
Abstract
In this article, we examine the coverage and reliability of distributed sensor networks that are designed for surveillance applications. In particular, we examine a model of sensor network coverage based on Poisson processes, and illustrate how this model combines with standard reliability models to provide estimates of field degradation over time. The results of the article illustrate how the number of sensors required changes with respect to reliability criteria, and how to design and re-seed sensor fields to maintain a minimal level of surveillance coverage. The formulation in the article is presented analytically, and all results are compared to numerical simulations.
Introduction
Distributed sensor networks are rapidly becoming a ubiquitous component of modern surveillance systems. Recent advances in computing, manufacturing, wireless communications, and power electronics have made the deployment of many small autonomous sensors an affordable alternative to large manned sensing platforms [1–3]. The general goal in deploying a large surveillance sensor network is to detect and/or track a target that has entered the surveillance region. Examples of such networks can be found in [4] and [5]. A particular feature of the target surveillance application is the use of sensors in environments where communications are constrained, and where specific placement is limited to spreading sensors according to a prescribed sensor density. When communications are readily available, various sensor planning algorithms (such as [6]) are available to carefully query and allocate sensor resources. However, under the constraints of difficult environments (such as the undersea environment), the sensor field's performance is enhanced only through careful initial planning of sensor placements. With good performance models, the deploy-and-forget planning of sensor fields for desired performance is possible. Suitable performance models for this type of planning have been developed for the cases of random deployments [7], clustered deployments [8], and for heterogeneous mixtures of sensors [9].
The analysis of the target tracking performance of distributed sensor networks is much more complicated than simply determining the “packing coverage” for sensors placed on a rigid grid. In recent practice, models of random placements combined with idealized individual sensor performance models are often used to provide rough order-of-magnitude estimates for the performance of actual systems. These models are particularly good at capturing trends in performance characteristics relative to deployment density and sensor characterization; such results are crucial for applications where large deployments are rapidly made over potentially large areas during time-critical scenarios. However, in many applications of interest, the sensors are necessarily complicated, finely-tuned engineered devices. This can drive up the price of large fields (see [10]) and eliminates the primary motivation for selecting the sensor network (instead of a large fixed asset) for a surveillance solution. Thus, the ability to field systems with simpler, less expensive sensors is of paramount importance to the design and employment of these networks.
In building and deploying systems with cheaper components, careful consideration must be given to the variability in individual sensor performance that can be expected with reduced per-unit cost. In practice, the performance of sensors in a sensor network varies with respect to spatial position and with respect to uncertain manufacturing flaws (since all sensors cannot be tested prior to deployment). The spatial variation of sensor detection performance is due to geographic differences in the local operating environment, and is often compensated for with on-board sensor processing so that sensor performance is effectively independent of location. Other mechanisms of spatial variation are attributed to the communications paths between sensors [11]. These are also compensated for by using the network to ascertain environmental features and applying appropriate processing changes. In contrast to the spatial variations in sensor performance, the variation in performance with respect to manufacturing uncertainties is generally uncompensated (since calibration is similar to testing of each unit) and thus the performance estimates obtained by assuming identical sensor performance are often overly optimistic. Recently, there has been acknowledgement of this shortcoming and analyses [12, 13] have been developed to show the impact of randomly deployed sensors with reliability limitations at the networking level. However, these studies do not consider the target surveillance aspect of sensor networks under limited individual sensor reliability.
In this article, we develop a sensor network analysis formulation that is based on spatial Poisson processes with an underlying density function on detection performance that contains reliability-based performance statistics for the sensor characterization. In this way, we show that our formulation addresses the performance of the sensor network under anticipated manufacturing and/or aging concerns for the individual sensors. We begin with a derivation of the sensor network performance model. Then we show the application of standard component reliability models to our network model. Examples of system performance under sensor failures as well as sensor degradation are shown, and we show how to use the reliability performance model to address system design issues of deployment size and network re-seeding. All examples shown include analytical solutions with validating simulations.
Sensor Network Model
Two issues of fundamental concern in time-critical scenarios are sensor placement and sensor availability. Realistic scenarios will often not provide the time for a precise placement of sensors. It may be necessary, for example, for sensors to be randomly distributed over the surveillance region (e.g., via aircraft). Secondly, depending on the size of the surveillance region and cost per sensor, there might not be sufficient sensors of any one type available to achieve the required field-wide detection performance. For this reason, it is necessary to develop techniques that measure the coverage of sensor networks consisting of disparate types of sensors (heterogeneous sensor fields). Finally, the number of sensors functioning in the field is not necessarily the same as the number deployed, as some sensors will immediately fail upon deployment. Others may drift or, due to measurement error, may be placed outside of the actual surveillance region. For these reasons, we consider a spatial Poisson process to model the coverage of the surveillance region. This allows for the actual number of sensors deployed to follow a Poisson random variable with mean number of sensors deployed equal to some parameter times the measure of the surveillance region. Conditioned on the actual number of sensors deployed, the distribution of the sensor locations is uniform over the surveillance region (cf. [14]). Moreover, as the detection ranges are allowed to vary from sensor to sensor, the analysis requires only the distributional characteristics of the sensor detection ranges (cf. [14]).
A spatial Poisson process is concerned with the number of points associated with some event over a region of space. Let Ω be an n-dimensional set and suppose A is a subset of Ω(A⊂.Ω). Consider points scattered randomly throughout Ω and let N(A) denote the number of points from the scattered set that are contained in A. The stochastic process N = {N(A), A ⊂ Ω} is called a point process in f. Let A denote the volume of A. The stochastic process N = {N(A),A ⊂ Ω} is an n-dimensional Poisson counting process with parameter λ > 0 if
N(A) follows a Poisson distribution with mean λA, and The number of points occurring in disjoint subsets of Ω are mutually independent.
Thus, if N =\{N(A),A⊂Ω} is an n-dimensional Poisson counting process with parameter λ > 0, then the probability of k occurrences in the subset A is given by

