
Abstract
Motivation
Existing methods for estimating copy number variations in array comparative genomic hybridization (aCGH) data are limited to estimations of the gain/loss of chromosome regions for single sample analysis. We propose the linear-median method for estimating shared copy numbers in DNA sequences across multiple samples, demonstrate its operating characteristics through simulations and applications to real cancer data, and compare it to two existing methods.
Results
Our proposed linear-median method has the power to estimate common changes that appear at isolated single probe positions or very short regions. Such changes are hard to detect by current methods. This new method shows a higher rate of true positives and a lower rate of false positives. The linear-median method is non-parametric and hence is more robust in estimating copy number. Additionally the linear-median method is easily computable for practical aCGH data sets compared to other copy number estimation methods.
Introduction
During cell division, a cell replicates its genome by synthesizing a new copy of each chromosome, using the original DNA as a template. The expected copy number of 2, may be less/greater than 2 when alterations occur during the replication process. Research has suggested that such abnormalities in the number of DNA copies in a cell are associated with the development and progression of disease, including cancer. 1 Laboratory research to estimate the altered copy numbers in a DNA sequence often uses aCGH. The technology used to produce aCGH data, however, may result in data that contain uncontrollable noise. 2 The use of appropriate statistical methods to normalize the data and produce meaningful estimates of copy number variation in a DNA sequence is integral to this research. Developing improved statistical methods for this application is the focus of this paper.
Different statistical methods have been suggested for use with aCGH data to estimate copy numbers in DNA sequences. Methods to analyze copy numbers in terms of identifying the locations of gains or losses of chromosome regions have been developed. Assuming that there is a connection between copy number changes in a cancer cell and the development/progression of the cancer, there must exist some common change regions in DNA sequences collected from different patients with the same cancer diagnosis. Techniques for analyzing shared copy number regions have been developed..3,4 For detecting copy number regions in a single sample, Olshen et al 5 and Venkatraman et al 6 had developed a widely used method, the faster circular binary segmentation (CBS) method. In this paper, we propose a new method, the linear-median method, for estimating shared copy number alterations in DNA sequences collected from the same type of cancer cells. The linear-median method is able to optimally use the information available across independent DNA sequences.
This paper is organized as follows. In Section 2.1, we discuss current existing statistical models used to assess aCGH data and describe a new model for analyzing multiple independent aCGH data sets. We introduce the linear-median method in Section 2.2. In Section 3.1, we present three simulation studies. We study how much extra information on copy number aberration can be obtained by using the linear-median method compared to the comparative genomic hybridization minimal common region (cghMCR) method and the CBS algorithm. We present an application of the linear-median method to real data in Section 3.2. Supporting figures and tables are available online as Supplementary Material.
Methods
Modeling DNA copy number alterations in aCGH data
aCGH employs the comparative hybridization of genomic DNA that is differentially labeled according to its source in a cancer cell versus a normal cell. The ratio of the hybridization intensities along the chromosomes provides a measure of the relative copy number of sequences in the genomes that hybridize to each location on the chromosomes. Estimating copy numbers and identifying the locations of gains and losses in a DNA sequence are two main challenges in the analysis of aCGH data. We label the normal genomic sequences as “reference” sample and the genomic sequences from cancer cells as the “test” sample. Let T p denote the “test” copy number at probe position p and R p denote the “reference” copy number at probe position p.
We briefly describe two current methods for modeling aCGH data. Let us denote by Y p the aCGH data (the logarithm intensity ratio) observed at probe position p.
Model 1:
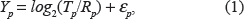
where ∊
p
are i.i.d. with normal distribution N(0,
Model 2:

where ∊ p and η p are i.i.d with a normal distribution N(0,σ 2 )..9,10
In practice, R p is assumed to be 2. Given the logarithm intensity ratio observations, {Y p }, we want to estimate the true copy number at position p or to estimate if the copy number at p is greater/less than 2.
Models 1 and 2 assume very different probability structures to describe the system. The variance of the log intensity ratios given by Model 1 is a constant, whereas the variance of the log intensity ratios given by Model 2 is a function of T p .
We consider which of the two models is a more appropriate model for the analysis of aCGH data. Although Model 1 looks simpler, it is not an appropriate model for aCGH data. The main reason for this is that aCGH data provide the ratio of the copy number variations, not the ratio of the copy numbers. Furthermore, empirical studies show that the standard error of the logarithm of the intensity ratios increases as the copy number increases. Additionally, the distribution of the logarithm of intensity ratios is skewed. 9 Thus, the distribution of ∊ p should not be assumed to be normal if Model 1 is adopted.
Compared to Model 1, Model 2 is a more appropriate model for aCGH data, as it takes into account the ratio of the copy number variations. However, this model can be improved further. The normality assumptions on the distributions of ∊ p and η p can imply that negative values of ∊ p and η p will lead to log2 (T p + ∊/2 + η) being ill-defined. Theoretically, this will cause problems for statistical inference methods based on such an assumption.
In Model 2, the errors ∊ p and η p play the role of measurement errors. Given the fact that the aCGH technique is maturing, it might be reasonable to suggest that both ∊ p and η p follow a uniform distribution U(–a, a), where a can assume any value between 0 and 2, depending on the nature of the underlying aCGH technique. If a takes a value close to 2, this may mean that the underlying aCGH technique is not very accurate, possibly leading to a very large variation in the observations of the intensity ratios. If a takes a value close to 0, we may assume that the underlying aCGH technique is very accurate and that there is less variation in the observations of the intensity ratios. For explicit technical considerations see wikipedia. 2 For our purpose, we restrict a to be less than 2. We apply this restriction to real data analysis in Section 3.2. The output of the real data analysis shows the restriction is acceptable.
Therefore, we consider a third model:
Model 3:
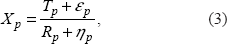
where ∊ p and η p are independent and have uniform distribution U(–a, a) with constant a ∈ (0, 2), and X p is the observed intensity ratio at probe position p.
To allow the model to be more flexible, we can assume that the uniform distributions for ∊ p and η p are not necessarily the same.
Model 3 is used to model one aCGH profile from one sample/patient. However, if there is a group of independent samples of aCGH data (eg, multiple patients) and their data share copy number change regions, we can extend Model 3 to such data.
Consider the following scenario. A group of n patients suffer from a common cancer. For each patient a sample of aCGH data is collected from a cancer cell. Let X
i,p
be the observed intensity ratio for the ith sample at probe position p. We use t
p
to denote the theoretical true value of the
For multiple independent aCGH data, the extended model can be considered as
Model 4:

where M is the total number of probe positions; n is the number of independent samples in the group; ∊
i,p
and η
i,p
are mutually independent random variables; T
i,p
has distribution P(T
i,p
= t
p
) = π and P(T
i,p
= 2) = 1–π, if t
p
≠ 2, ie, if at probe position p the
Model 4 provides a flexible way to model multiple independent aCGH data in terms of the following arguments:
The probability distributions of ∊ i,p and η i,p are allowed to be different. This means that the probability distribution of the measurement errors for the “test” and “reference” are allowed to be different.
The true
Hereafter, we consider multiple independent aCGH data and assume Model 4 as the basis for developing a method to estimate the
Currently, all raw data used for copy number analysis are presented in the format of a log2 intensity of the ratios of the test to the reference. From the current literature, we know that a linear format refers to using the intensity of the ratios of the test to the reference, and a nonlinear format refers to using a log2 intensity of the ratios of the test to the reference, as the log2(ratio) is not linearly related to the copy number. The variance of a linear format tends to be larger than the variance of a nonlinear format when the relative copy number is far away from 1. 11 This may explain why the nonlinear format is widely used.
It is expected that the log2 of the true relative copy number, ie, log2(t p /R p ), can be well estimated using the observations of the log2 intensity of the ratios of the test to the reference, ie, log2 [(T i,p + ∊ i,p )/(R i,p + η i,p )], through the sample mean. Unfortunately, this is generally not true. A simple reason for this is that, in general,

