
Abstract
Over the past decades, great progress has been made in clinical as well as experimental stroke research. Disappointingly, however, hundreds of clinical trials testing neuroprotective agents have failed despite efficacy in experimental models. Recently, several systematic reviews have exposed a number of important deficits in the quality of preclinical stroke research. Many of the issues raised in these reviews are not specific to experimental stroke research, but apply to studies of animal models of disease in general. It is the aim of this article to review some quality-related sources of bias with a particular focus on experimental stroke research. Weaknesses discussed include, among others, low statistical power and hence reproducibility, defects in statistical analysis, lack of blinding and randomization, lack of quality-control mechanisms, deficiencies in reporting, and negative publication bias. Although quantitative evidence for quality problems at present is restricted to preclinical stroke research, to spur discussion and in the hope that they will be exposed to meta-analysis in the near future, I have also included some quality-related sources of bias, which have not been systematically studied. Importantly, these may be also relevant to mechanism-driven basic stroke research. I propose that by a number of rather simple measures reproducibility of experimental results, as well as the step from bench to bedside in stroke research may be made more successful. However, the ultimate proof for this has to await successful phase III stroke trials, which were built on basic research conforming to the criteria as put forward in this article.
Keywords
Introduction
Over the past decades, great progress has been made in the prevention, diagnosis, and treatment of stroke (Cheng et al, 2004; Ward and Cohen, 2004; del Zoppo, 2004). At the same time, by modeling of stroke in animal experiments, our understanding of the pathophysiologic mechanisms by which focal cerebral ischemia kills brain cells has greatly improved (Lo et al, 2003; Dirnagl et al, 1999). In addition, experimental stroke studies have identified numerous therapeutic targets for stroke therapy (Dirnagl et al, 2003; Meisel et al, 2005; Endres, 2005; Lo et al, 2005; Lindvall and Kokaia, 2004). However, it is an overall failure to validate the efficacy of such treatment strategies, which is fuelling a debate concerning the general predictive value of experimental modeling of this complex disorder (Hoyte et al, 2004; Fisher and Tatlisumak, 2005; Kaste, 2005). Much of the discussion on why bench results get ‘lost in translation’ to the bedside has focused on issues such as species differences, side effects, hetereogeneity of strokes in humans, etc. (see below). Nevertheless, quality issues in experimental research that may impact on bench to bedside translation have recently been raised by a number of authors (Heard et al, 2005; Bebarta et al, 2003; Pound et al, 2004; Samsa and Matchar, 2001). More specifically, systematic reviews of experimental stroke research have exposed a number of important deficits in the quality of preclinical experimental stroke research, and a negative correlation between measured effect sizes and quality scores was demonstrated (see below, and Table 1). The discussion has been further sparked by research, which provocatively predicts that most published research findings are ʻfalseʼ (Ioannidis, 2005), and that quality issues are important reasons for this shocking finding. In this article, I would like to explore whether translational experimental stroke research is affected by quality problems. The purpose of my critical approach is not to denounce experimental stroke research, but to initiate a discussion geared at improving the translation of basic research into successful clinical stroke therapy. It is important to note that animal experiments in other areas of medicine, such as neurosurgery (Heard et al, 2005), cardiology (Lee et al, 2003), cancer (Clarke, 1997), or intensive care (Bebarta et al, 2003; Roberts et al, 2002), are affected by similar quality issues (Pound et al, 2004). In addition, I would like to stress that quality issues are but one factor that may impact on the success of bench to bedside translation in stroke research: validity of models, species issues, clinical trial design, among many others, may be equally or even more relevant determinants.
Overview of available quality score data from systematic reviews
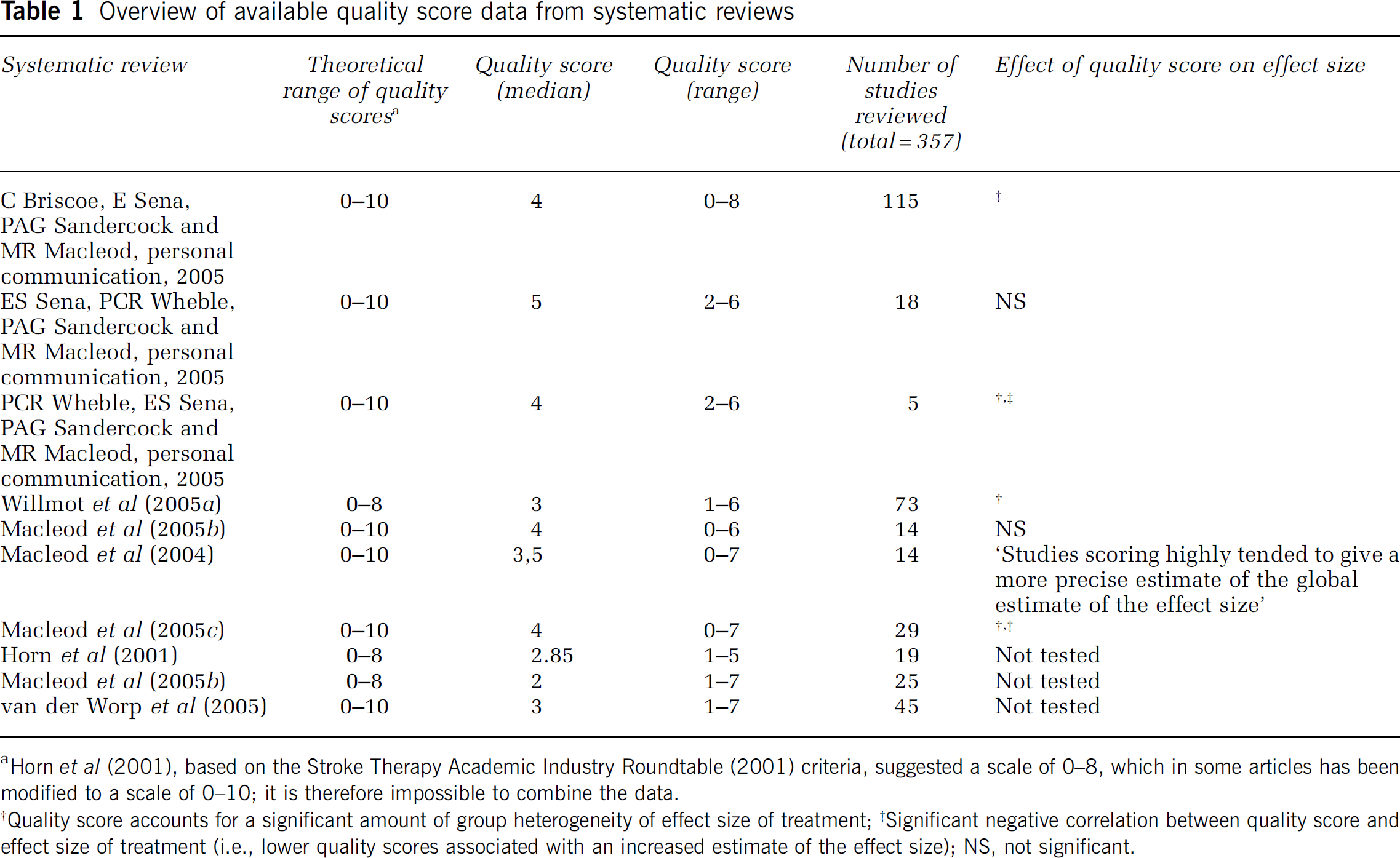
Horn et al (2001), based on the Stroke Therapy Academic Industry Roundtable (2001) criteria, suggested a scale of 0–8, which in some articles has been modified to a scale of 0–10; it is therefore impossible to combine the data.
