
Abstract
An adaptive Monte Carlo localization algorithm based on coevolution mechanism of ecological species is proposed. Samples are clustered into species, each of which represents a hypothesis of the robot's pose. Since the coevolution between the species ensures that the multiple distinct hypotheses can be tracked stably, the problem of premature convergence when using MCL in highly symmetric environments can be solved. And the sample size can be adjusted adaptively over time according to the uncertainty of the robot's pose by using the population growth model. In addition, by using the crossover and mutation operators in evolutionary computation, intra-species evolution can drive the samples move towards the regions where the desired posterior density is large. So a small size of samples can represent the desired density well enough to make precise localization. The new algorithm is termed coevolution based adaptive Monte Carlo localization (CEAMCL). Experiments have been carried out to prove the efficiency of the new localization algorithm.
1. Introduction
Self-localization, a basic problem in mobile robot systems, can be divided into two sub-problems: pose tracking and global localization. In pose tracking, the initial robot pose is known, and localization seeks to identify small, incremental errors in a robot's odometry (Leonard, J.J. & Durrant-Whyte, H.F., 1991). In global localization, however the robot is required to estimate its pose by local and incomplete observed information under the condition of uncertain initial pose. Global localization is a more challenging problem. Only most recently, several approaches based on probabilistic theory are proposed for global localization, including grid-based approaches (Burgard, W. et al, 1996), topological approaches (Kaelbling, L. P. et al, 1996) (Simmons, R. & Koenig, S., 1995), Monte Carlo localization (Dellaert, F. et al, 1999) and multi-hypothesis tracking (Jensfelt, P. & Kristensen, S., 2001) (Roumeliotis, S.I. & Bekey, G.A., 2000). By representing probability densities with sets of samples and using the sequential Monte Carlo importance sampling (Andrieu, C. & Doucet, A., 2002), Monte Carlo localization (MCL) can represent non-linear and non-Gaussian models well and focus the computational resources on regions with high likelihood. So MCL has attracted wide attention and has been applied in many real robot systems. But traditional MCL has some shortcomings. Since samples are actually drawn from a proposal density, if the observation density moves into one of the tails of the proposal density, most of the samples' non-normalized importance factors will be small. In this case, a large sample size is needed to represent the true posterior density to ensure stable and precise localization. Another problem is that samples often too quickly converge to a single, high likelihood pose. This might be undesirable in the case of localization in symmetric environments, where multiple distinct hypotheses have to be tracked for extended periods of time. How to get higher localization precision, to improve efficiency and to prevent premature convergence of MCL are the key concerns of the researchers. To make the samples represent the posterior density better, Thrun et al. proposed mixture-MCL (Thrun, S. et al, 2001), but it needs much additional computation in the sampling process. To improve the efficiency of MCL, methods adjusting sample size adaptively over time are proposed (Fox, D., 2003) (Koller, D. & Fratkina, R., 1998), but they increase the probability of premature convergence. Although clustered particle filters are applied to solve premature convergence (Milstein, A. et al, 2002), the method loses the advantage of focusing the computational resources on regions with high likelihood because it maintains the same sample size for all clusters.
In this paper, a new version of MCL is proposed to overcome those limitations. Samples are clustered into groups which are also called species. A coevolutionary model derived from competition of ecological species is introduced to make the species evolve cooperatively, so the premature convergence in highly symmetric environment can be prevented. The population growth model of species enables the sample size to be adjusted according to the total environment resources which represent uncertainty of the pose of the robot. And genetic operators are used for intra-species evolution to search for optimal samples in each species. So the samples can represent the desired posterior density better, and precise localization can be realized with a small size of sample. Compared with the traditional MCL, the new algorithm has the following advantages: (1) it can adaptively adjust the sample size during localization; (2) it can make stable localization in highly symmetric environment; (3) it can make precise localization with a small sample size.
2. Background
2.1. Robot Localization Problem
Robot localization is to estimate the current state xt of the robot, given the information about initial state and all the measurements Yt up to current time:

Typically, the state xt is a three-dimensional vector including the position and direction of the robot, i.e. the pose of the robot. From a statistical point of view, the estimation of xt is an instance of Bayes filtering problem, which can be implemented by constructing the posterior density p(xt | Yt). Assuming the environment is a Markov process, Bayes filters enable p(xt | Yt) to be computed recursively in two steps.
Prediction step: Predicting the state of the next time-step with previous state xt–1 according to the motion model p(xt | xt–1, ut–1):

Update step: Updating the state with the newly observed information yt according to the perceptual model p(yt | xt):

2.2. Monte Carlo localization (MCL)
If the state space is continuous, as is the case in mobile robot localization, implementing equations (2) and (3) is not trivial. The key idea of MCL is to represent the posterior density p(xt | Yt) by a set of weighted samples St:
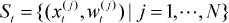
Where xt(j) is a possible state of the robot at current time t. The non-negative numerical factor wt(j) called importance factor represents the probability that the state of robot is xt(j) at time t. MCL includes the following three steps:
Resampling: Resample N samples randomly from St–1, according to the distribution defined by wt–1;
Importance sampling: sample state xt(j) from p(xt | x(j)t–1, ut–1) for each of the N possible state x(j)t–1; and evaluate the importance factor wt(j) = p(yt | xt(j)).
Summary: normalize the importance factors
2.3. Coevolutionary algorithms
Evolutionary algorithms (EAs), especially genetic algorithms, have been successfully used in different mobile robot applications, such as path planning (Chen, M. & Zalzala, A., 1995) (Potvin, J. et al, 1996), map building (Duckett, T., 2003) and even pose tracking for robot localization (Moreno, L. et al, 2002). But premature convergence is one of the main limitations when using evolutionary computation algorithms in more complex applications as in the case of global localization.
Coevolutionary algorithms (CEAs) are extensions of EAs. Based on the interaction between species, coevolution mechanism in CEAs can preserve diversity within the population of evolutionary algorithms to prevent premature convergence. According to the characters of interaction between species, CEAs can be divided into cooperative coevolutionary algorithms and competitive coevolutionary algorithms. Cooperative (also called symbiotic) coevolutionary algorithms involve a number of independently evolving species which together form complex structures. The fitness of an individual depends on its ability to collaborate with individuals from other species. Individuals are rewarded when they work well with other individuals and punished when they perform poorly together (Moriarty, D.E. & Miikkulainen, R., 1997) (Potter, M.A. & De Jong, K.A., 2000). In competitive coevolutionary algorithms, however the increased fitness of one of the species implies a diminution in the fitness of the other species. This evolutionary pressure tends to produce new strategies in the populations involved so as to maintain their chances of survival. This “arms race” ideally increases the capabilities of the species until they reach an optimum. Several methods have been developed to encourage the arms race (Angeline, P.J. & Pollack, J.B., 1993) (Ficici, S.G. & Pollack, J.B., 2001) (Rosin, C. & Belew, R., 1997), but these coevolution methods only consider interaction between species and neglect the effects of the change of the environment on the species.
Actually the concept of coevolution is also derived from ecologic science. In ecology, much of the early theoretical work on the interaction between species started with the Lotka-Volterra model of competition (Yuchang, S. & Xiaoming, C, 1996). The model itself was a modification of the logistic model of the growth of a single population and represented the result of competition between species by the change of the population size of each species. Although the model could not embody all the complex relations between species, it is simple and easy to use. So it has been accepted by most of the ecologists.
3. Coevolution Based Adaptive Monte Carlo Localization
To overcome the limitations of MCL, samples are clustered into different species. Samples in each species have similar characteristics, and each of the species represents a hypothesis of the place where the robot is located. The Lotka-Volterra model is used to model the competition between species. The competition for limited resources will lead to the extinction of some species, and at the same time make some species become more complex so as to coexist with each other. The environment resources which represent uncertainty of the pose of the robot will change over time, so the total sample size will also change over time. Compared with other coevolution models, our model involves the effects of competition between species as well as that of the change of environment on species.
3.1. Initial Species Generation
In the traditional MCL, the initial samples are randomly drawn from a uniform distribution for global localization. If a small sample size is used, few of the initial samples will fall in the regions where the desired posterior density is large, so MCL will fail to localize the robot correctly. In this paper, we propose an efficient initial sample selection method, and at the same time the method will cluster the samples into species.
In order to select the samples that can represent the initial location of the robot well, a large test sample set

