
Abstract
In this study, we present a visual recognition system that enables a robot to clean a tabletop. The proposed system comprises object recognition, material recognition and ungraspable object detection using information acquired from a visual sensor. Multiple cues such as colour, texture and three-dimensional point-clouds are incorporated adaptively for achieving object recognition. Moreover, near-infrared (NIR) reflection intensities captured by the visual sensor are used for realizing material recognition. The Gaussian mixture model (GMM) is employed for modelling the tabletop surface that is used for detecting ungraspable objects. The proposed system was implemented in a humanoid robot, and tasks such as object and material recognition were performed in various environments. In addition, we evaluated ungraspable object detection using various objects such as dust, grains and paper waste. Finally, we executed the cleaning task to evaluate the proposed system's performance. The results revealed that the proposed system affords high recognition rates and enables humanoid robots to perform domestic service tasks such as cleaning.
1. Introduction
In recent years, with technological advancements, robots have been used in varying environments for many purposes. In the near future, autonomous mobile robots are expected to carry out routine housework tasks in complex environments. To this end, robots should be able to recognize their surroundings, which might change unpredictably. Then, visual information becomes a basic element for executing various tasks in the domestic environment. Using a visual recognition system, domestic service robots can execute various tasks, including cleaning.
Although autonomous robots that can clean floors are commercially available, they cannot easily clean a tabletop, especially when there are objects on it. In this case, a humanoid robot is necessary because it can manipulate such objects for accomplishing the task. A visual processing system including object detection, object recognition and material recognition is required for this purpose. For example, if cleaning is performed on a tabletop on which there are a few graspable (plastic cups, cans, etc.) and ungraspable (coffee grains, sugar, etc.) objects, these objects should first be detected. A graspable object that is recognized as rubbish should be grasped and put into the dustbin, while ungraspable objects should be cleaned using a vacuum cleaner attached to the robot. Robot effectiveness can be enhanced through the incorporation of material recognition, because the robot can then segregate the collected rubbish into burnable and unburnable rubbish.
In this study, we present a visual recognition system that uses information acquired from a three-dimensional (3D) visual sensor [1]. The proposed system comprises object detection, object recognition and material recognition. Object detection can be divided into graspable and ungraspable object detection. Multiple features (i.e., colour, texture and shape information) are adaptively integrated to realize robust object recognition. Near-infrared (NIR) reflection intensity captured using a time-of-flight (TOF) camera is used for realizing material recognition. The proposed system is implemented on a humanoid robot so that the recognition results can be used for planning cleaning tasks. Objects on the table are moved or cleaned to ensure that the entire table is clean.
There are many related works on object recognition, material recognition and cleaning robots. Most existing research on 3D object recognition is based only on 3D point-clouds and does not consider the integration of multiple features [2, 3]. In [4], the authors have proposed colour and 3D information-based colour cubic higher-order auto-correlation (colour CHLAC) features for object detection in cluttered scenarios. However, colour CHLAC features are not rotation invariant and change depending on illumination conditions, because colour information is directly integrated in the feature. The RGB-D dataset was provided and a 3D object-recognition method based on colour, texture and 3D information was proposed in [5]. However, the method yielded different results in different environments, because the features (i.e., colour and depth information) were not adaptively incorporated.
Appearance-based material recognition has been studied in [6, 7]. In [6], multiple cues such as texture and edges are used for realizing material recognition. However, because these features do not represent material information well, the level of accuracy afforded is insufficient for practical purposes. NIR from environmental light is used in conjunction with colour information to realize material recognition tasks in [7]. However, the system is not robust because the amount and the type of NIR in environmental light are unknown, and object shape is not considered. In contrast, the proposed material recognition scheme uses a TOF camera, which offers control over NIR as well as 3D information of target objects.
Several cleaning robots have been developed [8–11]. Two-class material categorization of beverage containers, i.e., plastic bottles and cans, using the sound captured as the robot grasps these objects is applied in [8] for cleaning tasks. However, multi-class material recognition using NIR reflection intensities and object identification, which is useful for tasks such as tidying a tabletop, which involves cleaning ungraspable objects using tools such as a vacuum cleaner, is not considered in this study. In contrast, [9] deals with the problem of manipulating a vacuum cleaner for cleaning table surfaces effectively, but material and object recognition required for achieving cleaning tasks are not considered. In [10], the cleaning task of a vertical flat surface by a standing humanoid robot is investigated. However, the focus of this study is on the evaluation of the trajectory/force controller rather than the visual recognition-based cleaning. System integration of an assistive robot for tidying and cleaning rooms has been studied in [11]. However, the cleaning task of a tabletop involving graspable and ungraspable object recognition is not considered.
The remainder of this paper is organized as follows: An overview of the cleaning task, including its definition, the objects involved, task flow and robot platform, is described in the next section. The details of the visual recognition system, i.e., object recognition, material recognition and ungraspable object detection, are explained in section 3. Section 4 discusses the realization of the cleaning task, which integrates visual perception, as discussed in the previous section, and object manipulation as part of the task. Experimental results are discussed in section 5. Finally, section 6 concludes this study.
2. Approaches to Cleaning
2.1. Overview of Cleaning Task
In this study, “cleaning” is defined as a task that puts the table back into a clean or tidy state, as initially memorized by the robot. We define rubbish as any object on the target table that was not previously memorized by the robot (unknown objects). In contrast, every memorized object on the tabletop is not considered rubbish (we call such objects goods) and should be maintained in the same position as it was before cleaning. Here, upon task completion, the objects that are classified as rubbish are cleaned, while those classified as goods are left on the tabletop in their initial state.
According to the graspability of the objects existing on the table, the objects are classified as “graspable” (i.e., objects that can be grasped by the robot) and “ungraspable” (i.e., objects that cannot be grasped by the robot). Furthermore, ungraspable objects can be categorized as “small” and “big.” Small objects are objects of low height and are difficult to segregate with only plane detection. Normally, small objects are light and fine, such as grills and sugar. Most small objects on the tabletop can be thought of as rubbish; given their light weight, these objects can be removed using tools such as a vacuum cleaner. By contrast, big objects have heights such that they can be segregated by only plane detection, but are too heavy to be grasped by the robot, such as an electric kettle or coffee maker. In a normal situation, big objects tend to be categorized as goods. However, there are some situations in which small objects fall under the goods category, e.g., necklaces and documents, or big objects fall under the rubbish category, such as big boxes. This situation is out of the scope of our study. However, in our opinion, this problem can be solved by asking for human assistance.
For graspable objects, graspable rubbish can be moved to the dustbin, while graspable goods can be moved to suitable locations. An overview of the cleaning task is shown in Fig. 1.

