
Abstract
A strategy system with self-improvement and self-learning abilities for robot soccer system has been developed in this study. This work focuses on the cooperation strategy for the task assignment and develops an adaptive cooperation method for this system. This method was inspired by reinforcement learning (RL) and game theory. The developed system includes two subsystems: the task assignment system and the RL system. The task assignment system assigns one of the four roles, Attacker, Helper, Defender, and Goalkeeper, to each separate robot with the same physical and mechanical conditions to achieve cooperation. The assigned role to robots considers the situation in the game field. Each role has its own behaviors and tasks. The RL helps the Helper and Defender to improve the ability of their policy selection on the real-time confrontation. The RL system can not only learn to figure up how Helper helps its teammates to form an attack or a defense type but also learn to stand a proper defensive strategy. Some experiments on FIRE simulator and standard platform have been demonstrated that the proposed method performs better than the competitors.
Introduction
Many independent agents cooperate to accomplish a certain goal and this type of system is a multiagent system (MAS). 1,2 The MAS is a very common research topic in the artificial intelligence field. The existence of many other agents makes MASs usually uncertain and dynamic. We must consider the impact of other agents in the system on the agent that we focused on. Therefore, MASs are usually more complex than single-agent systems. The robot soccer system recently became a very popular platform for the research of multiagent technology, which includes many confrontational and collaborative tasks. 3 The collaborative is crucial for MASs because different agents have different behaviors, and the ultimate goal is to win the competition. However, it is difficult to develop an effective strategy for well-defined state-action mapping in an uncertain and dynamic environment. Therefore, an effective learning mechanism is very necessary, which can help agents adapt to unknown environments to achieve predetermined goals. 4
One of the most promising technologies for creating coexisting agents is reinforcement learning (RL), which is commonly used for policy selection. 5,6 In Hwang et al., 7 the authors have developed an adaptive decision-making technology that uses RL for robot soccer games. Robots can autonomously learn a good strategy after many iterations of learning. In addition, the RL methods are applied to tackle the cooperation problem in social dilemmas with the assumption of Nash equilibrium. 8 Multiagent RL is mostly based on a Markov game framework. 9 Some simple methods that do not consider the impact of other agents have been proposed. However, an obvious disadvantage of this method is that it takes a lot of time to converge, as the complexity of the environment increases, such as win or learn fast-policy hill climbing. 10 It is necessary to take other agents into consideration for multiagent RL, such as the Nash bargaining solution learning algorithm. 11 However, it also takes a lot of time on the learning process because of enormous Q-Table.
Multiagent RL uses general-sum stochastic games as a decision-making framework. A Q-learning method generated in this framework has been proved to converge to a Nash equilibrium under specified conditions. 12 Q-learning is a very simple way to realize a RL system. This method can effectively find the optimal strategy for scenarios with a unique Nash equilibrium. 13 The classical RL system only considers the states and actions that have been taken by agents. This method is very useful for practical applications, but it is often helpless for complex tasks. One potential solution is game theory. Recently, advances in deep learning have made it possible to extract high-level features from sensory data and which provides an opportunity of scaling to problems with infinite state spaces for the RL algorithms. 14,15 Besides, in robot soccer games, it is essential to adjust strategies for agents to cooperate effectively without baselines of deep learning while facing a competition. 16
The method for balancing individuals and collecting more positive feedback has recently become a hot topic for the task assignment in robot soccer systems. It is the ultimate goal for the collaboration to maximize the collected payoff. Poor collaboration capability will lead to a collaboration dilemma, which will have a negative impact on MASs. Therefore, the collaborative capability is very important for an MAS. If agents stay in the same state in a certain sojourn time, the cooperation between agents is deteriorating over time, and the dilemma of synergy will arise. 17,18 The learning process will stagnate if the agent cannot move. Furthermore, the collaboration dilemma will become worse and worse, as the number of agents increases and the efficiency of learning will be affected. 19 Previous works using centralized optimization faced a lot of computational costs while they got an opportunity for developing an efficient collaboration. 20 So, it is often feasible that depends on decentralized optimization schemes.
This work investigates the cooperation strategy for the task assignment in the robot soccer game. Firstly, this article proposed a task assignment method to determine the temporal task for each player with local information. Secondly, after the temporal task assignment, an RL method enables the individual player to achieve the best policy for searching the most appropriate position in zero-sum games. The RL method is derivated from a determined algorithm with built-in reward mechanisms to produce a policy for matching roles and players based on real-time situations. Finally, each robot with respective roles works as a team to contribute to the achievement of the global goal cooperatively.
The main contribution of this article is to develop an adaptive cooperation strategy system to zero-sum game scenarios for the robot soccer system. The cooperation among multirobots is achieved by a task assignment system involving the RL inspired by game theory. Each role in the game behaves primitively. The RL helps the Helper and Defender to improve their policy selections on the game field. The developed RL system is responsible for guiding the helper to form an attack or a defense type to assist its teammates. Meanwhile, it helps robots learn appropriate defensive strategies. The proposed method addresses the dilemma of a cooperation strategy for task assignment and does not require more empirical parameters than deep RL. It is very advantageous for the soccer robot system because of the self-adaptability of the proposed strategy.
This article is organized as follows: The second section describes the proposed method. The proposed method consists of task assignment and RL. Following the second section, some experiments are performed in the “Experiments” section. Experimental results demonstrate the proposed method outperforms some competitors. Finally, a conclusion is made in the last section.
Proposed method
There are two parts included in the proposed method: the task assignment and the RL. The role of each robot is assigned by the task assignment. Each agent takes actions depending on the environment states and their role and modify the action by RL method.
The task assignment
Four roles are assigned to robots by the task assignment system. The Goalkeeper, Attacker, Helper, and Defender are the four roles in this robot soccer game. Make the ball move to the opponent’s field is the final goal, which is the job of the Attacker. In a robot soccer game, the target of a soccer game is to achieve a goal and gain more scores. Therefore, the attacker becomes the first role to assign. The position of the robot is the essential factor for selecting the attacker because a fast and precisely attack is important. Therefore, we need the robot to get the ball within a short time and kick the ball in the correct direction at the same time as an attacker. First and foremost, we must identify which robots are on the good side according to the coordinate frame.
The center of the ball is defined as the origin of the coordinate frame. Its X-axis passes through the center of the opponent’s door and center of the ball, as shown in Figure 1. The Y-axis is perpendicular to the X-axis. The Z-axis is through and normal to the field plane.

