
Abstract
We study the discrimination of emotions annotated in free texts at the sentence level: a sentence can either be associated with no emotion (neutral) or multiple labels of emotion. The proposed system relies on three characteristics. We implement an early fusion of grams of increasing orders transposing an approach successfully employed in the related task of opinion mining. We apply a filtering process that consists in extracting frequent
Introduction
While opinion mining (the study of opinions as positive, negative or neutral in free texts) has received great attention over the past few years, 1 less work has been performed in the field of emotion mining that aims at identifying emotion labels, as for instance “anger”, “love” or “hate”. The lack of consensus in emotion models, the difficulty to annotate data-sets as well as the complexity of analyzing emotion expressions in free texts strongly participate in this phenomenon. The success of opinion mining can be explained by the availability of Internet user ratings as well as the simplicity of opinion representations: the task of opinion classification is often tackled as a classical binary classification task.
I2B2's challenge track 2 consists in learning to discriminate emotions labels in free texts.
2
To this aim, participants are provided with a training set made of 600 suicide notes annotated at the sentence level according to
Number of occurences of each emotion in the training set in decreasing order.
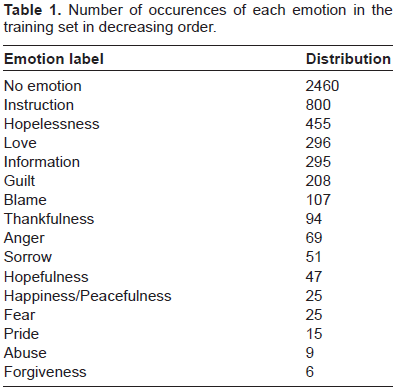
Micro averaged F1 score is employed to evaluate submitted systems over a testing set composed of 300 notes. To our knowledge, it is the first challenge on emotion classification particularly focused on machine learning; SemEval 2007 proposed a track (task 14) 3 consisting in classifying news headlines for several emotions, but due to the small size of the training set, purely linguistic approaches were strongly favored.
We propose a system based on the early fusion of
The motivation behind the use of grams of higher orders is to mix features with increasing lengths for representing expressions of emotions. While unigrams are widely employed for representing documents in the classical text classification task, they do not seem to provide enough description in the case of sentiment analysis. By fusing grams of increasing orders, one is able to make use of richer features to describe naturally complex and subtle expressions of emotions. An interesting example is the negation which plays an important role in the detection of emotions’ patterns. For instance, given the unigram “bad”, the change in polarity held by the expression “not bad” is captured by bigrams. More subtle constructs like “not really bad” are represented by trigrams and higher orders can capture even more complex and subtle expressions.
Given a specific gram's order
The rest of this paper is organized as follow. Related work is presented in Section 1. We then describe our system: sentences are first lemmatized (to this aim we employ TreeTagger)
5
then represented as binary feature vectors made of the fusion of increasing grams’ orders (in the vector, 1 indicates the presence of a feature, 0 indicates its absence). In Section 2 we introduce a method for filtering frequent
Related Work
Internet user reviews have been extensively studied in the task of opinion mining. Authors tackle the task of sentiment analysis as a binary classification task (positive vs. negative opinions). An early work shows that learning binary vectors of unigrams with linear SVMs produces the most accurate classifiers
6
. In their experiments, the authors find that adding bigrams for representing texts leads to a drop in performance. A second study
7
shows that concatenating bigrams and trigrams to the unigrams vector of representation does improve performance on the condition that the number of unigrams, bigrams and trigrams are maintained at balanced sizes. The authors make use of the weighted likelihood ratio in order to select the best
In this paper, we propose to transpose this approach by studying its efficiency in the task of emotion mining. Emotions are more complex and their expressions in text are more subtle than opinion. 9 As it is argued by psychologists 10 , emotions can be segmented in positive and negative emotions, emotion mining may then be regarded as a refinement of opinion mining.
