeling on the resulting words, allowing each summary to be represented as a proportion of different topics. We use latent Dirichlet allocation (e.g., Blei, Ng, and Jordan 2003), a common topic modeling framework (e.g., Berger and Packard 2018; Tirunillai and Tellis 2014), and include the posterior topic probabilities as control variables to represent the relative prevalence of each topic at the article level.
Second, we measure the presence of the same emotions measured in the body of the article and control for those as well.
Article popularity
Article popularity may also pick up variation in what attracts and holds attention that is not reflected in other aspects of the content. We account for this by including the logarithm of the number of unique readers of the article.
Reading progress
We also control for within-article aspects. More time spent reading an article may make readers more or less likely to continue reading, so we control for how much content someone has consumed so far using words up to that point. Continued consumption may also depend on where someone is in the article, so we also control for percentage consumed so far. We use both linear and quadratic terms to allow for nonlinearities.
Paragraph topics
We also control for other features of the focal paragraph. Just as the article's headline may impact reading, so might the topical content of the focal paragraph. Following the procedure for article summaries, we control for topics across all paragraphs (see Web Appendix Table W6 for distribution of topics across articles and sample words), which includes subjects like government (e.g., “state,” “govern”), sports (e.g., “game,” “team”), and personal technology (e.g., “app,” “google”). We include the posterior topic probabilities topics as control variables to represent the relative prevalence of each topic in each paragraph.
Other linguistic features
We also control for other linguistics features of the focal paragraph (i.e., baskets of words linked to other social or psychological constructs from LIWC dictionaries such as cognitive processes, sociality, perception, motivation, time, and formality).
Paragraph length
Given limited attention spans, the longer a paragraph is, the less likely people may be to read the next one. Consequently, we control for paragraph length using the number of words.
User heterogeneity
Finally, to accommodate differences across users in content consumption behavior, we adopt a modeling approach that allows for unobserved heterogeneity in users’ baseline levels of sustained attention (see the following section).
Model Specification
We estimate several models. Model 1 groups all emotional language together (i.e., emotionality), Model 2 separates positive and negative language, and Model 3 explores specific emotions. In addition to controlling for the factors previously mentioned, each model examines effects of processing ease (i.e., readability, syntactic simplicity, familiarity, and concreteness).
To accommodate user heterogeneity, we model user-specific fixed effects governed by a discrete mixture model (Vilcassim and Jain 1991). Specifically, we allow β0 to be characterized by N finite supports with probability masses [q1 q2 … qN]. As we increase the number of supports from N = 1 to N = 3, the substantive findings are unchanged. For N = 3, the smallest probability mass is less than 1%. Based on this, we present our empirical findings associated with N = 2. 6
To accommodate heterogeneity across articles, we control for article-level differences through the content of the headlines/summaries (i.e., topics and emotional content) and differences in views across articles. 7
Results
Processing ease
Supporting the hypothesized benefits of processing ease, content that was more readable, syntactically simple, and used familiar or concrete language was more likely to hold attention (all coefficients are positive and ps < .001; see Table 2). For example, the paragraph “It's the great retirement debate: How much can retirees spend each year without running out of money before they run out of breath?” was high on familiar language (.69) and had a higher completion rate (90%) than the paragraph “In a letter to a friend, the manager of a Florida urology practice worried in 2010 that her company would attract federal scrutiny for its frequent use of an expensive bladder-cancer test” (familiarity = −.95, completion rate = 81%).
How Content Characteristics Sustain Attention.