The rule to select the attacker.
Robots locating in the regions of phase I and phase II are on the good side. The new coordinate frame is evaluated easily since the positions of robots, ball, and door are already known in the world coordinate frame. The position for a robot required to be determined is only the translation on the X-axis and Y-axis and rotation about the Z-axis of the world frame. The transformation matrix is given by

where the center position of the ball is (xball, yball). The angle is θ, which is shown in Figure 1. Each position of the robot with respect to the new frame can be computed by

where the position for the robot is
The goalkeeper’s work is staying in front of our goal and follows the ball’s Y-coordinate position in rules. The second role is to assign a defender because the second vital job in a confrontation is to stop the opponent’s goal. The robot nearest to our goal is assigned to play the defender.
Helping the attacker or defender finishing their task is a Helper’s job. Two robots are assigned the third role, the Helper. RL helps the helper make wise decisions. When a game starts, helpers move to the position where they can support attackers and defenders, depending on the situation of the game field. Three formations are designed, which are attack formation, normal formation, and defense formation. For the attack formation, two helpers are assigned in front of the attacker. While in the normal formation, the attacker is surrounded by the two helpers. The two helpers are behind the attacker in defense formation. Accordingly, we can assign the Helper role to the robots closest to these two positions in the current formation.
The job for the defender blocks and prevents the opponent from getting a goal. The defender needs to move to the position, which can help the goalkeeper to stop the opponent from gaining a goal as well. So, three different positions can be chosen. Accordingly, the role also uses RL. The defender will be the last to be assigned. Therefore, the defender is assigned to the remaining robot that is not yet assigned any role.
