
Abstract
In the frame of the Cox proportional hazard (PH) model, a novel two-step procedure for estimating age-period-cohort (APC) effects on the hazard function of death from cancer was developed. In the first step, the procedure estimates the influence of joint APC effects on the hazard function, using Cox PH regression procedures from a standard software package. In the second step, the coefficients for age at diagnosis, time period and birth cohort effects are estimated. To solve the identifiability problem that arises in estimating these coefficients, an assumption that neighboring birth cohorts almost equally affect the hazard function was utilized. Using an anchoring technique, simple procedures for obtaining estimates of interrelated age at diagnosis, time period and birth cohort effect coefficients were developed.
As a proof-of-concept these procedures were used to analyze survival data, collected in the SEER database, on white men and women diagnosed with LC in 1975–1999 and the age at diagnosis, time period and birth cohort effect coefficients were estimated. The PH assumption was evaluated by a graphical approach using log-log plots. Analysis of trends of these coefficients suggests that the hazard of death from LC for a given time from cancer diagnosis: (i) decreases between 1975 and 1999; (ii) increases with increasing the age at diagnosis; and (iii) depends upon birth cohort effects.
The proposed computing procedure can be used for estimating joint APC effects, as well as interrelated age at diagnosis, time period and birth cohort effects in survival analysis of different types of cancer.
Introduction
In cancer epidemiology, survival and hazard functions are valuable characteristics of severity for a given type of cancer. By analyzing temporal trends of these functions, clinicians can evaluate their achievements in cancer diagnosis and treatment. This analysis can also help researchers develop novel approaches and strategies for fighting cancer.
The survival function, S(τ), is the probability for a cancer patient to stay alive longer than a specified time, τ, after cancer diagnosis. This function is related to the hazard function, h(τ), that determines the instantaneous risk (hazard) of death from the cancer at time, τ, given that the patient has survived up to this time:

where
For each cancer type, these functions, along with the most common risk factors, such as gender, race, geographical areas of living, etc., also depend on age at diagnosis (ages at which patients were diagnosed with cancer), time period (calendar years when patients were diagnosed with cancer) and birth cohort (calendar years when cancer patients were born) effects.
Traditionally, survival functions have been evaluated from cohort-based follow-up observations by monitoring cancer patient survival in clinical-based registries. To analyze survival data, a single variable Kaplan-Meier method has been widely used. 3 The survival functions obtained from these observations adequately describe survival data on cancer cases diagnosed many years ago. Data collected more recently have lower impact on evaluation of survival functions.
To overcome this shortcoming, the period analysis approach and its modification (called period analysis modeling technique) were introduced.4–8 The latter technique assumes the existence of a linear trend for the conditional survival estimates within the 5–year periods used for modeling. A period of five calendar years was chosen to optimize the most up-to-date and precise estimation of cancer survival function. Compared to traditional cohort-based approaches, the period analysis modeling technique allows one to derive more up-to-date and more precise estimates of survival function for cancer patients. However, the period analysis approach does not consider birth cohort effects.
A multivariate Cox regression approach in the frame of the proportional hazard (PH) model was used to assess the comparative risks or hazard functions of death from cancer. 9 The PH model assumes that values of the hazard function are proportionally dependent upon the risk factors. A graphical approach using log-log plots was utilized to evaluate the PH assumption. A multivariate Cox regression approach was applied to estimate differences in hazards by histological types of pancreatic cancer. Along with other variables, such as gender, race, histological type, surgery status and cancer stage, age at diagnosis and time period effects were considered, while cohort effects were ignored. As we show below, in the frame of the PH model, age at diagnosis, time period and birth cohort effects are interrelated. To date, there is no numerical method for simultaneous estimation of these interrelated effects.
In this paper we are proposing to extend the Cox PH model and apply it for estimation of the interrelated age-period-cohort effects on cancer survival. It should be noted that this model can be utilized if the parallelism of log-log survival curves is present. In contrast to the single variable Kaplan-Meier approach that accounts only for time to event (survival) data, a multivariate Cox regression approach accounts for many confounding variables, as well as for censored data. In cancer research, the Cox PH model has been widely used for the analysis of data collected in nested case-control, case-cohort, and cohort studies, as well as in clinical trials. However, to our best knowledge, this approach was not used for analysis of data from population-based studies to estimate the interrelated age-period-cohort (APC) effects on cancer survival. The main reason for that is an identifiability problem with multiple estimators that arises in estimating these effects. In this paper we introduce a simple, computationally effective method to solve this identifiability problem. The proposed solution of this problem is analogous to one that we recently utilized for accounting APC effects on cancer incidence rates.10,11
As a proof-of-concept, the proposed approach was utilized to analyze the SEER data on lung cancer (LC) survival in white men and women. The validity of the PH assumption for analyzing this data was initially checked by assessing the parallelism of log-log survival curves. The proposed approach allowed us to estimate numerically the interrelated age at diagnosis, time period and birth cohort effects on survival and hazard functions of LC in white men and women.
Methodology
Generally, APC analysis refers to a family of statistical techniques for understanding temporal trends of an outcome under consideration (such as cancer incidence or mortality rates, hazard function of death from cancer, etc.). The purpose of this analysis is to determine separate contributions of age, time period of observations, and birth cohort to this outcome. 12 This kind of analysis, along with other data, can also be performed with the use of cancer follow-up survival data collected over a long period of time from large population-based cancer registries (such as, for instance, the Surveillance, Epidemiology, and End Results (SEER) Program). 13
Statement of the problem
Let us assume that for each patient with a particular type of cancer, there is information on age at diagnosis, date of diagnosis, date of birth, as well as follow-up data on death from the cancer at time, τ, given that the patient has survived up to this time and the right censorship is presented by a dichotomous value (0 or 1). We can group the data by their belonging to the categorical intervals noted by the i, j and l indexes, where index i (i = 1,2, …, n) denotes successive age at diagnosis intervals, index j (j = 1,2, …, m) denotes successive time period intervals, and index l(l = 1,2, …, k) denotes successive birth cohort intervals. Let us denote the corresponding hazard functions for cancer patients with (i,j,l) grouped data by h i,j,l (τ). This function, along with τ, also depends on the i,j, and l indexes, which are related by the following linear relationship:

This relationship directly follows from the fact that if an event occurs to an individual of age a in year p then a particular cohort c = p - a must be involved. 12
To determine the separate contributions of age, period, and cohort effects to the h i,j,l (τ) function let us use the PH model, which is widely utilized in cancer survival analysis.1,2 In the frame of this model, the h i,j,l (τ) function proportionally depends upon age at diagnosis (w i ), time period (v j ) and birth cohort effect coefficients (u l ), as well as on the baseline hazard function (h0(τ)) the following way:

Now, the APC analysis problem is to estimate the w i , v j , and u l coefficients and the h0(τ) function, using the patient's survival time data, τ, grouped by the i, j and l indexes. These survival time data also contain information for right censorship presented by dichotomous values (0 or 1). Since the i, j and l indexes are connected by linear relationship (2), values of these coefficients are interrelated and the estimation of these coefficients is an identifiability problem with multiple estimators. 14 It means that there are many solutions to this problem that equally satisfy the observed survival time data and this problem needs to be transferred into the problem that has a single solution. This is the main difficulty in solving this problem. To the best of our knowledge in survival studies, the identifiability problem of APC analysis stated in such a way has not been solved yet.
Computational procedure for solving the problem
Below, we introduce a simple, computationally effective two-step procedure to solve the aforementioned identifiability problem. In the first step, it estimates the influence of joint APC effects on the hazard function, using a Cox PH approach. In the second step, the coefficients for age at diagnosis, time period and birth cohort effects are estimated. To solve the identifiability problem in estimating these coefficients, an additional assumption that neighboring birth cohorts almost equally affect the hazard function is utilized. The proposed procedure uses the same assumption that we have effectively used for accounting APC effects on cancer incidence rates.10,11 Using an anchoring technique, simple algorithms for obtaining estimates of interrelated age at diagnosis, time period and birth cohort effect coefficients are developed and coded into a computer program. A detailed explanation of this two-step procedure is presented below.
Step 1. Determination of joint age-period-cohort effect coefficients
Let us present (3) in the following way:

where a i,j,l designates the product of w i v j u l and h0(τ). Since l = j - i + n, grouping by three indexes i, j, and l can be reduced to the grouping by two indexes, i and j, and the system (4) can be presented as:
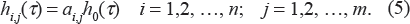
Now, using system (5) with observed survival data, one can assess each a
i,j
and its standard error (SE), as well as h0(τ). For this purpose, the Cox PH regression approach that uses maximum likelihood estimates can be utilized. The
Note: The Cox PH model, that is a particular case of the PH model, is usually written in terms of an exponential expression:

where parameters to be estimated are lna i,j . This exponential form of the expression (6) provides non-negative estimates of a i,j . 1
Step 2. Determination of coefficients for interrelated age at diagnosis, time period and birth cohort effects
The estimates
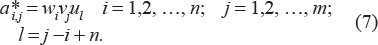
These sets are: (i) estimates for the age at diagnosis coefficients
To solve the identifiability problem in APC analysis it is necessary to make additional assumptions.12,15–18 For such an assumption, we hypothesize that the neighboring birth cohorts almost equally affect the cancer survival data. The rationale for this assumption is that, in practice, the adjacent cohorts are overlapping in time intervals and thus the values of the corresponding cohort effects should be close. 14 Based on this assumption, we proposed a novel computing procedure for numerical estimation of interrelated age at diagnosis, time period and birth cohort coefficients on cancer survival and hazard functions.
Estimation of age at diagnosis effect coefficients
Let us consider the i × j matrix with

and

Note: (8) provides (n - 1) × m conditional equations for assessing n - 1 ratios of time period coefficients
Assuming that any pair of the neighboring cohorts has a cohort effect coefficient ratio close to 1, the following pair of systems can be obtained:

and

When coefficients of variation of estimates

and
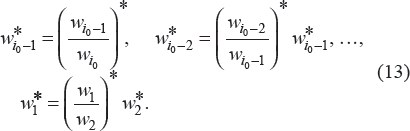
Note 1: Index i0 is defined from the corresponding index of the anchored coefficient
Note 2: Analogous to our previous works for the APC analysis of cancer incidence rates,10,11 one can show that errors of the estimates
Estimation of time period effect coefficients
By dividing the corresponding elements of the neighboring columns (with indexes j and j + 1 or j + 1 and j) of the i × j matrix with
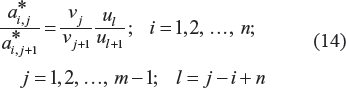
and

Note: (14) provides n × (m – 1) conditional equations for assessing m – 1 ratios of time period coefficients

and

When coefficients of variation of estimates
After anchoring the age at diagnosis coefficient at index j0, assuming

and
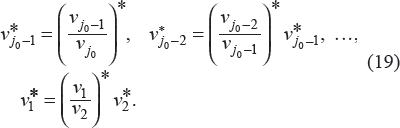
The SE of
Note 1: Index j0 is defined by the anchored coefficient
Note 2: The preceding method for estimation of time period effect coefficients is similar to the method for estimation of age at diagnosis effect coefficients. In the first case, the conditional equations are derived dividing the corresponding elements of the neighboring rows of i × j matrix with
Estimation of birth cohort effect coefficients
One way to assess u
l
is as follows. After evaluating the time period effect coefficients,

and
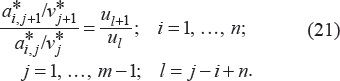
By the standard rules of error propagation, one can obtain SEs of the ratios of the corrected coefficients
By setting