Quality score accounts for a significant amount of group heterogeneity of effect size of treatment;‡Significant negative correlation between quality score and effect size of treatment (i.e., lower quality scores associated with an increased estimate of the effect size); NS, not significant.
In this article, I will concentrate on ʻexperimental stroke researchʼ, by which I refer to animal experiments, which test the effect of a physical, pharmacological, or genetic manipulation on outcome after an experimentally induced stroke. Experimental stroke research spans from explorative, basic science into disease mechanisms, to preclinical studies geared at informing companies and clinicians as to whether a compound, diagnostic or therapeutic principle, should be investigated in phase I/II clinical trial. As basic and preclinical stroke research have different aims and designs, some quality matters discussed here may have different impact on both types of studies. Where necessary, I will therefore point out the specific relevance of quality issues to basic and preclinical research (Table 2 and Table 3). Issues like choice of species, modeling of age, and complicating diseases, etc., are almost exclusively relevant to preclinical stroke research (see below) and have been discussed a number of times previously (most prominently: STAIR, Stroke Therapy Academic Industry Roundtable, 1999), and they will therefore only be mentioned in passing.
Summary of potential weaknesses in experimental stroke studies and relative relevance to mechanism-driven basic stroke research versus preclinical stroke research
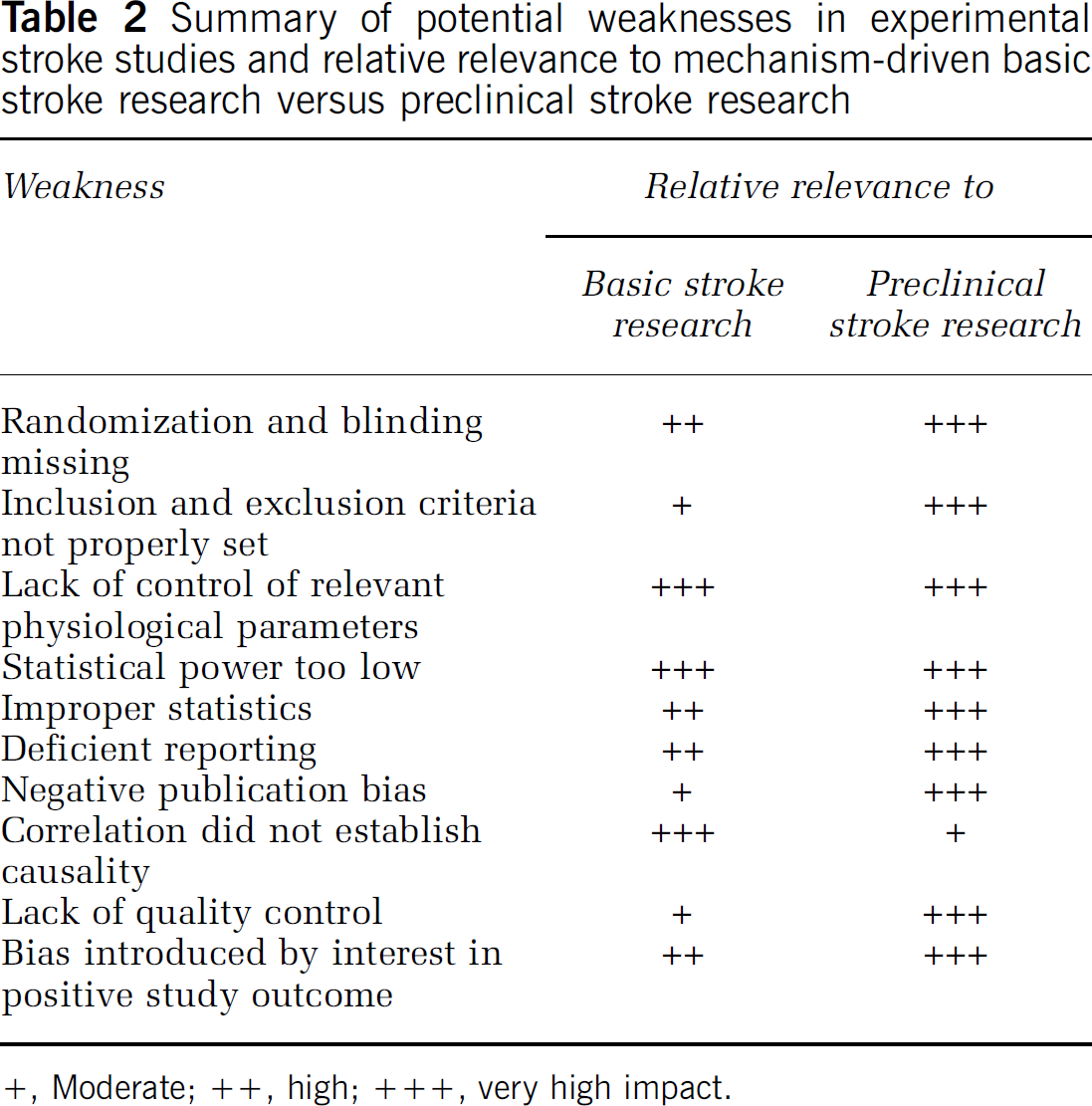
+, Moderate; ++, high; +++, very high impact.
