
Abstract
Recent advances in technology have made it possible to build surveillance systems using many low-cost sensor nodes with limited computation and communication capabilities. Due to a potentially large number of nodes deployed, node failures are inevitable and can render a surveillance system that has degraded detection performances. The exposure metric has been proposed earlier to assess the quality of a surveillance system based on the detection performances. In this paper, we characterize the vulnerability of a system in terms of its exposure with respect to the number of faulty nodes and their combinations. Specifically, we assess the exposure of a surveillance network subject to a given number of faulty nodes, and identify the worst-case fault combination for both an idling target and a traversing target. For an idling target, the worst-case fault combination and exposure is analytically identified. For a traversing target, a genetic algorithm based approach is proposed to derive a near worst-case fault combination, and extensive simulation results are presented to show the effectiveness of the algorithm.
Introduction
Emerging sensor network technology has enabled the production of a bridge between the computational space and the physical world, using many low-cost sensing devices with limited computation and communication capabilities [1]. Capable of sensing, processing, and communication, the devices (referred to as nodes hereafter) can form a network to collect measurements about the environment and extract useful information in the monitored region. Such sensor networks can be exploited for a variety of purposes. Having been showcased in applications such as wildlife tracking [2, 3] and battlefield intrusion detection [4, 5], one can envision that sensor networks will be an important infrastructure for how we observe the world in the future.
This paper addresses the problem of detecting an intruder or a target in a surveillance sensor network. The surveillance network is comprised of a set of nodes collaborating to detect the presence/absence of a target by exchanging information via wireless communications. Exposure defined as the least probability of detecting a target over all possible target maneuvers has been used to measure the quality of such surveillance networks [4]. Numerous research in literature has focused on the problem of computing the exposure of a given network [4, 6]. However, almost all of them do not consider node failures in the network. This article characterizes the impact of faults and develops algorithms to identify the worst-case fault combinations that make a given network most vulnerable to both idling and traversing targets with and without the presence of obstacles in the region.
The presence of faults mislead the network from arriving at a correct decision and substantially impacts the exposure for the deployment. As exposure varies with different fault combinations, the article identifies the worst-case fault combinations when detecting for either an idling or a traversing target. For an idling target, the article analytically identifies the worst-case fault combination and proposes efficient methods for computing the exposure in the presence of faults and obstacles. For a traversing target, the article proposes a genetic algorithm based approach [7] to find the worst-case fault combination, and compares the exposure in the presence of faults obtained by this approach to that of an exhaustive search. The comparison shows that the genetic algorithm based approach can find the worst-case or near worst-case fault combination with considerable improvement in terms of runtime and exposure.
The remainder of this article is organized as follows. Section II reviews the related work in literature. Section III details the fundamental assumptions and mathematical preliminaries for target detection in sensor networks. Section IV formally defines the problem addressed in this paper. In Section V, the approach to determine the worst-case fault combination(s) for an idling target is presented. In Section VI, a genetic algorithm is developed to search the worst-case fault combination for a traversing target and the evaluation results are presented. The paper concludes in Section VII.
Related Work
Exposure and coverage problems of sensor networks have been studied extensively in the literature [4–6, 8–14]. These studies often differ in the exact definition of exposure. In [6], exposure is defined as the integral of signal intensity measured by nodes when a target moves along a path. For a single sensor case, the paper derives the exact shape of the minimum exposure path in a square region. For a multiple sensor case, the paper proposes a centralized approach to determine the minimal exposure path using a high order grid and the shortest path algorithm. In contrast, both [9] and [15] study localized algorithms to identify the minimal exposure path. A probabilistic model of exposure is introduced in [4]. A key aspect of the model is that it considers noise in sensor measurements and directly computes the probability of detecting an idling or a traversing target. Due to noise, the network may incorrectly decide that a target is present when there is actually no target in the region. Trade-offs between exposure and the false alarm probability are also presented in the work. This model has also been used to study sensor deployment strategies to minimize the cost of the deployment subject to an exposure threshold [10]. Moreover, based on the same model, a method to identify the minimal exposure path for targets with varying speeds is proposed in [11].
A number of studies also use sensor network coverage to design sensor deployment strategies. In [16], an integer programming formulation is used to minimize the cost of covering the region of interest. The limitation of the method is that integer programming is not suitable for large sensor network problems. In [12], a heuristic algorithm based on virtual attractive/repulsive forces between nodes is proposed for deploying nodes. The algorithm moves nodes to positions where the virtual forces tend to be balanced. None of the above work considers node failures in the sensor deployment. However, node failures are inevitable in real sensor deployments.
Fusion is a critical issue for making consensus decisions. In the past, a considerable effort has been made to design protocols that reach agreement in the presence of inconsistent faults. For instance, the consensus problem presented in [17] considers n processes with initial values xi to reach an agreement on a value y = f(x1 …, xn), such that each non-faulty process terminates with a value y i = y. The classic Byzantine general's problem considers one specific node, named “general”, broadcasting its initial value x to all the other nodes, and all non-faulty nodes must terminate with an identical value y = x if the general is non-faulty [18]. To reach a correct agreement in this problem, the system must have at least 3m + 1 nodes, where m is the number of faults. However, fewer studies in literature have focused on fault-tolerance in sensor networks. Motivated by the result in [18], a truncation method is proposed in [5] to deal with inconsistent faults in sensor networks. The paper has given insight into the number of sensors required for obtaining a consistent decision, but are inadequate to assess the worst-case impact of faults on the detection performance. Other work has focused on fault detection and correction [19, 20], or redundancy utilization [21]. Our research addresses the method to identify the worst-case fault combination and the need to evaluate the worst-case detection performance in surveillance networks.
Preliminaries
In this section, we describe the fundamental assumptions of the decay model for energy emitted by a target, the impact of obstacles on energy propagation, and the fault model. We then detail the derivation for the probability of detecting a target in a region of interest [4].
Energy Model
Consider n nodes randomly deployed in a square field at positions
{s1, s2 …
s
n
}, respectively. A target present in the field can be
a heat source (such as fire), a vehicle, or a radiological dispersion device (RDD) that can
broadcast non-fissile, but highly radioactive particles. The target may constantly be emitting a
signal, which can be measured by the nodes. The energy of the target is assumed to decay with
distance from the target. Specifically, the target energy measured by node i if the
target is at location u is modeled as

