
Abstract
Efficient exploration of unknown environments is a fundamental problem in mobile robotics. We propose a novel topological map whose nodes are represented with the range finder's free beams together with the visual scale-invariant features. The topological map enables teams of robots to efficiently explore environments from different, unknown locations without knowing their initial poses, relative poses and global poses in a certain world reference frame. The experiments of map merging and coordinated exploration demonstrate the proposed map is not only easy for merging, but also convenient for robust and efficient explorations in unknown environments.
Introduction
There is growing interest in using groups of coordinating autonomous robots to perform such tasks as reconnaissance, rescue and hazard identification due to the fact that the cooperative robots promise the immediate advantages of parallelism, redundancy and fault tolerance (O'Berine, D. & Schukat, M., 2005).
Compared to the problems occurring in single robot exploration, the extension to multiple robots brings about several new challenges including map merging, exploration strategy and limited communication (Fox, D. & Ko, J., 2006).
In cooperative exploration, the quality of map consistency depends mostly on the robots' relative locations and the data registering techniques. Though data registering alone can fulfill map merging in theory, consistent integration of the data in large-scale, cluttered environments is more difficult if the robots don't know their relative locations or their initial pose with respect to the same world reference frame. Therefore, virtually all existing approaches to coordinated multi-robot exploration assume that the robots know their locations in a shared map of the environment and start at the same location so as to obtain the same world reference frame (Fox, D. & Ko, J., 2006). In addition, most existing approaches on the environment exploration and mapping rely on the global localization algorithms such as expectation maximization, Markov methods, extended Kaman filter, Monte Carlo localizer and Roa-Blackwellian particle filter (Liying Su & Min Tan, 2005). Once a robot is kidnapped during the course of exploration, the robot has to recover its global pose by data registering or by the help of other robots.
The exploration strategy is also closely linked with the map formalism adopted. Market-based approaches have recently been gaining popularity as efficient and versatile coordination mechanisms (Zlot, R. & Stentz, A., 2002) due to their reliability, robustness and efficiency in the exploration through negotiation or auction in the market economy. However, the goal generation algorithm they used is not as efficient as the frontier-based algorithm (Burgard, W. & Moors, M., 2000). Therefore, the frontier-based algorithm is naturally combined with the market-based approaches in such a way that the former generates the commodities or target points, while the latter allocate these tasks to the robots. However, the commodities used in the market are mostly the global coordinates rather than the location that has recognizable features. In other words, even a robot reaches the commodities, it still doesn't know what happens if either the auctioneer or the bidder has been kidnapped. As a result, an appropriate map representation will influence the exploration efficiency greatly.
The most common representations of the world model in mobile robotics, the so called map, can be grouped into two classes: metric maps and topological maps.
A metric map, including the grid-based approaches and the geometric approaches, represents the environment according to the absolute position of the objects. The grid-based approaches (Makarenko, A., 2003) have proved to be very simple and quite useful for obstacle avoidance and planning purposes. However, when the size of the environment is large, these models become difficult to handle. In the geometric approaches (Austin, D. J. & McCarragher, B. J., 2001), the environment is represented with geometric beacons and the position of the robot is estimated by matching the sensed features against the world model. Those algorithms are vulnerable to sensing errors and environmental uncertainties. Recent techniques of mapping and localization have remedied such limitations to some extent. For instance, such methods as FastSLAM and Roa-Blackwellian EKF (Hahnel, D. & Burgard, W., 2003) are quite capable of handling noise observations, kidnapped robot solutions and environmental uncertainties robustly.
In contrast, topological approaches those usually represent the world model in graph form are known to be robust to the fragility of purely geometrical methods (Fabrizi, E. & Saffiotti, A., 2002) (Ranganathan, A. & Menegatti, E., 2006). The elements of the topological map are strongly related to the semantics of the environments while the other two maps put more emphasis on geometrical information. As a result, the topological map is more capable than the others in managing reactive behaviors.
