
Abstract
We describe our approach for creating a system able to detect emotions in suicide notes. Motivated by the sparse and imbalanced data as well as the complex annotation scheme, we have considered three hybrid approaches for distinguishing between the different categories. Each of the three approaches combines machine learning with manually derived rules, where the latter target very sparse emotion categories. The first approach considers the task as single label multi-class classification, where an SVM and a CRF classifier are trained to recognise fifteen different categories and their results are combined. Our second approach trains individual binary classifiers (SVM and CRF) for each of the fifteen sentence categories and returns the union of the classifiers as the final result. Finally, our third approach is a combination of binary and multi-class classifiers (SVM and CRF) trained on different subsets of the training data. We considered a number of different feature configurations. All three systems were tested on 300 unseen messages. Our second system had the best performance of the three, yielding an F1 score of 45.6% and a Precision of 60.1% whereas our best Recall (43.6%) was obtained using the third system.
Introduction
Suicide is one of the leading causes of death worldwide and presents an increasingly serious public health problem in developed countries. 1 Doctors and other caregivers stand in the front line in the battle to prevent tragedy, facing the urgent need to determine from scarce information the risk of a successful attempt, such that preventative measures can be undertaken. The emotional state of the patient is highly relevant in this task, since depression and other disorders of emotional functioning are known to substantially raise the risk of suicide. Tools which are able to automatically process emotional state in textual resources will be invaluable in the medical fight to intercept such states.2,3 The 2011 i2b2 Medical NLP Challenge presents participants with the task of classifying emotions at the sentence level as they appear in a corpus of suicide notes collected during medical research. The training data consists of messages manually annotated with several different categories of emotion as well as two non-emotion categories: information and instructions. The annotation was performed by relatives of the victims.
There are multiple challenges in automatically assigning one of the 15 possible categories to a sentence in the notes. The annotation scheme is mixed, covering different categories of emotion as well as non-emotion categories; the guidelines, instructions and criteria followed by annotators have not been disclosed; there is apparent ambiguity between instructions and information; sentences are often annotated with more than one category, rendering their processing a multi-label classification task; and many of the categories are very sparse.
Our approach was motivated by these considerations. We first examined the distribution of the fifteen categories in the training data. The majority of annotated sentences (74%, 37.45% of total) are covered by just four categories, namely ‘instructions’, ‘hopelessness’, ‘love’ and ‘information’, while another three categories (‘guilt’, ‘blame’ and ‘thankfulness’) account for another (16%). So a total of 90% of the annotated data are described by only seven of the fifteen categories while 49% of all sentences received no annotation. A clear dilemma was whether to aim to maximise system performance by focusing on the four to seven major categories, or to try and address all emotion categories. Since this was a new task involving an important and controversial topic, we saw it as an opportunity to explore the annotation scheme and make observations about the types of features suited to the recognition of different types of emotions. We decided to follow a hybrid approach which would consider state of the art supervised machine learning as well as manually created rules to cater for the sparse emotion categories. We believe that our approach provides a good insight to the various emotion categories present in suicide notes and can lay the foundations for future applications which would make use of such emotion recognition.
Related Work
Recent work has described the use of text mining approaches to differentiate genuine suicide notes from simulated ones, finding that machine learning approaches were able to make the discrimination better than humans in some cases. 3 Both content-based and structural features were used in the classification. The authors observe that human discriminators focused primarily on content-based features (such as the concepts annotated from the ontology) in making the discrimination, while the machine learning approach obtained the highest information gain from the structural approaches in this task. However, as our task here is emotion classification rather than genuine note detection, we emphasised content-related features more highly in our selection.
The distinction between content and structural features is emphasised in the work of Shapero 4 which describes an extensive investigation into the language used in suicide notes, and reports on the features found more commonly in genuine notes than simulated notes. Genuine notes are found to include affection, the future tense, references to family members, pronouns, names, negatives, intensifiers and maximum quantity terms. Some structural features such as the presence of dates or the identity of the author were found to be more common in genuine notes.
With a promising approach to early intervention using the increasing online presence of particularly teenagers and young adults on Web 2.0, Huang et al describe a simple approach with dictionary-based keyword detection to automatically detect suicide risk and flag depression from blog posts and posts to popular social networks.5,6 This compares closely to the manual rule approach which we have adopted for the several least populous categories in our training data, which also relies on encoded keywords and phrases. However, Huang et al focus on one emotional category only, which simplifies their task, as they do not directly face disambiguation problems.
