
Abstract
A method is presented for estimating the distributions of the components and parameters determined with spectral analysis when it is applied to a single data set. The method uses bootstrap resampling to simulate the effect of noise on the computed spectrum and to correct for possible bias in the estimates. A number of bootstrap procedures are reviewed, and one is selected for application to the kinetic analysis of positron emission tomography dynamic studies. The technique is shown to require minimal assumptions about noise in the measurements, and its small sample properties are established through Monte-Carlo simulations. The advantages and limitations of spectral analysis with bootstrap resampling for deriving inferences for tracer kinetic modeling are illustrated through sample analyses of time-activity curves for [18F]fluorodeoxyglucose and [15O]-labeled water.
Keywords
Spectral analysis was introduced in 1993 as a tool for the mathematical modeling of data obtained with dynamic positron emission tomography (PET) procedures (Cunningham and Jones, 1993). The technique allows the description of the tissue time-activity curve of a tracer in terms of an optimal subset of kinetic components selected from a far larger set. The larger set samples the range of possible components that may be detectable in the data; it usually consists of convolution integrals of the input function with decaying exponentials so that the chosen components may be related to an appropriate compartmental model for the system under consideration. The compartmental model can then be used as the basis for interpretation of the kinetic data and estimation of the parameters of interest. Spectral analysis has been used in this framework in applications to PET studies of glucose metabolism, blood flow, and ligand binding in the brain with tissue data measured in regions of interest (ROI) or single pixels (Cunningham and Jones, 1993; Cunningham et al., 1993; Tadokoro et al., 1993; Turkheimer et al., 1994; Fujiwara et al., 1996; Richardson et al., 1996).
A problem that became apparent in early applications of the method was that noise in the data can exert an influence on component detection; it can result in detection of spurious components in the system as well as a shifting of components away from their true values. Procedures for combining adjacent peaks (Cunningham and Jones, 1993) and filters for high-frequency noise (Turkheimer et al., 1994) have been developed, but a more general approach to assess the uncertainty in all detected components is needed. When multiple measurements in the same region are available, the distribution of the detected components can be assessed simply by repeated application of the spectral analysis method to each set of measurements. We do not, however, currently have a method for assessing this distribution in the absence of repeated measurements. In this report we propose a bootstrap resampling procedure to assess the distributional properties of the components detected with spectral analysis, as well as any parameters derived from the detected components, when the method is applied to single data sets. Bootstrap resampling methods have been shown to have minimal statistical assumptions; their small-sample properties, when used with the spectral analysis method, are established through Monte-Carlo simulations. We also illustrate the advantages and limitations of spectral analysis with bootstrap resampling for deriving inferences for tracer kinetic modeling through sample analyses of time-activity curves for [18F]fluorodeoxyglucose and [15O]-labeled water.
Brief review of spectral analysis method
Most kinetic models used with PET tracers are based on the description of the system as a collection of well-mixed compartments with exchange of material among the compartments assumed to follow first-order kinetics. Tracer delivered to the tissue by the arterial blood exchanges with one or more compartments in the tissue, and exchange of material among the various tissue compartments can occur as well. The total concentration of tracer in the field of view of the PET camera can therefore be written as the convolution integral:
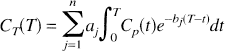
where Cp(t) denotes the arterial input function (t minutes after injection of tracer), T is the time at which the tissue activity is measured, CT(T) is the tissue activity at time T, n is the number of compartments in the tissue, and aj and bj are the parameters describing exchange of tracer among the compartments, the values of which are to be estimated. 1 The estimation problem, which is nonlinear in the parameters bj can be converted into a linear estimation problem by predefining a large number, N, of basis functions, fi(T) where
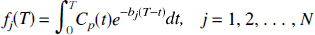
with a fixed set of values of bj and solving for the linear coefficients aj. The model, therefore, becomes
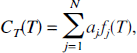
where the mathematical process now consists of estimating the N-vector
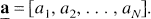
It is understood that coefficient aj is zero if the basis function fj(T) is not included in the model. Estimation of the coefficients aj from equation [3], however, requires non-negativity constraints on aj to avoid inclusion of pairs of nearly equal components with coefficients opposite in sign. For tracers that distribute into a compartment exchangeable with the plasma plus a trapped or reversibly-bound compartment, or that distribute into parallel sets of such compartments, the requirement that aj ≥ 0 is satisfied. This includes PET tracers used for measurement of cerebral blood flow, glucose metabolism, and many receptor ligands. For these and other compartmental systems that do not contain cycles, i.e., those systems in which it is not possible for material to pass from a given compartment through two or more other compartments back to the initial compartment, the exponents bj are real and non-negative (Hearon, 1963). The constants bj are chosen so that they span the range of possible exponents that may be detectable in the data given the time-sampling of the tissue data and the measurement noise level.
Because continuous time measurements of the tissue concentration of tracer are unavailable, the continuous time equation [3] is replaced by its discrete time counterpart. For tissue data sampled at times t1, t2, …, tM, the model equations are:
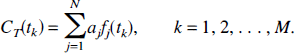
Furthermore, measured tissue concentrations include noise, or errors in the measurement. If X(tk) represents the measured tissue concentration at time tk, and ek is the error in the measurement, we have
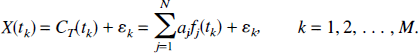
The errors are assumed to have zero mean.
