
Abstract
The dynamic cooperation model of multi-Agent is formed by combining reinforcement learning with BDI model. In this model, the concept of the individual optimization loses its meaning, because the repayment of each Agent dose not only depend on itsself but also on the choice of other Agents. All Agents can pursue a common optimum solution and try to realize the united intention as a whole to a maximum limit. The robot moves to its goal, depending on the present positions of the other robots that cooperate with it and the present position of the ball. One of these robots cooperating with it is controlled to move by man with a joystick. In this way, Agent can be ensured to search for each state-action as frequently as possible when it carries on choosing movements, so as to shorten the time of searching for the movement space so that the convergence speed of reinforcement learning can be improved. The validity of the proposed cooperative strategy for the robot soccer has been proved by combining theoretical analysis with simulation robot soccer match (11vs11).
Introduction
The study of the robot soccer simulation focuses on the advanced functions adopted by a team, including the current hot issues of artificial intelligence, such as multi-Agent cooperation, real-time reasoning–planning–decision-making the machine learning and obtainment of strategies in the uncertain dynamic environment. At present, some study technologies of the entrant teams have been realized, such as genetic algorithm [1], supervision learning and reinforcement learning. Reinforcement learning is used most frequently [2], 3, 4, [5]. Karlsruhe Brainstormer (a team in Germany) regarded reinforcement learning as their main research direction and had made the outstanding achievement: they won the runner-up of the simulation groups in 2000 RoboCup. Their goal is that the intellectual body can communicate with the environment independently and study various skills and strategies by only being told to finish scoring [6].
We have also done some research on the application of reinforcement learning to the robot soccer. We mainly study the application of the reinforcement learning to the multi-Agent cooperation [7], but not to the rudimentary behavior of an individual Agent (e.g. kick)[8].
In the research of multi-Agent, people have proposed the thinking model of multi-Agent—BDI model. This model includes the connection and activity relation between thinking property of multi-Agent and Agents. Among them, basic thinking property of multi-Agent is composed of belief, desire and intention. In BDI model of multi-Agent, belief is to describe the estimation of Agent at the present environment and the behavior it may adopt; desire is used to describe that Agent has a taste for the environment and behavior that it may adopt in the future; intention is used to describe that the Agent has made a promise in order to reach a certain goal.
Though multi-Agent represents different fields, and has its own local interests and local targets, while solving the problem in coordination, it should solve the problem in coordination and in an orderly manner under the restraint of the common planning. That is to say, the course of local solving must be adjusted in time according to the change of the external environment, in order to reach the interaction, dynamics and timeliness of the solving course in coordination. From the point of concept, BDI model based on the logical method has realized rational reasoning, while reinforcement learning has realized decision-making through optimization utility. From the point of technology, the logical method that adopts symbols to reason is unable to make utility best, and reinforcement learning with the numerical analysis has also ignored reasoning. As to a multi-Agent system of the dynamic environment, it is necessary to reason for the environmental message and to make a reasonable decision which may bring the maximum profit through learning.
In this paper, we combine reinforcement learning with BDI model [9, 10], so as to form a dynamic cooperative model of multi-Agent. In this model, the concept of the individual optimization loses its meaning, because the repayment of each Agent does not only depend on iteself but also on the choice of other Agents. All Agents can pursue a common optimum solution and try to realize the united intention as a whole to a maximum limit. The robot moves to its goal, depending on the present positions of other robots that cooperate with it and the present positions of ball. One of these robots cooperating with it is controlled to move by man with a joystick. In this way, Agent can be ensured to search for each state-action as frequently as possible when it carries on choosing movements, so as to shorten the time of searching for the movement space so that the convergence speed of reinforcement learning can be improved.
The Cooperative Strategy of the Robot Soccer in Match
The Attack Strategy
The research on the simulation robot soccer match (11 vs 11) is presented in this paper. The soccer field is divided as follows: The halfway line is made as the boundry; on the left of the halfway line, including the opposite goal areas is the fore court; on the right of the halfway line, including our goal areas is the back court. When the ball is at the fore court, the attack strategy is adopted; when the ball is at the back court, we adopt the defensive strategy. The fore court is divided into 8 areas. The division of the area and the coordinate orientation of the court are shown in Fig.1.