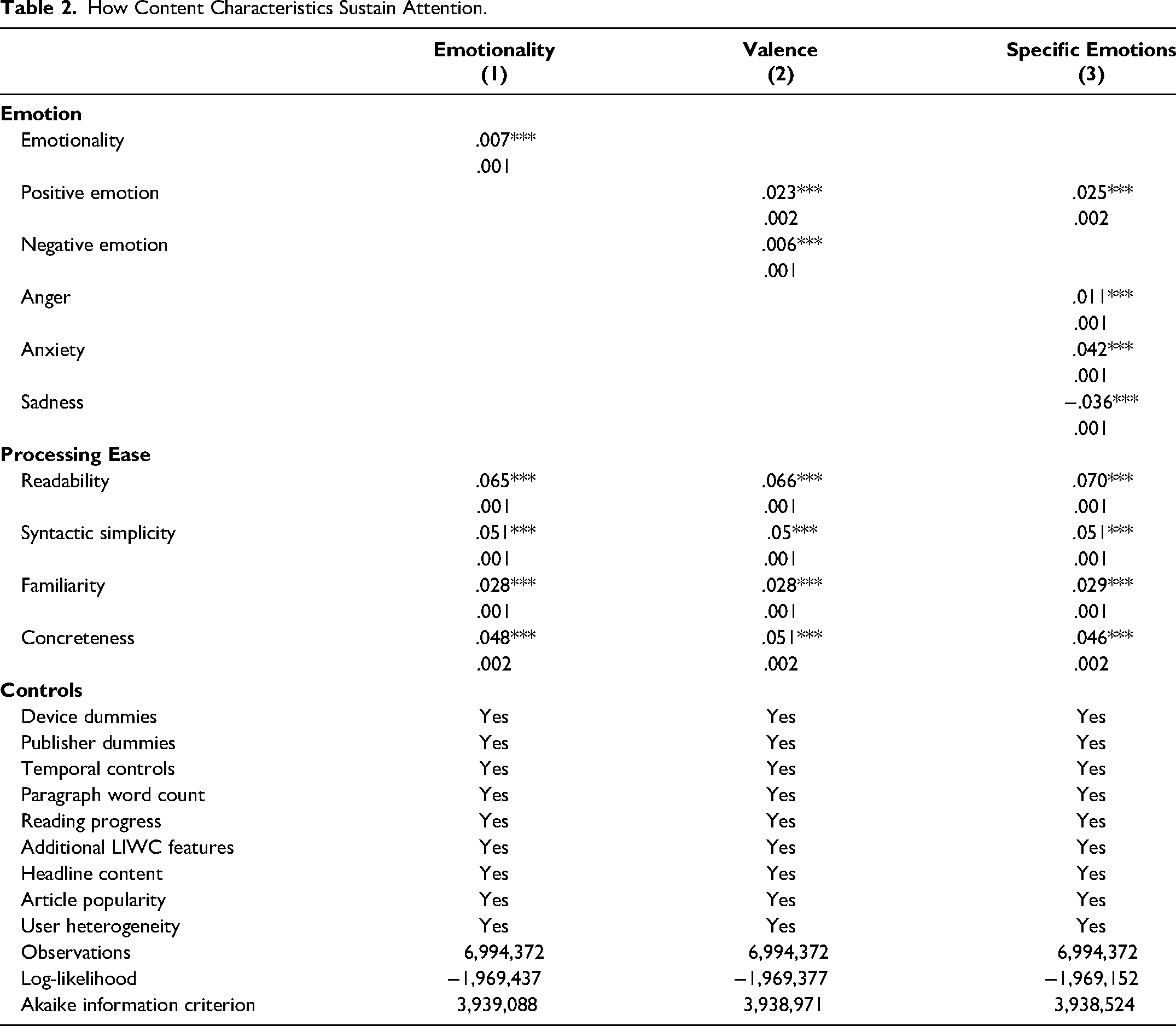
Emotional language
Model 1 suggests that more emotional language holds attention (β = .0072, p < .001), and Model 2 suggests that this is true for both positive (β = .023, p < .001) and negative (β = .0060, p < .001) emotions.
Consistent with our theorizing, however, exploring specific emotions (Models 3) paints a more nuanced picture. While anxious (β = .042, p < .001) or angry (β = .011, p < .001) language held attention, sad language discouraged it (β = −.036, p < .001). For example, see the following paragraph: In the winter of 1947, an American tourist arrived in New York City on a bus from Mexico, feeling feverish and stiff. He checked into a hotel and did some sightseeing before his condition worsened. A red rash now covered his body. He went to a local hospital, which monitored his vital signs and transferred him to a contagious disease facility, where he was incorrectly diagnosed with a mild drug reaction. He died a few days later of smallpox.