and

Note: Index l0, for anchoring the birth cohort coefficient is simply derived as: l0 = j0 – i0 + n. The SE of
Additional details of the proposed procedure are discussed below on the example of analysis of lung cancer (LC) survival data collected in the SEER database.
Potential limitations
The proposed extension of the Cox PH model has several potential limitations. First, this model can be utilized only if the parallelism of log-log survival curves is present. However, the problem of visual evaluation of the parallelism by graphical approaches is to decide “how parallel is parallel?” For a given data set, this decision can be quite subjective. Therefore, we utilized the recommendation of a conservative strategy proposed by Kleinbaum and Klein 1 suggesting that the PH assumption is satisfied if there is not strong evidence for the non-parallelism of considered log-log survival curves.
Second, to solve the identifiability problem, the proposed approach uses an assumption that neighboring birth cohorts almost equally affect the cancer survival data. Therefore, after estimating the birth cohort coefficients and their SEs, the validity of this assumption needs to be verified. If the obtained estimates of some neighboring birth cohort coefficients are statistically different (i.e. validity of this assumption will not be proved by obtained results of calculations), the results cannot be fully justifiable.
It could also be argued that the requirement for categorizing the age at diagnosis, time-period, and birth cohort by equally-sized time intervals reduces areas of possible application of the proposed procedure. By admitting this limitation, we suggest that in practice, the quantitative estimation of the age at diagnosis, time period and birth cohort effect coefficients mainly depends on the amount and quality of the collected data rather than on the use of the equally-sized time intervals. Indeed, according to common practice used in cancer epidemiology, to smooth out random fluctuations in cancer incidence rates, the age at diagnosis, time period and birth cohort intervals are grouped in 5-year time intervals. 18 When the amount of analyzed data is large enough, these time intervals can be diminished to, say, 3 or 4 years that will result in improved accuracy of coefficients determination. However, when the collected data is relatively small, the length of these intervals can be enlarged up to 10 years. 12 The price of this, however, will be the lower accuracy in calculated coefficients.
In principle, the approach proposed in this work can be further extended for cases when the age at diagnosis and time period intervals have different durations. For this purpose, the technique proposed in the literature 20 can be utilized. However, it poses additional identifiability problems 24 and the use of this technique requires the development of a more complicated computational procedure, while benefits of its use are questionable. Therefore, we decided to keep such an extension out of the scope of this work.
Example
Estimation of APC effects in lung cancer survival analysis
The proposed procedure was used for estimation of the APC effects in LC survival of white men and women. Selections of LC cases and data preparation, as well as implementation of the proposed procedure and analysis of the obtained results, are presented below.
Selection of LC cases and data preparation
In this work, we used the SEER database that contains cancer follow-up survival data collected 1973 through 2004 in the SEER 9 Registries 13 (Connecticut, Detroit, Hawaii, Iowa, New Mexico, San Francisco-Oakland, Utah, Atlanta (1975–2004), and Seattle-Puget Sound (1975–2004)). From this database, we selected cases for white men and white women aged 40–84 and diagnosed with LC in the 1975–1999 time period, for a total of 272,604 cases. By using the same data processing methodology as described in the SEER Survival Monograph 21 and our previous study, 22 we excluded 38,463 cases that were not first primary cancers; from the obtained subset, we excluded 5,006 cases that were diagnosed via death certificate or at autopsy only; then, we excluded 16,413 cases that were not microscopically confirmed by a pathologist, yielding a total of 212,722 cases (134,360 male and 78,362 female). Choosing the 1975–1999 time period allowed us to analyze the survival with a minimum of five years of follow-up data for LC patients diagnosed in 1999 or earlier. For the selected cases, the survival time was measured in months from the date of diagnosis until the date of death. Cases lost to follow-up were right-censored at the time of the last known follow-up, and patients alive at the end of our study period (December 31, 1999) were right-censored at this date.
The ages of LC patients at the time of diagnosis were divided in nine age at diagnosis intervals, denoted by index i:. i = 1 for 40–44; i = 2 for 45–49; …; i = 8 for 75–79; and i = 9 for 80–84. To get a sufficiently large sample size for statistical analysis, data for the age groups 40 years and over was used (in this case, the number of patients within each age at the diagnosis group exceeds 300). The considered 25-year range of observations (1975–1999) of LC patients was divided into five 5-year time period intervals denoted by index j: j = 1 for 1975–1979; j = 2 for 1980–1984; j = 3 for 1985–1989; j = 4 for 1990–1995; and j = 5 for 1995–1999. In addition, 13 birth cohorts corresponding to the aforementioned age at diagnosis and time periods were divided into 5-year intervals denoted by index l (l = j - i + 9): (l = 1) 1895–99; (l = 2) 1900–04; …; (l = 12) 1950–54; and (l = 13) 1955–59.
For the PH model, the hazard function of LC was presented as hi,j,l(τ)=wi,vj,ul,ho(τ) which is a function of the age at diagnosis (w i ), time period (v j ) and birth cohort (u l ) coefficients, as well as the baseline hazard function, h0(τ). For further convenience, we present this model in Table 1. In this table, hazard functions hi,j,l(τ)=wi,vj,ul,ho(τ) are located in the following way: for a given age at diagnosis interval (i) along the row; for a given time period interval (j) along the column; and for a given birth cohort interval (l) along the diagonal. From this table, it is clear that indexes i, j and l are interrelated: any combination of two indexes simply defines the third index (for instance, the row and column defines the diagonal, etc.).
Validation of the PH model
To test the validity of the PH model given by formulas (1) and (2), we used a graphical approach using log-log plots. 1 According to this approach, for each (I,j) cell of Table 1 we plotted the survival curves, S*, as a function of time τ determined by the method of Kaplan-Meier and then considered the ln(–ln S*) curve. 1 The parallelism of the log-log survival plots for different cells (i,j) provides one with a graphical approach for assessing the PH assumption. In fact, from (1) and (3) it follows:

and

Presentation of the hazard function h(τ, w i , v j , u l ) by age at diagnosis (w i ), time period (v j ) and birth cohort (u l ) effect coefficients, and the baseline hazard function, h0(τ).