Overview of cleaning task. The top panel illustrates the learning phase, i.e., learning the table's tidy state, which is the target of the cleaning task, while the bottom panel shows the cleaning task including tabletop recognition and object manipulation (e.g., object grasping and vacuuming ungraspable objects).
It can be seen from Fig. 1 that the cleaning task involves two phases: learning and task execution. In the learning phase, table properties such as table colour, material and location are learned by the robot. Moreover, the locations of goods on the tabletop are memorized as the initial or tidy state of the table. Once the tidy state is learned, the task-execution phase can be executed at any time. The task-execution phase includes tabletop recognition, that is, to detect and recognize the objects on the table. The graspable objects are grasped and placed at suitable positions, while the ungraspable rubbish is cleaned using a vacuum cleaner.
The basic elements required to accomplish the cleaning task are navigation, object manipulation and perception. Robot navigation is achieved using a laser range finder (LRF) for performing simultaneous localization and mapping (SLAM). The 3D information captured by the visual sensor [1] is used and rapidly exploring random tree (RRT)-based [12] path planning is employed for object manipulation. Robot perception is achieved by incorporating multiple cues such as colour, texture, 3D point-clouds and NIR reflection intensity for constructing a visual recognition system comprising object detection, object recognition and material recognition. The details of robot perception are discussed in section 3.
2.2. Robot Platform
The robot platform used in this paper is shown in Fig. 2. The robot is equipped with a visual sensor (for details see section 3.1), arms capable of six degrees of freedom (DOF), and 6-DOF hands. Moreover, omnidirectional wheels and a laser range finder (LRF) enable the robot to move freely within a room. To realize the previously described cleaning task, the robot should be equipped with a handy vacuum cleaner for cleaning the ungraspable rubbish. A handy vacuum cleaner is installed on the robot, with its hose set on the right hand. Thus, graspable rubbish, such as cans, can be put into the dustbin given that the left hand can grasp objects. Moreover, an XBee wireless radio module is installed on the vacuum cleaner to enable the robot to switch the vacuum cleaner on for cleaning ungraspable rubbish and switch it off automatically when done.

Robot equipped with 3D visual sensor and handy vacuum cleaner.
3. Vision System
As mentioned in the previous section, robot perception, which is required for executing the cleaning task, consists of (1) object detection, (2) object recognition, and (3) material recognition. In general, in a complex background, (1) is not an easy task. In this study, we employ (a) motion-attention-based object detection [13], (b) plane-detection-based object detection [14], (c) active search [15], and (d) ungraspable object detection. (a) can be used for finding novel objects in cluttered scenes during the learning phase, while (b) and (c) are suitable for use in the recognition phase. If the object is on the table, (b) is preferable over (c). However, we can use (b) and (c) complementarily when plane detection fails to achieve the desired level of system robustness. In this study, we focus our discussion on (1)-(d), (2) and (3) for realizing the visual recognition system. For further information on (1)(a)–(c), please refer to [13–15].
3.1. Visual Sensor
In this study, we use a 3D visual sensor [1]. This sensor consists of one TOF and two CCD cameras, as shown in Fig. 2. Here, colour information and 3D point clouds can be acquired in real time by calibrating the TOF and the two CCD cameras. Moreover, NIR reflection intensities can be acquired from the TOF camera because this sensor uses intensity values for calculating the confidence values of measured depth information. Therefore, colour, texture, 3D point clouds and NIR reflection intensities, which are captured by the sensor, are used for realizing object detection, object recognition and material recognition.
3.2. Multiple-Cue-based 3D Object Recognition
Multiple cues acquired from the visual sensor are used to construct the object recognition system shown in Fig. 3. The proposed system is divided into the learning and recognition phases. Object extraction, which is the first step in both phases, is built based on motion-attention and plane detection. The motion-attention-based method uses a motion detector for extracting an initial object region; the object region is then refined using the colour and depth information of the initial region. For more details on this method, please refer to [13]. For detecting objects on a table, the plane detection [14] technique is beneficial. The 3D randomized Hough transform (3DRHT) is used for fast and accurate plane detection. In the learning phase, an object database consisting of multiple feature vectors in various views is generated. Here, scale-, translation- and rotation-invariant properties are desirable. A histogram-based feature is employed in the proposed method because it can realize the rotation-and translation-invariant properties. Moreover, we can use 3D information to normalize scale and achieve the scale-invariant property. Because it is difficult to achieve the view-invariant property, we realized the same by matching all features obtained from various viewpoints. Next, we explain the features employed in this study.

