
Abstract
In this paper, we present the system we have developed for participating in the second task of the i2b2/VA 2011 challenge dedicated to emotion detection in clinical records. On the official evaluation, we ranked 6th out of 26 participants. Our best configuration, based upon a combination of both a machine-learning based approach and manually-defined transducers, obtained a 0.5383 global F-measure, while the distribution of the other 26 participants’ results is characterized by mean = 0.4875, stdev = 0.0742, min = 0.2967, max = 0.6139, and median = 0.5027. Combination of machine learning and transducer is achieved by computing the union of results from both approaches, each using a hierarchy of sentiment specific classifiers.
Introduction
In this paper, we present the LIMSI participation in the second track of the i2b2/VA 2011 challenge, whose aim was the detection of emotions expressed in a corpus of suicide notes, provided by the organizers. After a short reminder of the challenge requirements and a description of the corpus, we present our natural language processing pipelines. We then report on the evaluation of the different approaches we have tried and discuss our results on the task.
Related Work
One of the earliest approaches for automatic analysis of suicide notes was described by Stone et al. 1 They have used a system called General Inquirer created at IBM to detect fake suicide notes. The core of the General Inquirer system is a dictionary containing 11,789 senses of 8,641 English words (ie, certain words have several senses), each mapped to one or more of 182 categories, such as “positive”, “negative”, “self”, “family”, etc. The authors used the distribution of categories to distinguish between simulated and genuine suicide notes. The evaluation, using 33 simulated notes and 33 real notes, showed that the General Inquirer system was able to correctly identify 17 out of 18 test note pairs, which is a better performance than the one of random classification.
A more recent work by Pestian et al 2 used features extracted from the text of the notes to train different machine-learning classifiers. The features were: number of sentences, word distribution statistics, distribution of part-of-speech tags, readability scores, emotional words and phrases. The performance of machine-learning models were compared against the judgments of psychiatric trainees and mental health professionals. Experimental evaluations showed that the best machine-learning algorithms accurately classified 78% of the notes, while the best accuracy obtained by the human judges was 63%.
To our knowledge, there is no published research on automatic emotion detection in suicide notes or similar topics.
Among the categories that participating systems had to use to tag sentences, there were two categories not related to emotions: instructions and information. For these, previous work on objectivity detection is clearly relevant. In the related domain of sentiment classification, Riloff and Wiebe 3 proposed using lexico-syntactic patterns for classifying sentences as objective or subjective. The patterns contain both words and variables corresponding to part-of-speech tags, eg, <x> drives <y> up the wall, in order to deal with different surface forms of the same expressions. The patterns are automatically acquired using a bootstrapping approach. High-precision subjectivity classifiers first classify sentences as subjective or objective. Then, syntactic templates are applied to the sentences in order to generate extraction patterns which instantiate the templates. Finally, the patterns are ranked based on how often they occur in subjective versus objective sentences and the best patterns are selected. Subsequently, the patterns can be used for identifying other subjective sentences.
Pang and Lee
4
found that they could improve opinion detection by removing the sentences they considered as objective, before classifying. Pak and Paroubek
5
used a corpus made of text messages from the Twitter accounts of 44 popular newspapers and magazines, such as
Challenge Requirements
The second track of the i2b2 2011/VA Challenge consists in identifying the opinion expressed in suicide notes by tagging sentences with one or several of the following fifteen categories:
6
Corpus Description
The training corpus consists of 600 suicide notes hand-annotated, while the test corpus is composed of 300 suicide notes. Those documents are of several kinds, mainly last will and testament. The corpus has been fully de-identified * (names, dates, address) and tokenized.
Each name has been replaced by a generic name (
Each document from the training corpus is very brief, on average: 7 sentences and 132.5 tokens (mainly words but also punctuation marks) per document. Proportions are similar for the test corpus.
Documents include spelling errors (
Number of sentences for each number of annotations per line in both training and test corpora.