Where η is a predefined parameter, w̄0 is the average weight of grids in set V, and |V| is the number of grids in set V. This equation means that if the robot locates in a small area with high likelihood, a small initial sample size is needed.
Using the network defined through neighborhood relations between the grids, the set V is divided into connected regions (i.e. sets of connected grids). Assuming there are ? connected regions, these connected regions are used as seeds for the clustering procedure. A city-block distance is used in the network of grids. As in image processing field, the use of distance and seeds permits to define influence zones, and the boundary between influence zones is known as SKIZ (skeleton by influence zone) (Serra, J., 1982). So the robot's state space is partitioned into ? parts. And N0(i) samples which have the largest importance factor will be selected from the test samples falling in the ith part.

Where w̄0 (k) is the average weight of grids in the kth part of the state space. The selected N0(i) samples from the ith part form an initial species of N0(i) population size.
3.2. Inter-Species Competition
Inspired by ecology, when competing with other species the population growth of a species can be modeled using the Lotka-Volterra competition model. Assuming there are two species, the Lotka-Volterra competition model includes two equations of population growth, one for each of two competing species.

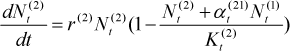
Where r(i) is the maximum possible rate of population growth, Nt(i) is the population size and Kt(i) is the upper limit of population size of species i that the environment resource can support at time step t respectively, and α t (ij) refers to the impact of an individual of species j on population growth of species i; here i, j ∈{1,2}. Actually, The Lotka-Volterra model of inter-specific competition also includes the effects of intra-specific competition on population of the species. When αt(ij) or Nt(i) equals 0, the population of the species j will grow according to the logistic growth model which models the intra competition between individuals in a species.
These equations can be used to predict the outcome of competition over time. To do this, we should determine equilibria, i.e. the condition that population growth of both species will be zero. Let dNt(1) / dt = 0 and dNt(2) / dt = 0. If r(1) Nt(1) and r(2)Nt(2) do not equal 0, we get two line equations which are called the isoclines of the species. They can be plotted in four cases, as are shown in Fig.1. According to the figure, there are four kinds of competition results determined by the relationship between Kt(1), Kt(2), α t (12) and α t (21).
When Kt(2) / α t (21) < Kt(1), Kt(1) / α t (12) > Kt(2) for all the time steps, species 1 will always win and the balance point is Nt(1) = Kt(1), Nt(2) = 0.
When Kt(2) / α t (21) > Kt(1), Kt(1) / α t (12) < Kt(2) for all the time steps, species 2 will always win and the balance point is Nt(1) = 0, Nt(2) = Kt(2).
When Kt(2) / α t (21) < Kt(1), Kt(1) / α t (12) < Kt(2) for all the time steps, they can win each other; the initial population of them determines who will win.
When Kt(2) / α t (21) > Kt(1), Kt(1) / α t (12) > Kt(2) for all the time steps, there is only one balance point and they can coexist with their own population size.
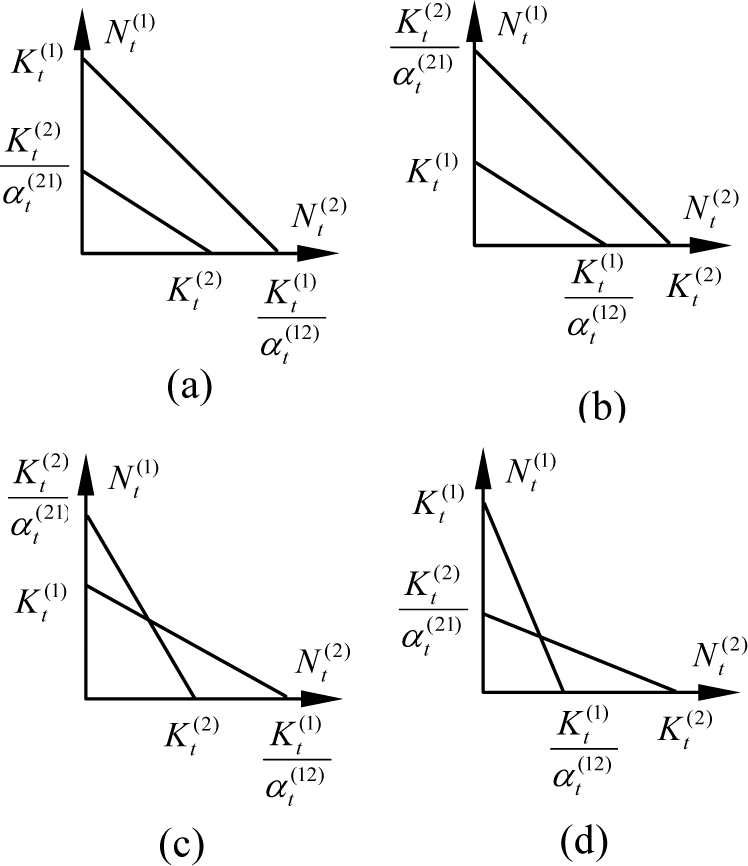
The isoclines of two coevolution species
For an environment that includes ? species, the competition equation can be modified as:

3.3. Environment Resources
Each species will occupy a part of the state space, which is called living domain of that species. Let matrix Qt(i) represent the covariance matrix calculated using the individuals in a species i. Qt(i) is a symmetric matrix of n × n, here n is the dimension of the state. Matrix Qt(i) can be decomposed using singular value decomposition:



Where dj is the variance of species i in direction ej, ej ∈ Rn is a unit vector, and

We define the living domain of the species i at time t to be an ellipsoid with radius of 2√dj in direction ej, and it is centered at x̄t(i) which is the weighted average of the individuals in species i. The size of the living domain is decided by:

Where Cn is a constant, depending on n, for example C2 = π, C3 = 4π/3. Actually the living domain of a species reflects the uncertainty of the robot's pose estimated according to that species, and it is similar to the uncertainty ellipsoid (Herbert, M. et al, 1997).
Environment resources are proportional to the size of the living domain. The environment resources occupied by a species are defined as:

Where δ is the number of resources in a unit living domain, and ε is the minimum living domain a species should maintain. Assuming a species can plunder the resources of other species through competition, i.e. the environment resources are shared by all species. And the number of individuals that a unit of resource can support is different for species with different fitness. The upper limit of population size that the environment resources can support of a species is determined by:

Where parameter
3.4. Intra-Species Evolution
Since genetic algorithm and sequential Monte Carlo importance sampling have many common aspects, Higuchi, T. (1997) has merged them together. In CEAMCL the genetic operators, crossover and mutation, are applied to search for optimal samples in each species independently. The intra-species evolution will interact with inter-species competition: the evolution of individuals in a species will increase its ability for inter-species competition, so as to survive for a longer time.
Because the observation density p(yt | xt) includes the most recent observed information of the robot, it is defined as the fitness function. The two operators: crossover and mutation, work directly over the floating-points to avoid the trouble brought by binary coding and decoding. The crossover and mutation operator are defined as following:
Crossover: for two parent samples (xt(p1), wt(p1)), (xt(p2), wt(p2)), the crossover operator mates them by formula (17) to generate two children samples.

Where ξ ~ U[0,1], and U[0,1] represents uniform distribution. And two samples with the largest importance factors are selected from the four samples for the next generation.
Mutation: for a parent sample (xt(p), wt(p)), the mutation operator on it is defined by formula (18).