However, several drawbacks have impeded the application of the topological maps in autonomous explorations and navigations:
Firstly, there is no uniform semantics associated with these graphs. For example, Kuipers and Byun (Kuipers, B., 1991) represent nodes with places, characterized by sensor data, and represent arcs with paths between places, characterized by control strategies. In contrast, the maps defined by Thrun (Thrun, S., 1998) are obtained by partitioning a probabilistic occupancy grid into regions separated by narrow passages according to a measure of local clearance. Since different definitions may lead to different topological architectures, it is difficult for a robot, even for a human, to construct a topological map online during the course of exploration. Therefore, most topological maps are supplied by human operators rather than built online by the robot itself. To resolve this problem, Fabrizzi (Fabrizi, E. & Saffiotti, A., 2002) extract the topological map from the grid by analyzing the shape of free space by means of the mathematical morphology image processing tool. This hierarchical approach still has the problem of large memory requirement involved in a grid map. Thrun et al. split free space into homogeneous regions according to region shape criteria. However, their topological map is constructed off-line and only when a fully explored metric map is available (Poncela, A. & Perez, E. J., 2002). As an alternative to these approaches, the direct topological map building using the voronoi diagram was proposed by Zwynsvoorde (Zwynsvoorde, D. V. & Simeon, T., 2000). The voronoi diagram, however, has difficulty in applying to arbitrarily shaped objects and needs long computation time. Chang-Hyuk Choi (Chang-Hyuk Choi & Jae-Bok Song., 2002) proposed a thinning method to build a topological map from a binary grid map. This method needs much simpler computation than that using a voronoi diagram. However, thinning, as an image processing method, is mainly used in rectangle-shaped region rather than ellipse-shaped area.
Secondly, the robot may have trouble to locate itself in the topological map by the sensors' data input. A variety of artificial landmarks such as ultrasonic beacons, reflecting tape, or visual patterns, allows fast and stable recognition of the specific location despite the fact that there often exist no artificial landmarks available in unknown environments. Many researchers thus manage to extract the distinctive features that are unaffected by nearby clutter, partial occlusion or environment variation. Some candidate feature types, such as line segments, eigenspace matching and Harris corner detector have been proposed and explored. Besides the features mentioned above, the scale-invariant feature transform (SIFT) (Lowe, D.G., 2004)(Kosecka, J. & Fayin Li, 2005) has been demonstrated to be invariant to image scaling, translation, rotation and partially invariant to illumination changes and affine or 3D projection.
Considering the challenges in the coordinated exploration, the advantages and drawbacks of the different map presentations, we propose a novel topological map whose nodes are represented with the range finder's free beams together with the visual scale-invariant features. The topological map has such advantages as follows: 1) This topological map can be constructed online by a single robot or multi-robots; 2) Compared with present metric maps, neither the global localizations nor the relative poses of the multi-robots are required in cooperative map building; 3) Compared with present topological maps, no artificial landmarks are required in location recognition.
The proposed topological map is combined with the market economy to realize efficient cooperative exploration. We also use a reactive navigational approach, the beam-curvature method(BCM) (Fernandez, J.L. & Sanz, R., 2004), to extract the topological nodes directly from the sensors' input. To our knowledge, no corresponding researches have been developed in this field. By the experiments of map merging and cooperative exploration, the feasibility and the validity of our exploration scheme can be confirmed.
The remainder of this paper is organized as follows. Section 2 introduces how to build a topological map online with BCM. The location recognition based on the single-node matching and the cooperative Hidden Markov Model (HMM) has been given in section 3. The experiments are summarized in section 4. Finally, conclusions and discussions are given in section 5.
Building a topological map online with BCM
BCM, as a hierarchically reactive navigational approach, first divides the world model into several beams according to the sensors' inputs. The best beam will be selected by maximizing an objective function and sent to the curvature-velocity method (CVM) (Simmons, R., 1996). CVM will then calculate the linear and angular velocity commands that satisfy all the physical constraints by trading off speed, safety and goal-directedness. Compared with other reactive methods such as the artificial potential fields method(APF) (Khatib, O., 1985), the vector field histogram method(VFH) (Borenstein, J. & Koren, Y., 1991) and the lane-curvature method(LCM) (Ko, N. Y. & Simmons, R. G., 1998), BCM can generate smoother and faster trajectory and have less chance of being trapped by the local minima. In our previus works (Chaoxia Shi & Bingrong Hong, 2006), we classify all the beams into the free beam and the block beam. The block beam is the beam that associates with an obstacle, while the free beam is the beam that doesn't comprise an obstacle.
Node definition and classification
In our topological map, the center of either a region that has one opening or the intersecting area of several passable routes will be regarded as a topological node.
