
Abstract
For the last eight years, microarray-based class prediction has been the subject of numerous publications in medicine, bioinformatics and statistics journals. However, in many articles, the assessment of classification accuracy is carried out using suboptimal procedures and is not paid much attention. In this paper, we carefully review various statistical aspects of classifier evaluation and validation from a practical point of view. The main topics addressed are accuracy measures, error rate estimation procedures, variable selection, choice of classifiers and validation strategy.
Keywords
Introduction
In the last few years, microarray-based class prediction has become a major topic in many medical fields. Cancer research is one of the most important fields of application of microarray-based prediction, although classifiers have also been proposed for other diseases such as multiple sclerosis (Bomprezzi et al. 2003). Important applications are molecular diagnosis of disease subtype and prediction of future events such as, e.g. response to treatment, relapses (in multiple sclerosis) or cancer recidive. Note that both problems are usually treated identically from a statistical point of view and related from a medical point of view, since patients with different disease subtypes also often have different outcomes.
Let us consider a standard class prediction problem where expression data of p transcripts and the class information are available for a group of n patients. From a statistical point of view, patients are observations and transcripts are variables. Note that a particular gene might be represented several times. To avoid misunderstandings, we prefer the statistical term “variable” to the ambiguous term “gene”. In microarray studies, the number of variables p is huge compared to n (typically, 5000 ≤ p ≤ 50000 and 20 ≤ n ≤300), which makes standard statistical prediction methods inapplicable. This dimensionality problem is also encountered in other fields such as proteomics or chemometrics. Hence, the issues discussed in the present article are not specific to microarray data. The term response class refers to the categorical variable that has to be predicted based on gene expression data. It can be, e.g. the presence or absence of disease, a tumor subtype such as ALL/AML (Golub et al. 1999) or the response to a therapy (Ghadimi et al. 2005; Rimkus et al. 2008). The number of classes may be higher than two, though binary class prediction is by far the most frequent case in practice.
Note that gene expression data may also be used to predict survival times, ordinal scores or continuous parameters. However, class prediction is the most relevant prediction problem in practice. The interpretation of results is much more intuitive for class prediction than for other prediction problems. From a medical point of view, it is often sensible to summarize more complex prediction problems such as, e.g. survival prediction or ordinal regression as binary class prediction. Moreover, we think that the model assumptions required by most survival analysis methods and methods for the prediction of continuous outcomes are certainly as questionable as the simplification into a classification problem. However, one has to be aware that transforming a general prediction problem into class prediction may lead to a loss of information, depending on the addressed medical question.
Beside some comparative studies briefly recalled in Section 2, several review articles on particular aspects of classification have been published in the last five years. For example, an extensive review on machine learning in bioinformatics including class prediction can be found in Larranaga et al. (2006), whereas Chen (2007) reviews both class comparison and class prediction with emphasis on univariate test statistics and model choice from the point of view of pharmacogenomics. Asyali et al. (2006) gives a wide overview of class prediction and related problems such as data preparation and clustering. Synthetic guidelines for good practice in microarray data analysis including class prediction can be found in Simon et al. (2003); Dupuy and Simon (2007). The latter also gives a critical overview of cancer research articles published in 2004.
In contrast to all these, the present article focuses specifically on the statistical evaluation of microarray-based prediction methods. After a brief overview of existing classification methods in Section 2, measures of classification accuracy including error rate, sensitivity and specificity as well as ROC-curve analysis are addressed in Section 3. Section 4 reviews different evaluation strategies such as leaving-one-out cross-validation or bootstrap methods from a technical point of view, whereas Section 5 gives guidelines for practical studies. An overview of software for microarray-based class prediction in the R system for statistical computing (R Development Core Team, 2006) is given in the appendix.
Overview of Existing Classifiers
Coping with High-Dimensional Data
There exist a variety of classification methods addressing exactly the same statistical problem. Several classifiers have been invented or adapted to address specifically prediction problems based on high-dimensional microarray data. Class prediction can also be addressed using machine learning approaches. The aim of this section is to provide a concise overview of the most well-known classification approaches rather than an exhaustive enumeration. In contrast to other authors, we organize this overview with respect to the scheme used to handle high-dimensionality and not to the classifier itself. From this perspective, methods for handling high-dimensional data can basically be grouped into three categories: approaches based on (explicit) variable selection, procedures based on dimension reduction and methods performing intrinsic variable selection. It should be noted that the three mentioned types of approaches for handling high dimensional data can also be combined with each other. For instance, variable selection may be performed prior to dimension reduction or before applying a method handling more variables than observations.
Variable Selection
The most intuitive approach consists of first selecting a small subset of variables and then applying a traditional classification method to the reduced data set. By traditional methods, we mean well-known statistical methods handling a rather limited number of variables, such as discriminant analysis methods reviewed and compared by Dudoit et al. (2002) including linear and quadratic discriminant analysis or Fisher's linear discriminant analysis, classical logistic regression or k-nearest-neighbors. In principle, the latter could be applied to a high number of variables but performs poorly on noisy data.
Many variable selection approaches have been described in the bioinformatics literature. Overviews include the works by Stolovitzky (2003) and Jeffery et al. (2006). The methods applied can be classified as univariate and multivariate approaches. Univariate approaches consider each variable separately: they are based on the marginal utility of each variable for the classification task. Variables are ranked according to some criterion reflecting their association to the phenotype of interest. After ranking, the first variables of the list are selected for further analysis. Many criteria are conceivable, for instance usual test statistics like Student's t-statistic or nonparametric statistics such as Wilcoxon's rank sum statistic. Further non-parametric univariate criteria include more heuristic measures such as the TnoM score by Ben-Dor et al. (2000). Some of the nonparametric univariate approaches are reviewed by Troyanskaya et al. (2002). The t-statistic, the Mann-Whitney statistic and the heuristic signal-to-noise ratio suggested by Golub et al. (1999) are the most widely-used criteria in practice (Dupuy and Simon, 2007).