Object recognition system.
3.2.1. Feature Extraction
To distinguish among objects of similar shape but different colour or texture, colour and texture information is used. Colour information is calculated as a colour histogram of hue (H) and saturation (S) in the HSV colour space, which was selected considering its robustness to illumination changes. The values of H and S at each pixel inside the target object are quantized into bins of size 32 and 10, respectively.
Texture information is represented as a bag of keypoints (BoK) [16]. According to [17], BoK-based image classification can be boosted when using many keypoints. To this end, a dense scale-invariant feature transform (DSIFT) [18] is employed instead of the original scale-invariant feature transform (SIFT) [19], which tends to extract fewer keypoints. We can control the number of keypoints extracted using SIFT by adjusting the threshold, but we cannot control individual points. This is undesirable for creating a better representation of texture information. Before obtaining the histogram, the DSIFT is vector-quantized using the predetermined 500-dimensional codebook, generated by k-means clustering from multiple indoor random scene images.
Shape information is represented as shape distribution (SD) [2]. SD represents the characteristics of an object's shape by calculating a metric among vertices. We use the distances between all combinations of two vertices in an object region, and compute the histogram of these distances as an object feature. The distances are quantized into bins of size 80. The bin sizes of colour, texture and shape information are determined by a preliminary experiment.
3.2.2. Object Recognition
In the recognition phase, the target object is compared to the object database. First, the Bhattacharyya distance of each feature Df(hkf,hinf) is calculated as follows:
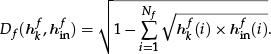
Here, f, hkf, hinf and Nf respectively represent the feature type f ∈ {colour, texture, shape} reference histogram of feature f that belongs to class k in the object database, histogram of feature f for a given target object, and size of those histograms. The likelihood of the target object for feature f is defined as follows:

where σf2 represents a variance of distances for feature f, which is calculated by cross validation over the object database (see section 3.2.3).
Assuming that the features are independent, the integrated likelihood P(hin|k) is defined as follows:

where win f is the weight of feature f, which is determined adaptively considering the environment and similarity among objects in the database (see section 3.2.4). win f is normalized as Σfwin f = 1. Finally, the result is determined from k-NN among the integrated distances:
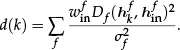
k-NN is easy to implement in our approach because we use adaptive weights, which change according to input data.
3.2.3. Database Cross-Validation
The parameter σf2 in (2), which expresses the variance of distances, can be calculated by cross-validation over the object database. Consider that each object has V feature vectors for each feature f. Let the reference histogram of feature f that belongs to the class k for a given view v be hkvf. The parameter σf2 can then be calculated as follows:

where, min(Dkf) indicates the minimum distance in Dkf, which is defined as follows:

Here, µf is the mean of all min(Dkf) and K denotes the number of objects in the database.
3.2.4. Adaptive Weights
The weights of each feature affect overall performance in multiple-features-based recognition. The weights can be calculated in a straightforward manner considering the environment and similarities (colour, texture, shape, etc.) among objects in the database. For example, in a dark environment, shape information, which is calculated based on 3D point clouds, is the most reliable type of information because it is robust to changes in illumination. However, objects with similar shape cannot be distinguished using only shape information. In this case, colour or texture information offers better reliability than shape information. Therefore, we determine the weights using the following policies.
For a given feature, if the minimum distance between the target object and database is large, the feature will not afford effective recognition. This will decrease the integrated likelihood of the recognition results and lead to false recognition. Therefore, weight should be set inverse to the minimum distance.
Database complexity, i.e., the similarity of a given feature among different objects, is also responsible for false recognition. To avoid this, the minimum distance from different objects can be used as a parameter for controlling the weights.
Based on these policies, the weights are calculated as follows:
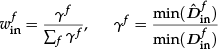
where,


kminf represents the index of the minimum distance and is defined as
3.3. NIR-based Material Recognition
In this section, we discuss the features used for material recognition. Material information represented by the reflectivity coefficient is an important part of the features because this information is different for each material. Additionally, distance and incident angle should be considered for robust recognition.
3.3.1. Radiance Model for TOF Camera
NIR reflection intensities obtained using the TOF camera are not affected by lighting conditions [20–22]. However, these intensities vary widely according to the integration time δt, distance to the object's surface d, and incident angle
Assume a Lambertian object surface. Generally, reflection from a Lambertian surface is diffuse. Then, a simple radiance model, shown in Fig. 4, is used for representing NIR reflection intensity. According to this model, the intensity of a certain wavelength (λ = 850nm for the TOF camera) can be written as follows:

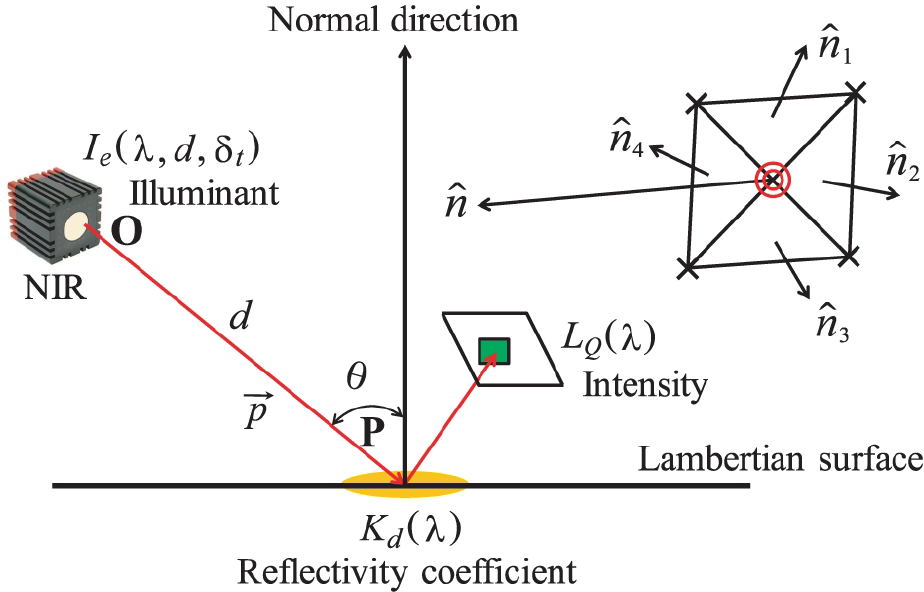
Simple radiance model for TOF camera.
where LQ, Ie, Kd, θ, d and δt represent, respectively, the reflection intensity, illuminant (NIR-light emitted from the TOF camera), reflectivity coefficient, incident angle relative to illuminant direction (centre of the TOF camera), surface-illuminant distance, and integration time. The normal vector ñ and incident angle θ can be obtained from the following equations:

where

Proposed material recognition system.
3.3.2. Classification Using SVM Classifiers
As mentioned above, the feature vector m(LQ, δt, d, θ) captures the reflectivity coefficient of the object's material. This information should be determined in various combinations to ensure robust material recognition. However, incorporating all elements into one classifier may result in significantly increased learning time and memory consumption. Here, the material map, which consists of multiple SVM classifiers, is proposed for overcoming this issue. SVM is used because it yields good classification performance. Normally, SVM is used for binary classification. However, it can be expanded for multi-class classification by considering all combinations of binary classifiers in the multi-class problem. In this study, we use LIBSVM for SVM implementation; for further information on SVM, please refer to [23]. In this study, two-dimensional data, which consist of NIR reflection intensity LQ and the incident angle θ of each pixel in the object region, are used for classifier training.
For generating a material map, a set of training data consisting of NIR and depth images is collected in the learning phase. Now, let dmin, dmax, δtmin, δtmax, respectively, be the minimum and maximum distances d and integration times δt in the collected training data. Furthermore, let T and D be the grid numbers of δt and d, respectively. Here, we select the pixels of interest


so that each grid
In the recognition phase, the target object is extracted using plane detection [14], and material information is calculated. The material map can be used if δt and d are known. Here, the δt can be set by adjusting a parameter of the TOF camera, while d can be measured using the TOF camera. Once d and δt of a given pixel are known, (12) and (13) are used to determine the grid
3.3.3. Object-based Smoothing
The above method gives results on a pixel-basis; consequently, the results are inconsistent. Therefore, these are smoothed to obtain the final result. We consider object-based smoothing here.
Let M be the number of materials to be classified.

This probability represents the confidence of material recognition at pixel (u, v), and the final result is determined from the maximum number of votes. For object-based smoothing, the final voting process is performed among the pixels inside the object region to determine the target object's material. The final decision regarding an object's material m̂i is arrived at as follows:

Because the proposed system is implemented in a real robot, it is possible for the robot to change pose and/or distance to the target object if the confidence of a given recognition result is low.
3.4. GMM-based Ungraspable Object Detection
When a robot cleans objects of adequate height, such as plastic bottles and cans, on a table, the plane detection method described in [14] can be applied for detecting objects on the table, recognizing them using the proposed recognition system, and then grasping them. However, small objects such as paper waste are difficult to detect using plane detection.
In this study, the table surface colour is learned in the learning phase, and colour differences between the table and other objects are used for object detection. More specifically, for robustness to changes in illumination, the table colour (i.e., hue and saturation in the HSV colour space) is represented using a Gaussian mixture model (GMM); this model is then used in the detection phase for discriminating the table from other objects. The GMM is employed because it has good colour-segmentation performance. However, object detection will fail if the colour of the table and objects is identical when using colour as the only discriminating factor. Therefore, NIR reflection intensity, which includes material information, is an important object-detection cue. Here, incident angle θ in the material information can be adjusted, similar to that in the learning phase; therefore, it can be ignored. Therefore, the feature vector I(H, S, LQ), which consists of the table's colour (H and S) and NIR reflection intensity LQ, is modelled using the GMM to achieve more robust small object detection. An overview of the system is shown in Fig. 6.
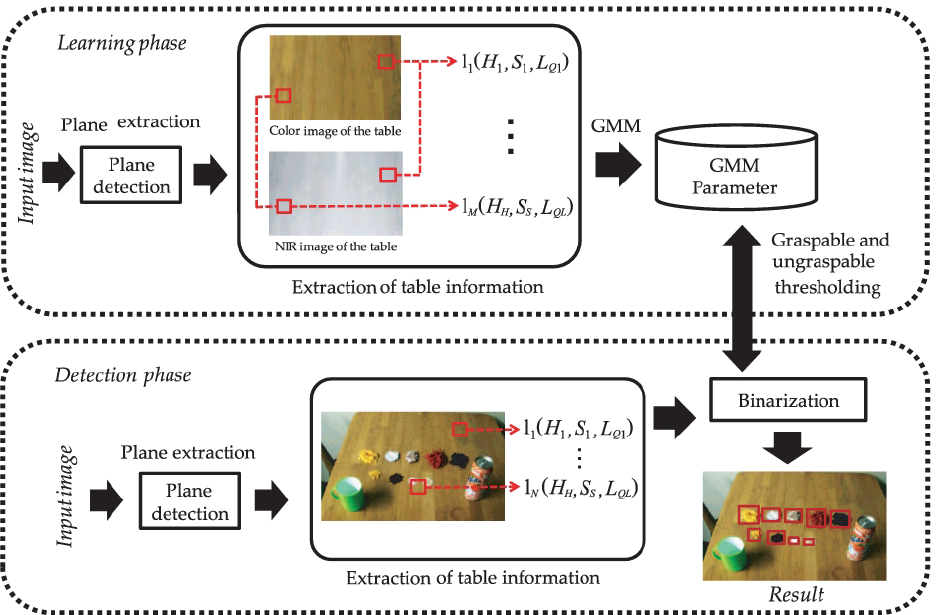
Overview of GMM-based ungraspable object detection.
Our task in the learning phase is to maximize the likelihood of all pixels that belong to the table. Let Ii be the feature vector of a pixel i on the table, and K be the number of Gaussian components in the GMM that has parameters Θ = (π1, µ1, Σ1,…, πK, µK, Σ K ). Then, the likelihood of the feature vector Ii can be calculated as follows:

where, Nscr;(*|*) represents a Gaussian distribution. The parameter Θ is estimated using the EM algorithm. In this study, we conducted preliminary experiments to find the best number of Gaussian components for the GMM model and determined that K = 3 yields the best result. In future, the Dirichlet process mixture (DPM) [24, 25] can be used for determining the number of mixture models.
In the recognition phase, the likelihood of each pixel Ii on the table is calculated using (16) and binarized as follows for generating a binarized map.

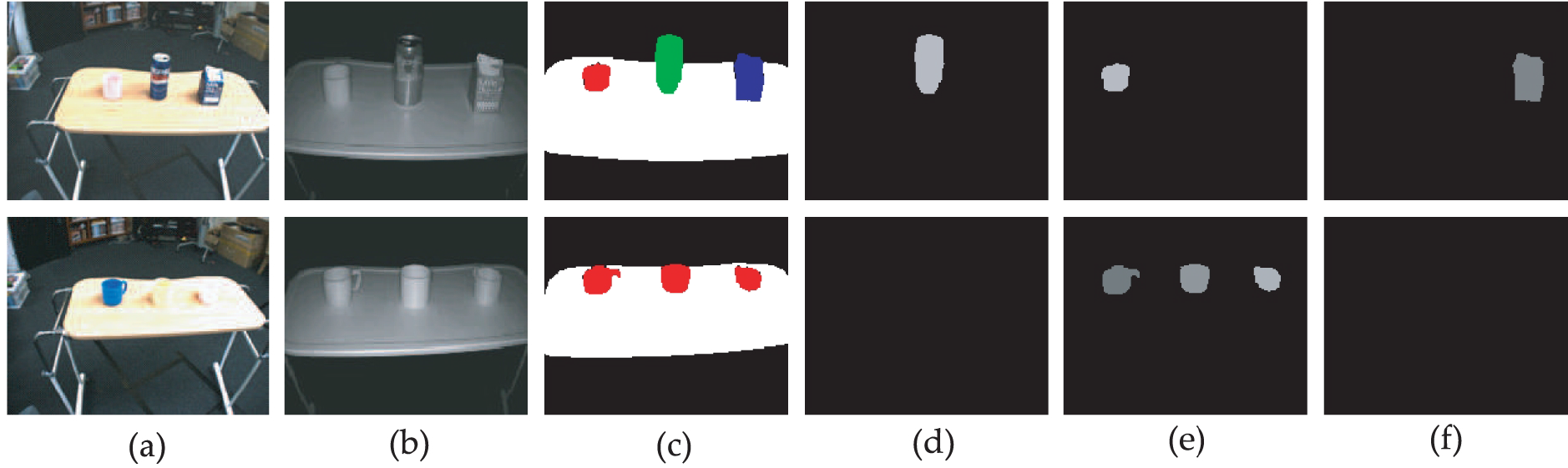
Here, Pt is an empirically defined threshold. Thereafter adjunctions are applied to the generated binarized map for refining it. Finally, connected-component labelling is employed, and the area of region Rℓ of each candidate S(Rℓ) (ℓ ∈ {1,2,…, L}) is calculated as follows:
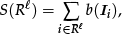
where L represents the number of labels. Candidate regions are filtered, and only the region Rℓ ∈ {Smin ≤ S(Rℓ) ≤ Smax} is selected as a detected object. Here, Smin and Smax, respectively denote the minimum and maximum area of region allowed; these values are determined empirically.
Given that these small objects are ungraspable by the robot, a handy vacuum cleaner is used to clean each selected region R*.
4. Realization of Cleaning Task
Robot perception, as discussed in the previous section, robot navigation, and object manipulation are integrated to realize the cleaning task as mentioned in section 2. The process flow of the cleaning task is shown in Fig. 7, and the details of the task are as follows.

