
Abstract
Online path planning (OPP) for unmanned aerial vehicles (UAVs) is a basic issue of intelligent flight and is indeed a dynamic multi-objective optimization problem (DMOP). In this paper, an OPP framework is proposed in the sense of model predictive control (MPC) to continuously update the environmental information for the planner. For solving the DMOP involved in the MPC we propose a dynamic multi-objective evolutionary algorithm based on linkage and prediction (LP-DMOEA). Within this algorithm, the historical Pareto sets are collected and analysed to enhance the performance. For intelligently selecting the best path from the output of the OPP, the Bayesian network and fuzzy logic are used to quantify the bias to each optimization objective. The DMOEA is validated on three benchmark problems characterized by different changing types in decision and objective spaces. Moreover, the simulation results show that the LP-DMOEA overcomes the restart method for OPP. The decision-making method for solution selection can assess the situation in an adversarial environment and accordingly adapt the path planner.
Keywords
1. Introduction
The application of unmanned aerial vehicles (UAVs) for various military missions has received growing attention in the last decade. Apart from the obvious advantage of not placing human life at risk, the lack of a human pilot enables significant weight savings and lower costs. UAVs also provide an opportunity for new operational paradigms. To realize these advantages, UAVs must have a high level of autonomy and preferably work cooperatively in groups. In addition to some key elements involved in traditional aerial vehicles, such as control algorithms, localization and navigation, more emphasis has been put on the autonomic and intelligent abilities in uncertain or even adversarial environments.
Intelligent flight is the basic issue for UAVs to carry out any complicated mission. When the environment is static and known beforehand the flight path can be well designed offline [1, 2]. However, when the environment is changeable or there is no exact knowledge in advance about the environment, a UAV needs to intelligently plan its path online.
To this end, in this paper, we intend to solve the intelligent online path planning (OPP) problem for UAVs.
In general, path planning involves multiple optimal objectives. For instance, maximal safety and minimal energy cost are the two most common objectives. In some literature multi-objective optimal problems (MOPs) are transformed to single-objective ones by weighting each objective and summing them up [3, 4]. This requires knowing the bias to objectives of the optimizer in advance. Unfortunately, sometimes it is difficult to achieve. Therefore, from the nature of the dynamic MOPs (DMOPs), we optimize all the objectives simultaneously. Moreover, considering the fact that no exact information about the environment is known beforehand and the environment may change during the mission, the objectives involved in path planning are time variant. Accordingly, we need a dynamic multi-objective optimal method to deal with the problem at hand.
Evolutionary algorithms (EAs) are now an established research field at the intersection of artificial intelligence, computer science and operations research. Its problem-independent and global optimal characteristics establish its position in the optimization domain. However, most research in EAs has focused on static optimization problems. The main problem of using traditional EAs for DOPs lies in that they eventually converge to an optimum and thereby lose their population diversity which is necessary for efficiently exploring the search space, which consequently deprives them of the ability to adapt to the changes in the environment. To enhance EAs to solve DOPs, over the past two decades, a number of researchers have developed many methods to maintain diversity for traditional EAs to continuously adapt to the changing environment. Most of these methods can be categorized into the following four types of approaches: (1) increasing the diversity after a change, such as the hyper-mutation method [5]; (2) maintaining the diversity throughout the run, such as the random immigrants scheme [6], sharing or crowding mechanisms [7], and the thermodynamical genetic algorithm [8]; (3) memory-based approaches [9-11]; and (4) multi-population approaches [12-15]. Comprehensive surveys on EAs applied to dynamic environments can be found in [16-20].
Recently, in several works [21-24], the convergence is accelerated by predicting the characteristics of future changes when the behaviour of the problem follows a certain trend. Inspired by these ideas, partly based on our previous work in [25], we propose a multi-objective EA (MOEA), called a dynamic MOEA with Pareto set linking and prediction, and denoted LP-DMOEA, which stores and analyses the historic information to enhance its performance on DMOPs, to solve the OPP problem. Within LP-DMOEA, the historic Pareto solutions are first linked to construct several time series, and then a prediction method is employed to anticipate the Pareto set of the next problem. Benefiting from such anticipation, the initial population for the new problem can be heuristically generated to accelerate the convergence in the new environment. It is noteworthy that the obtainment of Pareto optimal solutions is not the end of solving an MOP. One solution should be selected from the Pareto set by the decision-maker (DM). As for UAVs, there are no actual DMs to deal with such a decision mission. They should intelligently make such a decision without interacting with human beings. To this end, we employ a Bayesian network (BN) to model the inference process of a pilot when he is assessing the danger level of an environment. In addition, fuzzy logic is used to quantify the decision bias reference to infer results.
The remaining part of this paper is organized as follows. Section 2 presents the formulation of the OPP and the details of LP-DMOEA; Section 3 presents the intelligent decision-making methods to choose a Pareto solution. Section 4 presents the experimental results and analysis. Conclusions are drawn in Section 5.
2. Online Path Planning in Terms of Dynamic Multi-Objective Optimization
From the practice point of view, offline global path planning is likely to be invalid when the environment is uncertain and time-variant. A UAV has to independently plan its online path referring to the local information detected by its onboard sensors. Pongpunwattana has proposed an OPP scheme in the sense of model predictive control (MPC) in [26]. As shown in Fig. 1, suppose the UAV has planned a path starting from point A at

