
Abstract
High-dimensional data generally refer to data in which the number of variables is larger than the sample size. Analyzing such datasets poses great challenges for classical statistical learning because the finite-sample performance of methods developed within classical statistical learning does not live up to classical asymptotic premises in which the sample size unboundedly grows for a fixed dimensionality of observations. Much work has been done in developing mathematical-statistical techniques for analyzing high-dimensional data. Despite remarkable progress in this field, many practitioners still utilize classical methods for analyzing such datasets. This state of affairs can be attributed, in part, to a lack of knowledge and, in part, to the ready-to-use computational and statistical software packages that are well developed for classical techniques. Moreover, many scientists working in a specific field of high-dimensional statistical learning are either not aware of other existing machineries in the field or are not willing to try them out. The primary goal in this work is to bring together various machineries of high-dimensional analysis, give an overview of the important results, and present the operating conditions upon which they are grounded. When appropriate, readers are referred to relevant review articles for more information on a specific subject.
Keywords
Introduction
Classical statistical techniques have been fashioned for situations in which the number of data points is much larger than the number of variables. 1 This is in large part due to the classical notion of statistical consistency, which guarantees the performance of a statistical technique in situations where the number of measurements unboundedly increases (n ↠ ∞) for a fixed dimensionality p of observations.2–5
However, even though many modern datasets are characterized by a number of variables far exceeding the sample size, many practitioners still utilize classical learning methods to extract information out of such datasets. This state of affairs can be attributed, in part, to a lack of knowledge and, in part, to the ready-to-use computational and statistical software packages that are well developed for classical techniques. Nonetheless, one may argue that the so-called curse of dimensionality phenomenon in statistical learning can serve as a justification for utilizing classical techniques, and no need exists to incorporate many variables in a model. This phenomenon states that, when one attempts to improve performance by increasing the number of variables for a given number of data points, the performance improves up to a certain point, after which it starts deteriorating. 6 This phenomenon seems a justification for reducing the number of variables (dimensionality reduction) to a small number, perhaps much less than the sample size. In this reduced feature space, we are then “safe” to apply classical schemes because now the sample size is potentially much larger than the number of variables. The effect of the curse of dimensionality and its implications will be described in more detail later.
Using classification as an archetype, the dimensionality reduction generally follows a common methodology: 1) use a classification rule, including a feature selection, to design a classifier, and 2) use an error estimation rule to estimate the error of the designed classifier. The performance of many widely used classifiers is guaranteed in situations where n » p. They are designed to converge (in probability) to the Bayes classifier (optimal classifier) if n ↠ ∞ and p is fixed. Likewise, the performance of many error estimation rules lives up to similar asymptotic premises. Therefore, the feature selection strategy serves as an interface in order to scale the complexity of data to one that can be studied through classical methods. Fortunately, two mathematical-statistical machineries exist that are specifically designed to serve in high-dimensional settings: 1) shrinkage, and 2) the Girko G-analysis. These frameworks can serve as potential machineries in order to develop mathematical models suitable for analysis in situations where in the dimensionality of observations is comparable or potentially larger than the sample size. While the shrinkage estimation is grounded on the sparsity principle, G-analysis, in its simplest form, is based on double asymptotics n ↠ ∞, p ↠ ∞, p/n ↠ c, 0 < c < ∞, as well as on some conditions on the existence of moments of random variables involved. 7 However, G-analysis makes no assumption on the sparsity of the parameters to be estimated. Note that having the last two conditions, that is, p ↠ ∞ and p/n ↠ c, implies first n ↠ ∞.
The sparsity principle imposes an assumption on the nature of the probabilistic structure of observations; it assumes that only a small number of predictors contribute to the response. 8 In other words, while the curse of dimensionality restricts the number of variables feeding a model (by a subset selection strategy), the sparsity principle, on the other hand, does not restrict the number of variables. Instead, a model is potentially trained on all variables, and it has a good performance if the parameter space is sparse. While the effect of parameter sparsity on the behavior of shrinkage estimation has been studied to some extent, the effect of the curse of dimensionality on G-analysis has been generally left unexplored. Understating the effect of the peaking phenomenon or the curse of dimensionality is important because, if it can be avoided, then we can see the G-analysis as a potential machinery to follow in situations where the parameter sparsity is not well justified. It might be argued that there is nothing wrong with the classical methodologies (which work well when n ↠ ∞ and p is fixed) because (in the context of classification) ultimately it is the error of the designed classifier that matters, and, if classical methodology does not work, then the price paid will be poor performance. This is a legitimate argument as long as the cost is negligible. Unfortunately, this is not always the case, as the next paragraph illustrates.
Let us consider genomic datasets as a prototypical example of a modern, high-dimensional, small-sample dataset. In 2005, Michiels et al. 9 challenged the validity and repeatability of several microarray-based research studies. They reported that a reanalysis of data from the seven largest published microarray-based studies, which attempted to predict the prognosis of cancer patients, revealed that five of those seven did not really classify patients better than a random assignment. There were other studies aimed at reproducing the published results of such prognosis studies, but they too generally failed. 10–12 The consequence of the failures in many genomic research studies has been brought into sharp focus by Dr. J. Woodcock, Director of the Center for Drug Evaluation and Research (CDER) at the U.S. Food and Drug Administration. She stated, “We may be out of the general skepticism phase, but we are in the long slog phase”. 13 In listing barriers to “coming up with the right diagnostics,” she estimated that 75% of published biomarker applications are not replicable: “This poses a huge challenge for industry in biomarker identification and diagnostics development”. 13 From a technical point of view, the irreproducibility crisis of the results that we are facing today14,15 can be attributed in large part to the nature or misuse of our classical statistical techniques.16,17 This state of affairs could have been preventable years ago if we took the following lines noted by Ronald A. Fisher, one of the first biologist-geneticist-statisticians, more seriously. In 1925, he said18,19:
Little experience is sufficient to show that the traditional machinery of statistical processes is wholly unsuited to the needs of practical research. Not only does it take a cannon to shoot a sparrow, but it misses the sparrow! The elaborate mechanism built on the theory of infinitely large samples is not accurate enough for simple laboratory data. Only by systematically tackling small sample problems on their metrics does it seem possible to apply accurate tests to practical data.
Sparsity and Shrinkage Estimation
Let x be a realization of a random vector of p dimension that is normally distributed with unknown mean θ and identity covariance matrix, ie,
In a seminal work,
20
Stein astonished the statistical community by showing that, if we consider the total squares of the errors as the loss function and p ≥ 3, then there exists a class of estimators of θ that uniformly has a smaller risk than that of the regular maximum likelihood estimator. In other words, the “usual estimator” θ
ML
(