In the context of differential expression detection, several regularized variants of the standard t-statistic have been proposed in the last few years. They include, e.g. empirical Bayes methods (Smyth, 2004). An overview can be found in Opgen-Rhein and Strimmer (2007). Although empirical Bayes methods are usually considered as univariate approaches, they involve a multivariate component in the sense described below, since the statistic of each variable is derived by borrowing information from other variables.
Univariate methods are fast and conceptually simple. However, they do not take correlations or interactions between variables into account, resulting in a subset of variables that may not be optimal for the considered classification task. This is obvious in the extreme case where, say, the 10 first variables correspond to the same transcript, yielding a strong correlation structure. It is then suboptimal to select these 10 redundant variables instead of variables with a worse univariate criterion value but giving non-redundant information.
Multivariate variable selection approaches for microarray data have been the subject of a few tens of rather theoretical articles. They take the preceding argument seriously that the subset of the variables with best univariate discrimination power is not necessarily the best subset of variables, due to interactions and correlations between variables. Therefore, multivariate variable selection methods do not score each variable individually but rather try to determine which combinations of variables yield high prediction accuracy. A multivariate variable selection method is characterized by i) the criterion used to score the considered subsets of variables and ii) the algorithm employed to search the space of the possible subsets, an exhaustive enumeration of the 2p–1 possible subsets being computationally unfeasible. Scoring criteria can be categorized into wrapper criteria, i.e. criteria based on the classification accuracy or filter criteria that measure the discrimination power of the considered subset of variables without involving the classifier, for instance the Mahalanobis distance well-known from cluster analysis (which can roughly be seen as multivariate t-statistic).
There have also been various proposals regarding the search algorithms. Some methods, which could be denoted as “semi-multivariate” restrict the search to pairs of variables (Bo and Jonassen, 2002) or subsets of low-correlated and thus presumably non-redundant variables derived from the list of univariately best variables (Jäger et al. 2003). In contrast, other authors seek for globally optimal subsets of variables based on sophisticated search algorithms such as molecular algorithms (Goldberg, 1989) applied to microarray data by, e.g. Ooi and Tan (2003).
Note that most multivariate variable selection methods take only correlations between variables but not interactions into account, depending on the considered criterion used to score the variable subsets. The recent method suggested by Diaz-Uriarte and de Andrέs (2006) based on random forests (Breiman, 2001) is one of the very few methods taking interactions into account explicitly. Potential pitfalls of multivariate methods are the computational expense, the sensitivity to small changes in the learning data and the tendency to overfitting. This is particularly true for methods looking globally for good performing subsets of variables, which makes semi-multivariate methods preferable in our view. Note that, from a technical point of view, univariate variable selection methods, which select the top variables from a ranked list, may be seen as a special case of multivariate selection, where the candidate subsets are defined as the subsets formed by top variables.
In pattern recognition another interesting framework that has been suggested for variable selection is the rough set approach of Pawlak (1991). In this framework, concepts that are relevant for variable selection issues are the so-called reducts and the core of a data table, that can be outlined as follows. Subsets of variables that are sufficient to maintain the structure of equivalence classes (i.e. to distinguish groups of observations that share the same values of a set of variables) form the reduct. In a given data set, several reducts may equally well represent the structure of equivalence classes. However, a (potentially empty) subset of variables is included in all reducts. This so-called core contains those variables that cannot be removed from the data set without loosing information. In addition to the reducts and core based on the structure of the variables, the relative reducts and the relative core also incorporate the response class membership by means of rough sets. They are thus interesting concepts for variable selection issues in classification problems. This approach can be considered as a multivariate variable selection method because it reflects correlations within the data matrix and can be extended to cover interaction effects (Li and Zhang, 2006). However, Kohavi and Frasca (1994) show in a study on simulated and real data that the subset of features that is optimally suited for classification is not necessarily a relative reduct (i.e. does not necessarily include the relative core) but note that using the relative core as a starting point for, e.g. stepwise variable selection may be more promising (cf also Swiniarski and Skowron, 2003; Zhang and Yao, 2004, for overviews on rough set approaches for variable selection and recent advancements).
Dimension Reduction
A major shortcoming of variable selection when applied in combination with classification methods requiring the sample size n to be larger than the number p of variables is that only a small part of the available information is used. For example, if one applies logistic regression to a data set of size n = 50, the model should include at most about 10 variables, which excludes possibly interesting candidates. Moreover, correlations between variables are not taken into account and can even pose a problem in model estimation, the more as gene expression data are known to be highly correlated. An option to circumvent these problems is dimension reduction, which aims at “summarizing” the numerous predictors in form of a small number of new components (often linear combinations of the original predictors). Well-known examples are Principal Component Analysis (PCA), Partial Least Squares (PLS, Nguyen and Rocke, 2002; Boulesteix, 2004; Boulesteix and Strimmer, 2007) and its generalizations (Fort and Lambert-Lacroix, 2005; Ding and Gentleman, 2005), or the Independent Component Analysis (ICA) motivated approach to classificatory decomposition (Smolinski et al. 2006). A concise overview of dimension reduction methods that have been used for classification with microarray data is given in Boulesteix (2006).
After dimension reduction, one can basically apply any classification method to the constructed components, for instance logistic regression or discriminant analysis. However, as opposed to the original genetic or clinical variables, the components constructed with dimension reduction techniques themselves may not be interpretable any more.
Methods Handling a High Number of Variables Directly