Further information on spatial Poisson processes can be found in [15] or [16]. The use of spatial Poisson processes in studying the coverage of sensor fields of identically performing sensors has been previously examined in [17]. In the following, we generalize the analysis to include fields in which the detection range varies from sensor to sensor (heterogeneous sensor range).
Consider a set of disks (representing sensor coverage and henceforth refered to as sensors) scattered over a region Ω⊂R2. We assume that the sensors are spatially distributed according to a Poisson point process
1
with parameter λ. Suppose that the detection range for all sensors (i.e., the radii of the disks) are independent of sensor location and are distributed according to density f(r) with finite second moment. Then, it is known (see [16] or [14]) that the number of sensors that detect an arbitrary point x∈Ω is a Poisson random variable with parameter


Throughout the remainder of this paper, the statistic
Note that the expected coverage area of a single sensor under this model is given by

Next, consider the case where multiple detections are combined to provide a better certainty of a target's presence within the region. This use of multiple detections is common in sensor fusion networks because the multiple detections can reduce the field's potential degradation due to any single sensor's errant report [18]. While most commonly employed in tracking applications, the use of multiple detections to reduce the impact of these false alarms is equally applicable in examining spatial coverage for sensor fields. The term k-sensor detection is used to denote the event that k or more sensors detect the same point x
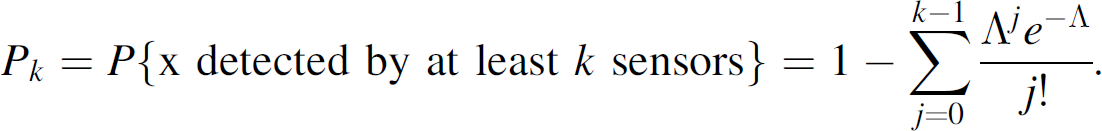
If an arbitrary point in the region is to be detected by at least k sensors, then the result shows the intensity level (i.e., Λ) that is required to achieve this performance, on average, for a given Pk. Since the mean number of sensors that detect an arbitrary point in Ω is