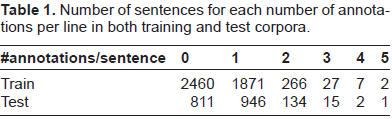
Lines with several annotated emotions are long sentences: the two lines composed of five emotions are between 73 and 82 tokens long. As an example, the longest line (
Number of annotations for each category in both training and test corpora.
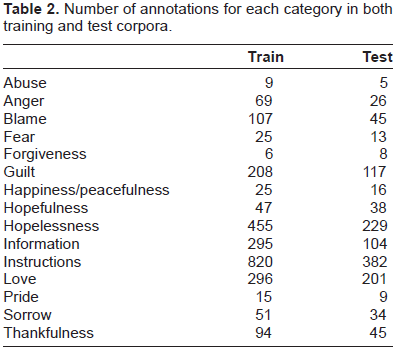
Here is an example of annotation from the test corpus with its reference annotation.
We have found the task to be difficult for the following reasons.
Multiple labeling makes the task more difficult for machine-learning classifiers that normally work with a single label per sample.
The ambiguous “no annotation” assumption adds noise to the training data.
Our Approach
In order to answer the challenge, we created a system that uses both a machine-learning approach and handwritten rules to detect emotions. Our intention was to create a high-precision rule-based system backed up by a machine-learning algorithm to improve recall and to generalize on unknown data.
Machine-learning based approach
In our machine-learning based approach, we trained an SVM classifier using different features extracted from the training set. We used the LIBLINEAR package 7 with a linear kernel and default settings. In order to perform multi-label classification, we employed the one-versus-all strategy, ie, we trained an SVM classifier for each emotion independently. Each classifier provides a decision whether a given sentence contains the emotion it was trained to recognize or not. Such a setting allows us to have multiple labels per line or no labels at all, when all the classifiers returned a negative answer.
Here is a list of features that we have used to build our classification model:
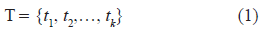
we define the feature vector of T as
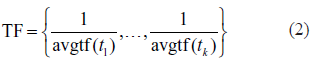
where avg.tf(
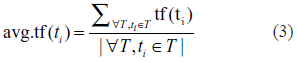
A procedure of attachment of the negation particle was performed to capture the negations, ie, particles “no” and “not” were attached to a following word when generating n-grams.
On different stages of classification, we used different combinations of the listed features. In order to combine features, we simply concatenated the produced feature vectors.
It has been shown that hierarchical classifiers yield better results than flat ones, when classifying emotions. 15 We have organized the labels into a hierarchy as shown in Figure 1.
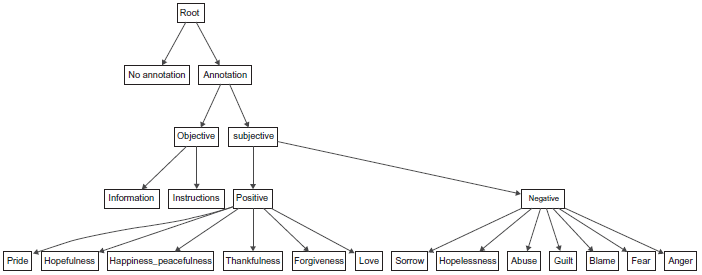
Emotions hierarchy.
Our final algorithms is as follows.
First, we have trained an annotation detector to distinguish sentences with annotations from unannotated ones. Features used: POS-tags, General Inquirer.
Next, the sentences considered to have annotations were fed to a subjectivity detector, to separate subjective sentences from objective ones. Features used: heuristic, POS-tags, General Inquirer.
Objective sentences were then classified between:
Subjective sentences were divided into emotions with a positive polarity and the ones with a negative polarity, using a polarity classifier. Features used: POS-tags, ANEW.
Sentences with a negative polarity were further classified according to 7 classes:
Sentences with a positive polarity were further classified among 6 classes:
In order to estimate the task difficulty, we have plotted the data on a 2-dimension graph using PCA for dimension reduction and General Inquirer features as shown in Figure 2. As we can see from the figures, it is very difficult to separate annotated samples from unannotated ones. The distinction between subjective/objective and negative/positive emotions is much easier. Finally, information and instructions classes are less distinguishable.
