
Abstract
Objective
To examine the epidemiologic theory of screening as it applies to low prevalence disorders, such as schizophrenia, in order to identify the tasks required for primary and secondary prevention.
Method
Review of principles of screening, computation of prevented fraction for varying sensitivities, specificities and prevalences of disease, and review of prevalence of schizophrenia in Australian general practice.
Results
There is no currently available efficient method of screening for schizophrenia or for prodromal symptoms. From the genesis of disease to eventual outcome, the milestones that are passed in the case of schizophrenia are uncertain in their nature and the intervening time periods are of uncertain and possibly varying duration. The extent of false positives and negatives in low prevalence disorders is high unless the specificity is very high.
Conclusion
It may be feasible to screen for behaviours that are precursors to schizophrenia; however, screening depends upon the existence of a reliable screening instrument that can be shown to discriminate accurately between diseased and disease-free individuals. Development of a method for screening requires comparison against formal clinical assessment of both screen positives and screen negatives. For low prevalence disorders the predictive values may be low unless specificity is high.
Notions of screening have been most developed from the field of cancer research, where screening has been in place for many years. The theoretical basis of screening and early intervention have been described by Morrison [1] and can be demonstrated schematically. Figure 1 shows a general model of the biological process that leads to disease and indicates the critical points in the timeline from disease onset to outcome. In the preclinical phase, for disorders that have a biological substrate, there is a point at which the biological or pathophysiological process begins. For some disorders, such as Down syndrome or spina bifida, the point of biological onset may be embryonic or gestational. For other disorders, such as mesothelioma, the onset follows exposure to an external agent that can occur at any time. However, in the early stages, external evidence of the pathological process may not be immediately available following disease onset, even to sophisticated biological testing, and the disorder remains silent.
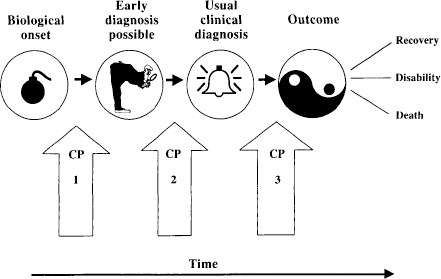
Theoretical timeline for biological processes leading to diagnosis and outcome
There comes a point, however, when sufficient progression has occurred for symptoms to become evident to the individual or for signs to be observable when investigations are mounted. For example, small breast lesions may be detected using mammography that are not evident on a visual or tactile breast examination, or an enlarged prostate may be discernible using endoscopy in the absence of symptoms. This is the point where early diagnosis becomes possible, and early intervention can be mounted. Thus, efforts are put into programs for early detection for disorders in which early detection can lead to earlier diagnosis, earlier treatment and a more favourable outcome.
The next point occurs when the disease is sufficiently progressed for symptoms to become evident and to result in help-seeking, where clinical investigation can lead to diagnosis. This point can provide the opportunity for intervention or treatment, and identifies the usual clinical pathway for most diseases. The vast majority of clinical treatment outcome studies commences at this point, in an effort to reduce the occurrence of unfavourable outcomes and postpone the inevitable (given that treatment may not save life but merely prolong it).
Between these milestones (biological onset, possible early diagnosis, usual clinical diagnosis and outcome) appear a series of critical points or intervals that define the various stages of prevention efforts. Primary prevention efforts are mounted to avoid, avert or postpone biological onset. For example, folate in diet during pregnancy may prevent the biological onset of neural tube defects; having never worked with asbestos may prevent asbestosis; and having never smoked may help to prevent carcinoma of the lung. However, for those disorders with genetic origins, primary prevention flows only from contraception. Given that biological onset may not always be avoidable, the next critical point appears between the point of biological onset and the point where there is sufficient progression for the disease to be detectable on examination. The time interval between onset and possible detection may vary greatly in different conditions and in different individuals. Thus, the very long lead time between the onset of atherosclerosis and the onset of heart disease, for example, poses different opportunities from those provided by other diseases with briefer lead times.