where K is the energy emitted by the target, α i (u) is the energy distortion factor due to obstacles, |u — si| is the Euclidean distance between the node and the target, l is the energy decay coefficient. Depending on the environment, the decay coefficient l is generally between 2.0 to 5.0 [22].
The function α
i
(u) characterizes energy
distortion caused by obstacles. We use a simplified model for energy distortion as illustrated in
Fig. 1. In this model, each obstacle is
characterized using two radii, r1 and r2,
with r1 ≤ r2. Given a target, a node,
and an obstacle between the target and the node, define t as the perpendicular
distance from the center of the obstacle to the line joining the node and the target. Then, the
energy distortion factor α is given as


The model for distortion factor α. PSfrag replacements: 0 < α < 1; α = 0; α = 1; r1; r2; t.
Intuitively, the model can be explained as follows. If the node lies between the two tangent lines from the target to the inner circle of radius r1 then α = 0. If the node lies outside the two tangent lines from the target to the outer circle of radius r2, then α = 1. If the node lies in the region between the inner and outer tangent lines, then α increases from 0 to 1 with the distance t — r1 Although the model simply illustrates energy absorbed by round obstacles, it can easily be extended to model other situations such as energy reflection and different shapes of obstacles. In any case, other models that can calculate the target energy strength at a given location can also be used to replace this model without loss of generality.
Measurements of the nodes are inherently corrupted by noise. Let
Impacts of faults on detection performance is contingent on both the fusion algorithm and the nodes' fault model. In this article, we cast our analysis over a typical fusion algorithm called value fusion [5], in which nodes periodically report energy measurements to a manager node to arrive at a consensus decision as to the presence or absence of the target. The manager node can be a special node with more powerful computation capability or a workstation in the control facility. We consider the crash fault model in which a faulty node does not send any measured data to the manager node. This fault model is mostly used to characterize mechanical malfunctions, destruction, and energy drainage of sensor nodes.
Detection
Based on value fusion, the manager node compares the sum of the energy measurements to a
threshold for reaching a consensus. If the sum exceeds the threshold, it decides that there is a
target. Otherwise, it decides that there is no target. More specifically, consider a target at a
position u in the region. Let Ei denote the target
energy measured by node i as described in Eq. (1), and Ni be the
noise energy measured by node i. Let


where η is the threshold for the consensus decision. If the noise that processes at the
nodes is independent, then the probability density function of the summation of