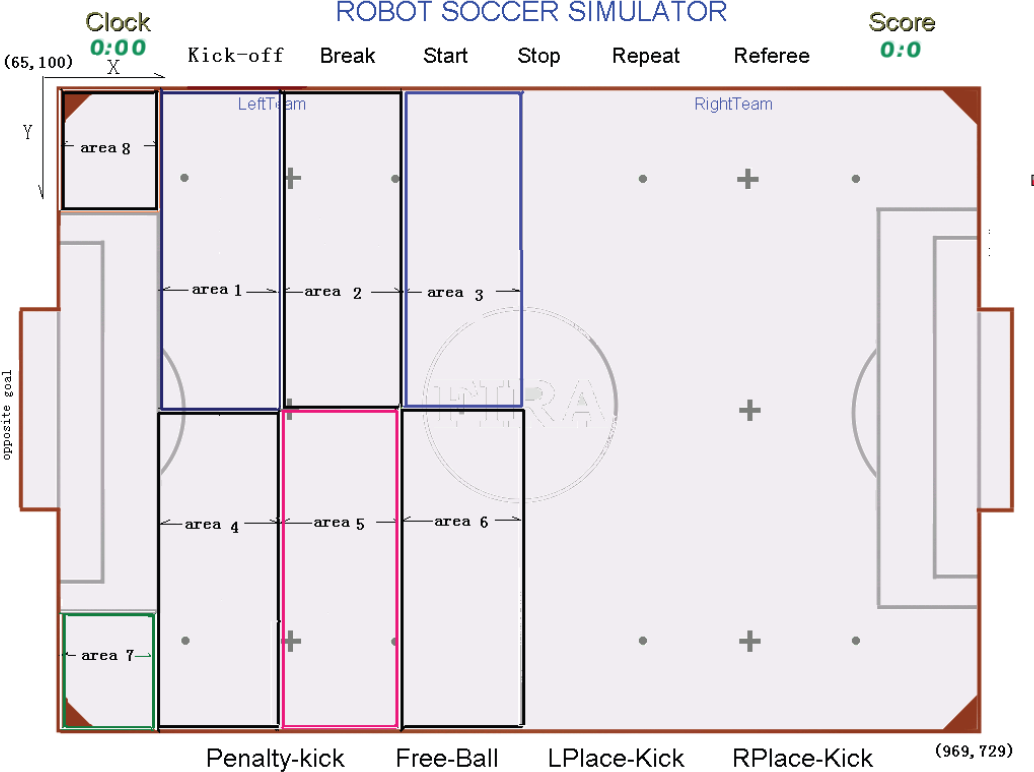
The division of the fore court and court coordinate orientation
The attack strategy: The members for attacking are divided into two groups–the shooting group and the mend-shooting group. Certain distance is kept between the members of two groups. All the members of two groups are before the opposite goal area (see Fig. 2).

The members for attacking is divided into two groups — the shooting group and the mend-shooting group
The shooting group: It is made up of 7 members. Its main task is to shoot the ball into the opposite goal.
The mend-shooting group: It is made up of 3 members, and its main task is to shoot the ball into the opposite goal again, which isn't shot into by the shooting group.
There are two kinds of possible situations: (1) The member of the shooting group has shot the ball, but the ball comes out from the opposite goal corner to the position where the members of the mend-shooting group stand; (2) The member of shooting group hasn't shot the ball into the opposite goal, but shot the ball from another side in front of the opposite goal area to the position where the members of the mend-shooting group stand.
The strategy of the shooting group: The positions of the shooting group members follow the present position of The ball closely. The one who is closest to the ball will shoot.
The strategy of the mend-shooting group: The positions of the mend-shooting group menbers are correlative with the position of ball and other members' positions in the same group. The one whose distance from the ball is less than 100 will shoot.
The strategy of the shooting group is simpler, while the strategy of the mend-shooting group, i.e. cooperative strategy, is more complicated. The reinforcement learning based on BDI model proposed in this paper mainly focuses on the cooperative strategy of the three members in the mend-shooting group.
The main task of the three members in the mend-shooting group is to determine the correct position of themselves at present according to the present position of the ball and other members in the same group and then shoot the ball to the opposite goal accurately when the ball comes. The task of the members in the mend-shooting group inclueds two steps:
The first step: According to the positions of the ball and the other members in the same group, they look for their own proper position;
The second step: Shoot the ball into the opposite goal.
The first step of the task determines whether the second step of the task will succeed or not: if the position where the members stand is proper, they will receive the ball and shoot the ball into the opposite goal, otherwise they can't receive the ball, or after receiving the ball, they can not shoot the ball into the opposite goal in a right direction. Therefore, we call the second step of the task as the follow-up task. This paper mainly study on the first step with reinforcement learning – look for an optimum strategy which enables the robot to find optimum movements according to the present state(the positions of the members and the ball), namely to find a couple of state-movements that can obtain the most reciprocation (the highest scoring rate).