This paragraph was high on sad language (1.23) and was less likely to be completed (91%) than the following paragraph: This winter, the Santa Cruz Museum of Art & History will feature an exhibit of works relating to the ocean, with paintings and sculptures by established artists alongside works by local residents. According to a call for submissions, that includes not just watercolors of Pacific sunsets, but that awesome GoPro footage you took while surfing and your two-year-old’s drawing of the beach that’s been on the fridge for five months.
This paragraph was below average on sad language (−2.71, 94% completion rate). See Table W4 for more examples.
The fact that different specific negative emotions have different effects suggests that emotions’ ability to sustain attention is driven by more than valence alone. Further, the effects are consistent with the hypothesized role of arousal and uncertainty. Anxiety (high arousal and uncertainty) held attention, anger (high arousal but certain) held attention to a lesser degree, and sadness (low arousal) reduced sustained attention.
Discussion
Natural language processing of over 600,000 reading events from over 35,000 pieces of content is consistent with our theorizing. First, results suggest that processing ease helps sustain attention. Content that was more readable, was more syntactically simple, and used familiar or concrete language held readers attention.
Second, emotional language plays an important role, but the effects are more nuanced than just emotionality or valence alone. Instead they are consistent with our suggestions regarding arousal and uncertainty. Whereas content that used anxious or angry language held attention, sad language had the opposite effect.
To illustrate the impact of linguistic features, Figure 1 shows the effect of a one-standard-deviation increase in each linguistic feature on the likelihood that readers complete the whole article. Consumers are approximately 25% more likely to finish articles that use shorter words and sentences (i.e., has higher readability) and around 14% more likely to finish articles that use more anxious language.

What Sustains Attention.
By comparing the effects of each textual feature with the average topic effect (dotted lines), Table 1 also illustrates the relative impact of topic versus writing style. Results suggest that language has a similar, and in several cases even larger, effect on holding attention than the average topic. This suggests that while topic (e.g., sports, science) certainly shapes attention, how that topic is discussed (i.e., the language used) also plays an important role.
We focused on anger, anxiety, and sadness because there are reliable tools to extract these emotions, but exploratory analyses on surprise and disgust underscore the hypothesized role of uncertainty and arousal (see the Web Appendix). Surprise, which is low certainty and high arousal, sustains attention, while disgust, which is associated with certainty, has the opposite effect.
Further analyses are also consistent with the suggested role of uncertainty and arousal. We measured uncertainty using LIWC's certainty (e.g., “always,” “never”) and tentative (e.g., “maybe,” “perhaps”) language measures, and we measured arousal using ratings from Warriner, Kuperman, and Brysbaert (2013). Results are consistent with the notion that uncertainty and arousal sustain attention. Less certain (β = −.001, p = .07) or more tentative (β = .006, p < .001) language sustained attention, as did language associated with arousal (β = .084, p < .001).
Including controls and robustness checks helps rule out alternative explanations, but selection bias might still be a concern. Consequently, to further test our theorizing and more directly test language's causal impact, we turn to experiments. This also enables us to better test the hypothesized process underlying the effects. Given the difficulty of orthogonally manipulating all features studied, and the fact that different emotions have different effects, the experiments focus on emotional language.
Study 2: Experimentally Manipulating Emotion
Study 2 has two main goals. First, while the results of Study 1 are consistent with the notion that emotional language impacts attention, one could wonder whether the effects are truly causal. To provide more direct evidence, we use an experiment. We take an article portion; manipulate whether it uses sad, anxious, or angry language; and measure the impact on whether people choose to continue reading. Consistent with the field data, we predict that different specific emotions will have different effects: compared with when an article uses sad language, anxious or angry language will hold attention.