When the PH assumption is valid, it follows from formulas (24) and (25) that ln(–ln S(τ,v j ,u l ,w i ) will represent the logarithm of the cumulative baseline hazard function of death from cancer, Ho(τ)=ln[ʃoτh0(z)dz], shifted along the ordinate axis by the value of ln(w i v j u l ). After inspecting the log-log survival plots for each cell of Table 1, we accepted the PH models for LC for both men and women (data not shown).
Results and Discussion
To estimate the joint APC effects in the frame of the Cox PH model, we used Table 2, where for each cell a i,j = w i v j u l (see the section Step 1, above).
Presentation of the hazard function h(τ, w i , v j , u l ) as a function of joint age-period-cohort effect coefficients a i,j (a i,j = w i v j u l ) and the baseline hazard function, h0(τ).

To estimate the a
i,j
coefficients, we used the Cox PH model, written in terms of an exponential expression (6), and utilized the MATLAB function, “coxphfit”. (It should be noted that for this purpose, other programs for Cox PH regression analysis can also be used.) For each (i,j) cell (where i = 1,2, …, 9; j = 1,2, …, 5) two files were used as input for this function. The first file contained the survival time data,
We obtained the estimates

and

To obtain estimates of the age at diagnosis, time period and birth cohort effect coefficients (
In this work, the age at diagnosis, time period, and birth cohort effect coefficients with median indexes of i = 5, j = 3 and l = 7 were chosen as anchors; values of these coefficients were taken as w5 = 1, v3 = 1 and u7 = 1 and their SEs were taken equal to 0. The anchored coefficients were chosen based on our numerical experiments and showed (data not presented) that, in this case, the SEs of the majority of coefficients to be estimated were smaller than for any other combination.
Table 3 presents the estimates of the age at diagnosis effect coefficients,
Estimated values of the age at diagnosis coefficients wi*, their standard errors (SE), and P-values characterizing the statistical difference between the estimated coefficient and the anchored coefficient.

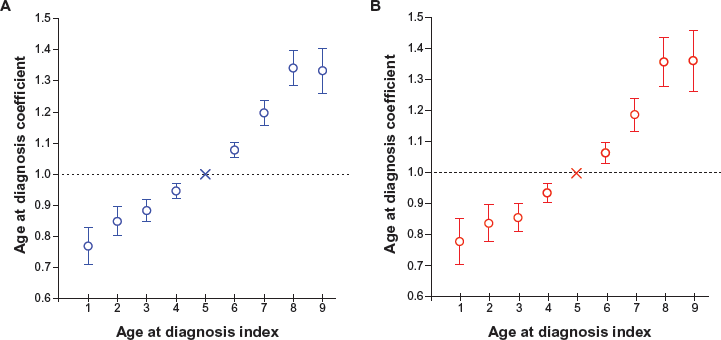
Variation of age at diagnosis coefficients, anchored at index 5, with time period index (i), in white men (
Table 4 presents for white men and women with LC estimates of the time period effect coefficients
Estimated values of the time period coefficients

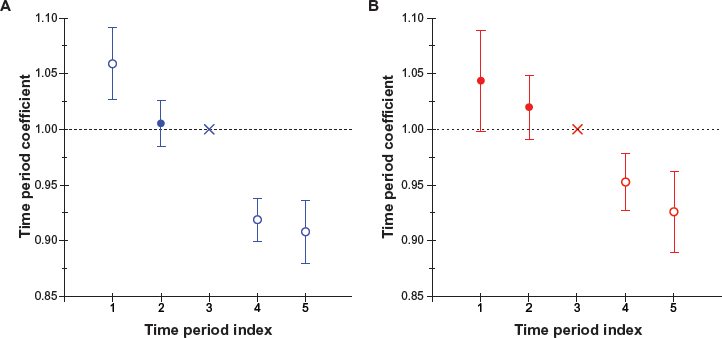
Variation of time period coefficients, anchored at index 3, with time period index (j), in white men (
Table 5 presents for white men and women with LC estimates of the birth cohort effect coefficients,