Another study aimed to automatically distinguish suicide notes from arbitrary newsgroup articles, as part of a broader effort to develop tools which can distinguish suicidal communication from general conversation. 2 This research used words and grammatical features which were automatically discovered in the corpus, then clustering features across the suicide notes and the newsgroup articles, showing clear divisibility in semantic space. Importantly, the clustering results also showed sub-categories within suicide notes for those which are emotional and those which are unemotional, providing some incentive for studying the emotional expressions in suicide notes.
Automatically classifying emotions in suicide notes is a special case of emotion detection in text, a task which has applications in human-computer interaction and sentiment analysis for marketing research.7,8 While such work is closely related to this project, it differs in the nature of the classification to be performed and the text to be classified. In some cases, only
Methods
We first considered single label multi-class classification, where sentences with multiple categories appeared in the training data as multiple copies, a reasonable first step as annotated sentences in the training data have 1.16 labels on average. We employed both JRip and SMO in weka 9 and also LibSVM and CRFSuite, for which we obtained higher performance (average f1 of 0.4425). We also trained binary classifiers for each emotion and considered their union in order to label the data with emotion categories. The latter approach permitted the assignment of multiple labels and also is better suited to imbalanced data. Indeed, we obtained our highest performance in this way (average f1 of 0.46). Another approach we considered was training both binary classifiers and multi-class classifiers on different subsets of the data and combining them to obtain class assignments. While this approach is promising both in terms of multiple label assignment and increased recall, it generated many false positives and achieved an average f1 measure of 0.3977.
Data
Our training data consist of 600 suicide messages of varying length and readability quality, ranging from a single sentence to 177, with over 80% of messages containing fewer than 10 sentences and the average message length being 4 sentences. The messages have been labelled at the sentence level with one or more of 15 categories while a large percentage (49.38%) have received no annotation. Label cardinality is 0.54 overall and 1.16 for annotated sentences, making multiple annotations rare. As humans reading the texts we found that the distinction between information, instruction and sentences without any annotation was unclear. We pre-processed such sentences to facilitate feature extraction by replacing all names, times and places with the words NAME, TIME and ADDRESS respectively.
Features
We employed a number of sentence based features as input to machine learning classifiers, many of which have been used in other types of text classification. Single words and bigrams extracted from a sentence are the default features and thus our baseline considers only ngrams. Other work on sentence based classification, such as argumentative zoning, 10 has shown that ngram-based systems are hard to beat. We also considered grammatical features such as verbs, the tense and voice of a verb (both of which have been shown to be significant in the classification of scientific texts11,12 as well as subjects, direct objects and indirect objects of verbs and grammatical triples. The latter consist of the type of the dependency relation (eg, subj, obj, iobj), the head word and the dependent word. We anticipated that the latter relations would help detect patterns which could distinguish between self-directed emotions and emotions geared towards others. To obtain the parts of speech and grammatical relations we used C&C tools. 13 We also introduced a negation feature, which denotes the presence or absence of a negative expression in a sentence. Negative expressions were annotated automatically using. 14 Negation is particularly relevant to the detection of certain emotions which are often followed by a negative expression. Indeed, overall performance increased with the addition of the negation feature. We also implemented length as a feature of the sentence, as different categories tend to have different average word length. Finally, we also took into account two global sentence features, namely the location of a sentence within a message, split into five equal segments, and the category of the previous sentence (history). The history feature was implemented when we used SVM as a classifier, to model the sequence of categories within a message. This feature was abandoned as soon as we established that SVMs performed better without it (up to 5% higher f-measure), which was due to propagation of error from preceding erroneous predictions.
Classifiers
We used LibSVM 1 , coded in C++ since with the same features it performed better than SMO in weka. Our experiments were conducted using a linear kernel, known to perform well in document classification. We used the default values for the C and ∈ parameters and concentrated on the input features. The recent BioNLP challenge, 15 which addresses a series of tasks ranging from event extraction to coreference resolution has shown the importance of input features as performance of the same classifier can dramatically according to the features.