Estimation of the vector
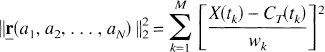
subject to aj ≥ 0, j = 1, 2, …, N, whereas the Simplex solution is obtained by minimization of
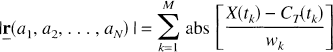
subject to the same non-negativity constraints. The symbols ‖
The result of minimization of [7a] or [7b] is an N-vector of estimated coefficients
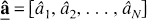
which usually contains only a few values different from zero. Results are often represented graphically by plotting the exponents bj on the x-axis and arranging the nonzero âj as “peaks” parallel to the y-axis; given its appearance this layout is called a “spectrum” in analogy to the spectra used in frequency analysis.
Bootstrapping in spectral analysis
A common approach for estimation of parameter uncertainties is to derive from the statistical properties of the errors in the measured data an analytical formula that describes the statistical properties of the estimated parameters. This parametric approach, however, requires a number of hypotheses concerning the distributional properties of the noise, usually that the errors at each time point be independent, normally distributed, and with a known variance. The conditions of normality and independence are not always met in PET studies (Pawlik and Thiel, 1996), and variance is known to vary between time-frames (Budinger et al., 1978).
An elegant solution to the problem of estimating parameter uncertainties in unknown noise conditions was introduced by Efron (1979), who observed that each data set is not only a sample from a population but can also be considered to be the only and best available approximation to the population itself. Therefore, we can compute numerically the variability of an estimate, not by repeatedly sampling from a theoretically well-defined population distribution, which is not available, but by resampling with replacement from the data. (For an overview of the extensive literature on bootstrap, see Efron and Tibshirani, 1993). Different ways of generating bootstrap observations are discussed below.
Bootstrapping residuals (Efron, 1979). The first, and simplest, method of generating bootstrap observations can be used if the errors on all the measurements are identically distributed with equal variance. Define the unweighted residuals as
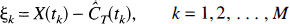
where
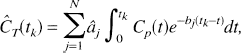
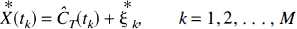
where
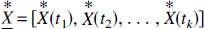
and the solution N-vector is recorded as
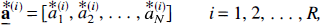
are obtained. The R bootstrap solution vectors form an (R × N) bootstrap distribution matrix
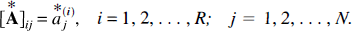
In addition, the N-vector
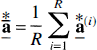
As stated above, this implementation of the bootstrap requires that the errors in the measurements be identically distributed with homogeneous variance. More complex resampling schemes are needed when variance of the error varies with time.
Bootstrapping pairs (
Efron, 1982
) The generation of the bootstrap data vector
Other resampling schemes If observations can be grouped so that measurements within each group have approximately equal variance, it is natural to resample the residuals within each group instead of resampling residuals from the entire set of observations (Hjorth, 1994). On the other hand, if one has available some estimates of the standard deviation of the residuals up to a proportionality constant, then the bootstrap residual resampling scheme can be modified as described below.
Let w1, w2, …, wM be the weights proportional to the standard deviations σ1, σ2, …, σM in the measurements at sampling times t1, t2, …, tM. The NNLS or the Simplex algorithm is used with the weights provided to find an estimate of the linear coefficients, i.e., a solution vector
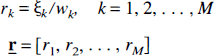
where the unweighted residual,
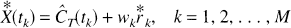
where
Note that the weight wk corresponding to the measurement at sample time tk is fixed; only the residuals are resampled. The bootstrap matrix
Application of the bootstrap procedure
Estimation of the vector of coefficients and confidence intervals Because of the non-negativity constraints imposed on the solution, the solution vector
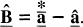
A new asymptotically unbiased estimator of the vector of coefficients can then be computed as
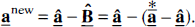
Since
Estimation of derived parameters and their distributions Components detected with spectral analysis can be combined to obtain parameters of physiologic interest. For example, Cunningham et al. (1993) used the detected components (âj, bj) to obtain an estimate of the impulse response function (IRF) of the tissue as:
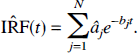
From equation [20] the parameters K1, the unidirectional clearance of tracer from blood to tissue, and Vd, the volume of distribution of the tracer in tissue relative to blood, were determined as:
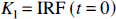
and
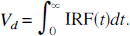
The remainder of this section illustrates how spectral analysis can be used, not only to estimate the derived parameter itself, but also to estimate the statistical properties of the parameter, such as its variance and confidence intervals.
Let
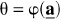
where φ is a function that describes the relationship between
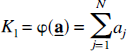
and when θ ≡ Vd
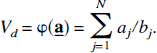
Let
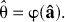
The bootstrap distribution of
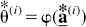
where
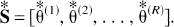
Then
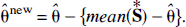
Finally, by ranking the set of bootstrap values from the smallest to the largest, percentiles of the distribution and confidence intervals of
MATERIAL AND METHODS
Algorithm implementation
Minimization of the 2-norm (defined in equation [7a]) was performed with the NNLS algorithm described by Lawson and Hanson (1974). For minimization of the 1-norm (defined in equation [7b]), the modified Simplex algorithm of Barrodale and Young (1966) was used. Programs were written in C language4 for the Sun Sparkstation 20 (Sun Microsystems, Mountain View, CA, U.S.A.). Range and distribution of the exponents bj of the basis functions were the same as those described by Turkheimer et al. (1994).
