
Abstract
Long-range terrain perception has a high value in performing efficient autonomous navigation and risky intervention tasks for field robots, such as earlier recognition of hazards, better path planning, and higher speeds. However, Stereo-based navigation systems can only perceive near-field terrain due to the nearsightedness of stereo vision. Many near-to-far learning methods, based on regions' appearance features, are proposed to predict the far-field terrain. We proposed a statistical prediction framework to enhance long-range terrain perception for autonomous mobile robots. The main difference between our solution and other existing methods is that our framework not only includes appearance features as its prediction basis, but also incorporates spatial relationships between terrain regions in a principled way. The experiment results show that our framework outperforms other existing approaches in terms of accuracy, robustness and adaptability to dynamic unstructured outdoor environments.
Introduction
Navigation in an unknown and unstructured outdoor environment is a fundamental and challenging problem for autonomous mobile robots. The navigation task requires identifying safe, traversable paths that allow the robot to progress toward a goal while avoiding obstacles. Standard approaches to complete the task use ranging sensors such as stereo vision or radar to recover the 3-D shape of the terrain. Various features of the terrain such as slopes or discontinuities are then analyzed to determine traversable regions (Matthies. 1992; Pagnot & Grandjean. 1995; Singh, Simmons, Smith. 2000; Rieder & Southall. 2002). However, ranging sensors such as stereo visions only supply short-range perception and gives reliable obstacle detection to a range of approximately 5m (Ollis, Huang, Happold. 2008). Navigating solely on short-range perception can lead to incorrect classification of safe and unsafe terrain in the far field, inefficient path following or even the failure of an experiment due to nearsightedness (Jackel, Krotkov, Perschbacher. 2006; Michael J. Procopio. 2009).
To address nearsighted navigational errors, near-to-far-learning-based, long-range perception approaches are developed, which collect both appearances and stereo information from the near field as inputs for training appearance-based models and then applies these models in the far field in order to predict safe terrain and obstacles farther out from the robot where stereo readings are unavailable (Dahlkamp, Kaehler, Stavens. 2006; Happold, Ollis & Johnson. 2006; Max Bajracharya. 2009).
We restrict our discussion to the online self-supervised learning since the diversity of the terrain and the lighting conditions of outdoor environments make it infeasible to employ a database of obstacle templates or features, or other forms of predefined description collections. The winner of DARPA Grand Challenge (Dahlkamp, Kaehler, Stavens. 2006) combines sensor information from a laser range finder and a pose estimation system to first identify a nearby patch (a set of neighboring pixels) of drivable surface. And then the vision system takes this patch and uses it to construct appearance models to find the drivable surface outward into the far range. (Happold, Ollis & Johnson. 2006) propose a method for classifying the traversability of terrain by combining unsupervised learning of color models that predict scene geometry with supervised learning of the relationship between geometric features and the traversability. A neural network is trained offline on hand-labeled geometric features computed from the stereo data. An online process learns the association between color and geometry, enabling the robot to assess the traversability of regions for which there is little range information by estimating the geometry from the color of the scene and passing this to the neural network. The system of (Max Bajracharya. 2009) consists of two learning algorithms: a short-range, geometry-based local terrain classifier that learns from very few proprioceptive examples; and a long-range, image-based classifier that learns from geometry-based classification and continuously generalizes geometry to the appearance.
Appearance-based near-to-far learning methods mentioned above do support the long-range perception which provides the “look-ahead” capability for complementing the traditional short-range stereo- or LIDAR-based sensing. However, appearance-based methods assume that the near-field mapping from the appearance to traversability is the same as the far-field mapping. Such an assumption does not necessarily hold due to the complex terrain geometry and varying lighting conditions in unstructured outdoor environment. Therefore, how to use other strategies to compensate for the mapping deviation begins to draw more attention.
(Lookingbill, Lieb & Thrun. 2007) use a reverse optical flow technique to trace back the current road appearance to how it appeared in previous image frames in order to extract road templates at various distances. The templates can be then matched with distant possible road regions in the imagery. However, trackable features, on which the reverse flow technique is based, are subject to the image saturation and scene elements occurrence patterns. Furthermore, changing illuminant conditions can result in unacceptable rates of misclassification. Noting that the visual size of features scales inversely with the distance from camera, (Hadsell, Sermanet, Ben. 2009) normalize the image by constructing a horizon-leveled input pyramid in which similar obstacles have similar heights, regardless of their distances from the camera. However, the distance estimation for different regions of images introduces extra uncertainties. In addition, this approach does not consider the influence of changing lighting conditions on appearances. (Michael J. Procopio. 2009) proposes the use of classifier ensembles to learn and store terrain models over time for the application to future terrain. These ensembles are validated and constructed dynamically from a model library that is maintained as the robot navigates terrain toward some goal. The outputs of the models in the resulting ensemble are combined dynamically and in real time. The main contribution of the ensembles approach is to leverage robots' past experience for classification of the current scene. However, since the validation of models is based on the stereo readings from the current scene, this approach is still subject to the mapping assumption.
In summary, all the existing near-to-far approaches rely excessively on appearance features and the mapping assumption. As a result, they lack the robustness and self-adaptability for changling illuminant conditions. Furthermore, the problem of appearance ambiguity is inherent in unstructured outdoor environments. Consider the navigating scene in Fig. 1, which is taken from the natural datasets of actual logged test runs by robots competing in the DARPA LAGR (Learning Applied to Ground Vehicle) program(Jackel, Krotkov, Perschbacher. 2006). In this scene, shadows are prominent and the appearance of the shadows case on the ground (traversable) appears very similar to that of the side of hay bale (non-traversable). The tops of the hay bales - which receive near-field stereo labels of “obstacle”- are very similar in appearance to both sky and groundplane. Therefore, the resulting instances have similar feature data but different class labels, which will easily confuse the navigating system.