where

Given a tolerable false alarm probability, one can determine the corresponding η. In general, detection probability and false alarm probability are closely related. A higher detection probability always comes with a higher false alarm probability.
Idling target
Let I be a period of observation and nodes detect the target energy in a
periodic manner every T time units. Without loss of generality, we assume
I is divisible by T. Let

where

where Cm is the set of all possible combinations of m faults and G is the set of all grid points within the monitored region. The corresponding target position for exposure is called the exposure point.
For evaluating the exposure for a traversing target, the region is also divided into a grid. The
target is assumed to traverse from the left to the right periphery along a path P
consisting of edges between adjacent grid points. Assume that the target is not detected if and only
if it is not detected at any point on the path. Let G(P) denote
the probability that a target is not detected along the path P and

where e is a grid edge and

where ℙ is the set of all possible target paths. The corresponding path for exposure is called exposure path.
If the set of m faulty nodes is fixed, we can find the exposure path on a graph
as follows. Given m faulty nodes, assign a weight

To find the exposure is to maximize G(P), which is equivalent
to finding the minimal sum of weights on the potential path P. Further, the minimal
sum of weights can be determined by the shortest path from the left periphery to the right
periphery. To find the shortest path, create a fictitious source point
ps and a fictitious destination point pd.
Connect ps to all the grid points on the left periphery and
pd to those on the right periphery with zero weight. Find the shortest
path from ps to pd. Denote
W as the weight on the shortest path P∗. We have
W = |log G(P∗)| and
the exposure is

Figure 2 shows a procedure to find the exposure path.

The pseudo-code for searching the exposure path.
As nodes can fail at a certain rate during operation, detection performance of a surveillance
sensor network needs to be evaluated as a function of time. A commonly used relationship between
failure rate and time is the bathtub curve [23]. A similar model may apply for sensors deployed in a region. Indeed, a realistic failure
rate function should assume high failure rate during deployment, then low failure rate for a certain
period, and high failure rate again for possibly running out of battery. With nodes failing over
time, the system is said to be operational if its exposure is above a desired threshold
ed. For system maintenance, it is useful to know the probability that a
system is operational at a given time t. The probability can be derived as
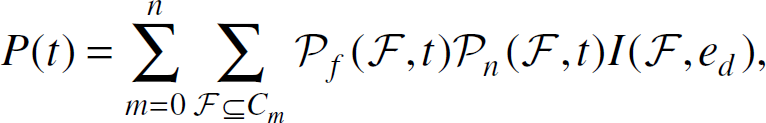
where Cm is the set of all combinations of m faults,

where ρ(t) is the probability that a node is faulty at time

where I(m, ed) is a function indicating if the system is operational in the worst-case scenario when m nodes are faulty. I(m, ed) = 1 if the worst-case exposure when m nodes are faulty is above ed. Otherwise I(m, ed) = 0.
In order to calculate Eq. (10), the worst-case fault combination with m faulty nodes and the worst-case exposure need to be determined. Specifically, the problem can be formulated as follows. Given n nodes deployed in a region to detect unauthorized targets. If m out of the n nodes are faulty, determine the worst-case combination of m faulty nodes that gives the least exposure. As the number of nodes is potentially large, it is impractical to find the worst-case fault combination by exhaustive search. Instead, efficient algorithms are required to identify the worst-case fault combinations for both idling and traversing targets in the monitored region.
Worst-case Fault Combination
Consider a sensor network with total n nodes and m of the nodes
are faulty. Assume that the noise process is AWGN with mean zero and variance one. A direct
computation of the exposure for idling targets using Eq. (6) requires one to calculate the detection
probability for all possible combinations of m faults. However, it is impractical
to check all of the
No obstacles
Consider the expression of detection probability in Eq. (4). Since
Theorem 1
Let Pm(u) be the probability of detecting a target
at position u in a decision period when the m nodes closest to
position u are faulty. The exposure is the minimum
Pm(u) over all possible target positions
u, i.e.,

Proof
Since the numbers of fault combinations and the grid points are finite, we have

We first prove that Pm(u) is the minimum probability
of detecting a target at u over all possible fault combinations. That is

From the relation between Eq.
(2) and Eq. (5),
The algorithm of finding the worst-case fault combination examines all of the grid points in the region, i.e., all possible target positions. For each grid point u, assume that the m closest nodes to u are faulty. Compute the probability of detecting a target at u using Eq. (5). The minimal detection probability over all the grid points is guaranteed to be the exposure as stated in Theorem 1, and the corresponding set of faulty nodes is the worst-case fault combination. Figure 3 lists the procedure to calculate the exposure for an idling target without obstacles.