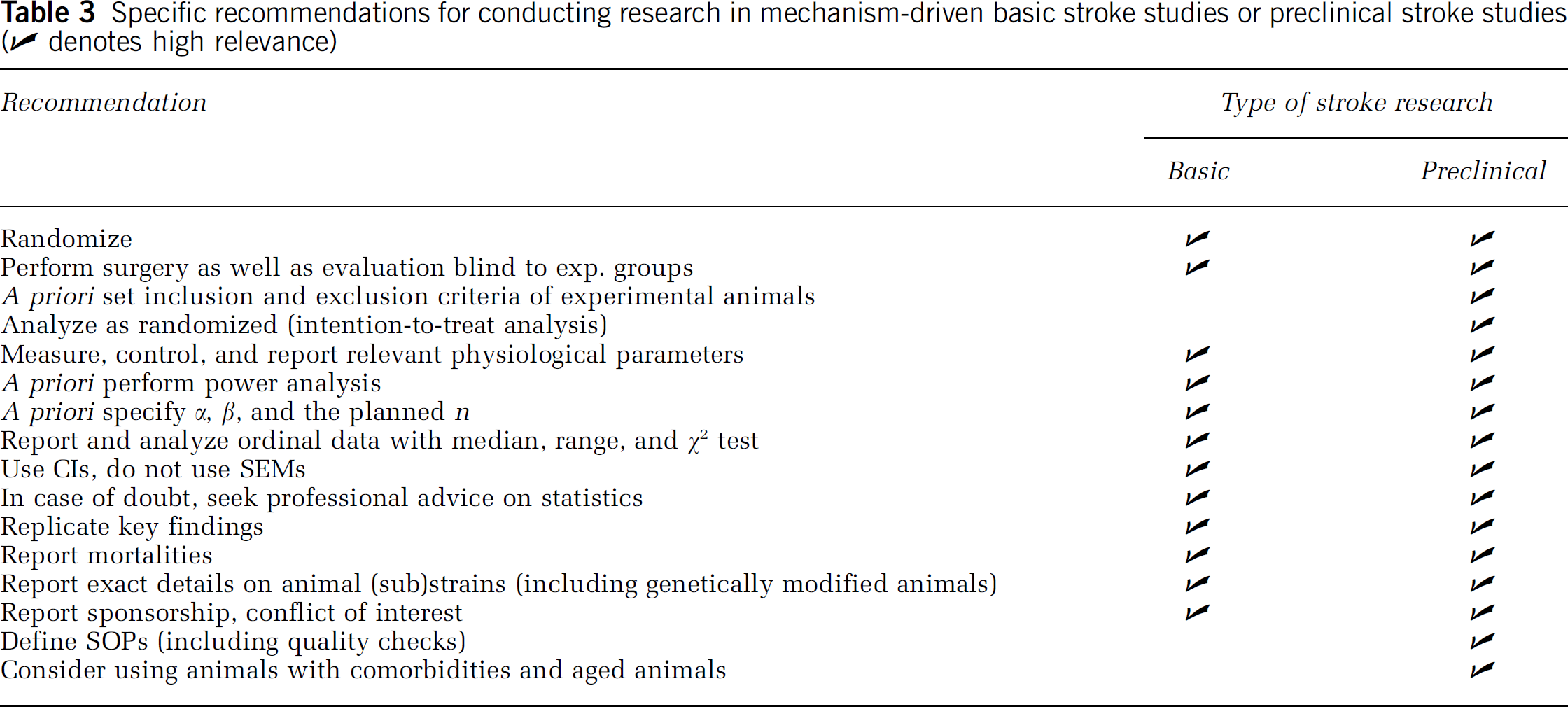
Specific recommendations for conducting research in mechanism-driven basic stroke studies or preclinical stroke studies (✔ denotes high relevance)
Decades of Progress in the Diagnosis and Treatment of Acute Stroke
Although effective pharmacological neuroprotection (or rather ʻbrain protectionʼ) is still unavailable for the treatment of patients with acute stroke, stroke diagnosis and therapy have made major progress over the past decades. Importantly, the demonstrated efficacy of recanalization within 3 h of the focally ischemic brain region via thrombolysis by recombinant tissue plasminogen activator was a major breakthrough in clinical medicine (Hacke et al, 1995; The National Institute of Neurological Disorders and Stroke rt-PA Stroke Study Group, 1995). In parallel to the establishment of this first pharmacological treatment of acute stroke, the ʻtime is brainʼ concept has emerged, and has led to significant improvements in the infrastructure of acute stroke care. In particular, stroke is now regarded as a treatable medical emergency by the general public, the emergency medical system, as well as physicians, with a resultant decrease in the time lag between symptom onset and initiation of treatment (Evenson et al, 2001; Hill et al, 2000). As a result of this concept of acute stroke as a treatable disease with a very short therapeutic window, a network of dedicated stroke units has been established in many countries. A clear therapeutic benefit of stroke units has been demonstrated (Langhorne and Dennis, 2004; Alberts et al, 2005; Stroke Unit Trialists' Collaboration, 1997; Indredavik et al, 1999; Drummond et al, 2005). Advanced diagnostic imaging of stroke is now widely available, and includes early measures of damage (DWI) as well as blood perfusion (magnetic resonance (MR)-angiography, MR perfusion, computed tomography perfusion; Warach, 2003; Hjort et al, 2005). In addition, stroke trial design has come of age. In particular, the study designs of randomized clinical trials (RCTs) have been refined with regards to patient selection and trial size, outcome measures and follow-up, as well as statistical analysis (Lees et al, 2003; Krams et al, 2005). All these improvements taken together have created an environment that is highly amenable for the successful establishment of pharmacological brain protection in acute stroke.
Decades of Progress in Basic Stroke Pathophysiology
These impressive achievements in clinical stroke research and therapy were accompanied by two decades of tremendous progress in basic stroke research. Robust animal models for ischemic stroke are now available. They may not faithfully reflect the pathophysiologic process, which leads to a stroke, but most researchers agree that they are suited to study the pathobiology that leads to tissue damage once a major brain vessel is occluded (Mergenthaler et al, 2004; Hossmann, 2004; Liang et al, 2004; Richard et al, 2003; Fukuda and del Zoppo, 2003; Traystman, 2003; Endres and Dirnagl, 2002; Leker and Constantini, 2002). Research on animal models of stroke, but also on cultured brain cells and tissues, has led to a basic understanding of how focal substrate deprivation kills brain cells (Dirnagl et al, 1999). In addition, we have learned that the brain mounts an endogenous protective response to reduce the deleterious effects of substrate deprivation (Dirnagl et al, 2003). Understanding such endogenous neuroprotective mechanisms has led to novel strategies of therapeutic brain protection. Although numerous questions with regard to this complex pathophysiology remain unanswered, and a plethora of cellular and molecular mechanisms remain to be explored, many promising therapeutic targets have been found. Experimentally induced acute stroke of the rodent is a treatable disease, as typical outcomes in experimental stroke studies have shown reductions in infarct size and improvements in neurologic outcome of 50% or more (see below). Although traditionally experimental stroke research has focused on early mechanisms of damage, only recently a surprising capacity of the central nervous system CNS) for regeneration and plasticity has been dentified, raising the hopes of developing therapeutic approaches based on these findings (Chen et al, 2002; Lindvall and Kokaia, 2004; Savitz et al, 2004, 2002; Roitberg, 2004; Chopp and Li, 2002). Further progress in the field has come from a recent remendous expansion of the methodological portfolio of experimental stroke research, ranging from genome-wide transcriptional and protein expression screens (Carmichael, 2003; Hubner et al, 2005), to the targeted deletion or overexpression of candidate genes (Liang et al, 2004), to sophisticated high-resolution in vivo imaging (Dijkhuizen and Nicolay, 2003).