According to the definition above, a topological map N1-N2-N3-N4-N5-N6 can be extracted from the official environment shown in Fig.1a. All the nodes are classified into three types in terms of the total amount of the free beams:

Free beams' variation and the node's detection
Type I: the node has only one free beam. This type of nodes, e.g. N1 and N6, often represent the dead end of a corridor or the innermost of a narrow space.
Type II: the node has two free beams. This type often represents the corner of a corridor or a convex of a large object. It is obvious that N2 belongs to this group.
Type III: the node has three more beams. This type of nodes, including N3, N4 and N5, often represent the intersection of several openings.
If the beams can be regarded as a certain kind of features, it is clear that the beams are more robust to ambient variation compared with other features such as line or corner. In fact, the beam features are mainly used for node detection rather than node recognition owing to their confusable representation about the surroundings. In contrast, the scale-invariant features transform supplies us a reliable way to recognize the node despite the considerable time spent on features extracting and data registering.
Without knowing how to detect a node nearby, the robot will have trouble to locate itself in the topological map. The reason why we use BCM to extract a topological map is that beam analyzing, as the basis of BCM, can also be used to detect a possible node. Generally, a node region is such a steady area in which the sum of the free beams at time t, Sumt, is invariant. The principle of node detection has been listed as follows: 1) If Sumt equals 1, there might be a type I node near the robot; 2) If Sumt equals 2 and the angle between the two free beams at time t, θt, is less than the angle threshold, θth, or the variation of θt, θ't, is larger than the variation threshold, θ'th, there might be a type II node close to the robot; 3) If Sumt equals 3 or more, the robot might be located at a type III node region.
Fig.1a shows us the example of node detection in a typical official environment, where the robot navigates from point S to D. The sum of the free beams and the angle variation are recorded in Fig.1b and Fig.1c respectively. During the journey from point S to 1 or from point 14 to D, Sumt equals 1, which means a type I node has been detected (N1, N6). When the robot moves from point 1 to 4, Sumt equals 2, and two peaks of angle variation above θ'th (0.3 radian) appear at point 2 and 3 so that a type II node, N2, can be detected. When the robot is located in arc segment 4–5, 6–8 or 9–13, Sumt is larger than or equal to 3, so that the type III node, N3, N4 and N5, will be detected.
Node localization
Once a possible node has been detected, the due position of the node in the robot's local reference frame should be calculated so that different robots can get similar views at the same location. Since each free beam is associated with a passable route/opening, the orientation of the rout e will be calculated by its neighboring block beams.
If we denote the left and right neighboring block beams of the ith free beam as the point sets

where

Localizing the node by a) the iterative closest point transform and b) local edge fitting, c) n reference frames can be constructed corresponding to n freebeams
A local edge fitting method (LEF) is also used to improve the performance of the nodes' localization. Considering all the k matched pairs, the orientation of the i th route (free beam) can be deduced by the slope of all the matched pairs. Though the laser range finder obtains the precise information from the obstacle, the discrete data will bring considerable error to the slope computation especially when the obstacle's surface is almost parallel to the sensor's projective direction. So we fit the obstacle's local edge around the matched pairs with several line segments. For example, taking into account a matched pair (b2(i-1),b1(i+1)) shown in Fig.2b, we fit the i-1 th obstacle's edge around b2(i-1) with the line segments b1(i-1)b2(i-1)b3(i-1). Similarly, the edge of the i+1 th obstacle at b1(i+1) can be fitted by the line segment b1(i+1)b2(i+1). Search for the closest point from the line segment b1(i-1)b2(i-1)b3(i-1) to the point b1(i+1) as well as that from the line segment b1(i+1)b2(i+1) to the point b2(i-1) by calculating the distance from a point to a line, the new matched pair (b(i-1), b1(i+1)) will be selected to replace the original pair (b2(i-1), b1(i+1)). Subsequently we may use the updated matched pairs to calculate the node's accurate position.
