
Abstract
A computational approach for estimating the overall, population, and individual cancer hazard rates was developed. The population rates characterize a risk of getting cancer of a specific site/type, occurring within an age-specific group of individuals from a specified population during a distinct time period. The individual rates characterize an analogous risk but only for the individuals susceptible to cancer. The approach uses a novel regularization and anchoring technique to solve an identifiability problem that occurs while determining the age, period, and cohort (APC) effects. These effects are used to estimate the overall rate, and to estimate the population and individual cancer hazard rates. To estimate the APC effects, as well as the population and individual rates, a new web-based computing tool, called the
Introduction
The concept of the population cancer hazard rates in aging is tightly connected with the concept of the age-specific incidence rates that are characterized by a number of new cancers of a specific site/type, occurring within an age-specific group of individuals from a specified population during a distinct time period.1–6 The population hazard rates in aging, which we will call the population hazard rates (or just population rates), are determined by a correction of the age-specific incidence rates on the age, period, and cohort (APC) effects (see Refs. 5–7 and below).
Recently, 5 a novel concept, the individual hazard rates in aging (shortly, individual rates), was introduced. This concept assumes that only a small fraction (pool) of individuals in the population is susceptible to cancer, while the rest of the population (a large fraction) is resistant to cancer. The individual rates characterize the risk of getting cancer for the age-specific group of individuals who are susceptible to cancer and will get cancer in their lifetime.
The main obstacle to the wide use of the population and individual rates in cancer research is the absence of a simple computational approach and a freely available computerized tool for their estimation. The present work is aimed at filling this gap.
The APC effects are more typical for adult rather than for childhood cancers. This is because the occurrence of adult cancers is often associated with lifestyle and environmental risk factors, while the occurrence of childhood cancers is often linked to genetic abnormalities. Since the adult cancers are usually diagnosed at the ages of 20 and older, analysis of the occurrence of these cancers is performed using cancer-related data on people in that age group.
In cancer epidemiology, the APC effects are often estimated in the frame of the log-linear age–period–cohort (LLAPC) model. While using this model, however, the identifiability problem arises. To solve this problem, the use of additional assumptions or specific estimable functions is needed (see Refs. 8–13 and references therein). Recently, in Ref. 9, a novel estimable function, called the fitted age-at-onset curve, was introduced and used to develop the
In the present work, we expanded the traditional approach,11–13 in which (within a set of the unknown parameters required for estimating the APC effects) four redundant parameters are equated to zero. In our approach, we set only three parameters to zero and determined an optimal value of the fourth parameter by an assumption that the effects of the adjacent cohorts are close. 7 To the best of our knowledge, this is the mildest assumption used so far to solve the APC problem.
Based on the approach 7 and using a simple regularization and anchoring technique, we developed a novel computational framework to estimate the APC effects, the population and individual hazard rates of cancer development in aging, and the overall cumulative hazard rate (or shortly the overall rate). In this framework, the population hazard rates are estimated by correcting the observed age-specific incidence rates of cancer on the APC effects. After that, the overall rate and the individual rates are determined.
The proposed computational framework was implemented in a new, stand-alone web tool, called
The performance of
Materials and Methods
Mathematical Methods.
Age-Specific Incidence Rates.
The age-specific incidence rates can be determined as a ratio of the number of cancer cases,
APC Analysis.
In the frame of the LLAPC model, the APC analysis is performed using the following system of conditional equations:

In the system (1):
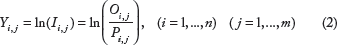
In the model used, 
The problem is to determine from the system of the
The system (1) cannot be solved directly by methods of multiple linear regressions. This is because the design matrix of the system (1) is rank deficient because of a linear interrelation of the APC effects. Consequently, the APC effects cannot be uniquely and simultaneously estimated (multiple estimators of these effects provide similar solutions). In this work, to solve this identifiability problem, we used the heuristic approach proposed in Ref. 7. We implemented this approach in the computational framework, which we used for developing the
Data Preparation.
The
Obtaining Data for the Case Matrix.
Initially, from the database, 14 we selected and saved a column with 19 numbers of histologically confirmed female lung cancers, diagnosed during the 1975–1979 time period in 19 age intervals (0, 1–4, 5–9, …; 80–84, and 85+). Then, we extended this column by splitting the number of cases in the 85+ age interval into the number of the female lung cancers in the 85–89, 90–94, 95–99, and 100+ age intervals. To do this, we determined a number of the cancers in the 85–89, 90–94, 95–99, and 100+ age intervals. Thus, we obtained a column with the numbers of the histologically confirmed female lung cancers diagnosed in 22 age intervals (0, 1–4, 5–9, 95–99, and 100+ years) during the 1975–1979 time period. Analogously, we determined columns with 22 numbers of the female lung cancers diagnosed during the 1980–1984, …, 2005–2009 time periods.
Overall, we obtained seven columns with 22 numbers of the histologically confirmed female cancers diagnosed in 22 age intervals (0, 1–4, 5–9, …, 95–99, and 100+) and in seven time periods (1975–1979, …, 2005–2009). Then, we concatenated (joined) these seven columns into one 22 × 7 matrix. Finally, we omitted six age intervals (0, 1–4, 5–9, 10–14, 15–19, and 100+) in which the numbers of lung cancers were small (less than 10). Thus, we truncated the 22 × 7 matrix to the 16 × 7 matrix, presenting the number of the female lung cancers diagnosed in 16 age intervals (20–24, …, 95–99) in seven time periods (1975–1979, …, 2005–2009). This truncated matrix was used for testing the
Obtaining Data for the Population Matrix.
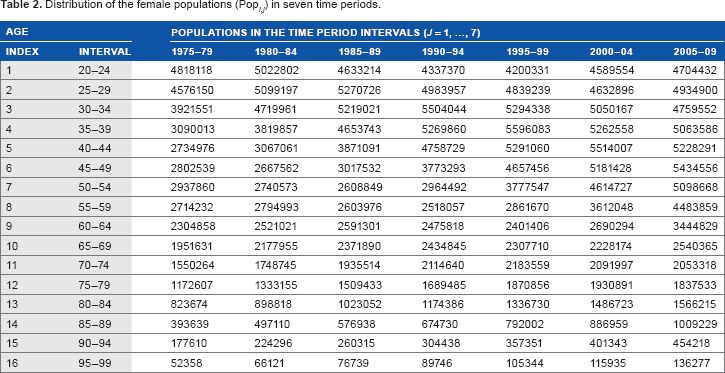
Using the database, 15 we created columns with 19 numbers showing the female populations in 19 age intervals (0, 1–4, 5–9, …, 80–84, and 85+ years) in the 1975–1979 time period. We also created analogous columns showing the female populations in the 1980–1984, 1985–1989, 1990–1994, and 1995–1999 time periods. Using the database, 16 we created columns showing the female populations in 22 age intervals (0, 1–4, 5–9, …, 95–99, and 100+ years) in the 2000–2004 and the 2005–2009 time periods.
To estimate the sizes of the female populations in the 85–89, 90–94, 95–99, and 100+ age intervals in the first five time periods considered (ie, 1975–1979, …, 1995–1999), we proportionally split the sizes of the female populations in the 85+ age interval based on the female populations in the 85–89, 90–94, 95–99, and 100+ age intervals. The proportions were estimated from the female populations observed within 2000–2009 in the 85–89, 90–94, 95–99, and 100+ age intervals. Thus, for all seven time periods, we obtained seven columns with the female populations in 22 age intervals (0, 1–4, 5–9, …, 95–99, and 100+).
Finally, we concatenated the obtained columns into one 22 × 7 matrix. This matrix presents the female populations in 22 age intervals (0–4, 5–9, …, 95–99, 100+) for the consecutive seven five-year time periods (1975–1979, 1980–1984, 1985–1989, 1990–1994, 1995–1999, 2000–2004, and 2005–2009). Finally, by omitting the female populations in six age intervals (0, 1–4, 5–9, 10–14, 15–19, and 100+), we truncated the obtained 22 × 7 population matrix to the 16 × 7 matrix. This was done to have the same dimensions for the case and population matrices.
Results and Discussion
Computational Framework.
We developed a three-step computational framework to estimate the population and individual hazard rates. In the first step, the APC effects and the intercept were estimated. In the second step, using these estimates, the population hazard rates were determined. Finally, in the third step, from the determined population hazard rates, the individual hazard rates were estimated. A more detailed description of this framework is presented below.
One way, which we called manual anchoring, is in using the appropriate, up-front given integer numbers as the
The other way, which we called an automatic anchoring, is to algorithmically determine the
By setting 

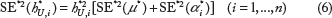
Web-Based Computing Tool, CancerHazard@Age .
The proposed computational framework was incorporated into a computing tool, called the

Screen shot of the input page. The page shows values of the input data described in Section utility of the

Screen shot of the output page. Additional graphs and tables are displayed when the corresponding check boxes are checked.
Input Data.
To work with the
Distribution of the female lung cancers (

Distribution of the female populations (Pop
Output Data.
The
Utility of the CancerHazard@Age .
To demonstrate the utility of the
Using these input data and the uploaded files, the
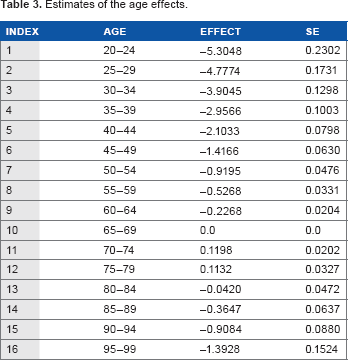
Estimates of the age effects.
Estimates of the period effects.
Estimates of the cohort effects.

Estimates of the population rates.

Estimates of the individual rates.

For the female lung cancers, Figure 3 shows how the age (A) effects depend on the age at diagnosis. The values of these effects and their SE are presented in Table 3. Figure 3 and Table 3 show that up to the age of 70, the age effects increase with the increase in the age at diagnosis, reach the maximum at the age interval of 70–74, and fall at older ages.

