
Abstract
This paper describes a system developed for Track 2 of the 2011 Medical NLP Challenge on identifying emotions in suicide notes. Our approach involves learning a collection of one-versus-all classifiers, each deciding whether or not a particular label should be assigned to a given sentence. We explore a variety of features types–-syntactic, semantic and surface-oriented. Cost-sensitive learning is used for dealing with the issue of class imbalance in the data.
Introduction
This paper presents a survey of the utility of various types of features for supervised training of Support Vector Machine (SVM) classifiers to determine whether sentences from suicide notes bear certain emotions, or if they communicate instructions or information. The work described in this paper was conducted in the context of Track 2 of the 2011 Medical NLP Challenge. 1 The task organizers provided developmental data consisting of 600 suicide notes, comprising 4,241 (pre-segmented) sentences with a total of 79,498 (pre-tokenized) words. Each sentence is annotated with any number of the 15 topic labels (as listed in Table 1). For evaluation purposes the organizers provided an additional set of 1,883 (initially unlabeled) sentences in 300 notes for held-out testing.
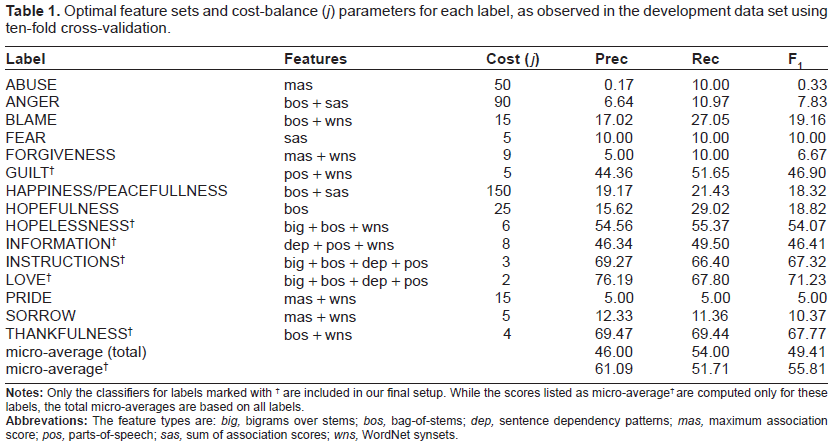
Optimal feature sets and cost-balance (
Our approach involves learning a collection of binary SVM classifiers, where each classifier decides whether or not a particular label should be assigned to a given sentence. The information sources explored in feature design range from simple bag-of-words features and
Method
Our approach to the suicide notes labeling task utilizes a collection of
As training data for each classifier, we use the set of all sentences annotated with the label as positive examples; the sentences in the set complement form the negative examples. We note, however, that the frequency distributions of the labels in the suicide notes vary greatly. For example, the most frequent class (INSTRUCTIONS) is applied to 19% of sentences, whereas the least frequent class (FORGIVENESS) occurs in only 0.1%. So for each classifier the negative examples will greatly outnumber positive examples. A well-known approach for improving classifier performance in the face of such skewed class distributions is the notion of
Sentences are represented by a variety of features that record both surface and syntactic characteristics, as well as semantic information from external resources, as described below.
The most basic features we employ describe the surface characteristics of sentences. These include:
The stem form of words, obtained using the implementation of the Porter Stemmer
5
in the Natural Language Toolkit
6
(eg,
Bigrams of stems, created from pairs of stems appearing in sequence (eg,
Lexicalized part-of-speech, formed of word stems concatenated with the PoS assigned by TreeTagger. 7
Features based on syntactic dependency analysis provide us with a method for abstracting over syntactic patterns in the data set. The data is parsed with the Maltparser system, a language-independent system for data-driven dependency parsing. 8 We train the parser on a PoS-tagged version of the Wall Street Journal sections 2–21 of the Penn treebank, using the parser and learner settings optimized for the Maltparser in the CoNLL-2007 Shared Task. The data was converted to dependencies using the Pennconverter software 9 with default settings–-see Figure 1 for an example. From these dependencies we extract:
Sentence dependency patterns; wordform, lemma, PoS of the root of the dependency graph, eg, (leave, leave, VV), and patterns of dependents from the (derived) root, expressed by their dependency label, (eg, VC-OBJ-OPRD), part-of-speech (VV–NN-VVD) or lemma (leave-door-unlock).
Dependency triples; the set of labeled relations between each head and dependent, eg, (will-SBJ-I, will-VC-leave, leave-OPRD-unlocked).