The orientation of the i
th
beam, θ
i
, is calculated by the k matched pairs as follows: Provided the index of the r
th
matched pair is denoted as m(r) and n(r), a possible value of θi decided by the r
th
matched pair,
If

where θ th is the threshold of θ(i,j), f(x) is the step function that values 1 when x≥0 and 0 otherwise. Eqn.3 denotes that the weight of the intersection point b(i,j) is proportional to the angle θ(i,j), if the angle between the line L(i) and L(i) is too small, their intersection point will not be considered. Fig.2b illustrates that the combination of ICPT and LEF improves on the node's localization efficaciously. For example, when a certain matched pair, (b2(i-1),b1(i+1)), is replaced by (b(i-1),b1(i+1)) due to the use of LEF, one of the consequential intersection points will move from the point O2 to O1. Compared with the traditional edge fitting method, Hough transform, LEF only use the edge's local features to evaluate the route's orientation, which on the one hand consumes less time, but also performs well in arbitrary shaped openings.
As to the type I node, the robot will calculate the node's position with the centroid of all the block beams,
Once a node has been found, n local reference frames will be set up in terms of n free beams (shown in Fig.2c). It is obvious that each local reference frame associates present node with another adjacent node individually. If one of the adjacent nodes has been selected as the target point, the robot's coordinates in the corresponding reference frame will be calculated by dead-reckoning.
After calculating the node's due position, the robot will steer to the node, capture the images along each free beam's direction and extract the scale-invariant features as the node's view. It will then match all the views of the node against that of other nodes in its local map, if a successful match can be found, update the information of the matched node. Otherwise, add a new node, including the node's label, the scale-invariant features and the coordinates in the corresponding local reference frame to the local map. Note that the selection of the local reference frame has nothing to do with its global pose in the world model. If the robot wants to go somewhere, the view that correlates present node with the target node and the associated free beam will be used to guide the robot leave for the target.
The environment model obtained by multiple robots consists of a database of model views. The ith location/node in the nth local map,
After a robot, i.e. the robot Rm, reaches a certain node, the node's coordinates in corresponding local reference frame, the associated SIFT features of all the views together with the view that belongs to the last node but directs to present node will be sent to its teammates in order to know whether this node has ever been visited. For the robot Rn being enquired, the new query sets of SIFT features {S
m
(Qk)|k=1…K} will be used to find the matched node in its own local map by matching against the database of

where C
th
is the matching threshold and f(x) is the step function described in Eqn.3. It is obvious that only when the number of the matched pairs
In the initial stage we fulfill the map merging by a single-node matching. Different from the method proposed by Kosecka (Kosecka, J. & Fayin Li, 2005), our location recognition is somewhat similar to gear engagement in which each view of a node is regarded as a tooth of a gear. The proposed algorithm is described as follows:
Firstly, as long as the robot R
n
received the query information from the robot R
m
, it will find the first matched teeth
Secondly, robot R
n
estimates the likelihood that the images stream {Q
k
|k=1…K} can be observed at location l
i
by:


Where j(k, p
i
, K) is to align the sequence of the corresponding views based on
Thirdly, after all the replies from other robots have been collected, the robot R
m
will select a certain local map which comprises the most similar location to extend its own local map by:
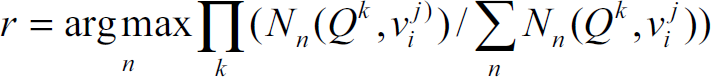
where n is the index of the robot. Based on the linked map, the robot R m may select appropriate exploration strategies by either moving to a visited location to refine the merged map or heading for the unexplored location to improve the efficiency of the multi-robot exploration.
Though SIFT features comprise abundant and distinct information of the surroundings compared with other features such as line or corner, the performance of location recognition is still affected by scanty of the features, dynamics of the environment or similarity of different locations. So we use a cooperative Hidden Markov Model to resolve these issues by modeling the neighborhood relationships between individual locations. According to the Bayes law and Markov assumption, the belief of the robot R
m
's current location in its own local map

where η is a normalizing constant. In perceptual model
Taking into account the robot R
m
's current pose which subject to


where
Sampling in different distributions
finds the first matched teeth calculates the perception model If one matched node l
i
is found, update l
i
.
Else if several matched nodes are found, record the robot R
m
's belief Else if no matched node is found, send corresponding information to other robots and add a new node to the mth local map.(to If several matched nodes are returned, find the best map by Eqn7 and merge the two maps.
finds the first matched teeth calculates the perception model If one node is matched, Else if several matched nodes are found, record the robot R
m
's belief Bel
m
(L
n
t
) of all matched nodes in the nth local map and return no node to robot R
m
. Else if no node is found matching, return no node to robot R
m
.
