
Abstract
Objective
To create a sentiment classification system for the Fifth i2b2/VA Challenge Track 2, which can identify thirteen subjective categories and two objective categories.
Design
We developed a hybrid system using Support Vector Machine (SVM) classifiers with augmented training data from the Internet. Our system consists of three types of classification-based systems: the first system uses spanning n-gram features for subjective categories, the second one uses bag-of-n-gram features for objective categories, and the third one uses pattern matching for infrequent or subtle emotion categories. The spanning n-gram features are selected by a feature selection algorithm that leverages emotional corpus from weblogs. Special normalization of objective sentences is generalized with shallow parsing and external web knowledge. We utilize three sources of web data: the weblog of LiveJournal which helps to improve the feature selection, the eBay List which assists in special normalization of
Measurements
The performance is evaluated by the overall micro-averaged precision, recall and F-measure.
Result
Our system achieved an overall micro-averaged F-measure of 0.59.
Conclusion
Our results indicated that classifying fine-grained sentiments at sentence level is a non-trivial task. It is effective to divide categories into different groups according to their semantic properties. In addition, our system performance benefits from external knowledge extracted from publically available web data of other purposes; performance can be further enhanced when more training data is available.
Introduction
A person who has committed suicide often experienced a cumulative psychological process which ultimately led to the decision of ending his/her own life. 13 The suicide note provides us with the firsthand information about that person's particular mind status and mind logic. 4 Analyzing the internal emotions revealed in the suicide note might help us to identify people who potentially have suicide ideation, and thus prevent the misery from happening.
The task of 2011 i2b2 Challenge Track 2 is designed to identify/recognize/categorize sentence-level sentiments in the suicide notes.5,6 The basic problem structure is divided into fifteen categories, including thirteen subjective categories (
The main difficulty in this task comes from the underlying ambiguity of the classification task and the limited amount of training data in each category. The entire task covers thirteen emotion categories and two additional factual categories, which are fine-grained, ie, to distinguish
A wide variety of existing methods in sentiment analysis are not immediately applicable to the tasks in this challenge. A single classification system might not be sufficient. Existing feature selection algorithms, such as document frequency thresholding, information gain, mutual information, ᵪ 2 statistic, and term strength, are also ineffective in dealing with the limited amount of training data and accidental features 7 in this case. Existing sentiment lexicons only consider limited number of categories and thus cannot be directly applied to this task; examples include positive/negative dictionaries from General Inquirer and six emotional categories from WordNet-Affect.
Our system aims to deal with the above difficulties by utilizing several web data resources in a multilayer classification system.
We divide the fifteen categories into three groups and handle each group differently. This is due to: (1) the expressions adopted by objective and subjective categories exhibit different properties; and (2) the effectiveness of machine learning method depends on the amount of available training data. For two objective categories (
The candidate features for classifying the
To alleviate the situation of having very limited amount of training data, we make an effort to collect additional data (posts from SuicideProject website)
11
with similar emotional contents as those in this challenge. A total number of 1,814 sentences are manually annotated according to the classification schema. Using our trained model as a classifier, we further choose the sentences with high SVM classifier confidence score as the labeled data. Another 268
In this paper, we describe our system for the i2b2 challenge 2011sentiment classification task. Section 2 reviews previous research in sentiment classification and suicide note analysis. Section 3 gives detailed explanations for each component of our system. In Section 4, experiment results are shown to compare alternative approaches and validate our system. Section 5 discusses the submitted results and Section 6 performs error analysis. Finally, conclusions are drawn in Section 7.
Related Work
Sentiment analysis is an increasingly important topic in NLP. There are some related work in blog data, user reviews and customer feedback. Farah et al 12 focused on the strength of subjective expressions within a sentence or a document using specific 200 news articles. The experiments demonstrated that a combination of adjectives and adverbs plays a more effective role than pure adjectives. Chesley et al 13 used blog corpus to identify each post as being objective, positive, or negative; their experiments demonstrated that verbs and adjectives are strong features in the blog corpus. Yang 14 used blog corpus such as LiveJournal, Windows Live Spaces and Yahoo! Kimo blog to classify emotions using Conditional Random Fields (CRF) and SVM. This work is similar to our task in using LiveJournal. Mihalcea 15 exploited LiveJournal to find words related to happiness or sadness; their method can be used to create a “happiness” dictionary. Mishne 16 utilized blog information to predict the levels of various moods within a certain time. Aman 17 classified emotions using some dictionaries such as General Inquirer, WordNet-Affect and other features.
