
Abstract
We present an autonomous assistive robotic system for human activity recognition from video sequences. Due to the large variability inherent to video capture from a non-fixed robot (as opposed to a fixed camera), as well as the robot's limited computing resources, implementation has been guided by robustness to this variability and by memory and computing speed efficiency. To accommodate motion speed variability across users, we encode motion using dense interest point trajectories. Our recognition model harnesses the dense interest point bag-of-words representation through an intersection kernel-based SVM that better accommodates the large intra-class variability stemming from a robot operating in different locations and conditions. To contextually assess the engine as implemented in the robot, we compare it with the most recent approaches of human action recognition performed on public datasets (non-robot-based), including a novel approach of our own that is based on a two-layer SVM-hidden conditional random field sequential recognition model. The latter's performance is among the best within the recent state of the art. We show that our robot-based recognition engine, while less accurate than the sequential model, nonetheless shows good performances, especially given the adverse test conditions of the robot, relative to those of a fixed camera.
Keywords
1. Introduction
Cognitive robotics has seen a surge of interest and attracted huge research endeavours over the last few years. Unlike the first robot generation, designed for specific repetitive industrial tasks, the new generation features robots as human partners endowed with cognitive capabilities, not with the aim to replace humans but rather to assist them in a collaborative way. Robots can be used interactively for entertainment [1], for education by assisting in learning a new language, or for both, through imitation [2]. Promoting the learning of a new activity in this way may help an elderly person maintain an enjoyable and healthy life. Robots can also assist a frail person in performing activities of daily living (ADLs). Although people prefer to grow old in their own homes, age-related impairments of physical, perceptual, and cognitive skills can make the performance of domestic tasks increasingly challenging [3]. The maintenance of independence and health requires all these skills, and includes self-maintenance tasks such as ADLs (e.g., the ability to use the toilet, feed and dress oneself); instrumental ADLs, or IADLs (e.g., using a phone, shopping, preparing food, housekeeping, managing medications and finances, and using transportation); and enhanced ADLs, or EADLs (e.g., social or hobby activities, and learning new skills). Scores of robots have been developed to support ADLs, IADLs, and EADLs, as part of elder assistance at home, mainly to support ambulation (an ADL) (i.e., reducing the need to move, supporting physical movement), housekeeping (an IADL), and social communication (an EADL). Most robots, nonetheless, are still remotely controlled using a computer or other device, as illustrated by the recent work in [4]. As a result, natural human-robot communication is hindered, thus limiting the potential of assistive robotics. It is key, therefore, to enable human robot interaction by means of natural sensory stimuli: speech, vision, touch, etc. [3]. While successful speech-based robotic applications are quite mature, vision-based applications are fewer and restricted to limited tasks. This can be explained by the previous limits in processing and storage power that were more suited to speech than to image (not to mention video) data, and also by the complexity of classifying object and human motion w.r.t. speech. Speech and vision, nonetheless, are both necessary to a cognitive robot: speech is less reliable in noisy settings, such as when sounds are emanating from the TV or surrounding home devices, or coming in from outside. Video can efficiently complement speech in such situations. Furthermore, vision robotics allow for smart applications such as gesture-based communication for people with speech-language disorders, as well as human-robot interactions stimulating physical exercise, rehabilitation and entertainment.
In this paper, we present an assistive robotic system developed for JULIETTE, a project that aims to integrate machine vision algorithms into the robot Nao, allowing it to recognize ADLs performed by a person in a smart home. Such a system could serve several purposes: detecting an abnormal event like a person falling down or not taking medication; reminding the user to close the door upon leaving the house; or engaging in an imitation game for entertainment or physical exercises. Nao has several advantages over a fixed camera or robot. First, its empathic look makes it friendlier and less likely to be perceived as intrusive. Second, Nao can move to seek locations that accommodate changes in lighting and occlusions, while ensuring good camera coverage within a suitable distance of the person. Third, thanks to Nao's humanoid character, a smart scheme can be designed to leverage on its cognitive capabilities and human-like sensory stimuli to allow it to act in a collaborative way. Upon recognizing a person fall, for instance, the robot can get close to the fall location and ask the person whether he/she is OK, in order to ascertain whether a fall had actually taken place. This is important, as falls — and most human motions, in fact — are inherently ambiguous when occurring in real-life. Nao can also be tuned according to user preferences, which increases its appeal among potential users. In this work, we have considered ADLs like walking, sitting down or opening doors, as well as an emergency event (falling down) and an imitating activity (applauding). We have deliberately included some ADLs with low motion content, like writing, so as to assess the robot's vision limits. Unlike a fixed camera or robot, Nao is able to change its location. This entails different levels of variability when dealing with background and lighting conditions, depending on the location of windows, lights being turned on or off, the presence of shadows, different viewing angles and distances of the robot w.r.t. the person, etc. On top of this, as the robot's vision capabilities are to be tested over several days, the above conditions are made even harder; the presence of people with different clothes and habits can make recognition a challenging task.