Instead of reducing the data to a small number of (either constructed or selected) predictors, methods handling large numbers of variables may be used. Preliminary variable selection or dimension reduction are then unnecessary in theory, although often useful in practice in the case of huge data sets including several tens of thousands of variables. Methods handling a high number of variables (p ≫ n) directly can roughly be divided into two categories: statistical methods based on penalization or shrinkage on the one hand, and approaches borrowed from the machine learning community on the other hand. The first category includes, e.g. penalized logistic regression (Zhu, 2004), the Prediction Analysis of Microarrays (PAM) method based on shrunken centroids (Tibshirani et al. 2002), Support Vector Machines (SVM) (Vapnik, 1995) or the more recent regularized linear discriminant analysis (Guo et al. 2007). Such methods usually involve one or several penalty or shrinkage parameter(s) reflecting the amount of regularization.
Ensemble methods based on recursive partitioning belong to the second category. They include for example bagging procedures (Breiman, 1996) applied to microarray data by Dudoit et al. (2002), boosting (Freund and Schapire, 1997) used in combination with decision trees by Dettling and Buhlmann (2003), BagBoosting (Dettling, 2004) or Breiman's (2001) random forests examined by Diaz-Uriarte and de Andrέs (2006) in the context of variable selection for classification. These methods may be easily applied in the n < p setting. However, most of them become intractable when the number of features reaches a few tens of thousands, as usual in recent data sets. They should then be employed in combination with variable selection or dimension reduction.
Methods handling a high number of variables can be seen as performing intrinsic variable selection. Shrinkage and penalization methods allow to distinguish irrelevant from relevant variables through modifying their coefficients. Tree-based ensemble methods also distinguish between irrelevant and relevant variables intrinsically, through variable selection at each split.
This somewhat artificial splitting into four categories (variable selection, dimension reduction, regularization methods and machine learning approaches) may inspire the choice of candidate classifiers in practical data analysis. Although our aim is definitely not to rate methods, let us sketch a possible approach inspired from the categories outlined above. Since it is in general recommendable to use methods of different nature, a possible combination would be: i) a simple discriminant analysis method such as Linear Discriminant Analysis (LDA) combined with variable selection, ii) a dimension reduction technique, for instance the supervised PLS approach, iii) some regularization techniques, for instance L1 or L2 penalized regression or Support Vector Machines and iv) an ensemble method such as random forests.
Comparison Studies
Prediction methods have been compared in a number of articles published in statistics and bioinformatics journals. Some of the comparisons are so-to-say neutral, whereas others aim at demonstrating the superiority of a particular method. Neutral comparison studies include Dudoit et al. (2002); Romualdi et al. (2003); Man et al. (2004); Lee et al. (2005); Statnikov et al. (2005). Comparison of different classification methods can also be found in biological articles with strong methodological background (e.g. Natsoulis et al. 2005). Most of these studies include common “benchmark” data sets such as the well-known leukemia (Golub et al. 1999) and colon (Alon et al. 1999) data sets. Table 2 (Appendix B) summarizes the characteristics and results of six published comparison studies, which we took as neutral, because they satisfy the following criteria:
The title includes explicitly words such as “comparison” or “evaluation”, but no specific method is mentioned, thus excluding articles whose main aim is to demonstrate the superiority of a particular (new) method. The article has a clear methodological orientation. In particular, the methods are described precisely (including, e.g. the chosen variant or the choice of parameters) and adequate statistical references are provided. The comparison is based on at least two data sets. The comparison is based on at least one of the following evaluation strategies: cross-validation, Monte-Carlo cross-validation, bootstrap methods (see Section 4).
However, even if those criteria are met, optimistically biased results are likely to be obtained with the method(s) from the authors’ expertise area. For example, authors are aware of all available implementations of that method and will quite naturally choose the best one. They may also tend to choose the variable selection method (e.g. t-test or Mann-Whitney test) according to their previous experience of classification, which has been mostly gained with this particular method. Similarly, an inexperienced investigator might overestimate the achievable error rate of methods involving many tuning parameters by setting them to values that are known to the experts as suboptimal.
The Connection between Classifiers and Variable Selection
When performed as a preliminary step, e.g. for computational reasons, variable selection should be seen as a part of classifier construction. In particular, when a classifier is built using a learning data set and tested subsequently on an independent test data set, variable selection must be performed based on the learning set only. Otherwise, one should expect non-negligible positive bias in the estimation of prediction accuracy. In the context of microarray data this problem was first pointed out by Ambroise and McLachlan (2002). Although it is obvious that test observations should not be used for variable selection, variable selection is often (wrongly) carried out as a “preliminary” step, especially when classification accuracy is measured using leave-one-out cross-validation. Even if performing t-tests or Wilcoxon tests n × p times becomes a daunting task when p reaches several tens of thousands, preliminary variable selection using all n arrays and leaving no separate test set for validation should definitively be banished. Bad practice related to this aspect has probably contributed to much “noise discovery” (Ioannidis, 2005).
A further important connection between classifiers and variable selection is the use of classifiers to evaluate the influence of single variables on the response class a posteriori. Parametric models, such as the logistic regression model, provide parameter estimates for main effects and interactions of predictor variables that can be interpreted directly for this purpose. However, the modern nonparametric approaches from machine learning, e.g. random forests, also provide variable importance measures that can be used not only for the preselection of relevant variables (Diaz-Uriarte and de Andrέs, 2006) but are also a means of evaluating the influence of a variable both individually and in interactions on the response. Random forest variable importance measures have thus become a popular and widely used tool in genetics and related fields. However, when the considered predictor variables vary in their scale of measurement or their number of categories, as, e.g. when both genetic and clinical covariates are considered, the computation of the variable importance can be biased and must be performed differently (Strobl et al. 2007).
We have seen in the previous section that in large-scale association studies classification can either be conducted with previous variable selection, dimension reduction, or with special classification methods that can deal with small n large p problems by intrinsically performing variable selection. However, these methods are very diverse, both in their methodological approach and their statistical features. In the following, we review concepts that allow to evaluate and compare all these different strategies and models and are adaptable to special needs of investigators, e.g. if asymmetric misclassification costs are supposed to be modelled.
Error Rate
We consider the random vector