The RL method inspired by game theory and eligibility traces is used for the helper and defender. Although they have different learning goals, they use the same method to partition states and have the same number of actions. The ball’s position, speed, and direction are included in the state space because they are the most necessary information in a robot soccer game. We use linear tile-coding function approximation 7 (also known as Cipher-based message authentication code (CMAC) 8 ) to represent the information. Therefore, the game field is partitioned into 6 ×9 = 54 blocks to indicate the coordinate for the ball, the eight directions in which the ball is moving, and two-speed level indicating the speed of the ball. The robot closest to the ball is considered, whether our robot or opponent is. For each learning agent, it has three actions to choose from. Three actions are mapped to three different formations for the RL agent of the helpers, which are attack formation, defense formation, and normal formation. According to the attacker’s position, these formations are generated. These formations are shown in Figure 2.
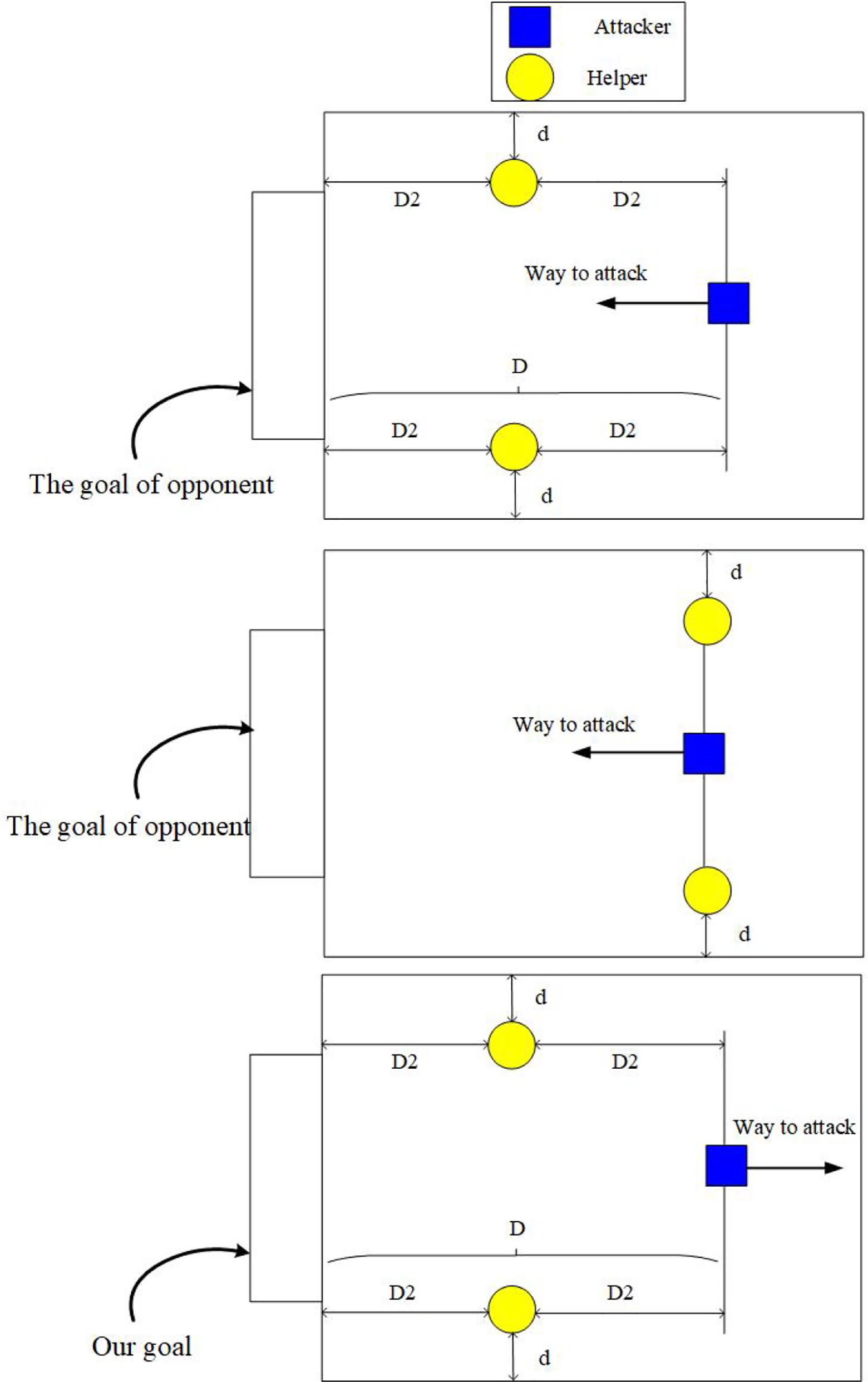
The rule to generate three formations.
RL for robot soccer
Previous works apply the game theory to Q-learning. 21,22 Our agent usually takes action on the basis of the opponent’s action in a two-player zero-sum game. 23 The opponents will choose the best action for themselves, but it may be the worst for us. If we want to win in a terrible situation, we need to take action as good as possible, which means that before we choose the action, we need to consider the actions of opponents first. The original Q-learning rule is given by