Computing the Dictionaries
In our setting, sentences are represented as binary feature vectors made of the relevant
Extraction step: frequent n-grams
The total number of orders employed in the proposed approach is limited by one factor: above a given
As the size of the dictionary drastically increases with grams’ orders we remove every
Filtering step: Shannon's entropy
The cleaned dictionaries still contain many entries, among them many correspond to noise (for example the unigrams “the”, “a”, or “and”) and many are simply not good at discriminating the sentences over the emotion labels. With a view to deal with noisy features one usually employs a “stop word list” whose role is to clean common words out of the dictionaries. While this approach is well suited to unigrams representations, it does not cope with grams of higher orders: defining stop lists for
Instead, we make use of an information measure: while weighted log-likelihood
7
ratios or
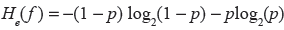
It can be observed that
For each of the 3 cleaned dictionaries, we propose to build one new dictionary per emotion label
We manually estimate ∊
Final representation
Given a sentence
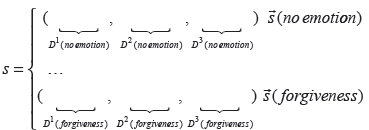
As presented in Section 3 each classifier, for emotion
Learning the Models
As illustrated on Figure 1, the classification of new sentences is viewed as a 2-step process involving
In the training set, 7% of the sentences are multi labeled.
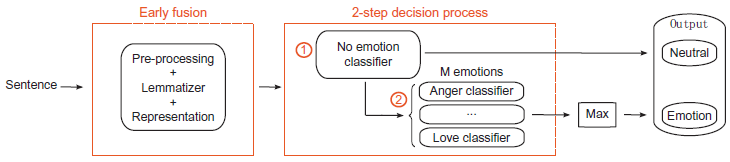
Architecture of the proposed 2-step system: pre-processed sentences are ran through a neutral vs. emotion classifier. Then, emotion bearing sentences are ran through
We use linear SVMs to learn the classifiers, employing the LIBLINEAR implementation, that solves the L1 regularized SVMs problem in the dual.
11
Linear SVMs compute a separating hyperplane based on the scalar product similarity function, they have been shown to stand for state of the art in traditional text classification and to perform well on the related task of opinion mining. In the neutral vs. emotion setting, sentences associated with no emotion account for the positive examples. In the
Experimental Results
In this section we first present and discuss the results obtained by the best performing individual classifiers: we first consider each gram's order independantly, then we consider their fusion. Finally, we give the results achieved by the final system on the testing set composed of 300 notes.
Individual results
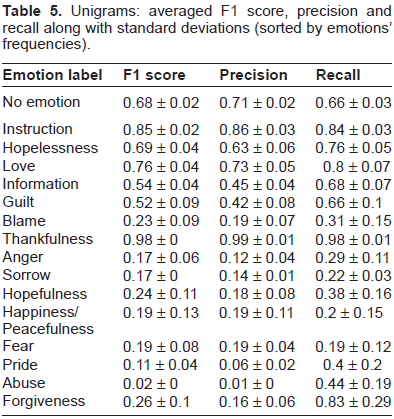
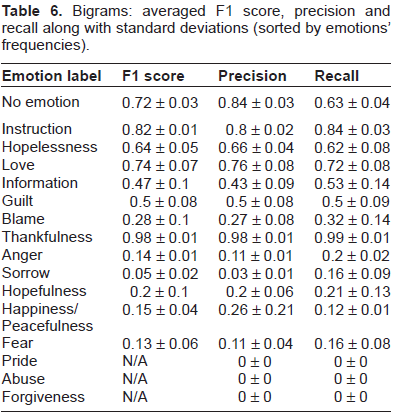
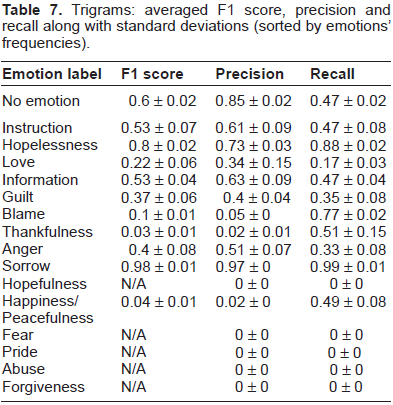
Tables 5–7 display the averaged F1 score, precision and recall for the best classifiers (maximizing the F1 score), trained separately on each emotion on respectively unigram, bigram and trigram representations. We must note that in the final system, as a 2-step process is performed, the performances on the emotion labels must be bounded by the performance of the “no emotion” classifier.