A challenging navigating scene
In this paper, we propose a Conditional Random Fields (CRF) (Lafferty, McCallum & Pereira. 2001) based near-to-far perception framework (CRFNFP) to compensate for such appearance ambiguities and to enhace robustness and self-adaptability to changing illuminant conditions. The main difference between our solution and other existing methods is that CRFNFP not only includes local region features, but also spatial relationship (spatial context) between different regions as its classification basis. The problem to be solved here is how to design a specific CRF framework, i.e., CRFNFP, with respect to the self-supervised, near-to-far learning in unstructured outdoor environments. To the best of our knowledge, ours is the first work that introduces and adapts the CRF-based framework to model the navigating scene contexts and to improve the long-range perception for mobile robot navigation.
In our solution, we first over segment the current scene into superpixels (a superpixel is a set of neighboring pixels) and update the classification database using training samples from stereo readings. Then we model both local appearance and spatial relationshops between regions under the CRFNFP framework. Thresholds on CRFNFP prediction marginals are used to determine the terrain categories of superpixels.
An outline of this paper is as follows: We first briefly describe the generation of training samples from the stereo in section 2. The CRFNFP framework will be detailed in section 3 and section 4 provides the experiment results. We conclude our paper in section 5 with our further research in this area.
Generation of sample labels
In our proposed method, a ground plane (Fig. 3b) is first fitted in the disparity image and subtracted out, resulting in an estimate of the ground plane deviation (GPD) (Fig. 3c). Second, pixels of big GPD are considered as candidate pixels for obstacles (Fig. 3f). Third, the RGB image (Fig. 2a) is over segmented by the graph-based technique (Felzenszwalb & Huttenlocher. 2004). Finally, the rate of terrain-specific candidate pixels within a superpixel is used to determine the superpixel label.