where
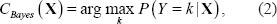
by deriving the posterior distribution P(Y|

Note that this and all following definitions of error rates are appropriate in the case of unordered response classes only. For ordinal response classes it may be desirable that misclassification in a more distant class affects the error term more severely than misclassification in a neighboring class, which could be modelled via pseudo-distances serving as weights in the computation of the error rate. For classifiers that return class probabilities instead of predicted class membership, such as Bayesian methods but also some versions of recursive partitioning, the difference between the predicted class probability and the true class membership can be computed, e.g. by the Brier Score (i.e. the quadratic distance, see, e.g. Spiegelhalter, 1986, for an introduction).
Since the theoretical joint distribution
The data set used to construct (i.e. “learn”) a classifier is usually denoted as “training” or “learning” data set. In this article, we use the term learning data. Let
In practical studies, investigators are often interested in the true error rate of a classifier built with all the available observations:

where

where
Estimating the Error Rate
Suppose we use a learning set

of this classifier is also unknown and has to be estimated based on available test data. Similarly to

where
Sensitivity and Specificity
Using the error rate as defined in Eq. (6), one implicitly considers all misclassifications as equally damaging. In practice, the proportion of misclassified observations might not be the most important feature of a classification method. This is particularly true if one wants to predict therapy response. If a non-responder is incorrectly classified as responder, possible inconveniences are the potentially severe side-effects of a useless therapy and–-from an economic point of view–-the cost of this therapy. On the other hand a responder who is incorrectly classified as nonresponder may be refused an effective therapy, which might lead to impairment or even death.
In the medical literature, these two different aspects are often formulated in terms of sensitivity and specificity. If Y = 1 denotes the condition that has to be detected (for instance responder to a therapy), the sensitivity of the classifier is the probability