We observe that trained separately, grams of lower orders hold better performances than grams of higher orders. It follows our intuition that grams of high orders are more specific and representations relying uniquely on them do not provide enough coverage. Moreover, precision tends to increase on bigrams while recall tends to decrease. However, the gain in precision does not allow the classifiers based on grams of higher orders to discriminate correctly between positive examples and negative examples. This is especially remarkable for the 3 most rare emotions: “Pride” (15 sentences), “Abuse” (9 sentences) and “Forgiveness” (6 sentences). Due to the extreme rarity of these labels in the training set and in spite of the weighting strategy we employed as described in Section 3, the bigrams and trigrams representations alone cannot be exploited to learn an effective classifier (N/A's in the tables indicate that the SVMs learned a majority vote classifier). Nevertheless, we notice that in some cases grams of high orders stand for the best description: for example trigrams provide a representation far better than unigrams and bigrams at describing the emotion “Sorrow” and, to a lesser extent, the emotion “Hopelessness”.
Despite a general drop in performance over infrequent emotions, we notice that some emotions seem naturally inclined to separate from the others: for example the emotions “Love” and “Thankfulness” do not occur much in the training set, yet they hold good performances on both unigrams and bigrams.
This suggests that for some emotions it may exist a specific vocabulary which is easier to identify.
While bigrams capture enriched features at the expense of coverage (higher precision and lower recall), unigrams capture simple and generic features (lower precision and higher recall). The combination of the two representations may therefore lead to a better compromise between precision and recall. Now, because the success of the complex constructs that are captured by trigrams prove to be dependant on emotions, we run further experiments (not reported in this paper) in which trigrams are added to the combination of unigrams and bigrams at the vector level. We observed that on average it did not significantly improve the performance of the classifiers. We therefore decide to only consider the combination of unigrams and bigrams. Table 2 displays the averaged F1 score, precision and recall for the best classifiers trained on the fusion of unigrams and bigrams. Again, in the final system, the performances on the emotion labels must be bounded by the performance of the “no emotion” classifier.
Fusion of unigrams and bigrams: averaged F1 score, precision and recall along with standard deviations (sorted by emotion labels’ frequencies).
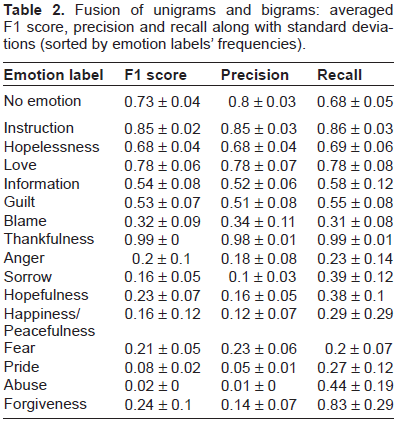
On average, the combination of unigrams and bigrams holds better performances than each representation taken separately. As expected, the resulting classifiers exploit a better compromise between precision and recall than for each of the representations taken separately. A good example is the emotion “Love” for which the fusion strategy of uni-grams and bigrams improves both precision and recall, leading to a better F1 score. We must note that some emotions like “Instruction” do not take benefit from the fusion. For this particular emotion, bigrams prove less successful than unigrams at holding precision. Therefore, the combination of unigrams and bigrams could not benefit from them. Generally speaking, it seems that for the fusion to hold better performances, both representations need to provide different strong points, either in terms of recall or precision.