Within the sensor network performance model, we recall the fact that the sensors are not necessarily perfect, they are not even necessarily identical in performance quality. In particular, f(r) (the distribution density function for the detection range over all sensors) provides a mechanism for capturing this variability. In practice, the variability may be due to manufacturing considerations and/or lack of calibration that allows the per-sensor cost to be kept down. Thus, instead of a few very expensive sensors with known fixed detection range r0, the network may contain many less expensive sensors having uncertain detection ranges. We expect our model to illustrate this distinction and provide the appropriate conditions under which the network of inexpensive sensors performs as well as the network of fewer expensive sensors.
Through sampling, one can get an estimate of the distribution for sensor detection range. In the idealized case, in which all sensors have identical (fixed) detection range r0, the sensor range density is given by the dirac delta function

The beta-type density model is used to convey the idea that some sensors will perform better than others. Figure 1 shows three examples of beta-type densities with realizations over the interval 0 ≤ r ≤ c where c = 5. The leftmost density in Fig. 1 (for α = 2.0 and β = 7.0) depicts the case where almost all sensors have weak detection performance. The center density in Fig. 1 depicts the opposite: for fixed β, as α increases, the density approaches the dirac delta density δ(r −5) corresponding to the homogeneous field. The rightmost density in Fig. 1 (α = 1.0 and β = 0.67) is used for the heterogeneous field in Fig. 2. This density slowly increases over most of the interval. Hence its samples are somewhat uniform over the interval with preference to samples from the upper end of the interval. It conveys the idea that, upon deployment, some sensors will be defective or give very poor performance, whereas others will perform very well. And, of course, several will provide just average performance.

Sample β-type density functions.

Sample homogeneous and heterogeneous sensor fields with same mean sensor detection range. The homogeneous field has r0 = 3 and the heterogeneous has f(r) given by a beta distribution with α = 1.0, β = 0.67, c = 5.0.
The mean range to detection for this heterogeneous system is given by


Two hundred and fifty simulations of the coverage for homogeneous and heterogeneous sensor fields over a 100 by 100 square unit area. The homogeneous field has detection range r0 = 3 linear units for all sensors and the heterogeneous has detection range density f(r) given by a beta-type distribution with α = 1.0, β = 0.67, c = 5.0.
The performance of the field coverage, as given by equation (3), depends on the sensor detection range distribution density f(r) only through the expected sensor coverage area

For the heterogeneous field with f(r)given by a beta-type distribution as in formula (7), we have