whereas the specificity is the probability

Related useful concepts are the positive predictive value and the negative predictive value, which depend on the prevalence of the condition Y = 1 in the population. It does not make sense to calculate them if the class frequencies for the considered n patients are not representative for the population of interest, as is often the case in case-control studies.
Decision Theoretic Aspects
When considering sensitivity and specificity it can be interesting to incorporate the idea of cost or loss functions from decision theory to evaluate misclassification costs. Instead of the error rate defined in Eq. (7), where a neutral cost function is used implicitly, one could use other cost functions, where the costs and thus the weights in the computation of the error rate, are defined depending of the relative seriousness of misclassifications.
More precisely, a neutral, often referred to as scientific cost function assigns unit costs whenever an observation is misclassified (regardless of the true and predicted class), and no costs when the observation is correctly classified. However, if, for instance, classifying an observation with Y = 1 as Y = 0 is more serious than vice-versa, such errors should have more weight, i.e. higher misclassification costs. Many classifiers allow to assign such asymmetric misclassification costs, either directly or via class priors. The following principle is obvious for Bayesian methods, where different prior weights may be assigned to the response classes, but also applies to, e.g. classification trees. Imagine that there are much more observations in class 0 than in class 1. Then, in order to reduce the number of misclassifications predicting class 1 for all observations–-regardless of the values of the predictor variables–-would be a pretty good strategy, because it would guarantee a high number of correctly classified observations.
This principle can be used to train a classifier to concentrate on one class, even if the proportions of class 0 and 1 observations in the actual population and data set are equal: one either has to “make the classifier believe” that there were more observations of class 0 by means of setting a high artificial prior probability for this class, or one has to “tell” the classifier directly that misclassifications of class 0 are more severe by means of specifying higher misclassification costs (cf, e.g. Ripley, 1996). Obviously, such changes in the prior probabilities and costs, that are internally handled as different weights for class 0 and 1 observations, affect sensitivity and specificity. For example, when misclassification of a responder as a non responder is punished more severely than vice-versa, the sensitivity (for correctly detecting a responder) increases, while at the same time the specificity (for correctly identifying a non-responder) decreases, because the classifier categorizes more observations as responders than under a neutral cost scheme.
From a decision theoretic point of view, what we considered as costs so far were actually “regrets” in the sense that the overall costs, e.g. for diagnosing a subject, were not included in our reasoning: only the particular costs induced by a wrong decision were considered, while the costs of correct decisions were considered to be zero. This approach is valid for the comparison of classifiers because the additional costs, e.g. for diagnosing a subject are equal for all classifiers.
Roc Curves
To account for the fact that the sensitivity and specificity of a classifier are not fixed characteristics, but are influenced by the misclassification cost scheme, the receiver operating characteristic (ROC) approach (cf, e.g. Swets, 1988, for an introduction and application examples) could be borrowed from signal detection, and could be used for comparing classifier performance, incorporating the performance under different cost schemes. Then, for each classifier a complete ROC curve describes the sensitivity and specificity under different cost schemes. The curves of two classifiers are directly comparable when they do not intersect. In this case the curve that is further from the diagonal, which would correspond to random class assignment, represents the better classifier. Confidence bounds for ROC curves can be computed (e.g. Schäfer, 1994). The distance from the diagonal, measured as the so called area under curve (AUC), is another useful diagnostic (Hanley and McNeil, 1982) and can be estimated via several approaches (e.g. DeLong et al. 1988). As an example, Figure 3 depicts four ROC curves corresponding to different prediction strengths. The diagonal corresponds to an AUC of 0.5 (random assignment), whereas the dotted line yields the optimal value AUC = 1 and the two dashed lines represent intermediate cases as commonly found in practice.
Credal Classification
So far we have considered only the case that the classifier gives a clear class prediction for each observation, say 0 or 1. In addition to this we noted that some classifiers may also return predicted class probabilities instead. Obviously, when the probability for class 1 is, say, 99% we would predict that class without hesitation. However, tree classifiers or ensemble methods that perform majority voting would also predict class 1 when its predicted probability is only, say, 51%–-as long as the probability for class 1 is higher than that for class 0, no matter how little the difference. In such a situation one might argue that there should be a third option, namely refusing to predict a class whenever the predicted probability is within a certain threshold or returning the extra value “in doubt” (cf Ripley, 1996, p. 5; 17 f) if further information is needed to classify an observation.

Examples of ROC curves.
Several authors have argued along a similar line, for instance the fuzzy set approach by Chianga and Hsub (2002), whose classifier returns the predicted degree of possibility for every class rather than a single predicted class, and Zaffalon (2002), who argues in favor of so-called “credal classification”, where a subset of possible classes for each configuration of predictor variables is returned when there is not enough information to predict one single class (see also Zaffalon et al. 2003, for an application to dementia diagnosis).
After this overview on accuracy measures for the comparison of classifiers, the next section describes possible sampling strategies for the evaluation of accuracy measures. Suggestions on the use of these sampling strategies, as well as a discussion of possible abuses, are given in Section 5.
For simplicity, we assume in the following that the error rate is used as an accuracy measure, but the same principles hold for other measures such as the sensitivity or the specificity. The goal of classifier evaluation is the estimation of the conditional error rate
In this article, we arbitrarily use the notation
In addition, all the methods reviewed in the present section are summarized in Table 1.
Summary of the reviewed evaluation strategies. Iterations: number of iterations, i.e. number of times a classifier is constructed and applied to data; u.d. = user-defined. Bias: Bias of the error estimation; ↑ means positive bias, i.e. underestimation of prediction accuracy and vice-versa. Principle: Gives the definition of the learning and test sets or the used combination of methods.

Summary of the reviewed evaluation strategies.
Summary of six comparison studies of classification methods. This summary should be considered with caution, since not detailing the used variants of the considered methods.

Resubstitution
The easiest–-and from a statistical point of view by far the worst–-evaluation strategy consists of building and evaluating a classifier based on the same data set

Test Data Set
To evaluate the performance of a classification method on independent observations, one should consider non-overlapping learning and test data sets. A classifier is built based on the learning data set only and subsequently applied to the test observations. If, as above,


where T denotes the size of
Note that, due to the fact that some of the observations from the learning data set are held back for the test set and thus the learning data set contains only L < n observations, the estimation of the prediction rule from the learning data set is worse and the resulting prediction error increases. Therefore
Cross-Validation
Another option to evaluate prediction accuracy consists of considering all the available observations as test observations successively in a procedure denoted as cross-validation (CV), see e.g. Hastie et al. (2001) for an overview. The available observations {1,…, n) are divided into m non-overlapping and approximately equally sized subsets whose indices are given by
A prediction is thus obtained for each of the n observations. The error rate is estimated as the mean proportion of misclassified observations over all cross-validation iterations:

This formula simplifies to
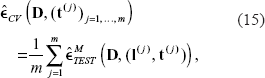
if
In this setting again decision theoretic considerations could be very helpful, leading to criteria going beyond the mere averaging of misclassified observations. For instance, a more conservative approach inspired by the minimax-decision criterion would be to consider for each classifier the maximum, instead of the average, proportion of misclassified observations over all cross-validation samples and finally choose the classifier with the minimal maximum proportion of misclassified observations over all classifiers. This approach could be called for in situations where not the average or expected performance is of interest but rather it is necessary to guarantee that a certain performance standard is held even in the worst case.
An important special case of cross-validation is m = n, where