Three members of the mend-shooting group are assigned separately as A, B and C. The position coordinate of three members are set up respectively as P a = (x a , y a ), P b = (x b , y b ) and P c = (x c , y c ). The position coordinate of the ball is P ball = (x ball , y ball ). Suppose the position of the member A is decided by present position of the ball, and the present positions of the other two members are not only related to the position of the ball but also to the other members' positions in the same group. In this way, three members could cooperate closely and pursue the common optimum solution – if the relative position of the three members is the best, the scoring rate will be the highest.
Seting the position coordinates of three members in the mend-shooting group are separately:

Where,
We know that the environment of the robot soccer is continuous. For example, the input includes the present position (two-dimentional vector) of the ball and robots, and it is continuous; the output is a sequence of movements and it is continuous too. But reinforcement learning is suitable for the solution of dispersed space. In this paper, so long as the present position of the ball is known, the positions of three members P a , P b , P c can be worked out by the 14 control parameters. In this way, as long as we make the position of ball dispersed in the 8 divided areas of the fore court, the dispersion of state space can be finished. When the ball is in each of 8 areas, the cooperative strategies of the three members are different, but in each of these areas, the three members all have a best position, which will make the rate of shooting the highest and bring the maximum repayment.
Because the position of the ball is at random, it can not evenly pass each area or the even dispersed positions of each area. Therefore, it is very difficult to search for the optimum solution. Because of this, the movement of the member A is controlled with the joystick in this paper, making it able to keep proper distance from the ball which moves at random so as to obtain the best rate of scoring. Because the other two members' positions correlate with the positions of the ball and the other members in the same group, if the best movement of the member A is set with the joystick - l, h are known, then the best movements of the member B and the member C are determined correspondingly too, and 14 control parameters l, h, a1, b1, c1,
BDI Model Based on Reinforcement Learning and The Realization of BDI Model
The basic principle of Reinforcement Learning
Reinforcement Learning is also called encourage learning. It is a method without supervision. It is the action of Agent to communicate with the dynamic environment by the method of trial-and-error and to study the correct action independently. The Agent utilizes the already having knowledge to try various movements constantly and to revise its own knowledge and strategy through the rewards and punishments from the environment, so as to find or approach the strategy that can get the maximum reward. The standard model of reinforcement learning composed is as follows:
Strategy II: S→A, mapping from the environmental state to action, function or a corresponding table;
Reward function R(s, a): S × A→R The reward after a movement is carried out;
Reward function for a long time V(s): S→V The reward after a series of movements are carried out;
Environmental model T (optional): S × A→ RxR0
The BDI Model Based on Reinforcement Learning
We combine reinforcement learning with BDI model in order to solve the decision-making problem of multi-Agent. We define it as multiple members:
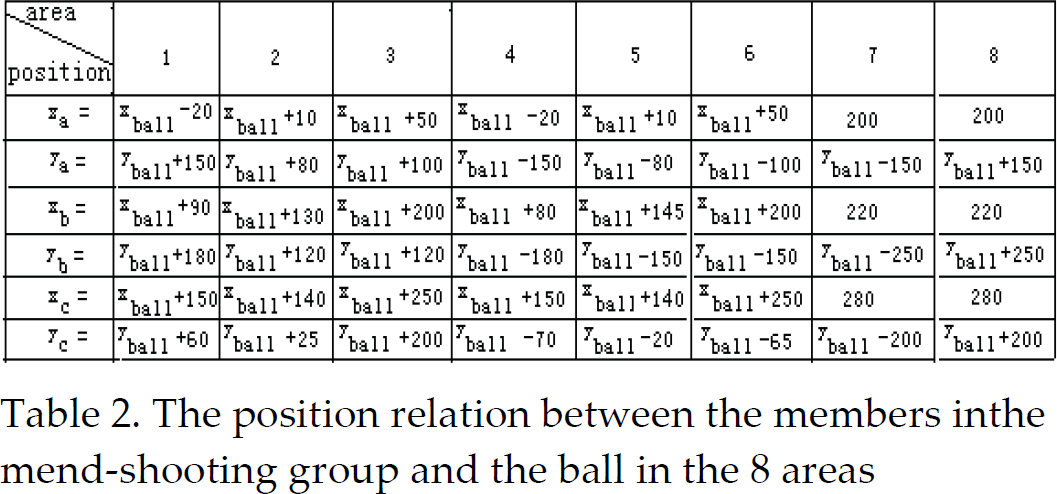
Definition 1. In {S, G, A, B, D, I, Λ}, S is the dispersed state space, G is the goal solved in coordination, A is a set of multi-Agent, B is a belief set of multi-Agent, D is a desire set of multi-Agent, I is an intention set of multi-Agent, and Λ={Λ1, Λ2,…, Λn} is a set of value coefficient when multi-Agent carries on solving the problem, Λ∈[0,1]. Generally speaking, each Agent solves the problem locally according to their own local planning, and does not consider the movement planning of other Agents, so there must be conflicts of intention between Agents, which makes the equation below established:

The internal motive force of the multi-Agent system is the intention, and the unstability comes mainly from the intention conflicts. According to the theory of dynamics, systematic movement is always towards the stable equilibrium attitude and far away from the unstable equilibrium attitude. To the Agent in system, whether in conflict or cooperation, it always reaches a certain equalization point or steady point finally. If we divide multi-Agent system into two parts: Agents whose intention have conflict and Agents whose intention have no conflict, then the system can be regarded as the gaming system of a pair of matrixes. According to Nash theorem, there must be a balance of mixed strategies in the gaming system of a pair of matrixes. If we assume all Agent study the same balanced Nash, this makes the choice of each Agent correspond to the choices of the other Agents optimumly, so the equation below can be established:

By this way, in our system, all Agents can pursue a common optimum solution, namely to pursue and realize the united intention as a whole to the maximum extent.