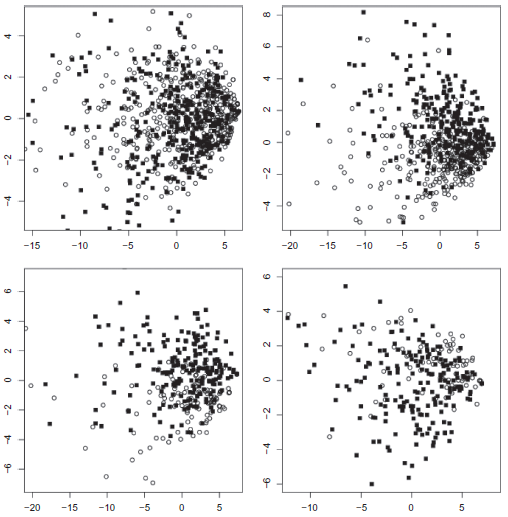
Visualizing samples in 2-dimensions: annotated (black squares) vs. not annotated (white discs), upper left corner (random 20% of total data); subjective (white discs) vs. objective (black squares), upper right corner (random 33% of total data); positive (white discs) vs. negative (black squares), lower left corner (random 33% of total data); information (white discs) vs. instructions (black squares), lower right corner (random 33% of total data).
Emotion detection using transducers
We also used an approach based on extraction patterns to identify emotions in suicide notes. Given the limited amount of training data and the number of target classes, we chose to define these patterns manually, rather than trying to identify them automatically. These patterns combine surface-level tokens, lemmas and POS (part-of-speech) tags and are detected in texts using finite-state transducers, which automatically tag pattern occurrences in the input text.
We have manually developed one transducer for each class using UNITEX (http://igm.univ-mlvfr/~unitex/),
16
which provides also with its base configuration a tokenizer, a POS tagger and a lemmatizer. The transducers were created by careful investigation of the training corpus. For instance, the transducer built for the love category is shown in Figure 3. It can identify expressions such
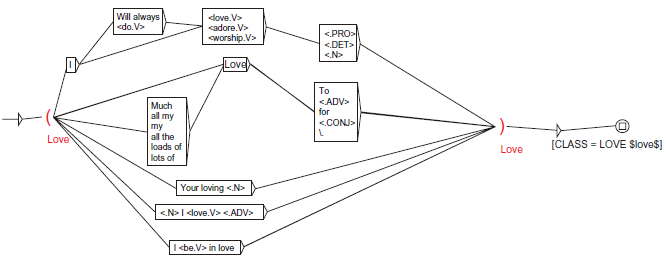
Example transducer for the emotion class love.
Each valid path in the graph represents an emotion-specific pattern, which is subsequently marked in the input text. Nodes in the transducer may correspond to sequences of surface tokens, lemmas with a given POS (eg, <
For the final classification, we applied all the transducers in a cascade, one after the other, in a specific order (
Experiments and Results
In order to tune the system parameters of the machine-learning component, we performed 10-fold cross validation on the training corpus. The task official performance measures are: micro-average precision/recall/F-measure. For our own purposes, we also calculated precision/recall/F-measure for each emotion category.
First, we analyzed the performance of the features used for emotion detection: GI, dependencies, unigrams, and bigrams. Figure 4 plots the classification F-measure of each emotion category and each feature using a flat classi-fication scheme. The classification performance of more frequent classes is higher than those of rarer ones: love, thankfulness, hopelessness, and guilt are much better classified than blame, fear, and anger. Moreover, Pride, sorrow, hopefulness, and happiness could be only detected with GI features, yet the performance is good. Abuse and forgiveness–-the most rare classes in the corpus–-are not detected by any features. As aforementioned, information and instructions classes are hardly distinguishable, which explains the low classification performance of the information and instructions classes, even though the later is the most frequent.