Simulation studies
To evaluate the small sample properties of the bootstrap method, simulation studies were performed as follows. Without loss of generality, the input function of the system, Cp(t), was assumed to be impulsive. With impulsive input, the convolution basis functions (equation [2]) are simple exponential functions, and the tissue concentration (equation [3]) is multiexponential. Noise conditions, time sampling, and the ratio between exponents of the functions were defined to represent a problem close to the practical limits for identification of separate exponential functions, as reported in the literature (Yeramian and Claviere, 1987). The biexponential test function was:
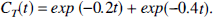
The data
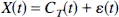
were sampled at 15 time points (t = 0,0.1,0.3,0.5, 0.7, 1, 1.5, 3, 5, 7.5, 10, 15, 20, 25, 35 minutes), and ε(tk) was randomly generated, independent and normally distributed at each time point, with 5% coefficient of variation. One hundred basis functions were given by

and the exponents bj were logarithmically distributed (Turkheimer et al., 1994) between 0.01 min−1 and 10 min−1. To simulate realistic conditions the standard deviations in the measurements were assumed to be unknown but to have a constant coefficient of variation. The data points themselves, X(tk), were used as the weights wk.
In each simulation 1,000 different data sets were generated. For each data set h, the NNLS algorithm was used to estimate the coefficients,
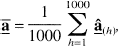
the mean of the mean bootstrap solution vectors,
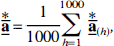
and the mean of the bias-corrected coefficients,
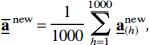
were computed.
For each simulated data set, the derived parameter
[18F]Fluorodeoxyglucose studies
The method was applied to the reexamination of [18F]fluorodeoxyglucose ([18F]FDG) PET scans of a normal male subject whose study was previously described (Lucignani et al., 1993). The data set consisted of 31 scans acquired according to the following schedule: 5 scans of 1 minute each, 5 scans of 2 minutes each, and 21 scans of 5 minutes each for a total scanning time of 120 minutes. The arterial plasma input function, Cp(t), was measured by collecting blood samples from the radial artery after a pulse of approximately 8 mCi of [18F]FDG was injected, rapidly centrifuging the samples, and assaying the plasma 18F concentrations. Anatomic ROIs were drawn on the images and the time course of total radioactivity in each ROI obtained. In addition, the time course of the whole-brain radioactivity was determined as the weighted average of the radioactivity in all image planes. All data were corrected for radioactive decay.
The basis functions consisted of 100 exponential functions convolved with the measured arterial plasma input function, Cp(t). The range of the exponents was from bj = 3 min−1 to bj = 0.0028 min−1. Two additional components were added, the integral of the input function (equivalent to a component with bj = 0) and the input function itself (equivalent to a component with bj = ∞), the latter to account for the blood pool in the tissue. The minimization procedure was weighted with estimates of the standard deviation in the tissue measurements, computed as described in Budinger et al. (1978). For each ROI, the bootstrap distribution of the coefficients, the 90th percentiles of the distribution, and the bias-corrected coefficients were estimated with 1,000 bootstraps.
In the [18F]FDG studies, the coefficient of the integral of the arterial plasma concentration, which we denote by a0, is proportional to the rate of glucose utilization in the tissue (Turkheimer et al., 1994). However, noise in the data can lead to a shifting of the detected components away from the peak in the spectrum at bj = 0 and a subsequent bias in estimating the rate of glucose utilization. One method proposed to compensate for this effect was to add all coefficients of components whose exponents fell below a certain cutoff frequency βcutoff (Cunningham and Jones, 1993). In each ROI examined in the current study, this parameter K, the rate constant for unidirectional trapping of tracer, was estimated from the bias-corrected coefficients as
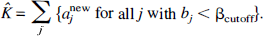
A cutoff threshold of 1/120 minute was used. In addition, the probability distribution and 90% confidence intervals for
H215O studies
As a second example, the method was used for the analysis of brain time-activity curves during an infusion of [15O]-labeled water (H215O) to measure cerebral blood flow. The H215O was infused into an antecubital vein of a normal male subject by an infusion pump (Model 44, Harvard Apparatus, South Natick, MA, U.S.A.) programmed to produce a rapid increase in brain tissue concentration of H215O and keep it elevated for 3 minutes, at which time the infusion was terminated. Measurement of the H215O concentration in arterial blood was initiated just before the infusion of the H215O and continued until the end of scanning by continuously withdrawing blood from a radial arterial catheter past a NaI detector. The dead space of the tubing leading from the artery to the detector, as well as the pump withdrawal rate were fixed, and the dispersion of the arterial curve through this sampling system was well characterized (Jaggi et al., 1997). Brain scanning was initiated concurrently with the start of infusion with a UGM180 scanner (UGM Medical Systems, Philadelphia, PA, U.S.A.) and consisted of six 5-second scans, six 10-second scans, and six 20-second scans. Regions of interest were placed on a number of gray matter structures. Before the application of the spectral analysis bootstrap method, the input function was corrected for estimated delay.
One hundred basis functions consisting of exponential functions convolved with the measured arterial whole blood input function were used. Exponents ranged from bj = 0.1 min−1 to bj = 10 min−1, and the input function and its integral were also included. The minimization procedure was unweighted, and, as with the FDG data analysis, 1,000 bootstraps were used to estimate the distribution of the coefficients, the 90th percentiles, and the bias-corrected coefficients.