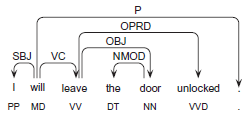
Example dependency representation.
We also draw on semantic information from external resources:
Synonym set features are generated using WordNet,
10
by mapping word forms and their predicted part-of-speech to the first synset identifier (eg, the adjectives
WordNetAffect
11
is used similarly, activating features that represent emotion classes when member words are observed in sentences (eg, the words
The final type of feature that we employ represents the degree to which each stem in a sentence is associated with each label, as estimated from the training data using the
The sum of the association scores of all words in a given sentence towards each label.
Boolean features indicating which label had the maximum association score.
Model tuning
For system tuning we performed a grid search of parameters for each classifier, evaluating different permutations of feature combinations. In parallel we also tuned the unsymmetric cost factors, drawing values from logarithmic intervals. Each model configuration was tested by ten-fold cross-validation on the development data (partitioning on the note-level), and for each label we then selected the combination of feature types and cost factor that resulted in the highest F1.
Results
The cross-validated micro-averaged results on the development data are: Precision = 46.00, Recall = 54.00, F = 49.41. Table 1 lists details of the results of our model tuning procedure. We note that the optimal configuration of features varies from label to label. However, while stems and synonym sets are often in the optimal permutation, dependency triples and features from WordNetAffect do not occur in any configuration.
We note that the unsymmetric cost factor enabled us to improve recall for many classes but this often came at a cost in terms of precision. While this typically lead to increased F1s for individual labels, the effect on the overall micro-averaged F1 was negative. We found that this was due to poor precision on the infrequent labels.
In the end, therefore, we only attempt to classify the six labels that we can predict most reliably–-GUILT, HOPELESSNESS, INFORMATION, INSTRUCTIONS, LOVE and THANKFULNESS–-and make no attempt on the remaining labels. In the development data this increases overall system performance in terms of the micro-average scores: Precision = 61.09, Recall = 51.71, F1 = 55.81. However, it should be noted that this decision is motivated by the fact that micro-averaging is used for the shared task evaluation. Micro-averaging emphasizes performance on frequent labels, whereas macro-averaging would encourage equal performance across all labels.
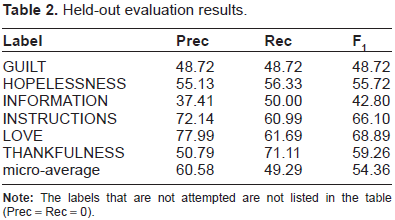
Table 2 describes the performance on the held-out evaluation data when training classifiers on the entire development data set, with details on each label attempted by our setup. As described above, we only apply classifiers for six of the labels in the data set (due to the low precision observed in the development results for the remaining nine labels). We find that the held-out results are quite consistent with those predicted by cross-validation on the development data. The final micro-averaged F1 is 54.36, a drop of only 1.45 compared to the development result.
Held-out evaluation results.
Conclusions
Our approach to the shared task on topic classification of sentences from suicide notes is summarized in Figure 2. Using a variety of external resources, we represented sentences using a diverse range of surface, syntactic and semantic features. We used these representations to train a set of binary support vector machine classifiers, where each classifier is responsible for determining whether or not a label applies to a given sentence. We also experimented with unsymmetric cost factors to handle problems with the skewed distribution of positive and negative examples in the data sets. We performed a grid search of hyper-parameters for each classifier to find optimal combinations of feature types and unsymmetric cost factors.
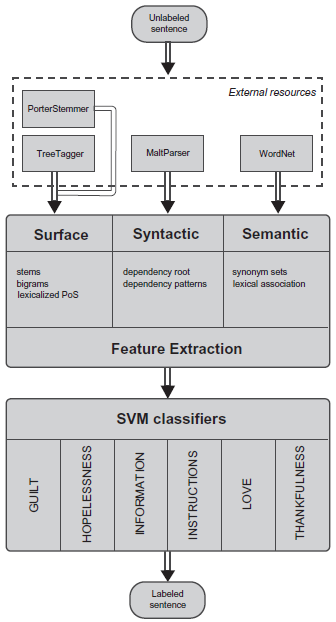
Final system architecture.
In future work we will optimize the parameters for each classifier with respect to the overall F1 (rather than the label F1, as described in this paper). We will also investigate how the performance for labels with few examples may be boosted by drawing information from large amounts of unlabeled text. For example, estimating the semantic similarity of words with prototypical examples of a label using measures of lexical association or distributional similarity can be informative when labeling text with sentiment or emotion. 12 We will experiment with this approach, both as a stand-alone technique, and by including its prediction in features for supervised classifiers.