
Abstract
Coalescent-based Bayesian Markov chain Monte Carlo (MCMC) inference generates estimates of evolutionary parameters and their posterior probability distributions. As the number of sequences increases, the length of time taken to complete an MCMC analysis increases as well. Here, we investigate an approach to distribute the MCMC analysis across a cluster of computers. To do this, we use bootstrapped topologies as fixed genealogies, perform a single MCMC analysis on each genealogy without topological rearrangements, and pool the results across all MCMC analyses. We show, through simulations, that although the standard MCMC performs better than the bootstrap-MCMC at estimating the effective population size (scaled by mutation rate), the bootstrap-MCMC returns better estimates of growth rates. Additionally, we find that our bootstrap-MCMC analyses are, on average, 37 times faster for equivalent effective sample sizes.
Introduction
The coalescent is a mathematical description of the genealogy of a sample of sequences from a Wright-Fisher population. Kingman1,2 showed that the times to common ancestry of any pair of lineages, measured from present to past, can be approximated by exponential random variables with the expected time proportional to 2
Of course, the genealogy is seldom known with certainty, and the approach adopted over the last few years has been to develop clever computational methods that integrate over all genealogies, weighting each genealogy by its likelihood:3,4

The term
This approach also applies to the Bayesian methods that have been developed.
5
Here, the aim is to recover the posterior probability distribution,
MCMC is a powerful computational technique that is naturally suited to Bayesian inference because, in its simplest and most intuitive form, it delivers a probability distribution of parameter values instead of one value that maximizes some function. In this paper, we will focus on MCMC and its use in coalescent-based Bayesian inference. There are many issues relating to the performance of MCMC: how do we know when the Markov chain has converged to the target distribution, how frequently should we sample, how long should chains be, and so on. We will ignore all of these, largely because there are many good texts, primers and reviews on these topics. Instead, we will focus on a method that permits us to distribute our MCMC coalescent integration across a computational cluster to achieve an increase in the speed of execution.
There are three main reasons to use cluster-based computing for MCMC: to assist with mixing, to increase the speed of the MCMC procedure, and as a check for convergence. For instance, MrBayes 6 uses a computational cluster to perform multi-chain Metropolis Coupled MCMC, permitting samples to mix across different chains. BayesPhylogenies 7 uses a computational cluster to calculate the likelihoods of parts of the data, thus increasing the speed of execution. Finally, it is also possible to run several MCMC chains of the same data on a cluster to check for convergence to the same target distribution.
In this paper, we examine an approach first proposed by Felsenstein 8 which involves the use of bootstrap trees. This method has not been implemented in any existing software, nor has it been tested to any great extent. Our aim is to study the properties of estimates derived using this approach, in an attempt to determine whether the relative benefits of increased computational speed outweigh any loss in estimation efficiency.
The procedure
We begin by noting that a genealogy, 

As before, to obtain the posterior probability of Θ, we have

Of course, as Felsenstein 8 noted, there is no guarantee that the bootstrap histories will be the “more likely” histories in any technical sense, but intuition suggests that they will constitute an assemblage of trees with reasonably high likelihoods. As an aside, it is worth noting that Kuhner, Yamato, and Felsenstein 4 argued against this approach because bootstrap trees admit zero-length branches and estimates of Θ based on these branches will be indeterminate under the coalescent likelihood (Eqn. 1). However, what we have done here is allow the MCMC procedure to alter the branch lengths, so we effectively strip the branch-lengths away leaving only the history.
Simulations
Seventy haploid sequences, each 1000 bases long, were generated randomly under the coalescent process using SimCoal 2. 10 The constant population size was set at 100,000. The mutation rate was 1.5 × 10−6 mutations per site per generation. Ten replicates were generated. This process was also repeated using sample sizes of 140 and 210 sequences. Sequences were also generated assuming an exponentially growing population with a current (or terminal) population size of 100,000 increasing at a rate of 0.0005, again with ten replicates for samples of 70, 140, and 210 sequences.
For each data set, 100 bootstrap trees were generated using PHYML v1.2.2. 11 A BIONJ distance-based tree is used as the starting tree in PHYML and optimized under a HKY substitution model using maximum likelihood with four substitution rate categories. All the other parameters (e.g. transition/transversion ratio, proportion of invariable sites and gamma distribution shape-parameter) were estimated using PHYML.