RESULTS
Simulation studies
Small differences between the mean of the coefficients computed for each of the simulations,
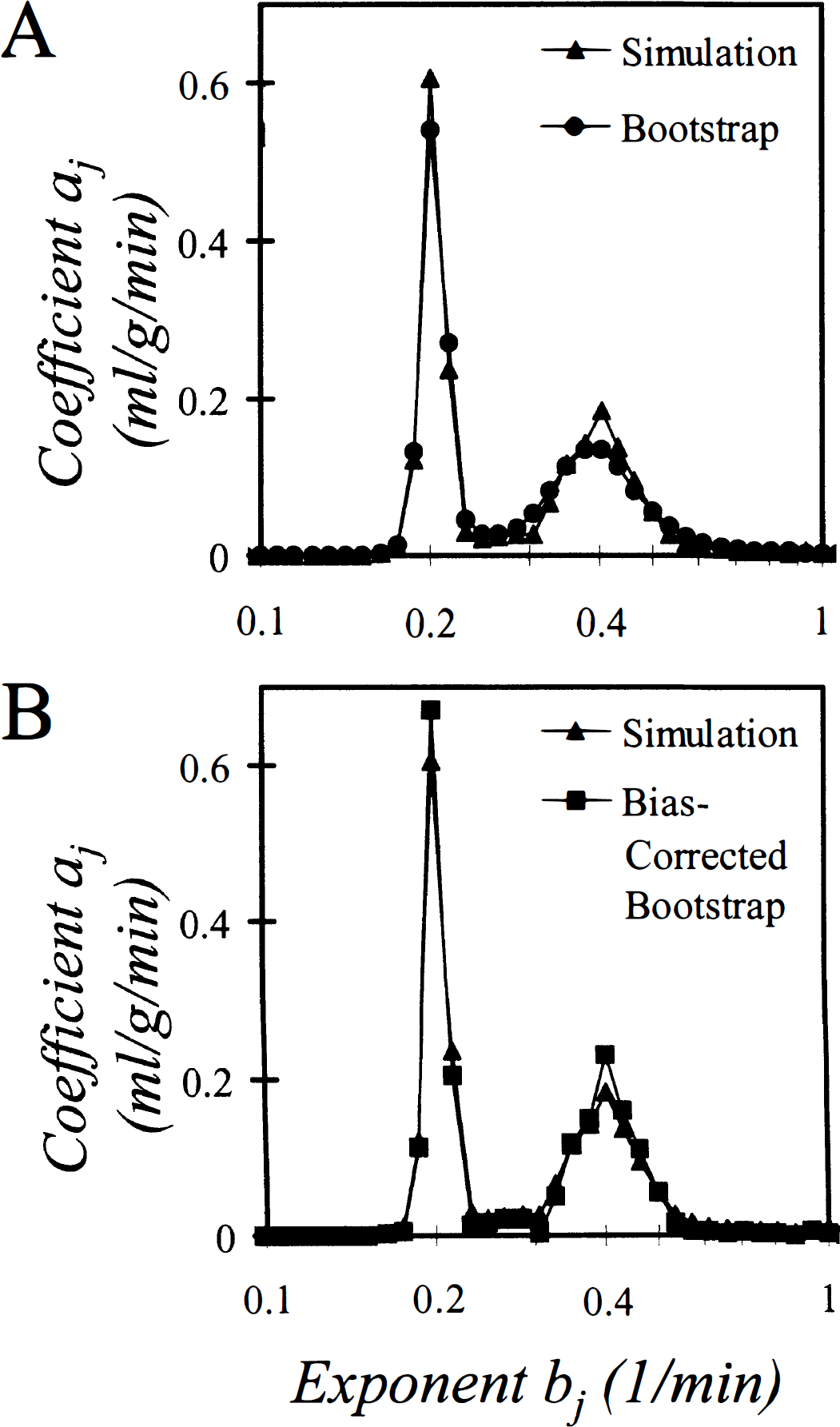
Results of simulation to examine properties of the bootstrap estimator. The biexponential function f(t) = a1 exp (−b1 t) + a2 exp (−b2 f), with b1 = 0.4 min−1, b2 = 0.2 min−1, a1 = a2 = 1, was sampled at times between 0 and 35 minutes. One thousand sample sets of 5% normally distributed noise were generated and added to the sample data; for each noisy data set a spectrum, a bootstrap spectrum, and a bias-corrected bootstrap spectrum were calculated.