where the state is represented by s, the action is represented by a, the action set is represented by A, the learning rate is represented by α, the discount factor is represented by γ, and the reward is r. The action taken is only considered in equation (1) and which tries to maximize the Q value in the future. So, previous works use
The

The proposed method uses the eligibility traces 24 and the replace-trace mechanism for RL. Many previous works use the eligibility traces for RL. Take TD(λ) as an example. The eligibility traces are represented by λ, which produces a more general method. Then, the update law for Q value is given by

where


where the discount rate is γ, and λ is the trace-decay parameter. At the time t, the eligibility trace for the state s is
This RL method is called the confrontation Q method. It is basically identical to the standard Q-learning algorithm with eligibility traces and zero-sum game theory. Figure 3 shows the complete algorithm using pseudocode.

Confrontation Q method.
The defender can choose three different positions. According to the current position of the ball, these positions are generated. First, the middle position is calculated between the ball and our goal. Next, the last two positions are calculated. Figure 4 gives the detail.

Three positions for the defender.
Learning to position using RL
For the confrontation Q method, the opponent’s action is needed to know. However, it is not clear what action the opponent is going to actually choose in a real-time situation. Thus, we need to observe the opponent’s state. Although the opponent’s action set cannot be known to us, the opponent’s position is observable. This information for opponent’s position can be used as the action set of the opponent. The opponent team has five robots, and every robot will move to a new position. If the information for the whole opponent team is used, the number of states will become too huge. Therefore, the most important robot, that is, the opponent’s attacker, is the only one that needs to be observed. The opponent robot, which is nearest to the ball, is chosen to be the opponent’s attacker. The CMAC is used to partition the opponent’s action. We partition the filter into 16 cells. The ball is located in the center of the circle. The radius of the outer circle is 6 and the radius of the inner circle is 3. Figure 5 gives the detail for the filter. These two separate reward mechanisms for different roles.

Decompositions of an opponent’s position into 16 cells. The radius of the outer circle is 3 and the radius of the inner circle is 3.
The rewards for the helpers are as follows: Get point: get reward +1; Lose point: get reward −1; Become the Attacker: get reward +0.5.
The rewards for the defender are as follows: Lose point: get reward −1; Become the Attacker: get reward +1.
It needs some time to execute the action we choose. If we always find a new action, there will be no time to execute well for the previous action. When the RL agent starts to learn, it will go wrong. Therefore, a new action is chosen when the attacker’s role is changed. The robot as the attacker will be changed in some cases using the rules of role selection, which means that it is not changed all the time. Hence, the execution time of the previous action is guaranteed.
Experiments
Some soccer games are performed on the simulation platform and real-world platform. The simulation is performed on the Federation of International Robot-soccer Association (FIRA) 5-versus-5 simulator. 25 The real-world environment is the standard robot soccer game platform. 26 We set some competitors to demonstrate the effect of the proposed method. The competitors are the minimax-Q learning method 27 and the renowned Q(λ)-learning method. 28 The eligibility traces technology is used in the Q(λ)-learning method. The minimax-Q method combines game theory and Q-learning. In these experiments, the computer CPU is Pentium 4 1.4G.
We trained robots with three different primitive behaviors, which are moving for target, collision avoidance, and shooting for goal. We place a robot at the center of the FIRA field. For collision avoidance, in the beginning, the robot takes random movement. The reward mechanism makes robots gradually learn to avoid obstacles. For the moving for target, the robot will learn a policy for moving to a certain orientation with assignment posture to arrival at the required position. There will still be a slight tolerance. For shooting for goal, the robot will shoot on the line between the center of the goal of the opponent and our ball after it moved to the required position.
Experiments on FIRA 5-versus-5 simulator
The first experiment on the FIRA simulator included three kinds of matches and every match has some rounds. The simulator is shown in Figure 6.
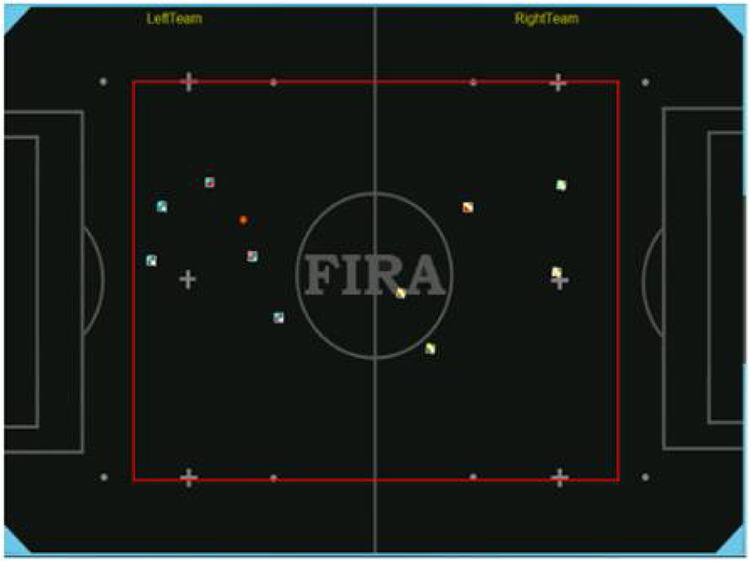
FIRA 5-versus-5 simulator. FIRA: Federation of International Robot-soccer Association.
Each round lasts 10 min. One team that uses the Q(λ)-learning method is used to play against another team that uses the default algorithm, Lingo, in the first match. The Lingo is a well-established baseline method and it has already been set well in the FIRA game. In the second match, one team using the minimax-Q learning method is used to play against the other team using the Lingo method. In the third match, one team using the proposed method is used to play against the team using the Lingo. Figures 7 –9 show all results for the first experiment.