Algorithm for calculating the exposure for an idling target with obstacles.
Note that exhaustive search for the worst-case fault combination has complexity of order
Obstacles, such as buildings or trees, are commonly present in the field. We now extend the
method to find the worst-case fault combination in the presence of obstacles. Similarly, the goal is
to identify the nodes that have the most significant impact on the detection probability. Since
energy propagation is distorted by obstacles, we cannot just use distance from the target position
to justify how much the node can contribute to the sum of target energy

Algorithm for calculating the exposure for an idling target with obstacles.
Theorem 2
Let H be the set of the m nodes with the highest energy
readings for a target at u with the presence of obstacles and
PH(u) be the probability of detecting the target in a
decision period when the nodes in H are faulty. The exposure is the minimum
PH(u) over all possible target position
u, i.e.,

Proof
Since the numbers of the fault combinations and the grid points are finite, we have

Now we prove that PH(u) is the minimum probability
of detecting a target at u over all possible fault combinations in the presence of
obstacles, i.e.,

From Eq. (2) and Eq. (5),
PF(u) is an increasing function of
In the presence of obstacles, the algorithm uses the energy detected by each node to find the worst-case fault combination rather than the distance from the target to the node.
Indeed, the case with the absence of obstacle is a special case of this algorithm. However, using the distance to determine the worst-case fault combination as shown in Fig. 3 is simpler for the cases without the presence of obstacles. The extra work in the presence of obstacles is to calculate the energy distortion factor. The complexity of the algorithm still depends on the number of grid points.