A schema illustrating the bias-correction procedure for the derived parameter K1 is given in Fig. 2. Simulation results for the parameter K1 confirmed the theoretically expected tradeoff between decreasing bias and increasing variance in the estimate. The true value of K1 in these simulations was 2.0, and the mean value of the estimate
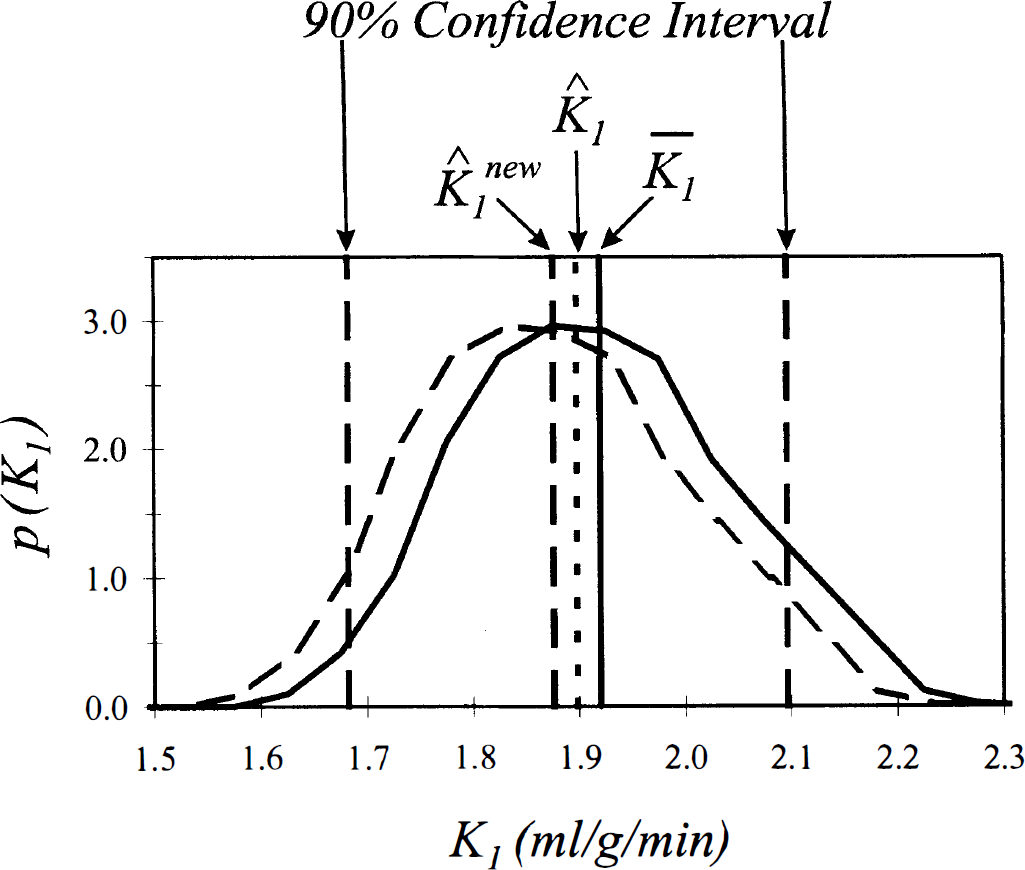
Schema illustrating the bias-correction procedure for a derived parameter. Values of the derived parameter K1 are shown along the x-axis, and the probability density function for the parameter, p(K1), is given on the y-axis. The biexponential function f(t) = 1 exp (−0.4 t) + 1 exp (−0.2 t) was sampled at times between 0 and 35 min as in Fig. 1. Fifteen percent normally distributed noise was generated and added to the sample data, the estimated coefficients
Computation time for evaluation of
[18F]Fluorodeoxyglucose studies
Results of the analysis of FDG data are displayed for the whole brain (Fig. 3A), a small white matter region (Fig. 3B) and a large ROI drawn over the visual cortex (Fig. 3C). The computed spectra shown in the left panels are consistent with previously computed spectra of FDG tissue data (Cunningham and Jones, 1993; Turkheimer et al., 1994). The peak on the far left, labeled a0, corresponds to the coefficient of the integral of the arterial plasma input function and indicates irreversible trapping of the tracer in the tissue, i.e., bj = O. The components detected at bj = 0.06 min−1 and bj ≅ 0.6 min−1 have been associated with exchangeable tissue compartments in white and gray matter, respectively (Turkheimer et al., 1994). Because of the partial volume effect of the scanner, heterogeneity was detected in all regions, even those in which the ROI was placed over an area that was predominantly white matter (Fig. 3B), or predominantly gray matter, such as the visual cortex (Fig. 3C). The fourth peak, detected at bj 2.5 min−1, is consistent with a rapid equilibration of the tracer in the tissue and has been associated to delay and dispersion of the measured input function (Cunningham and Jones, 1993).