Proposed method versus Lingo: all scores. (a) Proposed method scores log and trend line. (b) Lingo scores log and trend line. (c) Proposed method win scores log and trend line.
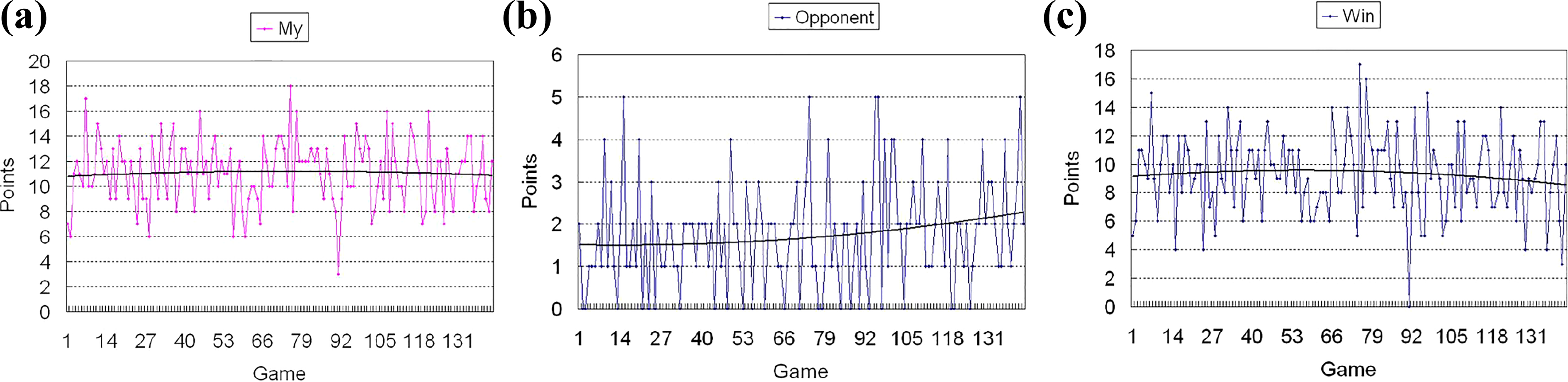
Minimax-Q versus Lingo: My scores. (a) Minimax-Q scores log and trend line. (b) Lingo scores log and trend line. (c) Minimax-Q win scores log and trend line.