Further, the probability distribution of log2[(T + ∊ p )/(R p + η p )] is not symmetric. Therefore, the sample mean of log2 [(T i,p + ∊ i,p )/(R i,p + η i,p )] might be biased from E [log2 ((T p +∊ p )/(R p + η p ))] for smaller samples. Figure 1 shows a histogram of simulated data drawn from the population log2 [(1 + ∊)/(2 + η)], with ∊ and η i.i.d. uniformly distributed U(–1.8, 1.8) (the function will not be defined if 1 + ∊ ≤ 0).
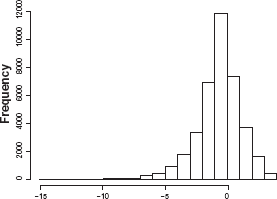
Histogram of log2[(1 + ∊)/(2 + η)].
For the estimating procedure we propose, we will use linear format data rather than nonlinear format data to estimate the shared copy number at probe position p, 0 ≤ p ≤ M.
As defined in Model 4, X i,p is a random variable of the intensity of the ratios of the test to the reference given by the ith sample at probe position p, 1 ≤ p ≤ M, and satisfies the model
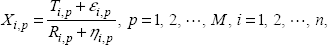
where i denotes the ith sample/patient; ∊ i,p and η i,p are i.i.d. with uniform distribution U(–a, a); T i,p and R i,p are the test intensity and reference intensity, respectively, for probe p for the ith sample.
As stated in Section 2.2, we always assign R
i,p
= 2, which is the information given by the “reference” genome. The true shared copy number t
p
at position p needs to be estimated. The estimate of t
p
is denoted by
Let x i,p be the observed values of X i,p , i = 1, 2, …, n, p = 1, …, M. Herein, we assume that parameter a is unknown but has a value within (0, 2) and that parameter π (defined in Model 4) is known or can be estimated from empirical knowledge.
The estimation of t p , p = 1, …, M, consists of three steps:
Step 1 Calculate the median of {x i,p } i = 1,2, …,n for each p, denoted by M p .
Step 2 Calculate 2(M p –1 + π)/π for each p.
Step 3 Determine the estimate of t p , p = 1, …, M,

where [c] denotes the integer part of the real number c.
We call this 3-step method the “linear-median method”. “Linear” indicates that the data (the intensity of the ratios of the test to the reference) are in a linear format. “Median” indicates that the median of the data is employed by this method.
Next, we explain theoretically why copy numbers can be accurately estimated by this 3-step method.
Let X p be the intensity of the ratios of the test to the reference at probe position p,

where ∊ p and η p are i.i.d. with uniform distribution U[–a, a); and T p is a random variable independent of ∊ p and η p , and has distribution P(T p = t p ) = π and P(Tp = 2) = 1 – π, if the shared copy number t p ≠ 2. As explained in Section 2.1, we assume 0 < a < 2.
Following the definition of X p and assuming the independence of T p + ∊ p and η p , we have

Thus

Equation (5) gives the exact relationship between t
p
and E(X). For each probe position p, if the mean of the intensity of the ratios of the test to the reference is known, and the system parameters a and π are known, the
However, E(X
p
) is unknown in practice and the probability distribution of X
p
is not usually symmetric. It is inappropriate to estimate E(X
p
) by using the sample mean
To overcome this difficulty, we suggest the following way to evaluate t p :
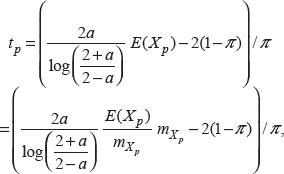
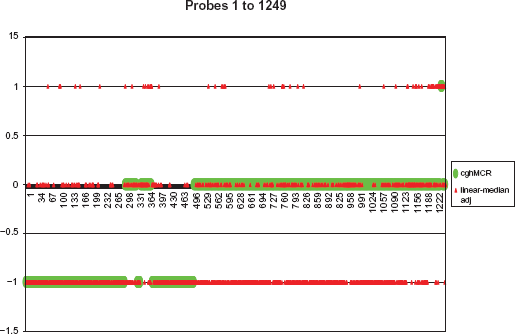
where

and prove that the ratio is close to 1, for any a ∈ (0, 2) and any π ∈ (0, 1).
We use the Monte Carlo method to indirectly show that the value of (6) is close to 1 for a = 0.1, 0.2, …, 1.9 and π = 0.1, 0.2, …, 1. (see Appendix A and Supplementary Tables 1 and 2 in the online materials for details). Therefore,

The sample mean and sample standard error of the estimated error rate {d(k)} given by different combinations of a and n, where a is the parameter of the uniform distribution U[–a, a] and n is the number of the independent sequences in the realizations.