A drawback in using SVMs is that one cannot easily model the sequence of categories in a message without introducing errors as was the case with the history feature. While we could not be certain that suicide messages are structured, as scientific texts are, one of our hypotheses is that certain emotion categories tend to follow others or tend to cluster together. For this reason we employed Conditional Random Fields (CRF), which have been shown to give good results in sequence labeling of abstracts. 16 We used CRFSuite, 2 an algorithm for linear-chain, First Order CRFs, optimised for speed and implemented in C. Stochastic Gradient Descent was employed for parameter estimation.
Both LibSVM and CRFSuite were used in a number of different configurations, both for single label multi-class classification and multi-label classification (Fig. 1).
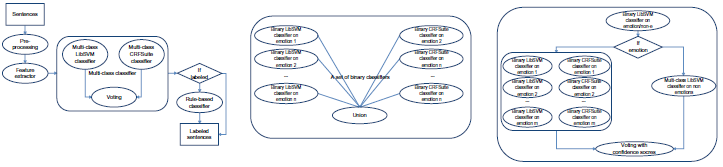
Multi-class single label/Union of binary classifiers, multi-label/Combination of binary and multiclass classifiers, multi-label.
Multi-class annotation
We trained LibSVM and CRFSuite models independently of each other but on the same training data single label multi-class classification. We combined the results of the two classifiers so that in cases of disagreement we chose the category that had received the highest probability, according to classifier output.
Binary classifiers
As instances in the training data contain multiple annotations per sentence, we trained individual binary classifiers for each of the fifteen categories present in the training data, for both LibSVM and CRFSuite and took the union of the classifiers. This allowed a sentence to receive more than one category if more than one binary classifier made a class assignment. Category assignments from LibSVM and CRFSuite were considered as separate if they involved different categories. This approach yielded the best performance.
Combination of binary and multi-class classifiers
We also implemented a variant of the binary classifiers, which combines binary classifiers trained on subsets of the data with a multi-class classifier trained on another subset. We call this approach ‘Hybrid Binary’ and is a variant on hierarchical classification. We first trained a single binary classifier on the training data, to distinguish between emotion and non-emotion sentences. We then trained individual emotion classifiers, using only the subset of the data pertaining to emotions, and a multi-class classifier on the non-emotion data, which determined whether a sentence should receive information, instructions, information-instructions or remain unannotated. A sentence was assigned the union of the output of the emotion classifiers. In cases where the binary non-emotion classifier fires, without the binary emotion classifier firing as well, the sentence is also assigned the category determined by the non-emotion multi-class classifier. This more sophisticated approach was intended to boost emotion recognition and indeed resulted in the best recall we achieved (43.6%). The drawback was that it also generated many false positives.
Manual rules
As several of the emotion categories were extremely sparsely annotated relative to the corpus as a whole, the classifiers were unable to return meaningful results for these categories. We thus decided to complement the machine learning approach with a dictionary of manual recognition rules for high precision, low recall emotion recognition. The rules were proposed by manual inspection of the relevant annotated sentences from the training data together with the examination of synonym sets from WordNet-Affect. 17 Each rule was then validated by testing against the corpus as a whole, and rules which were “noisy” were discarded.
We found that the type of language used in emotional sentences varied strongly depending on the emotion category. For example, the language used in the ‘love’ and ‘forgiveness’ categories was quite homogeneous (almost every sentence containing the words ‘love’ and ‘forgive’ respectively), while the language used in other categories such as ‘anger’ was extremely heterogeneous and metaphorical. There were also large overlaps in the language used between different categories which were close in semantic meaning, such as between ‘anger’ and ‘blame’, and between ‘happiness peacefulness’ and ‘hopefulness’.
We used 48 manual rules for the 8 sparsest categories, distributed across the categories: anger (12), sorrow (5), hopefulness (9), happiness_peacefulness (4), fear (6), pride (6), abuse (4), forgiveness (2). These manual rules, developed in Perl regular expressions, were only applied to those sentences not labelled by automatic classifiers, meaning that the number of sentences applied to the rules varies over automatic classifiers.