(a) RGB image; (b) superpixels expression and specific graph structure

Generation of pixels of samples from stereo: (a) Stereo disparity; (b) Ground plane predicted; (c) Ground plane deviation; (d) Hand-labeled ground truth; (e) candidate pixels (ground); (f) candidate pixels (obstacles)
The extraction of the ground plane is the most important geometric analysis. We assume that there is a dominant ground plane within the near-field terrain and that the plane also is the surface of support for the robot. Since planar features in the world will project into a planar surface in the disparity image (Max Bajracharya. 2009), the ground plane model is extracted by applying the RANSAC algorithm (Fischler & Bolles. 1981) to the disparity image. However, the dominant plane may not be extracted directly from the disparity image sometimes due to the complexity of terrain geometry. And in such a case, we use the default plane computed from vehicle geometry instead. The assumption of the single ground plane has proven to work well in practice for the present. However, when the robot comes to a very challenging scene, the uneven terrain and the side slope may affect the heading of the robot, the extraction of the ground plane and further the accuracy of classification. In the future, we plan to relax the assumption above and extract the ground plane based on the multi-surfaces fitting. Furthermore, we also plan to use appearance features, which are collected online or given in advance, to label the training samples since the feature of GPD alone is not adequate for such a challenging scene.
Another issue concerns the selection of training samples in the form of superpixels. In principle, the samples should be drawn from the near-field region, which corresponds to “bottom” half of the image, due to the dense and reliable stereo information in the near field. However, we find that the validation flags, which are created based on the texture and uniqueness validation of the stereo algorithm, are very accurate indicators for the correctness of stereo measuring. In other words, it's safe to conservatively select a superpixel as a training sample based on the rate of terrain-specific candidate pixels within the superpixel, even if it corresponds to the far-field region. Furthermore, such a selection is benificial to the collection of obstacle samples since there are few obstacle samples in the near field. We select training samples all over the image and we do not need to create balanced training sets using undersampling as (Michael J. Procopio. 2009), since our proposed algorithm is based on Bayes' rule.
During the whole process mentioned above, category-specific candidate pixels can be generated rather accurately. However, the parameter of MS (minimum component size) of the segmentation algorithm above has great influence on the accuracy of generation of training samples and our proposed method. The algorithm with an extremely large MS will create superpixels that contain many pixels of different categories. And since pixels within a superpixel are classified as a whole, many pixels may be misclassified. In our experiments, we find an MS of value 80 reduces the accuracy by nearly 15% compared with that of value 40. And we choose the value 40 for MS throughout all our experiments.
In our implementation, one superpixel produced one feature vector. The visual features used for our traversability classification task consist of color and texture information. Color information consists of average color in CIELAB color spaces. In addition, texture features of a superpixel are computed using eighteen filters selected from LM filter bank(Leung & Malik. 2001). The average response of each filter in a superpixel, and the distribution of the filter index of the maximum response at each pixel, represent texture features in a superpixel. The dimension of the feature vector is 39 as shown in Table 1.
Feature description
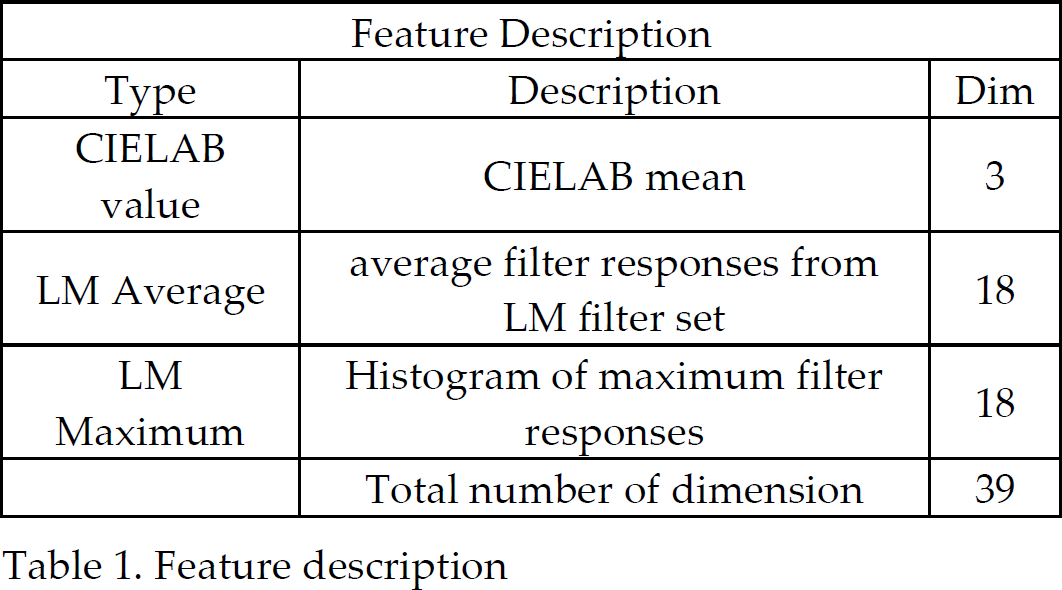
Feature description
Our CRFNFP framework is based on the concept of Conditional Random Field (CRF) proposed by (Lafferty, McCallum & Pereira. 2001) in the context of segmentation and labeling of 1-D text sequences. We first introduce the original definition of CRFs in our notations and pave the way for explaining our CRFNFP framework later.
Conditional Random Field framework
Let the observed data from an input image be given by
CRF Definition: Let
Given the observation 
Where Z is a normalizing constant known as partition function, and -
In this work, we first over segment the incoming scene into superpixels and then create a graph for the specific scene as shown in Fig 2b. Superpixels correspond to nodes (yellow points in Fig 2b) in the graph and the neighboring system N i is represented by the set of yellow lines. We have shown only a small portion of the graph and capitals are assigned to some nodes in Fig 2b for the ease of further explanation.
Our CRFNFP framework is an extended implementation of Standard Conditional Random Field (SCRF) in the context of self-supervised, near-to-far learning for mobile robots. In order to better adapt CRFNFP to changling illuminant conditions and the complex scene geometry of unstructured outdoor environments, we build CRFNFP based on SCRF with 3 modifications as bellow.
First, in unstructured outdoor environments, the feature distribution of terrain-specific samples is multimodal (samples are clustered into multiple centers in feature space), discriminative classifiers with linear or nonlinear decision boundaries, which SCRF uses to construct its association potential, are not suitable for our framework. Therefore, we develop a new version of the traversability classification algorithm in (Kim, Oh & Rehg. 2007) to construct the association potential of CRFNFP, which supports the incremental learning and the multimodal classification. The corresponding algorithm is described in subsection 3.2.1.
Second, the lighting condition and other unpredicted factors in outdoor environments usually make neighboring regions look different but with the same class such as regions A and B in Fig 2b. However, SCRF only incorporates feature-dependent terms into its interaction potential to allow the data to speak for themselves (i.e., only when neighboring superpixels are close in feature space, SCRF prefers to label them as the same class). Thus, we introduce an extra feature-independent smoothing term into the interaction potential to encourage the neighboring superpixels, although with different appearance, to be labeled as same classes. Detailed interaction potential construction is provided in subsection 3.2.2.
Finally, the context of online learning requires CRFNFP parameters to be adjusted continuously to the changing of scene geometry and lighting conditions. However, during real experiments, the change from one frame to the next is unpredictable and parameters directly learned from maximum likelihood framework are subject to abrupt changings. Therefore, we adopt a modified sequential bayesian parameter updating strategy to reduce parameter oscillations and to capture the overall trend of parameter changing. We describe parameter training and Bayesian updating algorithm in subsection 3.2.3 and 3.2.4 respectively.
Association Potential
The construction of association potential is based on an accumulation process of training samples and a real-time classification algorithm.
The accumulation process of training samples is similar to that of (Kim, Oh & Rehg. 2007). We maintain two models throughout the whole process: the traversability model ΘT and the non-traversability model ΘN. There are several prototypes (clustering centers in the feature space) contained in each model and each prototype
Given a novel superpixel with feature vector
First, if both dT and dN are larger than a predefined threshold θm, we simply assign the probability 0.5 to both
Second, if dT is larger than θm and dN is not, we assign the probabilities 0.2 and 0.8 to
Third, if dT is smaller than θm and dN is not, we assign the probabilities 0.8 and 0.2 to
Finally, if both dT and dN are smaller than θm, we use Bayes' rule where l denotes the unknown traversability variable:

The equation above shows that the posterior probability for the terrain with feature
The interaction potential in CRFNFP is defined as

Where δ(
where |
The interaction potential is used for representing the compatibility between classes of neighboring superpixels. The first term
In addition,
Average values of parameters

Since the robot can only obtain near-field labeled images 
where Θ denotes all the parameters in the model including 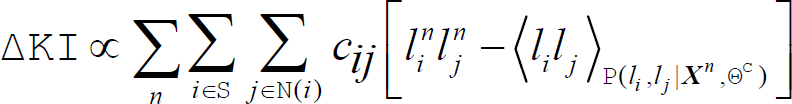
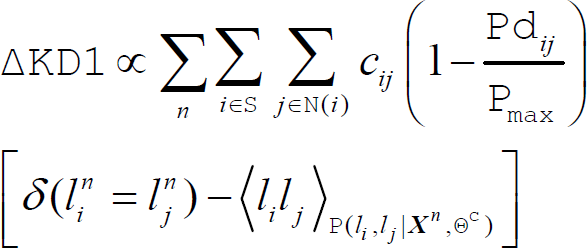

where Θ
c
represents the current parameter values and
We apply independent sequential bayesian updating for each of CRFNFP parameters and model each parameter as a Gaussian with known variance σ2 and unknown mean μ. We continuously take parameter training results as observations (input), construct prior, likelihood and posterior functions for mean μ, and then take the modal of posterior as the current value of corresponding parameter (output) of CRFNFP framework.
The likelihood function, which is the probability of the observed data given μ, viewed as a function of μ, is given by