The main issue for implementing video-based activity recognition in the robot is the conflict between the high demands of video processing and the robot's limited computing resources. One of our main contributions is to show how optimizing vision algorithms and robot settings can help ensure a good recognition performance. It is worth noting that most current robot-human activity or gesture interaction systems are based on a Kinect camera [5–8]. As a result, these robots need the Kinect sensor for data acquisition, as well as a computer to process the skeleton and RGBD raw data on one hand, and to serve as an interface between the Kinect and the robot on the other. In contrast, our aim in this paper is to allow the robot to be autonomous, relying only on its own camera for video acquisition and its own memory and processor for classifying the human activities. To the best of our knowledge, this is the first attempt to implement a full vision-based activity-recognition engine inside a robot. Our task is thus made more complex, as high-level skeleton data are not available and robust image processing is required to extract the relevant motion information. To achieve such a goal — and given Nao's limited storage and speed resources — drastic constraints were enforced both on the robot's settings, in terms of frame rate and image resolution, and on the duration of the video sequences filmed by the robot. These settings are detailed in Section 4.3.
A number of different approaches have been taken to video-based human gesture/action recognition by robots over the past few years. In [9], the authors propose a gesture recognition system in an interaction scenario restricted to hand movements within the image plane. A skin-colour Gaussian model is used to detect the face and hands, which are tracked by a Kalman filter to generate the gesture trajectories. A simple histogram of the trajectory points is then used for classification. The system was implemented in a Nao robot, but no classification and speed performances are reported. Moreover, the system relies on several manual tuning and heuristics on colour variations and hand positions, and is restricted to a small range of lighting variations. In [10], an approach to action recognition was proposed and evaluated based on video arm actions. First, human action primitives and object state changes are learned in an unsupervised way. Parametric hidden Markov models would then represent the movement trajectories as a function of their desired effect on the object. In [11], a simple hand gesture recognition system for a human-robot interface is proposed; the gesture involved pointing to a calendar in an outdoor environment. The system relies on a GMM method to segment the hand and thus implicitly recognize the pointing gesture, owing to its simplicity. For convenience, the prototype system adopts a notebook as the server processing the input images. In [12], the authors present a vision-based human robot simulation of the “Chalk, Blackboard, Duster” game, in which the robot identifies three simple human gestures. The humanoid robot HOAP-2 simulated in the Webots platform is used for this purpose. Using OpenCV, the HSV histogram is harnessed to detect the skin colour pixels and thus locate the hand. A set of 10 features based on hand dimensions — such as normalized palm area or height — are extracted and inputted into a neural network, in order to learn the gestures.
As can be seen above, most recent studies have been restricted to recognizing simple gestures involving only hands, which are made in front of the camera and close enough to the robot, thus making relevant image and motion information quite easy to extract. Our work is instead targeted at complex human motion involving all part of the human body in adverse conditions (with occlusions, view angle and distance variations, etc.).
Aside from the robotics perspective, vision-based human action/activity recognition (HAR) approaches can generally be classified into holistic approaches [13] and local approaches [14]. The first category employs explicit body representation, by extracting features from the silhouette using 2D image features or 3D features obtained from human joint angles. These approaches, however, require background subtraction and/or body tracking, which are unreliable in real-life scenes with fast non-linear motions and occlusions. As a result, these methods have attracted less interest recently. The second category uses local interest points (IPs) and can provide a sparse concise representation of motion events, without resorting to foreground/background segmentation and tracking. As IPs cannot be extracted in a well-defined spatio-temporal order for each frame, in a manner that would make the extraction of a feature vector feasible for each time step, a bag-of-words (BOW) representation is instead adopted: an approach that overlooks this order while encoding partial spatio-temporal information through the local representation of each IP neighbourhood.
Because of the relative success of the BOW+SVM paradigm over holistic approaches, most recent methods have sought to enrich the basic BOW representation and the related SVM classifier. The BOW representation has thus been enriched by various types of context, such as video binning, encoding IP trajectories, IP neighbourhood characterization, and pyramidal representation [15–18]. Nevertheless, one serious limitation of these approaches is that IPs may be too sparse for slower motions. In this work, we make use of dense interest point trajectories [19], as they generate a denser interest point motion representation. This is critical for ensuring recognition robustness w.r.t. motion speed variability across users. IP trajectories are characterized by various descriptors like HOG and HOF. Unlike the approach used in [19], we concatenate these descriptors into one long descriptor to ensure processing efficiency within the robot. In addition, our recognition model harnesses the dense interest point BOW representation through an intersection kernel-based SVM (IKSVM). The intersection kernel can better accommodate the large intra-class variability inherent in human activity recognition by a robot from different locations and operating under different conditions (view angle, illumination, distance, occlusion, etc.). The above scheme is efficient since, as the BOW representation is a concise motion sequence description and SVM is a sparse classifier relying only on a small subset of support vectors for classification, the storage requirements of our BOW-IKSVM model are suitable for integration into the robot.