Results and Discussion
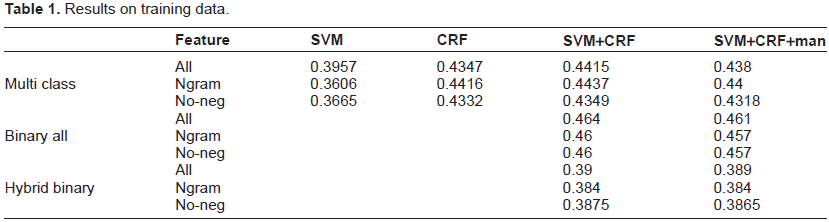
Table 1 shows the outcome of three different approaches each with three different feature configurations (all features, ngrams, and all features without negation) on the training data. We obtained the best F-measure from the ‘Binary All’ approach, which took the union of individual binary SVM and CRF classifiers trained with all features. From the multi-class classifier we can see that CRF performed better than SVM, which suggests that the sequence of sentences and categories does play a role in emotion detection in the suicide notes.
Results on training data.
Results on test data.
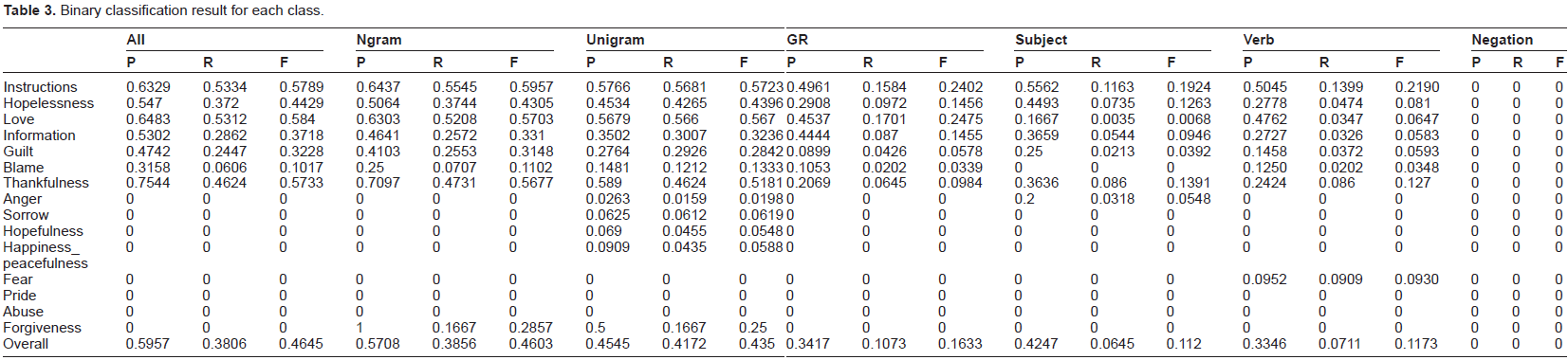
We also analysed the individual performance of the ‘Binary All’ approach for each category when all features were used and how it was influenced in the presence of a single feature (each of GR (grammatical triple), Subject, Verb, and Negation). Table 3 shows the result of the ‘Binary All’ classification for each category and Table 4 the same result combined with manual rules. For all major categories (instructions-thankfulness) the best results were obtained for the combination of all features but the difference between ngrams and all features is not very big, ranging from 1%–4%. For rare categories (anger to forgiveness) the combination with manual rules outperforms the machine learning classifier-only approach. However, this combination with manual rules reduces overall performance by increasing FP rather than reducing FN in the case of all, ngram and unigram features. In the case of the GR, Subject, Verb and Negation features, where using only ML classifiers produced no results, performance for rare categories increased.
Binary classification result for each class.
Binary classification result combined with manual rules for each class.