Illustration of online path planning
2.1. Formulation for the OPP Problem
In a 2-D case, we formulate the OPP problem as follows:

where
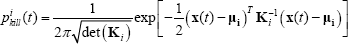
where
2.2. Problem Solving Approach: The LP-DMOEA
To deal with the DMOP at hand, we propose the LP-DMOEA. The main idea of LP-DMOEA lies in heuristically generating the initial population for a new problem by making predictions from the historical information. Historical Pareto solutions are linked to construct several time series and then a prediction method is employed to anticipate the Pareto set of the next problem. Lastly, the initial population for the new problem can be heuristically generated to accelerate the convergence speed for the new problem.
As shown in Fig. 2, suppose the environment changes (new problem arrives) at t, the Pareto set

Flow chart of the LP-DMOEA
2.2.1. Selecting Pareto Solutions for Linking
As for selecting Pareto solutions for linking, there are two major ideas in the literature. The first one accomplishes this by considering the feature of each candidate in the objective space. In the work of Hatzakis and Wallace [21], the anchor points and closest-to-ideal point of a Pareto front in the objective space are chosen as the key feature points, and the corresponding solutions in the decision space are used to make the anticipation. This approach uses two or three key points to characterize the Pareto front. However, this approach will be invalid when the front is concave or very complex. As for the other idea, the candidates are selected directly in the decision space under a special principle. In the work of Zhou et al. [23], all the Pareto solutions obtained prior to an environmental change are used to anticipate. This approach is more direct because the factors involved in the time series construction are only in the context of the decision space. However, each Pareto solution will be linked to a time series, which may lead to a large number of time series and the computational complexity could be enormous.
In this paper, we follow the second idea. The difference to [23] lies in that we use a hyper-box-based selection (HBS) to construct time series from the Pareto sets. As shown in Fig. 3, suppose there are two decision values and the range of each value is divided into many sections by a preset parameter

Diagram of the HBS
2.2.2. Construction of Time Series
As for constructing time series, the key issue is how to identify the relationship between the solutions selected by HBS. In this paper, we use the minimal distance principle to identify the relationship between two solutions. Each Pareto solution
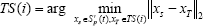
Considering the limitation of memory and computation resource, we use a preset parameter K to control the maximal order number of a time series. This means there are at most K elements in a time series. If the length of a time series is shorter than K, then
2.2.3. Prediction and Generation of the Initial Population
Many methods could be used to analyse the time series constructed above. In this paper, the following simple linear model is adopted:
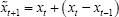
Considering the forecasting error caused by the inaccuracy of the forecasting model and the searching algorithm, the prediction results should not be directly used to initialize the new population, the diversity should be maintain to some degree. Here we maintain diversity in two aspects:
1) Only partial initial population is generated based on the prediction results: A preset parameter α is used to control the rate of the individuals which will be initialized referring to the prediction and the rest of the individuals will be randomly generated.
2) Variation with a noise: Similar to [23], we bring in a Gaussian noise λ to improve the chance of the initial population covering the true Pareto set. This noise is added to the predicted result of each decision value. The standard deviationδ of noise is estimated by looking at the changes that occurred before:

2.3. Chromosome Representation
The chromosome is the bridge between the optimization problem and the search space. For a path section, it is straightforward to code it as a series of consecutive line segments. However, this coding method is ambiguous for the control system since the control system cannot obtain an explicit input signal from such a chromosome. In this study, we use a series of consecutive yaw angle changing values to code a chromosome. In each time step (i.e.