However, early detection may not always be possible. Some diseases are ‘silent’ before a critical manifestation leads to help-seeking and the point of usual clinical diagnosis. Where help-seeking is delayed until debilitation occurs, the time for early diagnosis and treatment has passed. At this point attention turns to secondary prevention via treatment, to prevent the progression of disease or to aid in recovery. This has usually defined the task of clinicians: to recognise and treat before the disease process overwhelms the individual and the consequences become inevitable.
Screening for schizophrenia
Two major issues arise from this theoretical scenario; these concern the existence and appearance of these milestones and the duration of the intervening intervals. For example, in the case of schizophrenia, the milestones themselves are subject to debate, such as appears later in this monograph. There is evidence of the importance of genetic inheritance, indicating that the biological process underlying the disorder may begin from or even before conception. Other research points to the importance of gestational factors, of developmental factors, and of exposure factors such as psychotropic drugs. Thus, there is little agreement on the point of biological onset. The point at which early diagnosis is possible is also uncertain. While schizophrenia has a peak incidence in mid-second to mid-third decade [2,3], it also has a distribution of apparent first episode onsets occurring throughout the lifespan; there is no age at which incidence is zero [2]. If it is discernible in a prodromal phase, this may define the point at which early diagnosis is possible, but the distribution of this point in populations with schizophrenia remains undetermined [4].
A further problem is that the diagnosis remains syndromal, so that diagnosis is applicable only when multiple symptom thresholds have been reached. For example, the onset of feelings of being down or depressed may precede other symptoms of depression, such as sleeplessness, appetite loss or agitation, but the diagnosis of depression can be made only when a cluster of symptoms is present together rather than when a single symptom has expression. This immediately begs the question: at what point do all the symptoms ‘come together’ to enable accurate clinical diagnosis? One common strategy that is employed is to adopt a checklist of attendant symptoms so that, as symptoms are recruited, a cut-off point can be introduced, above which the disorder is judged to be present and below which it is judged to be absent. Psychometrics then takes over to determine the best place to insert this cut-off point, guided by a sensitivity analysis. However, this is not completely satisfactory and introduces its own uncertainty. For example, the term ‘hypertension’ is applied when diastolic blood pressure lies above 90 mmHg (depending upon age and other factors), as this identifies a large proportion of individuals who subsequently fall victim to stroke. However, the choice of a cut-off point is essentially arbitrary. This will also be so for schizophrenia screening based on prodromal symptoms.
A further complication is that, while the possibility exists that schizophrenia may not be a unitary disorder with a single underlying pathological process, the literature also entertains a possible dimensional, as opposed to a binary, view of disorder, which is in common with much thought-pervading theorising in human behaviour. Finally, the apparent luxury of histological or post-mortem confirmation of diagnostic judgement is currently unavailable in schizophrenia, as in much of psychiatry itself. The diagnostic certainty that is available in heart disease or cancer is absent. Thus, the existence and recognition of these milestones remain subject to doubt and debate.
The temporal sequence is also much in doubt. The time between biological onset and the onset of the disorder is unknown. By the time the disorder arrives at the point of usual clinical diagnosis, it is recognised that there has been a time period in which the afflicted have already suffered, this time period being referred to as the duration of untreated psychosis and determined and measured mostly retrospectively. This is shared with many psychiatric disorders, where the onset of individual problems frequently precedes the onset of diagnosis. For an example in anxiety and depression see Eaton et al. [5]. The temporal relation between the onset of the prodrome and the onset of the full disorder is subject to much debate. Finally, the time between diagnosis and outcome is quite variable. Many people, particularly those with late onset schizophrenia, have a single episode. Many more, however, continue to experience lifelong debilitating illness, often with mortal consequences. It is the relative size of this population that impels action toward early intervention and therefore screening, but the opportunities for detection and treatment, particularly for early detection and preventive treatments, are not readily identifiable.
However, all of this discussion is predicated on the existence of a tried and tested screener, which has been evaluated by trials of screening constituted with (ideally identical) screened and unscreened populations followed for sufficient time as to establish the outcome of screening and early intervention [1]. If, for example, the screen test cannot be shown to perform with the appropriate sensitivity and specificity (by comparing the predicted screen case status with rigorous clinical diagnosis), then it is futile to contemplate its use in an experimental intervention aimed at prevention. Finally, all of this rests on the existence of a successful treatment that can be shown independently to be effective in treating the disease or halting its progression, as surgery has been shown in breast cancer. Without an effective treatment, screening is useless.