There is some related work in feature design for sentiment analysis. N-grams 18 are the most widely used features. N-grams may ignore contextual information such as negations, and valence shifters. 18 A prior sentiment lexicon 19 is useful for sentiment analysis, but it is difficult to accurately build a dictionary for each category in our task. Syntax information is treated as features to classify sentiment. Nakagawa 20 described a dependency tree-based method for subjective sentiment analysis using CRFs with hidden variables. Jiang 21 applied syntax information such as verb, adjective, noun, and adverb to confirm target information to classify positive, negative and neutral.
Research on classification for suicide note corpus has not attracted much attention. Pestian et al1,4 used a feature selection strategy to tell genuine from elicited suicide notes by combining decision trees, classification rules, function models, lazy learners or instance-based learner, and meta learners. The accuracy of results by a learning-based algorithm, trainees, and mental health professionals are 78%, 49% and 63% respectively. Surprisingly, a learning-based approach achieves the best results. Matykiewicz et al 22 presented an unsupervised learning algorithm to distinguish actual suicide notes from newsgroups. The mean F-measure is 0.973 when the number of clusters varied from two to six. The experiment demonstrated that machine learning can be used to successfully detect suicide notes or newsgroups.
Methods
Figure 1 gives an overview of our system. Each sentence in a suicide note is first preprocessed (explained below) and then passed into three groups of one-versus-all binary classifiers, each deciding whether the sentence belongs to the corresponding category or not. The first group uses a linear SVM trained with spanning n-gram features (see a description below), accounting for eight subjective categories. Features are ranked and selected with the help of semantically matched corpora from LiveJournal. The second group accounts for the two objective categories. Items and locations are generalized by eBay product lists before the sentence is represented as 1–4 gram feature vector and learned by a linear SVM. The third group accounts for the remaining five infrequent/subtle subjective categories. Dictionaries of patterns are compiled from various resources and then matched against the sentence to determine its category. Finally, the output labels of each classifier are combined to assign categories for that sentence.
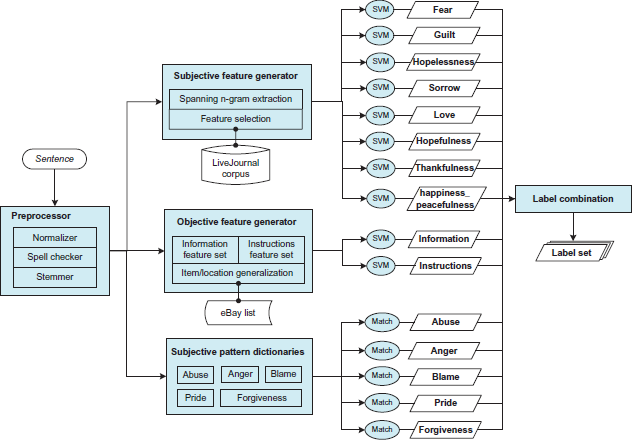
System architecture diagram.
Sentence Preprocessing
The preprocessing steps of a sentence include token normalization, spell checking and stemming. Normalized tokens are represented by numbers, dates, relatives, titles, first and last names, place names. Placeholders are also normalized, such as consecutive underscores “–” and letter x in “I am xxxx from –- –-”. Two spell checkers are used sequentially: the first one is compiled from training data, converting separate tokens into one token, such as “ca n't” to “can't”; the second one is Hunspell, 23 an open source spell checker. The stemmer utilizes a function provided by Hunspell. 23
Subjective classification using spanning n-grams features
We begin this subsection by introducing our spanning n-gram features; then we illustrate the process of feature computing and ranking, and feature selection by leveraging LiveJournal and POS patterns, and training an SVM model.