This achievement led to a large body of work on many aspects of the problem, proposing estimators for situations in which the covariance matrix of the normal population is known or unknown, extending this estimation procedure to non-normal populations, the Bayesian justification of the James–Stein estimator, and various attempts to improve upon the James–Stein estimator. Here, it is not possible to summarize the large amount of work done in this direction. We describe some of the key developments in the field, but for more information the readers are referred to other works.24–28 The James–Stein estimator is given by
23

It turns out that δ
JS
is itself inadmissible and has a peculiar behavior for small values of |


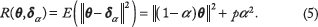
One can verify that the optimal choice of α that minimizes R(

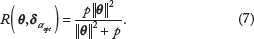
However, note that with the choice of α in (6), α

It is evident that, when
Similar to the James–Stein estimation, ridge estimation is a type of shrinkage originally proposed in
35
and developed further by many researchers. Consider the linear model


However, when p > n, the solution (10) does not exist because

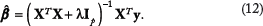
In this way, the inverse of possibly ill-conditioned

Here, λ determines a trade-off between the approximation error



Therefore, by minimizing the ℓ1 norm of coefficients, we are seeking for the sparsest possible solution. In the presence of noise, BP is used by solving a quadratically constrained linear program, which is a trade-off between a quadratic misfit and the ℓ1 norm of coefficients
51
:

Curse of Dimensionality and g-Analysis
Generalized consistent estimation (also known as Girko G-analysis) is a technique to construct estimators specific to situations in which the dimension is comparable to the number of samples. In this setting, an estimator is constructed such that it converges to the actual parameter in a “double-asymptotic” sense, to wit, in an asymptotic scenario in which dimension and sample size increase in a proportional manner, eg, n ↠ ∞, p ↠ ∞, and p/n ↠ c > 0. In this framework, the sparsity principle does not play a role. However, if the curse of dimensionality is intrinsic to frequentist statistics, then regardless of the model we use, there will still be a large gap between the complexity that we can capture through our model and the complexity of the phenomenon under study (if, of course, the phenomenon is complex per se). Therefore, in the subsequent discussion, we first examine the curse of dimensionality, its origin, and implications.
Curse of dimensionality
The curse of dimensionality, also known as the “peaking phenomenon” or the “Hughes phenomenon”, is generally considered as the known fact accounting for dimensionality reduction and feature selection.6,52,53 Regarding the peaking phenomenon, McLachlan stated 54 :
For training samples of finite size, the performance of a given discriminant rule in a frequentist framework does not keep on improving as the number p of feature variables is increased. Rather, its overall unconditional error rate will stop decreasing and start to increase asp is increased beyond a certain threshold, depending on the particular situation.
Jain and Waller stated 52 :
Thus, even if the cost of taking measurements is negligible, there exists an optimum measurement complexity, which is a function of the number of available training samples and the probability structure of the model.
Chandrasekaran and Jain pointed out:
It is known that, in general, the number of measurements in a pattern classification problem cannot be increased arbitrarily, when the class-conditional densities are not completely known and only a finite number of learning samples are available. Above a certain number of measurements, the performance starts deteriorating instead of improving steadily.
See Ref. 55 or p. 561 in Ref. 56 for more comments about this phenomenon. The first observation of peaking phenomenon is attributed to the work of Hughes. 53 However, the peaking observed by Hughes was shocking to many scientists since it was contrary to the previously reported results on the lack of peaking for Bayes (optimal) classifiers. Hughes noted, “If insufficient sample data are available to estimate the pattern probabilities accurately, then a Bayes recognizer is not necessarily optimal”.53,57 Various researchers correctly criticized Hughes’ work by pointing out that the paradoxial peaking phenomenon observed therein was not real and was due to the estimate of unknown cell probabilities from the data.57–60 In other words, the peaking phenomenon observed by Hughes was essentially within a frequentist framework, not a Bayesian.
Nevertheless, it is now the general consensus that in the frequentist framework, the performance of a constructed classifier does not keep improving as more features are added. To be more precise, it is assumed that there is a certain point after which we should not keep adding features because the expected error rate of the classifier starts to increase (see above quotes as well as Refs. 6 and 56). Commonly, this certain point is referred to as the “optimal number of features”.52,55 Nevertheless, all the aforementioned studies, and even terminologies such as curse of dimensionally or peaking phenomenon, give the impression that we should not learn from a large number of variables when a finite (and perhaps relatively small) number of samples is available.
Here, I shall try to convince you that the curse of dimensionally is not a phenomenon intrinsic to the frequentist framework. Instead, it is an artifact of many contemporary frequentist approaches. However, let us first review a few theoretical works that show peaking phenomenon in a frequentist setting.
In Ref. 6, the authors studied the peaking phenomenon in the context of discrete classification using a histogram rule. They considered multinomial distributions governing the data and characterized the expected error rate of the histogram rule over both sample space and a uniform prior distribution on the multinomial parameters. However, the complexity of the expression obtained there for the expected error rate did not let them achieve an analytical solution for the optimal dimension or analytical proof for the existence of a dimension at which the expected error rate is minimized.
Another work in this context is that of Jain and Waller,
52
who analytically studied the peaking phenomenon in connection with linear discriminant analysis (LDA) and in the context of Gaussian multivariate models. They used Bowker and Sitgreaves's61,62 approximation of the expected error of LDA to determine an expression for the minimal increase in