Second, Study 2 more directly tests the underlying process behind these effects. Using mediational analyses, we examine whether specific emotions hold attention because they evoke uncertainty and arousal.
Method
Participants (N = 278, recruited through Amazon Mechanical Turk) completed an experiment as part of a larger group of studies. They were told that experimenters were interested in perceptions of content and that they would read the beginning of a news article and respond to some questions.
First, we manipulated the language associated with specific emotions. All participants received a similar article about the stock market, but we manipulated whether part of the article used sad, anxious, or angry language. The [sad/anxious/angry] version said: Recent stock market performance has made investors really [sad/anxious/angry]. Most markets are down over 25%, the average American has lost tens of thousands of dollars, and many have [helplessly/nervously/furiously] watched as their retirement savings have dwindled. “I’m [heartbroken/worried/frustrated], said one New Jersey man, “my family is really [devastated/confused/bitter].”
The article portion was the same length and structure across conditions, and the only difference was the specific emotion words used. These words in particular were chosen based on their membership in specific emotion dictionaries (i.e., “helpless,” “heartbroken,” and “devastated” are all part of the sadness dictionary). A manipulation check (Web Appendix) shows that the manipulation worked as intended, reliably activating the intended emotions and not others. A second pretest further demonstrated that there was no difference between conditions on a variety of other measures (i.e., personal relevance, concreteness, extremity, or evoking hope).
After reading the article portion, participants completed the dependent variable: choosing whether they wanted to continue reading the rest of the article or switch to something else.
Finally, we measured the hypothesized underlying processes: uncertainty and arousal. Uncertainty was measured using three items adapted from Faraji-Rad and Pham (2017): “How does this article make you feel?” (seven-point scale anchored by “unsure/sure,” “hesitant/determined,” and “don’t feel confident/feel confident”; α = .93, reverse-scored and averaged to an uncertainty index). Arousal was measured using three items adapted from Berger (2011): “How does this article make you feel?” (seven-point scale anchored by very “low energy/very high energy,” “very passive/very active,” and “very mellow/very fired up”; α = .92, averaged to arousal index).
Results
Sustaining attention
As predicted, compared with using sad language (M = 52%), anxious (80%) or angry (71%) language led people to choose to continue reading the article (anxiety: χ2(1) = 18.99, p < .001; anger: χ2(1) = 7.66, p = .006).
Underlying processes
As predicted, a one-way analysis of variance (ANOVA) found that emotional language influenced uncertainty (F(2, 336) = 4.73, p = .009). Using anxious rather than angry language boosted feelings of uncertainty (M = 4.50 vs. M = 3.80; t(336) = 3.01, p = .003), as we expected. As noted previously, sad language can introduce either certainty or uncertainty, so we did not have a specific prediction. That said, in this particular context, sad language reduced uncertainty compared with anxious language (M = 4.12; t(336) = 2.05, p = .041) but directionally increased uncertainty compared with angry language (t(336) = 1.10, p = .27)
Emotional language also affected arousal (F(2, 336) = 7.62, p = .001). As expected, compared with using sad language (M = 3.88), using anxious (M = 4.34; t(336) = 2.23, p = .026) or angry (M = 4.71; t(336) = 3.87, p < .001) language boosted arousal.
Mediation
More importantly, a series of bias-corrected simultaneous mediation models (Hayes 2017) found that, as predicted, the combination of uncertainty and arousal drove the effects of specific emotions on holding attention. Compared with using sad language, anxious language sustains attention because it boosts both uncertainty (ab = .15, 95% CI: [.01, .38]) and arousal (ab = .23, 95% CI: [.04, .54]). Similarly, using angry rather than sad language sustains attention because it boosts arousal (ab = .44, 95% CI: [.20, .82]; uncertainty's indirect effect did not reach significance; ab = −.06, 95% CI: [−.26, .03]). Finally, also consistent with our theorizing, the difference between anxious and angry language was driven by uncertainty (ab = .18, 95% CI: [.009, .51]; arousal's indirect effect did not reach significance; ab = −.24, 95% CI: [−.58, .04]).