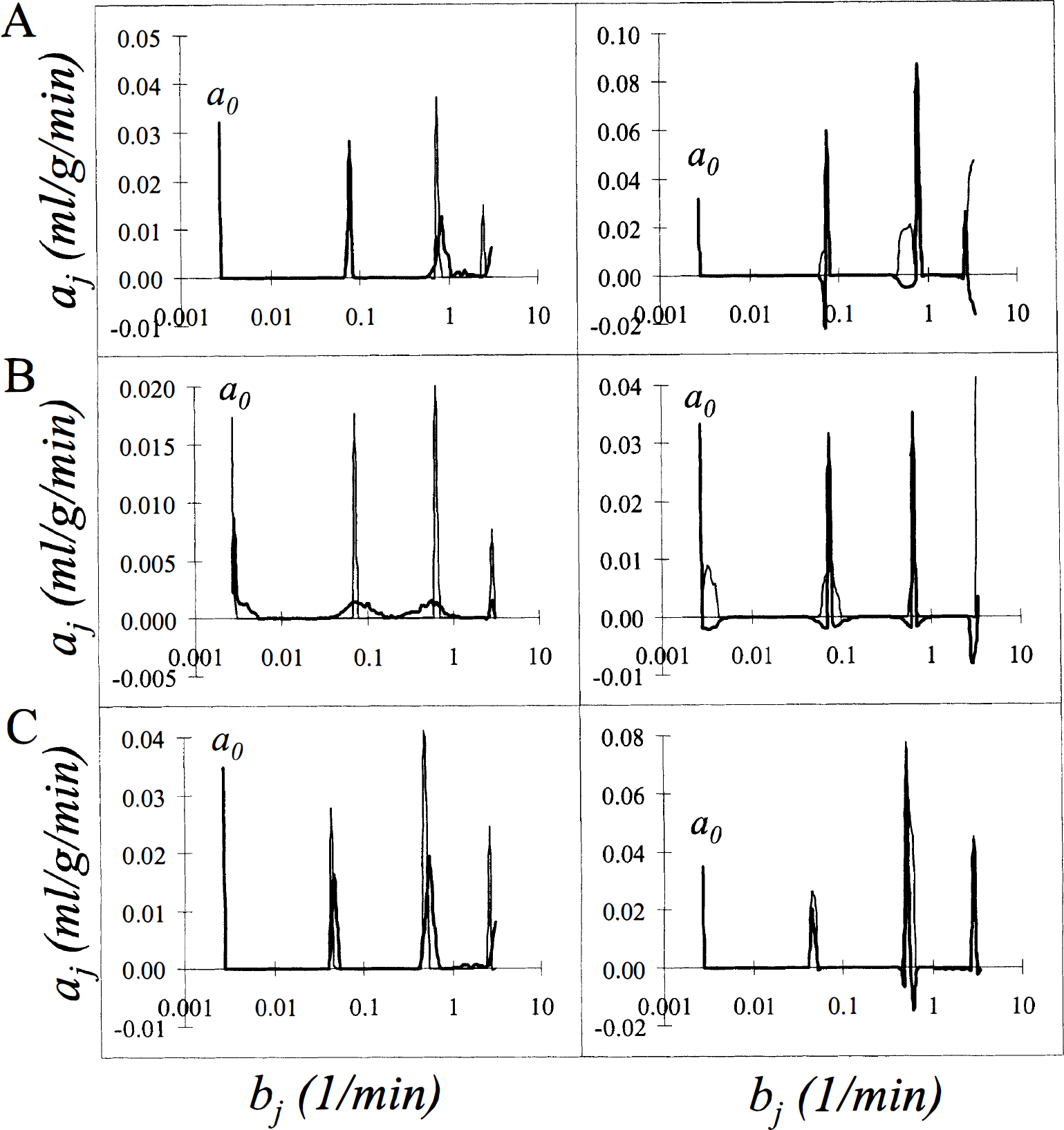
Results of spectral analysis with bootstrap resampling applied to brain tissue-activity curves after intravenous injection of [18F]fluorodeoxyglucose into a human subject. Regions shown are whole brain
The bootstrap spectra, shown in the heavy lines in the left panels, allow one to make inferences concerning the uncertainty of the detected peaks. The first and most expected is the increased width of the peaks in the relatively higher noise region, i.e., the white matter region (Fig. 3B), compared to the lower noise data sampled in the whole brain (Fig. 3A) or large gray matter region (Fig. 3C). Additionally, the bootstrap spectra indicate a greater variability in the peak associated with the gray matter exchangeable compartment (bj ≅ 0.6 min−1) than in the more slowly exchanging compartment (bj = 0.06 min−1); this may be caused by a combination of the higher noise level in the first minutes of scanning, which largely determine the faster component, and the greater heterogeneity of gray matter.
In the right panels are shown the 90th percentiles of the distribution of the coefficients and the bias-corrected spectra. The greater uncertainties in the coefficients in the higher noise white matter region are seen as broader “shoulders” on the peaks in the 90th percentile of the distribution. In particular, in the white matter region the coefficient a0 of the integrated component at bj = 0 min−1 was computed to be 0.020 mL·g−1·min−1, but its 90th percentile was found to be 0.032 mL·g−1·min−1, indicating a large degree of uncertainty in the estimate. By contrast, in low to medium noise conditions (Figs. 3A and C) the bias-corrected coefficient a0 and its 90th percentile are within 1% of the initially computed value.