The salient point is that, even with the existing classifiers that have been developed through the classical statistical framework (n ↠ ∞, p fixed), the peaking phenomenon is not what is commonly perceived. To show this, in the following, we present an example in which even after the so-called optimal number of features has been found, we still keep adding features to the model. From earlier discussion, recall that the optimal number of features is generally considered as the number after which adding more features deteriorates the performance. However, in this example, we observe that after initial deterioration in the performance of the classifier, the performance again starts to improve after adding many features. Furthermore, we observe that even by considering all features in this example, the performance is still better than the performance at the so-called optimal point. Although these observations depend on the complexity of classifiers and the probabilistic structure of the problem, they demonstrate that learning from a large number of variables is plausible.
Consider a set of n = n0 + n1 independent and identically distributed (i.i.d.) training samples in Rp, where


That is, the sign of



Assuming n0 = n1 = n, α0 = α1 and σ = σ
2

Let
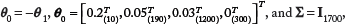
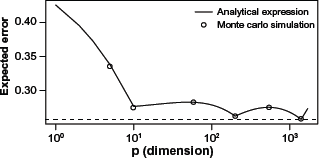
Expected error of Euclidean-distance classifier versus dimension for n0 = n1 = 100. The solid curve is obtained from theoretical results. The small circles are the result of simulation experiments for p = 10, 65, 200, 535, and 1,400.
The Monte Carlo simulation protocol.
Step I: Fix a of pair of p-dimensional Gaussian distribution πo and π1 with identity covariance matrices and means being the first p elements of vector θ0 and θ1 respectively. In simulations, we only consider p = 10, 65, 200, 535, and 1400.
Step II: From each distribution, generate a training set of size n = 100.
Step III: Using the training sample, construct EDC using (20) and (21).
Step IV: Find the true error of the constructed classifier using (22) and (24); this is possible because we have parameters of our model.
Step V: Repeat Steps II–-IV 500 times and take the average. The result is an estimate of E[∊ n,p ].
The result of the Monte Carlo simulation for the five dimensions that we have considered is depicted by small circles in Figure 1: they align well with the theoretical results represented by the curve. As we see in this figure, as soon as we start adding more than 10 features to the EDC model, the performance starts deteriorating, but if we keep adding more and more features, at about p = 65, the performance again starts to improve. At p = 200, it has a local minimum and this behavior repeats one more time, resulting in a multi-hump curve. Interestingly, by considering all 1,700 features in the classifier, we obtain a performance better than the first local minimum at p = 10; to wit, E[∊100,1700] = 0.273 < 0.276 = E[∊100,10. Nevertheless, the best performance happens when p = 1,400 (E[∊100,1400] = 0.254). Note that the EDC model is essentially a variant of the LDA classifier, which, under a Gaussian model, converges to the Bayes classifier as n ↠ ∞ and p fixed. It is natural to expect development of better classifiers from a mechanism such as the G-analysis framework, which is specifically designed for high-dimensional analysis. The conclusion to be drawn from this example is not to reject the peaking phenomenon – we can cite many examples that demonstrate that the peaking phenomenon is observed in the same way that is classically stated. Instead, this example demonstrates the following: 1) the way the curse of dimensionality is generally stated does not reflect what this phenomenon really is and may give a wrong impression to many practitioners, and 2) a compromise between complexity of the learning model and the number of predictors may achieve a better performance in a large-dimensional space than in a small one.
Double asymptotics and G-analysis
An example from random matrix theory
Random matrix theory (RMT) is a type of double-asymptotic analysis that is more focused on the analysis of spectral distribution of random matrices. The spectral distribution of random matrices is an important subject in multivariate analysis, as many statistics can be represented in terms of functionals of the spectral distribution of some matrices.
70
Let {xi,j, i,j = 1,2,…} be a double array of i.i.d. random variables with mean zero and variance 1. Let