Flowchart of cleaning task. The green block depicts the entire task, while the blue and red blocks, respectively, show the details of the tabletop recognition task and the robot's planning of executing the cleaning task.
In the learning phase, the robot memorizes information regarding the target table and the goods placed on the table. Colour and material information of the table surface is learned by estimating the GMM parameter mentioned in section 3.4. Once this parameter is learned, the robot learns information regarding the clean state. Here, graspable goods are detected using plane detection, and 3D object recognition is performed to recognize goods for memorizing their positions. After the robot memorizes the table with the goods on it, it can perform the actual task at any time. Task execution can be divided into tabletop recognition using robot perception (see section 3), planning and execution, which involves robot navigation and manipulation of graspable and ungraspable objects.
At task commencement, the robot navigates to the target table. Because the robot is LRF-equipped, iterative-closest-point (ICP)-based [26] SLAM is used for localization and map ping. For robot navigation path planning, we use an RRT-based [12] algorithm. After reaching the target table, the robot performs graspable object detection (i.e., plane-detection-based object detection or active-search-based object detection) to detect graspable objects on the table. Thereafter, specific object recognition using 3D object recognition is performed to recognize graspable objects. If the object is known (i.e., goods), it is grasped by the left hand, because the right hand holds the vacuum cleaner, and placed on another table. If the object is unknown (i.e., rubbish), the robot performs material recognition to classify the rubbish as burnable or unburnable. When there is some graspable rubbish, the robot can grasp the same and place it in the dustbin. Graspable object manipulation is performed until all graspable rubbish is thrown into the dustbin and all goods are placed on another table. In this study, path planning of the object-manipulation arm is performed using the RRT [12] algorithm.
After cleaning graspable rubbish, ungraspable object detection is performed using the GMM-based object detection scheme. Once ungraspable rubbish is detected, the vacuum cleaner is switched on automatically through an XBee wireless radio module. Then, the vacuum cleaner's hose is moved over each piece of detected ungraspable rubbish, as mentioned in section 3.4, for cleaning. To ensure that the ungraspable rubbish is cleared efficiently, the vacuum cleaner is moved around the centre of a detected location. The vacuum cleaner is switched off automatically when no more ungraspable rubbish is detected. Finally, the task is completed when the graspable goods are put back onto the table in their respective initial positions.
5. Experiments
We conducted experiments to validate the proposed object recognition, material recognition and ungraspable object detection schemes. Moreover, the implementation of the visual recognition system in the robot and the results of the cleaning task are described.
5.1. Evaluation of 3D Object Recognition
An experiment is carried out in the living room shown in Fig. 8 using 50 objects, as shown in Fig. 9. A user shows each object from various angles to the robot, and the object database, which contains the feature vectors of 50 frames per object, is generated in the learning phase. In the recognition phase, recognition is performed at five different locations under different illumination conditions, as shown in Fig. 10. Here, 50 image frames (10 frames per location) of each object are recognized, while the learning phase is completed at location 1. We use six different feature combinations, i.e., colour; texture; shape; integration of colour and texture; integration of colour, texture, an d shape without any weights; and integration of colour, texture, and shape with adaptive weights. The standard SIFT [19] and Colour-SIFT [27] approaches were applied for reference purposes. However, these approaches are based on keypoint matching.

Experimental environment: (a)living room, and (b)two-dimensional map of room.

Objects used for evaluation of 3D object recognition and their respective categories.

Varying illumination conditions. A fluorescent lamp is used at Locations 1, 4 and 5, while an incandescent lamp is used at Locations 2 and 3. The learning phase was conducted at Location 1.
For comparing the recognition results with regard to object properties, five categories, as shown in Fig. 9, were selected. Category 1 comprises objects having well-defined colours with different shapes and sizes. Category 2 comprises objects of the same colour and similar shapes. Category 3 comprises boxes of various sizes and textures. Category 4 contains cans of the same shape and size. Category 5 contains white dishes of different shapes and sizes.
The recognition rates of each feature for all objects in all locations are listed in Table 1. Moreover, Fig. 11 shows the recognition results for each object category (i.e., recognition results by category for all locations), while the results for each location (i.e., recognition results by location for all objects) are shown in Fig. 12.
Recognition results by category.