Distributions for the estimated rate constant for unidirectional trapping of tracer are shown in Fig. 4. In the whole brain and the visual cortex there is an extremely small spread of the parameter estimate about its mean value. The mean value and 90% confidence interval of the estimate
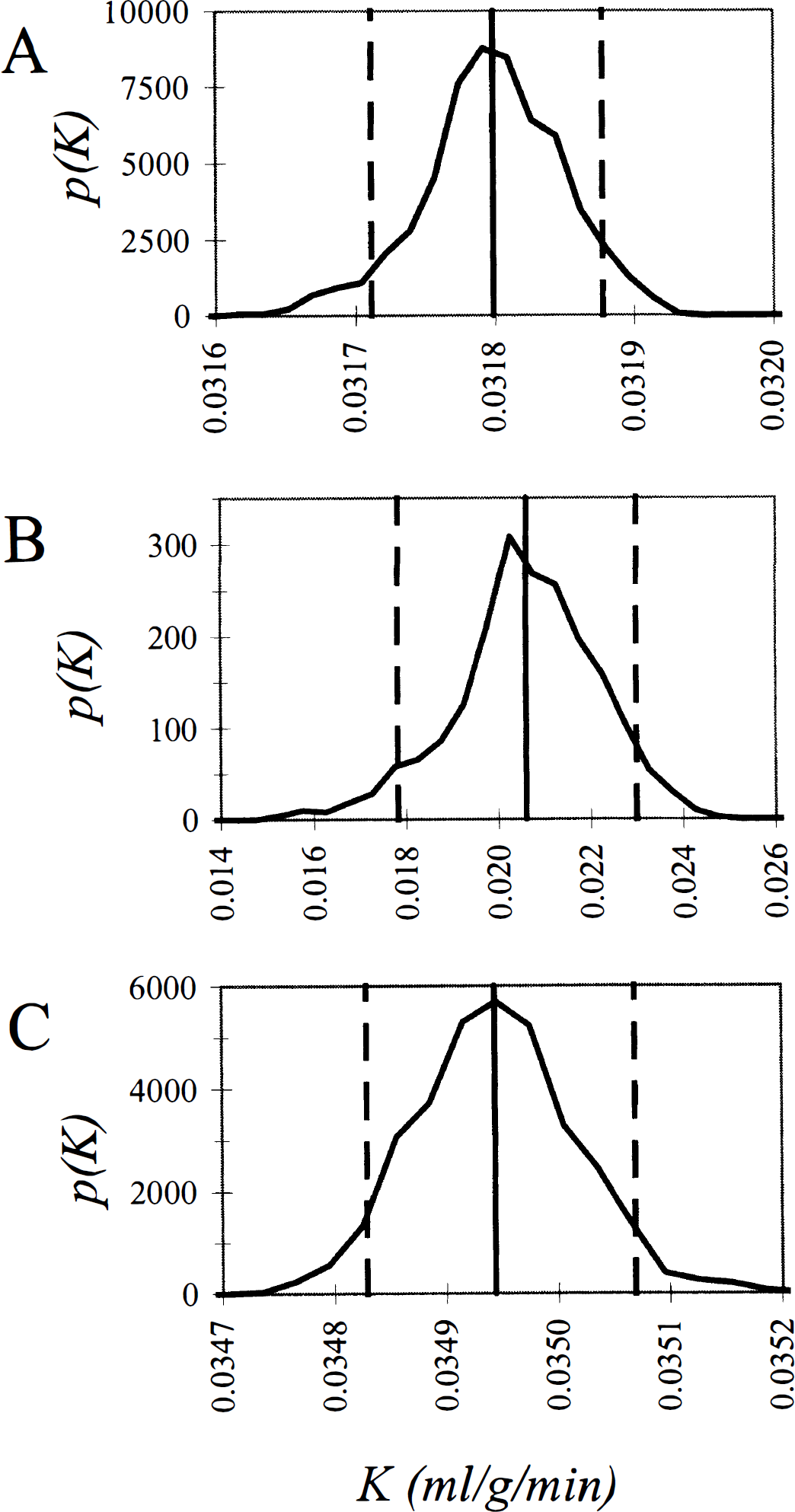
Probability density functions for the estimated rate constant for unidirectional trapping of tracer, K after intravenous injection of [18F]fluorodeoxyglucose into a human subject. In the presence of noise in the data, the parameter K leads to a more accurate determination of glucose utilization than the coefficient a0 (see Fig. 3). K is computed as the sum of those coefficients aj for which the corresponding exponents bj fall below a cutoff threshold (see text). Shown are the bias-corrected estimate of K (vertical unbroken line), its probability distribution function (unbroken curve), and its 90% confidence interval (vertical dashed lines) for the whole brain
H215O studies
Figure 5 shows the computed and bootstrap spectra (left panel) and the bias-corrected and 90th percentile spectra (right panel) resulting from the analysis of the time course of tissue radioactivity in the cerebellum during infusion of H215O. Whereas the computed spectrum is consistent with preceding analyses that have detected two peaks (Cunningham and Jones, 1993), new information concerning the variability of the two components is provided by the bootstrap spectrum. The first peak (bj = 0.7 min−1) represents relatively rapid exchange of tracer between blood and tissue; it probably corresponds to blood flow in the gray matter tissue. The uncertainty on the exponent bj is rather high; this is consistent with the observation that spectral analysis of H215O time activity curves does not lead to precise estimates of cerebral blood flow values (Cunningham et al., 1993).