In the first simulation, we illustrate the profile of the probability of detecting an idling target in a 20 × 20 region. In order to cover the monitored region well, nodes are deployed in a 26 × 26 region. We randomly deploy 50 nodes in the enlarged region. An idling target is assumed to emit energy with K = 50 and may appear on any point (x, y) with x, y = 1, 2, …, 20. Noise is assumed to be AWGN with mean zero and variance one. The threshold η is chosen such that the false alarm probability of each detection attempt is 0.001. The manager node makes a detection decision for every 30 attempts of energy measurements. Figure 5(a) shows the profile of detection probability in the region without the presence of faulty nodes. The darker the region the lower the detection probability. The exposure point is located in (12, 0), which is relatively far from the nodes in the vicinity and is the darkest spot in the region. Figure 5(b) shows the profile of detection probability for the same deployment with the presence of three faulty nodes. The exposure point is found by the algorithm shown in Fig. 3. The exposure point moves to (14, 0). From the figure, it is clear that the position (14, 0) is the furthest point from the vicinity nodes if the closest three nodes at (16.05, −0.82), (16.79, 0.94), and (18.25, 2.33) are failed. Thus, the probability of detecting a target at (14, 0) can drop lower than that at (12, 0). In addition, the exposure drops from 0.86 to 0.53 with the presence of three faults.
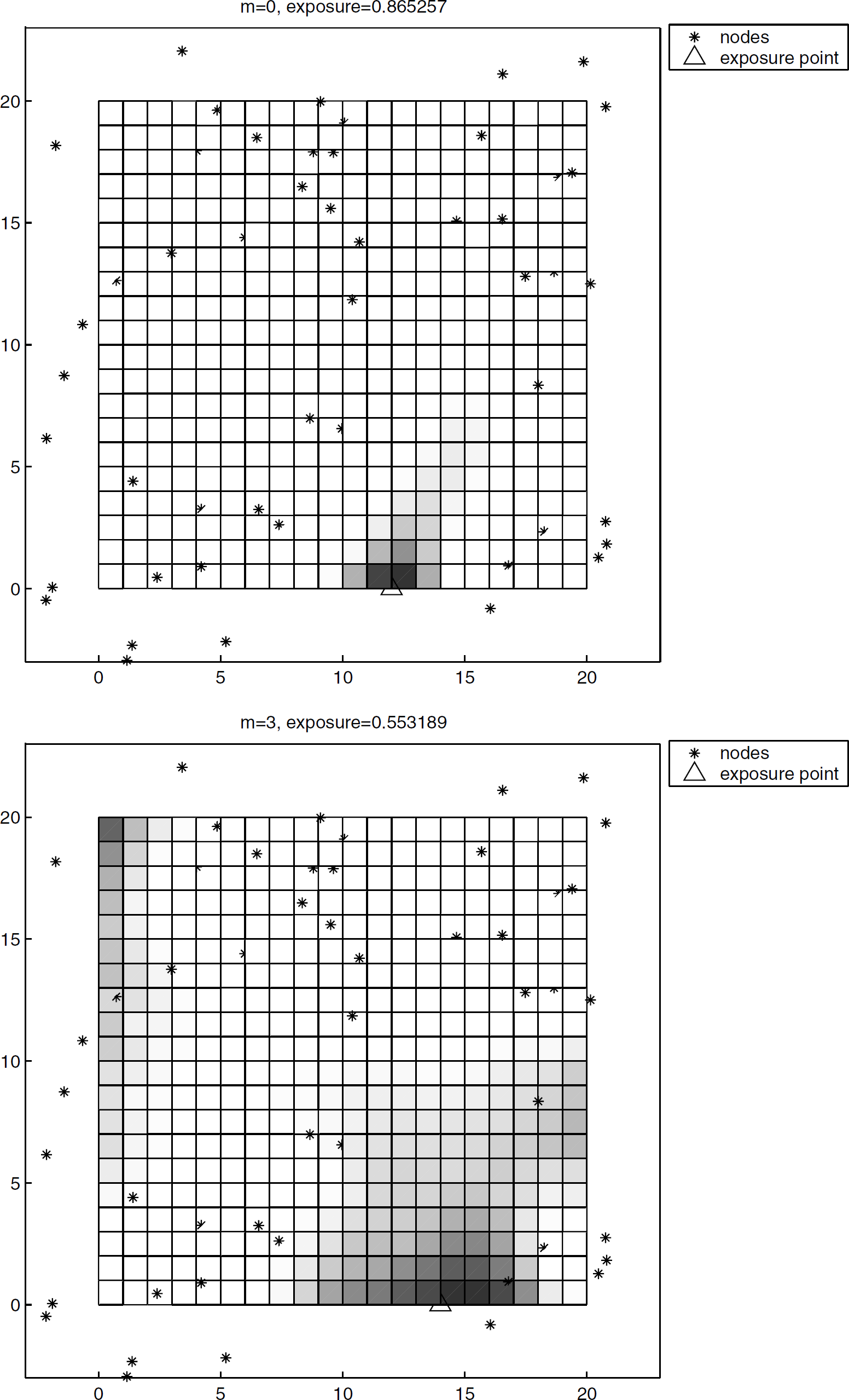
The profile of detection probability in the absence of obstacles. (a) No faults; (b) Three faults.
In the second simulation, five obstacles are placed randomly in the region. The radii r1 and r2 of the obstacles are 1 and 2 respectively. The other parameters are the same as those in the previous simulation. Figure 6(a) and 6(b) illustrate the profiles of detection probability without and with three faulty nodes respectively. With the presence of obstacles, the energy distortion must be calculated when applying the algorithm in Fig. 4 to determine the exposure point. From the figures, the exposure point is dramatically moved from (3, 10) to (4, 6) with the presence of faults. Obviously, point (4, 6) becomes a great position for the target to hide if the nodes at (2.91, 6.11), (1.19, 6.19), and (3.9, 2.21) are faulty. Moreover, the exposure drops dramatically from 0.67 to 0.13 in the presence of faults and obstacles.