Feature description
We design a feature called
The intuition behind this feature design is to capture the subtle emotions in a sentence. First, some emotions are not expressed in any single word but by colloquial phrases comprised of common words. A spanning n-gram allows for a certain degree of variation within a traditional n-gram, such as the
In our implementation, the window is bounded by punctuations in the sentence, and the maximum window size is set to be 8. Intuitively, a small window can barely capture distant dependencies, while a big window (spanning across several clauses) is too long to characterize a phrasal structure.
Feature computing and ranking
The number of extracted spanning n-grams is greater than their n-gram counterparts, resulting in a very high dimensional feature space. Given the limited size of training data, feature selection is performed in order for the SVM classifier to assign weights properly to most relevant features.
For each emotional category, we select a set of features by their relevance to that category, and use all these features to represent each sentence into a feature vector for statistical learning. The relevance is computed as a variant of odds ratio. In one-versusrest classification settings, denote
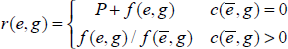
where
When
When
Whether to select those features with a low
Feature selection through LiveJournal corpus
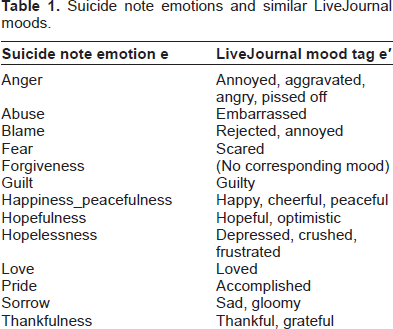
The high dimensional feature space produced by spanning n-gram and the limited training data result in a sparse feature matrix. Common feature selection algorithms may not be directly applicable here. LiveJournal is a weblog space where users are able to tag his/her article with an optional “mood”. The data from LiveJournal is a rich repository for sentiment analysis. Moods can be chosen from a list of 132 emotions. We select semantically matched moods to construct extended corpus for some of the suicide emotion categories, as shown in Table 1. If multiple LiveJournal moods are selected for one category, sentences from these moods are pooled together to form one LiveJournal mood set. We assume that people tend to use similar phrases to express similar emotions. For example, popular phrases in articles tagged “depressed”, “crushed” or “frustrated” would also be more relevant to “hopelessness” category in suicide notes.
Suicide note emotions and similar LiveJournal moods.
We compute the relevance of an infrequent spanning n-gram g to a suicide emotion category
The infrequent grams with
To this end, every emotion has a set of features: selected spanning n-grams and emotion-POS bins. These features are binary valued, representing the presence/absence of the feature. We concatenate these features to form the entire feature vector for subjective category classification.
Objective classification of information and instructions
The two objective categories,
First, four corresponding dictionaries are prepared. The “daily item” dictionary contains items appearing in training data. To cover as many daily items as possible, product category list from www.ebay.com is added. Since the data size is small, dictionaries of “financial term”, “location” and “location preposition” are manually compiled from the training data. This process is facilitated by POS-tagging and chunking 24 the sentences of objective categories.
Second, the OpenNLP chunker 24 is used to chunk a sentence based on a shallow parser. The chunk helps to (1) determine the part-of-speech of a matched word, since words like “watch” “check” and “ring” are not items if they are used as verbs; (2) allow different modifiers before the same head noun, so that “my ring” “my diamond ring” and “the engagement ring” are all recognized as long as the dictionary contains the single word “ring”. For each smallest unit produced by the chunk, if it contains any word from the above four dictionaries, it is normalized to the name of the dictionary. An example is shown in Figure 2. The sentence “Please find my insurance in the briefcase.” is chunked as “[VP Please/VB find/VB] [NP my/PRP$ insurance/NN] [PP in/IN] [NP the/DT briefcase/NN]./.”. It is first normalized as “Please find _ financial_term_ _location_ prep_ _daily_item_”.