Diagram of the chromosome representation
3. Decision-Making on the Selection of Executive Solution
Although a set of Pareto solutions can be dynamically obtained using the LP-DMOEA, the OPP problem is not solved until one feasible solution is selected out for executing. In this section, we focus on how to select a solution referring to the bias of the DM and how to intelligently make such a decision.
3.1. Methodology Used to Select Solutions from the Pareto Set
In this paper we use the Weighted Stress Function Method (WSFM) proposed by Ferreira [28] to integrate the DM preferences after the search process has been made. Therefore, this is a posterior method where the search and the decision process are sequential. The main principle of WSFM lies in that for each optimal objective, the relative importance attributed to each objective will induce a “stress” for searching for solutions that maximize such objective. Thus, the best solution will be the one where the differences between the stresses associated to each objective have the minimum possible value. For a problem with M optimal objectives the WSFM is converted to a single objective optimal problem:

where

where,



Since the equation above considers the maximization problem and each objective should be normalized, we rewrite the original objective function (1) as follows:
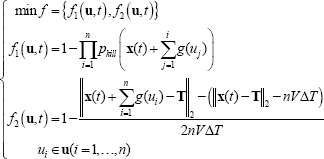
3.2. Intelligent Situation Assessment via Bayesian Network (BN)
Now the problem turns to how to set
3.2.1. Concept of the BN
The BN is a graphical representation of a joint probability distribution, representing dependence and conditional independence relationships. To our knowledge, it was first introduced by Kim and Pearl [29] and can be defined as follows.
The joint probability distribution can be written as:

3.2.2. A BN-Based Assessment Model of Environment
The construction process of a BN, including the structure and parameters, is indeed the integration of the DM's knowledge. The resulting BN will make an intelligent inference instead of the DM. In this work, the enemy air defence (i.e. threats for UAVs) consists of two types of anti-air weapons: the anti-air guns (AAGuns) and the surface-to-air missiles (SAMs). The threat type is written as TT for short. A threat may work in one of the following states: no targets are found and the system is inactive (IA); surveillance radar detects the targets (Surv); targets have been intercepted by radars (Intercept); targets are being traced by radars (Trace) and open fire (Fire). There are five environmental danger levels (EDLs): very dangerous (VD), dangerous (D), medium (M), safe (S), and very safe (VS). If the working states of the threats (TS) could be known, the EDL can be easily inferred.
However, the TS is difficult to know directly and a UAV has to infer such information referring to the local information collected by its onboard sensors. Suppose there are two major onboard sensors assembled on a UAV: the missile launching detector (MLD) and the radar warning receiver (RWR). For these sensors, there are two working states: active (A) and inactive (IA). When the RWR works in state A, the UAV has been detected or traced by enemy radars and the anti-air weapons will be launched imminently. The matter is worse when the MLD is working in state A which means the UAV is under attack.
In addition to the sensors' information, the distance between a threat and the UAV is also a key factor that impacts the EDL. Suppose there are five range (R) scales: R1 (0∼1 km), R2 (1∼2 km), R3 (2∼4 km), R4 (4∼6 km), and R5 (larger than 6 km). The BN structure is shown in Fig. 5 and the corresponding conditional probability tables (CPTs) are given in the Appendix.