Recognition results by location.
3D object recognition results

5.1.1. Recognition by Colour and Texture Information
The objects, except those in categories 2 and 5, have rich textures. They can be recognized relatively easily using texture information as opposed to colour information, as can be inferred from Table 1. The standard SIFT [19] approach shows a similar tendency in this case, especially for categories 2 and 5, the objects of which have only a few reliable keypoints.
It can be seen from Fig. 11 that the objects in categories 1, 3 and 4, which have well-defined colours or rich textures, can be recognized almost perfectly using colour and texture information. As a matter of course, it is difficult to recognize category 2 objects, which are of a single colour and have fewer textures. Recognition of the white objects in category 5 under varying illumination conditions is even more difficult.
It is natural that the best recognition result was obtained at Location 1, where the learning phase had been conducted, as shown in Fig. 12. However, the results deteriorate with changes in illumination.
Recognition results obtained using Colour-SIFT [27] are superior to those obtained using only colour information, but inferior to those obtained using texture information or a combination of colour and texture information. The Colour-SIFT used in this experiment employs the Harris-Laplace detector, with which it is difficult to detect objects having fewer textures. This leads to false recognition and an inability to match owing to insufficient keypoints. We can see from Table 1 that the integration of colour and BoK-based texture (76.0 %) can improve the recognition result of the Colour-SIFT scheme (62.7 %) by 13%.
5.1.2. Recognition by Shape Information
As can be seen from Fig. 11, recognition by shape information yielded almost the same result as texture-based recognition, except in the case of category 4. This category comprises objects of similar size and shape, thus making recognition difficult using the shape-based method. However, the recognition result for category 5, the objects in which are difficult to recognize by colour or texture, can be improved using shape information. Moreover, it can be seen from Fig. 12 that the recognition results for shape information in different locations are stable, except for those obtained in location 4.
5.1.3. Recognition Using Integrated Information
It can be inferred from Table 1 that the recognition results can be improved considerably by integrating colour, texture and shape information. Especially when adaptive weights are employed, the deviation in recognition for each category or location can be suppressed, thus resulting in the best recognition rates compared with other methods.
The adaptive weights have a considerable bearing on the results of categories 2 and 5, as shown in Fig. 11. This is because the objects in these two categories have fewer textures, colours and shapes that can act as recognition clues. However, the colour information becomes unstable as the illumination conditions change. In this case, the weight assigned to colour information is adaptively decreased in the proposed method. In contrast, recognition of objects belonging to categories 1 and 3 is not as difficult because these objects offer an adequate number of recognition clues. Therefore, the method using adaptive weights offers no significant improvement in the recognition of objects in these categories over the method using fixed weights.
Fig. 13 shows examples of adaptive weights by category and location. It can be seen that the weight of shape information at location 5 is high compared to those of the other information types. This is because, at this location, the reliability of colour or texture information is low owing to dark lighting conditions. By contrast, because object learning was conducted at location 1, the weights at that location are varied according to the object properties. For example, the weight of shape information for category 4 (i.e., the category with objects of similar size and shape) is the least. In contrast, shape information has high weight for category 5, because colour or texture information is unreliable for this category.

Examples of adaptive weights. Each histogram depicts the weight of each feature. Variation of weights across the five locations is illustrated from left to right in a category, while variation across the five categories is illustrated from top to bottom in a location.
Changes in viewpoints of an object seemed to be the main source of false recognition in this experiment. It is impossible for the robot to observe an object from equally spaced viewpoints because a human user shows the object to the robot. Such biased observation samples are responsible for deviations in the voting process. In future, this can be avoided through autonomous learning by the robot.
5.2. Evaluation of Material Recognition
In order to evaluate the proposed material recognition algorithm, we conducted an experiment using 60 objects; these can be classified as woods, fabrics, papers, plastics, cans and ceramics, as shown in Fig. 14.

Objects used for material recognition.
The recognition task was performed from a distance of 60-80cm according to the leave-one-out method. The confusion matrix of the average recognition rate is shown in Fig. 15, and the mean of the recognition rates was 70.2%. False recognition mainly occurred with woods and ceramics. High variance in NIR reflection intensities with woods and ceramics led to such false recognition.

Confusion matrix of material recognition with six categories. The right side depicts the corresponding average recognition rate of each colour in the confusion matrix.
In contrast, the recognition rates of burnable (i.e., woods, fabrics and papers) and unburnable (i.e., plastics, cans and ceramics) objects was 97.7%. Because material recognition is performed on separate burnable and unburnable rubbish, this result qualifies the method for cleaning.
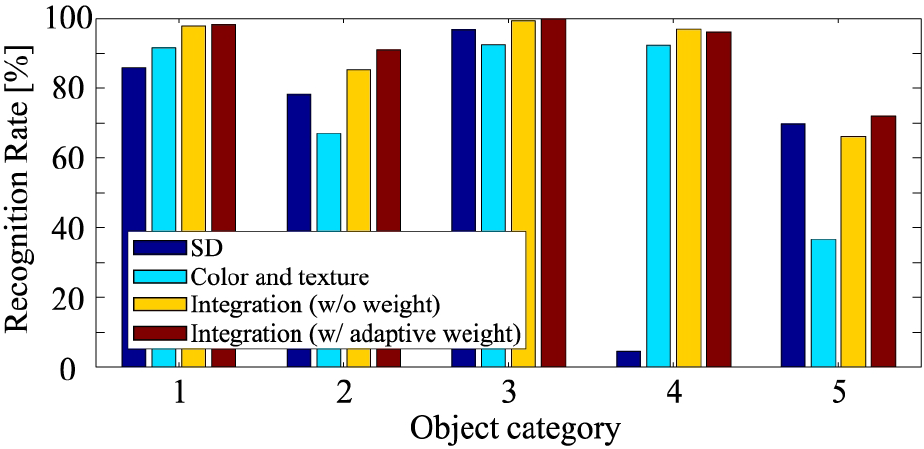
Examples of material recognition in a real scenario are shown in Fig. 16. We can see that paper packs, cans and plastic cups were detected from the scenes, and the materials of which these objects were made were recognized correctly. In addition, the confidence of the recognition results for each class is shown.
Examples of material recognition in real scenarios: (a) input colour image (1024 × 768), (b) NIR image (176 × 144), (c) segmented image (176 × 144), (d) probability map of cans (176 × 144), (e) probability map of plastics (176 × 144), and (f) probability map of paper packs (176 × 144). In the segmented image, the white colour represents the table, and the black colour indicates the low accuracy of depth pixels.
5.3. Evaluation of Ungraspable Object Detection
In order to validate the proposed ungraspable object detection scheme, the experiment was conducted using 15 small objects including paper waste and powders (sugar, milk, coffee, etc.) shown in Fig. 17, which are put on four different tables. Here, the two types of scenes, clean and messy, were considered for each table, and small object detection was conducted for a total of 12 scenes and 116 objects. An example of scenes is shown in Fig. 18. The PASCAL Visual Object Challenge (VOC) evaluation metric [28] was used to calculate detection rate. A candidate detection was considered correct if the size of the intersection of the predicted bounding box and the ground truth bounding box was more than half the size of their union. Only one of multiple successful detections for the same ground truth was considered correct, the rest were deemed as false positives. The result of small object detection was 79.3%. Because the NIR reflection intensity is included in the object detection system, the effect of changes in illumination can be reduced. However, the NIR reflection intensities of a few objects, such as coffee, were close to those of the table. In this case, if the colour of the table were different (e.g., white table), such objects could be detected using colour information. Overall, this result is good considering the main purpose of ungraspable object detection is to detect the approximate location for the vacuum cleaner.

