
Abstract
This article proposes a robotic system that aims to support the elderly, to comply with the medication regimen to which they are subject. The robot uses its locomotion system to move to the elderly and through computer vision detects the packaging of the medicine and identifies the person who should take it at the correct time. For the accomplishment of the task, an application was developed supported by a database with information about the elderly, the medicines that they have prescribed and the respective timetable of taking. The experimental work was done with the robot NAO, using development tools like MySQL, Python, and OpenCV. The elderly facial identification and the detection of medicine packing are performed through computer vision algorithms that process the images acquired by the robot’s camera. Experiments were carried out to evaluate the performance of object recognition, facial detection, and facial recognition algorithms, using public databases. The tests made it possible to obtain qualitative metrics about the algorithms’ performance. A proof of concept experiment was conducted in a simple scenario that recreates the environment of a dwelling with seniors who are assisted by the robot in the taking of medicines.
Introduction
With the aging of people, the risks for cognitive deficits and memory failures increase and attention skills decrease. 1,2 These age-related cognitive declines in the elderly reduce their ability to perform certain daily activities independently, such as eating, dressing, or even taking the medication to which they are subjected. 3 Often, the elders have various health problems and suffer from various diseases. Consequently, it is common for the elderly to take multiple medications to reduce symptoms, improve the quality of life, and occasionally cure the disease. Unfortunately, more than 50% of the elderly have difficulty complying with medication regimens due to many factors, such as disease severity, cognitive impairment, and the complex medication regimen. 4 Failure to follow the medication regimen may result in disease progression 5 and subsequent complications. The situation is aggravated by the fact that the elderly often live alone and no other person can help them in this task. In Western Europe, most older people live alone and want to stay in their homes for as long as possible, 6 avoiding psychological trauma and costly move to a nursing home or hospital away from friends and family. 7 There are several technology proposals to help seniors comply with medication schedules, including mobile applications, smart drug dispensers, and tablet dispensers that expel the tablet on time. 8 These types of applications make it easier to take medication, but one disadvantage is that all existing proposals require the user to go to the place where the medicines are stored and to select the correct one. Another problem with this type of solution is that the user does not have access to his smartphone at all times, which can cause him to fail to take medication at the correct time.
It is in this context that assistive social robotics (ASR) can simulate a human assistant to help elderly people to comply with their medication regimen. For this, it is necessary that the robotic system has a vision system that gives the perception of the environment and a locomotion system to allow its movement. The minimum functionalities required to perform the task are: – Facial recognition to identify the person, – Detection of packaging medicine, and – Information about the medication regimen.
In this work, a robotic system is proposed that supports the taking of medicines by the elderly. The robot with the ability to interact with the human gives him the correct medicine and at the right time. The main contribution is the software integration of well-established computer vision algorithms to produce a full functional prototype for experiments with users as described in the third section.
The focus is on facial recognition algorithms and object detection through the processing of images acquired by the robot. The part of the kinematics related to the movement of the robot and the manipulation of objects are not discussed in this article. All the kinematic process and the robot trajectory planning are assumed immutable not considering the variation of the test scenarios. In this way, the development was prepared for a specific scenario described in the fifth section.
In future work, the accuracy of object recognition and facial identification would be improved with the recent proposed deep learning architectures which have been successfully applied in these class of problems and a large variety of problems including these class of problem. Some authors propose the implementation of semantic segmentation, 9,10 object classification using convolutional neural network-based fusion of vision, 11 reinforcement learning method, 12 and new hardware and software architecture, 13 applied to autonomous driving. 14
The article is organized as follows. The second section introduces the concept of assistive social robotic and the key role of facial recognition for human–robot interaction (HRI). The third section presents the software architecture for robot operation. The fourth section is dedicated to the results and tests. The fifth section presents the main conclusions and future work.
Assistive social robotics
Social robots are designed to interact, collaborate, and work with people, engaging them at an interpersonal and socio-affective level. 15,16 The concept of applied robotics in health emerged a few decades ago, where it was used primarily for physical activities, rehabilitation, as well as personal assistance for daily tasks and activities. 17
ASR emerges to expand the concept of assistive robotics to include robots that operate through social interaction. With ASR, the objective is to create an interaction with the human to assist. 18 ASR has the potential to improve the quality of life of various users, including the elderly, people with cognitive and developmental disabilities, and people with social disorders. Although these devices are relevant to society, they are still a challenge because they are highly specific due to the individual needs of each user. 19 ASR have been designed for use in a variety of settings, such as hospitals, nursing homes, and private homes.
The creation of robotic systems to assist the elderly involves interaction with the human user. In this way, it is essential to study the HRI, thus allowing the design of robotic systems capable of performing interactive tasks in environments shared with humans, making them capable of interacting effectively and safely with humans. 20 Any robot developed with a social entity and able to communicate with users belongs to the category of social robots. Dautenhahn and Billard 21 have stated that social robots can participate in social interactions. 22
With the evolution of robotics, robots are increasingly used in environments that are suitable for human capabilities. The environment where the robot is present can change without any interference from the robot, for this reason, robots need to have the perception of the environment that surrounds them. In order to robots be able to perform their tasks efficiently, it is necessary that robots possess not only mechanical abilities, but also good social interaction with humans. 23 Facial recognition is one of the essential points in HRI for a social robot to recognize people. 24
A facial recognition system is a biometric system 25 that aims to identify faces present in an image or video automatically. Can operate in two distinct ways: (1) face verification (authentication) or (2) facial identification (recognition). The face check consists of a one-to-one match, that is, the image acquired with the face template that is checked and compared. In facial identification, one-to-many correspondence used, in which the comparison of the acquired image with the templates of all faces to determine the identity of the acquired face. 25 A facial recognition system usually consists of three stages (Figure 1). These steps, sequentially ordered, are face detection, feature extraction, and classification. However, the first two steps can be performed simultaneously. 26