Lost in Translation?
Surprisingly, these exciting developments in basic and clinical stroke research occurred in parallel, with too little direct translation between bench and bedside. Pharmacological brain protection, which has been a major focus of and a reality in experimental models of stroke for 20 years, is not available to stroke patients, despite hundreds of phase II and III clinical studies and billions of dollars spent in these trials (for an overview, see Washington University Internet Stroke Center, URL in Table 4). It is important to stress that there is no principal barrier for bench to bedside translation in the stroke field. Two key concepts, which were developed in in vivo models of cerebral ischemia, successfully found their way into clinical practice: the concept of the ischemic penumbra (Astrup et al, 1977; Symon et al, 1975) and fibrinolysis in acute ischemic stroke (Zivin et al, 1985) were developed in animal models of cerebral ischemia, and are now the cornerstones of diagnosis and treatment of stroke (The National Institute of Neurological Disorders and Stroke rt-PA Stroke Study Group, 1995; Fisher, 2004; Kidwell et al, 2003).
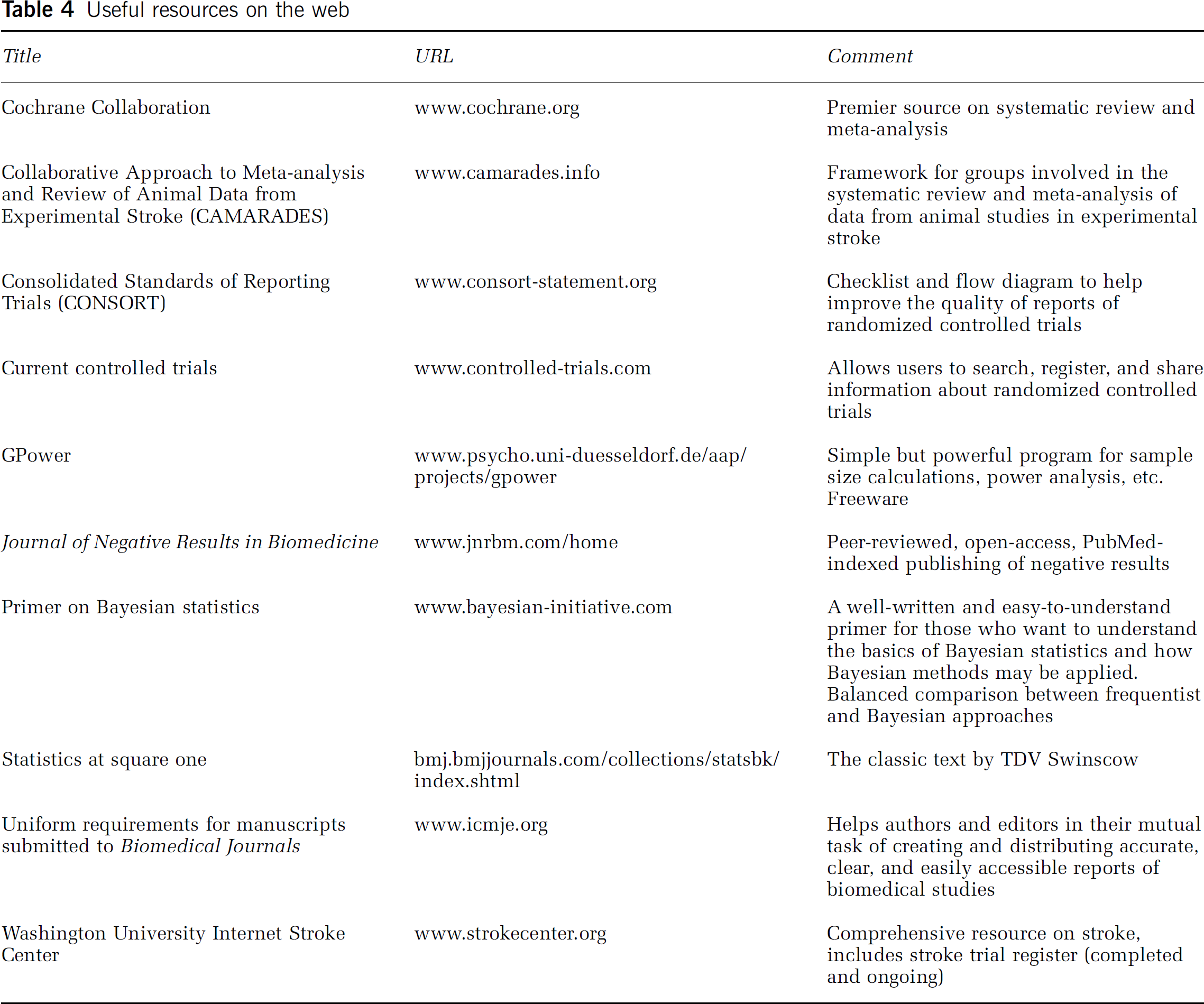
Useful resources on the web
Many highly cited articles (Dirnagl et al, 1999; Wahlgren and Ahmed, 2004; DeGraba and Pettigrew, 2000; del Zoppo, 1998; Danton and Dietrich, 2004; Curry, 2003; Green, 2002) and expert symposia, most importantly the Stroke Therapy Academic Industry Roundtable (STAIR, Stroke Therapy Academic Industry Roundtable, 1999), have tried to explain this striking lack of success of bench to bedside translation in the stroke field. High up on the list of potential reasons explaining this apparent ‘loss in translation’ are species differences, inappropriate time windows of treatment, effective drug levels not achievable in humans because of toxicity, use of young animals without comorbidity, failure to model white matter damage and protect axons, incongruent end points (infarct size in animal experiments versus neurologic outcome in clinical trials), hetereogeneity of stroke subtypes in patients, unrealistic expectation of effect size and false negatives because of a lack of statistical power in clinical trials, among others.
Surprisingly, a potential contributor to the apparent gap between bench and bedside results has only received very little attention: that quality problems in some of the basic research or preclinical studies on which clinical trials were based may have led to false-positive results, inflated effect sizes, and marginal reproducibility. Several authors have mentioned this possibility (Heard et al, 2005; Pound et al, 2004), and recent systematic reviews (Table 1) have found quantitative evidence for it in preclinical stroke research. However, the subject was never addressed comprehensively.