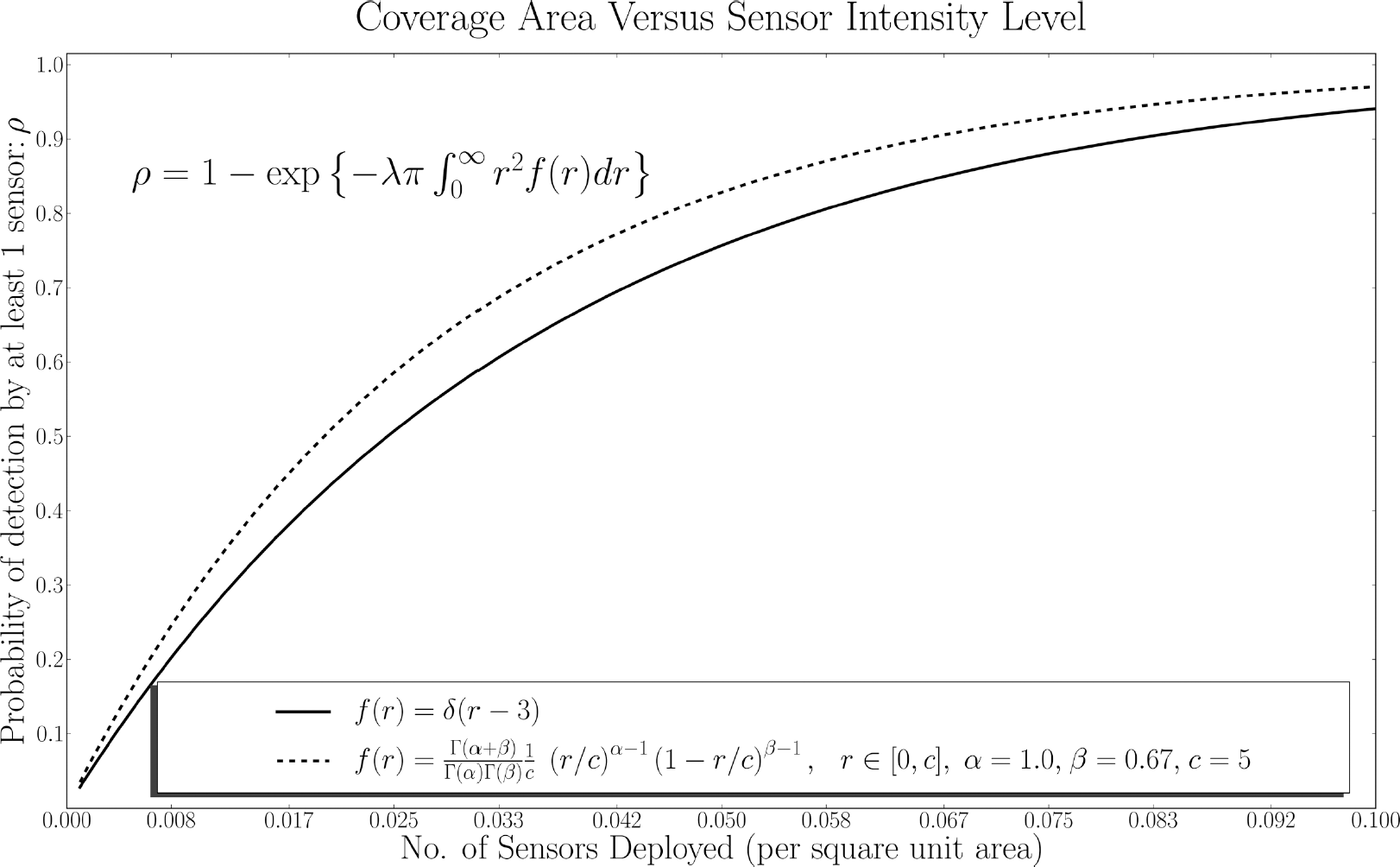
Comparison of expected coverage for homogeneous and heterogeneous sensor fields. The homogeneous field has r0 = 3 and the heterogeneous has f(r) given by a beta distribution with α = 1.0, β = 0.67, c = 5.0.
One of the primary motivations for the employment of a heterogeneous set of sensors is the potential cost savings from using non-ideal sensors. To examine this benefit, consider a set of sensors designed with an ideal sensing range r0. Due to manufacturing uncertainties and component irregularities, the resulting sensors do not achieve the ideal performance, but rather, may have a performance driven by a beta-type distribution with maximal range c = r0. From (10) we see that the mean sensing area for this type of heterogeneous system is given by
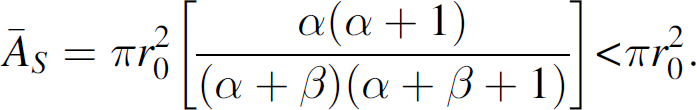
The inequality results from applying the constraints from (7) that α > 0 and β > 0. Thus, for any selection of distribution parameters, the mean sensing area performance cannot match that of the perfect sensors. However, recall from Eqs. (2), (4), and (5) that the sensor field performance is monotonically related to Λ, which is a simple product of the mean sensor coverage area

We close this section by pointing out that these methods may be generalized to compare the performance of any two sensor fields. For example, suppose S1 is a sensor field with intensity parameter λ1 and detection range density function f1. If S2 is another sensor field with detection range density f2, then the field intensity required in order to achieve, on average, the same coverage as S1 is