We also propose, in this paper, a new and fundamentally different approach to human activity recognition that explicitly models the sequential aspect of the video sequence. The modelling is based on a two-layer support vector machine/hidden conditional random field (SVM-HCRF), in which the SVM acts as a high-level discriminative front-end feature extractor. First, the video sequence is split into short overlapping segments of fixed size, through a sliding window technique. Each segment is described by a local BOW, associated with the histogram of dense interest points enclosed in the segment. A first layer classifier — specifically, a one-vs.-all SVM — converts each BOW into a vector of class-conditional probabilities. The SVM acts as an extractor of high-level discriminative features from the raw BOW data. The sequence of these vectors serves as the input observation sequence to the HCRF for the actual human activity recognition. This hierarchical modelling optimally combines two different information sources characterizing activities: the temporally local motion content, the discriminative power of which is inferred by the SVM; and the long-range motion feature dependencies modelled by the HCRF. This scheme also allows for a drastic feature dimensionality reduction, which prevents overfitting and increases not only processing speed but also recognition accuracy. Although this approach does outperform BOW-IKSVM, it requires a feature representation at each time step and hence takes longer to make a decision. Thus, we did not implement it within the robot, but will instead compare it with the BOW-IKSVM model — and with the most recent state-of-the-art HAR methods — using three popular public databases, so as to contextually assess the performance of BOW-IKSVM implemented in Nao.
The remainder of this paper is organized as follows. Section 2 describes the stages of the human activity recognition system implemented in the robot Nao, consisting of human motion encoding and IKSVM-based ADL recognition. Section 3 details our two-layer SVM-HCRF-based approach for human activity recognition implemented on public datasets (not implemented in Nao). We then present the experimental phase by first comparing the system implemented in Nao with recent state-of-the-art HAR methods implemented on public datasets, including our SVM-HCRF model. The following sections deal with HAR experiments with the Nao robot in real-life conditions, and discuss test setting and the results obtained by Nao in terms of accuracy and speed. Finally, we draw conclusions and sketch the future directions of our work.
2. The human activity recognition system implemented in the Nao robot
2.1 Motion encoding by dense trajectories
The current state-of-the-art methods for video feature extraction are based on local interest points (IPs). IPs are usually detected through an optimization stage, for instance by extending the Harris detector to three dimensions (time being the third), leading to the popular spacetime interest points (STIPs) [14]. Each IP is characterized by descriptors of surrounding gradient and optical flow information: namely, histograms of gradients (HOG) and histograms of optical flows (HOF). These approaches — when the STIPs are plugged into a BOW representation, which is inputted into a static (usually a support vector machine (SVM)) classifier [16] — achieve state-of-the-art performance for human action recognition. Nevertheless, they suffer from two limitations. First, the IPs may be too sparse for relatively slow motions, leading to poor characterization. Second, the characterization of IPs according to their local neighbourhood (through the HOG/HOF) prevents the capture of long-range motion dependencies. More recently, inspired by recent progress in dense sampling for image classification and trajectory-based action recognition, Wang et al. [19] tackled these two issues by combining dense sampling with the tracking of each IP, in order to describe its trajectory rather than its immediate neighbourhood. As the robot is intended to recognize motions of different speeds, made by a range of different people, we used the dense trajectories proposed in [19] to accommodate this variability. Figure 1 gives a pictorial summary of motion description through dense trajectories.
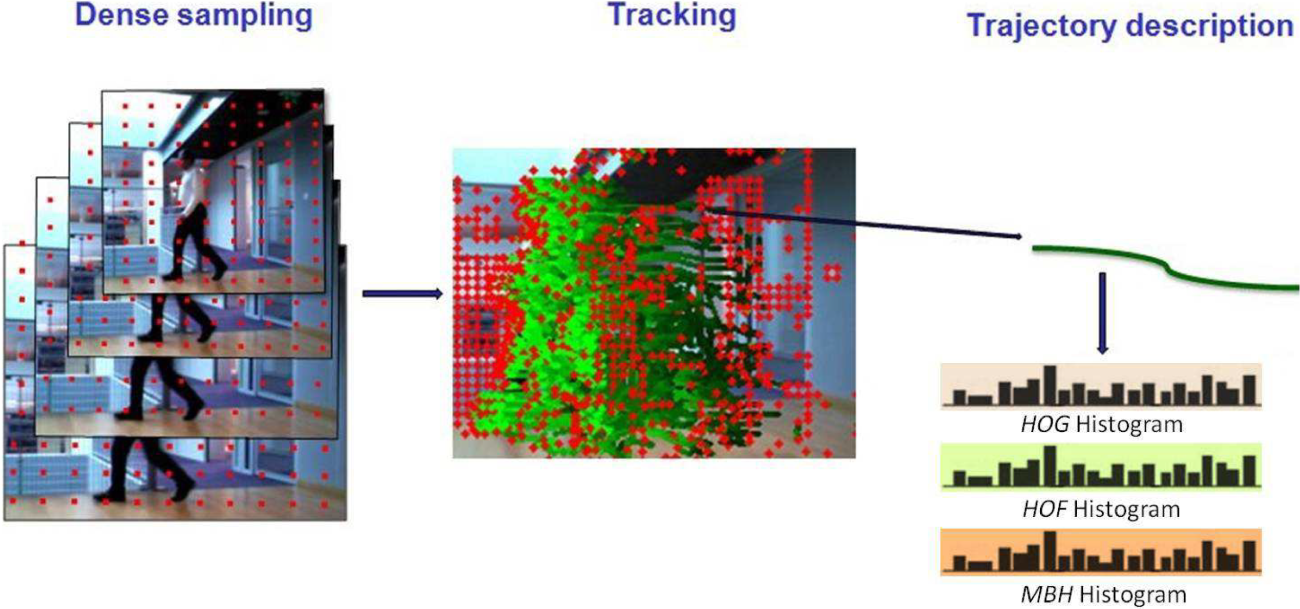
Description by dense trajectories (in green). The red dots show the sampled interest points.
Dense frame feature points are uniformly sampled by considering eight spatial scales. Within each scale, feature points are tracked over L=15 frames by a median filtering kernel operating on a dense optical flow, extracted using the algorithm in [20]. Several strategies are used to ensure the extraction of relevant trajectories: trajectories are limited to L frames to avoid drifting; in homogeneous image areas lacking any structure, of which tracking would be impossible, no track points are sampled; and finally, static trajectories are discarded, as they convey no motion information, and trajectories with large jumps are pruned, as they are usually erroneous. We use three descriptors generated from a 3D spatio-temporal volume surrounding each trajectory. In addition to the HOG and the HOF, the third descriptor is the motion boundary histogram (MBH) based on the optical flow field spatial horizontal and vertical derivatives (MBHx, MBHy) and the quantization of the orientation of each into histograms like the HOG. The MBH focuses more on foreground motion and is robust to camera motion. The HOG, HOF, MBHx and MBHy orientations are quantized over eight bins, with an additional bin for the HOF, and are thus encoded by vectors of dimension 96, 108, 96 and 96, respectively. The resulting vectors are normalized by the L2 norm. In our work, we used the combination MBH/HOG/HOF (dimension = 396) as the IP feature descriptor, since it has shown optimal performance. The obtained vectors were then converted into a BOW histogram of dimension D, by k-means clustering and a nearest-neighbour assignment process. Figure 2 shows an example of dense trajectories evolution for a falling motion. We observed that, for dense points not involving any person or object motion, barely any trajectory is generated.