where 
and the posterior distribution is given by

where


In our implementation, we first collect 20 qualified images (We define an image as “qualified” only when neither class-specific sample ratios fall bellow a certain threshold in order to avoid overfitting of model parameters.) and train CRFNFP parameters for initial values μ0. We continuously train parameters one time for every 5 new qualified images and take the result as one observation. And the modal, i.e., μ t of posterior is updated using Eq. (12), where N is 1 and σ2 N / σ2t−1 is set to a constant, which is defined as the ratio of image number used for training (5/20). In addition, we do not update σ2 t using Eq. (13) due to the fact that when the σ2 t is big enough, the μ t can hardly incorporates new information from the newest observation and can not be altered, which is obviously unsuitable for self-adaption of the robot.
When a new image 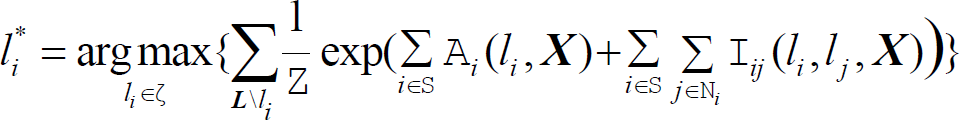
where
We ran two sets of experiments, i.e., the classification experiment and the navigation experiment, to compare the relative performance of our CRFNFP framework and another appearance-based approach. In the classification experiment, we used the natural data sets taken from logged field tests conducted by DARPA evaluators (Procopio. 2007b). We analyzed qualitative classification results of both algotirhms and compared prediction accuracies and the robustness under two performance metrics. In the navigation experiment, we implemented CRFNFP framework on our own UGV to confirm the extended perception range and more efficient path planning capability of our CRFNFP algorithm.
The appearance-based approach used to compare with our CRFNFP is a modified k-nearest neighboring (MKNN) algorithm of (Kim, Oh & Rehg. 2007). The major difference between MKNN and ours lies in the information they use to classify novel images. MKNN classifies image superpixels only based on appearance features, while our CRFNFP not only uses feature information but also utilizes the spatial contexts among superpixels. It's worth a mention that since many other near-to-far learning algorithms (Dahlkamp, Kaehler, Stavens. 2006; Happold, Ollis & Johnson; Max Bajracharya. 2009) are also based on appearance features only, we assume that the superiority of our CRFNFP framework over MKNN algorithm are applicable to cases of other algorithms of (Dahlkamp, Kaehler, Stavens. 2006; Happold, Ollis & Johnson. 2006; Max Bajracharya. 2009).
Classification experiment
Data Sets
The natural data sets used here are taken from logged field tests conducted by DARPA evaluators(Procopio. 2007b). Overall, three scenarios are considered. Each scenario is associated with two distinct image sequences, each representing a different lighting condition. Thus there are six data sets, i.e., DS3B, DS3A, DS2B, DS2A, DS1B, DS1A, and each data set consists of hundreds of frames. First 100 frames in each data set are hand-labeled, with each pixel being one of three classes: OBSTACLE, GROUNDPLANE, or UNKNOWN. The data sets are available on the internet(Procopio. 2007a).
Evaluation Metrics
We used the precision and recall as the evaluation metrics. These two metrics were defined as follows


The qualitative results for different data sets are shown in Fig. 4, Fig. 6 and Fig. 7, in which left columns show original RGB images, middle columns are related to the classification results of MKNN, and right columns concern the classification results of CRFNFP. White regions of the classification results indicate obstacles and black regions correspond to the ground.
DS3A is from a LAGR test run from 2006. The course is that of a trail, with dense, leafy foliage on either side. The trail proceeds deep into the far field. There are areas to the side of the trail that have appearance of the non-traversable foliage, a tricky aspect of the dataset. The scene is generally consistent from start to finish. DS3B is the same scenario as DS3A but with a different lighting condition, and the course appears generally darker. The classification results for typical images in DS3B and DS3A are shown in Fig. 4.
The Result comparison in Fig. 4 indicates that CRFNFP is prone to produce a continuous and coherent traversable region, which is of significant value for robot navigations in unstructured environments. While on the contrary, regions classified by MKNN are usually cut into pieces and full of noise due to stereo mismatch and unpredicted far-field appearance features as shown in Fig. 4e.
Another finding concerns the adaption to changing lighting conditions during a single run. Fig. 4a and Fig. 4d are taken from the same run but with very different classification performance as shown in Fig. 4b and Fig. 4e. The reason for such a case may be that when the lighting condition changes as the robot runs, appearance features in far-field become more unpredictable and vivid (different from dark appearance of near-field), and the classification database, which is collected during past experience and taken as the only classification basis for MKNN, can not account for the far-field appearance any more. As a consequence, the mapping assumption (introduced in section 1) from the appearance to geometry generally does not hold any longer. In contrast, our CRFNFP still maintains a coherent traversable region (shown in Fig. 4c and Fig. 4f) and keeps relatively high precision at different time points of a run (Fig. 5). In other words, the incorporation of spatial contexts in CRFNFP compensates for the mapping deviation and makes the vision system more adapted to lighting condition changings during a run.