Where τ ~ N(0, Σ) is a three-dimensional vector and N(0, Σ) represents normal distribution. The sample with larger importance factor is selected from the two samples for next generation. In CEAMCL, the crossover operator will perform with probability pc and mutation operator will perform with probability pm. Because the genetic operator can search for optimal samples, the sampling process is more efficient and the number of samples required to represent the posterior density can be reduced considerably.
3.5. CEAMCL Algorithm
The coevolution model is merged into the MCL, and the new algorithm is termed coevolution based adaptive Monte Carlo localization (CEAMCL). During localization, if two species cover each other and there is no valley of importance factor between them, they will be merged; and a species will be split if grids occupied by the samples can be split into more than one connected regions as in initial species generation. This is called splitting-merging process. The CEAMCL algorithm is described as following:
Initialization: select initial samples and cluster the samples into Ω species; for each species i, let dN0(i)/dt = 0; and let t = 1.
Sample size determination: if dN(i)t–1 / dt > 0, draw dN(i)t–1/dt samples randomly from the living domain of the ith species and merge the newly drawn samples to S(i)t–1; let Nt(i) = max(N(i)t–1 + dN(i)t–1/dt,0)
Resampling: for each species i, resample Nt(i) samples from S(i)t–1 according to w(i)t–1;
Importance Sampling: for each species i, sample state xt(ij) from p(xt | x(ij)t–1, ut–1) for each of the Nt(i) possible state x(ij)t–1; and evaluate the importance factor wt(ij) = p(yt | xt(ij)).
Intra-species evolution: for each species i randomly draw two samples, and mate them with probability pc, repeat this for Nt(i) /2 times; then randomly draw one sample from species i, and mutate it with probability pm, repeat this for Nt(i) times.
Splitting-merging process: split and merge the species using the rules defined in the splitting-merging process.
Calculating the sample size increment: for each species i calculate the upper limit population size of species i, and calculate dNt(i) / dt using equation (9).
Summary: The species whose average importance factor is the largest is assumed to be the location of the robot, and the importance factors of each species are normalized independently.
t=t+1; go to step 2) if not stop.
3.6. Computational Cost
Compared with MCL, CEAMCL requires more computation for each sample. But the sampling process is more efficient in CEAMCL. So it can considerably reduce the number of samples required to represent the posterior density.
The resampling, importance factor normalization and calculating statistic properties have almost the same computational cost per sample for the two algorithms. We denote the total cost of each sample in these calculations as Tr. The importance sampling step involves drawing a n dimensional-vector according to the motion model p(xt | x(j)t–1, ut–1) and computing the importance factor whose computational costs are denoted as Ts and Tf respectively. The additional computational cost for CEAMCL arises from the intra-species evolution step and the splitting-merging process. The evolution step computes the importance factor with probability pc in crossover and with probability pm in mutation. The other computation in evolution step includes drawing a n dimensional-vector from a Gaussian distribution, drawing a random number from uniform distribution of U[0,1] and several times of simple addition, multiplication and comparison. Since the other computational cost in evolution step is almost the same as Ts which also includes drawing a n dimensional-vector from a Gaussian distribution, the total computational cost for each sample in evolution step is approximated by (pc+ pm)Tf + Ts. The splitting or merging probability of species in each time step is small, especially when the species become stable no species need to be split or merged, so the computational cost of the splitting-merging process denoted as Tm is small. And the computational costs of other steps in CEAMCL are not related to the sample size, so they can be neglected. Defining NM and NC as the number of samples in MCL and CEAMCL respectively, the total computational costs for one of the iteration in localization TM and TC are given by:


Where p = pc + pm. The most computationally intensive procedure in localization is the computation of the importance factor which has to deal with the high dimensional sensor data, so Tf is much larger than the other terms. It is safe to draw the following rule:

4. Experimental Results
We have evaluated CEAMCL in the context of indoor mobile robot localization using data collected with a Pioneer II robot. The data consist of a sequence of laser range-finder scans along with odometry measurements annotated with time-stamps to allow systematic real-time evaluations. The experimental field is a large hall in our laboratory building whose size is of 15 × 15 m2, and the hall is partitioned into small rooms using boards to form a highly symmetric map shown in Fig 2.
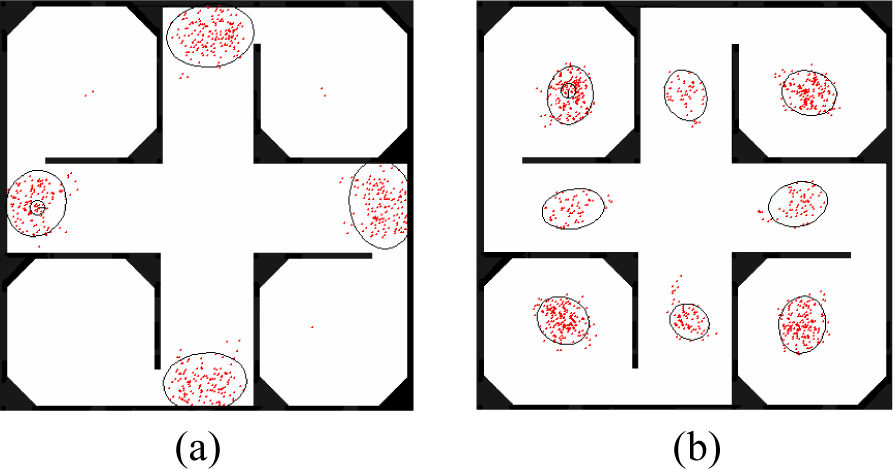
The initial species for localization. (a) 4 species with 537 samples (b) 8 species with 961 samples
In the initial species generation, we only use the x-y position and don't use direction to cluster the samples. The map is divided into 150 × 150 grids. The test sample size Ntest equals 1000000; the threshold parameter μ equals 0.85; and parameter η is 2. The initial species generation results are shown in Fig 2. It is obvious that even in the same environment the initial sample sizes are different when the robot is placed in different places. The real position of robot is marked using a small circle.
In the localization experiments, the robot was placed at the center of one of the four rooms, and it was commanded to go to a corner of another room. 5 times of experiments were conducted for each center. The three algorithms MCL, GMCL and CEAMCL were applied to localize the robot using the data collected in the experiments. Here GMCL is genetic Monte Carlo localization which merges genetic operators into MCL but without coevolution mechanism. The parameter
The success rate of the three algorithms to track the hypothesis corresponding to the robot's real pose until the robot reaches the goal is shown in table 1. In table 1, the converged time is the time when the samples converged to the four most likely positions; the expired time is the time when one of the hypotheses vanished. The data shows that the CEMCL can converge to the most likely positions as fast as GMCL, but it can maintain the hypotheses for a much longer time than the other two algorithms. This is because the species with much lower fitness will die out because of the competition between species, and the species with similar fitness can coexist with each other for a longer time. Figure 3 shows two inter moments when the robot ran from the center of room 1 to the goal using the CEAMCL algorithm.
Success rate of multi-hypotheses tracking