Dense trajectories for a falling motion over three frames
2.2 Classification of ADLs
To allow Nao to recognize ADLs, we have employed support vector machines (SVM): a machine learning model that possesses appealing properties such as margin maximization and the kernel trick, allowing for a seamless non-linear mapping of the feature vectors into huge dimensional spaces, in which linear class separation is easier. Another nice feature of SVMs is their limited storage requirements, as they rely on and store only a sparse set of training support vectors for recognition. The most used SVM kernel for action recognition is either the RBF or the χ2-based RBF kernel [16]. However, we have instead used an intersection kernel-based SVM (IKSVM) [21]. For two BOW histograms

This kernel has been shown to be more suitable for our ADL set. Owing to the fact that the activities were carried out in different locations under several variability factors, intraclass variability is inherently high. The intersection kernel is more suitable for detecting same-class similarities than other types of kernels.
3. Human activity recognition applied to public video action datasets
Our novel approach to HAR in general (not limited to its implementation in a robot with low resources) does not seek to improve recognition accuracy by improving current state-of-the-art IP-based features and their contexts while keeping a global video description. Instead, it seeks to explicitly model the temporal order of actions and at the same time harness the representative power of spatiotemporal interest point features. The modelling is based on a two-layer support vector machine/hidden conditional random field (SVM-HCRF) in which the SVM acts as a high-level discriminative front-end feature extractor. First, the video sequence is split into short overlapping segments of fixed size, using a sliding window technique akin to those used in speech or handwriting recognition. Each segment is described by a local BOW associated with the histogram of interest points enclosed in the segment. A first-layer classifier, namely a one-vs.-all probabilistic SVM [22], converts each BOW into a vector of class-conditional probabilities. The SVM acts as an extractor of high-level discriminative features from the raw BOW data. The sequence of these vectors serves as the input observation sequence to the HCRF for actual human action recognition. We have tested this two-layer model on various popular public HAR datasets and the results obtained for each are among the best in the current state of the art. Our contributions are twofold. First, we show how the hierarchical modelling based on the two-stage discriminative model optimally combines two different sources characterizing motion activities: the temporally local motion content whose discriminative power is inferred by the SVM, and the long-range motion feature dependencies modelled by HCRFs at a higher level. Second, this scheme also allows for a drastic raw feature dimensionality reduction, which can prevent overfitting and increase not only processing speed but also recognition accuracy. The architecture of our HAR system is depicted in Figure 3.
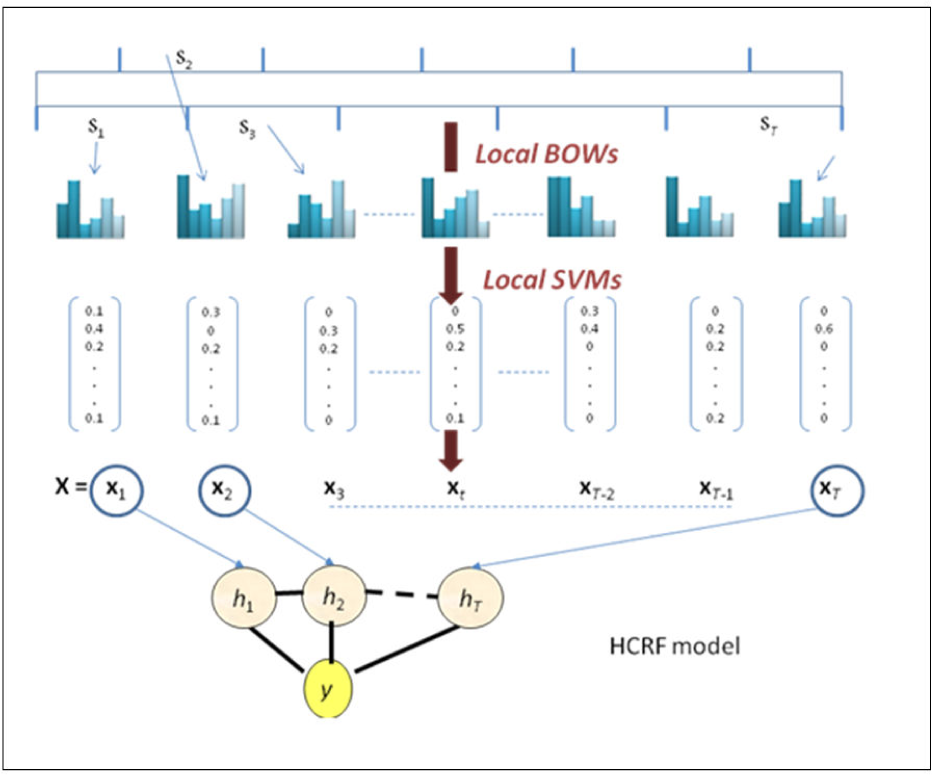
The architecture of our HAR sequential model
The video sequence is first uniformly split into segments of fixed size L (say 15 or 30 frames). Feature extraction is carried out in two steps. In the first step, each segment is represented by a BOW associated with local IP-based features. In the second step, a one-vs.-all SVM classifier takes as its input the raw BOW and converts it into a vector of conditional class probabilities, the dimension of which is the number of labels. The sequence of probability vectors obtained in this way serves as the input observation sequence for an HCRF model.
Each local segment conveys information about the label of the action/activity to which it belongs. However, the amount of information differs from one segment to another, depending on motion content. A high-information segment shares a large amount of mutual information with the class (low-entropy segment), while a low-information segment corresponds to a low amount of mutual information (high-entropy segment). In the former case, if a segment is highly discriminative, the conditional probability for the actual class will be high, while the other label probabilities will be low: the segment's strong informative content is reflected in a low-entropy probability vector. In the latter case, if a segment bears no information at all about the class, the class probabilities will be similar. To give an example, take an ADL recognition task performed over a reasonable duration of time. For such an activity, there may be temporal segments in which no motion occurs. These segments do not bear any information about the activity and we would want that to be reflected in the feature vector extracted from the segment. SVM is able to serve this purpose, as it is expected that the output probability vector would not favour any class when using the motion-based features described in our approach and in the state of the art. Thus the ambiguity is reflected in the probability vector with high class entropy. This does not mean that such segments are not relevant to recognition, as their temporal occurrence and relationship to other segments are not the same for all classes and hence they are valuable for making decision at the sequential level. Our modelling approach is therefore different from keyframe-based approaches; frame segments that do not bear intrinsic information about the classes are nevertheless not overlooked, since their temporal occurrence is by itself a discriminative factor in activity recognition. On the other hand, for segments containing basic arm motion for instance, the output probability vector will favour classes such as drinking or calling using a cell phone, and penalize others for which no such motion occurs. Such vectors are very discriminative as they convey a smaller level of ambiguity.
To harness the relationship between the partial high-level information conveyed by each segment through the SVM output probability vectors, we use a HCRF model that learns dependencies between the elementary parts of the action/activity in a discriminative way. The HCRF does not need the raw (low-level) features, but only the semantic information that each segment conveys about the classes, i.e., the SVM output class probabilities. The HCRF then integrates the sequence of semantic information vectors in a discriminative way to make a decision at the sequential level. For non-periodic actions — and above all for activities — the temporal segments contain a sequence of semantically different motion sub-events characterized by different feature subspaces. Our two-layer scheme avoids mixing these into the same global representation — e.g., a BOW, which may be prone to the “curse of dimensionality” problem — but rather describes each concisely using the intrinsic information regarding the labels. In this way, the HCRF focuses on high-level information conveyed by segments to learn actions/activities in a discriminative manner, without spending the bulk of its efforts optimizing parameters relating to low-level raw motion features. Given the huge overall parameter space associated with low-level raw input features and high-level sub-event information, the two-layer scheme helps guide the HCRF towards a better parameter space solution. As will be shown in the next few sections, this not only drastically reduces the HCRF training duration but also significantly enhances HAR accuracy. This can be explained by the fact that the two-layer SVM-HCRF model is less prone to overfitting issues when compared to pure HCRF, and spends the bulk of its efforts uncovering discriminative information that stems from segments.
3.1 Sliding window-based feature extraction
We used a sliding window to split the video into overlapping segments of fixed size. We considered a window size of 30 frames and an overlapping rate of 50%, in order to take correlation into account. Thus, the number of segments is proportional to the video sequence length. From each segment, we extracted low-level features based on interest points, such as spatio-temporal interest points and/or their trajectories. Our initial experiments using spatio-temporal interest points (STIPs) with HOG/HOF descriptors led to promising results for low-resolution frames (160×120). We have observed, however, that a small number of STIPs is generated for actions/activities that do not contain sufficient motion with reasonable amplitude. In this work, we use dense trajectory interest points (described in Section 2.1) as they deal better with this issue. A BOW is then generated by assigning each IP within the segment to its closest centre, after a prior clustering has been run on the IP descriptors from a subset of the training segments. Thus, each temporal segment is represented by a local BOW and the video sequence is represented by a sequence of T observations, where the ith observation corresponds to the BOW histogram extracted from segment Si, and T is the number of overlapping segments in the sequence.
For high-level feature extraction, we use a one-vs.-all SVM to convert each segment into a class-conditional probability vector, the dimension of which is the number of class labels in the targeted application. The SVM is trained on all the segments generated from the training video sequences and uses an exponential χ2 kernel [2]:
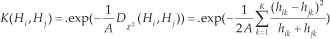
where A is the average of the χ2 distances over all segment pairs of the training set. We consider a probabilistic SVM providing conditional class probabilities rather than mere scores, as outputs between 0 and 1 are more suitable for a random initialization of HCRF parameters over the interval [0;1]. In the Experiments section, we will demonstrate the impact of the two SVM configurations (raw SVM scores vs. probabilistic SVM outputs) on the overall performance. Applying SVM to each input segment, a video is eventually converted into an observation sequence of T C-dimensional vectors, where C is the number of classes.
3.2 Activity modelling and recognition through a two-layer SVM-HCRF discriminative model
HCRFs [23] are an extension of CRFs initially used for natural language processing by Laferty et al. [24], which were recently proposed for sequence recognition purposes, augmenting the CRF with hidden states in order to model the underlying latent structures in temporal sequences, such as the sub-events in actions and activities. HCRFs have several advantages over standard generative HMMs trained in a maximum likelihood framework: 1) they do not make strong feature independence assumptions; 2) they do not consider a joint generative model P(