Variation of birth cohort coefficients, anchored at index 7, with birth cohort index (l), in white men (
Estimated values of the birth cohort coefficients,

Overall, our analysis suggests that for both white men and women diagnosed with LC during the 1975–1999 time period, the hazard for the death from LC depends not only on age at diagnosis (w i ) and time period (v j ) coefficients, but also on birth cohort (u l ) coefficients.
The obtained estimates of the joint (age at diagnosis, time period and birth cohort) effect coefficients,

As an example, Table 6 presents estimated probabilities (in %) of 12-, 36- and 60-month LC survival (τ = 12, τ = 36 and τ = 60, correspondingly) for the 60–64 age groups of white men and women. These data show that in men diagnosed with LC in the age interval of 60–64 years, 12-month survival probability has increased about 5%, 36-month survival probability about 4%, and 60-month survival probability about 4%. For women diagnosed with LC at the 60–64 age interval, 12-month survival probability has increased about 4%, 36-month survival probability about 4%, and 60-month survival probability about 3%. Analogous improvements of the LC survival for the time period of 1975–1999 were revealed for the majority of the considered age at diagnosis groups of white men and women.
Estimated values (in %) of the LC survival function for white men and white women in the 60–64 age at diagnosis group.

It should be noted that the estimates of survival functions for the observed data, indexed by (i,j), can also be obtained by the Kaplan-Meier method. 3 Our calculations showed that the estimates obtained by the proposed approach were close to values of survival functions obtained by the Kaplan–Meier method (data not shown). However, the single variable Kaplan–Meier approach accounts only for time to event (survival) data, while our approach allows modeling survival functions and, in the frame of the PH model, estimating the joint, as well as separate influences of interrelated age at diagnosis, time period and birth cohort effects on the survival and hazard functions.
Conclusion
A novel, computationally effective two-step procedure for estimating APC effects for cancer survival in the frame of the PH model was developed. This procedure allows one to estimate joint APC effect coefficients, as well as interrelated age at diagnosis, time period and birth cohort effect coefficients.
A standard software package for Cox PH regression analysis was used to estimate joint APC effect coefficients. To obtain estimates of the interrelated age at diagnosis, time period and birth cohort effect coefficients, we assumed that the neighboring birth cohorts almost equally affect the hazard function for the death from cancer. It should be noted that this assumption is milder than assumptions utilized in APC analysis of cancer incidence rates by other authors (such as, for example, that cohort effects are absent, 18 or trends of cohort effects can be presented as smooth functions, 14 etc.). Our assumption allows one to solve the identifiability problem of estimating these coefficients. Using an anchoring technique, we developed simple algorithms to obtain estimates of the age at diagnosis, time period and birth cohort effect coefficients. These algorithms were coded into our newly developed MATLAB computing program, called the “apcsur” function.
As the proof-of-concept, the proposed approach was utilized for analyzing SEER data of LC survival for white men and women, observed within the following successive 5-year time periods: 1975–1979, 1980–1984, 1985–1989, 1990–1994, and 1995–1999. A graphical approach using log-log plots was applied to evaluate the PH assumption. The estimates of coefficients of age at diagnosis, time period and birth cohort effects were obtained. Analysis of trends of these estimates suggests that the hazard of death from LC for a given time passed after the cancer diagnosis: (i) decreases between 1975 and 1999; (ii) increases with increasing the age at diagnosis; and (iii) depends upon birth cohort effects. Our analysis, performed in the frame of the PH model, clearly suggests that there is a small but statistically significant improvement of the LC survival in the time period of 1975–1999. Biological and clinical insights of the obtained results need further analysis, which is out of the scope of this methodologically-oriented work.
Overall, we suggest that the proposed computing procedure could also be used for estimating APC effects in survival analysis of different types of cancer.
Disclosures
This manuscript has been read and approved by all authors. This paper is unique and is not under consideration by any other publication and has not been published elsewhere. The authors and peer reviewers of this paper report no conflicts of interest. The authors confirm that they have permission to reproduce any copyrighted material.
Footnotes
Acknowledgement
This work was partially supported by an R01 CA140940-01 A1 (NIH, SS the PI) grant.