Stated differently, if system S1 has N1 sensors, then the number of system S2 sensors required to achieve the same coverage, on average, is

In this section, the reliability of the sensor network system over time is examined. Two scenarios are considered. In the first case, we analyze the change in k-coverage (k or more sensors detect an arbitrary point) of the network as sensors randomly fail. In the second scenario, we consider the system coverage as the detection capability for each sensor decays with time. This situation can occur, for example, as a result of battery depletion. Both scenarios result in reduced coverage; however, the techniques of the latter section allow for the possibility that the depleted sensors are recharged, or that the network is seeded with new sensors. While methods such as those in [19] look at extending sensor network reliability via scheduling, our focus is on surveillance in adversarial regions. In these regions, it is difficult to regularly communicate with and/or re-populate the sensors within the field. Thus, we only consider the situation in which all sensors within the field are expected to be available for sensing at all times after deployment.
Sensor Failure
We assume that the sensor lifetimes Ti are independent and identically distributed. Special attention is given to the case where the sensor lifetimes follow a Weibull distribution with scale and shape parameters μ and ν, respectively. Thus

The Weibull and, other gamma-type distributions, are often used in reliability theory to model the time to failure or life expectancy of electronic systems. They are particularly suited to cases where the failure mechanisms correspond to events that occur with observable (or predictable) rates. Such failure modes have been noted in sensor networks for military surveillance applications, as noted in [20].
Under the Weibull failure model, the probability that a particular sensor survives beyond time τ is

Thus, under the independence assumption, if N sensors are initially distributed, then the number to survive beyond time τ is a Binomial random variable with parameters N and P{T > τ}. Moreover, NP{T > τ} is the expected number of sensors to survive beyond time τ. Therefore the updated estimate for the sensor field intensity parameters (λ and Λ) are


Let C(τ) be the number of sensors that cover an arbitrary point in Ω at time τ. The k-coverage system statistic at time τ is defined as the probability that k or more sensors detect an arbitrary point in Ω at time τ:

Similarly, we define the k-coverage system η-life, τ
k
, η, as the time taken for the network k-coverage to degenerate to the fraction η of its original coverage level. That is,

The k-coverage system half-life is denoted by τ k 1/2.
As an example of the k-coverage system η-life, we consider the 1-coverage system half-life associated with a Weibull failure model. First note that if the sensor failure rate is T ∼ W(μ, ν), then P{T > τ} is given as in Eq. (16). Now the 1-coverage system half-life occurs at τ1,1/2 satisfying ρ1(τ1,1/2) = ρ1(0)/2, i.e., from Eq. (3),

Solving this equality for
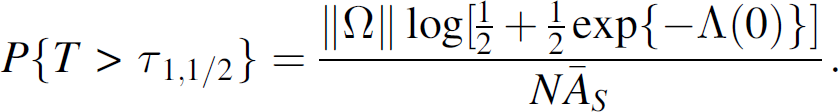
Finally, using (16), we solve explicitly for
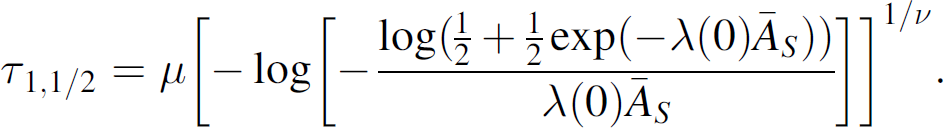
Fig. 5 shows the theoretical (solid black curve) and five simulations of the 1-coverage degradation over time of a network consisting of 250 sensors (distributed over a 100 by 100 square unit area). All sensors have a detection range of r0 = 3 units and a failure rate modeled by a Weibull distribution with (μ, ν) = (12.5,2.25).