Discussion
The results of Study 2 bolster the findings of the field data in a controlled setting and provide evidence for the hypothesized underlying process. First, manipulating emotional language influenced whether content held attention and the effect depended on the specific emotion considered. Consistent with Study 1, compared with sad language, angry or anxious language made people to want to read more. The fact that these effects held even when we manipulated just a few words in the same article underscores the causal impact of specific emotion.
Second, as predicted, these effects were driven by how much uncertainty and arousal different specific emotions evoked. Using angry or anxious (rather than sad) language evoked arousal, and using anxious (rather than angry) language evoked uncertainty. Both uncertainty and arousal sustained attention, and, in combination, drove specific emotions' effects.
Study 3: Positive Emotions
Studies 1 and 2 focused on negative emotions because there are reliable tools for measuring such features in language, but to explore whether positive emotions show similar effects, and whether they are driven by the same underlying processes, Study 3 manipulates positive emotions. While contentment is a relatively low-arousal positive emotion, excitement—and, to some degree, hope—are relatively high arousal (Berger and Milkman 2012; Cavanaugh, Bettman, and Luce 2015; Kim, Park, and Schwarz 2010; MacInnis and De Mello 2005). Similarly, while contentment is a relatively certain positive emotion, hope is characterized by more uncertainty (i.e., people are hopeful but not sure that something with happen) and excitement may be as well (Cavanaugh, Bettman, and Luce 2015; Kim, Park, and Schwarz 2010; MacInnis and De Mello 2005). Consequently, we predict that compared with contentment, both excitement and hope should sustain attention more because they increase excitement and arousal.
Further, to provide additional control and rule out alternative explanations, in Study 3 we manipulate emotions outside the content itself (i.e., through a seemingly unrelated task; for similar approaches, see Berger [2011] and Cavanaugh, Bettman, and Luce [2015]). By keeping the focal reading content identical across conditions and manipulating emotion incidentally, we ensure that any observed difference between conditions is driven by emotion rather than some other factor. Participants wrote about a time they felt content, excited, or hopeful, and then, as part of an ostensibly unrelated experiment, read part of a neutral article and reported their interest in continuing to read more. If specific emotions sustain attention, as we suggest, then the emotion induced in the first task should spill over into the second. Even though everyone read the same article, the incidental emotion manipulation should impact reading, with the effects driven by how these discrete emotions impact uncertainty and arousal.
Method
Two hundred forty-eight Prolific participants completed two ostensibly unrelated studies and were randomly assigned to one of three between-subject conditions (content vs. excited vs. hopeful). The study was preregistered at https://aspredicted.org/p6gt8.pdf. See Web Appendix for exclusion criteria.
First, we manipulated specific emotions. Adapting manipulations used in prior work (Griskevicius, Shiota, and Neufeld 2010), participants described something that made them feel the focal emotion. In the excited condition, for example, participants were asked to recall a time when they felt excited, take a minute to remember it vividly, and then write a paragraph about it in as much detail as they could. The prompt was similar in the content and hopeful conditions, with the substitution of “content” and “hopeful” as the emotions participants felt. Manipulation checks indicate that the manipulations worked as intended.
Second, we measured the hypothesized processes using the uncertainty and arousal measures from Study 2
Third, we measured the dependent variable. After completing the first part of the study, participants moved on to the ostensibly unrelated second part. This involved reading content from a news article (about wireless charging, adapted from the New York Times) and answering some follow-up questions. After reading the first paragraph, participants were asked how likely they would be to read more of the article (1 = “not at all,” and 7 = “very much”) if they came across it while browsing online.
Results
Specific emotions
As predicted, a one-way ANOVA found that emotions sustained attention (F(2, 246) = 4.84, p = .009). Consistent with our theorizing, compared with contentment (M = 3.57), both excitement (M = 4.44; t(246) = 3.03, p = .003) and hope (M = 4.15; t(246) = 2.088, p = .038) held attention.