A Provocative Hypothesis
I propose that a relevant fraction of experimental stroke studies are affected by quality problems, and that this, among several other factors, may negatively impact successful bench to bedside translation. I further propose that by a joint effort of scientists and journal editors, this problem can be corrected. In the following, I will discuss the most common and important quality problems in this field, illustrated by examples on how they impact on study results (overview in Table 2). My hypothesis is mainly based on systematic reviews of preclinical stroke research in which a ‘quality score’ was applied (C Briscoe, E Sena, PAG Sandercock and MR Macleod, personal communication, 2005; ES Sena, PCR Wheble, PAG Sandercock and MR Macleod, personal communication, 2005; PCR Wheble, ES Sena, PAG Sandercock and MR Macleod, personal communication, 2005; Willmot et al, 2005b; Macleod et al, 2004, 2005b, c , d ; Horn et al, 2001). As the existing systematic reviews have a limited coverage of published experimental stroke studies, and as such quality scores represent a rather coarse measure, which does not include a number of potentially relevant aspects of ʻqualityʼ, and are therefore subject to criticism (see below), I will also raise some issues which have not been systematically reviewed so far. In these cases, quantitative evidence is lacking that they indeed significantly affect the effect sizes or general outcomes of experimental stroke studies. The purpose of this approach is to generate a framework for the improvement of quality scales, and to promote systematic studies into the effects of these potential determinants of quality and hence outcome in preclinical as well as basic stroke research.
Quantification of Methodological Quality in Preclinical Stroke Studies
Following the quality criteria of the STAIR recommendations (Stroke Therapy Academic Industry Roundtable, 1999), Horn et al (2001), were the first to analyze methodological quality of preclinical experimental stroke studies in a systematic review. In their rating scale (possible total score of 8), points are attributed for (1) the dose/response relationship that was investigated, (2) randomization of the experiment, (3) optimal time window of the treatment investigated, (4) monitoring of physiologic parameters, (5) masked outcome assessment, (6) assessment of at least two outcomes (infarct size and functional outcome), (7) outcome assessment in the acute phase (1 to 3 days), and (8) outcome assessment in the chronic phase (7 to 30 days). Macleod et al (2004) have further refined this scale by giving one point (possible total score of 10) each for (1) peer—reviewed publication, (2) statement of control of temperature, (3) random allocation to treatment or control; (4) masked induction of ischemia; (5) masked assessment of outcome, (6) use of anesthetic without significant intrinsic neuroprotective activity, (7) appropriate animal model (aged, diabetic, or hypertensive), (8) sample size calculation, (9) compliance with animal welfare regulations, and (10) statement of potential conflict of interests. Further modifications of these scores exist (van der Worp et al, 2005).
These authors should be commended for approaching the issue of methodological quality in a quantitative manner. However, the ordinal data from such scales have to be interpreted with great caution. For example, does random allocation to experimental groups have the same implications with regard to methodological quality as compliance with animal welfare? Further, only binary decisions are possible in each category: the use of an aged hypertensive animal thus gives the same score as the use of an aged one. Power calculation per se is rewarded with one point, regardless of its result, etc. As will be shown below, a number of additional indicators for methodological quality can be identified (e.g., flaws in statistics, reporting, study interpretation, etc.), which are not scored in the presently used systems.
Notwithstanding the limitations of quality scores, the fact that the median quality scores of 357 preclinical stroke studies systematically reviewed in 10 articles were 50% or less of the maximum score is per se alarming. Horn et al (2001) qualified studies scoring below 50% as ʻof poor methodological qualityʼ. Importantly, many of these meta-analyses were able to show that the quality score accounted for a significant amount of group heterogeneity of effect size of treatment, and/or that there was a statistically significant negative correlation between quality score and effect size of treatment. In other words, lower quality scores were associated with an increased estimate of the effect size.
It should be noted here that the scores discussed above were developed to assess methodological quality of preclinical studies. For example, it is certainly not a sign of low quality if a basic research study identifies a mechanism or a novel therapeutic target, but does so only in adolescent animals, and not in aged ones. However, some of the ʻqualityʼ ratings may also be applied to basic research (e.g., randomization, monitoring of physiologic parameters, statistics, etc.). I propose that specific scales should be developed for the systematic review of mechanism-driven explanatory studies.
As quantitative indicators from systematic reviews point to defects in methodological quality in preclinical stroke research, I would like to now explore this issue in greater detail by scrutinizing the relevant methodological aspects that collectively determine the ‘quality’ of a study. I will expand my discussion to include aspects relevant for basic stroke research.
Study Design
Wherever systematically studied, it has been quantitatively shown that experimental studies that violate standards of study design (Festing, 2003, 2006; Johnson and Besselsen, 2002), such as randomization and blinding (see below), are more likely to report differences between study groups (Bebarta et al, 2003; Lee et al, 2003). It appears to be common practice to start testing a compound without a priori setting an effect size that will be considered biologically meaningful, and without accordingly calculating the necessary numbers of animals (see below). It is very rare that detailed protocols are specified. It appears that often without consideration of statistical power between 6 and 12 animals per group are investigated, and a P-value (usually 0.05) is used to determine the biologic relevance of the findings. In the following, I will discuss several study design issues in more detail.
Randomization
In a systematic review by Bart van der Worp et al (2005), only 42% of 45 analyzed experimental stroke studies reported randomized treatment allocation. It appears trivial that random allocation to the various experimental groups is a mandatory exercise. Randomization is necessary to exclude systematic errors of sampling. These may arise, for example, if one batch of animals is affected by an undetected infection, or if the experimenter on a ‘bad day’ only operates control animals, or if the surgeon is trained while operating the control animals, and investigates the treatment group once the technique is mastered. For all these reasons, it is unacceptable to use historical controls in stroke research.
Blinding
As with randomization, blinding is reported only in a fraction of experimental stroke studies: in one systematic review (van der Worp et al, 2005), only 22% of 45 studies analyzed administered study medication in a masked manner. We have to accept that investigators are biased towards the outcomes of their experiments, which necessitates an outcome assessment, which is blind to the experimental groups. In addition, surgery should be performed without prior knowledge to which experimental group the animal belongs (e.g., an mutant mouse), or will be randomized (in a drug trial). For obvious reasons, double-blind protocols, in which the subject under study is unaware to which group it belongs, are neither feasible nor necessary in animal experiments. Interestingly, however, double-blind animal stroke studies have been published (Germano et al, 1987; Xu et al, 2005), raising concerns about the review process (see below).