LOOCV is deterministic, in contrast to cross-validation with m < n which possibly yields different results depending on the (randomly) chosen partition
In order to reduce the variability of cross-validation results due to the choice of the partition 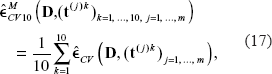
In stratified cross-vlalidation, each subset
Monte-Carlo Cross-Validation(Or Subsampling)
Like cross-validation, Monte-Carlo cross-validation (MCCV) strategies consist of a succession of iterations and evaluate classification based on test data sets that are not used for classifier construction. It may be seen as an averaging of the test set procedure over several splits into learning and test data sets. In contrast to cross-validation, the test sets are not chosen to form a partition of {1, …, n}. In Monte-Carlo cross-validation (also called random splitting or subsampling), the learning sets 
This formula is identical to the formula of
Bootstrap Sampling
In bootstrap sampling, the learning sets
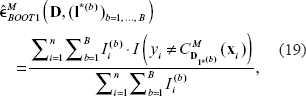
with

Note that the MCCV error estimator presented in the previous section may also be expressed in this way. In contrast, the second bootstrap variant considers each observation individually and estimates the error rate as

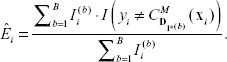
These two variants agree when B ↠ 0 and usually produce nearly identical results (Efron and Tibshirani, 1997).
Note that the principle of bootstrap learning samples that determine their own test samples (the observations not included in the current bootstrap sample, also called “out-of-bag” observations) is also incorporated in the recent ensemble methods bagging (Breiman, 1996) and random forests (Breiman, 2001). Here the prediction accuracy of ensembles of classifiers learned on bootstrap samples is evaluated internally on the out-of-bag observations. Therefore these methods have a built-in control against overoptimistic estimations of the error rate.
The 0.632 and 0.632+ Estimators
Bootstrap estimators of the error rate are upwardly biased, since classifiers are built using on average only 63.2% of the available observations. That is why Efron and Gong (1983) suggest an estimation procedure that combines the bootstrap sampling error rate and the resubstitution error rate. They define the 0.632 estimator as