Number of genes identified by the linear-median method (LM) and the cghMCR method in the regions of shared copy number aberrations with the status of copy number loss, neutrality or gain. NR/U is not cancer-related or unknown function phenotype, CR is cancer-related phenotype (except for lung cancer), and LCR is lung cancer-related phenotype.

Simulation studies
The linear-median method is designed for estimating
In a recent review of methods for detecting “recurrent” copy number alterations, Rueda and Diaz-Uriarte evaluated the CGHregions method, Master HMMs, cghMCR, GISTIC, MSA, RAE, and others. 12 In this subsection, we compare the linear-median method to the cghMCR method and the CBS method.
We present three simulation studies to highlight the performance of our proposed linear-median method.

We simulated a group of independent realizations {X i,p } from model (t p + ∊ i,p )/(2 + η i,p ), p = 1, 2, …, 100 and i = 1,2, …, n, where ∊ i,p and η i,p are i.i.d. with uniform distribution U[–a, a].
Subsequently, we generated 1000 replicates. For the kth replicate, k = 1,2, …, 1000, let d(k) be the percentage of
Table 1 shows that the error rate increases with a. This is obvious because a larger value of a is equivalent to a larger measurement error in the data. However, the error rate will be reduced when the number of independent samples in the group increases. In general, the mean error rate calculated for the linear-median method is reasonably low: the mean error rate was less than 10%, as expected, for all three cases of varying a.
Although the underlying model involves the parameter a, Example 1 shows, in general, that the impact of the value of a on the estimation of the copy number is not significant in terms of the mean of d(k), except for a very large value of a(>1). (Further demonstrations are presented in the Supplementary Material.) In summary, the value of a ∈ (0, 2) has minimal effect on the estimation of the
The cghMCR method is designed to identify the minimal common copy number alteration regions among a group of independent samples; thus it is analogous to the linear-median method and is an appropriate method to compare to the linear-median method. Using segmented data (ie, smoothed data), the cghMCR algorithm first identifies altered segments within each subject (those above the 97th or below the 3rd percentile of the data) and then joins adjacent segments separated by a user-defined parameter. The R package for the cghMCR method is available at the following URL: http://www.bioconductor.org/packages/2.6/bioc/html/cghMCR.html. See the work of Aguirre et al for explicit details and a complete review of the cghMCR method. 3
We use simulated data to compare the performance of the linear-median method to that of the cghMCR method. The data were simulated by assuming non dependency between the intensity ratios across probe positions, which is a very simple situation.
Consider a sequence of true

Plot of the sequence of the true copy numbers.
The sequence t
p
consists of four abnormal
We simulated data from the following model

i = 1, 2, …, n, where ∊ i,p , and η i,p are i.i.d. with uniform distribution U(–a, a). Let B(1, π) be a random variable with a Bernoulli distribution such that E[B(1, π)] = π. We considered 3 × 5 × 3 different combinations for (a, π, n), where a = 0.5, 1, 1.5, π = 0.2, 0.4, 0.6, 0.8, 1 and n = 20, 50, 100.
We applied the linear-median method and the cghMCR method to each group of independent samples with size n for different pairs of parameters (a, π), respectively. Then, for each triplet (a, π, n), we calculated the true positive (TP) rates and the false positive (FP) rates produced by each model. TP rate = P(the method shows “copy number changed” | copy number is changed). FP rate = P(the method shows “copy number changed” | copy number is not changed). The linear-median method is able to provide an estimate of the
Finally, we carried out 250 replicates for the case where n = 20; 100 replicates for the case where n = 50, and 50 replicates for the case where n = 100. The resulting TP and FP rates, means, and standard errors obtained from both methods are shown in Supplementary Tables 3–5.
List of lung cancer-related genes for each phenotypic group identified by the linear-median method (LM) and the cghMCR method.