The current tasks in schizophrenia screening are, therefore, two-fold. First, to establish a screening instrument that has high sensitivity, specificity and predictive value when compared with comprehensive clinical diagnosis. This can only be accomplished by developing a screener that can be shown to discriminate highly between those with schizophrenia and those without. Thus, a screener must be evaluated initially in populations whose diagnostic status is known, or full diagnostic assessments must be made of random samples of screen positives and screen negatives to compare the ability of the screener to accord with or mark those who can be shown independently to be diagnostically positive. Study designs are available to accomplish this task [6]. The second task is to establish the efficacy of screening in a high-risk group using appropriate randomised controlled trial methods. The evaluation of mammography screening always entails comparison of outcome in similar screened and unscreened samples that are randomly allocated, with screening and treatment declared successful if survival time is increased in the screened sample compared with the unscreened sample. Successful screening in schizophrenia must be shown to meet similar standards.
Constraints and challenges
There are three well-recognised sources of error in all studies of humans. Studies may fall victim to errors (i) in the subjects who are enrolled in the studies (selection, sampling and response errors); (ii) in measurement of their characteristics (inadequate, unreliable or invalid measures); (iii) of confounding (where another factor accounts for the observed relationship between two factors). These are universally occurring errors that plague all studies of humans (for a discussion of these in prevention in psychiatry see O'Toole [7]). Testing a screener requires methods to compare its performance in appropriately constructed random samples of populations of known diagnostic status. Thus, subjects must be selected from groups known to have schizophrenia, such as will be found in mental health facilities, and groups known not to have schizophrenia, such as may be found in general population samples. In Australia, it has been shown that general medical practice can be used as a recruiting ground for representative samples of the general population [8,9]. If the screener is to be used in people who exhibit prodromal features without necessarily having been diagnosed with schizophrenia, then samples of individuals who may be at increased risk can be used, such as those with first-degree relatives (parents, children and siblings, especially monozygotic twins) who already have the diagnosis.
To assess the ability of the screener to differentiate among disease groups, during screener development all screen positives must be assessed with appropriate diagnostic procedures to ensure that the screener can identify those with the disorder. Thus, following mammography, all test positives must be confirmed using histological techniques. The extent to which any screener can be evaluated is highly dependent upon the accuracy of consequent diagnosis; if diagnosis itself is not accurate then it is difficult to properly evaluate the screener. Integral to this evaluation also is the application of these diagnostic techniques to samples of those who screen negatively. Thus, from the population of screened individuals, screen negatives as well as screen positives need to be assessed using accurate diagnostic techniques. If the prevalence of screen negatives is high then random samples can suffice for this. While diagnostic assessment of entire samples is unnecessary, to evaluate the measurement error that arises with the use of a screener, the ex-tent of false negatives and false positives must be assessed.
Once a screener has been developed, a strong measurement error may be introduced in the test of screening efficacy if the period of surveillance is artificially truncated, such as would occur in circumstances of time-limited funding such as is introduced by short-term (e.g. 3 years) research grants, or limited tenure of investigators. Depending upon the duration of the critical periods between the milestones, and particularly between diagnosis and eventual outcome, evaluation of the success of any screening and consequent intervention is highly dependent on the ability to observe through time. Thus, one may have to wait decades to evaluate interventions that are mounted in childhood or during gestation; even a modest intervention that aims to screen people in the highest-risk age for onset (mid-second to mid-third decade of life) is required to follow screened and unscreened cohorts for years. This is not itself an artefact of screening but a function of the requirement to measure outcome adequately and avoid what is statistically termed ‘right censoring’.
It has long been recognised [10] that, deterministically, evidence of hazard is easier to accumulate than evidence of safety, as a single adverse event is needed to refute proof of safety, yet observation must be intensive and prolonged to refute claims of harm. Thus, it is necessary to accumulate a continuing absence of episodes in order to argue for effectiveness. Stochastically the situation is more benign as demonstration of effectiveness is based on statistical techniques. A measurement bias occurs when sample size is inadequate to assess the degree to which an intervention is successful (or not). Inadequate sample sizes lead to type II errors; that is, the inability to detect a true difference as statistically significant. Thus, adequate samples sizes are required to provide the appropriate statistical evidence for screening efficacy. The weaker the effect of early intervention, the larger the sample size required.