Results comparison for DS3B Frame 29, 76 and DS3A Frame 97

Frame-varying precision of DS3B for ground class
DS2A and DS2B are also logged from a LAGR test run from 2006 with different lighting conditions. Major challenges faced by algorithms are: stereo usually struggles on dense, leafless foliage contained in DS2A and DS2B; obstacle examples can be very few; some areas of the traversable terrain have the same appearance as some of the obstacles (foliage). And the classification results on DS2A and DS2B are shown in Fig. 6.
From Fig. 6, we observe that if no sufficient training samples for a specific terrain category are accumulated in the classification database during past experience, MKNN would classify such terrain regions randomly (e.g., sky area and the upper part of foliage in Fig. 6a, or even incorrectly (e.g., taking lower part of foliage in Fig. 6a as ground), since almost all the training samples collected in classification database, which have the same appearacne as the lower part of foliage, belong to the category of ground. As a result, large amounts of pseudo-path appear as shown in Fig. 6b and Fig. 6e. Such pseudo-paths will guide the robot toward the foliage until the stereo vision finds it is an inefficient decision. In contrast, CRFNFP generally recognizes far-field obstacles (foliage) and guides the robot toward the right side ahead of time, endowing the robot with real long-range perception and planning abilities. Fig. 6e shows that though the stereo vision has confirmed the lower part of foliage as obstacle, the MKNN still classifies upper part of foliage as ground, which highlights the limitation of appearance-only-based approaches and the necessity of including spatial contexts as part of the basis for classification.

Results comparison for DS2B Frame 368, 400 and DS2A Frame 285
DS1A is a very challenging data set due to the difficult lighting conditions. Some image saturation is present and shadows are prominent as shown in Fig. 7d and Fig. 7g. Many training instances have similar feature data but different class labels, a situation that will easily confuse the classifier. DS1B is logged from a different run with a better lighting condition. The result comparison in Fig. 7 shows that MKNN still struggles on randomness of far-field classification and the generation of pseudo-paths. And our CRFNFP generally achieves better classification results.

Results comparison for DS1B Frame 221 and DS1A Frame 178, 291
In order to further highlight the superiority of CRFNFP over MKNN approach, we collected average recall and precision results for all 6 data sets in Table 3. Note that in our experiment, only pixels manually labeled as OBSTACLE or GROUNDPLANE in (Procopio. 2007a) are considered in computations of precision and recall. The high performance of CRFNFP and MKNN for ground category is due to the fact that many ground pixels are located in the perception range of stereo vision and can be easily recognized.
The first 3 rows of Table 3 represent different combinations of performance metric, terrain category and the classification approach. We list the main findings from Table 3 as bellow.
Quantitative comparison results I