Generic facial recognition steps. Adapted from Zhao and Rosenfeld. 26
In the process, there are some common problems as described by Yang et al.
27
Among the problems are:
Pose: The face image varies depending on the relative position of the camera or the face position itself. With the variation of the pose, some of the characteristics occluded.
Facial expression: Facial expressions make a face look different. Change in structural components—the presence of structural components such as a moustache, beard, or glasses that can still vary in size, shape, and color.
Obstruction: In an image or video, a face may be entirely or partially occluded by objects or other faces.
Image orientation: Face images may appear with different rotations on the optical axis of the camera.
Image condition: Factors such as lighting and camera characteristics affect the appearance of the face.
Object recognition is a key task in computer vision and is also fundamental for work cooperation between robots and humans. This problem consists in automatically recognizing the identity or category of an object. 28 The process can be based on several aspects of the image such as shape 29 or color. 30
Object recognition can be done for a specific object or a generic category. 28 Recognition of the class of an object requires a strong generalization ability of the classification methods to be able to succeed with variations of illumination, occlusions, and viewing angles. A good performance in object recognition algorithms is to use features that are invariant to common transformations. The object recognition process is divided into two steps feature extraction and classification (Figure 2).

General steps in object recognition.
Briefly, the object recognition process has two phases: a training phase and a recognition phase. In the training phase, the system extract features from training images and obtains a description for the object or class of objects. In the recognition phase, the characteristics of the test image are extracted and compared with the features of the training phase to verify if there are matches between both descriptions.
The classification process consists of a comparison between the features of the training image and the test image trying to find out which training image is most similar to the test image. 31 Through this process, the most similar image description is used for the classification of the test image. 32
Software architecture for robot operation
System overview
In this work, we propose a robotic system architecture based on the NAO robot to support elderly people comply with their medication regimen (Figure 3). The robot uses its locomotion system to move and deliver to the elder the medicine package that he needs to take at that time. The control of the robot is made by a software composed by three main modules: service scheduler, image acquisition and processing, and the kinematic module. The scheduler, responsible for requests launching, is fed by a database storing the information of each elder person in the house, their faces images, the photos of the medicines packages, and the respective times of taking. The image acquisition and processing module controls the acquisition of images through the cameras imbed in the robot and also includes the computer vision algorithms for elderly facial verification and the detection of drug packaging. The kinematic module is responsible for planning and execution of robot’s movements and gestures. Although a specific robot was used, the proposed robotic system is not unique to this robot and can be adapted to any robot that has a locomotion system to move, grippers prepared for grasping, and manipulating objects and a visual system to capture and process images.

Robotic system overview.
NAO robot description
The NAO robot measures approximately 58 cm and weighs 5.4 kg. It has a human body structure with several components for the vision and perception of the environment. Its latest version as a 1.6 GHz ATOM CPU, located on the head of the robot (“Motherboard,” nd), which runs its own operating system, OpenNAO, based on a Linux (Gentoo). So that the robot behaves as closely as possible to a human, it includes several characteristics that allow it to move, perceive, and communicate.