The profile of detection probability in the presence of five obstacles. (a) No faults (b) Three faults.
Figure 7 shows the average impact of faults and obstacles on exposure. Each bar in the figure is an average of exposure over 100 deployments with 50 nodes. Nodes and obstacles are placed randomly and the simulation parameters are the same as the previous simulations. It is noted that η is independent of the number of obstacles but depends on the number of nodes participating in the fusion. Therefore, η must be adjusted for a different number of faulty nodes such that the comparison is based on a fixed false alarm probability. As expected, the exposure decreases with the number of faulty nodes and obstacles. On average, exposure tends to drop faster with the number of faults than the number of obstacles. However, the size, location, and the characteristic radii r1 and r2 can have different impact on the exposure.
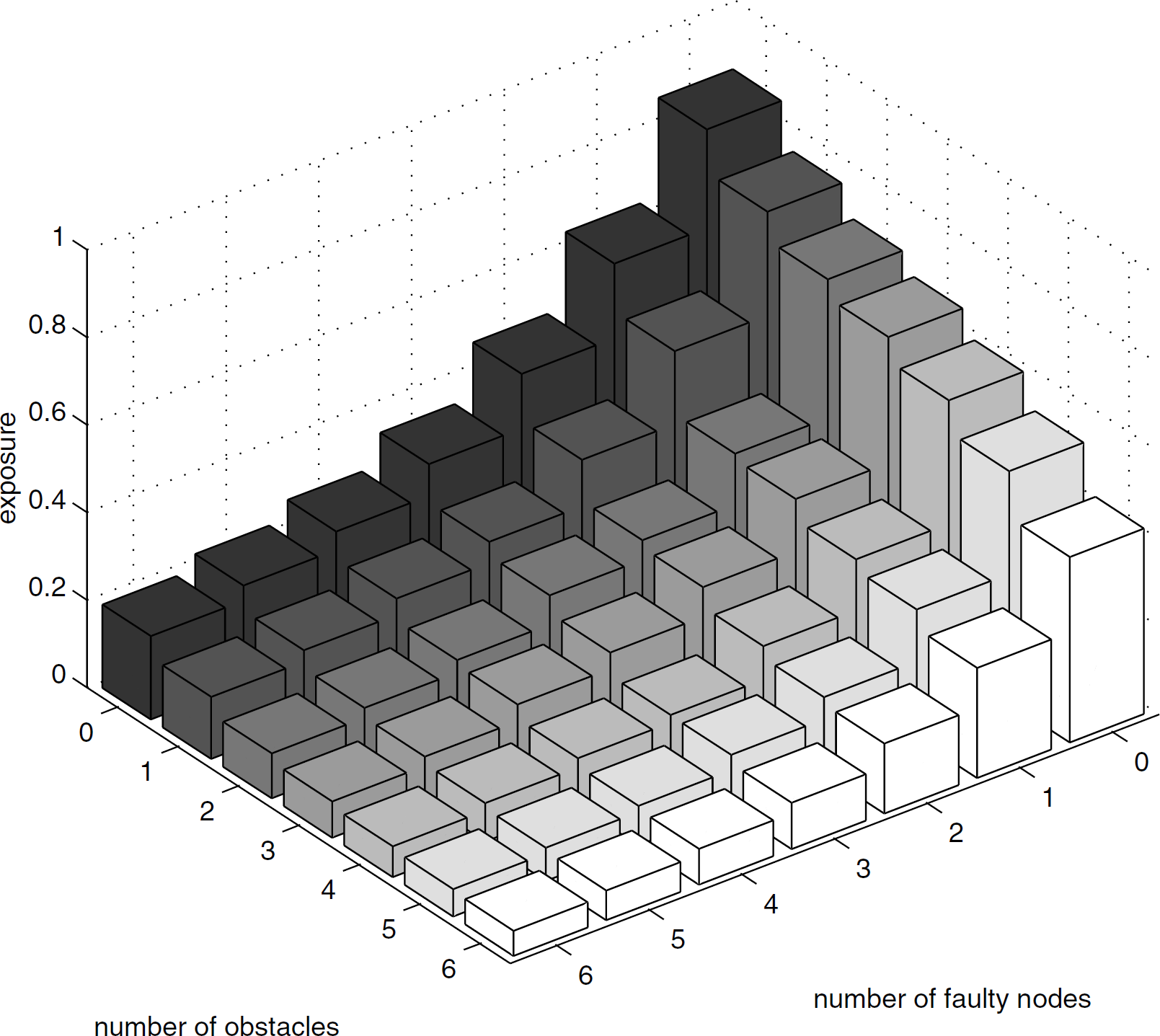
Average exposure vs number of faulty nodes and obstacles.
Worst-case Fault Combination
For target traversal, the target is assumed to move across the region from the left periphery to the right periphery with constant speed. Exposure for a traversing target is not merely a function of the distance from the target to the nodes, but associated with a series of target positions. Consequently, it is not sufficient to find the combination of faults that makes a single point poorly exposed as in the idling target case. Instead, a fault combination that makes a series of grid points hard to detect simultaneously has to be found. A first intuition for the worst-case fault combination may be the m closest nodes to the exposure path in the absence of faults. Unfortunately, this is not always the case. The exposure path in the presence of faults can be far away from the exposure path in the absence of faults.
The proposed solution is a genetic algorithm based approach that does not guarantee finding the worst-case fault combination, but has been found to be effective in a high percentage of the simulated examples. The premise of the algorithm is based on the observation that a combination of faults that intersects with the worst-case fault combination often gives lower exposure than a combination of faults that does not intersect with the worst-case fault combination. The algorithm is designed so that combinations of faults that intersect with the worst-case fault combination have a chance to be coupled to produce the worst-case fault combination.
Figure 8 lists the procedure of the
genetic algorithm based approach. Initially, the algorithm randomly generates a population of
N chromosomes. A chromosome is a fault combination with m distinct
nodes. Each chromosome is assigned a fitness value, which is defined as (1 − ϕ) where
Selection: Selects two chromosomes with probability proportional to the fitness values such that
fault combinations with low φ can be selected with high probability. Crossover: The genes (i.e., faulty nodes) in the two selected chromosomes are rotated for a
random distance in position. Then, the two chromosomes generate two children by exchanging genes
pair by pair with probability pcross. The best two chromosomes with the
highest fitness values of the four chromosomes (two parents and two children) are kept in the
population. Mutation: Through mutation, the algorithm can further diversify the population. The algorithm
randomly picks one chromosome from the population and changes each gene in the chromosome with a
very small probability pmul.

