
Abstract
The issue of wide feature-set variability has recently been raised in the context of expression-based classification using microarray data. This paper addresses this concern by demonstrating the natural manner in which many feature sets of a certain size chosen from a large collection of potential features can be so close to being optimal that they are statistically indistinguishable. Feature-set optimality is inherently related to sample size because it only arises on account of the tendency for diminished classifier accuracy as the number of features grows too large for satisfactory design from the sample data. The paper considers optimal feature sets in the framework of a model in which the features are grouped in such a way that intra-group correlation is substantial whereas inter-group correlation is minimal, the intent being to model the situation in which there are groups of highly correlated co-regulated genes and there is little correlation between the co-regulated groups. This is accomplished by using a block model for the covariance matrix that reflects these conditions. Focusing on linear discriminant analysis, we demonstrate how these assumptions can lead to very large numbers of close-to-optimal feature sets.
Introduction
Concern has recently been expressed regarding the fact that different studies reveal different gene sets for microarray-based cancer classifiers meant to achieve a decision for the same characteristics. In particular, we refer to the concern regarding different gene sets for predicting prognosis for breast cancer (Ioannidis, 2005; Jenssen and Hovig, 2005). In one study, the issue is addressed by repeatedly randomly selecting a subset of the data, designing a classifier on the subset, estimating the error of the designed classifier on the remaining data points, and considering the distribution of the genes composing the various classifier feature sets (Michiels et al. 2005). Concern is expressed over the wide variability of the feature sets and the large number of genes contributing to the various feature sets. Reference is made to the sample size. While sample size is a factor, it is not the only one. A wide array of feature sets can occur with large samples owing to the relations among the genes. The potential for a large number of “best” feature sets is an inherent property of pattern recognition and is not particular to microarrays. In this paper we will explore this potential taking a model-based approach, specifically, modeling the covariance matrix of the features.
Before proceeding we must clarify the problem. Suppose we have some large number, D, of features from which to choose, say 20,000 gene-expression levels from a microarray. If we know the class conditional probability distributions, say the distributions of the genes for two phenotypes, then the collection of all D features is optimal. Many may be redundant and can be removed with negligible effect on classification accuracy; nonetheless, all can be kept without doing harm to the classification accuracy. This, however, is abstract. In practice, feature sets and classifiers must be derived from sample data, and here there is the common situation of the error declining as the number of features grows to a certain point and then beginning to increase as the number of features increases beyond that point – the peaking phenomenon (Hughes, 1969; Kanal and Chandrasekaran, 1971; Jain and Waller, 1978) Peaking tends to occur later for larger samples. It occurs because too many features overfit the data. Hence, the issue of an optimal feature set is inherently one of classifier design from sample data. Given a sample, among all possible feature sets, which one results in a classifier with minimal error? Or more generally, what is the optimal number of features, in the sense that the expected error for samples of the optimal size is minimized relative to all possible sizes? The answer depends on the type of classifier being designed (Hua et al. 2005).
Since the actual distributions are unknown, evaluating feature sets requires error estimation. Different error estimators will yield different rankings of feature-set performance. Even for large samples, error estimation suffers some imprecision. Thus, if there is a large number of close-to-optimal feature sets arising from a sample, then many of these may be statistically indistinguishable. Moreover, and this seems to be the issue concerning some investigators, different samples will yield different top-performing feature sets. But this is to be expected if each sample yields a list of feature sets (and classifiers) whose error rates are indistinguishable.
Putting aside error estimation for the moment, and focusing solely on classifier design, is it even conceivable to find an optimal feature set for a given sample? In the abstract, one could design a classifier for every possible feature set according to the desired classification rule, find the errors for these, and choose the best classifying feature set. But this program cannot be carried out because the number of possible feature sets to check is astronomical. Moreover, in the absence of prior distributional knowledge, which is the common situation in applications, a full search cannot be avoided if we wish to be assured of finding an optimal feature set (Cover and van Campenhout, 1977). This leads to the feature-selection problem, which is to apply some algorithm to select a less-than-optimal feature set that provides good classification. Depending on the feature-selection algorithm, or possible variant choices within the algorithm, different feature sets will be obtained for the same sample. There is the expectation that the more data one has, the better will be the selected feature set; nonetheless, outcome variability remains. Owing to the instability of feature-selection algorithms, one can surely expect slight changes in the data to result in different outputs. It is important to recognize that feature selection is part of classifier design. It determines the features that serve as variables for the classifier, which is a function on those variables. In doing so, it is part of the classification rule by which the classifier is constructed from the data. If we now incorporate error estimation into our reasoning, not only does it create imprecision in obtaining errors, but it also affects the feature-selection algorithm (Sima et al. 2005).
Given the preceding considerations, we will approach the optimal-feature-set problem in the following way: given the class conditional distributions and a positive integer d, find the family of all feature sets of size d from among the potential features that possess minimal error, and hence are optimal. As posed, feature selection and error estimation do not play a role. Practically, error estimation is a must, so that, regarding the number of “best” feature sets, the issue is not so much one of simply finding the number optimal feature sets, but one of showing that there can be a very large number of feature sets of size d whose (true) errors are close to minimal, since these will be statistically indistinguishable. We note in this regard that increasing the sample size does not necessarily mitigate the problem of a large number of statistically indistinguishable feature sets, because as the sample size grows, so too does the size of the feature set producing minimal error, which means extraordinary growth in the number of feature sets of that size.
In the context of gene-expression classification, reflection on biological regulation indicates the enormous gene set variability that can be expected from a microarray study. A set of genes is useful for discriminating pathologies if its behavior, as a collection, varies according to the phenotypes. It may be that the genes involved have some primary regulatory function relating to the phenotype or that they are related, within the overall genome regulation, to other genes governing the phenotype. Given the complex regulatory connectivity within the genome–intricate feedback, massive redundancy, regulatory cascades, and tightly controlled co-regulation of gene cohorts–one should expect a large collection of gene sets having essentially equivalent capability for phenotype discrimination. Add to this the vast number of genes involved. Even if we throw away 80% of the genes on a 20-000-gene microarray, this leaves C(4000, d) feature sets of size d, where C(D, d) denotes the number of subsets of size d that can be formed from D elements. Even for a modest size d this number is enormous. Fore instance, C(4000, 40) > 1080. Consequently, the errors corresponding to the feature sets can be expected to be extremely dense in the interval [∈, 1], where ∈ is the Bayes error (minimal achievable error) for the classification problem. This observation alone should make it apparent that we can expect to find a large number of feature sets whose errors are statistically indistinguishable from the optimal one.
This paper considers a model in which the features are grouped in such a way that intra-group correlation is substantial whereas inter-group correlation is minimal, the intent being to model the situation in which there are groups of highly correlated co-regulated genes and there is little correlation between the co-regulated groups. This will be accomplished by using a block model for the covariance matrix that reflects these conditions. Focusing on linear discriminant analysis, we demonstrate how these assumptions can lead to large numbers of close-to-optimal feature sets.
A Covariance Structure Leading to Many Close-to-Optimal Feature Sets
We consider classification for two Gaussian classes. Thus, the classes 0 and 1 possess normal conditional distributions, with mean vectors μ
k
and covariance matrices