1-Coverage degradation for a network of 250 sensors distributed over 100 by 100 square unit area. Sensor failures occur randomly, following a Weibull distribution with parameters μ = 12.5, ν = 2.25.
In general, the η-life k-coverage for the system lifetime must be solved numerically. For example, consider τ
k,η
, the time taken for the system k-coverage to decay to 100η % (0 < η < 1) of its original coverage level. From formula (5), it follows that

We are interested in τ
k,η
satisfying ρk(τ
k,η
) = ηρ
k
(0). That is,

Or equivalently, after collecting terms,

Now, for given η, the right hand side of (26) is constant. Therefore, we can set


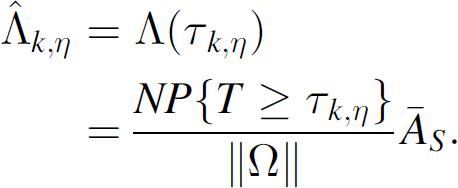
Hence the k-coverage η-lifetime,

In the particular case where the sensor failure rate follows a known distribution, we can solve (30) explicitly for τk,η. For example, recall (see Eq. (16)) that for the Weibull sensor failure rate
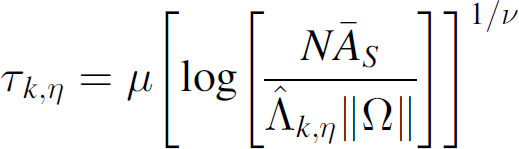

Fig. 6 compares the degradation for the 1, 2, and 3-coverage for a network of 500 homogeneous sensors. In all of the examples in Fig. 6, the degradation follows a Weibull distribution with parameters (μ, ν) = (12.5, 2.25). Note that the graphs start out essentially flat, due to few sensor failures at the time of deployment. Note also that the k-coverage half-life decreases with increasing k. This is to be expected since coverage overlap decreases as the sensors randomly die off.

k-coverage degradation for a network of 500 homogeneous sensors distributed over 100 by 100 square unit area. Sensor failures occur according to a Weibull distribution with parameters (μ, ν) = (12.5, 2.25).
Equation (30) describes the relationship between N, the number of sensors initially distributed, and τk,η, the time taken for the system k-coverage to degrade to a fraction η of the initial coverage. It is desirable to know the number of sensors to deploy in order to guarantee a certain level of performance at some future time. This can be found by solving Eq. (30) for N. Recall, however, from (17)–(18) that
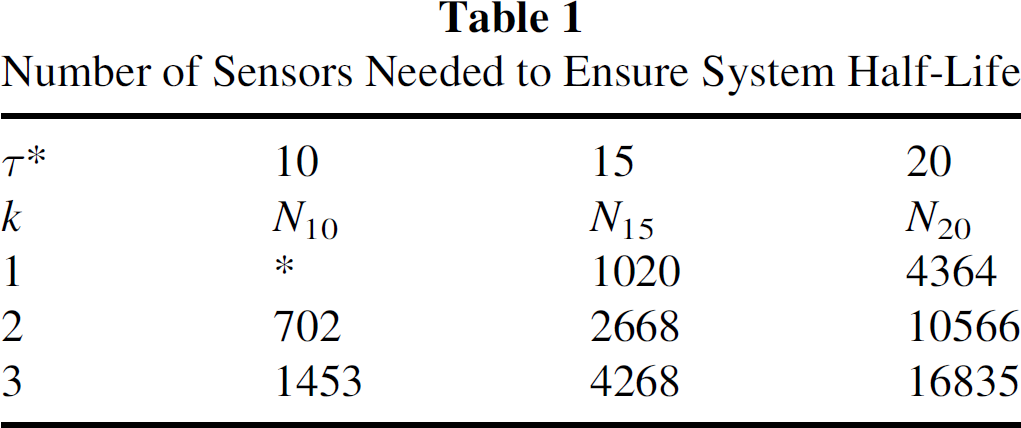
Table 1 shows the required values of Nτ∗ for k = 1,2, and 3 to achieve various levels of τ∗. For this example, all sensors have a detection range of 3 units, and the life expectancy of the sensors is assumed to follow a Weibull distribution with parameters μ = 12.5 and ν = 2.25. The surveillance region is a 100 by 100 square unit area. The asterisk in row one signifies that, under the given parameters for the sensor life expectancy, the expected 1-coverage for any number of distributed sensors is greater than ten time units. The mean value of a Weibull random variable with parameters (μ, ν) = (12.5, 2.25) is μ(1 + 1/ν) = 11.07. Therefore, on average, a network consisting of just one sensor will maintain coverage up to 10 time units after deployment. Moreover, the expected system k-coverage (for any k) increases with increasing N. This occurs due to the following: For any number of sensors initially deployed, points in the space are covered by either fewer than k sensors, or are covered by at least k sensors. If additional sensors are immediately (i.e., no time passes between the initial and secondary deployment) added to the field, then some points previously not covered by k sensors will attain m-coverage, m ≥ k. Over time, these points will lose their k-coverage at a rate no greater than points previously covered by exactly k sensors. Some points already covered by at least k sensors (i.e., before the additional sensors were deployed) will acquire additional coverage; these points will lose their k-coverage at a slower rate than they would without the additional sensors.
Number of Sensors Needed to Ensure System Half-Life
Due to limited battery supply and the autonomous nature of the distributed sensors, it is expected that degrading range sensitivity is a more prevalent reliability issue (especially over extended periods of operation) than simple failure. In this section we consider the field performance for the situation where sensor effectiveness degrades with time.
Although the field intensity parameter λ is constant, the detection range density across all sensors and the mean sensor detection parameter are functions of time, denoted F(r; τ) and 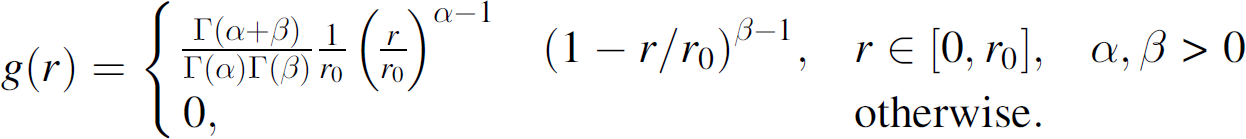
An initial-terminal range analysis can be used to determine a lower bound on the network performance over time.
As time progresses, the network evolves into a mixture of the initial and terminal sensor systems with density