Table 1. Map merging based on cooperative HMM
The topological map developed has been implemented and tested in a large-scale official environment by a team of autonomous mobile robots. Several robots named Pioneer 3-DX are equipped with a PTZ camera, a ring of 16 Polaroid ultrasonic sensors and a laser range finder from SICK Electro-Optics that provides scans in 180° angular field with a resolution of 1° through its RS232 interface with 19200 baud. All the robots can communicate with each other by a strong wireless networks dispread in the building.
To validate the proposed topological map in resolving the challenges mentioned in section 1, two experiments are executed in a 50m × 18m official environment where a variety of furniture such as desks, chairs and book shelves are placed.
Map merging by multi-robots
The experiment of map merging demonstrates that the proposed map is easy to be integrated by multi-robots. Considering the fact that a team of mobile robots are placed in an entirely unknown environment for rescue missions, there often exist no landmarks for the robot to recognize the specific locations. Furthermore, the robots may start from different locations in order to improve the searching efficiency, which means it is difficult to assign an initial pose in the same world reference frame to each robot. Therefore, in our experiment, no artificial landmark is placed in the building and the initial poses of all the robots are also unknown. In this case, the map merging depend purely on the spatial relationship between individual locations and the corresponding SIFT features of the nodes rather than the global pose in a certain world reference frame.
Provided three local maps a1-a2-a3-a4-a5, b1-b2-b3 and c1-c2-c3-c4-c5 have been constructed simultaneously in Fig.4. Without the help of artificial landmarks, the metric map may have trouble to merge the three local maps by purely the scan matching techniques. On the one hand, it is infeasible to merge the different local maps by scan matching due to the huge time consumed in data registering. On the other hand, the features of line or corner can't supply the sufficient proof for matching the node a4 in Fig.4a with the node b2 in Fig.4b or the node c4 in Fig.4c. The topological map, however, can handle these difficulties easily by cooperative HMM or even by a single-node matching. The SIFT features denoted as the black or yellow circle with certain radius and direction together with the free beams denoted as green sectors, as is shown in fig.5b, supply the robots with a reliable way to distinguish the node a4 with a5 (shown in Fig.5a) so that the three local maps can be integrated into one as soon as possible.

Local metric maps and topological maps constructed by three robots

a) Map merging by b) the free beams and the SIFT features
Due to the fact that the performance of map merging is mainly decided by location recognition, Table 2 shows us the correct recognition rate for 37 nodes and 118 views by single-node matching and cooperative HMM during the course of exploration and navigation. At exploration stage, the views of all the nodes are considered to be static, while at navigation stage, the environmental illumination and dynamics may change more often. Compared with the recognition performance of single-node matching, cooperative HMM can obtain a reliable and high recognition result by taking into account the spatial relationship between different nodes.
Recognition performance for 37 nodes and 118 views in terms of % of correctly classified nodes by Single-node matching and HMM at exploration stage and navigation stage respectively

As far as the cooperative exploration is concerned, a good map representation should be not only easy for merging but also convenient for strategy making. Since market-based approaches have recently been gaining popularity as efficient and versatile coordination mechanisms, we use the economic approach to validate the proposed topological map and allocate targets for robots through auction. Fig.6 shows us the experimental results when the robots start from the same location, where the solid lines denote the practical trajectories of the robots. The area painted with light color means the region explored by corresponding robot, whereas the deep color means the obstacle or the wall. A topological map consists of 37 nodes and 118 views can be extracted online when the robots explore the environment. The node in Fig.6 is denoted with small circle and the robot is denoted with the big one. Different from these market-based approaches based on metric map, the target points/commodities used in our experiments are detectable nodes rather than the global position of the frontier points, which means the global localization and the initial pose of each robot in a certain world reference frame are not necessary during the course of exploration. Since global localization means nothing to the robot, the performance of cooperative exploration is robust to the robots' kidnapping. For example, when a kidnapped bidder (purple robot) reaches the node F, no matter whether the auctioneer (red robot) is kidnapped or not, the view that directs to the unexplored region will be selected if present node has been recognized as the target point. In contrast, the robot in metric map will keep moving to the “global position” of the target point until both the bidder and the auctioneer have recovered from the kidnapping.