Genetic algorith for searching the least exposure path.
A copy of the overall best chromosome is recorded and the above three steps are repeated until
the stopping criterion is satisfied. Possible stopping criteria include: Stop after a specified number of fitness evaluations; Stop when the best chromosome does not change for a period of time; Stop after a specified runtime.
The algorithm is executed once at the control center after the nodes are deployed to diagnose the weakness of the surveillance system. Therefore, the genetic algorithm would not affect the operation of the detection.
We compare the fault combination found by the genetic algorithm based approach to the true worst-case fault combination found by exhaustive search. The parameters for the genetic algorithm based approach in all the following simulations are shown in Table 1 unless specified otherwise. The target is assumed to traverse across the monitored region from left to right periphery. The noise process is AWGN with mean zero and variance one. The stopping criterion used in the genetic algorithm is to stop after 10, 000 fitness evaluations. In the first simulation, we observe 100 deployments for both cases with and without obstacles in the region. In each deployment, 50 nodes are randomly placed in the deployed region. For the cases with the presence of obstacles, five obstacles are randomly placed in the deployed region. We assume that six out of the fifty nodes are faulty and use the genetic algorithm based approach to find a near worst-case fault combination and the exhaustive search to find the true worst-case fault combination.
Simulation parameters

Simulation parameters
Figure 9(a) shows the percentage of deployments in which the genetic algorithm found the optimal solution (the worst-case fault combination) during the execution. After 10, 000 fitness evaluations, the algorithm found the worst-case fault combinations in 80% of the deployments without the presence of obstacles, and in 72% of the deployments with the presence of obstacles. Furthermore, in most of the deployments, the worst-case fault combination was found within 3000 fitness evaluations. Comparing with the total 15, 890, 700 fault combinations, this is only 0.02% of the total number. This shows that the genetic algorithm can save a considerable amount of time in a large network where doing exhaustive search is impractical. In fact, for a deployment with 50 nodes, it takes about two hours to exhaustively search the worst-case fault combination with six faulty nodes on a Pentium 2.5GHz Linux machine with 1GB memory. In contrast, the genetic algorithm takes about one minute for 10, 000 fitness evaluations and finds a relatively good solution.

Comparison of the genetic algorithm and exhaustive search. (a) The fraction reaching optimal solution. (b) The average difference of exposure from optimal.
Figure 9(b) shows the average difference between the true exposure and the exposure obtained by the genetic algorithm if the worst-case fault combination is not found. Although the genetic algorithm does not guarantee to find the optimal solution, the deviation from the true exposure is not very large at the end of the execution. With and without the presence of obstacles, the average deviation is about 0.17. Note that this is only for the deployments that the worst-case fault combinations were not found and those were only 20% and 28% of the deployments in the cases without and with the presence of obstacles, respectively.
Figure 10(a) compares the average exposure obtained by the genetic algorithm based approach to a random search method without the presence of obstacles. The random search method iteratively chooses an arbitrary combination of six faulty nodes and calculates the exposure with faults for the deployment. For fair comparison, it also runs 10, 000 iterations and keeps the best solution until the end of execution. Each data point in the figure is also an average over 100 deployments. We also investigated deployments with 25, 50, and 75 nodes and assumed six of the nodes are faulty. The results are slightly different in each case and are shown in Fig. 10. For 75 nodes, exposure is high since the node density is high. Six faulty nodes is a relatively small number and is likely to have very little impact on the overall exposure no matter what fault combination is chosen. On the other hand, for 25 nodes, the exposure is already very low and there is no significant change in the exposure no matter what fault combination is chosen. In contrast, for 50 nodes, the number of nodes and the monitored region size is in some sense in a critical point such that the positions of faulty nodes can affect exposure dramatically. From the result, the genetic algorithm based approach can approach the optimal solution very quickly. Furthermore, in all three cases, the genetic algorithm based approach can find better solutions than the random search method. The results for the cases with five obstacles randomly placed in the region are shown in Fig. 10(b). Similar results are shown as in Fig. 10(a), except the exposure is lower because of the presence of obstacles in the region.