Inclusion and Exclusion Criteria
Only a negligible minority of experimental stroke studies report a priori criteria for inclusion or exclusion of animals. It is reasonable to assume that even with highly skilled surgeons, practically all middle cerebral artery occlusion (MCAO) models have at least some mortality (approx. 5%). It is therefore distressing that many experimental stroke studies do not report mortalities (27% of the analyzed studies in van der Worp et al (2005)). Why is it important to a priori set and report such criteria, as well as publish how the experimental cohorts were stratified accordingly? A strong bias can be introduced by exclusion of certain animals after randomization, such as those that did show no or ‘unexpectedly small’ infarcts, or had ‘unphysiologic’ blood gases or systemic arterial pressures. Even such a ‘clear’ exclusion criterion as death of the animal before reaching end-point evaluation may pose problems: a putative neuroprotectant X may be toxic (e.g., respiratory depressant), but without any direct effect on infarct size. Because of the differences in vascular collaterals, among other factors, MCAO produces quite heterogeneous infarcts and neurologic outcomes in individual rodents. A scenario can be envisioned, in which compound X kills only animals that are most severely affected by MCAO (as they are already struggling to survive), whereas animals with minor damage are able to survive and will be evaluated for outcome. Thus, the surviving treated animals have been selected for smaller infarcts, and the toxic compound X appears as effective as a neuroprotectant!
Control of Relevant Physiologic Parameters
In 1990, Buchan and Pulsinelli explained the neuroprotective effect of the N-methyl-D-aspartate receptor blocker MK-801 in a model of global cerebral ischemia with its effect on postischemic body (and thus brain) temperature (Buchan and Pulsinelli, 1990). This is probably the most prominent example in which the effects of an experimental manipulation (e.g., a drug, or a genetic manipulation) were explained by its effect on a systemic variable (such as blood pressure, or temperature), or on cerebral blood flow, and not by a direct neuroprotective effect. In the last decade of the 20th century, therefore, great emphasis was put by researchers, reviewers, and editors on demonstrating the (lack of) effect of the mechanistic manipulation under study on such variables. In parallel to a proliferation of studies in (genetically modified) mice, in which physiologic monitoring is much more demanding and less reliable than in larger rodents, the emphasis on proper monitoring and control of physiologic parameters (including cerebral blood flow) has clearly diminished. There is no formal proof that this has significantly affected experimental stroke research, but this trend should be closely monitored, and its effects investigated.
Statistics
Scholarly journals like Stroke or the Journal of Cerebral Blood Flow no longer feature statistical consultants on their editorial boards, and statisticians no longer partake in the scientific discourse (Ford, 1983). In addition, instructions for authors do not mention statistics, let alone specific statistical requirements or standards. In contrast, some experimental (e.g., American Physiological Society, 2005) and eminent clinical journals like The New England Journal of Medicine, The British Medical Journal, or The Lancet publish extensive and specific guidelines for acceptable statistical procedures, as proposed by the ʻUniform Requirements for Manuscripts Submitted to Biomedical Journals: Writing and Editing for Biomedical Publication (URL see Table 4). This apparent lack of attention to statistics is distressing, as it is not uncommon to find violations of statistical standards in published papers in experimental stroke research.
As statistical power, or the lack thereof, is one of the most common statistical problems encountered in experimental stroke studies, I will focus on this issue first. When experimental stroke studies report negative results, it is very rare to find mention of a priori power analysis or the effect size that could have been detected given the variance of the data and the preset levels for α (risk of committing a type I error, or false positive) and β (risk of committing a type II error, or false negative, (Sterne and Davey, 2001; Mulaik et al, 1997) (Table 1). van der Worp et al (2005), in a systematic review of 45 experimental stroke studies, identified only one study that performed power analysis.
This is particularly distressing, as it appears to be unknown to most researchers that statistical power is not only an issue when the null hypothesis was not rejected (i.e., no difference was found between experimental groups at a given α). When the null hypothesis is in fact false (the drug really works, the knockout mouse has a phenotype, etc.), the overall error rate is not the α level, but the type II error rate β (Schmidt and Hunter, 1997). It is impossible to falsely conclude that the null hypothesis is false, when in fact it is false! This apparently trivial insight may have important consequences for the interpretation of experimental data, and ultimately for its translation to the patient: If β is high (i.e., statistical power is low: power = 1–β), the probability to be able to reproduce data becomes small. For example, at a power of 0.5, which is not uncommon in experimental stroke research (see below), the probability to be able to replicate the findings of a study is 50%, equivalent to throwing a coin (Mulaik et al, 1997)!
Is this relevant to experimental stroke studies? Many ʻstatistically significantʼ experimental stroke studies find reductions in infarct size of around 40%, have standard deviations of about 40% of the mean, group sizes of approximately 10 (van der Worp et al, 2005), and accept P < 0.05 as statistically significant. In the above scenario, statistical power is 0.56! As no systematic review of power in experimental stroke studies exists, and to test whether this is a realistic estimate, I randomly sampled 30 preclinical as well as basic experimental stroke studies published in 2004 or 2005 in Stroke and the Journal of Cerebral Blood Flow and Metabolism and calculated post hoc their statistical power in analyzing infarct volumes. The mean β of this sample was 0.58 (95% confidence interval (CI) 0.49 to 0.63).
Unfortunately, lack of power is not the only statistical flaw found in some experimental stroke studies. A list of such defects includes: lack of correction for multiple comparisons; reporting of ordinal variables (e.g., from histologic or neuro-behavioral scores) with standard error of the mean (s.e.m.) or standard deviations (s.d.) (instead of median and range), and statistical comparisons of these values with a t-test (instead of a χ2 test). The majority of experimental stroke studies describe numerical data as means + s.e.m.ʼs instead of s.d.ʼs. This promotes ʻniceʼ graphical displays but obscures the (large) variance of the data. The s.e.m. is a measure of precision of an estimate of a population parameter. In other words, it tells us how accurately we can estimate the mean. However, what we usually want to be informed about is the variability of the observations, which is given by the s.d. Statisticians have fought for decades to ban the use of s.e.m.ʼs (and with less fervor, even of s.d.ʼs) for reporting numerical biomedical data, and instead advocated the use of CIs (Reichhardt and Gollob, 1997; Gardner and Altman, 1995).
Another prevalent statistical misconception is that P-values indicate biologic significance (Cohen, 1997; Sterne and Davey, 2001; Greenwald et al, 1996). This has contributed to the popularity of null-hypothesis testing in biomedical research, and may have sometimes clouded a more (neuro)biologically driven interpretation of the data.