The NAO robot has two identical chambers located on the front of the robot’s head. Both cameras provide video acquisition up to the maximum resolution of 1280 × 960 at the rate of 30 fps. Each of the cameras has a limitation of 60.97° horizontally and 47.64° vertically. Both cameras have various parameters that can be customized, such as brightness, contrast, or resolution.
The operating system of the NAO robot, titled OpenNao, is based on the Gentoo Linux distribution. NaoQi is the middleware responsible for controlling the robot’s hardware. The use of this middleware allows programming of the robot and makes it possible to combat some of the everyday needs in robotics such as parallelism, synchronization, events, and resources. The NaoQi allows the homogeneous communication between several modules (movement, audio, etc.), homogeneous programming and homogeneous information sharing. This framework is multiplatform, multi-language and allows introspection. NaoQi is responsible for managing multiple proxies. A proxy is an object that represents a module and behaves like this, that is, proxies intercede in the interaction with peripheral modules, such as the camera or memory. This is possible because the robot receive commands through the network, which makes it possible to control the robot through a remote computer. NaoQi allows the robot to be controlled using the methods available in the various modules. There are two ways to execute methods of a module, locally or remotely. Locally executed modules are executed directly in the robot, and there is no need for another computational system. On the other hand, the modules executed remotely are executed in a computer system and communicate through the network the actions to be performed. The provided SDK support application development for several languages, such as C++ and Python.
Software implementation
The stages of medication taking are executed sequentially starting with the launch of a service request and ending with the medication delivery to the intended elderly. Figure 4 shows the flow diagram of the process.

Flowchart of medication taking process.
A localhost database with three main tables User, Medicine, and Time stores the data from the elders, medicines and all the timing of the medication regimen for all the elderly that live in the house. The training images and their respective image descriptors are also stored locally in directories whose name is the identifier of each elderly/drug. By querying the database, the scheduler launches a service request whenever it is time for user, U, take the medicine, M. In the service request, two images arguments are sent: the user’s face image and the packaging medication image. The request is handled through a set of actions performed by the robot. Firstly, the robot moves to the pharmacy to capture an image where the medicines are stored. After image processing the intended packaging medicine is detected and the robot carries it to the elderly which is identified through his face. For the facial user verification and the detection of packing medication computer vision algorithms were implemented using the OpenCV library.
Computer vision algorithms
The main focus of this work refers to the computer vision tasks, facial recognition, and package medicine detection. A way to achieve good performance in object/face recognition algorithms is to use features that are invariant to common geometrical transformations and lighting changes. In order for a computer vision system to recognize an object, it is necessary to detect its distinct features in the training phase. 33 Usually the object recognition process is divided into two steps: feature extraction and classification (Figure 2).
Recognition of medicines packaging
To help the elderly in complying with the medication regimen, the robot needs to pick up the correct medicine from the place where they are stored (house pharmacy). The desired medicine package recognition is based on the match between the image acquired by the camera’s robot, when is looking for packages stored in the pharmacy, and the training images stored in the database. Briefly, the process consists in establishing the correspondence between feature points extracted from the training images of each packing and the feature points detected in the image acquired by the robot (input image). The algorithm is represented in Figure 5.