Comparison of the genetic algorithm and random search. (a) Without obstacles (b) With obstacles.
In Fig. 11, we investigate the impact
of the number of faulty nodes on the genetic algorithm based approach. We choose the typical
scenario of deploying 50 nodes randomly in each deployment and plot the average exposure over 100
deployments. In such scenarios, exposure is more sensitive to the number of faults. As expected,
exposure is lower as more nodes become faulty. However, the genetic algorithm based approach still
converges very fast within 3000 fitness evaluations for all the cases. Note that the total number of
fault combinations is

The convergence of the genetic algorithm for different number of faults. (a) Without obstacles (b) With obstacles.
Figure 12 shows the results of the genetic algorithm based approach with different number of obstacles. The results are also the average over 100 deployments with 50 nodes randomly deployed in the region and six of the nodes are assumed to be faulty. The figure shows that the exposure with ten obstacles is higher than that with five obstacles. This is because when there are a lot of obstacles in the region, a large number of paths are blocked by the obstacles. Hence, the target is easier to be detected. In contrast, if there are only a few number of obstacles, the target still has many paths to choose and the energy absorbed by obstacles makes the target harder to be detected. However, the genetic algorithm based approach still converges very fast and performs well with a different number of obstacles.

The convergence of the genetic algorithm for different number of obstacles.
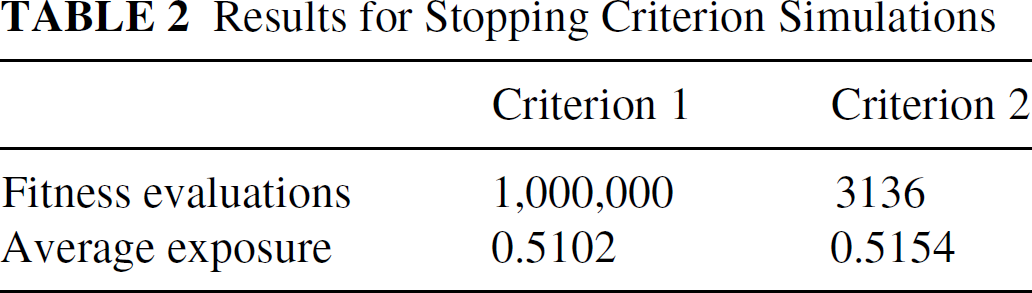
Different stopping criteria for the genetic algorithm are also examined to compare the run time and the best solution found by the genetic algorithm. The simulation parameters are the same as those in Table 1, except 150 nodes are placed in the region and the energy emitted by the target is reduced to 10. The first stopping criterion is to stop after one million fitness evaluations. We made the number large to ensure that the algorithm reaches a good solution. The second stopping criterion is to stop when the number of fitness evaluations exceeds 3000 and the best solution does not change for a period of time, which is chosen as 10% of the current number of fitness evaluations. The results are given in Table 2. The final exposure values of the two stopping criteria are almost the same, while the stopping criterion 2 needs much less number of fitness evaluations. Thus, even with a large number of nodes deployed, the genetic algorithm can stil stop very early and find a good solution using stopping criterion 2.
Results for Stopping Criterion Simulations
This paper characterizes the vulnerability of sensor networks to faults. The exposure metric for unauthorized target idling and target traversal is used to measure the quality of the deployment. Determining the worst-case fault combination is a critical issue for evaluating exposure in the presence of faults. In this paper, the worst-case fault combination for an idling target is analytically characterized and algorithms are presented to efficiently identify the worst-case fault combination with and without obstacles in the monitored region. For a traversing target, a genetic algorithm based approach is proposed to search the worst-case fault combination. Simulation results show that the genetic algorithm can find the worst-case fault combination in most cases and the convergence of the algorithm to the optimal solution is very fast in various deployment conditions. This work provides an assessable metric to evaluate the robustness of surveillance systems in the presence of faults for different target activities. Since faults are inevitable in real systems, we believe that this evaluation is important in actual sensor deployments and must be considered when deploying the nodes.