The empirical spectral distribution (ESD) of matrix

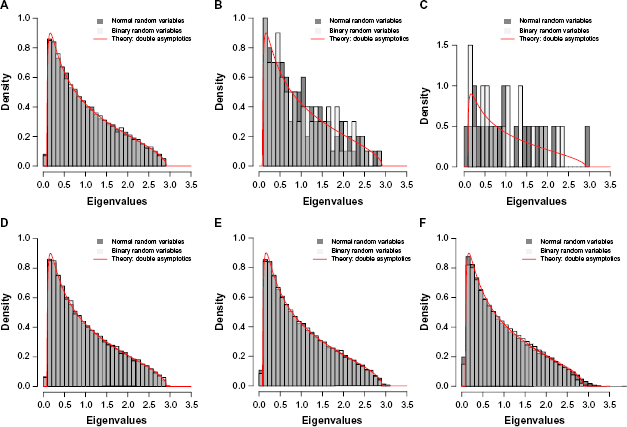
(A)–(C) Comparing the empirical spectral distribution of one realization of the covariance matrix with the limiting spectral distribution: (A) p = 1,000, n = 2,000; (B) p = 100, n = 200; (C) p = 20, n = 40. (D), (E) Comparing the average empirical spectral distribution of N realizations of the covariance matrix with the limiting spectral distribution: (D) p = 1,000, n = 2,000, and N = 10; (E) p = 100, n = 200, and N = 100; (F) p = 20, n = 40, and N = 10,000. Marčenko and Pastur 71 obtained the closed-form solution of the limiting spectral distribution by using the double-asymptotic framework.
Figure 2D–2F show the result of comparison between the average empirical spectral distribution of N realizations of covariance matrix
The convergence of histograms in Figure 2(D)–(F) to the same density shows another interesting property of this operating regime: if we consider the average (expected) behavior of the ESD, the result of double asymptotics, although theoretically valid for p ↠ ∞ and n ↠ ∞, agrees well with the empirical result even for situations in which p and n are relatively small (Fig. 2F). Note that in many practical situations we are interested in average behavior of a statistic and, in this regard, double asymptotics can serve as a potential machinery for analyzing and synthesizing statistics. It is illuminating to compare the result of double-asymptotic analysis with the classical asymptotic analysis. The only information that we have from the classical asymptotic analysis is that, as n ↠ ∞ and for fixed p, the distribution of λi(
Emergence of double-asymptotic analysis
In the past few decades, double-asymptotic analysis, in general, and RMT, in particular, have found eminent roles in various disciplines, including nuclear physics, statistical mechanics, signal processing, wireless communications, biology, and economics.70,72 Some scientists, such as Raj Nadakuditi, 73 believe that RMT is “somehow buried deep in the heart of nature”. The first account of double-asymptotic analysis can be traced back to studying the limiting spectral distribution of random matrices of large dimension. This analysis was done by Eugene P. Wigner, the Nobel Prize winning physicist who, in the context of quantum physics and in connection with the energy levels of heavy nuclei, proved that the expected spectral distribution of Wigner matrices of increasing dimension converges to the semicircle law.74–76 In quantum physics, any measurable physical quantity (a dynamical variable) of a system is represented by a self-adjoint operator (commonly referred to as the Hamiltonian) that acts in the state space. The Hamiltonian operator acting in state space can be represented in the matrix representation, resulting in matrix mechanics – which Heisenberg used to formulate quantum mechanics in the first place.77,78 Concerning the rise of RMT in physics, Freeman Dyson writes 79 :
By assuming all states of a very large ensemble to be equally probable, one obtains useful information about the overall behavior of a complex system, when the observation of the state of the system in all its detail is impossible. What is here required is a new kind of statistical mechanics, in which we renounce exact knowledge not of the state of a system but of the nature of the system itself. We picture a complex nucleus as a ‘black box’ in which a large number of particles are interacting according to unknown laws. The problem then is to define in a mathematically precise way an ensemble of systems in which all possible laws of interaction are equally probable.
And concerning the randomness of the Hamiltonian that appears in Schrödinger's equation, Mehta writes, 80
In the case of the nucleus, however, there are two difficulties. First, we do not know the Hamiltonian and, second, even if we did, it would be far too complicated to attempt to solve the corresponding equation. Therefore, from the very beginning we shall be making statistical hypotheses on
Here Mehta eloquently describes the reason why pioneers such as Wigner and Dyson associated the randomness of the Hamiltonian and, consequently, its corresponding matrix representation with the complexity of the nucleus (see Ref. 79 for more details). Beside the curse of dimensionality that we discussed earlier, the principle of parsimony is another motivation for an immediate use of dimensionality reduction regardless of the complexity of the phenomenon under study. While the principle of parsimony tells us that a simpler model is preferable to a competing complex model, it does not tell that all phenomena are simple. While the sparsity of parameters describing a phenomenon seems a tempting idea, not all phenomena are sparse. A heavy nucleus is a perfect example of a complex system. What Wigner did was not to create a parsimonious model to describe such a system. Instead, in his groundbreaking work, he increased the complexity of model to infinity by considering random matrices of infinite dimension.74,75 As described in Ref. 81, the Bayesian philosophy dominated the statistics in the nineteenth century, but twentieth century was more a frequentist one. I believe that after the long 250-year-old debate between Bayesians and frequentists, if there is a revolution in statistical learning community (if not yet), it happens in shifting the low-dimensional analytical paradigm to a high-dimensional one (see the R.A. Fisher's quote in the introduction).
In the last 60 years, there have been an enormous number of studies in the context of random matrices of increasing dimension. The field has been developed to a large extent in the hands of F. J. Dyson,79,82,83 M. L. Mehta,84–87 L. A. Pastur,71,88,89 V. L. Girko, J. W. Silverstein,93–96 Z. D. Bai,97–100 and Y. Q, Yin.101–104 As estimated in Ref. 70, there has been more than 2,500 publications in the field from 1955 to 2004. The readers are encouraged to consult70,72,80 for historical surveys of some of important results in the field.
A set of independent, but closely related work to previous studies, is the work of Raudys, Deev, Meshalkin, Serdobolskii, and Fujikoshi on the application of double asymptotics in classification.105–112 This body of work is formalized as follows: consider a sequence of Gaussian discrimination problems with a sequence of parameters and sample sizes:
G-analysis
Regarding the general statistical analysis of observation (G-analysis) and its connection to G-estimation and the Kolmogorov asymptotic conditions, V. L. Girko, one of the pioneers in developing this theory, writes:
The general statistical analysis of observations (G-analysis) is a mathematical theory studying some complex system S, such that the number mn of parameters of its mathematical models can increase together with the growth of the number n of observations of the system S. The use of this theory consists in finding, with the help of observations of the system S, mathematical models (G-estimators) that approach the system S in some sense with a given rate under general assumptions on the observations: the existence of the distribution densities of the observed random vectors and matrices are not needed. The existence of several first moments of their components is all that is required; in addition, the numbers mn and n satisfy the G-condition:

The notation
In recent years, several research groups, predominantly in signal processing community, have utilized the idea of G-analysis in various settings. For example, Mestre and Lagunas derived the generalized consistent estimator of the optimum loading factor in spatial filtering. 2 In Ref. 3, Rubio and Mestre used the G-analysis to first evaluate the performance of a global minimum variance portfolio (GMVP) implementation based on shrinkage covariance matrix estimation and weighted sampling. Then they used the G-analysis to characterize the limiting expression of the realized variance and, based on that, they achieved a generalized consistent estimator of out-of-sample portfolio variance. 3 In Ref. 121, the authors developed an estimator of the optimal linear filter for both multiantenna array signals and financial asset returns. In Ref. 5, we utilized the G-analysis to calibrate a traditional estimator of the true error of the regularized LDA. This classical estimator, known as the plug-in estimator, is consistent under n ↠ ∞ and fixed p regime with a poor performance in small-sample situations. We observe that the calibrated new estimator can outperform not only the plug-in estimator but also other estimators of the true error, including Bootstrap 0.632 and cross-validation, in many situations in terms of bias and root-mean-square (RMS) error. Some other applications of G-analysis include estimating the eigenvalues and eigenvectors of sample covariance matrix 122 and estimating the direction of arrival (DoA) in linear sensor arrays. 123
Extending G-analysis to Bayesian settings
In Ref. 124, we characterized the moments of a Bayesian minimum mean-square error (MMSE) error estimator,