The set of movements that can be chosen is described by an abstract movement. This abstract movement is: a[P1, P2] = P1 → P2. It means that a member can move from the position P1 to the position P2. It is realized by the function in programming: position (robot, cpoint(P1, P2)), the first parameter of the function “robot” means the robot controlled; the second parameter P1 is the original position of the robot; the third parameter P2 is the goal position of the robot. There are also three special abstract movements:
a[P1, P2, success]: This abstract movement shows the member moves from the position P1 to the position P2. The follow-up task can be adopted and the task succeeds. The ball is shot into the opposite goal; a[P1, P2, 0]: It shows that the member moves from the position P1 to the position P2. The follow-up task can't be adopted; a[P1, P2, failure]: It shows that the member moves from the position P1 to the position P2. The follow-up task can be adopted, but the task fails.
The Study Scheme
The punishment rule: Using the Q-learning algorithm with Q value as the appraisal value of the state-movement, the rule of rewards and punishments is designed as follows:
The member moves from the position P1 to the position P2. The follow-up task (shoots) can be adopted and the task succeeds, then r = 1 (corresponding to the abstract movement a[P1, P2, success]); 12); The member moves from the position P1 to the position P2, The follow-up task (shoots) can be adopted and the task fails, then r = 0 (corresponding to the abstract movement a[P1, P2, failure]); The member moves from the position P1 to the position P2. The follow-up task can't be adopted (the distance between the member and the ball is greater than 100), then r = −1 (corresponding to the abstract movement a[P1, P2,0]).
Determine the environment and action:
Set of the state: S = S1 ∪ S0, the state in S1 is the position of the ball P ball (x ball , y ball ), and the positions of three members P a , P b and P c ; the state in S0 is the positions of the ball and three members, in which the follow-up task can be adopted and the task succeeds.
Action: A ⊆ S, the state (position) that can be reached from a kind of state (position) after carrying out a basic order: position (robot, cpoint(P1, P2)).
Determine the parameter (immediate reward r):
the follow-up task can be adopted, and the task succeeds, then r = 1; the follow-up task can be adopted, and the task fails, then r = 0; the follow-up task can't be adopted, then r = −1.
The algorithm of searching online:
Search for S, search for S0 from S, S0 ∈ S; Determine the action a from S0, a represents the action with maximum Q value
The goal position of the action is determined by 14 control parameters in (1). Send the basic order that action a needs: a[P1, P2] → position (robot, cpoint (P1, P2))
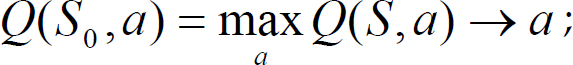
The realization steps of the algorithm:
To each S, a, (where a = (a1, a2, a3)), initialize Choose a movement a and carry out it Receive the immediate reward r
i
Observe the new state S′ Update

Where,
Simulation
In view of the simulation robot soccer match (11 vs 11), the match strategy proposed in this paper based on reinforcement learning has been demonstrated in this experiment. In the 8 areas that are divided in the court, the optimum solutions of 14 control parameters are searched on-line. In order to avoid the influence of random factors on the experimental result, the experiments of many sessions have been carried out. When the optimum solution tends towards stability, 14 control parameters are determined, as shown in Table 1. Then with the 14 control parameters decided, the match is carried on based on the attack strategy proposed in this paper.