In terms of the TP rates, the linear-median method worked reasonably well in each case and performed vastly better than the cghMCR method, which showed poor performance, especially when a was larger and π was smaller. In this particular example of a true
The ability to estimate the actual
Better power in identifying shorter alternating regions. For example, considering the data simulated from (7) with a = 1.5, π = 1 and n = 20, we can compare the means of the estimated copy numbers given by both methods. Since a = 1.5, the variance for U(–a, a) is relatively large and the simulated data involve a lot of random noise. By choosing π = 1, there is no variation on the true copy numbers shared across the independent samples. Technically, one expects that the linear-median method and the cghMCR method will perform at the same level. However, it turns out that the linear-median method dominates the cghMCR method. At almost every probe position, the sample mean and median of the estimated
Application of the CBS method to the sequence of the median of the logarithm of the ratios (top panel). The red bars show the values of the estimation of log2(t p /2). Application of the linear-median method to the data in Example 3 (bottom panel), showing the estimates of t p at each probe position.
This simulation example (Example 2) illustrates that the cghMCR method performs very poorly in high-noise scenarios, for example, a = 1.5, and the cghMCR method is not robust for large values of a. We believe this is due to the fact that the cghMCR method performs segmentation and calling functions independently of one other; whereas the linear-median method borrows strength from all the samples.