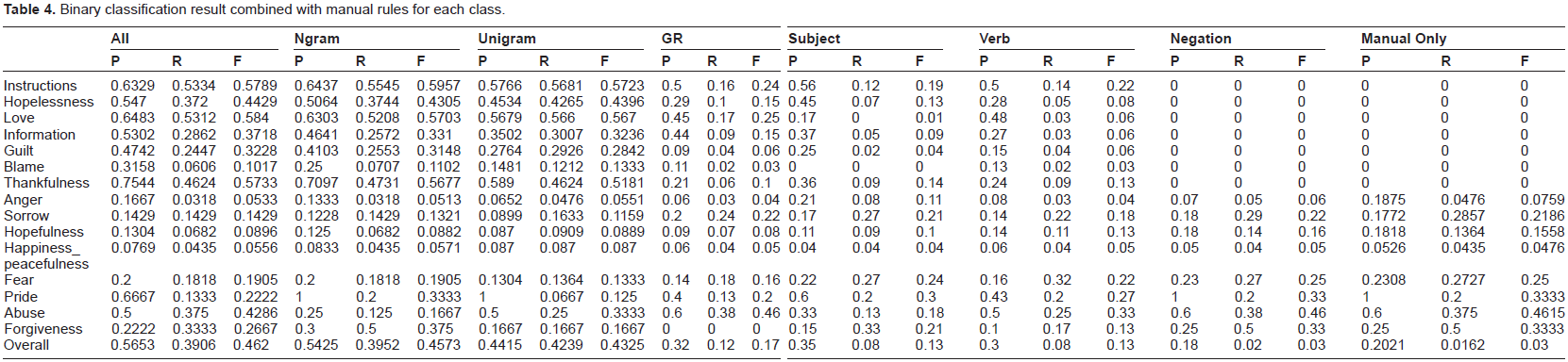
We believe that we could improve our results by finding better ways of combining classifiers, perhaps through stacking or joint inference, techniques which achieved the highest results in BioNLP 2011. 15 Judging from manual rule-only results for the rare categories, we believe that a hybrid system which combines machine learning predictions for the major categories with manual rule-only results for the rare categories could boost recognition performance.
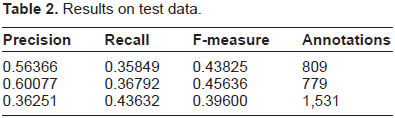
For the test data submission, we first chose the best feature model from each category of classifiers (ie, multi-class, binary and hybrid binary) and applied it to the test data. We separately applied the manual rules to the test data. We then combined the output of each model with the manual rules so that the manual rules applied only to sentences where the classifiers had made no predictions. The results we obtained from the scoring website are in Table 2.
Data inconsistency
We observed several inconsistencies in the training data, a factor which we believe led to decreased performance in the resulting machine learning and rule-based approaches. Structurally, it is noticeable that the “sentence-level” annotation often transcends sentences. For example,
There were also inconsistencies in the annotation of categories to the sentences. We observed significant ambiguities between the (most voluminous) non-emotional categories ‘information’ and ‘instructions’. Some sentences were annotated with both categories, such as
Within emotional categories, several sentences which are very similar were inconsistently annotated, for example the phrase phrase
Annotation Guidelines
Sentence-level annotation of classification categories in free text is an intrinsically difficult task, and quality of annotations need to be ensured by interannotator agreement values. In an ideal corpus for machine learning, consistency in annotation is required. Emotion language is deeply ambiguous and open to diverse interpretations. Furthermore, a sentence might express that the writer was feeling a certain way when they wrote the text, although this is not in itself explicit in the text. Many of the sentences which were labelled with anger were labelled as such because the tone of the sentence seemed angry, not because anger was explicitly mentioned: the word “angry” does not appear even once in the corpus of 69 annotated sentences. On the other hand, the statement
It is of general interest that the principal emotion found in this suicide note corpus is hopelessness. This can be compared to the result of, 3 who find that the most relevant emotion categories for detecting genuine notes are: giving things away, hopeless, regret and sorrow. However, detecting emotions such as hopelessness in human text is inherently plagued by the flexibility of words such as “hope” and “wish”. Both 3 and 4 find a surprising role for structural features in real suicide notes–-which are not obviously emotional in nature. A parallel in the current task is that the highest prevalence is instructions in the notes. It would be surprising, however, if the same features worked equally well for such non-emotional content as for detecting the emotional sentences.
Conclusions and Future Work
In this paper, we described three different approaches to detect emotions from sentences, motivated by the sparse and imbalanced data as well as the complex annotation scheme. In each approach, we explored various feature representations from simple unigrams to rich grammatical information, and we also tested the use of negation which can change the meaning of sentences. To improve the performance for rare categories, we wrote manual rules and combined them with ML-based classification results. We found some interesting results which encourage further investigating the use of manual rules for rare categories.
As future work, we plan to explore various methods of integrating different machine learning classifiers for emotion recognition, using techniques such as stacking and joint inference. We would also like to experiment with different techniques for combining manual rules with automatic classifiers more systematically. We will test the use of meta-classifiers using results of individual classifiers as features of ML-based classifiers. It will also be interesting to test if more elaborate feature selection could help improve the results.
We believe that our work can provide insight into the recognition of various emotion categories present in suicide notes and can benefit applications relating to emotion recognition in blogs and other personal statements.
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.