where ht is a hidden state at time t (ht ɛ H), fk is the kth feature function (i.e., BOW components), θ is the parameter vector,

An example of an HCRF model
HMM-HCRF is known as the generative-discriminative pair for sequential input, as the Naïve Bayes–logistic regression (NB-LR) is for static input [25]. The two pairs share several properties, among which is the fact that HCRF and LR are both discriminative (unlike the generative HMM and NB) and that HCRF and LR are more prone to overfitting issues. HCRF parameter estimation consists of searching for θ = (θ1;…; θ D ), maximizing the regularized log conditional likelihood of the labels l(θ):
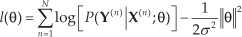
Optimization can be achieved through gradient ascent optimization for each component of θ. However, each component-wise optimization is a demanding task, owing to the denominator of Equation (2) that runs over all competing labels and not just the current observation sequence label, as in generative models. In a BOW-based HAR, the number of components D of θ is the BOW dimension K, which is of the order of 4000 in the current state of the art [16]. For such an order of magnitude, HCRF training is intractable. In the proposed two-layer SVM-HCRF model, by contrast, D is equal to the dimension of the probability vector output by the SVM, i.e., the number of class labels C. As C does not exceed the tens at the most, the gain in dimensionality reduction and subsequently in HCRF training speed is significant (since it is closely related to the feature vector dimension) and overfitting issues are overcome accordingly.
4. Experiments
4.1 Benchmarking the IKSVM and the two-layer SVM-HCRF models on public human action databases
For benchmarking, we ran experiments on three public datasets for human action recognition: the KTH Human Action Database, the Rochester Activities of Daily Living dataset, and UT-Interaction Dataset 1 [26]. The KTH dataset was obtained by recording 25 people performing six actions: boxing, hand clapping, hand waving, jogging, running, and walking. Each person carried out each action in four different scenarios: outdoors (s1), outdoors with scale variation (s2), outdoors with different clothes (s3) and indoors (s4) (Figure 5). The sequences were recorded with a 25 fps frame rate and downsampled to the spatial resolution of 160×120 pixels; they have an average length of four seconds. The Rochester ADL dataset consists of 10 activities considered useful for assisted cognition tasks: answering a phone, dialling a phone, looking up a phone number in a telephone directory, writing a phone number on a whiteboard, drinking a glass of water, eating snack chips, peeling a banana, eating a banana, chopping a banana, and eating food with silverware (Figure 6). These activities were each performed three times by five different people and lasted between 10 to 60 seconds so that each activity is represented by 15 video sequences. The videos used in our experiments had a 640×480-pixel resolution, at 30 frames per second. UT-Interaction Dataset 1 contains six classes of human-human interaction: shaking hands, pointing, hugging, pushing, kicking, and punching (Figure 7). The videos were recorded at a resolution of 720×480, 30 fps, featuring 10 different actors with different clothing conditions, backgrounds, scale, and illumination. They were taken in a car park at slightly varying zoom ratios, and mostly against a static background with little camera jitter. Each of the six interaction classes above was performed 10 times. Contrary to KTH and Rochester, this dataset does not consist of video sequences featuring one person at a time, but rather involves high-level complex actions associated with interactions between humans.