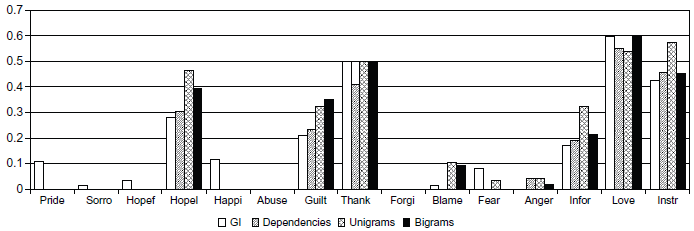
Performance of different features used for emotion detection across the classes.
When performing hierarchical classification, we achieved 71% of accuracy on annotation detection, 84% on subjectivity detection, and 85% on polarity classification. The effect of the hierarchical classification is depicted on Figure 5. Micro-average precision/recall/F1-measure are presented for each feature. We can observe that precision augments when using hierarchical classification, but F1-measure drops due to the decrease of recall. To compensate this, we decided to use hierarchical classification with the mentioned features, but we added another classifier based on combination of unigrams and bigrams, which does a flat classification across all classes.
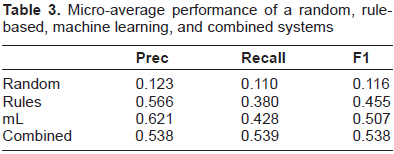
The final classification system consists of the rule-based component and the machine-learning based one. We present the classification performance of rule-based, machine-learning, and the combination of both systems on the evaluation set in Figure 6 (across the classes) and in Figure 7 (micro-average). A baseline random classifier was added for a comparison.
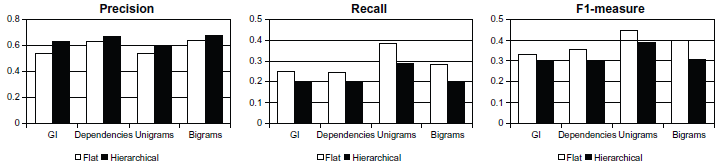
Hierarchical vs. flat classification performance (precision, recall and F1-measure).
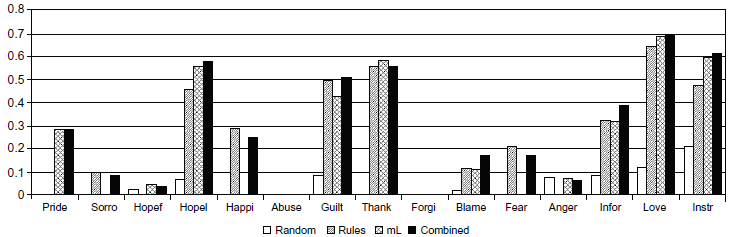
Performance of a random, rule-based, machine-learning, and combined systems across the classes.
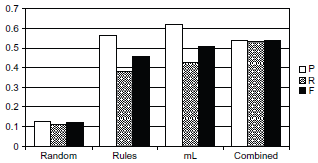
Micro-average performance of a random, rule-based, machine learning, and combined systems.
Official evaluations results
On the training corpus, the transducer-based system achieved a precision of 0.6033, a recall of 0.4873 and an F-measure of 0.5392. The results obtained on the test corpus were very closed from those obtained on the training corpus, with a 0.5383 global F-measure. This decrease in performance is mainly due to lower recall, as it is difficult to manually list all possible emotion-specific expressions. Another problem we have encountered with the data were the numerous spelling mistakes, which also lead to a lower recall, since transducers work with strict string equality. Nevertheless, those equivalent scores reveal the robustness of our system.
Micro-average performance of a random, rule-based, machine learning, and combined systems
Conclusion
The emotion detection track of the i2b2/VA 2011 evaluation campaign is a difficult task due to the nature of the data and the specificity of the annotation schema. The LIMSI team has developed a system combining two approaches for emotion detection and classification: machine learning and rule-based approaches. On the official evaluation, we ranked 6th out of 26 participants with a 0.5383 global F-measure. As a future work, we would like to test our approach on other corpora, such as blogs or movie reviews, to see how well it generalizes on other domains.
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.
Footnotes
Acknowledgements
This work was partially funded by project DoXA under grant number DGE no 08-2-93-0888 supported by the numeric competitiveness center CAP DIGITAL of Ile-de-France region.