Q(λ)-learning versus Lingo: My scores. (a) Q(λ)-learning scores log and trend line. (b) Lingo scores log and trend line. (c) Q(λ)-learning win scores log and trend line.
In each figure, the horizontal axis and the vertical axis indicate the number of rounds and the total scores the team gets, respectively. Figures 7 –9 show the experimental results for the three matches. In Figure 7, Figures 8, and 9, The symbol My, respectively, represents the proposed algorithm, the minimax-Q learning method, and Q(λ)-learning method. Each figure uses two kinds of lines. One of the lines is the saw-tooth-like line, which is formed by connecting the scores got from each game. The other is the smooth line, which is the tendency of the saw-tooth-like line. The global view about the scores changing trend is showed by trend line (smooth line). From experiment results, in each match, the Lingo method is always defeated. However, the points for beating the Lingo method are always different. So, we use three different curves to show the experiment results, which are the score for “My,” the score for Lingo, and the win score for this match. The win score means how much more than the score of other side. From the results, the proposed method beats more points than the minimax-Q learning method and Q(λ)-learning method, about 17 points, which shows that the proposed method is more effective.
The second experiment has three kinds of matches. In the second experiment, each kind of match is similar to the first experiment, but the opponent uses a rule-based strategy 29 instead of the Lingo method. The opponent that uses the rule-based strategy has a better behavior than the Lingo method. Figures 10 –12 give the experimental results. The experimental results show that the opponent’s score decreased faster when competing with the proposed method. The results further illustrate the validity of the proposed method.
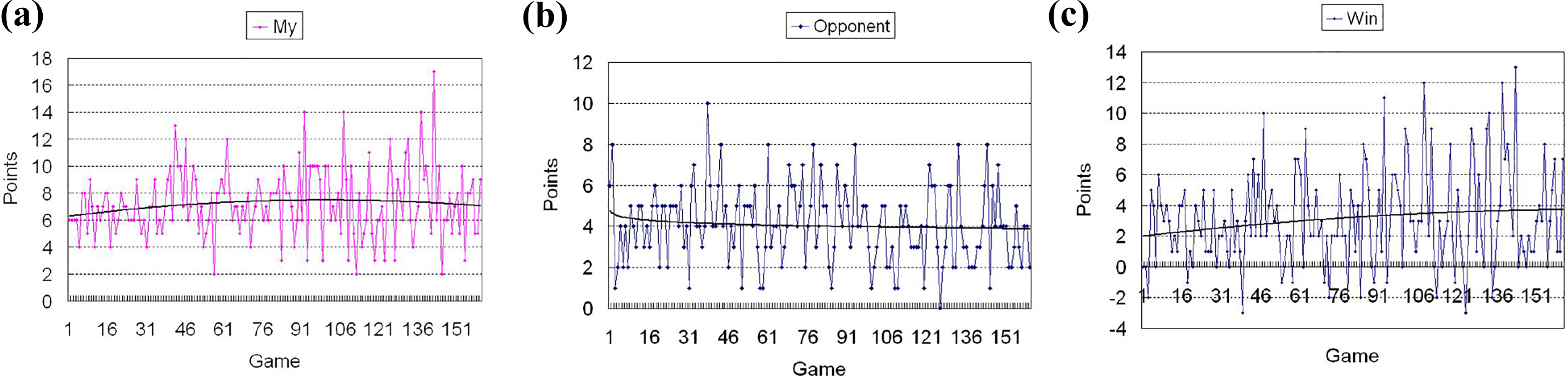
Q(λ)-learning versus rule-based strategy: My scores. (a) Q(λ)-learning scores log and trend line. (b) Lingo scores log and trend line. (c) Q(λ)-learning win scores log and trend line.