Bootstrap Cross-Validation
Fu et al. (2005) suggest an approach denoted as bootstrap cross-validation combining bootstrap estimation and LOOCV. The resulting error rate estimator can be seen as a bagging predictor, in the sense that the final error rate estimate results from the combination of several (LOOCV) estimates based on bootstrap samples. For each of the B bootstrap samples, LOOCV is carried out. Error estimation is then obtained by averaging the LOOCV result over the B bootstrap iterations.
Since bootstrap samples have duplicates, learning and test sets may overlap for the corresponding CV iterations. Fu et al. (2005) claim that such an overlapping should be seen as an advantage rather than a disadvantage for small samples, since correcting the upward bias of bootstrap error estimation. Bootstrap cross-validation is reported to perform better than bootstrap and the 0.632 and 0.632+ estimators (Fu et al. 2005).
In this section, we have mainly focused on the potential bias of error rate estimation approaches. The estimation of the variance of these estimators, which is a very complex task in the case of small samples, is addressed in several recent articles. For instance, Berrar et al. (2006) consider the problem of comparisons between several error rates (involving a multiple testing component) and confidence intervals for error rates, whereas Wickenberg-Bolin et al. (2006) suggest an improved variance estimation method for small sample situations. Another aspect to be considered when interpreting error rates is the comparison to error rates obtained using different variants of trivial random classifiers, see Wood et al. (2007) for a thorough discussion of this topic.
The evaluation of classification methods may have various goals. One goal may be to compare several classification methods from a methodological point of view and explain observed differences (for instance, Dudoit et al. 2002; Romualdi et al. 2003; Statnikov et al. 2005). Medical or biological articles on the other hand are concerned with the performance on future independent data of the best classifier, which should be selected following a strict procedure (typically one of those used in the comparison studies mentioned above).
For that selection procedure, resubstitution should never be employed, since yielding far too optimistic estimates of accuracy. Even if the goal is to compare different methods rather than to estimate the absolute prediction accuracy, resubstitution turns out to be inappropriate, since artificially favoring those methods that overfit the learning data. Hence, an inescapable rule is that classifiers should not be evaluated only on the same data set they were trained on.
In this context, the above warning should be repeated. A classical flaw encountered in the literature consists of selecting variables based on the whole data set and building classifiers based on this reduced set of variables. This approach should be banned, see Ambroise and McLachlan (2002); Simon et al. (2003); Wood et al. (2007) for studies on this topic. Even (and especially) when the number of variables reaches several tens of thousands, variable selection must be carried out for each splitting into learning and test data sets successively.
Cross-Validation, Monte-Carlo Cross-Validation and Bootstrap for Classifiers Comparison
In a purely statistical study with focus on the comparison of classification methods in high dimensional settings, it is not recommended to estimate prediction accuracy based on a single learning data set and test data set, because for limited sample sizes the results depend highly on the chosen partition (cf, e.g. Hothorn et al. 2005). From a statistical point of view, when the original learning data set is split into one learning and one test set, increasing the size of the test set decreases the variance of the prediction accuracy estimation. However, it also decreases the size of the leftover learning data set and thus increases the bias, since using less observations than available for learning the prediction rule yields an artificially high and variable error. In the case of a very small n, this might even lead to the too pessimistic conclusion that gene expression data do not contribute to prediction. Procedures like cross-validation, Monte-Carlo cross-validation or bootstrap sampling may be seen as an attempt to decrease the estimation bias by considering larger learning sets, while limiting the variability through averaging over several partitions into learning and test data sets.
Contradicting studies have been published on the comparison of CV, MCCV and bootstrap strategies for error rate estimation. The use of CV (Eq. (14)) in small sample settings is controversial (Braga-Neto and Dougherty, 2004) because of its high variability compared to MCCV (Eq. (18)) or bootstrap sampling (Eq. (19–20)). For instance, in the case of n = 30, each observation accounts for more than 3% in the error rate estimation. For a data set in which, say, at most three patients are difficult to classify, CV does not allow a fair comparison of classification methods. Braga-Neto and Dougherty (2004) recommend bootstrap strategies or repeated CV (denoted as CV10 in the present article, see Eq. (17)) as more robust alternatives. In contrast, another study by Molinaro et al. (2005) taking small sample size and high-dimensionality into account reports good performance for LOOCV estimation, as well as for 5- and 10-fold CV. The low bias of LOOCV, its conceptual simplicity as well as the fact that it does not have any random component make it popular in the context of microarray data. Meanwhile, it has become a standard measure of accuracy used for comparing results from different studies. However, if one wants to use CV, a more recommendable approach consists of repeating cross-validation several times, i.e. with different partitions
Stable estimates of prediction accuracy can also be obtained via MCCV or bootstrap sampling. In MCCV, the choice of the ratio n
When on the other hand the aim of a benchmark study is a complete ranking of all considered classifiers with respect to any performance measure the Bradley-Terry(-Luce) model for paired comparisons (Bradley and Terry, 1952) or the recent approach of Hornik and Meyer (2007) for consensus rankings are attractive. In addition to the purely descriptive ranking of these approaches statistical inference on the performance differences between classifiers can be conducted when the test samples are drawn appropriately, e.g. when several CV- or bootstrap-samples are available (Hothorn et al. 2005).
Validation in Medical Studies
In medical studies, the problem is different. Investigators are not interested in the methods themselves but in their practical relevance and validity for future independent patient data. The addressed questions are:
Can reliable prediction be performed for new patients? Which classification method should be used on these new data?
Whereas the second question is basically the same as in statistical studies, the first question is most often ignored in statistical papers, whose goal is rather to compare methods from a theoretical point of view than to produce “ready-to-use” classifiers to be used in medical practice.
Question 1 can be answered reliably only based on several, or one large, validation data set that has been made available to the statistician after construction and selection of an appropriate classifier. A validation set that remains unopened until the end of the analysis is necessary, in the vein of the validation policy developed by the Sylvia Lawry Centre for Multiple Sclerosis Research (Daumer et al. 2007).
Choice of the Validation Data Set
The impact of the reported classifier accuracy in the medical community increases with the differences between validation data set and open data set. For example, it is much more difficult to find similar results (and thus much more impressing when such results are found) on a validation data set collected in a different lab at a different time and for patients with different ethnic, social or geographical background than in a validation set drawn at random from a homogeneous data set at the beginning of the analysis. An important special case is when the learning and validation sets are defined chronologically. In this scheme, the first recruited patients are considered as learning data and used for classifier construction and selection before the validation data set is collected, hence warranting that the validation data remain unopened until the end of the learning phase. Obviously, evaluating a classifier on a validation data set does not provide an estimate of the error rate which would be obtained if both learning and validation data set were used for learning the classifier. However, having an untouched validation data set is the only way to simulate prediction of new data. See Simon (2006) for considerations on the validation problem in concrete cancer studies and Buyse et al. (2006) for details on the validation experiments conducted to validate the well-known 70-gene signature for breast cancer outcome prediction by (van'tVeer et al. 2002).