Any evaluation of a screening program must be relative to the situation that would prevail if screening were not undertaken. Thus, evaluation of mammography screening always entails comparison of outcome in similar screened and unscreened populations, with screening and treatment declared successful if survival time is increased in the screened sample compared with the unscreened sample. However, even if treatment does not affect the course of disease, then screened populations may have a lead time between detection of abnormality and outcome that is not available to the unscreened population. This apparent increased survival time is illusory, and may merely entail living longer with a diagnosis. This is called ‘lead time bias’ [1]. In schizophrenia, even if early intervention does not change the course of the disorder, screening brings forward the point of diagnosis and may result in sufferers merely acquiring a longer period of time between diagnosis and outcome. A second temporal bias, length biased sampling, occurs when screening identifies cases with a long benign course (such as prostatic cancer), even if there is no lead time or reduction in adverse outcome from early intervention. This is because those diseases with long time courses will be more prevalent and thus more readily detectable. It is possible that screening in the highest-risk age interval may tend to identify individuals who have late onset, rather than short-term onset.
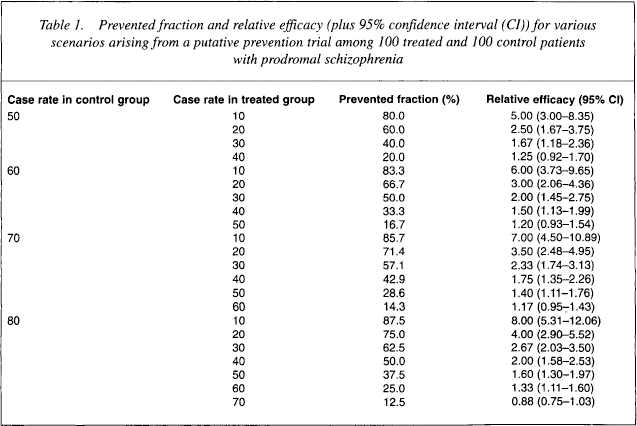
The concept of relative risk and aetiological fraction is used to assess causal mechanisms in disease processes. Similarly, the concept of inverse relative risk (relative protection) and prevented fraction has been invoked to assess the effectiveness of intervention programs [11]. A simple calculation can demonstrate the need for sufficient sample sizes. For example, in a sample of 200 patients in which 100 were treated and 100 were untreated (controls), if it could be expected that half the untreated group would go on to psychotic episodes while only 10 of the treated group did so, then the treatment could be said to have prevented 40 cases. In this instance, the prevented fraction would be 40/50 or 80%. The relative efficacy (the inverse of the relative risk) would be the ratio of the proportion of cases in the untreated group to the proportion of cases in the treated group (50/100 ÷ 10/100); that is, 5.0. Confidence intervals (CI) can be assigned to these estimates using standard methods [12].
Table 1 shows the situation where the number of controls who become cases varies from 50, through to 60, 70 and 80, while the number in the treated group varies from 10, through to 20, 30, 40, etc. Thus, when 50 in the control group become cases and 30 in the treated group become cases then the prevented fraction is 40% and the relative efficacy is 1.67. If only 10 cases are prevented in the treatment group, then the prevented fraction is 20% and relative efficacy drops to 1.25 which, with a CI of 0.92–1.70, is a non-significant efficacy. However, if the proportion of untreated who become cases rises to 80 in 100 then preventing 20 cases in the treated group entails a prevented fraction of 25% at a relative efficacy of 1.33 (with 95% CI of 1.11–1.60). Efficacious prevention of 20 cases in the treated group is easier to demonstrate the higher the incidence or prevalence is in the untreated group. This, of course, is one reason behind the strategy of enrolling various ‘high-risk’ groups into longitudinal cohorts. Moreover, the situation can be reversed, and the number of individuals who need to be treated can be calculated. If the treatment effect is weak, the number of people who need to be treated can be very large indeed.