Underlying processes
A one-way ANOVA found similar effects on uncertainty (F(2, 246) = 7.05, p = .001) and arousal (F(2, 246) = 6.97, p = .001). Compared with contentment (M = 2.31), both excitement (M = 3.04; t(246) = 3.64, p < .001) and hope (M = 2.80; t(246) = 2.54, p = .012) made people feel more uncertain. Similarly, compared with contentment (M = 4.34), both excitement (M = 5.04; t(246) = 3.41, p = .001) and hope (M = 4.93; t(246) = 2.94, p = .004) made people feel greater arousal.
Mediation
Finally, bias-corrected simultaneous mediation models (Hayes 2017) found that uncertainty and arousal drove the effects on discrete emotions on attention. First, compared with contentment, excitement sustains attention because it boosts both uncertainty (ab = .20, 95% CI: [.04, .45]) and arousal (ab = .27, 95% CI: [.10, .54]). Similarly, compared with contentment, hope sustains attention because it boosts both uncertainty (ab = .17, 95% CI: [.03, .41]) and arousal (ab = .20, 95% CI: [.05, .45]).
Discussion
Study 3 underscores the findings of the first two studies. First, the results demonstrate that the effects of Studies 1 and 2 extended to positive emotions. Compared with contentment, excitement and hope sustain attention. Second, consistent with our theorizing, these effects were driven by arousal and uncertainty. Third, manipulating emotion incidentally casts doubt on the possibility that something else, beyond discrete emotions, is driving the effect. Fourth, by studying positive emotions, we decouple the effects of a specific emotion (e.g., anxiety) from the effects of arousing emotions more generally. The fact that we find similar effects for both positive and negative emotions suggests that the effects are not about any individual emotion per se but rather the larger dimensions that different discrete emotions are associated with.
Implications for Algorithmic Design
Taken together, the results of the field data and experiments have implications for the algorithms digital platforms use to recommend content. Many publishers and social media platforms employ algorithms to select what content to present, as suggested stories or part of a user's feed. Traditionally, these algorithms have relied on manual categorization of stories into broad categories or have identified and promoted topics that match user preferences. More recently, however, algorithms identify and promote content that increases interaction and attention. In addition to considering likes and shares, for example, some platforms rank content according to “time spent” when determining what content to include in a user's feed (Newberry 2022).
Our findings demonstrate that content features beyond just topic help sustain attention. In particular, they suggest that algorithms trained to sustain attention could privilege types of content (e.g., anxiety-producing) that could have consequences for individual users and the overall tone of content in the community.
To demonstrate how our findings interact with algorithm design, we simulated 10,000 users whose attention is determined by a baseline tendency, topic preference, and response to anxiety-producing content (we chose such content because it had the largest effect in the field data, but this could be replaced with any content feature or multiple content features). In this stylized simulation, we specify user i's probability of engaging with a specific piece of content, j, as follows:
We start with a simulated environment where each of these three parameters are normally distributed across users with mean 0 and standard deviation of 1. For simplicity, we assume TOPIC is 1 or 0, representing the presence or absence of a topic, and likewise for ANXIETY. These simple and stylized assumptions help establish a baseline behavior where consumer preferences for topic and emotional content are normally distributed across the population. Our simulation considers the presence or absence of a single topic or content feature (in this case, anxiety), but it can be generalized to accommodate multiple topics or different emotions. User i's engagement with a piece of content is 0 or 1 according to a Bernoulli draw of pij.
The content recommendation algorithm suggests new content to each user based on their prior behavior. We consider two types of algorithms, one that is trained to serve content that matches the user's topical interests and one that is trained to maximize sustained attention, driven by both content topic and emotionality. In both cases, the simulation begins with randomly selected content (i.e., both TOPIC and ANXIETY are randomly chosen) being served. Depending on whether the served content sustains attention, subsequent recommendations evolve, varying by the algorithm being used and the user's engagement decision from the previous round. For the topic-focused algorithm, content that matches the topic served previously would be served again if the user attends to it; otherwise, the other topic would be served. For the algorithm that also considers emotionality, both the topic and emotionality would be matched if the user attended to it in the last round.