Quantitative comparison results I
First, CRFNFP generally outperforms MKNN under various combinations of performance metrics and terrain categories. For example, consider the obstacle recall of both algorithms on all data sets, i.e. values in column 4 and 5. The increased percentages of CRFNFP compared with MKNN are 8.05, 32.07, 2.11, 12.35, 19.15, 11.71 for DS2A, DS2B, DS3A, DS3B, DS1A and DS1B respectively. It's worth a mention that since stereo vision would correctly recognize near-field terrain for both algorithms, the recall increase mainly corresponds to the improvement of recognition of mid- and far-field terrain. So such an increase, even small sometimes, is of great value for the long-range perception of mobile robots. One example of this point is shown in Fig. 6b and Fig. 6c, where the increase of recall mainly concerns the foliage in the far-field. Such an earlier recognition of obstacles (hazards) in far-field would greatly improve the navigation efficience, which is extremely important for tasks such as searching and rescue.
The second finding is related to the robustness of classifications. Consider the results (marked in bold) of DS2A and DS2B, which are logged from the same scenario but in a different day and lighting condition. Obstacle recall of MKNN on DS2A is 75.10 while that on DS2B is reduceed to 51.04, and ground precision of MKNN on DS2A is 85.04 but 73.51 for that on DS2B. In other words, the performance of MKNN, based on appearance only, is subject to detailed lighting conditions and other potential factors. In contrast, the difference between obstacle recalls of CRFNFP on DS2A and DS2B is merely 0.04 and ground precision difference is 0.73, which indicated CRFNFP is more robust than MKNN with respect to lighting conditions and other factors. Similar comparison results can be found in values for other data sets, which highlights the classification stability and robustness of our CRFNFP framework.
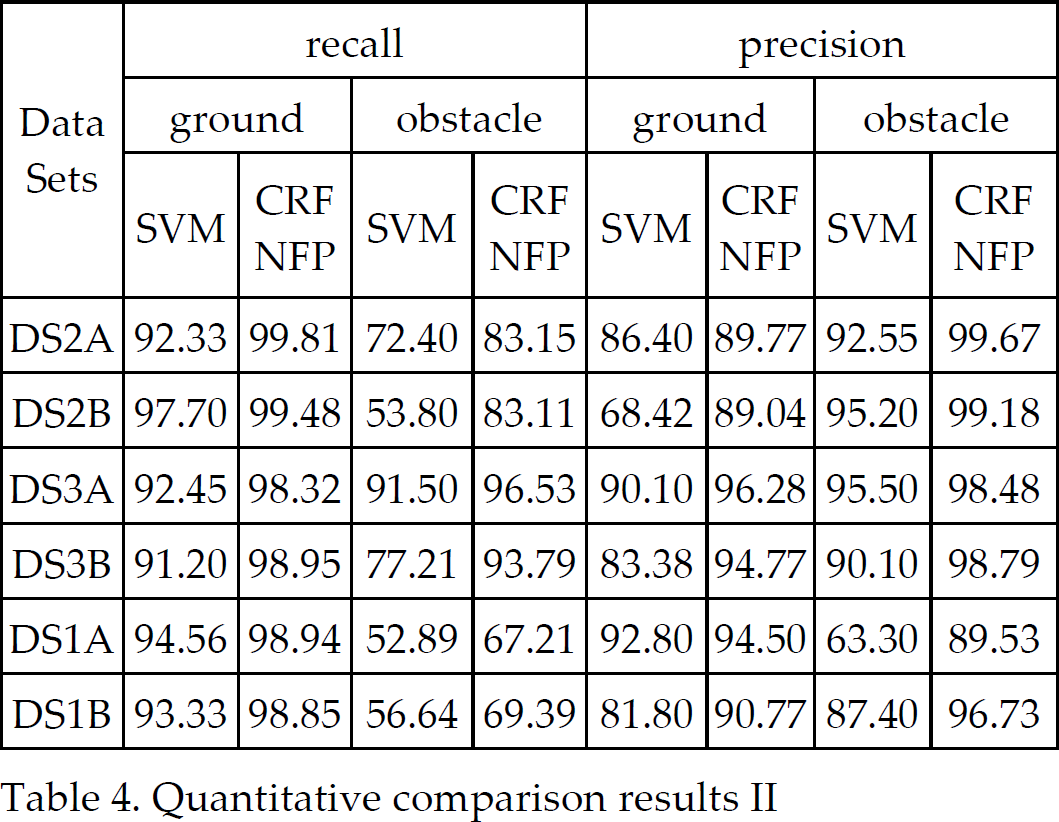
Table 4 lists the comparison results of a linear SVM and CRFNFP. Readers may refer to (Max Bajracharya. 2009) for the parameter selection for linear SVM. The results also reflect the superiority of CRFNFP.
Quantitative comparison results II
In order to confirm that CRFNFP does enhance the long-range perception for mobile robots and helps planning more efficient paths for the navigation, we conducted outdoor navigation experiments with our UGV (shown in Fig. 8), which is a four-wheeled, 8 DOF mobile robot with each wheel individually driven and steered to obtain the desired maneuverability. Our experiment field (Fig. 9) is a deserted playground at nanjing agricultral university (32° 7'46.26“N, 118°41'28.66”E), containing grass, foliage, rocks and ground. We assume that the experiment field is generally even with modest dips and rises and the most common obstacles are foliage and tall grass. We do not assume the shape of the traversable region, which is totally determined by the classification of CRFNFP. The task of the robot was to reach the goal, which was beyond 200 meters away from the start point. In the future, we will further study on the navigation in challenging or hilly scenes. The goal was specified by global positioning system (GPS) coordinates and since we were planning in image space, we porjected the goal into the image plane, assuming that the ground is flat. When the distance between the robot and the goal, calculated and transformed from the GPS readings, was less than 50 centimeters, the task was considered to be performed successfully. We used AgGPS (20 cm, positioning error) and PointGray Bumblebee stereo uint (reliable obstacle detection, 5m) in our navigation experiment. During runs, near-field stereo information was not only used to update near-field map but also to construct the classification database for the far-field terrain prediction. The cost of a move to a pixel was determined by the probability of obstacle, which, in turn, is generated by CRFNFP framework. The cost image is shown in Fig. 10, in which, the darker a pixel was, the more easily it could be traversed. We performed an A* search on the cost image to find a pixel-to-pixel path to the goal pixel. A number of details, although worth mentioning, will not be expanded here since it is not the focus of this paper.