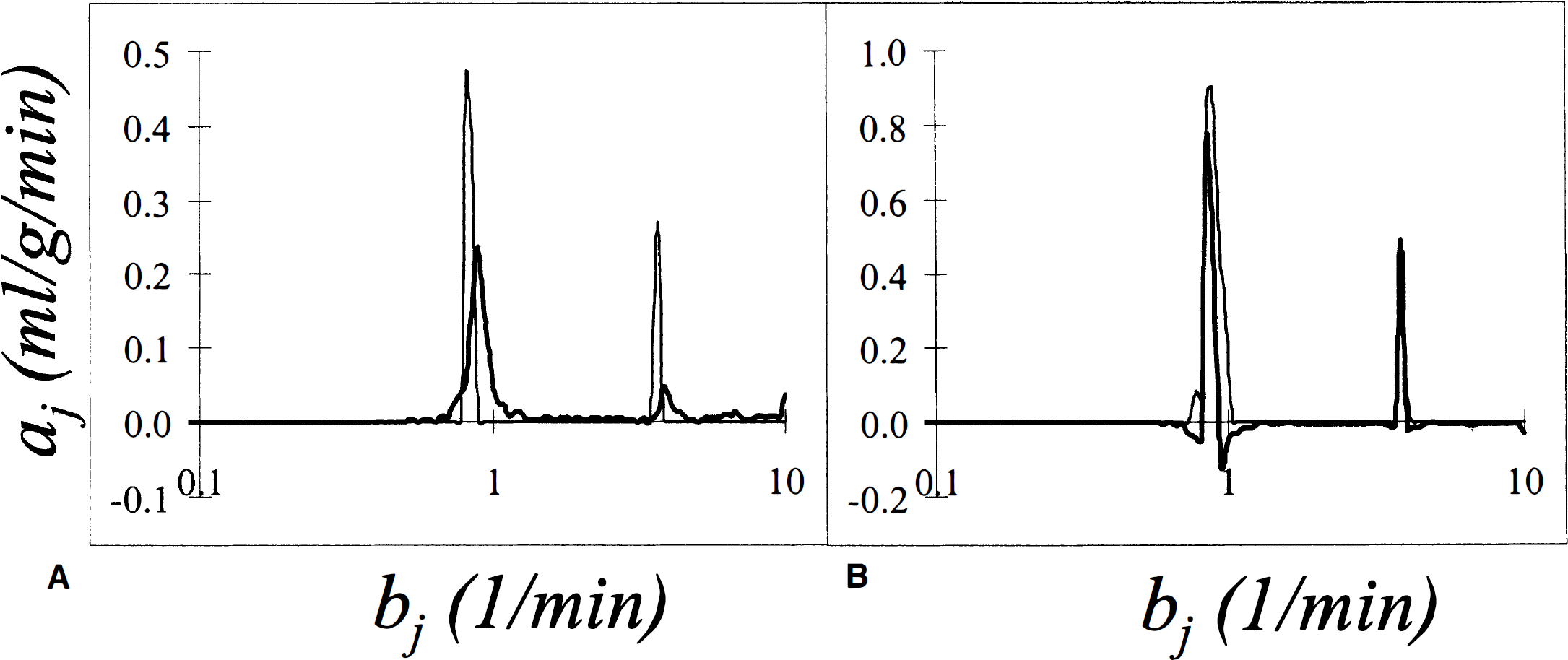
Results of spectral analysis with bootstrap resampling applied to brain tissue activity curves measured during infusion of 15O-labeled water into a human subject. Data are for a region of interest placed over the cerebellum. In
It is interesting to observe the lack of a peak that can be associated with white matter flow even though white matter is known to be present in all ROI because of the limited spatial resolution. The magnitude of the coefficient of the white matter flow component is expected to be small and is probably not detectable at the given noise levels; in addition the length of the sampling schedule may be inadequate for the detection of the much slower white matter component.
The very fast peak (bj ≅ 4 min−1), related to dispersion and delay in the input function, is also determined with a large degree of uncertainty. The 90th percentile of its coefficient, 0.47 mL·g−1·min−1, is almost twice its computed value of 0.27 mL·g·min−1. Although its value cannot be precisely estimated by the spectral analysis technique, the presence of the very fast peak must be taken into account for any further modeling as previously discussed (Cunningham et al., 1993).
DISCUSSION
This report proposes a method to estimate the statistical distributional properties of the components determined by spectral analysis and of parameters derived from those components when the method is applied to a single data set. The method uses the bootstrap technique to estimate the mean effect of noise on the computed spectrum, to estimate bias in the bootstrap spectrum, and to correct for that bias. The bias-corrected bootstrap spectrum was shown to be a good estimator of the average spectrum that would have been obtained if repeated samples of the measured data set were available. Assumptions concerning the distributional properties of noise in the data are minimal, and specific implementations of the bootstrap procedure have been considered to handle the case of inhomogeneity of variance in the measured data.
The application of the method to two sets of PET dynamic data was also presented to illustrate the main property of the bootstrap estimator, i.e., it provides an assessment of the uncertainty of the computed peaks, and gives a preliminary picture for the subsequent modeling or parameter estimation. The proposed method does not eliminate the need to use biochemical or physiologic information obtained from other sources to interpret the dynamics of the system.
It is also worth noting that application of spectral analysis to the data in this report has relied on the assumption that the kinetic behavior of the system can be described by a non-negative linear combination of the chosen basis functions. Non-negativity of the linear coefficients is an essential requirement of this approach; other analysis methods must be applied if the system does not satisfy this constraint. If the system requires functions other than convolution integrals, the method can be applied only if another set of basis functions, valid for the system under study, is defined.
Finally, because the bootstrap procedure is computer intensive, its use may be limited in the case of very large data sets as in the voxel-by-voxel analysis of PET volumes.
Footnotes
Acknowledgments
The authors thank Dr. Julian Matthews for his many valuable discussions with us.
Abbreviations used
1
Equation [1] assumes that the eigenvalues of the system are distinct (Godfrey, 1983).
2
Usually the standard deviations in the measurements, σk, are used as weights. It is only the relative weights in the measurements, however, that are required. If the measurement variance is unknown, weights of one are used when the variance is assumed to be the same at all measurement times, and weights equal to the measured tissue concentrations themselves are used when the coefficient of variation is assumed constant.
3
For example, if the original residuals are
4
Software available on request from the author.
APPENDIX I
APPENDIX II
Percentiles of the distribution of the estimated coefficients of