The 14 control parameters determined in the 8 areas

The 14 control parameters determined in the 8 areas
We have adopted two kinds of attack strategies to carry on the match:
The first is the attack strategy based on reinforcement learning proposed in this paper, which adopts the 14 control parameters in Table 1 to determine the positions of three members in the mend-shooting group, but the abscissa positions of the three members must meet the conditions: when x i < 185, then x i = 185 (i = a,b,c).
The second is the attack strategy without machine learning, which is adopted as the strategy (simulation 11 vs 11) of our team in the fifth national robot soccer championship match (won over Nanjing University of Technology, defeated by Chengdu University of Technology). While adopting the second kind of attack strategy to carry on the match, in each of the 8 areas of the court, each of the three members' position correlates with the position of the ball, and has nothing to do with the positions of the other members in the same group. The position relations of the members and the ball are determined by experience, not by the method of machine learning. The position coordinate relation between the three members and the ball in the 8 areas are shown in Table 2.
The position relation between the members inthe mend-shooting group and the ball in the 8 areas
The same rival is chosen (the rival's strategy does not change) while these two kinds of attack strategies are adopted in the match. Each kind of attack strategy has been carried on in 10 matches. The experimental results of these two kinds of attack strategies adopted in matches are shown as Fig. 3 and Fig. 4. It is shown that, the score of the soccer team based on the dynamic cooperation model is obviously higher than that of the soccer team which hasn't adopted reinforcement learning in the attack strategy.
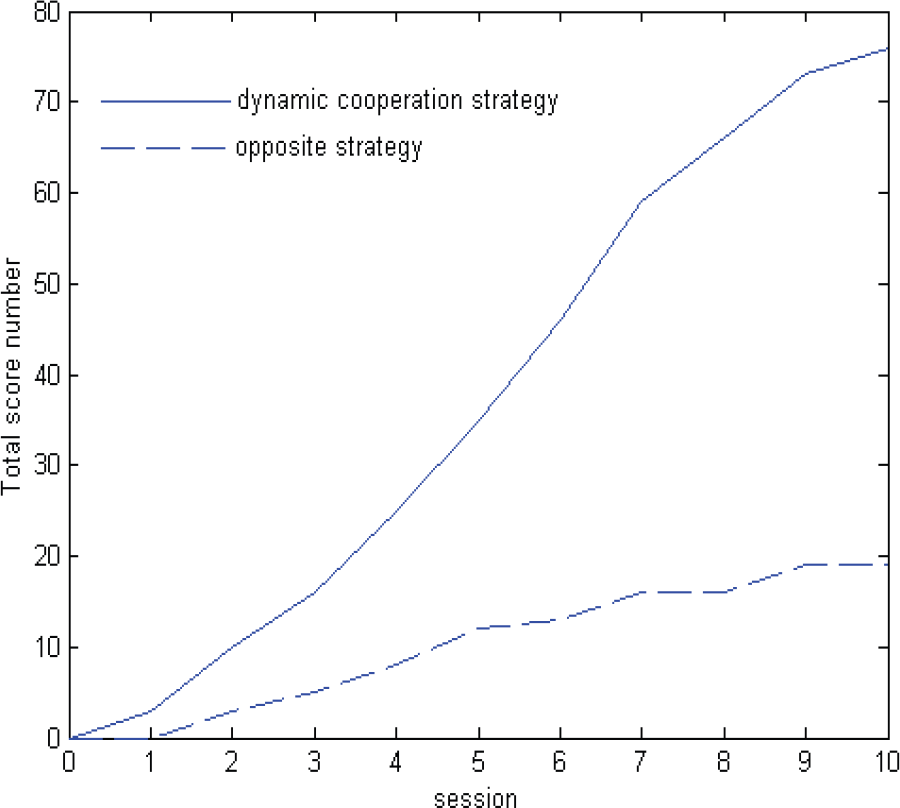
Total score comparison between the team adopting dynamic cooperation strategy and the rival

Total score comparison between the teams adopting no machine learning strategy and the rival
Reinforcement learning is combined with BDI thinking model in this paper and the dynamic cooperative model is formed in view of multi-intelligent robots. In this model, the concept of the individual optimization has lost its meaning. All intelligent robots can pursue a common optimum solution, and try to realize the united intention as a whole to a maximum limit. Because the space searched for reinforcement learning is quite large, in order to accelerate the optimum solution convergence, one of the robots that cooperate with each other is controlled by man with a joystick. In this way, the intelligent robot can be ensured to search for each a couple of state-action as frequently as possible when it carries on choosing movements, so as to shorten the time of searching for the movement space so that the convergence speed of reinforcement learning can be improved. In the simulation robot soccer match (11 vs 11), the validity of the cooperative strategy proposed in this paper has been proved.