UGV used for navigation experiment

Experiment field

Path planning in image space using A* algorithm(Hart, Nilsson & Raphael. 1968): (a) CRFNFP & frame 22; (b) MKNN & frame 22; (c) CRFNFP & frame 84; (d) MKNN & frame 84. Note that although paths in the image are planned pixel to pixel, we have drawn them using straight lines between sampled points (large dots) for greater clarity.
We totally performed 6 runs on the same scenario, 3 runs using CRFNFP and another 3 using MKNN. For all runs, the robot successfully reached the goal. Running times for runs using CRFNFP were 249s, 263s and 258s, with an average time of 257s. And running times for runs using MKNN were 334s, 378s and 288s, with an average time of 333s. The discrepancy in the average running times indicated that paths, planned based on CRFNFP classification results, were more efficient compared with that on MKNN classification results. The reason for such a discrepancy could be well explained by the two inefficiency modes (shown in Fig. 10b and Fig. 10d respectively), which, in turn, were caused by the intrinsic randomness of appearance-based long-range approaches. First, possibly due to the shortage of corresponding training samples in classification database for far-field trees as shown in Fig. 10b, MKNN misclassified part of far-field trees as ground, and in order to minimize the overall cost, the corresponding path first went to the right side and then turned left in the far-field. As a result, the robot turned right at its current position, while the first choice should have been to keep going straight or turn left slightly. Second inefficiency mode was shown in Fig. 10d, in which the robot, based on MKNN classification result, found the “shortest” pseudo-path on the left. Consequently, the robot turned left sharply and approached tall grass (obstacle) until the arrival of stereo correction, which usually took several extra seconds.
In addition, based on results in Fig. 10 and Fig. 11, we could confirm that CRFNFP did enhance long-range perception ability of the robot. It could be easily verified that CRFNFP nearly recognized whole drivable regions in images and the perception ranges usually reached up to 80 meters (much larger than 5 meters of stereo perception region). On the other hand, appearance-based approaches, e.g., MKNN, also provided the robot with a similar long-range perception capability. However, the randomness (Fig. 10b) and the tendency to misclassification (Fig. 10d) counteracted the benefit of long-range perception.

Frames 022, 065, 084, 086, 088 from navigation experiment
In our experiments, the runtime of our CRFNFP algorithm was 1.1 Hz on the color images with 320 × 240 resolution. We implemented the CRFNFP algorithm using multithread programming under Visual C++ 6.0. Our CPU processor in the robot is 2.26 GHz Intel Core Duo P8400. On the other hand, the runtime of MKNN algorithm was 2.3 Hz.
In this paper, we proposed a new statistical prediction framework, CRFNFP, in the context of near-to-far terrain learning and perception of mobile robots. Compared with other existing near-to-far learning approaches, the CRFNFP framework not only incorporated appearance features of far-field terrain, but also used the spatial contexts among terrain regions. Our original contributions concerned the design of a specific CRF framework, i.e., CRFNFP, with respect to the self-supervised, near-to-far learning in unstructured outdoor environments. The results from both experiments showed that our CRFNFP outperformed appearance-only-based approaches in aspects of accuracy, robustness and the adaptability to unstructured outdoor environments.
In the future, we plan to enhance our CRFNFP with other contexts such as temporal contexts, e.g., the temporal relationship between the current frame and the next. Based on observations from the current scene, how to dynamically select and combine various contexts to better classify the current scene is another concern of our future study.
Footnotes
6. Acknowledgement
This work is supported by the National High-Tech Research and Development Program of China (2006AA10A304, 2006AA10Z259, 2008AA100905).