Bootstrapped trees were midpoint-rooted and were then analyzed using BEAST 12 with shortened chain length (3 million). Thus, we performed 100 MCMC runs for each data set and the topology used in each run was fixed on a different bootstrap tree topology. MCMC samples from all runs on the set of bootstrapped topologies were then combined to obtain the final marginal distributions. Additionally, each original (non-bootstrapped) dataset was analysed with BEAST allowing topological rearrangements, as a comparison. The number of generations for these “standard” MCMC analyses were set to allow the Effective Sample Size (ESS) to approximate that obtained using the bootstrap-MCMC analyses. Generally, MCMC chains for the standard analyses ran for 60–420 million generations. For all analyses, parameters of the substitution model were allowed to vary, uniform priors were used for all continuous parameter variables, the chains were sampled every 5000 generations, and the first 10% were discarded as burn-in values. All MCMC analyses were run on a 10-node SGI Altix XE320 cluster, with each node consisting of 2 × Quad Core Xeon 2.8 GHz processors. In total, 80 cores were available.
Analyses of median estimates of Θ and growth rates,
Results
Results for all simulations are given in Tables 1 and 2. For constant sized populations, the bootstrap-MCMC estimates of Θ averaged 0.163, compared to the true value of 0.150–-this equates to about a 10% difference between the true and estimated values. In contrast, the standard MCMC returned an average of 0.149, a difference of less than 1%. The difference in estimation between the bootstrap-MCMC and the standard MCMC was statistically significant (
Parameter estimated from sequences under constant growth rate using both bootstrap-MCMC and standard-MCMC. The true value of Θ is

Parameters estimated from sequences under exponential growth rate using both bootstrap-MCMC and standard-MCMC. The true value of Θ is
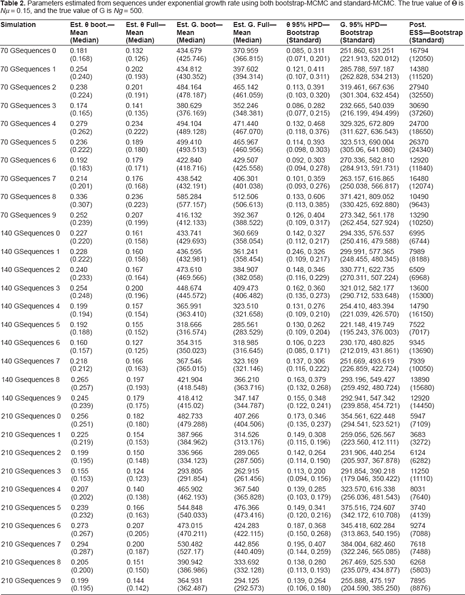
In contrast, when we compare the bootstrap-MCMC and the standard MCMC estimates of growth rate, we find that there is a statistically significant interaction effect between Method and Simulation (
Whereas the standard MCMC does not appear to estimate growth rates as well as the bootstrap-MCMC, it seems to estimate the terminal value of Θ better than the bootstrap-MCMC, and theses estimates improve as more sequences are added. Of the 30 95% HPDs, 7 of the bootstrap-MCMC HPDs exclude the true value, whereas all standard MCMC HPDs enclose the true value (
Interestingly, the frequency distribution of posterior probabilities is multimodal for the bootstrap-MCMC and unimodal for the standard MCMC (Figs. 1A, B). In retrospect, this is not surprising, since only a small part of topology space is explored under the bootstrap-MCMC. It is worth noting, however, that the number of modes on the marginal distribution of log-posterior probabilities obtained using the bootstrap-MCMC does not correspond to the number of unique topologies obtained using the bootstrap. There are more topologies obtained than modes on the marginal distribution of posterior probabilities. Also, it is worth pointing out that the bootstrap-MCMC obtains lower log-posterior probabilities than the standard MCMC.
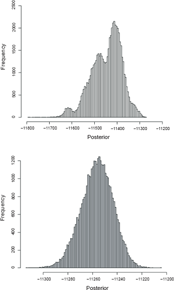
Posterior distribution from bootstrap-MCMC and standard-MCMC. Example of the log-posterior probability distribution from both bootstrap-MCMC (top) and standard-MCMC (below) obtained with 210 sequences simulated with a constant population size. Note also the difference in scales of the horizontal axes.