With little effort, F (r;τ) can also be adjusted to account for additional sensors randomly distributed over the field. For example, suppose M additional sensors are added to the field at time τ∗. Then the proportion of all sensors to have undergone change at time τ > τ∗ is

Using the decay mixture described by equation (34) with the corresponding end state of Eq. (33), the mean sensor area coverage reduces to

Figure 7 shows the coverage degradation over time of the predicted result (dark line) and five simulations of a sensor network in which range sensitivity degrade from a homogeneous network (all sensors have detection range of 3 units) to a heterogeneous network (detection over all sensors decay to samples from a beta-type distribution of the form of equation (7) with (α, β) = (2,2)). The time to decayed performance for each sensor follows a Weibull distribution with parameters (μ, ν) = (12.5, 2.25). After 15 time units the field is recharged with the addition of another 125 homogeneous sensors. From Fig. 7, it is clear that the re-seeded field does not behave identically to the initial field, although it does reach the same peak level. In particular, note that the slope of the decay in performance after reseeding is greater than that initially. This is an important feature of maintaining many aged sensors in the field, and is a critical component of the model for sensor deployment planning purposes.

System Degradation with Reseeding.
A mathematical model has been presented to examine the coverage and reliability of distributed sensor networks that are designed for surveillance applications. The model uses established methods of sensor network coverage analysis that are based on Poisson processes, and extends them with known reliability models to provide estimates of field degradation over time. Examples were presented that show the required numbers of initially deployed sensors to maintain coverage over extended periods of operation, as well as how to choose appropriate re-seeding of a field that has degraded. When used in conjunction with appropriate cost models, the methods of this paper can be utilized to derive optimal deployment strategies for surveillance application of distributed sensor networks.
Footnotes
1
2
We use the term approximately because we assume that sensors are randomly distributed according to a spatial Poisson point process with parameter