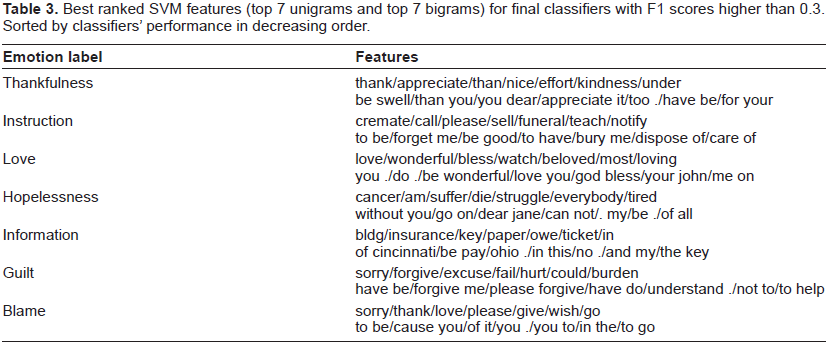
In order to gain further insight into the final individual classifiers, we observe the best weighted features in the SVMs models. Table 3 gives the best features of classifiers holding F1 scores higher than 0.3. In the table, we reported the 7 top ranked unigrams as well as the 7 top ranked bigrams. While features like “love” and “thank” are naturally high rated by linear SVMs, more complex patterns emerge: for instance, the unigram “.” ending a sentence combined with the unigram “too” is more relevant to the emotion Thankfulness than the two of them taken separately. We also notice that while identical unigram features can be shared between different classifiers, bigram features remain specific to each emotions.
Best ranked SVM features (top 7 unigrams and top 7 bigrams) for final classifiers with F1 scores higher than 0.3. Sorted by classifiers’ performance in decreasing order.
Final results
The final system we prepare for evaluation relies on the fusion of unigrams and bigrams. As described in Section 3, test sentences are first pre-processed then labeled using the 2-step decision process described in Section 3.
It must be noted that the proposed system does not output multiple emotions: for emotion bearing sentences, the classifier with highest confidence wins.
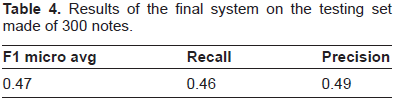
As presented in Table 4, on the testing set composed of 300 notes, it obtains 0.47 on micro averaged F1 score, 0.49 on precision and 0.46 on recall. Among all systems submitted to the I2B2 challenge, the worst micro averaged F1 score is 0.30 while the best is 0.61. The average performance is 0.49 ± 0.07.
Results of the final system on the testing set made of 300 notes.
Unigrams: averaged F1 score, precision and recall along with standard deviations (sorted by emotions’ frequencies).
Bigrams: averaged F1 score, precision and recall along with standard deviations (sorted by emotions’ frequencies).
Trigrams: averaged F1 score, precision and recall along with standard deviations (sorted by emotions’ frequencies).
Conclusions and Perspectives
In this paper, we presented a system for classifiying sentences’ emotional content relying on 3 characteristics: the early fusion of grams of increasing orders, a method for filtering the grams based on Shannon's entropy and a 2-step decision process for dealing with neutral sentences. We showed that unigrams only were not sufficient at describing expressions of emotions, naturally complex and subtle. By adding bigram features at the vector levels, we train classifiers holding better performances on average than on each representation separately. In this setting, unigrams seem to boost the recall while bigrams seem to boost the precision of the resulting classifiers. We also show that, by modeling complex constructs, grams of higher orders like trigrams can provide a better description for discriminating emotions. An interesting developement of this work would be to investigate further types of fusions: we believe that combining low level features with external knowledge is relevant for discriminating emotions. In this setting, intermediate fusion allows to combine different similarity functions, each specific to one source of information. Another perspective of this work is to study the problem of multi-labeling, for instance considering aggregation functions other than
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.
Footnotes
Acknowledgements
This work was supported by the CAP DIGITAL project DOXA funded by DGCIS (N°. DGE 08-2-93-0888).