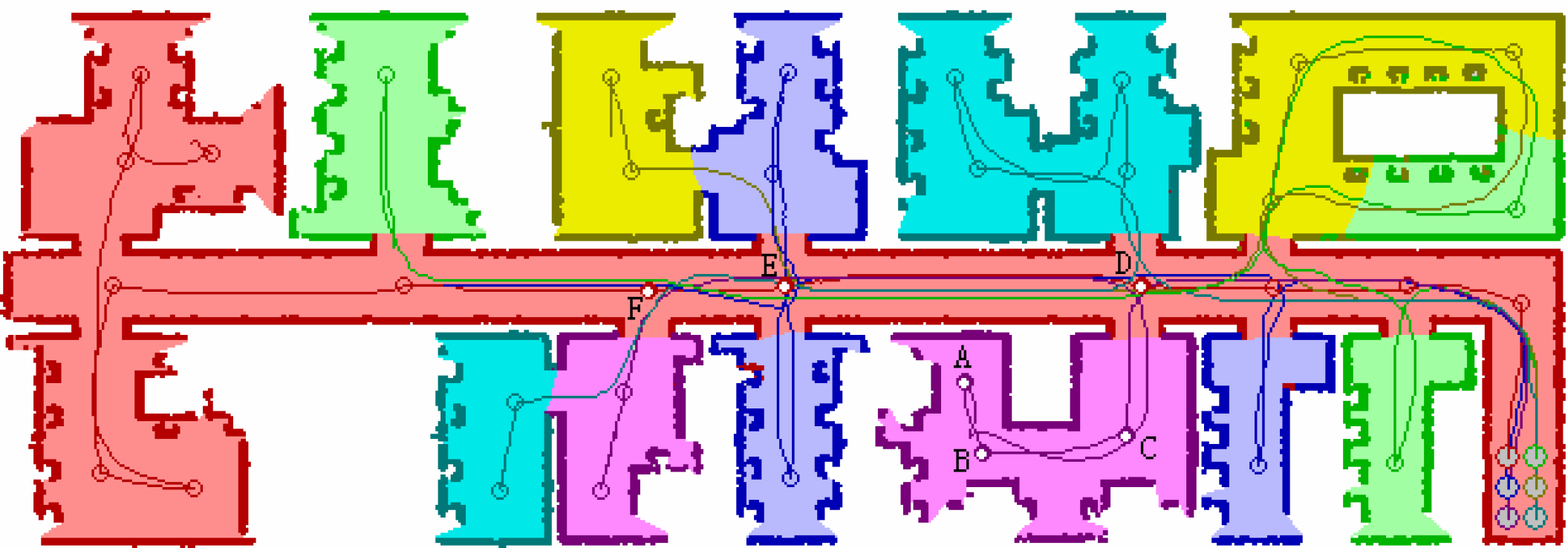
Cooperative exploration when the robots start from the same location
Another advantage brought by the topological map is the navigation without global localization. Besides the cooperative strategies, navigation based on an existing map also plays an important role in exploration efficiency. Provided the purple robot reaches the node A, the node F may have chance to be selected as the next target point according to certain principles. If the robot is guided by a metric map, it has to plan a feasible path from the node A to the target point F. It is obvious that there exists a local minimum between the two points, which means the failure of path tracking will trap the robot in the region A, B or C forever. Topological map, however, can produce a feasible path A-B-C-D-E-F easily by searching the linking relationship between the individual nodes. Thereafter, the global path is divided into several pieces and each neighboring node will be regarded as the sub-goal so that the robot is not inclined to be trapped by the minima.
Fig.7a shows us the time spent in the exploration when several robots start from either the dispersive locations or the same location. It is clear that the time consuming decrease nonlinearly with the increase of the robots' amount. Furthermore, the robots that start from dispersive locations spent less time on exploration than those who start from the same location. This phenomenon can be explained by the average repeat coverage rate shown in Fig.7b. The repeat coverage rate is calculated by 100*(N visit −N total )/N total , where N visit is the total number of visited times for all the nodes and N total is the sum of the nodes in the environment. When the robots start from the same location, the repeat coverage rate is much higher than that of dispersive case. Therefore, the proposed topological map constructs a reliable, robust and efficient platform for cooperative exploration by removing the physical constraints such as the landmarks in the environments and the global localization of the robot so that the robots can start anywhere without “worrying about” its global poses in the world reference frame.