Female lung cancer occurrence: age effects vs. age at diagnosis. Filled circles present the age (A) effects for mid-points (mid-age) of the age intervals at which the cancer diagnosis was performed. Bars show the 95% confidence intervals (CIs) of the A effects. The solid line shows the trend of the A effects. The triangle presents the anchored A effect.
Figure 4 shows how the period (P) effects depend on the period of diagnosis. The values of these effects and their SE are presented in Table 4. As can be seen from Figure 4 and Table 4, the trend of the P effects continuously increases when the period (date) of the cancer diagnosis increases.

Female lung cancer occurrence: time-period effects vs. time period of diagnosis. Filled circles present the time-period (P) effects for the mid-points (mid-dates, in years) of the corresponding time-period intervals within which the cancer diagnosis was performed. Bars show the 95% CI of the P effects. The solid line shows the trend of the P effects. The triangle presents the anchored P effect. The diamond presents the identification parameter.
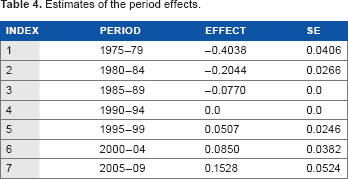
Figure 5 shows the birth cohort (C) effects vs. the year of the cohort birth. The values of these effects and their SE are presented in Table 5. A mid-year birth of the cohort considered at the date of diagnosis is considered as the year of the cohort birth. Figure 5 and Table 5 show that the trend of the C effects, referred to by 1880, 1985, …, and 1920, increases with an increase in the mid-year of the cohort birth; reaches a maximum for the cohort referred to by 1925; falls for the cohorts referred to by 1930, 1935, …, 1960; and almost flattens for the cohorts referred to by 1965, 1970, …, 1985.
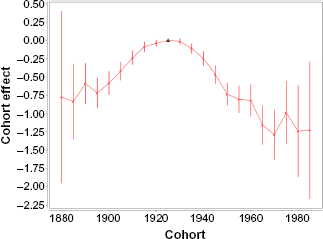
Female lung cancer occurrence: birth cohort effects vs. year of the cohort birth. Filled circles present the birth cohort (C) effects for the mid-year of the cohort birth. Bars show the 95% CI of the C effects. The solid line shows the trend of the C effects. The triangle shows the anchored C effect.
Figure 6 shows the population rates vs. age at diagnosis. The estimates of these rates and their SE are presented in Table 6. These estimates are given in units of the number of cancer cases per 100,000 person-years. Figure 6 and Table 6 suggest that the trend of the population rates increases up to the age of 70, reaches a maximum at the 70–74 age interval, and falls at older ages.

Female lung cancer occurrence: population hazard rates vs. age at diagnosis. Filled circles present the population hazard rates for the mid-points of the age intervals at which the cancer diagnosis was performed. Bars show the 95% CI of the population hazard rates. The rates and their CI are given in units of the number of cancer cases per 100,000 person-years. The solid line shows the trend of the population hazard rates. The triangle presents the anchored population hazard rate.
Figure 7 shows the individual rates vs. age at diagnosis. The estimates of these rates and their standard errors are presented in Table 7. These estimates are given in units of the number of cancer cases per 100,000 person-years. (It should be noted that the point presenting the individual rates in the 95–99 age interval is not shown in Figure 7. The individual rates are inaccurately estimated in that age interval because of the fact that a very small number of women susceptible to lung cancer are alive at the ages of 95 and older.) Figure 7 and Table 7 suggest that the trend of the individual rates increases, with an increase in the age at diagnosis.
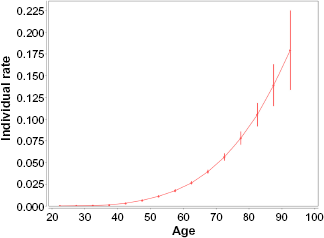
Female lung cancer occurrence: individual hazard rates vs. age at diagnosis. Filled circles present the individual hazard rates for mid-points of the age intervals at which the cancer diagnosis was performed. Bars show the 95% CI of the individual hazard rates. The rates and their CI are given in units of the number of cancer cases per 100,000 person-years. The solid line shows the trend of the individual hazard rates.
Main Distinguishable Features of the CancerHazard@Age .
Conceptually, the
The
The population and individual cancer hazard rates can be further analyzed by methods of statistical modeling (such as proportional hazards, confounding factors, interaction, and effect modification). The overall cancer hazard rate and the population and individual cancer hazard rates determined by the
Author Contributions
Conceived and designed the experiments: TM, AS, OS, SS. Analyzed the data: TM, AS, OS, SS. Wrote the first draft of the manuscript: TM, SS. Contributed to the writing of the manuscript: TM, AS, OS, SS. Agree with manuscript results and conclusions: TM, AS, OS, SS. Jointly developed the structure and arguments for the paper: TM, AS, OS, SS. Made critical revisions and approved final version: SS. All authors reviewed and approved of the final manuscript.