Minimax-Q versus rule-based strategy: My scores. (a) Minimax-Q learning scores log and trend line. (b) Rule-based strategy scores log and trend line. (c) Minimax-Q learning win scores log and trend line.
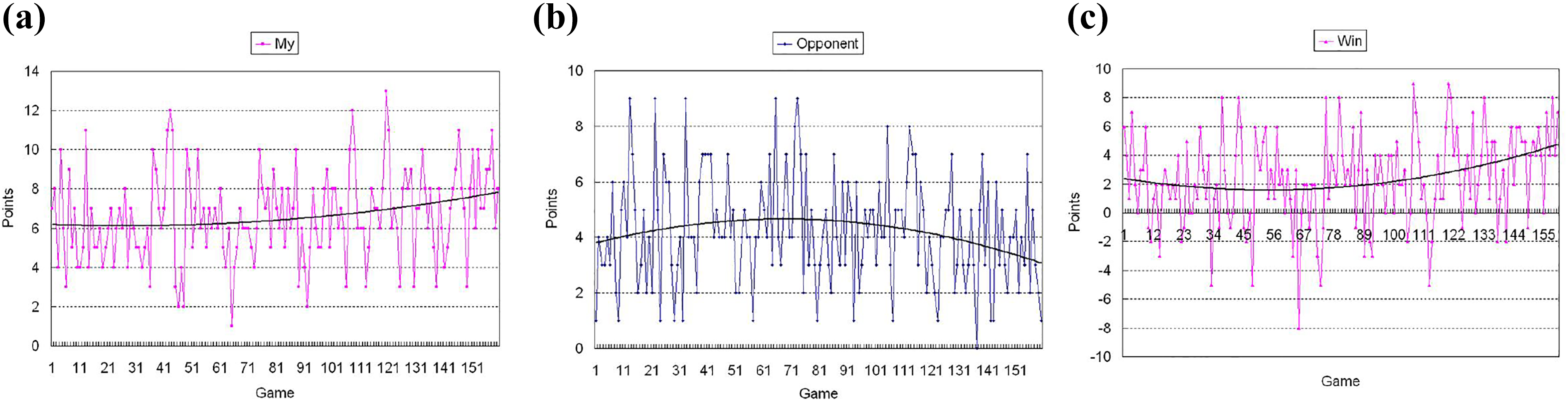
Proposed method versus rule-based strategy: My scores. (a) Proposed method scores log and trend line. (b) Rule-based strategy scores log and trend line. (c) Proposed method win scores log and trend line.
Experiments on the standard platform
The environment of the real-world experiments is shown in Figure 13. Two teams are placed on the platform. One on the right side is the team trained by the simulator and the opponent with no training experience. Similar to the simulation, two matches are performed on the standard platform. The results for competition between these two teams are recorded for comparing the performance of the proposed method. The first match uses the Lingo as the baseline method for comparing the results of the minimax-Q learning method and Q(λ)-learning method. Then, the second match uses the rule-based strategy instead of the Lingo as the challenger for three learning methods.

Standard platform for robot soccer.
Table 1 presents the results of the first match. The experimental results show that the proposed method wins the opponent about 11–12 scores. Meanwhile, the Q(λ)-learning wins the opponent about 9–11 scores and the Minimax-Q method wins the opponent 9 scores. The experimental results show that the proposed method has the highest score compared with the other two methods.
Results of the first match.

Table 2 presents the experimental results for the second match. In this table, if our side uses the proposed method, the score of the opponent is decreased a lot. The results show that the proposed method has better performance than the Q(λ)-learning method and the minimax-Q method. In the case of fighting against different opponents, the experimental results demonstrate that the proposed method can show superior performance.
Results of the second match.

Conclusion
The proposed method is based on the confrontation Q method. Each agent’s appropriate rules are assigned by using the task assignment system and the RL to adapt to the environment has been demonstrated. The task assignment system can assign a better attacker in time to make sure that the team can get more scores. In addition, the appropriate agent is assigned by the task assignment system for defense, which makes the opponent’s goal get much less than other methods. Moreover, according to the environment condition, the dynamic role assignment can make the response of a team faster than the fixed role assignment method. The proposed method learns the best strategies, which are based on the identified compositions of factors that represent a variety of situations in the game field with the help of the RL. According to the results of these experiments, comparing with the other two kinds of the baseline method, the proposed method has better cooperation results.
In the robot soccer games, each robot’s commands asserted by the learning system are actually carrying the mixture of time-triggered and event-triggered task sets, which communicate over protocols consisting of both static and dynamic phases. 30,31 How to partition and schedule the system functionality into these two domains, which are event-triggered and time-triggered domains, is the focus of our future work. Corresponding to the communication protocol, the optimization of parameters is essential for the future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by the Natural Science Foundation of Hubei Province under Grant 2013CFC026 and in part by the International Science and Technology Cooperation Program of Hubei province under Grant 2017AHB060.