Algorithm for the medicines packaging recognition.
The feature extractor has the purpose of extracting specific attributes from the image so that these features undoubtedly describe the class of objects or the object in question (Forsyth and Ponce, 2012). 34 The scale-invariant feature transform (SIFT) is used to detect some distinct features from the input image as key points for medicine package recognition.
SIFT is a computer vision algorithm published by Lowe 35 used to detect and describe local features in images. The algorithm gives feature points directly and calculates the descriptors associated with each key point. The key point descriptor is an array representing the key points orientation based on local image gradient directions. The features extracted by the algorithm are invariable to scale and rotation providing a robust classification even in the presence of distortions, change of image perspective, noise, and changes of illumination, 36 which is an important advantage for correct package recognition under different views and light changes in the scene. Figure 6 shows an example of features extracted using the SIFT algorithm in a package medicine.

Example of feature extraction using SIFT. SIFT: scale-invariant feature transform.
In the next step, a feature matcher matches the features obtained in the training image with the features extracted from the input image. The K nearest neighbors algorithm, with k = 2, is used to match the features in both images. 37 To avoid poor matches, we compute the ratio between the best and the second-best match. Only the key points whose distance from the best neighbor is 75% smaller than the distance of the second best neighbor are considered a good match. This check is performed to eliminate possible false positives (FPs). When enough feature matches are found, above a predefined threshold, we consider there is a match and the presence of the packing is verified in the input image. Figure 7 shows the result of the algorithm when applied to detect the Bisoltussin packing medicine (training image) on an input image acquired by the robot when is in front of the pharmacy.

Example of the result of the comparison between the features points of a training image and a test image.
After recognizing the desired medicine and detecting its position on the pharmacy, the robot “pushes” the package into a basket attached around the neck to deliver it to the elder, together with the bottle of water.
User recognition
Once selected the correct medicine, the robot must look around to deliver the user the medicine package and the water. The user recognition algorithm has two main stages: face detection and face verification to confirm the user identity. Figure 8 presents the flowchart algorithm for facial user verification.

Algorithm for facial user verification.
While moving, the robot captures images of the environment at regular intervals to detect faces and identify the user. Each input image is processed by Viola–Jones algorithm to detect possible faces in the image. 38 The choice of this algorithm is justified by its robustness, high precision, with a FP rate less than 1%, and fast enough to be used in practical applications. When a face is detected (position and size), it is properly cropped, resized, and converted to grayscale to be further processed in the verification stage. The facial recognition algorithm operates on verification mode, comparing the descriptors between the input image and the user’s facial image who should take the medicine.
The local binary patterns histogram (LBPH) algorithm was used as facial descriptor to build several local descriptions of the face and combine them into a global description. Following the Ahonen’s work, the facial image is divided into local regions and LBP texture descriptors are extracted from each region independently. By concatenating the regional descriptors, a histogram is created to form a global description of the face. 39 In the training phase, the LBPH algorithm is used to create a global face descriptor (histogram of descriptors) for each elderly that lives in the house. In Figure 9, the whole process is illustrated.