Finally, if we compare the times of the runs, we find that if the MCMC run for 100 bootstrapped topologies was performed on a 80-core cluster, the bootstrap MCMC took an average of just over an hour (61 mins, range: 44–94 mins) to obtain an average ESS of 17372; in contrast, the standard MCMC took, on average, 37 hrs (2216 mins, range: 1446–4373 mins) to obtain approximately the same ESS (17888).
Discussion
In this paper, we explore the properties of an approach to coalescent-based Bayesian MCMC estimation of evolutionary parameters that begins with a set of bootstrapped topologies which remains fixed throughout the analyses. Distributing these topologies across a cluster of computers affords up to a 37-fold increase in computational speed. In terms of estimation efficiency, the results are mixed: whereas the standard MCMC performs better at estimating Θ, it fails to estimate growth rate as well as the bootstrap-MCMC.
It is fair to say that in the absence of any analytic solution, most estimation methods in phylogenetics and evolutionary genetics rely on heuristic procedures. MCMC itself is a heuristic procedure that only guarantees convergence to the target distribution (generally, the posterior probabilities), under appropriate conditions, without any specification of when that convergence will be reached. Consequently, we never know that we are sampling from the correct distribution without running additional tests. Heuristic methods are useful because, typically, a researcher is prepared to make a trade-off between the time it takes to run an analysis (i.e. computational efficiency) and the degree of uncertainty in the estimates (i.e. estimation efficiency). This is particularly true as we accumulate more sequences, because standard MCMC analyses will require longer times to run. As noted above, the method described here achieves a phenomenal speed increase with our simulations.
The method proposed here can almost certainly be improved. If, instead of using bootstrapped trees, we use trees that are most likely, or nearly most-likely, then we will get closer to essence of the procedure described above. After all, we only use bootstrap trees because we think that these are going to be in the neighborhood of the likelihood peak. Also, if instead of midpoint rooting our bootstrap trees, we found the root that was the most likely under some clock-constraint, we would again have better topologies to work with. However, in both these instances, we would take time to obtain our set of topologies, and this in turn would defeat the purpose of the exercise: the rapid delivery of estimates of evolutionary parameters with reasonable coverage properties. One possible solution, suggested by a reviewer, is to use UPGMA to build the starting topologies. The value of UPGMA is that the root for the tree is found naturally as part of the agglomerative process. UPGMA works well when a strict molecular clock applies (as in our simulations), but performs badly when there is lineage-specific rate variation. We repeated our analyses using UPGMA, but found no substantial differences to the patterns obtained with mid-point rooting, except that for growth rates, the bootstrap MCMC performed more poorly than the standard MCMC (data not shown).
Of course, the gains in computational efficiency of the method described here depend on access to a computational cluster. Such availability is no longer an issue in most research institutions. There are a variety of strategies that can be used to distribute MCMC analyses across a computational cluster. The simulated annealing literature also has distributed computing approaches that warrant exploration. 15 In fact, the simplest approach may be to run multiple independent chains, and pool the posterior distributions, but there are two problems with this strategy: (a) each chain needs to burn in, and (b) there is no sharing of information across chains. Other strategies attempt to correct for these shortcomings, but arguably, a synthesis of several methods may be needed to deliver a significant speed increase. For instance, before the chain has converged, Metropolis Coupled MCMC may be appropriate, but after the burn-in period, pooling the distributions from several different and independent chains can be used to increase the effective sample size. Recently, the paper by Lakner et al 16 examined the mixing and convergence characteristics of different MCMC topological rearrangements. They concluded that mixing and burn-in may be improved by a hybrid approach with different moves applied at different parts of the chain. Most recently, Suchard and Rambaut 17 have demonstrated a significant speed increase with BEAST by deploying parts of the analysis on Graphics Processing Units (GPUs). Interest in GPU computing is increasing rapidly, and there is the potential for significant speed gains; the drawback is that parallelization has to be implemented in a particular way because of the constraints of GPU architecture. Alternatively, if we are willing to obtain good but “approximate” posterior distributions, then bootstrapping as we have applied it here, may be the answer.
Disclosure
The authors report no conflicts of interest.
Footnotes
Acknowledgments
We thank two reviewers for their helpful comments.