where ∊ i,p , and η i,p , are i.i.d uniformly distributed in [–1, 1], i = 1, 2, … 60. In this example we continue to assume π = 1. The abnormal copy number regions are [101, 150] for t p = 3; [151, 152] for t p = 4; [153, 200] for t p = 3; [201, 202] and [205, 300] for t p = 1. Segments of [101, 150], [153, 200] and [205, 300] are relatively longer. Segments of [151, 152] and [201, 202] are relatively shorter.
In this example, we compare the linear-median method to the circular binary segmentation (CBS) method, which was developed by Olshen et al. 6 An R package description for the CBS method is available at the following URL: http://bioconductor.org/packages/2.6/bioc/manuals/DNAcopy/man/DNAcopy.pdf. The CBS method is employed to find segments along the chromosome that share constant DNA copy numbers. Technically, it is inappropriate to directly compare the analytical results obtained by these two methods because the CBS method is designed for application to a single sample of data, whereas the linear-median method is applicable to a group of independent samples.
To apply the CBS algorithm to observations {x i,p }, i = 1, …, 60, p = 1, …, 300, we make the following adjustment. We calculate log2(x i,p ) for all i and p, since the CBS method is designed for data in a nonlinear format. Then, for each fixed p, we calculate the median of {log2(x i,p )}, forming a new sequence. Finally, we apply the CBS method to this sequence. We justify this comparison with the following argument: If there are common copy number alteration regions among the group of independent samples, the new sequence must contain the information on shared common regions. We consider the new sequence as if it were a single sample of data from a “patient”. Thus, if the information of a shared common region is strong enough, the CBS method should be able to detect the region based on the data of the new sequence. We used the default parameters in our application of the R package to the simulation data in this example.
Figure 3 shows the plot of the medians of {log2(x i,p )} and the estimate of log2(t p /2) (in red), obtained by the CBS method (top panel), and the plot of the estimation of t p obtained by the linear-median method (bottom panel). We see that the linear-median method is able to detect all the changes in the copy number.
Comparing the plots in Figures 3, both approaches, the linear-median method and the CBS method, were able to detect all the longer regions of alternations. However, all the shorter regions of alterations, [151, 152], [201, 202] and [203, 204], were missed by the CBS method. This indicates that the linear-median method has more power than the CBS method to detect shorter segments of alterations or narrow gaps between segments.
We applied the linear-median method to a subset of aCGH data from 39 well-studied lung cancer cell lines.
The data, originally published by Coe et al 13 and Garnis et al 14 are available for downloading from http://sigma.bccrc.ca/. For this study, we used data from only the subgroup with the largest sample size, that of non-small cell adenocarcinoma (NA), which included 18 samples.
As both the linear-median method and the cghMCR method are designed for application to multiple aCGH data, the sample size is a critical issue. Data with more independent samples are able to provide more information on the commonalities across all samples.
Accurately identifying the locations of copy number aberrations has many important medical applications. As far as we know, the cghMCR method is one of the methods used to estimate the
Information on the exact
The total number of probe positions in the NA data (chromosome 9) is 1249. Recalling Model 4 in Section 2.1, in order to estimate the
Combining all the results given by the linear-median method and the cghMCR method for π = 0.2, 0.4, 0.6, 0.8 and 1, we were able to identify a common trend in the outputs of the two methods for all probe positions as the value π moves from 1 to 0.2 (data not shown). For the NA data, both the linear-median method and the cghMCR method give neutral states to all probe positions when π is assigned as 1, with the exception of a few probe positions identified as gain/loss by the linear-median method. In our empirical study of the NA data, if a probe position a is more likely to lose copy number(s), then the
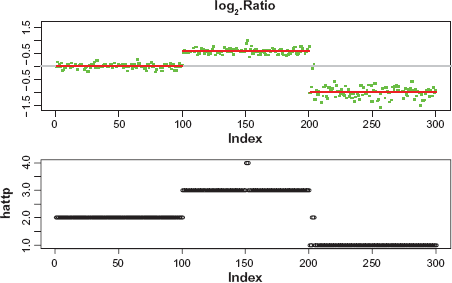
The output of the linear-median adjusted method is shown in red and that of the cghMCR method is in green.
From probe positions 1 to 500 and 1235 to 1249, both the cghMCR method and the linear-median method provide similar results, except for some isolated prob positions. This is what we expect to find because our simulation studies demonstrated that the linear-median method can identify those isolated regions.
From probe positions 501 to 1234, the results obtained from the linear-median method and the cghMCR method are quite different. The cghMCR method claims that all the probe positions are neutral, in contrast to the findings of the linear-median method, which identifies gains/losses at these probe positions. One possible explanation for the large difference between the two sets of results in this prob region is that the π used in the estimation for this region may be too high. A lower value of π should be used to accurately estimate copy numbers in this interval. These results suggest that the parameter π might vary over sequences of NA data. If this is true, then, detecting the change in π will be an interesting challenge for future studies.
Information on the true
The 1249 probe sets we studied target the
In order to classify these genes as one of three general categories, we performed a search of the OMIM database (http://www.ncbi.nlm.nih.gov/omim). The three categories we used were “not related to/unknown cancer phenotype (NR/U)”, “cancer-related phenotype, except for lung cancer (CR)”, and “lung cancer-related phenotype (LCR)”. The results are presented in Tables 2 and 3. Identifying altered regions where important cancer-related genes are located aids the biological interpretation of our findings and works as an empirical form of validation. Detailed locations of the genes categorized as NR/U, CR and LCR are presented in Supplementary Appendix B. From Tables 2 and 3 we can see that the linear-median method is able to report more CR and LCR with copy number losses/gains than the cghMCR method.
We were able to find additional information of interest from the output of the linear-median method. Focusing on the probe positions at which the estimated