The discriminant is a linear function of
The decision boundary and error for LDA depend on the means, variances, and correlation coefficients. Obtaining direct insight concerning feature selection is not possible in the general case. A standard approach is to adopt a tractable covariance model that represents some assumptions on the relations among the features. For instance, a classic paper on finding the optimal number of features for LDA considers three covariance models (Jain and Waller, 1978). For all models it assumes a common variance σ 2 and a single base value ρ from which the correlation coefficients are obtained. The models are defined by their correlation assumptions: (I) ρ ij = ρ, (II) ρ ij = ρ|i–j|, and (III)ρ ij = ρ if |i–j| = 1 and ρ ij = 0 if |i–j| > 1. The 3x3 forms of these models are given by the following covariance models:
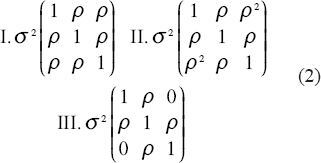
In this paper we adopt a model suitable to the independent co-regulation of gene groups. Genes in different groups are uncorrelated and those within the same group are correlated. If we label these groups as G1, G2,…, Gm, then the covariance matrix is blocked and takes the form

where, for k = 1, 2,…, m,
We illustrate feature-set separation with several examples. Because the simulations required to construct the examples are extremely computational, we limit ourselves to relatively small covariance matrices. We first consider

Percentage of separated optimal feature sets as a function of the correlation coefficient ρ. First row:
To demonstrate the commonplace nature of the preceding results, as well as how they can vary depending on the model and the variability of the variance, we have done similar analyses in a number of circumstances. The results are shown in the remaining parts of Fig. 1: (c)
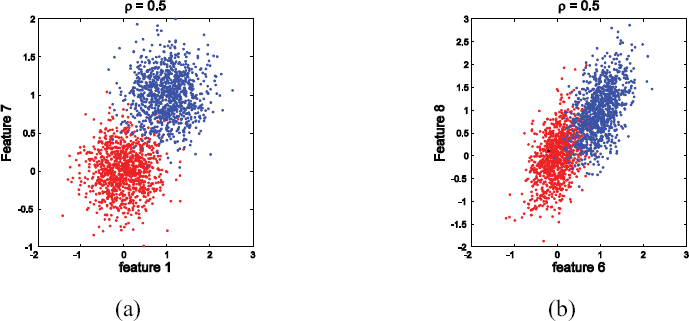
To look closer at the low separation percentage when ρ ≈ 1, we consider two examples for the model having