Not surprisingly, results (see Table 3) indicate that incorporating linguistic features improved engagement. After ten rounds of recommendations, the topic-only algorithm achieved engagement among 52% of users (compared with 50% in the initial round when the content was randomly chosen). When the algorithm also considered whether the content evokes anxiety, engagement increased to 54%. This suggests that if users are driven by both topic preferences and emotions, as our findings suggest, then algorithms designed to consider more than just topical interests will increase engagement.
Simulation Results.

That said, given that our empirical findings show that some emotional content (e.g., anxiety-inducing) sustains attention more than others, we also simulate an environment where b2i is distributed N(1,1) to mirror that tendency. In other words, we create a simulated world where consumers are drawn to anxiety-inducing content, as we observe in our empirical analyses. In this scenario, engagement increases to 64% after ten rounds, but the recommended content has a mean anxiety score of .63. This suggests that the content being served becomes notably more anxiety-inducing after rounds of algorithmic recommendations (whereas there was no difference in the previous scenarios).
While highly stylized, the simulation has implications for content recommendation algorithms. If engagement is influenced by specific emotions (e.g., anxiety), as our findings show, then algorithms trained to increase engagement based on content features will systematically serve content that caters to those preferences, with according impacts on overall content tone. Consequently, firms that design and employ algorithms that serve content designed to increase engagement should be aware that such algorithms, unless monitored, have the potential to increase negativity in their community.
General Discussion
From advertisers and marketers to salespeople and leaders, everyone wants to hold attention. They want to make ads, pitches, presentations, and content that captivate audiences and keep them engaged. But some content does a better job of holding attention. Why?
A multimethod investigation demonstrates the important role of language. Content that was easier to process (i.e., more readable, syntactically simple, and used familiar or concrete language) or used more emotional language helped sustain attention. But rather than any emotion sustaining attention, or positive emotions having different effects than negative ones, the results demonstrate that the effect of emotional language is driven by uncertainty and arousal. Anxious, exciting, or hopeful language sustains attention, for example, because it evokes uncertainty and arousal.
Contributions
These findings make several contributions. First, on a theoretical level, they shed light on what holds attention. Decades of studies have examined different aspects of reading and attention. However, while this work has provided important insights into comprehension, memory, and other topics, there has been less focus on what sustains attention. This article demonstrates that linguistic features associated with processing ease (e.g., familiar language, concrete language) and emotional language (particularly emotions that evoke uncertainty and arousal) hold attention and keep audiences engaged.
Second, on a practical level, the findings have clear takeaways for increasing engagement. Subtle shifts in language can help sustain attention. Replacing abstract words with more concrete ones (e.g., replacing “product” with “phone,” describing a car in terms of its color), for example, or less familiar words with more familiar synonyms, should keep audiences engaged. Using the right emotional language should have similar effects. Rather than just relying on facts, for example, a nonprofit focused on climate change might benefit from leveraging emotions that evoke uncertainty and arousal. Using exciting or hopeful language should help sustain attention.
That said, sustaining attention should be balanced against other outcomes. Increasing anxiety in advertising might sustain attention but hurt brand equity. As our simulation suggests, there are also important societal implications. Platforms can use measures of sustained attention to recommend future content, but this may lead readers to be served an endless stream of anxiety-producing information. Addressing this issue, though, is not straightforward. By understanding what sustains attention, hopefully content creators can level the playing field and design useful information to hold attention.
Third, results demonstrate that content consumption depends on more than just the topic alone. People often lament that it is easier to get audiences to attend to “frivolous” topics (e.g., celebrity gossip) than “weightier” ones (e.g., policy discussions, environmental appeals). But while topic certainly plays a role in holding attention, our results demonstrate that it is not the only factor. Even controlling for what content is about (i.e., its topics), how that topic was discussed (i.e., the language used) played an important role. This is good news for communicators trying to sustain attention for less engaging topics. While the topic itself may not be the most enthralling, writing about it in the right ways can hold readers’ attention. Writing style can compensate for topic.