Actions from the KTH dataset: walking, jogging, running, boxing, hand waving and hand clapping

Activities from the Rochester dataset

Activities from UT-Interaction Dataset 1: shaking hands, hugging, kicking, pointing, punching and pushing
Figure 8 and Figure 9 show examples of dense interest point trajectories extracted from video sequences pertaining to UT-Interaction Dataset 1 and to the Rochester dataset, respectively. As can be seen, the trajectories are able to encode the general spatio-temporal motion shapes taking place in the actions/activities.
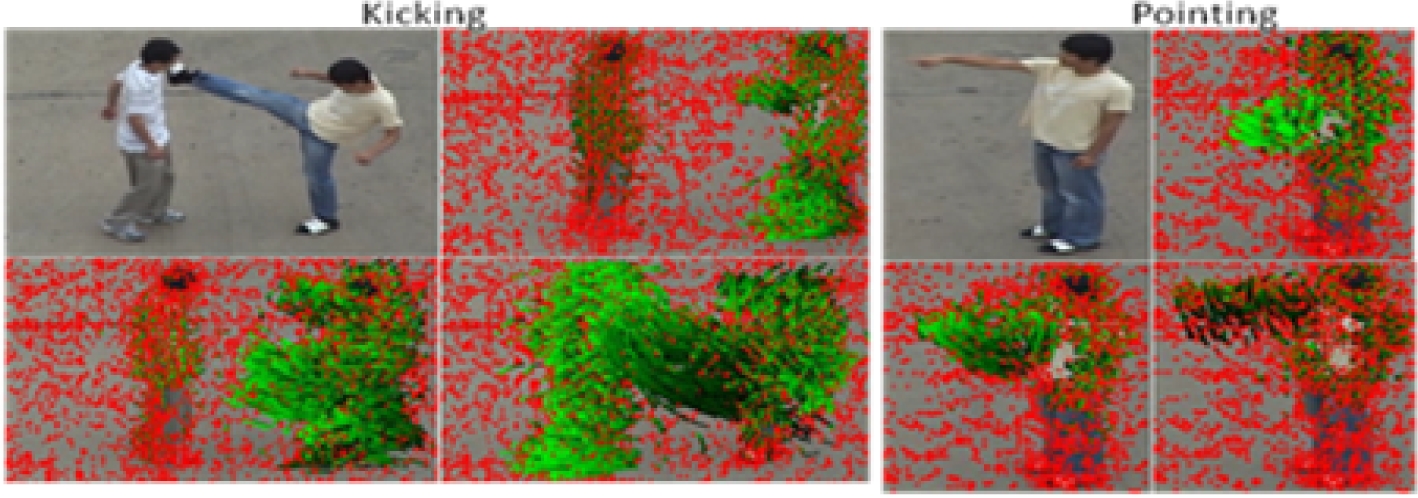
Dense trajectories (in green) characterizing the kicking and pointing actions from UT-Interaction Dataset 1

Dense trajectories (in green) characterizing the “drinking water” and “eating a banana” activities from the Rochester dataset
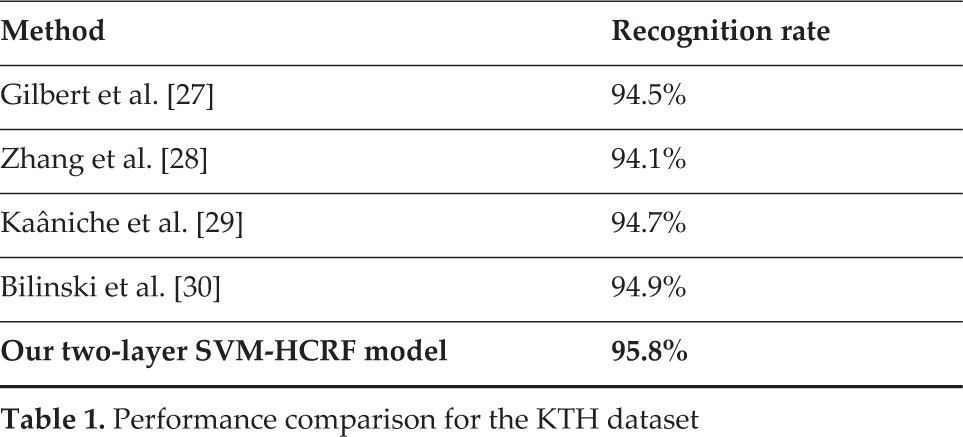
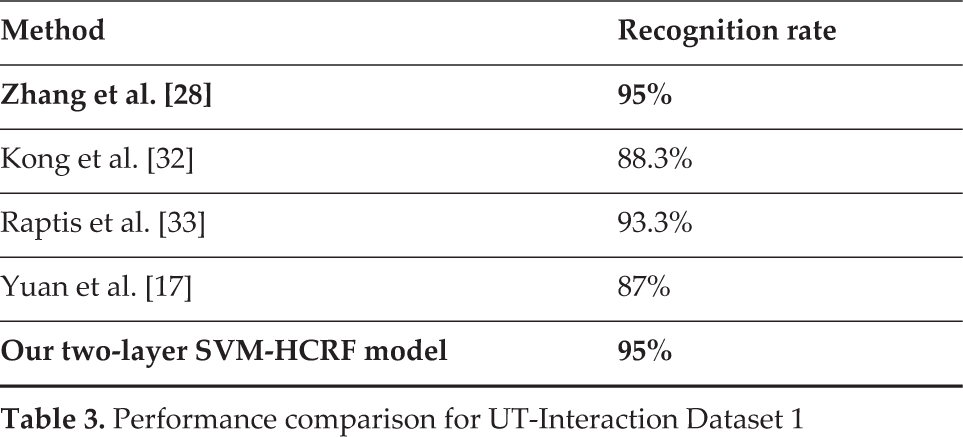
To make a comparison with the state of the art, we followed the standard experimental protocols on each of the three datasets. For KTH, we used the first 16 out of 25 people for training and the final nine for testing. For Rochester, we considered the five-fold leave-one-person-out setting, which consists of leaving out each person in turn for testing, training on the remaining four, and then averaging out the five individual results to obtain the recognition rate. The same setting was used for UT-Interaction Dataset 1, by this time considering a 10-fold leave-one-person-out. We used cross-validation for the local SVM to optimize the BOW codebook size. For KTH and Rochester, the retained codebook size was K = 2000 while for UT-Interaction Dataset 1, K = 500. This meant that the feature vector dimension was reduced from 2000 to 6, 10 and 6, respectively. A performance comparison of our approach with some recent state-of-the-art results on the three datasets is reported in Table 1, Table 2 and Table 3.
Performance comparison for the KTH dataset
Performance comparison for the Rochester dataset