Steps of LBPH algorithm. LBPH: local binary patterns histogram.
The result of user verification is obtained calculating the difference between the histograms of detected face and the elderly face that it is intended to be recognized. If the histograms are similar their difference is low (less than a predefined threshold) and the user identity is confirmed.
Experiments and results
To evaluate the algorithms’ performance, a set of tests were performed to obtain qualitative metrics. Besides the algorithm’s evaluation, a real scenario experiment with the robot and two users was also carried out to validate the whole robotic system as a proof of concept.
The proposed models were evaluated using the following performance metrics: Confusion matrix, True positive (TP) rate or sensitivity, False negative (FN) rate, True negative (TN) rate or specificity, FP rate, Precision, and Accuracy.
Evaluation of medicines packaging recognition model
The first set of tests aims to evaluate the performance of SIFT algorithm for medicines packaging recognition. The recognition model was trained to recognize 50 different products, including medicines, cereals, and cans of soda (Figure 10—training set). The model was evaluated with images containing several packages, as shown in Figure 10—testing set.

Examples of training images and testing images for packaging recognition.
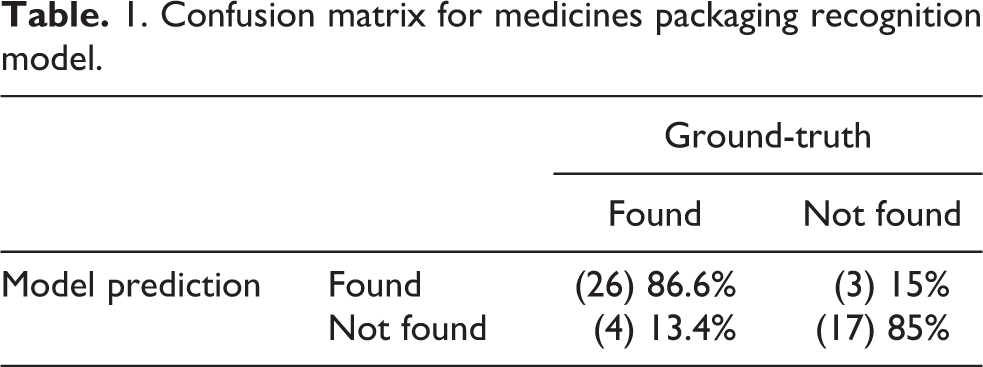
The confusion matrix shown in Table 1 contains the information about ground-truth and predictions obtained by the model for ben-u-ron packaging recognition in 50 test images, of which 30 had the packaging visible and 20 images had other product packing. Although not shown, similar results were obtained in packaging recognition for other products.
1. Confusion matrix for medicines packaging recognition model.
Using these results, we can derive the metrics presented in Table 2.
Performance evaluation of the packaging recognition algorithm.

Of the 30 images that contained ben-u-ron packaging, 26 were recognized and 4 were not recognized, which gives a total TP rate (proportion of actual positives that were correctly detected) of 86.6% and an FN rate (proportion of actual positives that were not detected) of 13.4%. Of the 20 images test images with no ben-u-ron packaging, 17 were detected, giving a TN rate (proportion of actual negatives that were not correctly detected) of 85% and an FP rate (proportion of actual negatives that were incorrectly detected) of 15%. The model precision (how often positive predictions are correct) is 89.7% and accuracy (how often model predictions are correct) is 86%.
The results obtained are quite positive. However, since the object recognition algorithm will be used for medicine recognition, the FP rate value should be lower. In a real case, if a false detection occurs, the robot can deliver the wrong drug to an elderly person, and this may bring complications to their health. On the other hand, the value obtained through the precision metric should be higher, which would mean that there would be fewer occurrences of “FPs.” Once again, the FPs would mean that the robot could deliver the wrong drug to the user. The recognition errors could be decreased if several slightly different input images of the same packaging are processed before taking the definitive result.
Evaluation of user recognition model
In the last stage of the tests, the facial recognition algorithm was evaluated. The tests were performed in images from the public data set available by the National University of Cheng Kung (Databases for Face Detection). 40
This image data set contains 6660 facial images of 90 different people, that is, 74 images per person. Each person has 37 images with intervals of 5°, from the right profile view (90°) to the left profile view (−90°), obtained through the panoramic rotation. The remaining 37 images of each person were obtained through the use of software, turning the images horizontally.
For the tests only facial images with angles between −35° and +35° were used, which generated a total of 15 images per person. The user recognition model described in “User recognition” section was trained with a training set of 600 images (50 different persons and 12 images of each person). The testing set has a total of 150 images, from 50 different persons, each one with three images in the testing set.
The evaluation test consists in recognizing the person present in each image of testing set. Since all the testing images belong to one of the people contained in the data set, the possible results in are: Correct recognition—The algorithm recognizes the person correctly (TP). Wrong recognition—The algorithm recognizes a person who does not correspond to the person present in the test image (FP). Non-recognition—The algorithm does not recognize any person as being in the data set (FN).
Table 3 shows the results obtained in the test.
Results obtained in the facial recognition test.