Scatter plots for model
In the second example, we let ρ = 0.5 and generate one realization of
Scatter plots for model
Comparing Figures 2(b) and 3(b) for the feature set {X6, X8} shows what is happening, ρ is the common conditional correlation coefficient for the conditional densities fX|0 and fx|1. Since ρ ≈ 1 in Fig. 2(b), the sample points for each class lie almost on a line, the lines being distinct because the class means are not equal. These two almost linear point masses are easily discriminated by a straight line between them. In Fig. 3(b), where ρ = 0.5, we see that the point masses are scattered around the two lines and extensively intermingle. Therefore they are not well discriminated.
Analysis of Feature-Set Redundancy
Now that we know there are many separated feature sets resulting from the covariance model of Eq. 3, let A be such a feature set, μ01, μ02,…, μ0m and μ11, μ12,…, μ1m denote the means of the features in A for classes 0 and 1, respectively, and

where Δ(A) is the Mahalanobis distance. Since g1, g2,…, gm are independent, this distance is determined by

Each term of the sum gives the contribution of the feature in reducing the error. The contribution is increased for greater separation of the means and smaller variance. The error tends to 0 as Δ(A) tends to infinity. If, for any feature g with variance
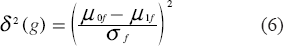
then Eq. 5 can be rewritten as
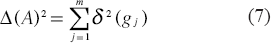
To consider feature-set redundancy, suppose t is a very small positive number and that, for k = 1, 2,…, m, the set Gk has a subset

for i = 1, 2,…, mk. We form a feature set B by replacing q features in A by elements in q of the sets
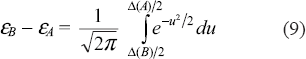
Equations 7 and 8 yield
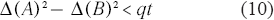
Some simple algebra shows that

Denoting the fraction on the right by η(q, t), we conclude that

For very small t, this difference is negligible, in which case the performances of the two feature sets are negligibly different. Since there are mk features in Gk satisfying Eq. 8, the q elements can be chosen in
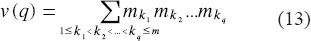
ways. If we consider all feature sets formed by replacing 1,2,…, m elements from different blocks, then the total number of close-to-optimal feature sets formed in this manner is

If the blocks are large and there are several genes in some or all of the blocks satisfying Eq. 8, then this number can be very large.
The point is clear: if the blocks are large, which they may well be when they represent co-regulation of independent cohorts of genes, then there may be many features in a block possessing contributions close to the maximum. These can be interchanged with little effect on the error, thereby leading to close-to-optimal feature sets. In practice, feature sets whose errors are close to optimal will be indistinguishable owing to the need for error estimation.
We now illustrate feature-set redundancy with two examples generated from the model of Eq. 3 with
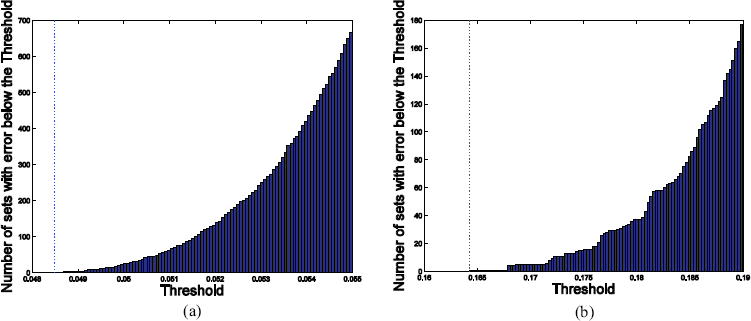
Cumulative histograms of superior feature-set errors: (a) low Bayes error; (b) high Bayes error.
Conclusion
Feature-set variability should not be of concern in the context of finding expression-based diagnostic panels. It arises naturally from the relationships among the features, the vast number of feature sets when there is a large number of potential features, and the inherent natures of both classifier design and error estimation from sample data. Owing to the peaking phenomenon, larger sample sizes may not reduce the number of close-to-optimal feature sets because the number of feature sets rises dramatically as their size increases. The important issue is finding good feature sets that can achieve desirable classification rates. Based on what we have seen, it is not unlikely that two studies using comparable technologies and classification procedures will arrive at equally performing feature sets possessing small intersection-or, for that matter, no intersection. Rather than perceive this as a negative, one should see it as a positive. Given the incertitude of feature selection and the imprecision of error estimation, it can be beneficial to have many close-to-optimal feature sets.
Let us close by citing two previous empirical studies that have come to similar conclusions. In one, the authors consider a specific breast-cancer data set and classification with regard to good and bad prognosis (Ein-Dor et al. 2005). Their approach is to rank genes based on their correlation with survival, take feature sets consisting of the first through eighth sets of 70 genes in the list, and to show that classifiers based on each of these feature sets perform essentially the same. In another, it was shown that using an exhaustive search finds large numbers of indistinguishably performing small feature sets (Grate, 2005). By taking a model-based approach we have characterized this phenomenon for linear classification in terms of the discriminant and the actual error, and shown how intra- and inter-group correlation effect the phenomenon.
Reviewing Editor: James Lyons-Weiler.