Performance comparison for UT-Interaction Dataset 1
As can be seen above, the performance obtained by our two-layer discriminative model is among the top for all three datasets. This shows the power of a two-layer SVM-HCRF model that discriminates both at the local segment level, through SVM, and at the sequence level, by modelling through HCRF the interactions between the latent subsequences within a video sequence. As the segments are described by high-level low-dimension feature information — i.e., the conditional class probability vectors outputted by the local SVM and not by huge BOW representations — the HCRF is guided towards a better parameter space solution for sequence modelling, while raw data parameter estimation is dealt with locally through SVMs.
To compare the two-layer SVM-HCRF with the standard BOW-based global SVM approach, we ran two experiments on the KTH and Rochester datasets. For both sets, we considered a BOW codebook size K = 2000, the one that leads to the best performance. The accuracies of the SVM-HCRF and global SVM on the KTH and Rochester datasets are reported respectively in Table 4 and Table 5.
Comparison of the two-layer SVM-HCRF model with the global SVM on the KTH dataset

Comparison of the two-layer SVM-HCRF model with the global SVM on the Rochester dataset

As can be seen above, the SVM-HCRF outperforms the global SVM by 2% on the KTH dataset, and by a higher margin (8%) on the Rochester dataset. Nonetheless, the sequential SVM-HCRF model requires a feature representation at each time step; hence, it takes much longer to make a decision as feature extraction based on dense image sampling makes up the bulk of global processing time. Thus we chose not to implement this model within the robot, but rather the BOW-IK-SVM model. As can be seen from the tables above, the latter's recognition accuracy is lower than the former's, but it remains satisfactory overall.
4.2 Robot settings
Nao is a programmable, 58cm-tall humanoid robot characterized by 25 degrees of freedom (Figure 10). It features communication devices based on voice and LED lights and is equipped with several sensors, including two cameras and four microphones, as well as infrared, tactile and pressure sensors. Nao's processor is an Intel Atom 1.6 GHz CPU, located in the head, that runs a Linux kernel and supports NAOqi, an embedded Nao software that allows for the seamless integration of algorithms developed in C+ +, Python, or .Net. Nao's two 920p HD cameras can capture up to 30 images per second with a 1280×960 resolution. The first is intended for peripheral vision and is located on the forehead, while the second scans the immediate surroundings and is located at the mouth level.

The Nao robot
4.3 Video collection settings
The ADLs considered in this work are the following: 1) making a phone call (picking up/hanging up a phone); 2) sitting down; 3) standing up; 4) drinking a beverage; 5) writing; 6) opening a door; 7) closing a door; 8) using a remote control; 9) applauding; 10) walking; and 11) falling down. These ADLs not only represent typical domestic tasks, but they also show a large variety in human motion content and magnitude. The videos were collected in real-life conditions under several variability factors, such as viewing direction, distance, lighting, activity structural variability, and object types.
Viewing direction: For each activity, several directions were taken into account. For instance, more than four walking directions were considered to cover horizontal and diagonal directions and heading towards or away from the robot (see Figure 11 for some examples). Similar variability conditions concern falling down (Figure 12). Overall, the viewing angle was variable for all the ADLs.
Distance: The distance between the user and the robot roughly varied between 3 and 30 feet, depending on the activity performed (walking was filmed from a larger distance than writing, for instance) and on user preferences (e.g., Figure 11.c and Figure 11.d vs. Figure 14).
Lighting: Lighting conditions were highly variable, as they depended significantly on the location of recording, time of day, etc. (e.g., Figure 11.c vs. Figure 14.a).
Activity structural variability: Structural variability is variability that does not result from signal noise or lighting, but rather from the way in which the activity is carried out. An example of such variability in our settings is the fact that either the left or the right arm could be involved in opening or closing a door, hanging up a phone, drinking or using a remote control. Additionally, opening and closing a door were carried out in two different manners, depending on which side of the door the person initially was on (Figure 14).
Object types: Object types could also be different (different doors, bottles, glasses, cans of different colours, falls occurring on a mat or directly onto the floor, etc.) (e.g., Figure 12.a vs. Figure 12.e).
Occlusions: The activities under consideration naturally involve occlusions. Doors or tables, for instance, may occlude a significant part of the body when opening/closing a door or sitting down/standing up. Drinking or making a phone call, on the other hand, often lead to self-occlusions, as the moving arm may hide the face and other body parts.