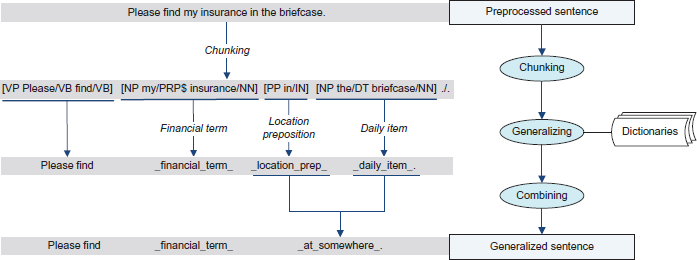
Objective information generalization.
Third, if both a preposition and the following noun phrase are normalized, then they are normalized to “_at_somewhere_”. In the above example, the sentence is further normalized as “Please find _financial_ term_ _at_somewhere_”.
1–4 grams of the normalized sentence is used as features for information and instruction. In addition, the count of “_at_somewhere_” is a special feature for information; the presence of a funeral-related term (“bury”, “cremation”, etc.) is a special feature for instructions. A list of funeral-related terms is compiled from training data.
Subjective classification using pattern matching
Some subjective categories such as
Results
The performance of experiments was measured using three standard measures: precision (P), recall (R) and F-measure (F).
To compare different statistical classifiers, we used bag of 1–4 grams features to train SVM, Naïve Bayes and decision tree boosting classifiers 26 using 600 training data with 10-fold cross validation experiments. Table 2 is the micro-averaged results of the three classifiers. The experiment results demonstrated the results of SVM (tune bias of each category) have the best performance compared with other two classifiers. The results in Table 2 show that SVM is flexible. After tuning threshold parameter of each category, SVM ranks top in the three classifiers. In this task, SVM was chosen as the classifier for its flexibility.
10-fold cross validation micro-averaged results using bag of 1–4 gram features as baselines (categories
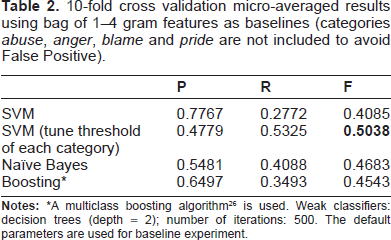
A multiclass boosting algorithm 26 is used. Weak classifiers: decision trees (depth = 2); number of iterations: 500. The default parameters are used for baseline experiment.
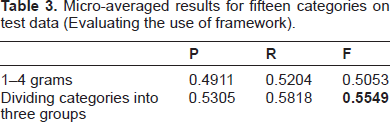
The effect of the framework, ie, dividing fifteen categories into three groups, is shown in Table 3. The first row uses preprocessed sentences and 1–4 grams without feature selection, but categories
Micro-averaged results for fifteen categories on test data (Evaluating the use of framework).
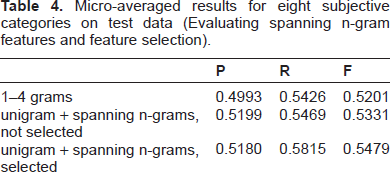
The effect of spanning n-gram feature for eight subjective categories is shown in Table 4. All systems used bias-tuned SVM as classifiers. The baseline uses 1–4 gram features. When we replace the feature with unigram and four types of spanning n-grams without feature selection, both precision and recall improved by a margin. After feature ranking and selection with the help of LiveJournal corpus, the classification result is further improved.
Micro-averaged results for eight subjective categories on test data (Evaluating spanning n-gram features and feature selection).
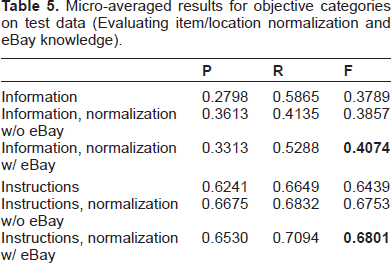
The influence of item/location generalization for objective categories is shown in Table 5. The baseline uses pure 1–4 gram features. The results show that generalization greatly improves the performance of the two categories. To assess the effectiveness of knowledge from eBay, we conduct experiments with and without item normalization. We can see that the eBay knowledge contributes to a more significant performance gain for
Micro-averaged results for objective categories on test data (Evaluating item/location normalization and eBay knowledge).