The BN structure of the environmental assessment model
3.3. Quantification of Environmental Assessment Results
Since the BN is a qualitative inference tool, we need to quantify the inference results (i.e. the EDLs) to obtain the weight values associated to each optimization objective. In this work, we use fuzzy logic [30] to set the value of

Fuzzy rules between EDL and

Triangular-shaped membership function. Suppose the value range of
4. Experimental Results and Analysis
In this section the NSGA2 [31] is used as the basic MOEA. We apply LP-DMOEA and random restart methods to NSGA2, and the resulting dynamic MOEAs are written as LP-DNSGA2 and R-DNSGA2, respectively. We firstly validate the LP-DMOEA by comparing LP-DNSGA2 with R-DNSGA2 on benchmark problems. Then will compare two OPP algorithms: OPP-A and OPP-B which use LP-DNSGA2 and R-DNSGA2, respectively. Lastly, the intelligent OPP using LP-DNSGA2 and the intelligent decision-making methods will be validated.
4.1. Performance Comparison on Benchmark Problems
In the following experiments and analysis the general algorithmic settings are given as follows: population size is set to 100, probability of simulated binary crossover is set to 0.9 and polynomial mutation rate is
4.1.1. Benchmark Problems
Three benchmark problems are used here. FDA1 and FDA3 are proposed by Ferina and Deb [23], and ZJZ is proposed by Zhou, Jin and Zhang [16]. Their definitions are given as follows where τ is the generation counter,
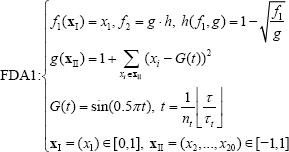


4.1.2. Performance Indicators
The general distance (GD) performance indicator has been widely used by many researchers to measure the convergence of a multi-objective evolutionary algorithm.
In this paper, the decision space GD (VD) is used and its definition is given below:

where
To fairly measure an algorithm, each algorithm is run

4.1.3. Experimental Results on Benchmark Problems
The Pareto set and Pareto front of the benchmark problem can be mathematically analysed and are given in Table 1; their characteristics are also shown.
The performance of LP-DNSGA2 and R-DNSGA2 in 50 independent runs is compared in Fig. 8. One can see LP-DNSGA2 overcomes R-DNSGA2 on all benchmark problems, its population converges better and the obtained Pareto fronts are closer to the reference Pareto fronts. This means our LP-DMOEA works effectively to solve dynamic multi-objective optimization problems.
The global Pareto solution sets of FDA1~FDA3 and their Pareto fronts


Comparison of the mean and stand deviation of

A set of simulation snapshots of online path planning for a UAV. There are two moving threats (e.g. enemy aircraft) with
4.2. Results and Analysis on the Intelligent OPP Algorithm
The algorithmic parameters involved in the following experiments are given as follows:
Parameters involved in LP-DNSGA2: rate of the heuristically generated individuals is set to 50% (i.e.
Parameters involved in OPP: time step
4.2.1. Validation of LP-DMOEA-Based OPP Algorithm
To test the validity of the LP-DMOEA-based OPP algorithm (i.e. OPP-A), we consider a moving threat case. In this case, two enemy moving threats patrol in the mission field. A UAV should dynamically plan its flying path to avoid being detected. Fig. 9 shows the simulation snapshots. It can be seen that the UAV can successfully keep its stealth. In other words, in the 215 simulations, the UAV successfully keeps its survival probability equal to 1.0.
4.2.2. Comparison of Two OPP Algorithms
We compare OPP-A with OPP-B to show the advantage of the proposed dynamic MOEA over the random restart method. In addition, we would like to test the validity of WSFM. Therefore, in the following experiments, the intelligent decision-making method will not be used. Two OPP algorithms will be tested in an unknown environment (no information about the four threats are known in advance) with fixed bias weight values (
There are four threats in the simulated battlefield whose parameters are given in Table 2. The simulation terminates when the distance between the goal and the UAV is within 1 km.
Parameters of the threats