Walking

Falling down

Closing a door

Activities from closer ranges: (a) writing, (b) using a remote control, (c) making a phone call, and (d) sitting down
Given Nao's limited storage and speed resources, the following configuration was set to target ADL recognition in reasonable time:
All the activities were collected through only one of the robot's cameras, that is, the one intended for peripheral vision and located on the forehead (Figure 10).
The frame rate was set to 12 frames per second (fps), instead of the usual rate of 30 fps.
Image resolution was set to 160×120 (the lowest possible), instead of the higher resolutions that are usually used.
Dense sampling was performed within four scales instead of eight, to reduce the number of IPs to track.
The robot was not put in a fixed location but in dozens of locations, as shown by the figures above. Nonetheless, when filming an activity, the robot was fixed. This is a realistic setting corresponding to a moving robot that stops to film an activity, to avoid unnecessary robot motion balancing.
4.4 Classification results
We conducted a number of real-life experiments with Nao by collecting a training corpus of 290 video data from eight persons. On average, each activity was performed about three times for each person. From each video, interest points were densely sampled and tracked over a window of 15 frames and then each encoded by a HOG/HOF/MBH combination descriptor of dimension 396. The IP descriptors were converted into a BOW through IP nearest-neighbour assignment to their closest centres (or codewords), obtained through k-means clustering. The BOW dimension D was set to 330, roughly 30 codewords for each class on average. Under the adverse conditions above, we tested the capability of Nao to recognize activities from new persons/conditions on a corpus of 157 ADL videos. Recognition by Nao was usually performed in about 15 seconds. The accuracy achieved can be summarized by the confusion matrix in Table 6:
The confusion matrix for human activity recognition by a Nao robot in real-life conditions (OD: opening a door; CD: closing a door; FD: falling down; RC: using a remote control; SU: standing up; WR: writing; SD: sitting down; AP: applauding; WK: walking; DK: drinking; PC: making a phone call)
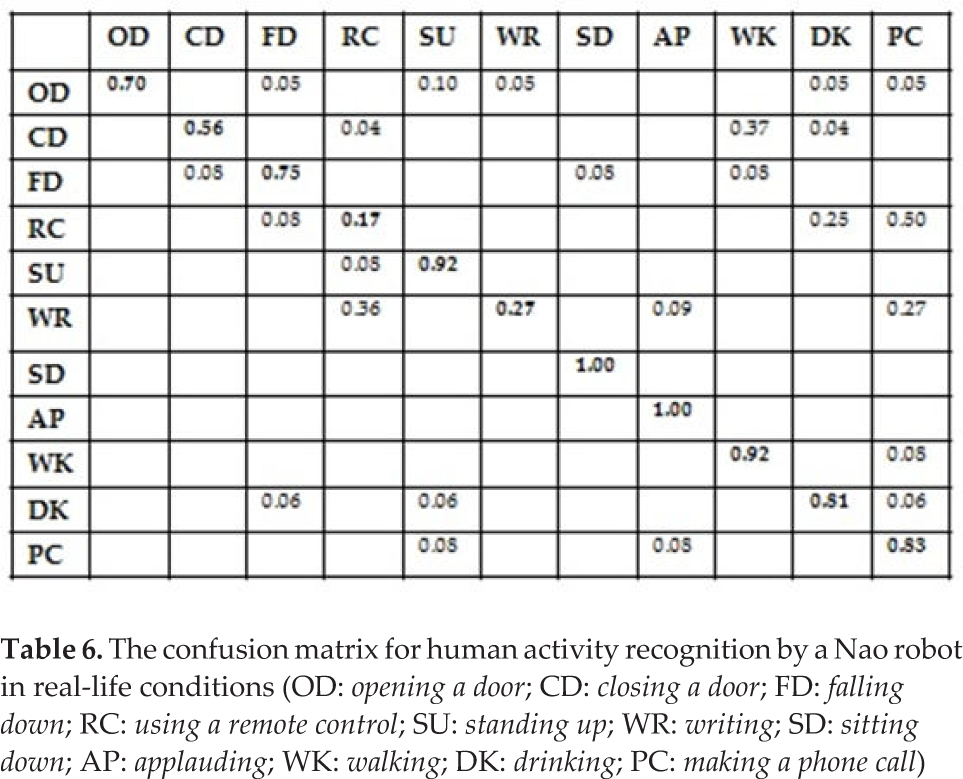
Some activities like applauding, sitting down, standing up and walking are easily recognized as they generate motion content that ensures discrimination. Some errors may occur nonetheless if Nao's view field does not fully cover the moving person; Nao was tested so that persons would appear at different distances (from 3 to 30 feet) and from different angle views, a much harder task w.r.t. fixed-location testing settings. The system also does a good job of detecting falling down, with a recognition rate of about 75%. The errors that occurred are understandable, as they are shared between closing a door, sitting down and walking, which may look similar to falling down if the video sequence is short (their beginnings may be similar). The performance is fair for closing a door, as this may be similar to walking if the person moves his/her legs when closing the door. As expected, performance was poor for writing and using a remote control, as they generate insufficient motion, especially under our settings considering only 12 fps with a 160×120 resolution. It is worth noting that current state-of-the-art datasets do not contain actions like writing or quickly using a remote control, which involve either small finger motions or fast short motion that are barely perceptible under non-high-definition camera settings. We decided to include these kinds of motions in order to distinguish gestures that the robot is quite robust at recognizing {walking, applauding, opening/closing a door, etc.) from gestures for which the robot's classification needs to be enhanced. In our case, better settings (30 fps, a resolution of 640×480 and a shorter distance between Nao and the user) may significantly improve performance for recognizing writing for instance.
Overall, the performance is surprisingly satisfactory, given the adverse settings summarized below:
The training corpus consisted of eight people only, each providing about three video sequences per activity, which is insufficient given the factors of variability considered and described next.
The training data were collected in a couple of locations but the robot was tested in new locations, involving different backgrounds and lighting conditions.
For each activity, several directions were considered (e.g., more than four walking (and falling) directions).
The view angle was variable for all of the ADLs.
The same object may consist of different types (different doors, bottles, glasses, cans, falls occurring on a mat or directly onto the floor (Figure 15)).
Both left and right arms could be used for opening/closing a door, hanging up a phone, drinking, etc.

An activity example in which a person falls down; falls could occur on a mat or directly onto the floor
Despite this large structural and non-structural variability, the classifier did a pretty good job at discriminating between the activities. One reason is that dense trajectories concisely encode motion and are robust w.r.t. changes in background and lighting. The interest points are not only dense but they are also encoded — in addition to the HOG/HOF descriptor — by the MBH descriptor, which helps eliminate noise due to background motion.
In terms of speed, the worst computational time was about 15s. This is reasonable giving the limited processing power of Nao. Most of the computational resources (>90%) are actually allocated to motion encoding though dense trajectories. Indeed, in order to enable the model embedded in the robot to recognize activities irrespective of location, the dense trajectory encoding scheme distinguishes moving objects/body parts from background and static objects. This comes at a price, since the whole scene then needs to be densely scanned by the robot, in order to focus only on the pixels moving over time and not on those that are static.
5. Conclusion and perspectives
Given the strong sensory and computational constraints we have imposed on Nao, as well as the adverse test settings associated with changes in location, background, view angle, clothes and objects, the HAR performance achieved is quite satisfactory. A straightforward improvement of Nao's ADL recognition accuracy could be obtained by considering a higher resolution and frame rate to better characterize ambiguous gestures/ADLs (e.g., drinking vs. making a phone call vs. using a remote control). Recognition could also be enhanced by making use of both cameras, instead of just one, to ensure comprehensive scene coverage. Prior to this, however, it is necessary to reduce classification processing time. As the bulk of processing time is spent on characterizing trajectories from densely sampled interest points, speed-up of feature extraction could be achieved by limiting sampling to regions with large motion magnitude, rather than sampling uniformly. An important direction for future work might be to increase the training corpus from eight persons to a much larger size. This would ensure not only a better capture of intra-and inter-person variability, but it would enable the development of sound probabilistic settings to enhance Nao's recognition reliability. Generating probability outputs from an SVM is indeed possible, but output reliability depends heavily on the training data size. If trained on a large training corpus, Nao could either make decisions if the conditional probability of the recognized class is high, or judge that the input ADL is ambiguous or unknown and thus ask the user for the correct class, so as to improve Nao's learning. Finally, we intend to investigate methods for the continuous detection and recognition of ADLs from a video stream based on the two-layer SVM-HCRF sequential model, which can be optimized for implementation in the robot.
Footnotes
6. Acknowledgements
The authors would like to thank Région Île de France for funding this work through the “Fonds européen de développement régional” (FEDER) JULIETTE project.