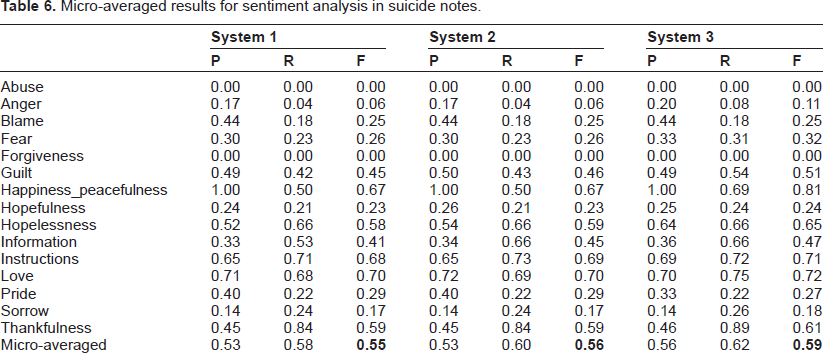
We submitted three systems for the task. System 1 used the 600 notes provided by i2b2 organizers as training data and 300 notes as testing data. In System 2, extra labeled
The last test results were micro-averaged. Table 6 is the micro-averaged results for sentiment analysis in suicide notes. The experiment results demonstrated that adding extra labeled data can improve the overall performance.
Micro-averaged results for sentiment analysis in suicide notes.
Discussion
The results show that better performance can be achieved when more data is supplied to machine learning classifiers, as previous work have demonstrated.
27
In System 2, as we added more
Some categories such as
Error Analysis
Two major sources of errors are shared among all categories.
No-label sentences are labeled: the system assigns a label to a sentence, but the gold standard assigns no label to it. Since more than half of the sentences bear no label in the gold standard, this type of error accounts for a major portion of the false positives (FPs) in all categories. For example, nearly 2/3 FPs of the category
Multiple labels compete with each other: for a sentence with
Besides, errors are also caused by word sense ambiguity. Some words, such as “please” (the beginning of an imperative sentence) and “call” (to contact someone by telephone), are usually strong indicators of
Lastly, FNs appear where the test data are too bizarre to be generalized by the model learned from training data. Since we adopt a one-versus-rest classification scheme, the size of positive training set is smaller than that of the negative training set. Therefore, the model learned by a linear binary SVM classifier is biased toward the negative side. If a positive test sentence contains no feature with significantly positive weight, the classifier will not be confident enough to assign a positive label. This is especially the case for some of the small emotion categories, where the training set is far from representative of that emotion.
Conclusion
In this paper, we have described a sentiment classification system by utilizing augmented web data and devising effective features. The task categories are systematically divided into three groups. The first type makes use of spanning n-gram features for subjective categories; the second one mainly focuses on bag-of-n-gram features for objective categories; the third type is based on unigram feature for those subjective categories which need semantic understanding. The external web data are from three sources: the weblog of LiveJournal which assists the feature selection process in spanning n-gram features, the eBay List derived an item dictionary to help special normalization in
Disclosures
Author(s) have provided signed confirmations to the publisher of their compliance with all applicable legal and ethical obligations in respect to declaration of conflicts of interest, funding, authorship and contributorship, and compliance with ethical requirements in respect to treatment of human and animal test subjects. If this article contains identifiable human subject(s) author(s) were required to supply signed patient consent prior to publication. Author(s) have confirmed that the published article is unique and not under consideration nor published by any other publication and that they have consent to reproduce any copyrighted material. The peer reviewers declared no conflicts of interest.
Footnotes
Acknowledgement
This work was supported by Microsoft Research Asia (MSR Asia). The work was also supported by MSRA eHealth grant, Grant 61073077 from National Science Foundation of China and Grant SKLSDE-2011ZX-13 from State Key Laboratory of Software Development Environment in Beihang University. We would like to thank the organizers of the i2b2 NLP challenge, especially Dr. Ozlem Uzuner and Dr. Scott Duvall for their tremendous contribution. Z. Tu is supported by ONR N000140910099and NSF CAREER award IIS-0844566.