The plot of the estimated copy numbers (<1 or >3) given by the linear-median method for π = 0.2.
We developed a new model for aCGH data analysis, the linear-median method, which estimates shared copy numbers in DNA sequences. Using simulated data, we found the linear-median method to be more powerful than the cghMCR method in terms of achieving a higher rate of true positives and a lower rate of false positives. In addition to estimating the common gain/loss of chromosome regions, the linear-median method estimates the number of DNA copies. In other words, analytic results produced by the linear-median method allow us to extract additional information on the tested DNA sequences. In particular, the linear-median method has the power to estimate common changes that appear at isolated single probe positions or very short regions. The only drawback of the linear-median method is that it ignores the dependency information in samples. However, based on our application of the proposed method to real data, we find that most information on shared copy number aberrations can be captured by the linear-median method using only the information across independent samples.
Disclosure
This manuscript has been read and approved by all authors. This paper is unique and is not under consideration by any other publication and has not been published elsewhere. The authors and peer reviewers of this paper report no conflicts of interest. The authors confirm that they have permission to reproduce any copyrighted material.
Footnotes
Acknowledgement
V. Baladandayuthapani was partially supported by US National Science Foundation grant IIS 0914861. K.-A. Do was partially supported by the University of Texas SPORE grants in Prostate Cancer P50 CA140388, Breast Cancer P50 CA116199, Brain Cancer P50 CA127001, and the Cancer Center Support Grant P30 CA016672. We would also like to acknowledge LeeAnn Chastain (UTMDACC) for her editorial contributions to the manuscript.
Supplementary Material Appendix A
Use Monte Carlo method to indirectly show that the value of aE(X p )/{log[(2+a)/(2–a)]m Xp } is close to 1 for a = 0.1, 0.2,…, 1.9 and π = 0.1, 0.2, …, 1.
The simulation is conducted as follows. For each triplet (a, π, t p ), 5000 independent samples are simulated from model
where random variables T
p
, ∊ and η are independent; T
p
has a distribution such that P(T
p
= t
p
) = π and P(T
p
= 2) = 1 – π; ∊ and η have uniform distribution U(–a, a), a = 0.1, 0.2, 0.3, …, 1.9 and π = 0.1, …, 1 with increments of 0.1 respectively; t
p
= 1, 2, …, 9 with increments of 1. The mean and median of X
p
(a, π) are estimated by its sample mean
For each π and t p fixed, the sample mean m(π, t p ) and sample variance s 2 (π, t p ) of
are calculated by the following formulae:
The Monte Carlo simulation results clearly show that all the sample means m(π, t p ) are close to 1 and the sample variance s 2 (π, t p ) are close to 0. Therefore, it is reasonable to accept that aE(X p (a,π))/{log[(2+a)/(2–a)] m Xp (a,π)}, for any a ∈ (0, 2), π ∈ (0, 1) and t p ∈ {1, …, 9}.
Appendix B
The locations of the genes of NR/U, CR and LCR in non-small cell adenocarci-noma (NA) and related references.
R code for the linear-median function
The true positive (TP) rates and false positive (FP) rates for the linear-median method and the cghMCR method, where n = 100.

| n = 100 | L-M | cgh MCR | L-M | cgh MCR | L-M | cgh MCR |
|---|---|---|---|---|---|---|
| π | α = 0.5 | α = 1 | α = 1.5 | |||
| 0.2 | ||||||
| TP | 0.6771 (0.0539) | 0.0048 (0.0203) | 0.7438 (0.0505) | 0 (0) | 0.7335 (0.0461) | 0 (0) |
| FP | 0.0561 (0.0187) | 0 (0) | 0.3266 (0.0412) | 0 (0) | 0.5146 (0.0381) | 0 (0) |
| 0.4 | ||||||
| TP | 0.9566 (0.0233) | 0.6650 (0.1317) | 0.9299 (0.02653) | 0.0004 (0.0030) | 0.8718 (0.0341) | 0 (0) |
| FP | 0.0003 (0.0013) | 0.0455 (0.0270) | 0.0578 (0.0196) | 0 (0) | 0.2012 (0.0340) | 0 (0) |
| 0.6 | ||||||
| TP | 0.9998 (0.0015) | 0.9033 (0.0108) | 0.9920 (0.01010) | 02804 (0.0706) | 0.9556 (0.0239) | 0 (0) |
| FP | 0 (0) | 0 (0) | 0.0065 (0.0075) | 0 (0) | 0.0621 (0.0224) | 0 (0) |
| 0.8 | ||||||
| TP | 1 (0) | 0.8956 (0.0087) | 0.9998 (0.0015) | 0.3345 (0.0193) | 0.9922 (0.0099) | 0 (0) |
| FP | 0 (0) | 0 (0) | 0.0003 (0.0013) | 0 (0) | 0.0167 (0.0125) | 0 (0) |
| 1 | ||||||
| TP | 1 (0) | 0.8971 (0.0177) | 0.9998 (0.0015) | 0.2263 (0.1156) | 0.9983 (0.0044) | 0 (0) |
| FP | 0 (0) | 0 (0) | 0.0003 (0.0013) | 0 (0) | 0.0043 (0.0056) | 0 (0) |