Ungraspable objects.

Recognition results on four tables. For each table, three images are presented: a colour image of resolution 1024 × 768 (top), depth image of resolution 176 × 144 (middle), and NIR image of resolution 176 × 144 (bottom). Detected frames: ungraspable objects (red); identified objects: by object recognition (blue), by material recognition (green).
5.4. Evaluation of Cleaning Tasks
The proposed cleaning task was then implemented on a real robot platform. Visual recognition, which was conducted on the tabletops, is shown in Fig. 18. Recognition results of graspable objects that were to be disposed (rubbish, indicated by green frames), put on another table for tidying the target table (goods, indicated by blue frames), and the objects required to be cleaned away using the vacuum cleaner (ungraspable rubbish, indicated by red frames), are shown.
A quantitative evaluation of the cleaning task is difficult to do because the definition of “similar” as the initial state is difficult to measure. However, the proposed method can be evaluated on qualitative criteria such as “How close are the results to the initial state?”.
An action plan is generated based on the visual recognition results for performing the cleaning task. Figure 19 shows how the robot actually performed the cleaning task based on the flowchart shown in Fig. 7 (see section 4). It can be seen from Fig. 19 that the robot, which memorized the initial tabletop state, navigates to the table and recognizes it. Thereafter, the robot searched for graspable rubbish and disposed of the same into the dustbin. After all graspable rubbish was eliminated, the robot grasped the goods and put them on another table except the last goods item. The last goods item was grasped in the left hand, and ungraspable rubbish was cleaned by the vacuum cleaner in the robot's right hand. After vacuuming the ungraspable rubbish, the robot navigated to the other table where it had placed the goods to bring them back to their original locations.

Example of cleaning task. The task is performed according to the planning shown in Fig. 7. The main parts of the robot's action are navigation, recognition and object manipulation, including vacuuming ungraspable rubbish.
To evaluate the proposed method, the cleaning task was conducted over 10 trials; seven trials succeeded, while three failed. In the failed trials, the robot either missed when throwing rubbish into the dustbin or placing the goods on another table. In these cases, the target table was cleaned, but, as the whole, the task was not performed as desired. Among the successful trials, five trials were considered qualitatively clean, while in the other two trials, ungraspable rubbish was left on the table. Examples of several conditions after the completion of cleaning are shown in Fig. 20. Overall, the robot's navigation errors during the task were responsible for the lack of accuracy in placing the goods in their initial positions and failure to position the vacuum cleaner at the desired location for cleaning the ungraspable rubbish.

Examples of conditions when the cleaning task is completed. The top left of the figure shows the initial (tidy) condition, while the right panel shows the untidy condition. The bottom figures illustrate a few examples of executed cleaning tasks, with results changing worse to better.
6. Conclusion
In this paper, we proposed a visual recognition system based on multiple cues acquired using a 3D visual sensor. The proposed system consists of 3D object recognition that adaptively incorporates multiple features and NIR-reflection-intensity-based material recognition. Moreover, ungraspable object detection using the GMM model was proposed. We showed that the visual recognition system yields good results for each performance aspect, i.e., object identification under various illumination conditions, material recognition of unknown objects, and ungraspable object detection. Furthermore, the visual recognition system was implemented on a humanoid robot and examined through a cleaning task. The results showed that a relatively clean state could be achieved over several trials.
The current visual recognition system can be considered as an independent recognition system that consists of object and material recognition. Integration and improvement of independent recognition systems through hierarchical object recognition will be studied in the future. Other future areas of research include the application of a visual recognition system to other domestic tasks such as mobile manipulation in uncertain environments and quantitative evaluation of said applications. Moreover, reducing navigation error and object manipulation errors are important topics for our future work. Furniture recognition using 3D models is also considered as a future research area since the 3D model can be used to localize and clean up the tabletop without the learning phase.
Footnotes
7. Acknowledgement
This work was supported by JSPS KAKENHI grant number 24009813.