Prevented fraction and relative efficacy (plus 95% confidence interval (CI)) for various scenarios arising from a putative prevention trial among 100 treated and 100 control patients with prodromal schizophrenia
The importance of screener accuracy
Two parameters that are important to screening are the sensitivity and specificity of the screen itself; that is, the ability of the test to discriminate true positives (sensitivity) and true negatives (specificity) against a true ‘gold’ standard (Table 2). It is almost axiomatic that no test has ever been developed with ideal sensitivity and specificity (i.e. 100% accuracy). All tests, diagnoses and judgements carry false positive and false negative properties; in this, psychiatry is no different from any other endeavour. Thus, some screen positives and screen negatives will be false. The parameters measuring these are the positive predictive and negative predictive values and are easily calculable from the 2 × 2 table that represents screening results against the ‘gold’ standard (Table 3). Suppose a screener has sensitivity and specificity of 99%, and that the prevalence of disorder in a random population sample of 200 is 50%. Then 99 of every 100 cases would be detected and 99 non-cases of every 100 would be identified, so that in the sample of 200 (100 cases and 100 non-cases) the positive predictive and negative predictive values would each be 99%.
Sensitivity, specificity, positive (+) and negative (–) predictive values calculated from a 2 × 2 table comparing test outcome (+ or –) with ‘true’ status (+ or –)

Sensitivity = a/(a + c) = Proportion of true positives that are detected by the test.
Specificity = d/(b + d) = Proportion of true negatives that are detected by the test.
Positive predictive value = a/(a + b) = Proportion of test positives that are true positives.
Negative predictive value = d/(c + d) = Proportion of test negatives that are true positives.
Positive and negative predictive values for samples of varying sensitivity, specificity and prevalence
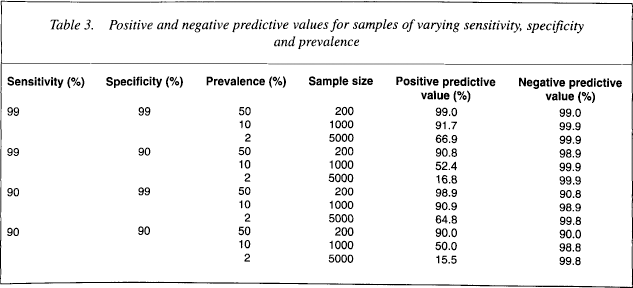
Suppose, however, that prevalence was 10%; hence, a sample of 1000 individuals would contain 100 cases and 900 non-cases. If sensitivity and specificity were still 99%, then 99 of the 100 cases would be detected and 891 of the 900 non-cases would be detected, giving a positive predictive value of 92% and a negative predictive value of 99.9%. Suppose prevalence is only 2%, so that a sample of 5000 would comprise 100 cases and 4900 non-cases. Still with sensitivity and specificity of 99%, the positive predictive value falls to 67% while the negative predictive value rises to 99.98%. Thus, one out of every three detected cases would be false positives, although the number of false negatives would be very low. Suppose now that specificity falls to 90%. At a prevalence of 50%, the positive predictive value falls to 91%; at a prevalence of 10% the positive predictive value falls to 52%; at a prevalence of 2% the positive predictive value falls to only 17%, which means that if 5000 people were screened for a disorder of only 2% prevalence then, even under conditions of high sensitivity and specificity, 490 of the 589 cases detected would be false. This is merely a property of the mathematics of screening, and shows the difficulty encountered with screening in low prevalence disorders, even with the use of highly sensitive and specific tests.
In fact, it has been long recognised that sensitivity and specificity themselves are dependent upon prevalence, even when nothing else changes [13]. Thus, a common strategy employed to reduce the chances of false positives in the face of low prevalence disorders and high sensitivity is to increase the observed prevalence within the screened group by utilising the ‘high-risk’ strategy that is commonly advocated [14], and by employing a test that has very high specificity. For example, in mammography it is recommended that screening not be undertaken for young women, because of the low prevalence of breast cancer in, say, women under 40. Moreover, mammography screening radiology is a powerful tool with high specificity, so that the chances of false negatives are low.