Furthermore, if the learning and test sets are essentially different (e.g. from a geographical or technical point of view), bad performance may be obtained even with a classifier that is optimal with respect to the learning data. The error rate on the validation set increases with i) the level of independence between Y and
Thus, it does make a difference whether the learning and test sets are (random) samples from the same original data set, or if the test set is sampled, e.g. in a different center in a multi-center clinical trial or at a different point in time in a long-term study. The first case–-ideally with random sampling of the learning and test sets–-corresponds to the most general assumption for all kinds of statistical models, namely the “i.i.d.” assumption that all data in the learning and test sets are randomly drawn independent samples from the same distribution and that the samples only vary randomly from this distribution due to their limited sample size. This common distribution is often called the data generating process (DGP). A classifier that was trained on a learning sample is supposed to perform well on a test sample from the same DGP, as long as it does not overfit.
A different story is the performance of a classifier learned on one data set and tested on another one from a different place or time. If the classifier performs badly on this kind of test sample this can have different reasons: either important confounder variables were not accounted for in the original classifier, e.g. an effect of climate when the classifier is supposed to be generalized over different continents (cf Altman and Royston, 2000, who state that models may not be “transportable”), or–-even more severe for the scientist–-the DGP has actually changed, e.g. over time, which is an issue discussed as “data drift”, “concept drift” or “structural change” in the literature. In this latter case, rather than discarding the classifier, the change in the data stream should be detected (Kifer et al. 2004) and modelled accordingly–-or in restricted situations it is even possible to formalize conditions under which some performance guarantees can be proved for the test set (Ben-David et al. 2007).
When on the other hand the ultimate goal is to find a classifier that is generalizable to all kinds of test sets, including those from different places or points in time, as a consequence we would have to follow the reasoning of “Occam's razor” for our statistical models: the sparsest model is always the best choice other things being equal. Such arguments can be found in Altman and Royston (2000) and, more drastically, in Hand (2006), who uses this argument not only with respect to avoiding overfitting and the inclusion of too many covariates, but also, e.g. in favor of linear models as opposed to recursive partitioning, where it is, however, at least questionable from our point of view, if the strictly linear, parametric and additive approach of linear models is really more “sparse” than, e.g. simple binary partitioning.
Recommendations
With respect to the first question posed at the beginning of this subsection we therefore have to conclude that there are at least one clinical and one–-if not a dozen–-statistical answers, while for the second question we have a clear recommendation. Question 2 should be addressed based on the open learning data set only via cross-validation, repeated cross-validation, Monte-Carlo cross-validation or bootstrap approaches. The procedure is as follows:
Define Niter pairs of learning and test sets ( For each iteration (j = 1, …, Niter), repeat the following steps:
Construct classifiers based on Predict the observations from the test set Estimate the error rate based on the chosen procedure for all methods M1, …, Mq successively. Select the method yielding the smallest error rate. It should then be validated using the observations from the independent validation set.
A critical aspect of this procedure is the choice of the “candidate” methods M1, …, M On the one hand, trying many methods increases the probability to find a method performing better than the other methods “by chance”. On the other hand, obviously, increasing the number of methods also increases the chance of finding the right method, i.e. the method that best reflects the true data structure and is thus expected to show good performance on independent new data as well.
CV, MCCV or bootstrap procedures might also be useful in medical studies for accuracy estimation, but their results should not be over-interpreted. They give a valuable preview of classifier accuracy when the collected data set is still not large enough for putting aside a large enough validation set. In this case, one should adopt one the following approaches for choosing the method parameters:
Using the default parameter values. Selecting parameter values by internal cross-validation (or a related approach) within each iteration (Varma and Simon, 2006). The computational complexity is then n
2
, which makes it prohibitive if the chosen classification method is not very fast, especially when it involves variable selection. Selecting parameter values based on solid previous publications analyzing other data sets.
Trying several values and reporting only the error rate obtained with the optimal value is an incorrect approach. Studies and discussions on the bias induced by this approach can be found in Varma and Simon (2006); Wood et al. (2007). In all cases, it should be mentioned that such an analysis does not replace an independent validation data set.
For fair evaluation of classifiers, the following rules should be taken into account.
The constructed classifier should ideally be tested on a independent validation data set. If impossible (e.g. because the sample is too small), the error rate should be estimated with a procedure which tests the classifier based on data that were not used for its construction, such as cross-validation, Monte-Carlo cross-validation or bootstrap sampling.
Variable selection should be considered as a step of classifier construction. As such, it should be carried out using the learning data only.
Whenever appropriate, sensitivity and specificity of classifiers should be estimated. If the goal of the study is, e.g. to reach high sensitivity, it is important to design the classifier correspondingly.
Note that both the construction and the evaluation of prediction rules have to be modified if the outcome is not, as assumed in this paper, nominal, but ordinal, continuous or censored. While ordinal variables are very difficult to handle in the small sample setting and thus often dichotomized, censored survival variables can be handled using specific methods coping with the n < p setting. Since censoring makes the use of usual criteria like the mean square error impossible, sophisticated evaluation procedures have to be used, such as the Brier score (see VanWieringen et al. (2007) for a review of several criteria).
Another aspect that has not been treated in the present paper because it would have gone beyond its scope is the stability of classifiers and classifier assessment. For instance, would the same classifier be obtained if an observation were removed from the data set? How does an incorrect response specification affect the classification rule and the estimation of its error rate? Further research is needed to answer these most relevant questions, which affect all microarray studies.
Further research should also consider the fact that due to the many steps involved in the experimental process, from hybridization to image analysis, even in high quality experimental data severe measurement error may be present (see, e.g. Rocke and Durbin, 2001; Tadesse et al. 2005; Purdom and Holmes, 2005). As a consequence, prediction and diagnosis no longer coincide, since prediction is usually still based on the mismeasured variables, while diagnosis tries to understand the material relations between the true variables. While several powerful procedures to correct measurement error are available for regression models (see, e.g. Wansbeek and Meijer, 2000; Cheng and Ness, 1999; Carroll et al. 2006; Schneeweiß and Augustin, 2006, for surveys considering linear and nonlinear models, respectively), in the classification context well-founded treatment of measurement error is still in its infancy.
A further problem which is largely ignored by many statistical articles is the incorporation of clinical parameters into the classifier and the underlying question of the additional predictive value of gene expression data compared to clinical parameters alone. Although “adjustment for other classic predictors of the disease outcome [is] essential” (Ntzani and Ioannidis, 2003), this problem is largely ignored by most methodological articles. Specific evaluation and comparison strategies have to be developed to answer this question.
Footnotes
Acknowledgement
We are grateful to the two anonymous referees for their helpful comments. ALB was supported by the Porticus Foundation in the context of the International School for Clinical Bioinformatics and Technical Medicine.