As shown in Fig. 10, the paths obtained by OPP-A (solid line) are more reasonable and smoother than that of OPP-B (dotted line). This can be explained by Fig. 11 where the curves of the yaw angle are compared. It can be seen that the yaw angle curve calculated by OPP-B fluctuates more violently, which is harmful for the control mechanism of an actual UAV.
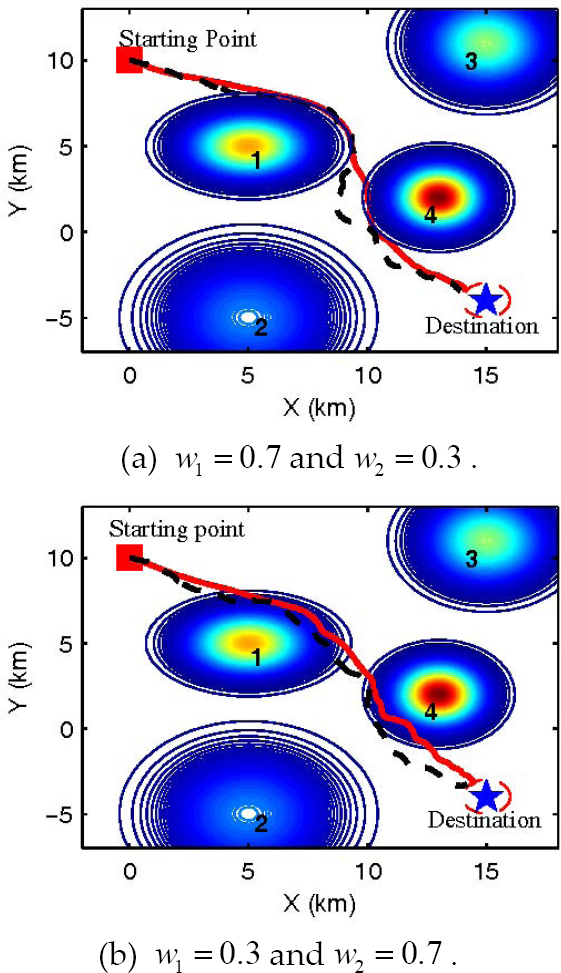
Comparison between OPP-A (solid line) and OPP-B (dashed line)

The curves of yaw angle of OPP-A and OPP-B
The results of the survival probability and flight time are given in Table 3. It is obvious that OPP-A outperforms OPP-B again. This is because LP-DNSGA2 employed by OPP-A can effectively improve the dynamic optimization performance in contrast to R-DNSGA2. In addition, the paths considering the DM bias of
Simulation results

4.2.3. Validation of Intelligent Behaviour Against A Pop-up Threat
In the following experiments, we will show the validity of the intelligent OPP which is the combination of OPP-A and the intelligent environment assessment. Here, we assume that Threat-4 does not appear or work until the UAV flies for 50 seconds. In such a case, the UAV should assess the environment and react to the pop-up threat intelligently.
As shown in Fig. 12, in the first 50 seconds, the UAV has successfully evaded the threats and would fly in a straight trajectory toward to its goal if the hostile environment did not change. Then, a pop-up threat (No. 4) suddenly appears at 50 s, and fortunately, the UAV can react to this change by flying away from the pop-up threat as quickly as possible. At that moment, the intelligent environmental assessment works effectively to increase the probability of

Path planned by intelligent OPP algorithm proposed in this paper

The probabilities of each EDL versus time

The value of
5. Conclusion
Usually the mission environment for a UAV is unknown and may change arbitrarily. The intelligent flight is a key technology for a UAV to react to the changing environment. The major contribution of this work is to solve the intelligent OPP problem, which is a basic issue for intelligent flight, by integrating dynamic MOEA, BN and fuzzy logic.
Considering the fact that a UAV has to collect information via its onboard sensors sometimes, a MPC-like OPP method is employed to continuously update the local environmental information for the planner and this method is in fact a DMOP. For solving this problem, we have proposed the LP-DMOEA and the main idea is to utilize the historical information to enhance the performance. The historical Pareto sets are collected to construct several time series and the search process for the new problem could be guided by the prediction of those time series. The WSFM has been introduced to select the best solution referring to the bias of DM. For making use of such a posterior method, the BN is used to model the environmental assessment accomplished by a pilot and fuzzy logic is employed to quantify the assessment results so as to obtain the weight value associated to each optimal objective. We have used the famous NSGA2 as the basic MOEA and the simulation is in a simple military case. The experimental results show that the LP-DMOEA works more effectively for the OPP in contrast to the restart method due to the positive impact on heuristically initializing the population for the new problem. In addition, the intelligent methods for solution selection can automatically assess the changing environment and adapt the path planner.