Sensitivity and specificity themselves can be manipulated when using symptom aggregation (e.g. in checklists of prodromal symptoms) by changing the cut-off point. But they can also be changed in circumstances where the costs of missing a ‘true’ positive or falsely indicating a negative are high. For example, in mammography, there is a cost to a woman who receives a positive result that later is shown to be false. There is also a cost to the health system that arises from an unnecessary diagnostic follow-up. However, there is also the cost of false negatives to be taken into account, as the consequences of missing breast cancer may be dire. In aviation, the cost of sending a plane up with a falsely clear mechanical report is judged very high, so that safety procedures and standards are high and some aeroplanes are grounded on what are shown later to be minor mechanical faults that might not have led to an aircraft falling from the sky. In this case, the goal is high specificity. In schizophrenia, it will be important to thoroughly evaluate the point at which a screener gives a positive ‘reading’, as this may entail pharmacological, behavioural and social interventions that are unnecessary. On the other hand, the cost of a false negative may also have dire consequences. There are no hard and fast rules here, and judgement will be required as to the point at which to declare a screen positive, given the balance of costs of false positives and false negatives.
The feasibility of screening in Australia
From this earlier discussion it can be seen that, even given very high sensitivity and specificity, low prevalence disorders require large samples in order to demonstrate screening efficacy and these samples need to include people who have a high risk of progressing to diagnosable disorder. Test characteristics aside, the question of the availability of such samples in Australia can be addressed by determining the number of individuals who are potentially available for screening, as well as the expected prevalence of schizophrenia that has been described in general population samples.
In 1990–1991, the Australian Morbidity and Therapeutic Study in general practice found that males aged 15–24 constituted 4.3% of all encounters and females constituted 6.7% [15]. During the fiscal year 1995/1996, the Australian Health Insurance Commission reported that males aged 15–24 had 4 310 252 encounters in general practice, at an average rate of 270 per GP per annum, or 4.1% of all encounters. Females aged 15–24 had 7 283 933 encounters, an average of 456 per GP per annum, constituting 6.9% of all encounters. Using the age–gender specific incidence reported in New South Wales [2, table 2], the incidence in males aged 15–24 would be 109 per 100 000 and in females 66 per 100 000 [2]. Thus, in order to yield 200 cases, it would be required to screen 114 285 individuals. Assuming approximately 100 encounters per GP per week, and assuming that males and females together constitute 11.0% of encounters, 10 390 GP-weeks would be needed, which translates to approximately 200 GPs screening for 52 weeks (or 400 for 26 weeks, and so on). This seems feasible in large metropolitan areas, where the number of GPs could be increased in order to decrease the screening load per GP or to decrease the length of time in which screening would be in operation. However, the geographical spread of a GP workforce this broad would clearly require a large logistic effort, involving multiple sites of operations, particularly if screen positives and samples of screen negatives are required to be assessed with thorough diagnostic techniques.
Given that there may be sufficient samples available to develop and test a screener for schizophrenia, there remains a set of well-recognised conditions that favour early diagnosis [16]. Does early diagnosis lead to improved clinical outcomes? Is clinical time and expertise available for confirmation of the diagnosis? Is clinical time and expertise available for long-term case management? Will patients comply with treatment? Has effectiveness of screening been demonstrated? Is screening accurate, acceptable and non-costly? The answers to these questions, aside from the statistical questions, ultimately determine the utility of screening. For example, in the case of breast cancer, it is argued that early diagnosis and surgical intervention can indeed lead to increased survival; confirmation of the diagnosis is readily and cheaply available; long-term case management is available through general and specialist practice; and that patients usually comply with treatment (surgery or chemotherapy). While the effectiveness of screening may remain debatable on methodological grounds [17], it is the case that mammography is accurate (very high sensitivity, specificity and predictive values), is generally widely acceptable and is relatively cheap. In the case of prostate cancer, however, early diagnosis and intervention carries a significant risk of impotence and urinary incontinence; the disease has a relatively long course (men may die with prostate cancer rather than of it) unlike breast cancer; effectiveness of screening has not been demonstrated; and the costs of screening are not greatly lower than the costs of intervention. Thus, mammography screening is acceptable, prostate screening is not. The answers to these questions will determine the acceptability of screening for schizophrenia in Australia.