Reporting
That deficits in reporting can affect the outcome of a study has been shown by many studies (Sutton et al, 2000; Chan and Altman, 2005a, Chan and Altman, 2005b; Chan et al, 2004; Kyzas et al, 2005). Interestingly, no clear standards exist for the reporting of experimental data. This is in sharp contrast to the publication of RCTs, where international guidelines exist (CONSORT; Moher et al, 2001): failure to adhere to these guidelines leads to automatic rejection of a manuscript. Potentially as a consequence of missing standards, the following deficiencies can be found in some experimental stroke studies: failure to report mortality, no numerical values given (only graphs), (sub)strain information lacking, no information on sponsorship, conflict of interest, etc. In the early days of research with genetically modified animals, issues of genetic background (e.g., flanking gene problem or genetic drift; (Wolfer et al, 2002) were widely discussed (Picciotto and Wickman, 1998; Majzoub and Muglia, 1996; Aguzzi et al, 1996), and details on strains, source, and generation of animals, etc., were reported in sufficient detail in most publications. Today, however, crucial information is missing in many articles, and it is not rare that even the source and background of the genetically modified animal is not reported.
Negative Publication Bias
Studies that do not show an effect of a compound on outcome after a stroke, or find no stroke phenotype of a mouse with a null mutation, are considered ʻnegativeʼ. This label already reveals the negative bias towards such study outcomes. This results in the practical problem that it is very hard to publish negative study results. The so-called ʻnegative publication bias' is well known, and leads to a skewed view on the effects of drugs and mechanisms alike: conflicting, that is, negative findings, may exist, but they are not accessible to the scientific community. Negative publication bias can therefore strongly affect the overall quality of research in a given field. An effect of publication bias in experimental stroke research has already been shown (Macleod et al, 2004). Even in clinical research, where the publication of negative results is easier and more common than in experimental research, negative publication bias exists, and its negative consequences have been intensely documented (Veitch, 2005; Hayashino et al, 2005; Demaria, 2004; Phillips, 2004).
Study Interpretation: Correlation Does Not Establish Causality
Experimental stroke researchers apply mechanistic manipulations (pharmacology, genetically modified animals) to modify infarct volume. With a reduction in the amount of damaged brain tissue, secondary pathophysiologic events are also reduced. In this situation, it is hard to discriminate whether a mechanism that covaries with lesion size, is a causal agent of tissue damage, or an epiphenomenon. A good example for this problem (which is a pitfall in the interpretation of study data in any scientific field) is the investigation into the effects of mechanisms and compounds which, among other effects, may reduce stroke-induced inflammation (Emerich et al, 2002).
How Can We Improve Quality In Experimental Research?
For the individual researcher planning and conducting experimental stroke studies, it is easy to improve quality. Many of the quality problems discussed above are easily overcome, particularly the one's listed under study design, reporting, and study interpretation (overview in Table 3). In theory, it is also easy to deal with the statistical power issue: a biologically relevant effect size should be set based on pathophysiologic and clinical reasoning. Then error levels for α and β are chosen (e.g., 0.05 and 0.2). By estimating the variance of the data, the necessary number of animals for this design can then be calculated. To reiterate, this should be performed a priori, that is, before starting the study. As outcome data of experimental stroke studies often have a high variance, the numbers of animals needed to achieve acceptable β-values may necessitate group sizes larger than what is common practice. For the typical stroke study mentioned above (effect size and standard deviation around 40% of the mean), a priori sample size calculation for ã < 0.05 and β < 0.2 suggests a total n of 34 (17 control, 17 treatment). It should be stressed here, however, that power calculations should play no role once the data has been collected (Goodman and Berlin, 1994). Instead, ʻnullʼ results should be presented using CIs (see also below) around parameters such as the differences between means and effect sizes. This allows for conclusions about how far the population parameter could reasonably deviate from the value in the null hypothesis (Aberson, 2002).
In addition to using appropriately powered designs, replication of results should be considered (Dirnagl et al, 1990) before using data as a foundation for an extensive mechanistic investigation of the effect, which may not be reproducible, or the planning of a clinical study based on the experimental results.
Although beyond the scope of this article, I strongly believe that a more profound discussion of the use of statistics would benefit the field. This discussion could lead to a more critical and responsible use of null hypothesis testing and classical (ʻfrequentistʼ) statistics (Cohen, 1997; Greenwald et al, 1996), and potentially to the introduction of Bayesian approaches in the planning and evaluation of experimental stroke studies (O'Hagan and Luce, 2003). For a specific data set and specific hypothesis (not just the null hypothesis), Bayesian statistics allows the computation of the probability that the hypothesis is true, and it specifies the probability that the true value of the parameter is within any given interval. Bayesian statistics provides an easy way to revise estimates in an orderly and defensible manner as one collects new data. This way of thinking and computing frees the investigator from some of the concerns about disclosing data before the planned end of the trial, and thereby provides a set of tools to dynamically optimize the number of animal needed with optional stopping rules (O'Hagan and Luce, 2003). As a result of these advantages, Bayesian study designs have already entered the stage in clinical stroke trials (Krams et al, 2005; Lees, 2001).
The Case for Reporting Inclusion and Exclusion Criteria, as well as Mortality
I propose that experimental stroke studies evaluating treatment regimens should not only report criteria for inclusion and exclusion of animals but also for mortality. In particular, preclinical studies, which affect the decision to further develop a compound in clinical trials (at least supplementing conventional analysis), an intention-to-treat analysis should be considered, which is the gold standard in RCTs (Fergusson et al, 2002). In this type of analysis (ʻAnalyze as randomized!ʼ), animals that do not reach a predefined end point are scored with the worst possible outcome (e.g., an infarcted hemisphere).
The Case for Systematic Reviews in Preclinical Stroke Research
Systematic reviews are the foundation of evidence-based medicine and therefore common practice in clinical research. Only recently some authors have started to conduct systematic reviews of experimental stroke studies. As already mentioned above, quality deficiencies in experimental stroke research were exposed in these reviews. Interestingly, some (if not all!) clinical trials that resulted in negative outcomes (e.g., nimodipine) were, contrary to common belief, not supported by sufficient evidence from animal experiments (Horn et al, 2001; Horn and Limburg, 2001; Jonas et al, 1997). Presently, systematic reviews of experimental stroke studies exist on nimodipine (Horn et al, 2001), FK506 (Macleod et al, 2005c), nicotinamide (Macleod et al, 2004), melatonin (Macleod et al, 2005b), nitric oxide donors (Willmot et al, 2005b), nitric oxide synthase inhibitors (Willmot et al, 2005a), glutamate release inhibitors (Nava-Ocampo et al, 2000), and diffusion-weighted imaging (Rivers and Wardlaw, 2005). Systematic reviews on thrombolysis (C Briscoe, E Sena, PAG Sandercock and MR Macleod, personal communication, 2005), piracetam (PCR Wheble, ES Sena, PAG Sandercock and MR Macleod, personal communication, 2005), tirilazad (ES Sena, PCR Wheble, PAG Sandercock and MR Macleod, personal communication, 2005), are in submission.