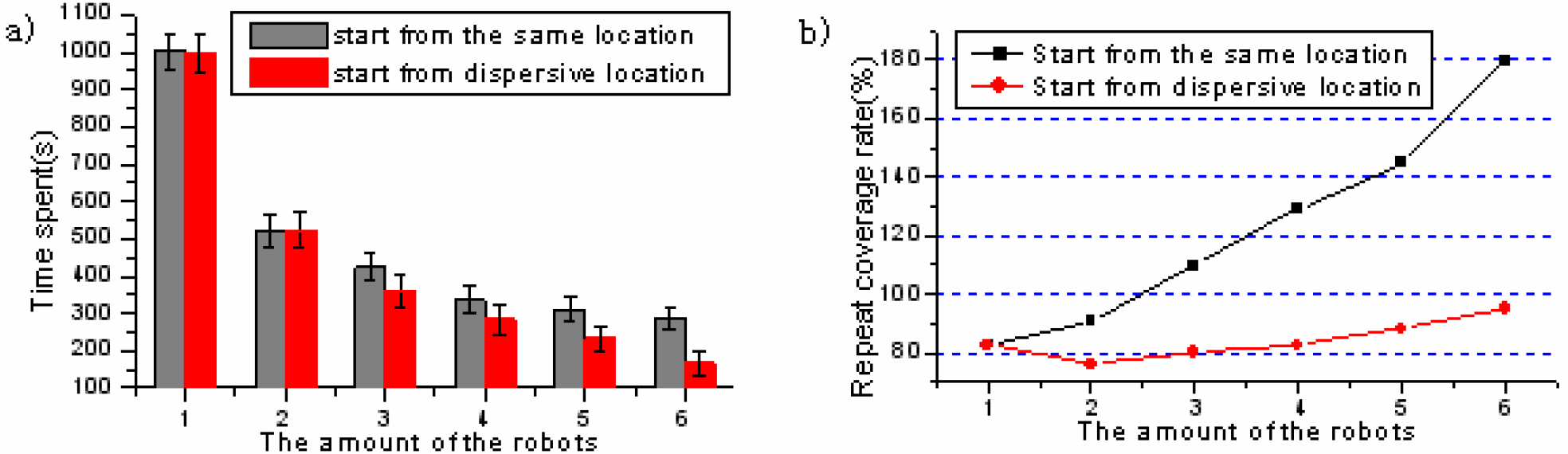
a) Time spent and b) Repeat coverage rate when the robots start from the dispersive and the same location respectively
Inspired by human's capability of navigation without precisely global localization, we first propose a novel topological map that represents the environment with the laser's free beams and the visual scale-invariant features. By virtue of a reactive approach, BCM, the proposed topological map can be constructed online without the interference of the operators.
Compared with the traditional topological map and metric map, the proposed map form has such advantages as follows:
Firstly, no landmarks are required in the course of exploration, which endows the robots with the capability of exploring in entirely unknown environments.
Secondly, the map merging doesn't depend on the initial pose and the global localization of the robots, which make it possible for multi-robots to explore a large-scale environment cooperatively and efficiently.
Thirdly, the proposed topological map supplies a new way for autonomous exploration/navigation, that is, exploration/navigation without global localization.
There also exist some limitations need to be resolved:
Firstly, the topological map can only be used in typical indoor environments such as home, offices, hospitals etc, in which the topology structure can be extracted. It may fail in spacious region, i.e. a square or outdoors, where no obstacles can be detected. To resolve the limitation, a feasible method is to construct a hierarchical map in which the topological map is used to outline the structure, while the metric map is used to detail the topological node.
Secondly, the data transfer of SIFT features from one robot to another puts considerable burden on wireless communication. Though we resolve this problem by, on the one hand, decreasing the dimension of the feature vector, on the other hand, removing the features with low repeatability, this problem is still unresolved thoroughly. Thirdly, the dynamics of the environment is not considered. We should admit that the dynamics such as door open and close will change the type of the node greatly or even make the node disappear. To resolve the problem of environmental dynamics will be our future research in this field.
Footnotes
6. Acknowledgement
This work has been supported by the National High-Tech Research and Development Plan of China under Grant No. 2006AA04Z259