This limit is defined for a situation in which there is a conditioning on a specific value of feature label distribution parameters such as μ
p,i
. Therefore, in this case μ
p,i
is not a random variable, and for each p, it is a vector of constants. Absent such conditioning, the sequence of discrimination problems and the above limit reduce to
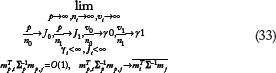
Discussion
In recent years, various statistical learning rules have been put forward for cancer diagnosis, prognosis, discriminating stages of cancer, types of pathology, and duration of survivability based on molecular profiles such as gene or protein expression patterns and single nucleotide polymorphism genotypes. Such a biomarker discovery process in high-throughput genomic and proteomic profiles has presented the statistical learning community with a challenging problem, namely how to learn from a large number of variables and a relatively small sample size. The properties of high-dimensional data, though, are not well understood. 127 A high-dimensional setting is not the place to rely on intuition, nonrigorous propositions, and heuristics. At the same time, the classical notion of statistical consistency, which guarantees the performance of many classical statistical techniques, falters because this notion guarantees the performance of a technique in situations where the number of measurements unboundedly increases (n ↠ ∞) for a fixed dimensionality of observations, p. In a finite sample operating regime, this implies that in order to expect an acceptable performance from a statistical technique, we need to have many more sample points than variables – a scenario opposite to what we currently face in high-throughput biology. Despite many achievements in the last few decades in the field of statistical learning, some of the most elementary problems remain unsolved. In this regard, Serdobolskii stated 68 :
It is difficult to describe the recent state of affairs in applied multivariate methods as satisfactory. Unimprovable (dominating) statistical procedures are still unknown except for a few specific cases. The simplest problem of estimating the mean vector with minimum quadratic risk is unsolved, even for normal distributions. Commonly used standard linear multivariate procedures based on the inversion of sample covariance matrices can lead to unstable results or provide no solution in dependence of data. Thus nearly all conventional linear methods of multivariate statistics prove to be unreliable or even not applicable to high-dimensional data.
Two mathematical-statistical machineries, discussed herein, show promising results in constructing techniques of high-dimensional data analysis: 1) shrinkage, and 2) Girko G-analysis. This paper presented a brief history of development, the underlying assumptions, and some of important results of each machinery. While in the last decade there has been some effort to create statistical software packages from some of the shrinkage methods, the methods developed through G-analysis remain mostly in the literature and unknown to many theoreticians and practitioners. Some effort from applied statistics and the signal processing community seems worthwhile in order to create ready-to-use software packages from these methods. In addition, practical implications of the underlying assumptions in G-analysis need further investigation. For example, we assumed n ↠ infin;, p ↠ infin;, p/n ↠ c, 0 c < ∞ along with some conditions on the existence of moments of random variables involved. In an asymptotic sense, the results are applicable to any ratio of p/n. However, in a finite-sample regime, it would be interesting to study the robustness of designed methods with respect to this ratio. Other natural directions that deserve further research in this line of work are 1) understanding the true nature of the so-called curse of dimensionality phenomenon, 2) the connection between G-analysis conditions and the curse of dimensionality, 3) the possibility of using G-analysis in creating lasso-like operators that have the capability of performing model selection, and 4) extending G-analysis to Bayesian statistics.
Author Contributions
Conceived the concepts: AZ. Wrote the first draft of the manuscript: AZ. Developed the structure and arguments for the paper: AZ. Made critical revisions: AZ. The author reviewed and approved of the final manuscript.