TP: true positive; FP: false positive; FN: false negative.
Using these values, we can derive some of the metrics previously presented.
Out of the 150 face images in the testing set, 123 were correctly recognized and 27 were not recognized correctly, which gives a total TP rate of 82% and an FN rate of 18%. This results in a model precision of 84.2% and an accuracy of 96.6%.
The results are generally positive. However, facial recognition is an essential process because the misrecognition of an older adult causes two problems: wrong administration of medications to an older adult and deprivation of medication to another older adult.
Experiment in a real scenario
To test and demonstrate the system functionality similar to others works, 41,42 we run a test with two users aged between 50 and 60 years. We setup a scenario with two persons sitting in chairs and three medicines (Bisoltussin, Mirtazapine Psidep, and Claritine) packaging stored on a black shelf in front of the robot (Figure 11).

Test scenario in the real environment.
Before running the experiment, the facial recognition model was trained with 12 photos of each user. The database was loaded with user information, medication, and scheduling as shown in Table 4.
Database information for the experiment.

At the time of the previously scheduled medication intake (14:05), the robot started the service request recognizing the medication (Claritine) and placing it in the basket. Then, the robot guides its field of vision to the chair number 2 and takes a photo which is processed to verify if it is the correct person. Since he is not the correct person, the robot guides his field of vision to the chair number 1 and takes another photo which is processed for user verification. In this case, he recognized the person who should take medicine (female D. Maria), the robot moves in her direction for medicine and the water delivering. Throughout this experimental process, the robot speaks to the elderly giving him information, as represented in Figure 12. All the kinematic process and the trajectory planning are pre-programmed assuming a static and well-known test scenario.

The representation of the various stages of the test in the real scenario.
In the test performed, the results were as expected and the robot identified the correct medicine and the correct person delivering the medicine packaging successfully.
Conclusions and future work
Summarizing, the proposed robotic platform allows to improve and develop new ideas, also this type of robotic platform is very good for serious research. During implementation, several algorithms were used for the various process stage. In medicine packaging recognition, SIFT algorithm was used; on the other hand, for facial detection and recognition of the elderly, LBP and LBPH were used, respectively. After the algorithm implementation, a set of tests were carried out to the three algorithms to obtain qualitative metrics of the system’s performance. These tests have revealed quite positive results. However, complications mistaken recognition of a person will lead the robot to deliver a specific medicine to a wrong person. This error causes two problems: wrong administration of medications to an older adult and failure to take the medication to another older adult. On the other hand, the recognition of medicines in the wrong way will lead to the administration of a wrong drug to an older adult and the deprivation of the right medicine. In general terms, the results obtained in the evaluation of the algorithms can be considered satisfactory for the intended purpose.
Supplemental material
Supplemental Material, Assinatura-copyright-ass_(1) - Robotics services at home support
Supplemental Material, Assinatura-copyright-ass_(1) for Robotics services at home support by Leonel Crisóstomo, NM Fonseca Ferreira and Vitor Filipe in International Journal of Advanced Robotic Systems
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.