Localization based on CEAMCL. (a) samples at 7th second (b) samples at 16th second
To compare the localization precision of the three algorithms, we use the robot position tracked by using MCL with 5000 samples in the condition of knowing the initial position to be the reference robot position. The average estimation errors along the running time are shown in Fig 4. Since the summary in CEAMCL is based on the most likely species and the genetic operator in intra-species evolution can drive the samples to the regions with large importance factors, so localization error of CEAMCL is much lower. Although GMCL almost has the same precision as CEAMCL after some time, GMCL is much more likely to produce premature convergence in symmetric environment.
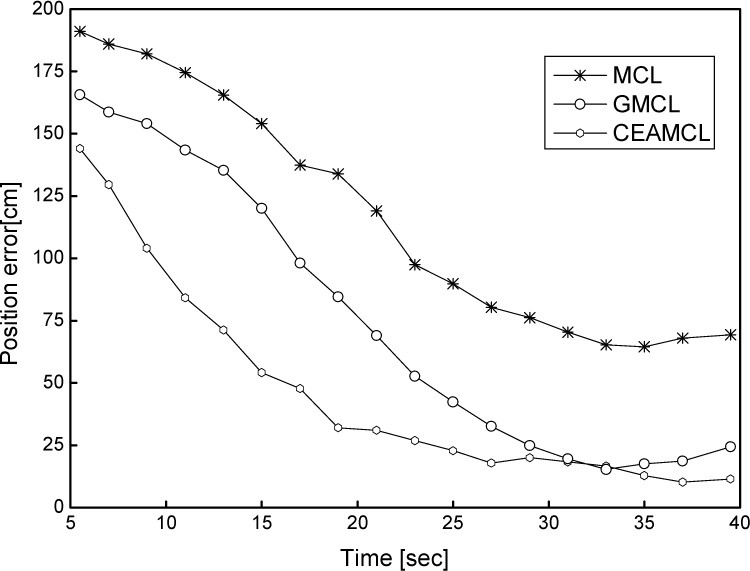
Estimation Error
The computational time needed for each iteration with 961 initial samples on a computer with a CPU of PENIUM□ 800 is shown in Fig 5. Because pc + pm = 1, the computational time needed for each iteration of CEAMCL is almost twice of that of MCL with the same size of sample set. But since the sample size of CEAMCL is adaptively adjusted during the localization process, the computational time for each iteration of CEAMCL becomes less than that of MCL after some time. From Fig 4. and Fig 5. we can see that the CEAMCL can make precise localization with a small sample size. The changes of the total environment resources and the total number of samples are shown in Fig 6. From the figure we can see that the resources will be reduced when the position becomes certain, the total sample size needed for robot localization will also be reduced.

Computational time for each iteration

Change of resource and sample size
The parameter δ which represents the number of resources in a unit living domain is important in CEAMCL, because it will affect the competition between species. Large δ will reduce the competition between the species since there is enough resource for them. The curve of total sample size with different δ is shown in Fig 7. The growth rate r(i) is another important parameter. Large r(i) will increase the rate of convergence to the species that have larger fitness. But if r(i) is too large it may cause premature convergence.
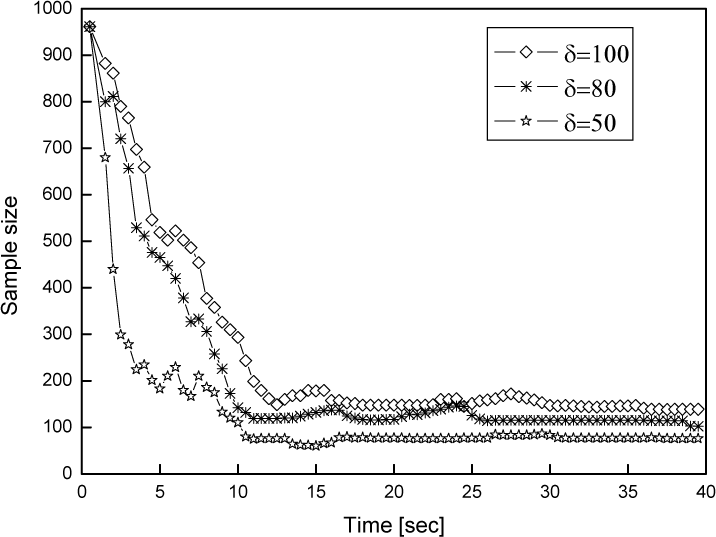
Effect of δ on sample size
5. Conclusion
An adaptive localization algorithm CEAMCL is proposed in this paper. Using an ecological competition model, CEAMCL can adaptively adjust the sample size according to the total environment resource, which represents uncertainty of the position of the robot. Coevolution between species ensures that the problem of premature convergence when using MCL in highly symmetric environments can be solved. And genetic operators used for intra-species evolution can search for optimal samples in each species, so the samples can represent the desired posterior density better. Experiments prove that CEAMCL has the following advantages: (1) it can adaptively adjust the sample size during localization; (2) it can make stable localization in highly symmetric environment; (3) it can make precise localization with a small sample size.
Footnotes
Acknowledgements
This work was found in part by the National Natural Science Foundation of China (No.69985002).