Future Research
As with any preliminary effort, more remains to be done. Research might examine other textual features. How does the similarity between an article and its outlet shape reading? For a sports outlet, for example, are people more likely to deeply read a typical article (e.g., about the results of a game) or one that is more atypical (e.g., about player's personal lives)? Similarity could also be examined within content. Content can be broken down into chunks (i.e., sentences or paragraphs). How might the similarity between those chunks impact sustained attention? Content that flows between similar chunks should be easier to process and follow, which might deepen sustained attention. Alternatively, chunks that are too similar might feel repetitive or like the plot is not advancing fast enough (for related work, see Laurino Dos Santos and Berger [2022] and Toubia, Berger, and Eliashberg [2021]).
Future work could also examine where readers come from. Compared with readers who come to an article through the outlet's homepage, for example, those who click on an article through social media may not read as much. Similarly, does reading one article impact reading behavior on a subsequent article? If people leave one article because it is not engaging enough, might that increase their impatience and decrease their likelihood of sustained attention in a subsequent article? One could also examine individual differences in readers’ emotional state, or factors that affect the mood of the general populace. Similarly, one could examine whether user preferences change throughout the course of reading an article (e.g., emotion has a larger impact earlier in a piece) or whether there might be complex interactions within content over time (e.g., whether positive content followed by negative content might have differing effects then the opposite order).
It would also be interesting to consider how sustaining attention influences return visits and subscriptions. One would imagine that the more attention articles get, the more likely readers will be to return to that content provider, generating more advertising revenue and possibly increasing subscriptions. If most articles hold attention for only a couple paragraphs, they’re less likely to keep people coming back. This highlights the downsides of overly attention-grabbing headlines. Clickbait may be great for attracting views, but to maintain long-term value (e.g., Du et al. 2021), it may be necessary to sustain readers’ attention. Further research into content's ability to sustain attention may also shed light on the effectiveness of embedded advertising (e.g., Fossen and Schweidel 2019; Schweidel and Moe 2016).
Future work might also examine the boundaries of our findings. What sustains attention on a very technical website, for example, might be different from what sustains attention for news or social media content. Similarly, although we found that uncertainty sustains attention, in situations where it casts doubt on whether continuing to read will lead the reader to find the information they are looking for, it may have the opposite effect.
Finally, although there are many cases where most consumers might respond the same way, future work might explore whether, when, and why different consumers might respond differently to the same content. A news article might report on a Republican election victory with a positive tone, for example, but whereas Republicans might react positively, Democrats might react negatively. Similarly, while most investors would be sad or anxious about a tanking stock market, short sellers might react more positively. Future work could examine which types of content are more likely to have heterogeneous effects and why.
Conclusion
In conclusion, holding attention has important implications for consumers, organizations, and society. It shapes what issues get attention and what products and services consumers learn about and purchase. By better understanding what sustains attention, hopefully we can improve outcomes for all these audiences.
Supplemental Material
sj-pdf-1-jmx-10.1177_00222429231152880 - Supplemental material for What Holds Attention? Linguistic Drivers of Engagement
Supplemental material, sj-pdf-1-jmx-10.1177_00222429231152880 for What Holds Attention? Linguistic Drivers of Engagement by Jonah Berger, Wendy W. Moe and David A. Schweidel in Journal of Marketing
Footnotes
Acknowledgments
The authors that Yuhao Fan, Nir Grinberg, Mor Naaman, Katherine Du, Reihane Boghrati, and Russel Richie for assistance with various aspects of the project; Jordan Etkin and attendees at the Marketing Science and Association for Consumer Research Conference for helpful feedback on the research; and the company for providing the data.
Associate Editor
Caleb Warren
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.