Systematic reviews are an important tool to improve quality in experimental stroke research (Sandercock and Roberts, 2002; Macleod et al, 2005a, Macleod et al, 2005d; Roberts et al, 2002; van der Worp et al, 2005), as they not only, at least partially, overcome the problem of small sample sizes, but they can also deliver quantitative estimates for such confounders as publication bias (e.g., by funnel plot; Sutton et al, 2000) or effect of industry sponsorship on outcome. The CAMARADES (Collaborative Approach to Meta Analysis and Review of Animal Data from Experimental Stroke) collaboration, an initiative of Clinical Neurosciences, University of Edinburgh, UK and the National Stroke Research Institute, Melbourne, Australia, is spearheading the introduction of this approach into experimental stroke research. CAMARADES provides a supporting framework for groups involved in the systematic review and meta-analysis of data from animal studies in experimental stroke. Their website (URL see Table 4) features background information and practical tools to conduct such reviews.
Whether systematic reviews should also play an important role in safeguarding high standards of experimentation in mechanism-driven experimental stroke research remains unclear at present. Recently, meta-analysis has been applied successfully to assess the information available, which correlates histologic features with lesion appearance in diffusion-weighted imaging (Rivers and Wardlaw, 2005). In other neuroscience fields, meta analysis has been already applied to exploratory experimental studies (e.g., Myhrer, 2003).
The Case for Standard Operating Procedures in Preclinical Stroke Research
Monitoring, auditing, and standard operating procedures (SOPs) are key elements of quality control in RCTs. I propose that stroke laboratories should set up and publish (e.g., on institutional websites) their SOPs, and guarantee that their studies adhere to these standards. This is all the more important, as a relevant fraction of experiments, evaluations, etc. in experimental stroke studies are not performed by professionals, but rather by students in training unaware of these issues. International professional societies, such as the International Society for Cerebral Blood Flow and Metabolism (ISCBFM), may help to establish standards, propose schemes to safeguard adherence to them, and may even certify laboratories. In its most comprehensive form, certification would involve the participation in interlaboratory (ʻround robinʼ) tests, in which a known neuroprotectant (and/or placebo) is sent to participating laboratories in a masked manner. For certification, the results would have to lie within certain values. Most preclinical laboratories of the pharmaceutical industry use SOPs, and test novel compounds together with known neuroprotectants (very often MK-801) in a masked manner. Under the auspices of professional societies, stroke research laboratories could also audit each other (ʻpeer auditʼ). In any case, I propose that scientists and professional societies should proactively discuss issues of research governance.
The Case for Publishing Negative Results and a Trial Register
Negative results in experimental stroke research should be made accessible to other researchers after peer review. This could be done via dedicated journals (e.g., the open-access publication Journal of Negative Results in Biomedicine; URL see Table 4), or special repositories of websites of scholarly journals in the field. In addition, it might be worthwhile to consider a trial database for ongoing experimental studies (such as the International Standard Randomized Controlled Trial Number Register for Clinical Trials; URL see Table 4). Almost complete coverage of all ongoing trials and their negative or positive results once finished could be guaranteed if journals were to require registration before study onset when a study is submitted (as is the case for clinical studies in top journals). The running costs of such a database could be provided by registration fees, whereas the implementation of the database might be financed by grants from the National Institute of Neurological Disorders and Stroke (NINDS) or the European Union.
An Important Role for the Editors of Scholarly Journals
Editors of major clinical journals have spearheaded the recent improvements in the quality of clinical trials. This success story could be repeated in the experimental research domain if editors would only accept articles that (1) adhere to certain standards for reporting and statistics, (2) are internationally registered, and (3) lay open sponsorship or conflicts of interest.
A Gold Standard for Experimental Stroke Research?
Using multidisciplinary approaches, in vivo and in vitro experimental stroke researchers investigate basic mechanisms of stroke injury. However, experimental stroke studies may also test treatment or diagnostic strategies before a decision is made whether clinical trials should be undertaken. Thus, there can be no gold standard concerning models, species, or outcome assessment strategies in experimental stroke research. As recommended by STAIR (Stroke Therapy Academic Industry Roundtable, 1999), in preclinical stroke research animals with comorbidities, mixed gender, advanced age, etc. should play an important role to model the complexities of risk factors, patient profiles, and clinical situation as much as possible. The ʻqualityʼ of such studies, for example, if measured by a score (see above) would critically depend on how successfully clinical relevance was implemented in the research. Clearly, this would not be viable in reductionist mechanistic stroke research, which depends on excluding confounders, and therefore has no reason to cope with the consequences of increased variability, high numbers of required animals, and increased cost of long-term studies. A similar reasoning applies to effect sizes. For example, whether a 10% or a 30% reduction in infarct size is used for a priori power calculations depends entirely on the hypothesis to be tested. I suggest that authors, in particular if they report ‘negative’ results, justify their choice of effect size threshold.
It was the aim of this article to discuss some potential weaknesses (and therefore sources of bias) in the design, evaluation, and reporting of published experimental studies in stroke research. Where available I have quoted quantitative data on the frequency and impact of such weaknesses. I have also included, and clearly labeled, quality-related sources of bias, which have not been systematically studied (e.g., lack of inclusion/exclusion criteria; low statistical power). I have done this to spur discussion and in the hope that they will be exposed to meta-analysis in the near future. I am aware of the fact that until then it has to remain open whether these factors truly impact on effect sizes and reproducibility. However, to fully harness the power of meta-analysis, we need to improve the standard of reporting of results in this field, which is the reason why I have particularly emphasized this issue. From an analysis of potential weaknesses, I have deduced a catalog of measures to improve or implement quality standards. The use of animals for studies with questionable predictive value is not justifiable. Equally important, patients may be put at risk when clinical trials are based on weak or flawed experimental evidence. I propose that by a number of rather simple measures, the step from bench to bedside in stroke research can be made more successful. However, the ultimate proof for this can only come from successful phase III stroke trials, which built on basic research conforming to the criteria as put forward in this article or by STAIR (Stroke Therapy Academic Industry Roundtable, 1999).
Note added in proof
Since this review was accepted for publication, an important study (O'Collins et al., 2006) was published, which systematically evaluated experimental studies on 1,026 putative neuroprotectants and concludes that the drugs taken forward to clinical trial have not been distinguished by superior efficacy. The study urges for greater rigor in the conduct and reporting of animal data in experimental stroke research.